
Abstract
In this article, we study the ground moving target tracking problem for a fixed-wing unmanned aerial vehicle equipped with a radar. This problem is formulated in a partially observable Markov process framework, which contains the following two parts: in the first part, the unmanned aerial vehicle utilizes the measurements from its radar and employs a Kalman filter to estimate the target’s real-time location; in the second part, the unmanned aerial vehicle optimizes its trajectory in a real-time manner so that the radar’s measurements can include more useful information. To solve the trajectory optimization problem, we proposed an information geometry-based partially observable Markov decision process method. Specifically, the cumulative amount of information in the observation is represented by Fisher information of information geometry, and acts as the criterion of the partially observable Markov decision process problem. Furthermore, to guarantee the real-time performance, an important trade-off between the optimality and computation cost is made by an approximate receding horizon approach. Finally, simulation results corroborate the accuracy and time-efficiency of our proposed method and also show our advantage in computation time compared to existing methods.
Keywords
Introduction
Guiding unmanned aerial vehicle (UAV) to detect and track a suspicious ground target is an important requirement in many intelligence, surveillance, target acquisition, and reconnaissance (ISTAR) 1 problems. Different from predefined trajectory tracking problems, tracking a moving target is more challenging, since it requires the UAV to respond promptly to the random movement of the target. Our article focuses on the problem of a UAV tracking a moving ground target in an uncertain environment. In many practical scenarios, the accurate observation and tracking of a target is achieved through adequate maneuver of the UAV equipped with a sensor. Therefore, the UAV needs to make a movement strategy based on the state of the target. However, the information of the target location obtained by the UAV sensor is usually incomplete or imperfect. In this regard, the task of target tracking mainly consists of two aspects 2 : one is the estimation of the state of the target based on the measurements obtained by the sensor, and the other is the adjustment of the position/pose of the UAV based on the prediction of the target state to obtain better measurements.
For target state estimation, different strategies have been developed in the past decade. In order to estimate and predict the target state more accurately, the classical methods such as Kalman filter (KF), 3 –7 particle filter, 8 –11 and their modifications were widely used. For instance, an unscented KF was utilized to track an underwater submarine target/moving ship. 6,12 Tang and Ozguner proposed the particle-filter-and-hospitability-map algorithm (PF-HMap) 8 to deal with the general target tracking maintenance problem with regional and intermittent measurements. In these abovementioned methods, the classical KF is one of the most widely used methods for estimation and tracking, due to its optimality, simplicity, and tractability.
For position/pose adjustment, one possible method is to track the estimated location of the target. A novel algorithm combining the tangent vector field guidance (TVFG) path-planning approach and the Lyapunov vector field guidance (LVFG) algorithm 13 was developed. Given the target position and current UAV dynamic state, this method is theoretically possible to obtain the shortest path with UAV operational constraints. In addition, based on the division of two kinds of possible path parttens, that is, the z type (sinusoidal type) and the whirling type, the ground target pursuit algorithm 14,15 generates waypoints step by step and steers the UAV to the latest waypoint. Most of these planning methods are based on precomputed vector fields or alternative paths, which do not respond well to system uncertainties.
The other method for position/pose adjustment is based on the decision-making framework, which can better handle the system uncertainties. In this framework, the transition model of the tracking system is usually assumed to be Markovian. Then, the tracking policy selection problem can be formulated as a partially observed Markov decision process (POMDP), in which the state is only partially observed and one seeks to design a control policy which maps the state probability distributions to actions and maximizes the accuracy of target location. With its decision-making ability in an uncertain environment, 16,17 the POMDP framework has been widely used in a variety of real-world scenarios. Prentice and Roy 18 addressed the problem of trajectory planning with imperfect state information, and model it as a linear-Guassian POMDP. Assuming that the UAV’s state and kinematics are known, Ragi and Chong 3,4 employed the POMDP, combining with the motion constraints of the UAV, to design the guidance algorithm of UAV tracking a ground target. However, solving POMDP optimally is proven to be PSPACE-hard. 19 A large number of literature focuses on various heuristic or approximate solution techniques. 20 Some literature use the receding horizon theory to approximate a POMDP. Sunberg et al. 21 proposed a receding horizon control approach to solve the information space dynamic programming of POMDPs. In the POMDP framework, the tracking decision problem was transformed into an optimization problem, and the choice of the optimization criterion plays a crucial role, 22 which directly determines the speed and performance of the solution. Different from the approach 3,4 that used the trace of covariance matrix, we use the cumulative quantity of information from information geometry (IG) as the reward criterion of POMDP to evaluate the performance of the tracking strategy in essence and simplify the calculation.
