
Abstract
Human object detection, tracking, and recognition have applications in many areas, such as in the development of assistance robots and intelligent monitoring systems. The emergence of an RGB-D camera, namely the Kinect v2, has simplified the process of human object detection and tracking. Color space methods are dependent on lighting conditions. Because skeleton-tracking algorithms are based on depth images, they are light invariant relative to color space methods. However, skeleton information may sometimes be incorrect or become lost. An algorithm for human-target recognition is thus required. Therefore, this study proposes a human-target tracking and recognition system combining RGB images, depth images, body index, and skeleton information. The system first extracts the color information of five body parts (two upper arms, the torso, and two thighs) using color, depth, and skeleton information. The system then analyzes the color information using a mixed nine-dimensional histogram and single-color analysis method. The algorithm also includes overlap detection during the process of human-target tracking to prevent misidentification caused by occlusion. To test the proposed system, various scenarios were carefully designed to simulate the extremely complex environmental changes characteristic of the real world. Furthermore, the dynamic statistical method of event statistics was used to collect results. Experiments revealed that the proposed method is robust under varying lighting conditions and increases the success rate for individuals wearing similar clothing with monochrome colors.
Introduction
Assistance robots have attracted an increasing amount of attention in recent years. Assistance robots are being developed not only for use in workplaces but also in the daily lives of individuals. Assistance robots for daily life should be easy to operate and human-friendly; thus the software may offer affordances such as enabling users to interact with the robot using gestures 1,2 or their voice 2 ; an assistance robot might be programmed to follow a specific person. 3,4 Such following robots have a variety of applications, including security, monitoring, elder care, and helping humans pick up objects.
Human object detection, tracking, and recognition are critical in robots that are required to follow a particular person (hereafter called following robots). Many of the previous research studies used stationary camera to avoid the difficulty of having to separate the foreground from the background. 5 There was the problem of the camera movements that required further attention. The emergence of the Kinect v2 RGB-D (Microsoft) camera has simplified the process of background removing by providing skeletal tracking information with a player ID. 6 In general, skeletal tracking information is reliable for use by following robots and for the purpose of person reidentification. However, skeleton tracking may be subject to error when the target is occluded by another person on the edge of the detection region of the infrared sensor or in the event of occlusion by more than one person. Herein, an error in skeleton-tracking ID is defined as a change in the tracking ID from one person to another person between successive frames. This type of phenomenon is observed in the occlusion of a tracked individual by an untracked individual and must be considered when using Kinect v2 and its software development kit (SDK) for the human tracking algorithm. In addition to errors in skeleton-tracking ID, the skeleton-tracking ID becomes lost when the tracked person is occluded or out of the tracking range of the Kinect v2. Therefore, an algorithm for person reidentification is required.
Several methods have been proposed for person reidentification, 7 –9 such as the use of pictorial structures for estimating body parts. 10 A full-body MSCR and 11 HSV color histograms of body parts are then extracted to perform reidentification. Experiments have demonstrated that despite the significance of body parts varying among data sets, the torso is always the most critical.
One study used depth information to extract information for the shirt region. 11 The HSV color histogram of the shirt could then be extracted to perform reidentification. Because only nine histogram bins were extracted, the feature was less sensitive to varying lighting conditions and less powerful for similar colors compared with other methods. How et al. 12 also used shirt information for reidentification by adopting the speeded-up robust features algorithm to extract the shirt pattern as the reidentification feature. In their experiments, a dark-colored shirt with a pattern in the middle was identified as the most effective. However, the algorithm was ineffective for bright colors, because folded parts of a shirt were marked as a feature.
Imani and Soltanizadeh 13 proposed a method based on depth and skeleton information in which a human-based object was separated into three parts (head, torso, and legs), and histograms were extracted from each depth-image region. The histograms were produced using descriptors of local binary patterns, local derivative patterns, or local tetra patterns. Additionally, nine anthropometric measurements were extracted using skeleton information provided by Kinect. The feature used for person reidentification was information obtained from anthropometric measurements and the histograms of local pattern descriptors. Because this method was based on depth information, it was more invariant to illumination conditions than were methods based on color information.
