
Abstract
The main challenge of using robots in social environments such as houses is coping with the frequent changes in tasks. Since it is infeasible to come up with an implementation for all possible cases of all tasks, robots should find solutions for new problems by themselves. So, learning is one of the major abilities for a robot to deal with changing tasks. However, it is generally time-consuming to find even a near-optimal solution for complex tasks through learning. On the other hand, learning in humans is a never-ending process and much faster, thanks to transferring prior knowledge. In this work, we build a knowledge base (called as skill library) from the subsets of the tasks discovered during the learning process. Since most of the tasks encountered have common subsets, the skill library enables us to transfer previous experiences while learning the strategy of a new task. The robot progressively accumulates skills to reduce the difficulty of learning the forthcoming tasks. We choose navigation in different unknown environments as the test bed. The results show a significant improvement especially on the performance of the robot in the initial episodes, a substantial reduction in the cost of the overall learning process, and in the convergence time to the (near-)optimal policy.
Introduction
Recently, the use of robots in social environments such as houses is becoming popular. However, even small changes in the tasks or the expectations of the household members may lead to a substantial algorithm redesign effort. It is not feasible to handle requests by developing algorithms for each task. Thus, personal robots should have learning capability for changing tasks and expectations. Unfortunately, it is a time-consuming process to learn solutions for robotic problems. Humans, however, have the ability to learn to cope up with new problems easily.
Piaget 1 introduced the developmental nature of learning in humans. Adaptation and development of intelligence are to maintain the equilibrium between the actions of the organism on the environment and vice versa. Thus, intelligent creatures are expected to adapt their behaviors to the changes in their tasks. Acquiring new skills as an abstraction in a learning process may enable robots to cope up with changing household expectations.
We can model most of the robotic problems as a Markov decision process (MDP). 2 MDPs are defined by state space (S), action space (A), transition probabilities (T), and reward function (R). States are the representations of the internal and external configurations of the agent. Actions are the abilities to change its state. Transition probability determines the probabilities of being in a state after an action is taken. It is a mapping from S × A × S to probabilities. The reward function is the prize or the punishment received for the resulting state. The main problem in MDPs is finding the (near-)optimal policy (π) to accomplish the given tasks.
Reinforcement learning (RL) 3 is a popular learning approach to find the (near-)optimal policies by interacting with the environment through experiences. In RL, unlike supervised learning, rewards are scarce and are generally received at the end of each episode. So, this approach is more suitable for real-world problems where the goodness of each and every action cannot be readily defined. When the state and/or action spaces are huge and/or there are bottleneck states like in Figure 1 (i.e. the scarce edges to go from one state cluster like cluster A in the figure to another one like cluster B in the figure), the problem becomes complex. Since RL suffers from the curse of dimensionality, it is not feasible to apply it to complex tasks.

Two state clusters and one subgoal to separate.
Hierarchical Reinforcement Learning (HRL) 4 and Knowledge Transfer (KT) or Transfer Learning (TL) 5 are two popular approaches to make learning feasible in real-world applications by reducing the complexity of the tasks. In the HRL approach, the problem is represented as a layered structure and divided into simpler ones. In this way, a divide-and-conquer strategy can be applied to prevent the curse of dimensionality.
In addition to the curse of dimensionality, the agent usually spends too much time during the exploration process, especially in the initial episodes. The initialization of the Q-values that determine the Quality of the state-action pairs in Q-Learning 6 has a dramatic effect on the time spent in the exploration phase. TL aims to address this problem by starting the learning process with a better initialization rather than a random one.We can define this as the utilization of the knowledge obtained at the end of the learning process of previous task(s) (i.e. source task(s)) in that of new task(s) (i.e. target task(s)).
In this work, we address the learning ability of an agent as a life-long process and propose a novel TL algorithm combining with HRL. Since most of the tasks encountered have common requirements, previous experiences should improve the learning speed in the life-long learning approach. As this is a never-ending process, we propose to build and transfer an accumulated knowledge base. On the other hand, they may also have conflicting or irrelevant requirements which make the tasks different. Because forthcoming tasks are unknown, the knowledge base should contain the information independent of the task definition. So, the entities in a good knowledge base should contain useful information which is common for the majority of the tasks and exclude task-specific information that may cause a negative bias in the exploration stage.
The main contribution of the proposed approach (This article is an extended version of previous works 7,8 ) is that the robot transfers the partial knowledge that is expected to be useful in target task.
In the proposed approach, we design an agent to be fully-autonomous and operate without any human intervention. It autonomously determines the bottleneck states that are possibly common and difficult to learn for different tasks and stores the policies to reach those states in the knowledge base as a new skill. The knowledge base is called as a skill library. An agent can also extract the most useful skill(s) from the skill library probabilistically for the new task. To analyze the performance of the proposed approach, we conducted experiments on the grid world navigation problem in three different environments with different characteristics. The results are compared with no transfer where the learning process starts from scratch and full transfer where the learning process is initiated with the previously learned model. It is also compared with one of the state of the art approaches, Probabilistic Policy Reuse 9 (More detailed results are given in our previous studies 7,8 ).
In addition to the performance analysis, the time and space complexity of the proposed approach is also given for the feasibility in real-world applications.
Related work
The main drawbacks of RL are long exploration periods and curse of dimensionality. HRL and TL are the two well-known approaches to improve the learning process of RL.
Hierarchical reinforcement learning
Most of the real world tasks are combinations of simpler ones. While an agent is learning a task, it needs to solve others unknowingly. The HRL approach represents the problem in a hierarchy. There are mainly three ways to construct the hierarchy and represent the subproblems; learning complex actions as a combination of simpler ones like the options framework,
10
using non-deterministic finite-state controllers such as Hierarchy of abstract machines
11
and representing subproblems in terms of a termination predicate and a local reward function like MAXQ.
12
Although all these approaches improve the learning process, the system starts from scratch when the task definition is changed. Autonomous subgoal discovery is one of the most popular ways to construct the hierarchy. Subgoals are defined as critical bottlenecks in the environment. For example, as it is shown in Figure 1, if there are two state clusters (A and B) and there is a bottleneck state (
Graph-based approaches represent the problem as a graph. Here, the states are the nodes and the transitions determine the edges in the graph. Hengst
13
proposes to represent experiences (i.e. trajectories which can be defined as paths without cycles followed in each episode) as a directed graph. For example, if one of the paths has an action
Metric-based approaches use measurements for features of the states and transitions. Although the time complexity of algorithms is low, the resulting subgoal states do not divide the state space as well as the graph-based approaches do.
Kretchmar et al. 20 propose a subgoal discovery approach by merging the frequency and distance metrics. Both features are calculated from successful T trajectories where cycles are pruned. Following equations are used for calculation
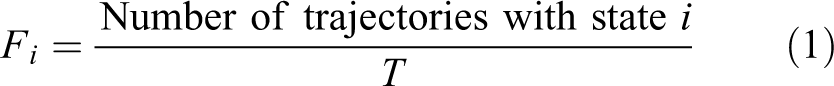


