
Abstract
As a kind of unsupervised learning model, the autoencoder is usually adopted to perform the pretraining to obtain the optimal initial value of parameter space, so as to avoid the local minimality that the nonconvex problem may fall into and gradient vanishment of the process of back propagation. However, the autoencoder and its variants have not taken the statistical characteristics and domain knowledge of the train set and also lost plenty of essential representaions learned from different levels when it comes to image processing and computer vision. In this article, we firstly add a sparsity-induced layer into the autoencoder to exploit and extract more representative and essential features exist in the input and then combining the ensemble learning mechanism, we propose a novel sparse feature ensemble learning method, named Boosting sparsity-induced autoencoder, which could make full use of hierarchical and diverse features, increase the accuracy and the stability of a single model. The classification results on different data sets illustrated the effectiveness of our proposed method.
Introduction
When dealing with classification tasks, the performance of the general learning algorithm depends to a large extent on the quality of the feature representation learned from the original input. Good features can not only remove the irrelevant or redundant features coexisting in the original input space but also retain the essential information. Therefore, how to build a good feature extractor is one of the key issues to achieve high performance for various tasks. With the development of deep learning, the feature extractors constructed by unsupervised learning methods are further used in the field of computer vision. At the same time, deep hierarchical features generated by stacked unsupervised models have been proved to be a powerful tool to employ the computer vision tasks, which have brought about the widespread attention in the field of computer vision. 1,2
The sparseness of the representation has been shown to have advantages in robustness to denoising and also improved classification performance in high-dimensional spaces. 3,4 Meanwhile, the sparse representation has proven its significant impact on computer vision. 5 –7 Some works pointed out that the performance of a specific task can be improved if the input image can be represented by sparse representation, and in classification tasks, the networks with sparse structures always have better performance than the dense one, especially for original data set with degraded quality. 7,8 A significant advantage of the sparse representation method is that it can produce coding or feature representation that is more robust to noise. Some methods, such as sparse encoding strategy, sparse regularization term and sparse filtering, have taken the input samples into sparse depth-related neural network model. Based on these strategies, the sparse deep model is proposed recently.
In recent years, deep learning has been widely used in image classification tasks. 9 –12 Autoencoder, a deep learning tool with special structure, has been stacked to pretrain a deep neural network by using a greedy layer-wise means. 13 Then, the unsupervised pretraining method is adopted to initialize the every layer of autoencoder, and back propagation is used for fine-tuning by a supervised learning algorithm, leading to solve the problem of inadequate expressive ability of shallow network. Denoising autoencoder is employed based on image patches, 14 which leads a denoising result among various deep networks due to its peculiar unsupervised feature learning mechanism. Sparse autoencoder, 15 serves as one typical model for unsupervised feature learning, proposed with a sparsity constraint on the hidden units. Since it consists of an encoding stage and a decoding stage and also requires output as much as input data, autoencoder can be recognized as an identical mapping that could reconstruct the original input.
However, when it comes to design a deep network, autoencoder and its variants do not take the statistical characteristics and the domain knowledge of train set into account. What’s more, they also abandon a large number of features obtained from multilayers. Besides, due to the large variance and low generalization ability on the unknown test set, autoencoder usually serves as a pretraining method. Accordingly, how to take full advantage of the characteristics of input is one of the most important focuses in our work. It is well-known that ensemble learning is considered as a practical technique for improving accuracy and stability, which could employs several weak single classifiers according to some combination rules to construct a stronger classifier. To ensure a better performance, two key issues should be considered, namely the diversity and accuracy of each learner and the combination rules used in ensemble learning. 16
In this work, we propose a new sparsity encourage mechanism for autoecndoer and further build a sparsity-induced autoencoder (SparsityAE) that can exploit more representative and intrinsic features from input. Then, to benefit from the ability of ensemble learning method and boost the autoencoders performance, an ensemble sparse feature learning algorithm based on SparsityAE is proposed, named Boosting sparsity-induced autoencoder (BoostingAE). In our work, multilevel sparse features will be obtained when pretraining SparsityAE is complete, and ensemble learning is used in our study, which could effectively improve the accuracy and stability of single learner. Experimental results for classification tasks on different data sets show that the advantages of SparsityAE in sparse feature extraction and that our BoostingAE can significantly improve the overall performance compared with single learners.
Related work
Some related models and methods used in our work will be briefly introduced in this section.
Sparse representation
Sparse coding
Sparse coding provides a family of methods for acquiring the condense representations of input. Usually, we try to learn features from input directly and then reconstruct the data from the learned sparse codes by transforming which from the feature space to the data space. Although sparse coding is closely related to the traditional sparse coding techniques on image denoising, its main disadvantage is the high computational cost. In addition, it is well-known that sparse coding is not “smooth,” 17,18 which means that a small change in original input data space may lead to a significant difference in the code space.
Sparse filtering
Compared with existing feature learning models, an important property of sparse filtering is that it needs only one hyper-parameter for its simple cost function 19