In another study, 14 anthropometric measurements were combined with information concerning human color appearance to form an individual’s reidentification feature. During experimentation, the fusion feature achieved favorable performance compared with clothing appearance alone. Zheng et al. 7 offered a fairly comprehensive survey of the development of the person reidentification technique. Although their focus was on reidentification after certain changes, such as from aging, they provided a very nice classification of the available techniques. The results on the following robots were not as frequently encountered. Following the result from the study by Pala et al., 14 Sun et al. 6 proposed a similar method in which the information regarding clothes appearance and body size were combined into a feature for reidentification; their experiments revealed superior performance over other methods. Furthermore, the clothes-appearance method outperformed the body-size method because of substantial position errors of joints in some frames in the body-size method. To overcome the problem of measurement errors, they used 50 samples to construct information on a selected human target. How et al. 12 proposed a Speed-Up Robust Feature (SURF) as fast and robust algorithm for moving human-target identification. They claimed the human following application, but the experiments were based on stationary camera. Cao and Hashimoto 15 proposed a method based on Kinect skeleton information. However, this method was affected by noise during skeleton measurement that could not be mitigated even using 10 skeleton data samples. The result by Abdul Shukor et al. 16 used only Kinect for human recognition. They offered their result on the most appropriate scene for the skeleton-based human detection, but all the test cases took seconds to achieve the detection. In a separate research, Xiao et al. 17 used a single laser scanner to detect human legs. Their research did not include cases when more persons were involved. In fact, laser range finder were proposed in many research studies. 18,19 People had proposed to use ultrawide band technology for human tracking. 20 The method was robust to environment change, but the user had to wear a tag. With successful identification of the location of the human, there were many research studies discussing the tracking strategies for the robot. 21 –23 To make use of more available information from a person, Khedher et al. 24 proposed to use multiple shots to fuse the movement style into the recognition procedure. They were able to achieve very good performance; however, the camera in the setup was fixed. Tsun et al. 25 considered the trajectory planning problem of a person-following robot. They proposed a very nice fusion algorithm but only presented simulation results. A small survey of human tracking was also available, 26 but this was aimed for the use of multiple stationary cameras. An interesting and very recent result is by Wang et al. 27 who proposed the fusion of a monocular camera with an ultrasonic sensor. They did not address the multiple person scenario, but they were able to operate their robot outdoor.
This study introduces a human object recognition and tracking method based on the consumer camera of the Kinect v2. Human object detection and tracking using the Kinect v2 and its SDK with an occlusion detector can reduce the occurrence of errors in skeleton-tracking ID. After the human object has been detected, the color information of five body parts (two upper arms, torso, and two thighs) is extracted for recognition. The extraction of features consists of two phases. First, the depth and skeleton information obtained using the Kinect v2 sensor is employed to segment the five body parts in the color image. Second, color features are obtained using mixed nine-dimensional histograms and the single-color analysis method.
The main contribution of this research is the segmentation of five body parts and the development of an integrated mixed nine-dimensional histogram and single-color analysis method. The remainder of this study is organized as follows. In the second section, the system structure and segmentation of the five body parts are introduced. Third section presents the mixed nine-dimensional histogram and single-color analysis method. The experimental results are provided in the fourth section, and conclusions are presented in the fifth section.
System structure and body-part segmentation method
System structure
Figure 1 is a flowchart of the vision system used in human tracking. Tracking human targets is crucial for the functionality of following robots, which require interfaces to select their human targets. In this study, a human target was selected through the recognition of a series of hand-gesture sequences implemented based on the gesture recognition technique of the Kinect v2. Using hand gestures to select a human target, the system can be established as more user-friendly. When first obtaining information regarding the human target, the system must obtain information for all five body parts.