Here, g is the goal state and lt is the trajectory length. The metric used to define the subgoal is the product of frequency and distance measurements (i.e. A sub-goal state is a state with the following structural property: the state space trajectories originating from a significantly larger than expected number of states lead to the sub-goal state while its successor state does not have this property.
Transfer learning
The second approach to improve the performance of RL is transferring the experiences from previously learned task(s). In the definition of TL methods, there are two types of tasks: the source task(s) and the target task(s). Source tasks can be defined as the tasks where knowledge has been obtained and can be reused to improve forthcoming learning processes. On the other hand, the target task is defined as the new goal which is aimed to be learned lastly. If the state and action domains are the same in both the source and target tasks, it is classified as an intra-domain transfer. Otherwise, it is called as inter-domain.
Fernandez and Veloso 9 propose reusing the previously learned policies to improve the exploration stage of the learning process. They also construct a policy library. When a new task occurs, the agent chooses one of the policies in the policy list probabilistically. At the end of each episode, the agent updates the weight of the selected policy as

where K is the number of policies in the policy list, H is the number of actions taken, γ is the discount factor, and r is the reward function. Since the source and target tasks are defined in the same domain, it can be classified as an intra-domain transfer. The policy list does not include all the policies. Thus, the main problem in this approach is determining the list to be reused. In another TL approach, 23 policies are stored as relational macros called Skills. Skill transfer is achieved via inductive logic programming (ILP). The robot uses the knowledge obtained in the training process of “2 on 1 breakaway task” to learn the policies for “3 on 2” and “4 on 3 breakaway tasks.” Since the rules are directly transferred, the domain of the target tasks should be very similar to that of the source task even if it is an inter-domain transfer. Barrett et al. 24 apply TL for RL on a real robot, called Nao. The experiment is about hitting a ball to throw it with 45°. In the experiment, the state consists of the positions and velocities of the joints, and the actions are the increase or decrease in the joint velocity in 10° s−1 . In the source task, the robot has control on two shoulder joints. Therefore, the learning process is fast but the success rate of the robot is low. As the target task, the robot can control all four joints in the shoulder. The learning process starts with the latest Q-values of the source task. Taylor and Stone 25 propose to use the learned policy for a domain as an advisor for learning other tasks in other domains. Rule transfer maps two different domains. Although it is mainly handled manually, an example is shown to learn the rule translation function between keep-away and ring-world tasks. They use Radial basis functions (RBF) as the action-value function.
Ammar et al. 26 propose an inter-domain TL approach. Common subspaces are constructed to find the mapping between two domains via taking state samples from the source and target tasks. Since the domains of the tasks are different, a common subset of those domains is the domain of the common subspace. The key idea in the mapping is the ease of defining common subspaces. The mapping function is fitted on the samples in the common subspace via locally weighted regression. Learning in the target task starts with the transferred policy of the source task via the corresponding mapping function. Although the idea works for most cases, it requires having common parts in the representation of tasks. Additionally, the samples from the tasks should cover the domains as much as possible to have a well-defined mapping. Thus, the success depends on the quality of the supervision.
Although these methods are promising, when the definition of the target problem has conflicts with the source task, it becomes necessary to define a mapping function between the states of the source and the target task. Finding such a function is generally non-trivial since it may mislead the agent in learning the policy for the target task.
Proposed approach
As mentioned in the section “Introduction,” learning is a life-long process and the initialization of the model has serious effects on the overall process. Additionally, the rewards for an action in the real world are scarce and it is not always possible to define immediate rewards. RL is suitable for such real-world problems. In RL studies, two approaches are commonly used for initial model:
In this work, we assume that most of the tasks have both common and conflicting/irrelevant requirements. Ideally, we should transfer only the knowledge about the common requirements to avoid negative transfer. If we call such requirements as subtasks or subgoals, we can define the nth task in terms of subtasks (

where f is an unknown function between new task and previous tasks and novel part. Gn is a task of the agent defined as a MDP as explained in “Introduction.” The aim of the learning process is to find the (near-)optimal policy (π) for a given MDP (Gn).
X is the novel part of the new problem which makes the problem different from other tasks and can also be defined as an MDP.
To improve the learning process using the prior knowledge obtained in earlier learning processes, we propose a novel TL approach to reduce the learning process of a new task to finding the most appropriate “f” which transfers only the commonly required skills that can be defined as learned solutions for subtasks and learning “X.” We measure the use of each skill in the learning process on a new problem to find the (near-) optimal “f.” Because “X” is unknown, we cannot transfer any knowledge for it. It should be learned from scratch (i.e. find the policy
The flow of our approach is given in Figure 2. At the end of each training process, the agent determines the states with a high probability of being required in the forthcoming tasks and generates skills to reach them. After updating the skill library, the agent starts to wait for a new task. When a new task is requested, the agent selects skill(s) from the skill library probabilistically and searches for a solution to accomplish the task with the selected skill(s). At the end of each episode, the conditional probability of selecting the corresponding skill(s) is updated with the performance of the agent. When the requested task is learned, new subgoals are discovered and the skill library is updated with the generated skill(s). In this way, the learning process continues whenever a new task is requested. The details of the proposed approach to learn a single task are given in Algorithm 1. As it is shown in Figure 2 and Algorithm 1, there are two important steps to construct the knowledge base for the performance improvement; how to choose a skill; and how to discover new skills to enrich the skill library.

Flow diagram of the proposed approach.
Partial transfer learning.


Skill selection
In this work, we propose to select skills according to a probability distribution with the following random variables:
C: Convergence of the system,
The aim of skill selection is to find the skills satisfying

where si is the goal state of the skill i.
Main criteria to find the most useful skill(s) are based on the similarities with the new task and the performance of the agent with the selected skill. Thus, joint probability is calculated as follows

Since the model of the problem and relationship with previous experiences are unknown, we define heuristic functions to model distributions. For prior probability distribution for the skill selection (

Example prior probability distribution where
Since the prior probability distribution disregards the transition probabilities, it may not be sufficient for finding the most commonly required skills. As an example, we can consider a sample MDP shown in Figure 4(a). In this MDP, the agent is expected to learn policies for three different tasks. Tasks are going from


Misleading prior distribution. (a) Sample MDP and (b) initial knowledge for third task. MDP: Markov decision process.
Skill generation
While updating the skill library with the new skills, the distribution of their goal states in the state space is important for the coverage of the skill library. Subgoals discovered in the learning process are the goal states of the skills and will be the potentially required states for most of the tasks. In this work, we discover the subgoals autonomously based on the
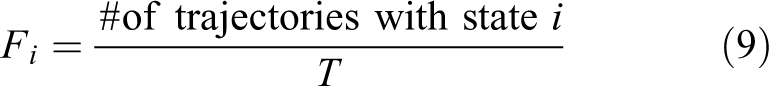


The metric to define the subgoal is the multiplication of frequency and distance measures (i.e.
Skill library update.