where f represents features learned from input sample,
Sparse regularization
Different from sparse coding, there is no need for sparsity regularization to perform an extra separate stage to induce sparsity and to encourage sparse representations of input, which can make sparsity be induced more automatically and efficiently even a new term is added to its loss function. Various sparse regularization methods are used in deep belief networks or autoencoders, 20 and the results have proved that these methods have beneficial effects for a particular scene.
Softmax regression
Softmax regression is a generalized version of logistic regression, usually applied to classification problems where the class label y can be defined as any one in a label set that has no less than two values. Assume that there are m training samples and k labels:
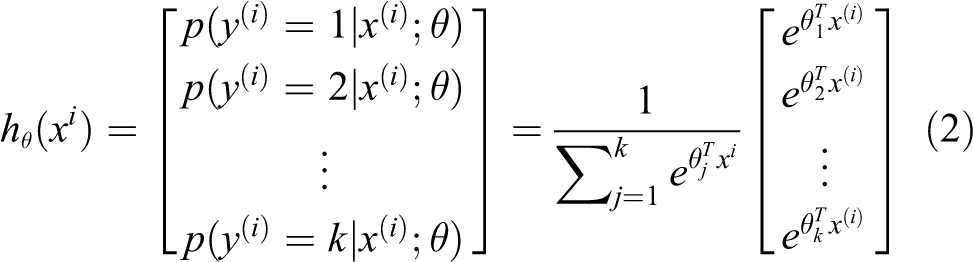
where θ represents the parameter of softmax model, and the probability of its category is estimated to be
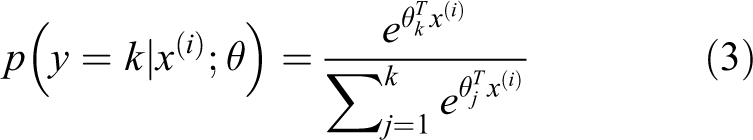
Ensemble learning
In ensemble learning, according to the combination rules, some weak classifiers are used to construct a strong classifier whose generalization error much lower than any weak classifier. Compared to random guessing, the weak learner means that whose generalization performance is slightly better on the unknown test sets. From a mathematical point of view, ensemble learning could effectively reduce variance and achieve more stable performance. To get a better integration result, each weak learner needs to be as different as possible, that is to say, there is a high degree of diversity between the base weak learners, which will be helpful for the performance of ensemble learning.
Boosting method is a widely used method of statistical learning and serves as an important means of ensemble learning. By changing the weights of training samples, boosting method trains multiple base learners, according to a combination rule to get the final decision result.
Figure 1 shows a schematic diagram of the boosting method. Usually, boosting method trains a set of individual learners that learning ability is relatively weak and then adjusts the distribution of training samples according to the classification accuracy of the classifier; after that, the adjusted sample distribution will be used to train the next learner. The above process is operated repeatedly until the number of base learners meets the preset value. Finally, combining the pretrained classifiers with a combination rule to give the final decision output.