Vision system flowchart.
The flowchart comprises two decisions. The tracking state of the human target is determined using the player ID information provided by the Kinect v2. When the same human-target player ID is detected in the subsequent image frame, reidentification is not implemented, which minimizes computation time. The second decision is the “overlap-detection method,” which is discussed regarding its use for preventing misidentification caused by occlusion.
Body-part extraction
The body-part extraction method involves the series of steps displayed in Figure 2. First, the color image and body index image, which are provided by the Kinect v2 sensor, are used to remove the background. If the pixel value of the body index image is between 0 and 5, then the pixel belongs to player ID k; if it is greater than 5, then the pixel belongs to the background.

Body-part extraction flowchart.
Second, the no-background color image is combined with skeleton information to extract five specific body parts: the two upper arms, torso, and two thighs. The extraction regions are indicated by yellow rectangles in Figure 3. Table 1 lists the corresponding joints. The lengths of the torso and two thighs are adjusted during the process of body-part extraction; the middle three-fifths are defined as the length because an uncertain area between them may influence the two parts. The lengths of the two upper arms are also adjusted; the lower three-fifths are defined as the lengths because when a person is facing away from the Kinect camera, some areas of the upper arms are located in the region of the torso. The extraction region is constructed from points C, D, E, and F (Figure 4). The vertex locations in the image plane
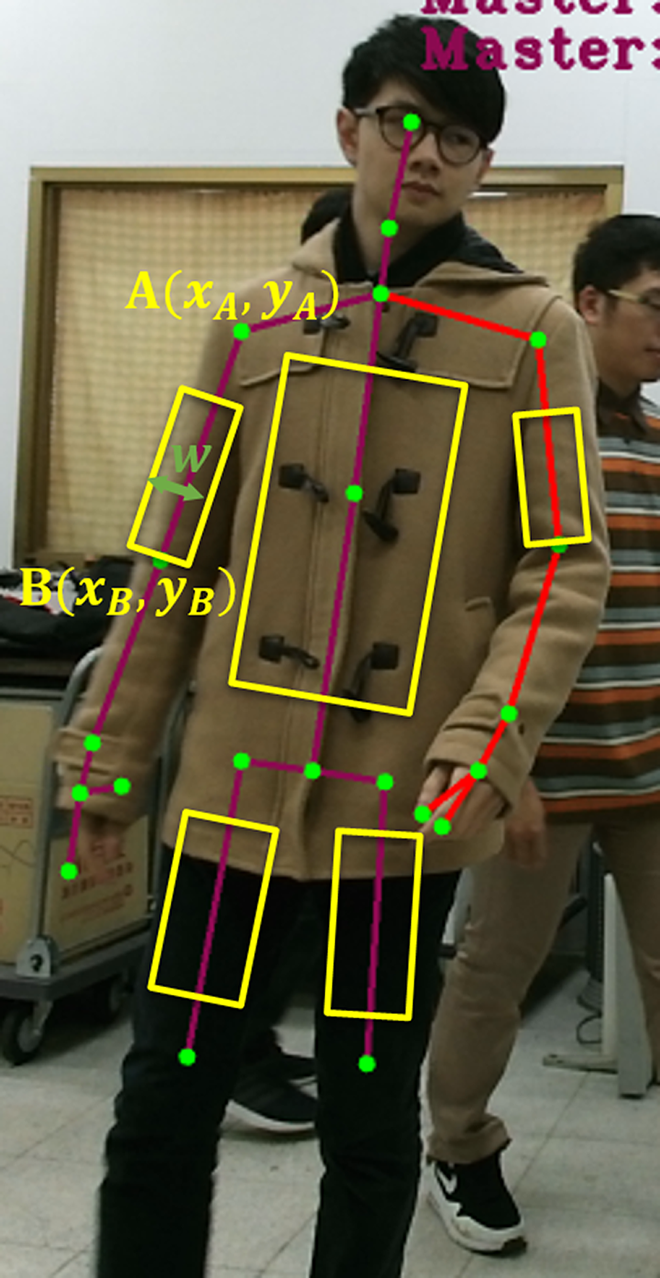
Five body-part extraction regions.

Extraction region.
Reference points of the body-part extraction regions.

Reference points for body-part extraction.
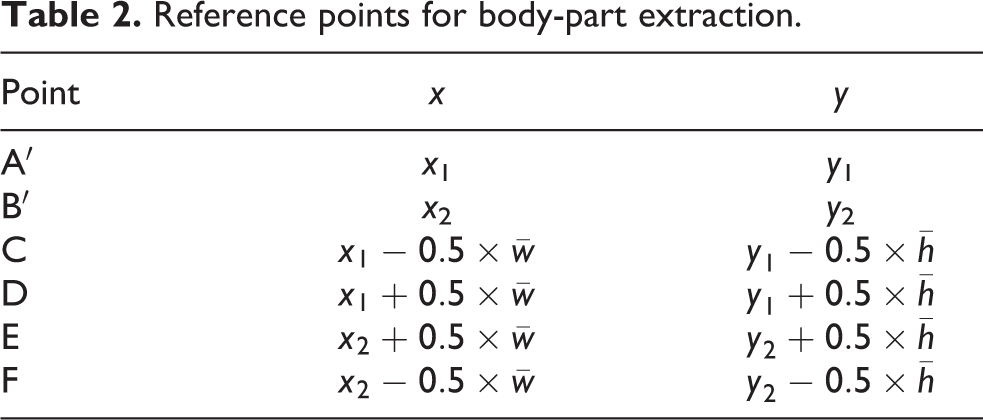
Widths of body-part extraction.