Experimental results
In the proposed approach, the coverage of skills, that is, distribution of subgoals, has a critical impact on the performance. Thus, we first analyze the quality of subgoals. Additionally, we test the performance of partial transfer learning (PTL) and the effects of the assumptions on the learning process, including the known goal state assumption in terms of the metrics explained in Langley’s work. 27
Experimental setup
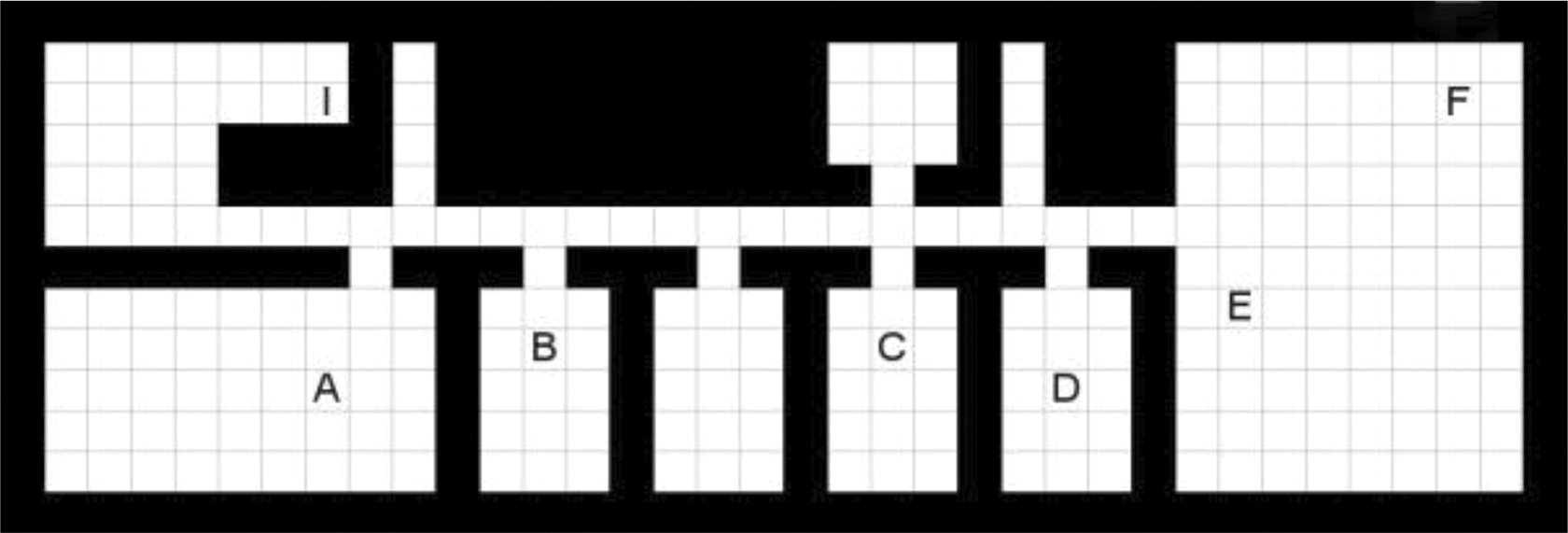
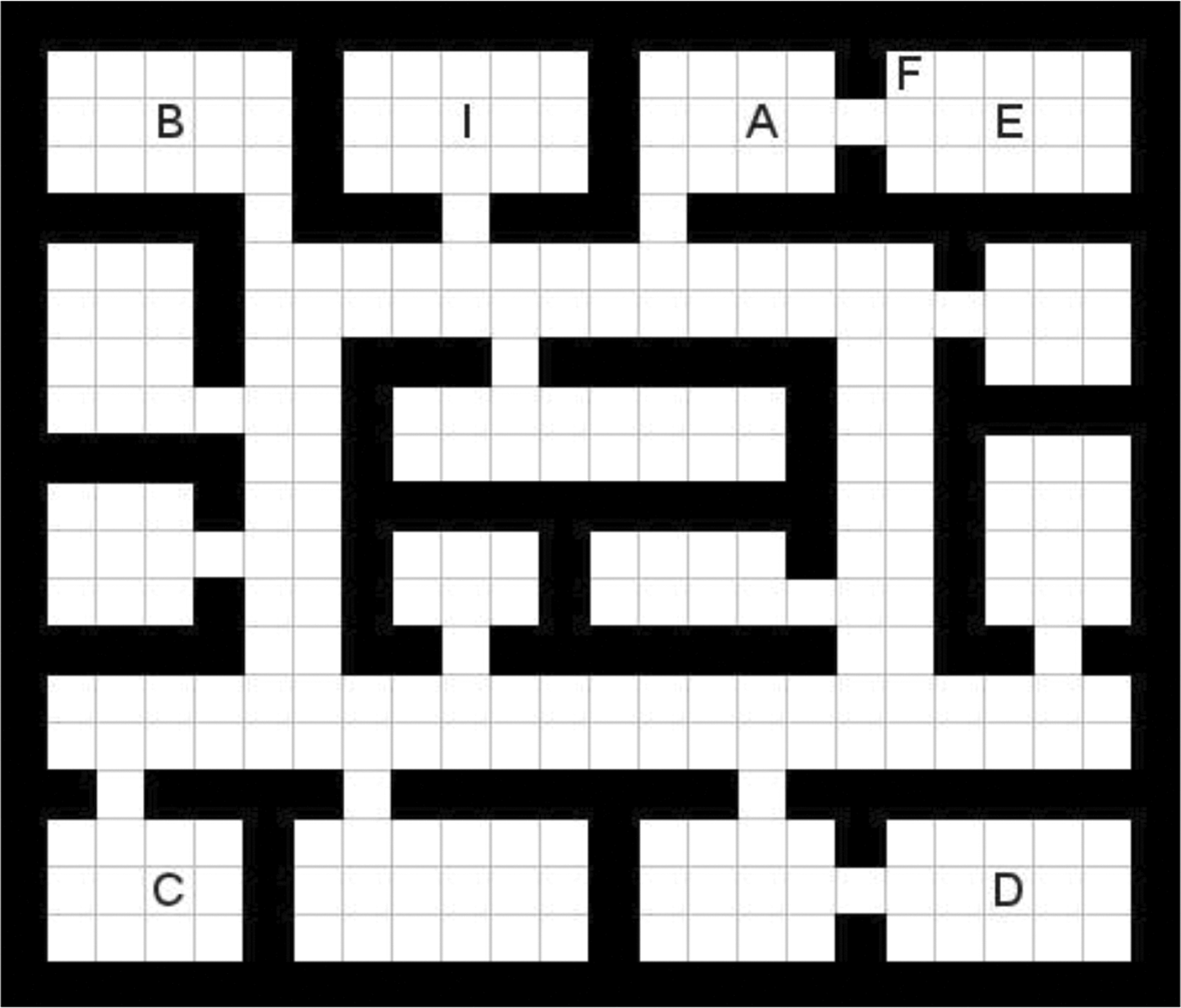
Navigation in a grid world is a common AI test bed for learning approaches. We conduct experiments to teach an agent to navigate in three unknown indoor environments. Each environment has different challenges. The agent has four actions to move from one cell to the neighboring cells. States are represented by the coordinates of the grid cell. In each environment, the agent starts from the location labeled as “I” and learns to reach one of the locations labeled as “A, B, C, D, E, and F.” The tasks are encountered in alphabetical order. In the experiments, the agent is rewarded if it reaches to the target position and no punishment is applied for other actions. Environment 1: The first configuration (Figure 5) helps us to visualize the incremental structure of the learning process. The agent starts learning to reach a close location and it is required to pass through only one doorway. While learning simpler tasks, skills are acquired in order to be able to learn more complex tasks which in this case require passing through additional doorways. Since the doorways are the bottleneck locations without any alternatives, the number of required doorways to reach the target location determines the complexity of the task. In this configuration, the complexity increases regularly, since one room with the same size and door location is added for each new task. Environment 2: The second configuration (Figure 6) is one of the floors of our department building. In this configuration, there are dead ends and rooms with doors opening to a common corridor. The complexity of the tasks is similar to that of the previous configuration. The main difference in this configuration is that the complexity does not increase regularly. The tasks do not require visiting the rooms of the previous tasks, but the door of the room where the target is located gets further away in the corridor as the complexity increases. Environment 3: The last environment has the same configuration with the environment used in the probabilistic policy reuse approach.
9
In this configuration (Figure 7), the complexity of the tasks is not increasing. On the other hand, the tasks require following not only similar paths but also different paths.