IG is proposed by Rao, 23 and axiomatized by Chentsov. 24 It constructs a distance representation between statistical distributions. It deals with families of parameterized probability densities which carry a metric structure. This structure is derived via the well-known Fisher information metric. Recently, significant attention has been drawn in the area of IG. Costa et al. 25 presented the Fisher information distance as a measure of difference between two probability distribution functions. The Fisher information distance is related to the information of the target estimation. Therefore, the target tracking problem is transformed into searching for the strategy that maximizes the accuracy of the target estimation. There have been many works on how IG methodology can be applied to the tracking process as it does in the signal processing. 26 –29 In their study, Akselrod et al. 27 proposed a MDP model to formulate the collaborative sensor management for multi-target tracking decision processes, where the objective function is based on the Fisher information measure. However, in that study, the Fisher information is merely approximated by the posterior covariance matrix from the KF, which is not an exact derivation. Actually, it did not analyze the source and significance of the Fisher information in essence. In target tracking, the noise covariance depends on the performance of the sensor. That means the covariance matrix of noise matches to the Riemannian manifold of positive definite matrix. Wang et al. 29 derived a complete form of relationship between the accuracy of the target location and the optimal sensor position, based on the maximum determinant of the Fisher information matrix (FIM) criterion, where the theory of IG to study the problem of bearing-only tracking was employed.
The above summarizes the research results about the construction of the tracking decision-making framework, the selection of the evaluation function, and the solution of the optimal decision. However, even though IG is a power tool in analyzing the statistics of the moving target, few studies provide rigorous analysis and design of the IG-based UAV ground target tracking problem. Previous work by Zhao et al.
30
has shown the effectiveness of the IG method in the target tracking decision in two-dimensional (2-D) space by simulation results. In this article, we extend the problem of target tracking with an airborne radar to general three dimensions with new simulation results and more detailed analysis. The iterative form of FIM about the 3-D bearing-and-range radar, which takes into account the uncertainties of predicted target states, is derived. Then, the Fisher information distance on the Riemann manifold is regarded as the basis for POMDP, and the convergence of the POMDP approximate solution algorithm is proved theoretically. The detailed contributions of the proposed algorithm are as follows: A novel IG-based POMDP frame is provided for the UAV to track a moving ground target in a 3-D uncertain environment. In this frame, the state of the target is observed by the 3-D bearing-and-range radar. The optimization criterion based on the 3-D observation model in the POMDP is derived based on Fisher information in the view of the IG, which is the key to optimize the action polices in the UAV-to-target problem. An approximate receding horizon control is developed to obtain an acceptable control strategy in the trade-off between the optimization and the computation cost. We also prove the convergence of approximation algorithm theoretically.
The rest of this article is organized as follows. In the “Problem formulation” section, the system model is given and the target tracking problem is formulated. The framework of the POMDP and its criterion of accumulative information are presented in “Target tracking decision-making based on IG” section, where the FIM is derived by iterative calculation via the predicted target state. In “Approximate receding horizon approach for POMDP” section, we introduce our proposed approximate receding horizon approach for the POMDP, and analyze the performance of the algorithm. “Simulation results” section presents the simulation and results, which is followed by the conclusion.
Problem formulation
In this article, the target tracking system is composed of a UAV and a target vehicle. The mission of the UAV is to observe and track the moving target on the ground. The UAV is equipped with a radar that can obtain the bearing and range measurements of the tracked object with limited precision and reliability.
Fixed-wing UAV model
The fixed-wing UAV dynamics augmented by the autopilot is a high dimensional, highly nonlinear, and extremely complex system. In our work, the UAV is supposed to fly at a constant altitude h, and the unicycle model is adopted to describe kinematics of fixed-wing UAV.
The UAV autopilot controls bank angle ϕ and forward acceleration a directly. The UAV state, which is a part of the world states, is