If line




Mixed nine-dimensional histogram and single-color analysis method
The feature vectors of the body parts are produced using color information of the extracted body-part regions, which consist of the torso, mixed upper arms, and mixed thighs. The mixed upper arms and thighs are used to prevent the problem of left and right reversal and the change in thigh lighting conditions during the act of walking. First, this method transforms the extracted body-part regions from an RGB into an HSV color space representation to increase the robustness of the method under varying lighting conditions. Second, based on the concept of Southwell and Fang, 11 nine-dimensional histogram feature vectors are constructed in the HSV color space. Third, if one of the six chromatic colors (red, yellow, green, cyan, blue, and magenta) in the nine-dimensional histogram feature vector accounts for more than 90% of all color during the process of human-target selection (first-time construction of human-target information), then this region is labeled as monochrome. The single-color analysis method is used to produce a dominant color feature vector. In the reidentification process, the condition becomes 85% if this stored human-target region is labeled as monochrome and 95% if this stored human-target region is labeled as a non-monochrome. Fourth, the confidence ruling method 11 or fuzzy sets are used to compare the feature vectors and recognize the human target. The steps are described in detail as follows.
Color space conversion
The RGB information of body parts is converted into HSV color space using equations (7
–9), in which



Feature vector extraction
Feature vector of the nine-dimensional histogram method
The nine-dimensional histogram feature vectors are constructed using the concept proposed by Southwell and Fang.
11
The feature vector 

HSV regions for feature-vector extraction.

Feature vector of the single-color analysis method
Whether body-part region i is monochrome is determined after the nine-dimensional histogram feature vectors have been extracted. The label One of the six chromatic color regions accounts for more than 90% of all color during the process of human-target selection. One of the six chromatic color regions accounts for more than 85% of all color when this stored human-target region is labeled as monochrome during the reidentification process. One of the six chromatic color regions accounts for more than 95% of all color when this stored human-target region is labeled as a nonmonochrome in the reidentification process.
When the body-part region i is labeled as monochrome, the single-color analysis method is used and
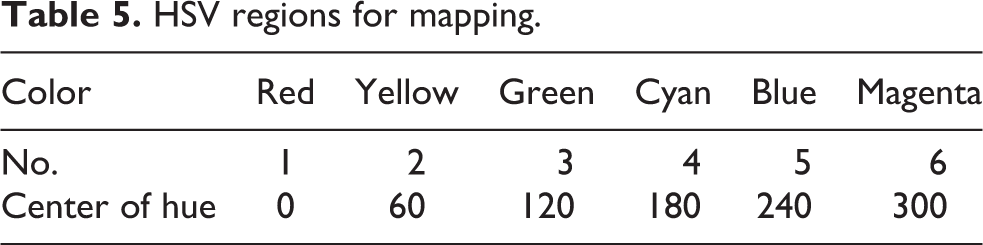
In step 1, the hue and saturation values of body-part region i* are extracted and collected to form a hue vector
HSV regions for mapping.
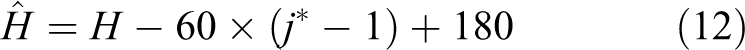



Expectation calculation
Expectation of the nine-dimensional histogram method
The expectation of the nine-dimensional histogram method is calculated using the confidence ruling method,
11
and that of the nine-dimensional histogram feature vector of body-part region i of a player ID k,


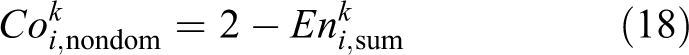


Expectation of the single-color analysis method
The expectation of the single-color analysis method is calculated using the dominant color j* and fuzzy sets, as demonstrated in Figure 5. The symbol “*” is used to indicate that a region has been labeled as a single color and only appears after other symbols. If the dominant color of the human target

Fuzzy sets.
Subtotal and total expectation
The total expectation is calculated using equations (21) to (23). Subtotal expectation 1,


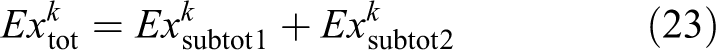
Human-target reidentification
After total and subtotal expectations have been calculated using equations (21) to (23), human-target recognition is performed using two thresholds in some steps, as illustrated in Figure 6, in which

Flowchart of human-target reidentification.
Overlap-detection method
The Kinect skeleton-tracking player ID may alternate from one person to another between frames. This occurs in the event of occlusion between two people on the edge of the detection region of an infrared sensor or during occlusion by more than one person. In particular, it occurs when one person is tracked and another person is untracked. This phenomenon can be problematic when player ID is used as a tracker for tracking a human target. To overcome this problem, a method for overlap detection was developed in which a specific joint on the skeleton of the human target is tracked and its displacement,
In this study, spine_shoulder was selected as the tracking joint because the probability of a “not tracked” state in the event of overlap is lower for this joint than other joints. The threshold