Environment 1.
Environment 2.
Environment 3.
Incremental subgoal discovery
The performance of the proposed approach highly depends on the skill library. To improve the performance significantly, the skill library should contain abilities to reach states which are mostly required for different tasks. To determine the most commonly required states in a domain, we run the original

where n is the number of states,
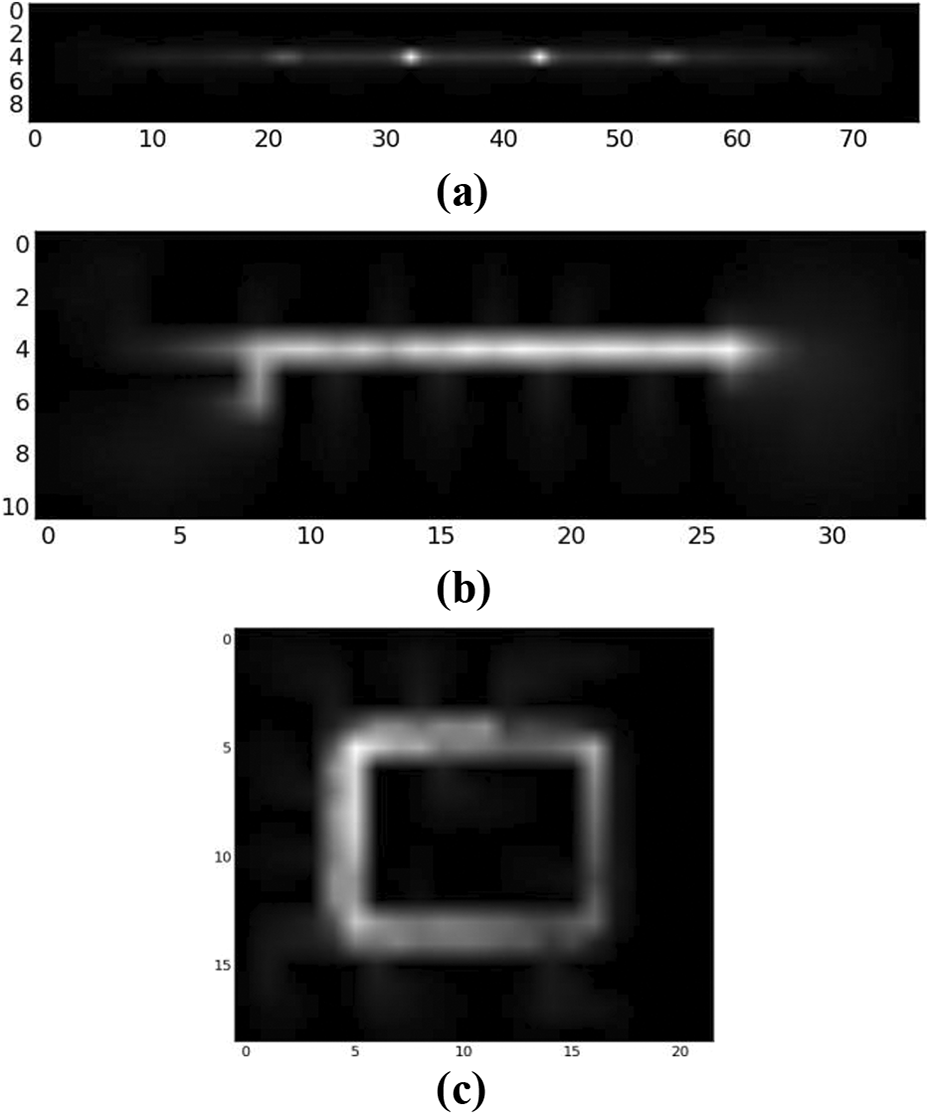
Subgoal selection frequencies. (a) Environment 1, (b) environment 2, and (c) environment 3.
We analyzed the F/D metrics of each state to compare the incremental subgoal discovery approach with the Kretchmar’s work.
20
Since the use of the incremental approach highly depends on the skills that are already stored in the library, we analyze the results after the policies for the tasks A, B, and C have been learned and some skills have been developed. Environment 1: In Figure 9, the results for Environment 1 are shown. In this environment, the rooms are sequential and each room is connected to the next room through the doorway. When the goal location is not in the next room of the initial location, the agent should pass through more than one bottleneck locations. The

F/D metrics calculated by original algorithm and incremental approach in environment 1. (a) Task D original algorithm, (b) task D incremental approach, (c) task E original algorithm, (d) task E incremental approach, (e) task F original algorithm, and (f) task F incremental approach.
On the other hand, our approach uses prior knowledge to find the bottleneck states not included in the knowledge base. Because the complexity of the tasks increases monotonically, new subgoals are concentrated on the doorways as shown in Figure 9(b), (d), and (f). Figure 8(a) shows that those doorways are the most commonly selected subgoals. Environment 2: The results in the second environment are similar to that of the first environment as shown in Figure 10. When the goal locations are in the small rooms, the proposed approach selects the doorways of the corresponding rooms, because the corridor is also a bottleneck for simpler tasks and has already been learned. If the goal position is located in the big room, the agent selects a location in the room instead of the corridor, because the corridor is already learned and stored in the skill library. Additionally, the agent starts to find important locations in the bigger room when the tasks start to aim locations in the bigger room. Environment 3: The third environment has different characteristics than the others; the complexities of the tasks do not increase regularly. Thus, it is easier to interpret that the proposed approach tries to distribute the sub-goals in the environment. The main reason for the difference between Figure 11(a) and (b) is that the proposed approach has acquired knowledge about the upper part of the corridor from the previous tasks (tasks A and B). Since the incremental approach wants to obtain a skill which covers information about the unknown part as much as possible, the new subgoal is located in the lower part of the corridor. Similarly, the known part is eliminated in Figure 11(c) and the unknown part gets more focus as in Figure 11(d). Tasks E and F are the incremental versions of Task A. So, the system prefers to acquire knowledge about the additional parts (i.e. inside of the room) as in Figure 11(f) and (h).