where
Target model
In this system, the target is on the ground and its exact state is not available. The state is given by
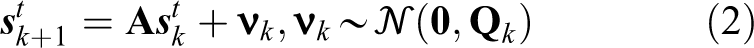
where

and
The states of the target are measured by the active radar mounted on the UAV. The radar can measure the range and bearing information determined by relative state
Observation model
In this work, the UAV only installs one radar as the measuring sensor. The airborne radar for target tracking provides measurement of the target in the sensor CS, which is a polar CS with range r and bearing φ. The measurement model with noise at time k is

where

For the radar, the error-free target position in the sensor polar CS is represented as

As for an active sensor, the measurement error is dependent on the signal-to-noise ratio which is proportional to the fourth power of distance. Then the covariance matrix of the measurement is

where σr and σφ are the standard deviations of the range and bearing measurements, respectively. In equation (6),
This study considers a UAV decision-making problem, in which the goal is to design an algorithm to control a UAV for target tracking. Specifically, the UAV motion model is simplified as equation (1). It is mounted with a sensor that measures the relative position of the target. The observation model (equation (4)), combined with the assumed target model (equation (2)), is used to estimate and predict the states of the target. Based on these states the UAV makes action decision. The values of actions are limited to the maximum and minimum range. The objective is to obtain better observation for a more accurate estimation of the target state.
Tracking in Cartesian coordinate
In the target tracking problem, the target’s movement is described in Cartesian coordinate, while the measurement is available physically in the sensor polar CS. Thus, it is necessary to convert the measurements from the polar CS to the Cartesian coordinate. Specifically, in the Cartesian CS (selecting the UAV as the origin), the measurement model is converted to the following form

where the measurement matrix is
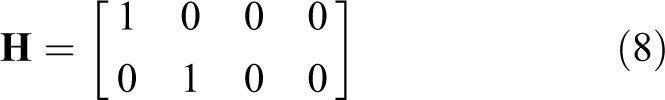
In equation (7),
Defining

where (x, y) and (r, φ) are the coordinates in the polar CS and the Cartesian CS, respectively. Then, the relative position from the target to the UAV in Cartesian coordinate, defined as

By Taylor series expansion of
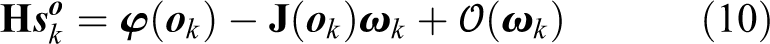
where

Considering

The standard approach usually ignores

Target tracking decision-making based on IG
The decision-making problem of UAV under uncertain environment is modeled as a POMDP. In the POMDP framework, the decision-making program obtains measurements from the airborne radar and makes the action decisions for the UAV. For more measurement information of the target, we should predict the states of the target and make appropriate action decisions based on a certain criterion. In this article, we represent the reward criterion by the accumulative information, which is derived from the FIM in the IG. This section introduces the POMDP-based target tracking algorithm, especially the calculation of the decision-making criterion. In the second part of this section, we describe the traditional criterion and analyze its shortcomings. Then we propose the decision-making criterion based on the IG in the last part of this section. The key point is that we use the iterative calculation form of the FIM for the range-and-bearing radar to redefine the decision-making criterion in essence.
The framework of POMDP-based decision-making
POMDP is a stochastic process controlled by a decision-maker. In the target tracking problem, since the system state transition is a random process with the Markov property, and the states of the target cannot be obtained directly, we use the POMDP to select a sequence of actions for the UAV to reduce the uncertainty of target localization. In general, an infinite horizon POMDP is defined by a tuple
States. The state set
Actions. In this system, the action of the UAV is the control quantity
State transition probabilities.
Observations and observation probabilities.
Belief state. Belief state is the distribution of the real state. Specially, the state distribution at time k = 0 is b0. Since the UAV states are fully observable, the belief state is
Reward function. The real-valued reward function R defines the reward of the action. It is used to compare different alternative action policies. In the target tracking problem, the core of evaluation is the accuracy of the target location. Some literatures describe it as the trace of covariance. In our work, for the purpose of better reflecting the essential characteristics of radar measurement, we propose the IG method to represent the reward function.
Remark 1
Partially observable Markov process. At each time period, the system is in some state
The goal of the POMDP for the agent is to choose actions at each time step that maximize its long-run average expected reward