Overview of boosting method.
AdaBoost is a well-known ensemble method, which can be adopted in conjunction with many various types of learners to serve as a strong learner. It trains the single classifier in “rounds,” and at each round the importance of training examples is increased that were misclassified in the previous round. The final ensemble is then aggregated using weights that were calculated during the training process.
Boosting sparsity-induced autoencoder
Sparsity-induced autoencoder
Based on the assumptions of the sparse representation and the efficient reconstruction of low-dimensional feature representation obtained in the encoding phase of deep models, a novel sparse feature learning approach, named SparsityAE, is proposed firstly by employing the sparsity property of input and adding an sparsity-induced layer that is placed to the last layer of encoding phase of a stacked deep model, which could efficiently capture the sparse feature representations from multiple layers.
The structure of the SparsityAE is shown in Figure 2. From the topology map, we can tell that the new sparsity-induced layer is added next to the last layer of the encoder phase, also just in the middle of the whole deep hierarchical architecture, which could apply the sparsity constraint to obtain the sparse robust and highly intrinsic features. We input the high-dimensional data set into the encoding stage. With the deepening of the encoder, the length of the code learned from each layer becomes shorter and shorter. The last layer of the encoding stage is followed by a novel sparsity-induced layer to generate sparse code. In contrast, the decoding stage reconstructs the compressive and sparse codes given by the sparsity-induced layer.
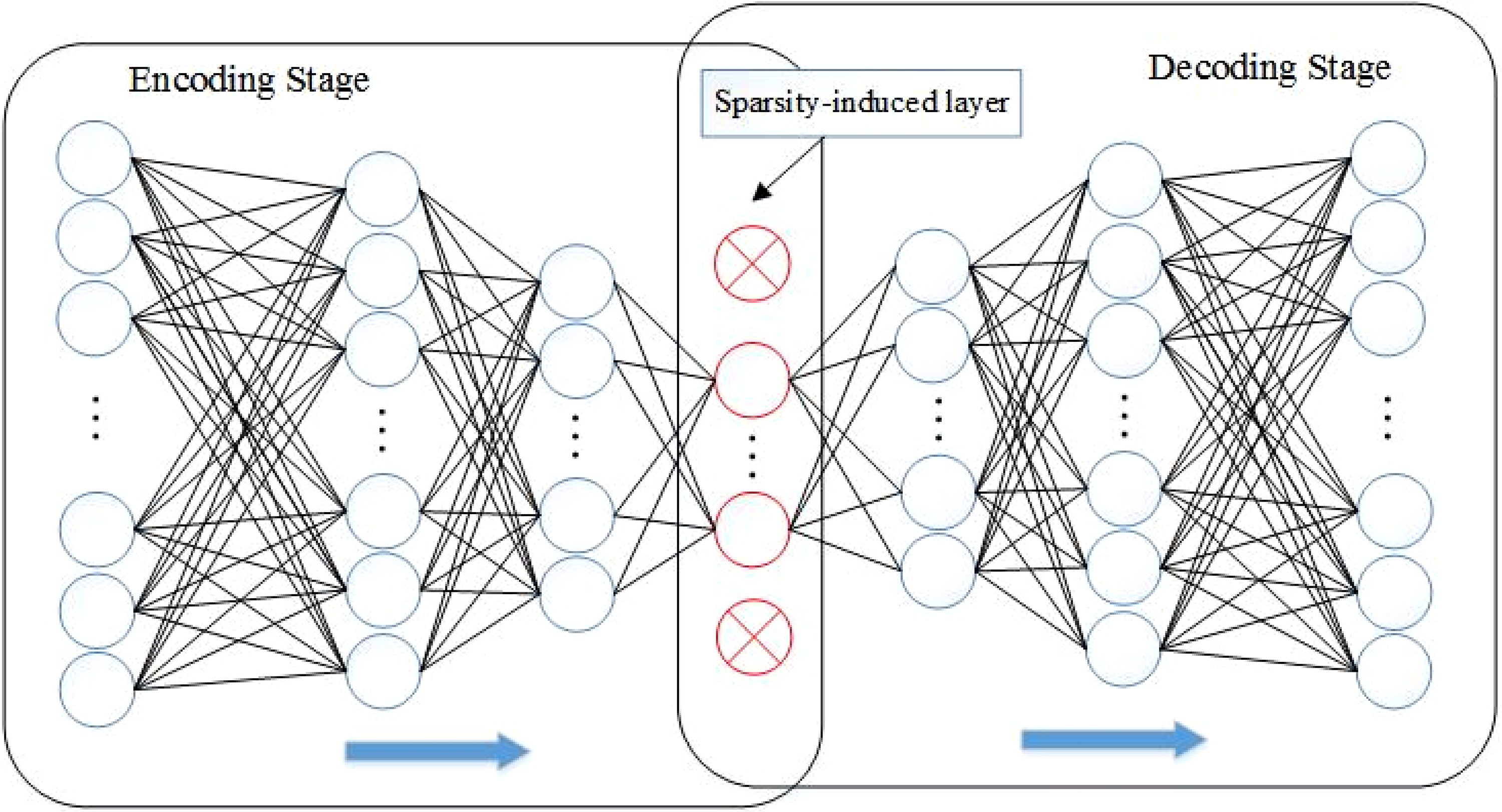
The topology of the proposed SparsityAE.
In SparsityAE, the number of neuron decreases layer-by-layer. In the sparsity-induced layer, according to the threshold set in advance, the neurons whose activation value lower than threshold will be set to zero, while retaining other neurons whose activation value is significantly higher than that threshold. The introduction of sparsity-induced layer could not only compress the original input space by reducing the number of neurons but also eliminate the correlation among attributes. That is to say, it reduces the complexity of the model and further improves the generalization ability of the model. In the view of the neural network, the deeper the layers are, the more abstract and essential features can be extracted.
Assuming that
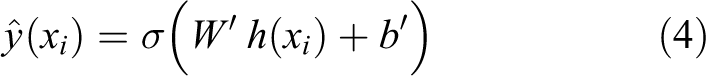
where
For our SparsityAE, we optimize the reconstruction loss regularized by a weight decay and a sparsity-inducing term. The cost function can be designed as follows
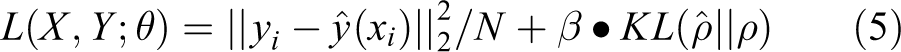
where
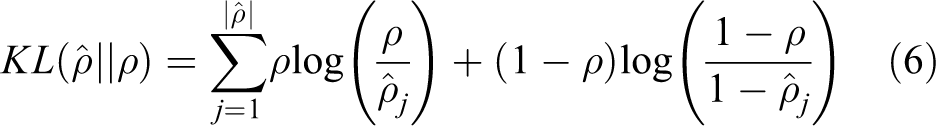
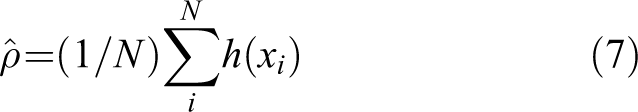
As shown in Algorithm 1, we initialize the data by computing the pairwise data similarity and determine the reconstruction coefficient for each data firstly. After that, minimizing the loss function by using the stochastic gradient descent to update network parameters. Then, updating the data according to the hidden representation derived from the SparsityAE and setting the neurons without significant activation value to zero. Repeat the steps (2), (3), and (4) until convergence.
SparsityAE