F/D metrics calculated by original algorithm and incremental approach in environment 2. (a) Task D original algorithm, (b) task D incremental approach, (c) task E original algorithm, (d) task E incremental approach, (e) task F original algorithm, and (f) task f incremental approach.

F/D metrics calculated by original algorithm and incremental approach in environment 3. (a) Task C original algorithm, (b) task C incremental approach, (c) task D original algorithm, (d) task D incremental approach, (e) task E original algorithm, (f) task E incremental approach, (g) task F original algorithm, and (h) task F incremental approach
Convergence speed to (near-)optimal policy
The proposed approach aims to transfer policies only for common requirements in the learning process of a new task. In this way, the agent can eliminate the conflicting requirements and transfer only the related knowledge. Similarly, Fernandez and Veloso 9 propose a probabilistic policy reuse approach to store all policies to speed up the learning process in different problems. Thus, we compare the learning process of our work with that of the probabilistic policy reuse approach (The approach proposed by Fernandez and Veloso 9 ). We also compare the performance of the proposed approach with that of no transfer where each learning process starts from scratch and full transfer where all the knowledge from previous experience directly transferred. Since the knowledge base plays an important role in the performances of the PTL and probabilistic policy reuse approaches, we consider the learning processes after some of the tasks have already been learned. Thus, we consider task Fs in each environment for the analysis.
We show the learning processes in Figure 12 in terms of the number of primitive steps. The results in the first and second environments show that the proposed method compared to the other methods definitely speeds up the process. In the third environment, task F is very similar to the previous one. Thus, all methods except learning from scratch perform well and learning is completed in a few episodes. In some episodes, the performance of the probabilistic reuse approach degrades because searching for useful policies in the policy library may affect the performance poorly.

Learning process of RL without transfer, RL with full transfer, PTL and probabilistic policy reuse approaches. (a) Environment 1, (b) environment 2, and (c) environment 3. RL: reinforcement learning; PTL: partial transfer learning.
TL metrics
In the previous section, we analyze the performance of the proposed approach and show improvement in the learning rate. Langley 27 defines three metrics to evaluate the TL approaches: jump start, asymptotic performance, and time to threshold. Expected learning curves of the standard and TL approaches and related metrics are shown in Figure 13. Jump start is the improvement on the performance of the agent in the first episode as shown in Figure 13(a). This metric is important for reducing the initial exploration period after the KT. In addition to the improvement on the initial performance, TL also aims to find a better policy than the standard algorithms. Asymptotic performance (Figure 13(b)) is the metric to measure the quality improvement on the learned policy. Lastly, the required number of episodes to increase the performance of the agent to a predefined level, called time to threshold, is also critical. As shown in Figure 13(c), this objective aims to reduce the number of trials in the learning process.

Objectives of the TL. 27 (a) Jump start, (b) asymptotic performance, and (c) time to threshold. TL: transfer learning.
Taylor and Stone 5 define two additional metrics to measure the performance of the overall learning process: total performance and transfer ratio. Total performance is defined as the area under the learning curve. The scale of total performance highly depends on the reward function. Similarly, transfer ratio (r) also measures the overall performance improvement but it is defined as the ratio of improvement on the overall performance over the total performance without KT as given in equation (13). Thus, the transfer ratio is independent of the scale of the reward function