The estimated speed of the human target is used to determine whether the human target is moving at a high or low speed. The speed of the human target is estimated by dividing the spine_shoulder displacement
Experimental results
A ThinkPad T540p laptop computer with a core i7-4710MQ 2.5-GHz CPU and 8 GB RAM was used to evaluate the performance of the vision system. Videos were recorded using the Kinect v2 sensor with Kinect Studio. The system was developed using VS2012 in Windows 8, and OpenCV 3.0 was used to display the resultant images.
Database
To test the proposed method, we recorded approximately 200 videos using Kinect Studio v2.0 provided by Kinect SDK v2.0. The duration of each prerecorded video was approximately 15 s. The videos contained 8 scenes and 26 users. Some scenes had another illumination condition, and most of the users had occlusions in at least one video. Furthermore, some of the users in the prerecorded videos were jogging, holding things, and jumping. The videos were recorded on different days; therefore, the illumination conditions may have differed for the same scene. Data regarding the prerecorded videos and corresponding user numbers are presented in Tables 6 and 7. The first column of Table 7 indicates the teaching environment of the human target.
Prerecorded video data.
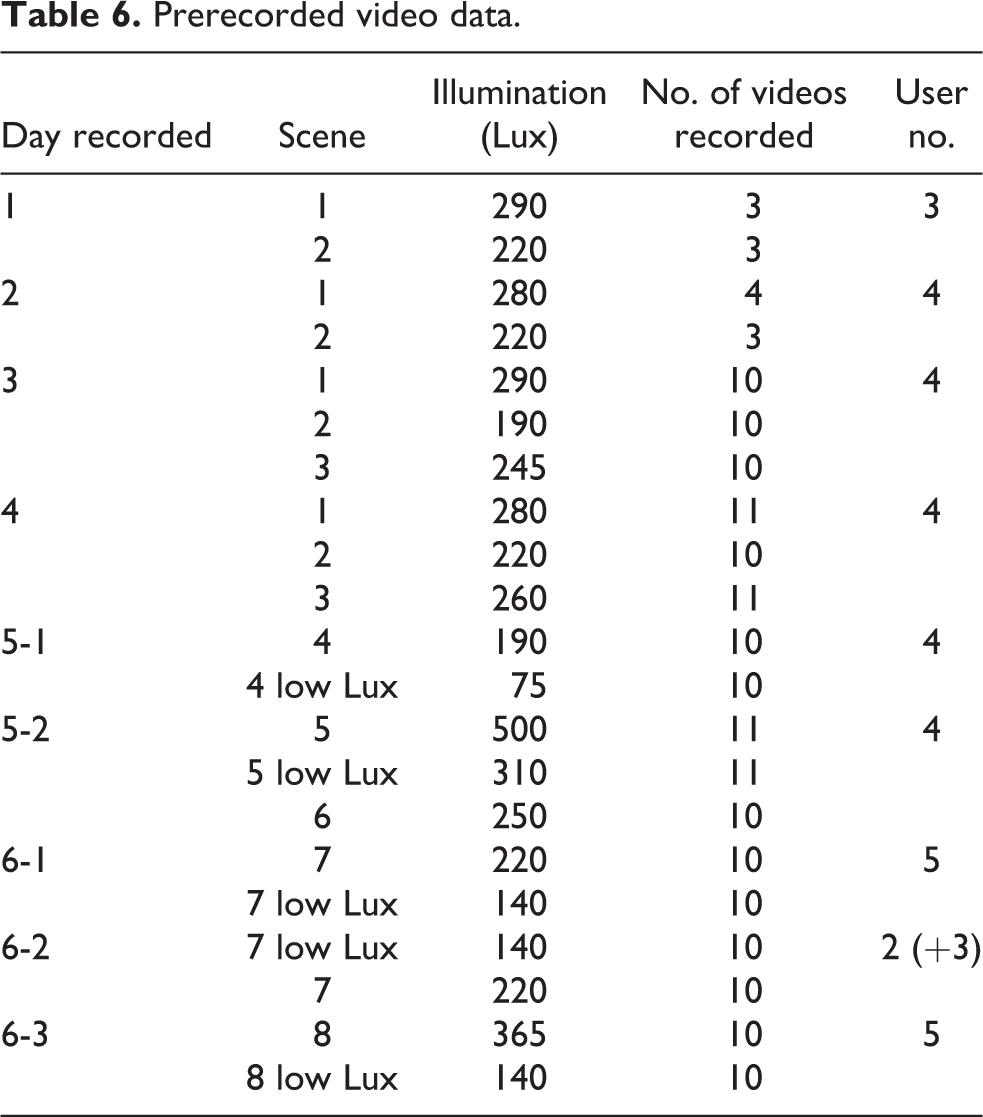
Scenes, illumination conditions, and users in the prerecorded videos.