Feature ensemble method
With the SparistyAE introduced above, we can obtain multiple sparse features. And considering that ensemble feature learning can significantly increase the accuracy and stability of the single classifier, a BoostingAE based on SparsityAE and ensemble learning is proposed.
To make the whole structure easy to understand, Figure 3 shows a detailed construction of BoostingAE, which indicates that BoostingAE is theoretically possible to obtain multiple sparse representations that come from the cascaded SparsityAEs. Suppose a deep net with N hidden layers for image classification has been trained, N SparsityAE s will be pretrained to set initial values of boosting network and, therefore, produce N representations of input data. To make full use of the learned representations, a classification algorithm is selected to train the first M representations to obtain M corresponding classifiers. Finally, a fusion rule is used to aggregate the results of multiple classifiers so as to get the final prediction result.

The topology of the proposed BoostingAE.
Specifically, we train three SparsityAEs to establish the BoostingAE. First, we train SparsityAE_1 in Figure 3. Let x be the original input,

Treat

From the horizontal direction, the sparse features learned from the current layer will be passed to the next SparsityAE through the above process. As a result, all of three SparsityAEs can be trained. At the same time, three trained classifiers and their corresponding optimal parameters will be obtained by the softmax regression and the training of the feature representations at the encoding stage.
Combination method of voting
When all three classifiers are set up, final prediction is given by the fusion result of all classifiers with a specific fusion rule. Here, the Naive Bayes combination rules 21 are applied, which assume that individual classifiers are mutually independent. Naive Bayes combination rules include MAX rule, MIN rule, and AVG rule. In our work, we will adopt all three combination mehtods mentioned above.
Given a sample x and its label y, where y has L possible values. Suppose that BoostingAE contains N base classifiers, and
MAX rule:

MIN rule:

AVG rule:

BoostingAE algorithm
From Figure 3, BoostingAE includes an input layer, some hidden layers and an output layer to carry out specific tasks, of which SparsityAE are mainly employed to provide sparse features for next layer.
Here, two key problems will directly affect the performance of the BoostingAE: how to measure the importance of feature of every layer and how to select the optimal model for each base learner. A main contribution of this article is that Adaboost will be employed to supervise the adjustment of parameters and weight coefficients. Algorithm 2 gives the detailed explanation of BoostingAE. The traditional sparse stacked autoencoder, especially in the encoding stage will extract multilayer features. However, it only uses the output of the last layer of the encoding stage, which wastes the features learned from other layers when it comes to the image processing.
BoostingAE

BoostingAE can make full use of the multilayer features by integrating base classifiers, thus avoiding the waste of computing and storage resources. And the representations extracted from multiple layers enhance the diversity of base learners in integrated learning architecture, which is more conducive to the performance of integrated learning. More concretely, BoostingAEs characteristics are shown in following aspects: Similar to AdaBoost, BootingAE also adopts the cascade serialization mechanism rather than the parallel one to combine base learners, which makes the individual learners interrelated but different. The output of the current layer will be the input of the next layer to get more features. While further deepening the network and acquiring abundant feature representation, it also makes the “training samples” received by every individual learners have great differences. In the designing of individual learners, the topology of each model can be defined separately, rather than by a unified model. This can not only maintain the homogeneity of basic learners but also further increase the diversity of individual learners.
Experiments
In this section, we will verify the performance of SparsityAE with respect to sparse feature learning first. Next, to accurately illustrate the performance and stability of the proposed ensemble sparse feature learning method on real-world image processing and computer vision tasks, BoostingAE will be carried out on three widely employed image data sets. Moreover, we also provide the compared results by employing some state-of-the-art methods on same data sets.
The sparse feature learning of SparsityAE
In this part, we mainly focus on denoising of gray scale images. A group of natural images that come from http://decsai.ugr.es/cvg/dbimagenes are employed as the train set, and a group of standard natural images as the testing set has been widely used in the image processing.
Before the stage of training, we select a clean image y randomly from the data set and corrupt it with a specific strength of additive white Gaussian noise to generate the corresponding noisy image x. At the end of the training process, given any noisy image, the model can reconstruct its corresponding clean image. To avoid the local minimum, we adopt the layerwise pretraining procedure. 13
First, Figure 4 shows the visualization results of the learned weight matrix of autoencoder with KL-divergence sparsity constraint only and SparsityAE, respectively, which means that the features obtained from SparsityAE can describe the edge, contour, and texture details of the image more accurately and also indicates that SparsityAE could learn more representative features from the inputs. Moreover, the comparison with the autoencoder with KL-divergence sparsity constraint which also shows good performance of SparsityAE is due to the introduction of sparsity-induced layer.

The learned weight matrix visualization results of different autoencoders. (a) Left one is the visualization of autoencoder with KL-divergence sparsity constraint only, and (b) the right is the result of our method.
Next, to compare the denoising performance of our SparsityAE with some classic methods such as KSVD
22
and BM3D,
23
we implemented the above methods on standard testing images, which have been degraded by different noise levels. Figure 5 illustrates that when the model is trained with the noise, image degradation is only

Denoising performance comparison of various methods with various noise levels.
Table 1 gives the numerical denoising results of SparsityAE, KSVD, and BM3D, which is measured by the peak signal-to-noise ratio (PSNR in dB). And we highlighted the best result of each image in bold. Besides, we also compare SparsityAE and other state-of-the-art denoising methods, WNNM, 24 and two training-based methods, MLP 25 and TNRD, 26 in Table 2. The results show that KSVD and BM3D are more suitable for processing images with a large number of repetitive structures, but the adopted method in this study is better in all images, except Couple and Barbara. In addition, our SparsityAE can compete with WNNM, MLP, and TNPD.
Comparison between SparsityAE, KSVD, and BM3D measured by PSNR.a

SparsityAE: sparsity-induced autoencoder.
aThe best result of each image is provided in boldface.
Comparison between SpasityAE and several state-of-the-art denoising measured by PSNR.a