Performance measurements are in terms of the number of actions and less number of steps means higher performance. To represent negative transfer with the sign of the transfer ratio, negative of equation (13) is used as the transfer ratio. If the transfer is positive and improves the performance, transfer ratio represents the ratio of reduction on the number of steps to the performance in the learning approach without transfer.
In addition to the comparison of proposed approach’s performance with other methods, effects of different characteristics (supervised skill selection and unknown goal) are also measured in terms of those metrics. Because these are random processes, each experiment is repeated 30 times, and the average values and standard deviations (in the parenthesis) are considered in the analysis. The results are given in Tables 1
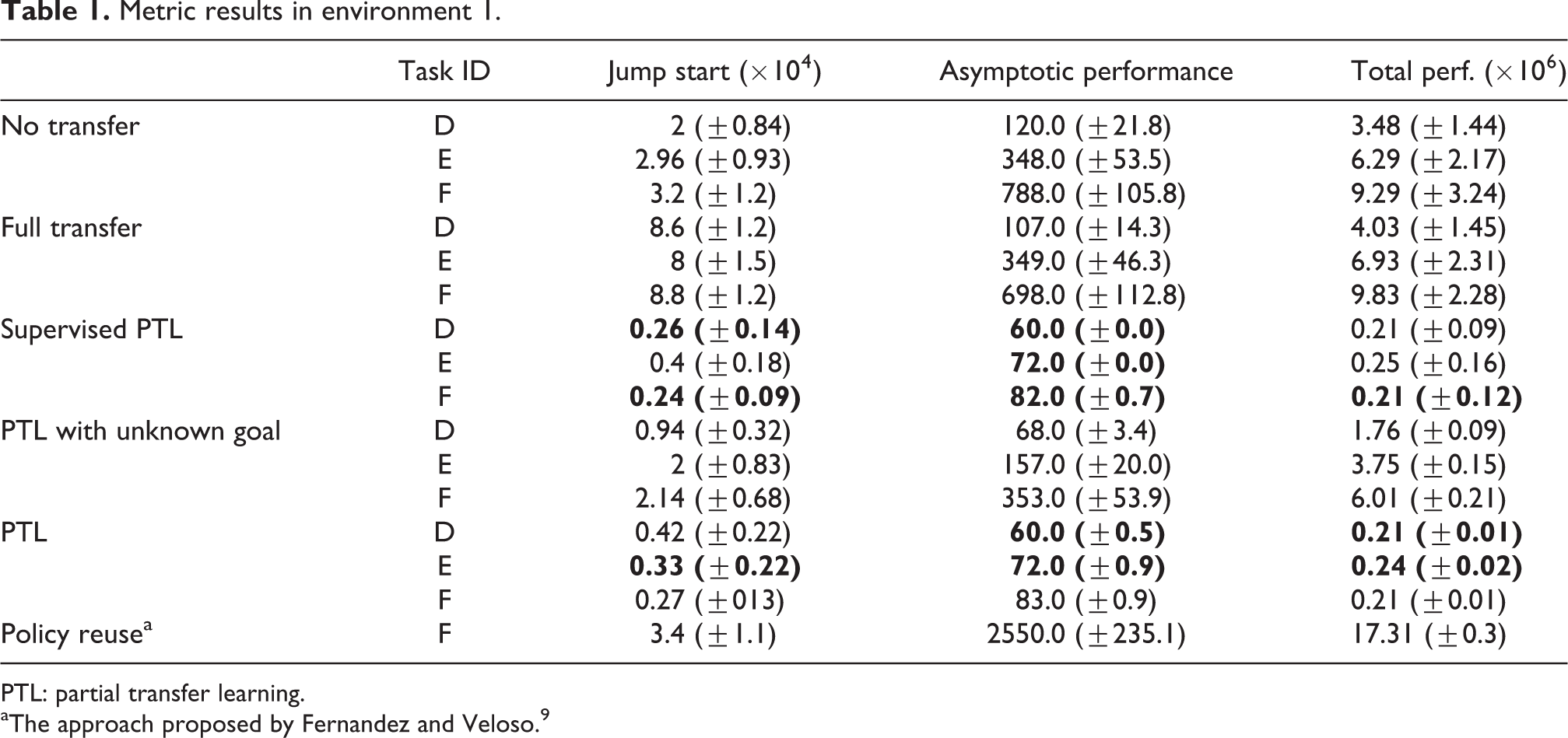
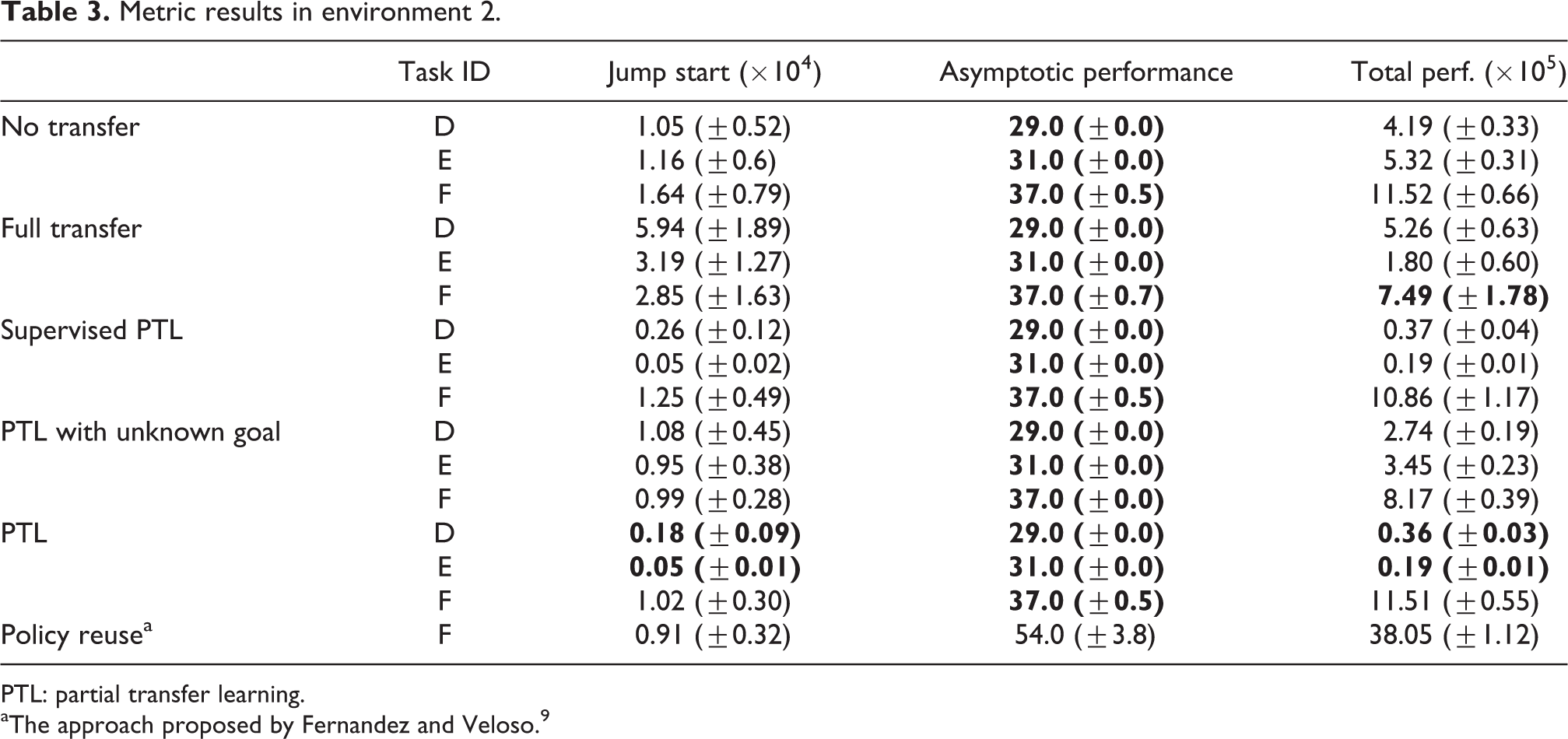
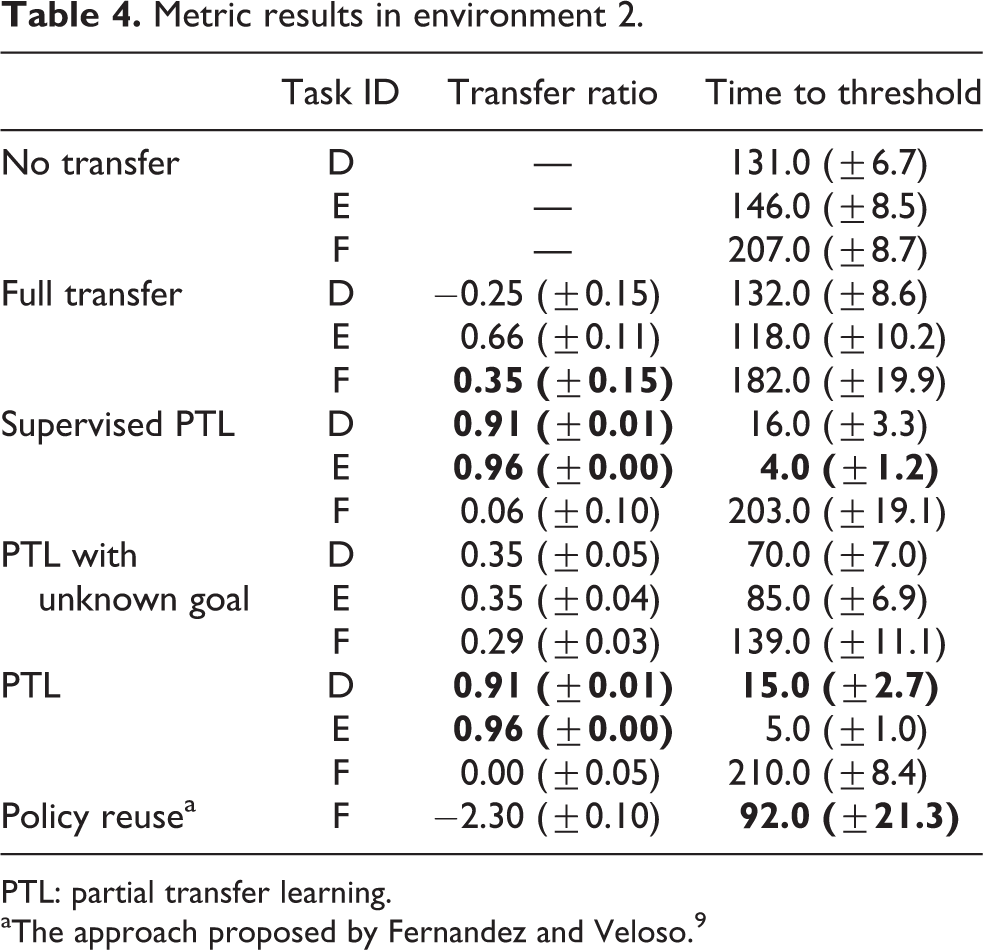
to 6. In the tables, the best performances are given in bold. Environment 1: The performance results in the first environment are given in Tables 1 and 2. Since the complexity of the problem increases regularly, the performance of RL without KT also degrades. The results show that partial TL, in any case, improves the learning process significantly for all metrics. The asymptotic performance metric shows that the proposed approach learns a better policy than the approaches without KT or full transfer even if the goal state is unknown. Not only optimality but also the initial performance of the learning process is important for feasibility to apply to real robots. The improvement on the initial performance is around 80–90%. Thus, the transferred skills reduce the exploration period in the learning process dramatically. Additionally, the agent needs fewer trials to converge to the (near-)optimal policy. For the most complex task (F), the agent can learn the policy in about 80 episodes. Therefore, in the proposed approach, the exploitation period is also reduced significantly. The total performance and transfer ratio metrics show the drastic improvement on the overall learning process. The proposed approach improves the total performance in these cases by more than 90%. Lastly, a degradation on the performance improvement appears when the goal state is unknown. We can interpret the result as the benefit of the