where H is the time horizon. In our target tracking system, the aim of decision-making is to find the optimal control policies for the UAV. This strategy is to make the UAV better able to observe and track the target, so as to maximize the accuracy of the target position estimation.
A policy is a sequence

This reward
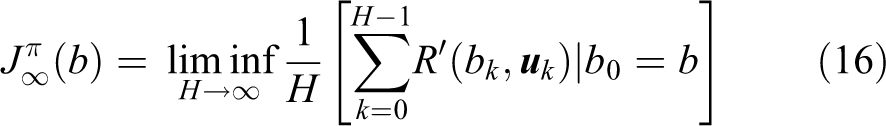
according to the nominal belief state optimization. 4 The objective function is approximated as follows

where
Covariance-based conventional criterion function
In some literatures,
3,4
the belief of the target mentioned above can be identified with the state of the tracker

The reward function is defined to represent the uncertainty of the target location, which is usually represented by the mean-squared error between the tracker and the target. Then, the objective function is as follows

The Kalman filtering equation is a linearized conversion of the actual system model. The measurement model in the sensor CS is equation (4), and the observation model in the Cartesian CS is in the form of equation (7). In contrast with the long-run reward from the trace of the Kalman filtering error covariance matrix (equation (19)), the FIM in the IG processes the original measurement data of the radar. It is derived from the measurement model in the natural sensor CS directly and has a clearly physical meaning, which reflects the volume of information from the measurement data. The greater the cumulative information is, the more accurate the measurement would be. Hence the Fisher information from the IG can better evaluate the accuracy of the predicted states. We use the Fisher information distance (which will be explained later) on the statistical manifold as the basis of the POMDP.
Cumulative information in IG
IG 23 offers a comprehensive result about statistical models by regarding them as geometrical objects. From the perspective of IG, the set of belief states forms the statistical manifold of a particular geometric structure. The information is defined on the Fisher information divergence between the current belief state and the belief state after a measurement has been made. The cumulative information which the sensor may acquire from the target is characterized by the Fisher information distance. In a discrete measurement sampling scenario, the sum of the determinant of FIM is used to approximate the information distance. 32
In this article, the determinant of the FIM is used to characterize the volume of information obtained by measurements. The performance index is the expected long-run average reward, therefore, it is a feasible way to predict the information each time through iterations. The following introduces the iteration process of the discrete FIM of the radar measurements.
We define
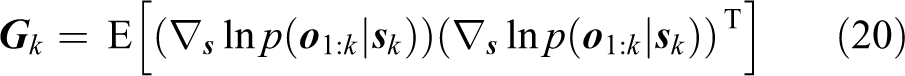
where
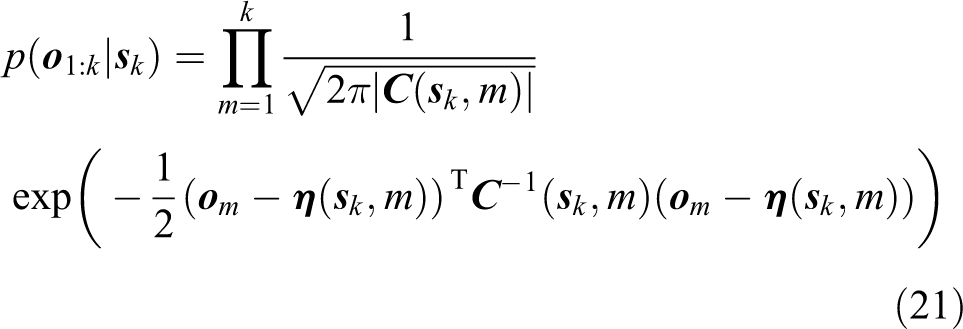
where