SparsityAE: sparsity-induced autoencoder.
aThe best result of each image is provided in boldface.
From the above results, we known that SparsityAE, the crux of the subsequent work, can project the original high-dimensional space to a lower dimensional and more intrinsic space from the dimensionality reduction point of view but also capture the more representative sparse features derived from multilayers to make full use of the information contained in inputs. SparsityAE is a more streamlined and targeted network structure and effectively improves its performance in image denoising.
BoostingAE for classification on MNIST
MNIST is a widely used handwritten digits data set, and the size of each image is 28 × 28. It consists of 60,000 training images and 10,000 testing images.
For illustration of the performance of BoostingAE on MINIST, we need to establish the topological structure of the BoostingAE for MNIST. The topology is
Table 3 lists that the classification results of three base classifiers are better than those of KNN and SVM because of the introduction of the sparsity-induced layer. And under the effect of three different fusion rules, BoostingAE achieves 98.37%, 98.43%, and 98.87% accuracy rate, respectively, which are better than any individual classification and very close to Lpnorm AE. 27 Moreover, benefiting from convolution operations and hidden layers, stacked CAE 28 and CASE 29 can extract more abstract features of input, so the result of our BostingAE is slightly worse than theirs.
Numerical results of classification on MNIST.

BoostingAE for classification on CIFAR-10 and SVHN
CIFAR-10 includes 10 types of color images, and each category contains 60,000 28 × 28 color images. The train set consists of 5000 images in each category, a total of 50,000 training images, and the remaining images are used for test. Its images are obtained from the real life so the background is more complex and comparing with other simple data sets are difficult to identify.
SVHN data set is also drawn from the real world and can be viewed as the deformation and upgrade of MNIST, but it has a more complex objective environment than MNIST because there is not one number in each image (the images are cut from house number plates so the category is decided by middle number). Same as MNIST, SVHN data set also contains 10 types of color images, as well as be marked as 0–9. SVHN includes a train set, a testing set, and an extra set. The validation set is derived from the train set and the extra set. It is generated randomly: two-third of it comes from the train set (400 samples per class), and the rest are from the extra set (200 samples per class).
Before the experiment, it is necessary to transform the images of CIFAR-10 and SVHN from RGB space into gray space and then normalize them. In the process of pretraining and fine-tuning the model, a mini-batch gradient descent algorithm will be implemented to improve the training efficiency. Taking into account, the unsupervised learning mechanism of autoencoder, both CIFAR-10 and SVHN use a certain proportion of unlabeled samples as train set in pretraining. At the stage of fine-tuning, both two data sets require ground truth to classify the image.
Next, similar to the experimental process on MNIST, the SparsityAE model is firstly determined, whose topology is
Table 4 lists the numerical results of comparison methods, individual classifiers that are based on the sparsity-induced layer, and the proposed method. From the results in Table 3, we get a conclusion same as that of MNIST. In all comparison methods, our method has achieved the best result.
Numerical results of classification on CIFAR-10 and SVHN.

From the experiments of BoostingAE on three data sets, the individual classifiers Classifier_1, Classifier_2, and Classifier_3 have better classification results than or close to comparison methods because of the introduction of sparsity-encouraged mechanism in SparsityAE. Moreover, the BoostingAE with three different fusion rules achieve better performance than any other methods, and compared with the single classifier, more than three percentage points is improved, among which AVE rule is more stable, the MAX rule is worse, MIN rule in the middle. All of the experimental results illustrated that BoostingAE can not only capture more sparse representation but also utilize the multilayer features, resulting in the improvement of accuracy and diversity of overall model.
Conclusions
Based on the sparse representations of general signal and the efficient reconstruction of low-dimensional features obtained in the encoding stage of deep models, we first introduced a novel sparsity-encouraged mechanism to build SparsityAE by adding a sparsity-induced layer, which could efficiently induce the sparse feature representations of input data. And then, on the basis of SparsityAE and ensemble learning, considering that the multilayer features of input data will be learned after training several SparsityAE s and the input has not been exploited and reused reasonably, we proposed BoostingAE that could make full use of the more abstract and intrinsic features learned from multilayers and improve the performance of individual learners under the premise of guaranteeing the accuracy and diversity of base learning classification. An experiment about image denoising and the experiments of image classification on three different data sets validated the effectiveness of the proposed algorithm.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work was jointly supported by the National Natural Science Foundations of China under grant No. 61772396.