proper usage of additional information. But, even if the agent does not know the goal state, the proposed approach still outperforms the other approaches. On the other hand, we can see the effects of the conflicting parts of the problem when the whole learned model is transferred. The negative values of the transfer ratio show us the cases of negative transfer in the problem. Environment 2: The metric results in the second environment (Tables 3 and 4) are similar to that of the first experiment because of the similarity of the environments’ characteristics. The proposed approach makes improvements on all metrics significantly. The only exception for the significant improvement is for the initial performance when the goal state is unknown. Because of lack of information, the standard deviation is high and we cannot interpret the results as a significant improvement. But on the average, the proposed approach requires less number of steps for the first trial in the environment. Additionally, the number of states is much less than that of the first environment. Thus, RL without transfer and with full transfer can converge to the (near-)optimal policy. However, it requires much more episodes than the proposed approach. The results also show that in this case, the full transfer becomes a positive transfer because of fewer conflicts between the source and target tasks. Environment 3: The characteristics of the environment and the order of the tasks in the third environment are different from that of the others. In this environment, the complexity of the tasks is not increasing regularly. Thus, results in the third environment (Tables 5 and 6) are also different. Because of the unordered task complexities, the Jump start metric could not be improved. On the other hand, the required number of episodes to learn (near-)optimal policies is significantly reduced. Thus, the learning speed increases dramatically, even if the initial performance of the agent degrades. Additionally, we obtain more than 50% transfer ratio which means a significant improvement on the overall learning process. Therefore, we can summarize the results in the third environment as the quick recovery property of the proposed approach from misleading skills.
Metric results in environment 1.
PTL: partial transfer learning.
aThe approach proposed by Fernandez and Veloso. 9
Metric results in environment 1.