Besides,

and

In the above equations, considering the linear motion target model described previously, we have

Then the FIM at time k can be calculated in a recursive form as follows
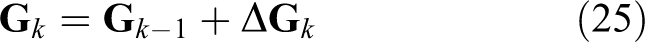
where

In equation (26),
Since the sensor collects measurements only at discrete points, the accumulative information should only consider those points when the sensor takes measurements. It is assumed that the decision-making points are consistent with the measurement points. Therefore, the sum of determinant of the FIM
29
is used to approximate the accumulative information
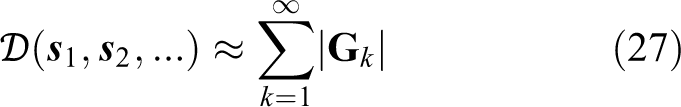
The reward function based on the IG is

The larger the volume of information is, the more accurate the estimation of the target state will be and the better the tracking performance the algorithm will have. Our decision-making algorithm aims to find the optimal sequence of actions which maximizes the predicted cumulative information. From equation (20), we obtain that the FIM is determined by the relative position between the UAV and the target. However, the states of the target are unobservable. Thus, when we make decision, we use the predicted belief states to present the reward of the POMDP, that is, the predicted determinant of the FIM. That is to say, we use
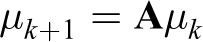
to predict the belief state of the target, and
Approximate receding horizon approach for POMDP
Since it is intractable to solve the policy for maximizing the objective function (equation (17)) exactly, we use an fixed finite-horizon POMDP to create a policy to solve the infinite-horizon POMDP approximatively in this article, which is called “approximate receding horizon approach.”
Algorithm design
The idea of the approximate receding horizon approach is that at the current time t, we obtain the optimal policy sequence of the POMDP over a finite horizon
The specific algorithm is as follows.
The approximate receding horizon algorithm


Algorithm analysis
In this section, we analyze the performance of the approximate receding horizon approach for infinite-horizon average reward.
When we say the algorithm is stable, we mean that the difference between the value function and the optimal value function is bounded. Then the proposed algorithm is stable and the following theorem can be obtained.
Theorem 1
By defining the receding H-horizon control policy as
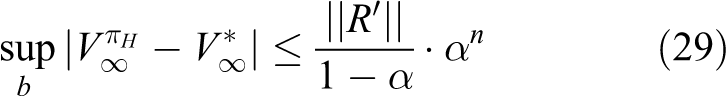
Proof
Recall that the state of the UAV is observable and controllable, and the state of the target obeys normal distribution.
The expectation of the system state at time k is

Then we have
Define
The ergodicity condition can be expressed in another way. 33 That is, there exists a constant α < 1 such that

where the sup is over all
Recall the one-step reward
Thus we have

where

The smallest distance between the target and the UAV is the height of the UAV which is h. From this it can be seen that the reward is bounded, that is

The above specification shows that the system satisfies the condition under which Hernández-Lerma 33 show that

We can see that the receding horizon approach provides a good approximation for the optimal infinite-horizon average reward and the error approaches zero geometrically with α.
The decision-making of UAV needs high real-time performance, so we tend to choose algorithm which is lower in the complexity of computation time. Next, the article analyzes the complexity of the computation time of the objective function in our algorithm (equation (28)), and compares it with that based on KF (equation (19)).
Using the reward derived from the IG to calculate the objective function, we should obtain
Required operations for the IG-based objective function and the KF-based objective function.