Event statistics method
A confusion matrix was used to evaluate the performance of the proposed method. Four possible outcomes were defined as follows. True positive (TP): skeleton of human target exists and TRUE human target is reidentified. True negative (TN): skeleton of human target does NOT exist and human target is NOT reidentified. False positive (FP): FALSE human target is reidentified. False negative (FN): skeleton of human target exists and human target is NOT reidentified.
The recorded videos were used to evaluate tracking methods, and a method was required for presenting the observation results numerically. An event statistics method was proposed for this purpose, the primary aim of which is for the event to distinguish the section that can be tracked without problems. An event is defined as the moment at which tracking problems occur. Additionally, only one outcome (TP, TN, FP, and FN) exists between two events.
In this study, an event is defined at the beginning and end of a video for a skeleton lost because of occlusion or being located outside of the skeleton-tracking range of the Kinect as well as for misidentification caused by occlusion. When a skeleton is tracked as the human target, events are based on this skeleton, regardless of the tracking accuracy. When no skeleton is tracked as the human target, events are based on the skeleton of the true human target. Only one outcome is possible for each of the two events, and these outcomes have different implications. In this study, an FP was more significant than an FN. Moreover, because of the design of the statistical method, a TN was only used for the final event interval.
In this study, the event statistics method was used to present the observation results. Accuracy rates and receiver operating characteristic (ROC) graphs 28 are used for discussing the experimental results.
Thresholds and parameter selection
For the samples collected on a given day, 2–4 videos and 1–2 users were randomly selected to determine the thresholds and parameters. In addition to the randomly selected videos, those used for human-target selection were also considered. Each video and user was tested between recording days. A few specific videos that included jogging and jumping were used for parameter selection in the overlap-detection method. The remaining prerecorded videos were used for performance testing. The thresholds and parameter selection procedures were as follows. First, the proposed method was tested without using the overlap-detection method. The testing included two cases:
The values of the parameters in the overlap-detection method, selected through trial and error, were as follows:
The experimental results obtained from 60 prerecorded videos with 81 occlusions, 15 movements out of range, and 13 misidentifications caused by occlusion are displayed in Figures 7 and 8. The label “our” indicates that the proposed method was used, and “our + odm” indicates that the proposed method was used in combination with the overlap-detection method. First, considering only the results without the overlap-detection method, when
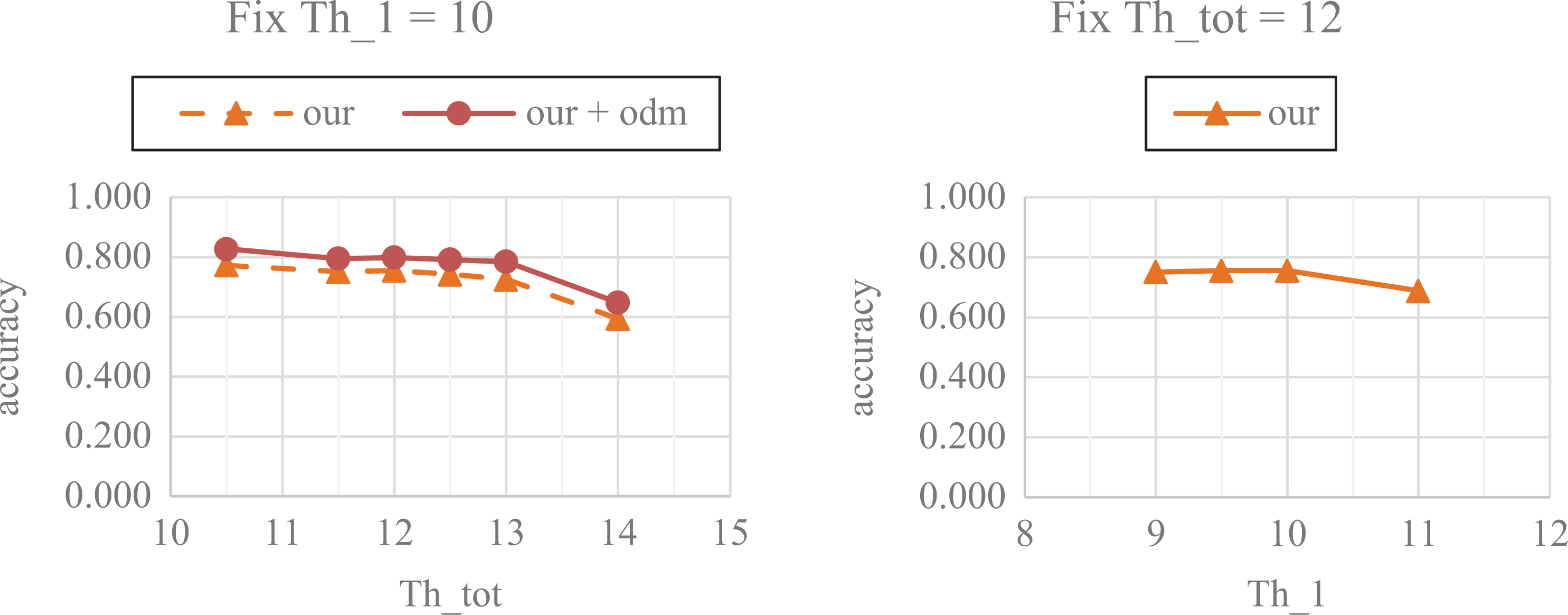
Accuracy results for threshold selection: (left) fixed