PTL: partial transfer learning.
aThe approach proposed by Fernandez and Veloso. 9
Metric results in environment 2.
PTL: partial transfer learning.
aThe approach proposed by Fernandez and Veloso. 9
Metric results in environment 2.
PTL: partial transfer learning.
aThe approach proposed by Fernandez and Veloso. 9
Metric results in environment 3.

PTL: partial transfer learning.
aThe approach proposed by Fernandez and Veloso. 9
Metric results in environment 3.
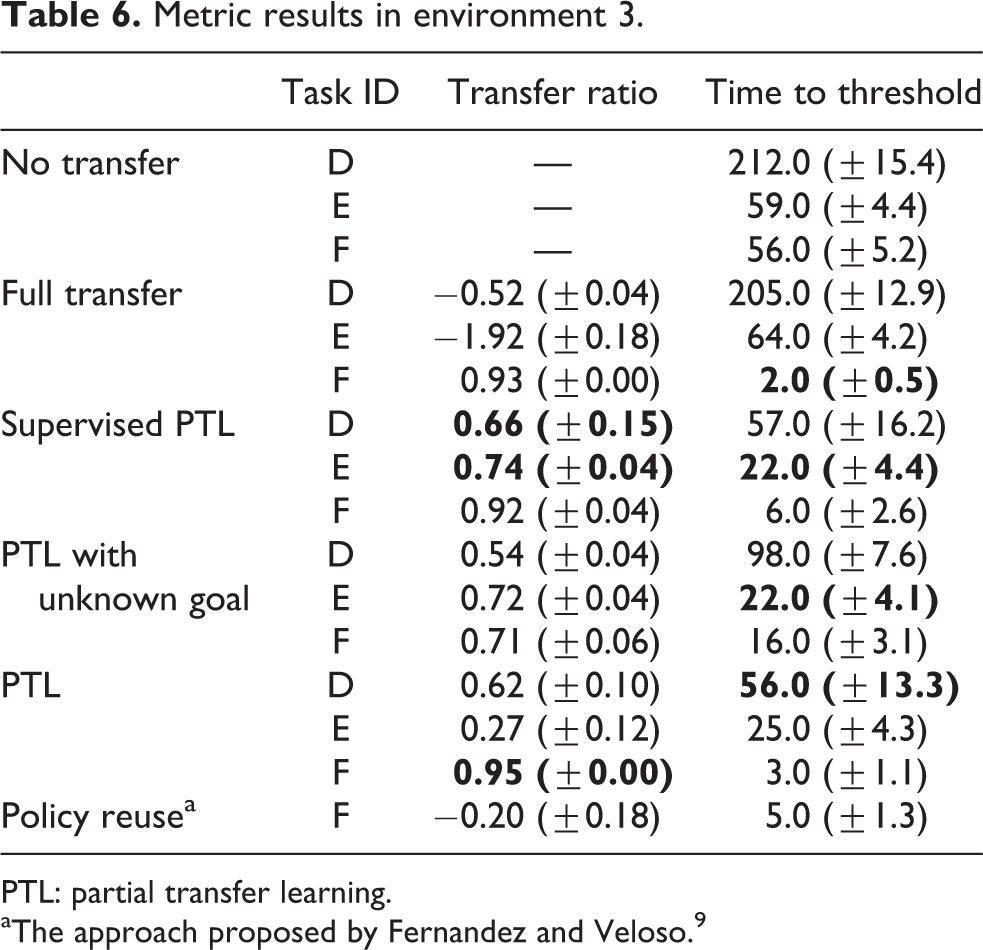
PTL: partial transfer learning.
aThe approach proposed by Fernandez and Veloso. 9
Complexity analysis
In addition to convergence to the (near-)optimal policy, the complexity of the proposed approach is also essential for applicability in the real-world cases. Thus, we make the time and space complexity analysis of the algorithm.
Time complexity
The proposed approach has two extensions in terms of time complexity: skill generation and skill selection. Skill selection is a single loop over existing skills to calculate the corresponding probabilities according to the rules explained in Skill selection. Thus, the complexity of the skill selection operation is
Space complexity
We need to use a data storage for the skill library. Thus, space complexity of skill library can be considered as that of proposed approach. All states are the candidates to be a subgoal that generates a skill in the library. So, upper boundary for the number of skills in the library is the number of the states in the state space. For each skill, a policy is stored for the visited states in the learning process. In the worst case, all states may also be included in each policy. Thus, the space complexity of the proposed approach is
We also constructed an experiment in an unstructured environment (third environment) to analyze the growth rate of the skill library while new random tasks continuously rise. Since it is a random process, the experiment is repeated 30 times. The resulting growth rate of the skill library is shown in Figure 14. The growth rate has a linear relation with the number of tasks for the first seven tasks. After that, requirements for new skills decrease and the growth rate also decreases dramatically. These results show us the growth rate of the skill library is very low in long-term learning processes, like life-long learning.
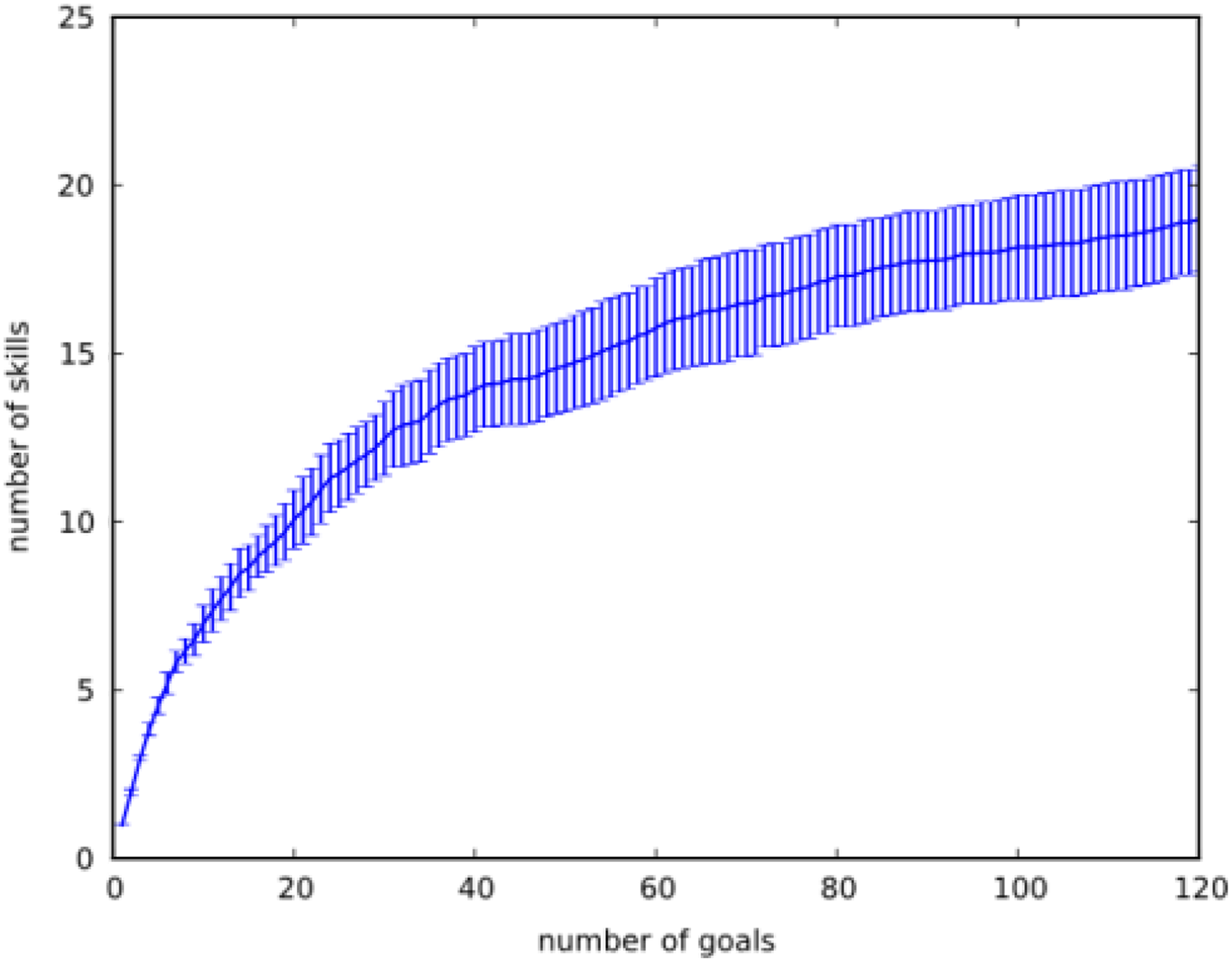
Growth rate of the skill library.
Discussion and conclusion
Learning and adaptation are the key elements for general purpose robots, but learning is a time-consuming and sometimes detrimental process.
In this study, we are mainly interested in the developmental structure of the learning process and propose an incremental learning approach. A new-born agent starts to learn tasks and builds a skill library. As new tasks are encountered, the skill library is expanded with new skills. Such skills provide useful suggestions to improve the learning process of new tasks and acquiring more skills. In this work, we extended a subgoal discovery approach to increase the state space coverage of the skill library.
Experiments are conducted in three grid world environments with different characteristics: incremental structure, rooms with dead ends, and without incremental structure. Results of the experiments show that the usage of the skill library improves the learning process dramatically and has a high potential to make learning feasible for robots. In addition to the performance of the proposed approach, time and space complexity are also analyzed for the feasibility.
The current work only considers intra-domain skill transfer where the state and action domains are the same. As a future work, we are planning to have an extension for inter-domain transfers. In this way, skills in the library will store the knowledge for different domains. Additionally, the proposed approach can be extended for continuous domain problems and tested on a real robot.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors received no financial support for the research and authorship of this article but disclosed receipt of financial support for the publication of this article from Triodor Software R&D.