IG: information geometry; KF: Kalman filter.
It is clearly shown in Table 1 that the required operations, either addition and multiplication or other operations of the IG-based objective function (equation (28)), are much less than those of the KF-based objective function (equation (19)), in other words, it can greatly improve computational efficiency to use information accumulation as the objective function of the optimal decision-making.
Remark 2
Several notes on operations. (1) The operations of matrix inversion in equation (18) are counted based on the adjoint matrix inversion method. (2) In the following simulation, the MATLAB command fmincon is used to minimize the objective function. (3) Due to the randomness of the tracking system, the difference of initial conditions, and the limitation of iteration steps, the computation time of optimal strategy is not linear with the computational complexity of the objective function and the tracking error also has a certain randomness.
Simulation results
This section presents the simulations to verify the performance of the proposed algorithm, and compares the simulation results with other method. In the comparative algorithm, the trace of the covariance in the KF is used as the objective function.
The simulation is implemented in MATLAB R2016b (maci64), where the action decision is obtained from the MATLAB command
In these four experiments, the time horizon H is set to 6, 3 which means that in every time step, the UAV plans 6 future time steps in advance, but only the first action is implemented. In each simulation group, we carry out 200 Monte Carlo simulation experiments. Each experiment performs 100 steps and takes 0.5 s per step. In the simulations, the root-mean-square error (RMSE) between the target and the tracker is employed to measure the location estimation accuracy for different algorithms (our algorithm and a KF-based algorithm; the KF-based algorithm means the performance criterion is based on the trace of the corresponding covariance matrix). Additionally, the computation time is taken into account for comparing the real-time performance of different algorithms.
In the first two groups of simulation experiments, the target is subjected to rectilinear motion, and the average linear velocity of the target is 15 m/s. The initial position of the UAV is (0, 50), and the initial position of the target is (0, 0). Figure 1 shows the trajectories of the UAV for target tracking.

The trajectories of a UAV tracking a rectilinear motion target. UAV: unmanned aerial vehicle.
In the first simulation group, the sensor measurement standard deviation parameters are

The performance of group I: (a) the RMSE of tracking and (b) the computation time. RMSE: root-mean-square error.
In the second simulation group, the sensor measurement standard deviation parameters are
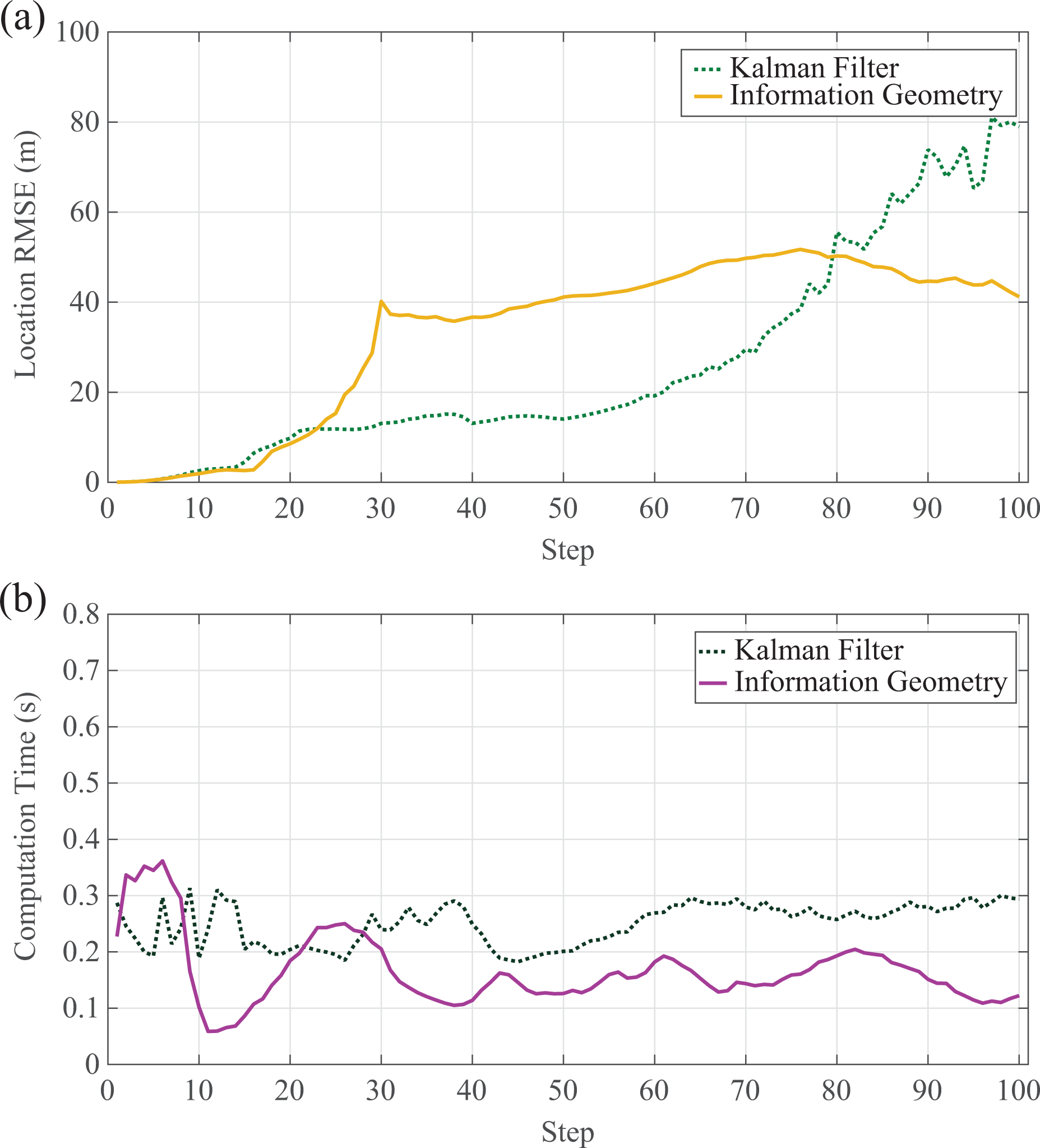
The performance of group II: (a) the RMSE of tracking and (b) the computation time. RMSE: root-mean-square error.
For the first two simulation groups, when the sensor measurement noise is larger, our proposed method performs better. Moreover, the decision-making takes only half of the computation time which is required by the KF-based algorithm, which is significant in the practical application of UAVs.
In the next two simulation groups, the target moves in a circle, and the angular velocity of the target is 0.1 rad/s, and the radius of motion is 200 m. The UAV’s initial position is (0, 100), and the initial position of the target is (0, 200). Figure 4 shows the trajectories of the UAV and the target.