ROC graph for threshold selection with fixed
The concepts that aided the selection of Small Large
Robustness under varying lighting conditions is desired.
Therefore, we selected
Evaluation of the single-color analysis method
As explained in the introduction, the target system is an assistive robot that operates in a dynamic environment. The robot would rock when it was following its master around. As a result, most of the methods we tested fail to provide continuous recognition to fulfill the tracking requirement. After many failed attempts, we came to realize that the algorithm not only has to be accurate but also be very fast. We were thus faced with the constraints from both ends. On the one end, the algorithm needs to be able to distinguish its master under change environment; on the other end, it also has to complete the computation within a very limited amount of time before the vision system lost frame. While most previous researches used stationary cameras, we were left with very few options of applicable algorithms. Here, we compared our approach with the shirt recognition method proposed in Southwell and Fang,
11
which is simple enough to achieve fast computing. We set the weighting factors as
Results of the evaluation of the single-color analysis method.
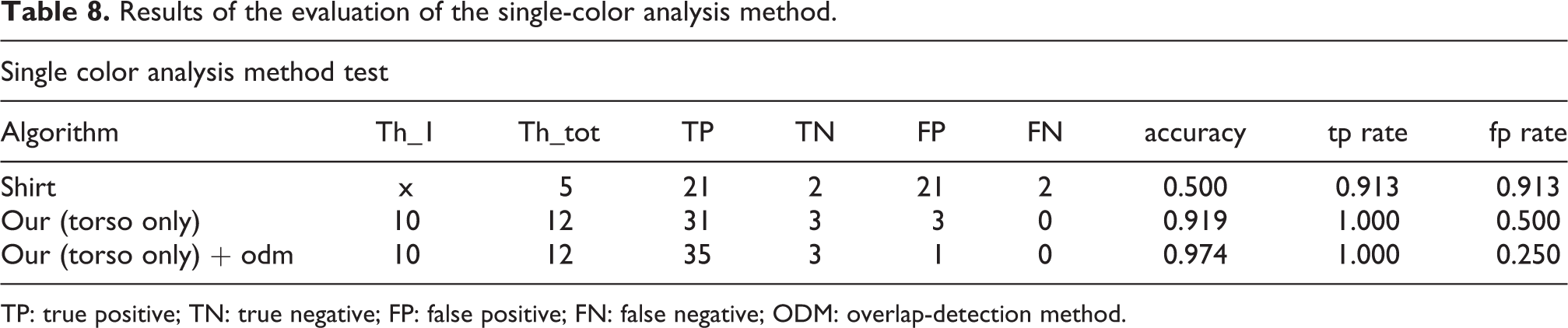
TP: true positive; TN: true negative; FP: false positive; FN: false negative; ODM: overlap-detection method.
In this experiment, we discovered that the single-color analysis method improved performance for monochrome objects. Although the overlap-detection method can overcome the problem of misidentification caused by occlusion, it still has some limitations.
Human-target recognition
To test the performance of the selected thresholds and parameters, each user was randomly selected from two videos for each corresponding scene and each day from the remaining prerecorded videos. The results obtained using our proposed method, our method combined with the overlap-detection method, and the shirt recognition method 11 were compared. The experimental results, which were obtained using 164 prerecorded videos with 278 occlusions, 56 movements out of range, and 27 misidentifications caused by occlusion, are presented in Table 9 and Figure 9. Our proposed method with the overlap-detection method demonstrated the highest accuracy, and the shirt recognition method had the lowest accuracy. The accuracy of the proposed method was 13.9% and 11.1% higher, and FP rates were 25.1% and 22.4% lower than those of the shirt recognition method, as indicated by the performance test and parameter selection test, respectively. Nevertheless, the TP rates were 2% and 2.5% lower compared with the shirt recognition method. This was because in some scenes, users wore the same or similar shirts, which are difficult to distinguish with the shirt recognition method, as was the case for user 1 and user 2 on day 1; user 7 and user 10 on day 3; and all users on day 6-1 and day 6-3. Our method outperforms the shirt recognition method, because it uses information of five body parts and improves the resolution of the nine-dimensional histogram with respect to chromatic color. However, our proposed method has some limitations with respect to achromatic color. For example, user 18 was often recognized as user 20 on day 6-1. In our experiments, the lighting conditions of the thighs of the user changed while the user was walking, and some chromatic colors were converted into achromatic colors when illumination was low. The pants of user 18 had this type of color. This phenomenon was also observed for user 4 and user 6 on day 2. Although the information of five body parts was used in our method, distinguishing between user 23 and 24 on day 6-2 was still difficult.
Results of performance test and parameter selection.

Note: our proposed method with overlap-detection method has highest accuracy rate in performance test, mark in boldface. TP: true positive; TN: true negative; FP: false positive; FN: false negative.

ROC graph: change from parameter selection to performance test. ROC: receiver operating characteristic.
Incorporating the overlap-detection method increased the accuracy of our method by approximately 3.5% and 4.3% in the performance test and parameter selection test, respectively; moreover, the FP rates decreased by 14.8% and 13.4%, and the TP rates decreased by approximately 1% and 0.3%, respectively. The decrease in TP rate was because of the difficulty in person reidentification when occlusion occurred. Moreover, skeletons sometimes embodied an incorrect position and then the correct person was reidentified. Our method is based on the Kinect skeleton-tracking method; therefore, the problem of misidentification because of occlusion affected the system performance. The testing results indicate that incorporating the overlap-detection method increases the performance of the proposed method.
Table 9 and Figure 9 reveal that all accuracies, TP rates, and FP rates obtained were lower in the performance test than the parameter selection test. This is because person reidentification was more difficult in the performance test than in the parameter selection test. For example, in the scenes used in the performance test, the profile of the human target was presented between two events, and the target enacted the motions of pitching and sitting on a chair.
The experimental results revealed a lower accuracy than that reported in other studies because of misidentification caused by occlusion that occurred during dynamic testing; moreover, the scenarios designed in this study are more complex than those used in other studies.
Computation time
To test the computation time of the vision system, images were extracted from the Kinect v2 and processed using the proposed method and shirt recognition method. 11 The computation time was recorded under five conditions: zero, one, two, three, and four people in the field of view (Figure 10). The additional computation time required to add one person to the field of view was then calculated. Additionally, all of the people in Figure 10 were selected as the human target for this test. Finally, the amounts of time required for additional computation were averaged to obtain an average computation time per skeleton.

Test of computation time.
The experimental results indicate that the average computation time per skeleton for the shirt recognition method 11 and proposed method with and without the overlap-detection method were 7.5 ms, 25.9 ms, and 24.5 ms, respectively. The average computation time per skeleton was higher for the proposed method than the shirt recognition method, 11 because more extracted pixels were employed in the method of segmenting five body parts; moreover, identifying monochrome colors required more computation time in the proposed method than in the shirt recognition method. 11 The average computation time per skeleton increased by only 1.4 ms when the overlap-detection method was included.
Conclusions
This study introduced a human object recognition and tracking method based on an RGB-D sensor (Kinect v2). This method uses the depth, skeleton, and color information of five body parts for human object recognition. First, a segmentation method is employed to identify five body parts based on depth and skeleton information. Second, the color information of the five body parts is extracted using the nine-dimensional histogram method or single-color analysis method. Third, although the overlap-detection method can be used to prevent misidentification caused by occlusion during the tracking process, the proposed method increases the success rate for distinguishing similar clothing with monochrome colors; moreover, robustness is maintained under varying lighting conditions. However, the single-color analysis method is not applicable for achromatic colors, and chromatic colors can be converted into achromatic colors under low-illumination conditions. Using information of five body parts for reidentification can distinguish more users compared with using shirt information alone. Therefore, the proposed method can be used to overcome the problem of misidentification because of occlusion because it may cause a FP between two events during the process of tracking. As accuracy increased, the FP rate decreased and the performance of the system improved. The aforementioned results indicate that the proposed method is suitable for recognizing and tracking a person wearing chromatic clothing. Further research is required for recognizing individuals wearing achromatic clothing.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported in part by Hon Hai Precision Industry Company Ltd (under contract no. 104-S-A26) and in part by the Ministry of Science and Technologies, Taiwan (under grant 104-2221-E-002-197-MY3).
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.