The trajectories of a UAV tracking a circular motion target. UAV: unmanned aerial vehicle.
In the third group of simulations, the sensor measurement standard deviation parameters are set to

The performance of group III: (a) the RMSE of tracking and (b) the computation time. RMSE: root-mean-square error.
In the fourth group of simulations, the sensor measurement standard deviation parameters in group III are

The performance of group IV: (a) the RMSE of tracking and (b) the computation time. RMSE: root-mean-square error.
As it shows in the last two scenarios, our method produces better tracking performance and is more time-efficient in solving.
The simulations indicate that the IG-based algorithm can obtain strategies faster in different sensor measurement precision and target movement forms. As shown in the previous section where the computational complexity of the objective function is analyzed, the decision-making algorithm based on the IG can greatly save the computation time. Besides, when the observation error increases, the tracking accuracy decreases.
In addition, we also present partial numerical results. For each set of experiments, we calculate the average distance error and average computation time. We summate every step distance error over the simulation runtime, and the mean of these errors (from each Monte Carlo run) is called the average tracking error. Similarly, for every step of the simulation runtime, we record the average of computation time, which is called the average computation time. The data statistics are listed in Table 2, and the better data are bolded. Obviously, our algorithm is more time-efficient in solving in each simulation. It is clear that the calculations of inverse matrix in KF cost more time than our method. It is also important to emphasize that the decision time for each step is shorter than the predefined time (0.5 s) per step. That is to say, the algorithm can meet the requirement of real-time calculation. However, in view that IG method takes shorter for decision-making, there is a greater degree of pre-improvement of the performance of decision-making by the short decision period. At the same time, we notice that the tracking error of the IG-based algorithm does not always perform better than the KF-based algorithm. The main reason is that, in this discrete measurement sampling scenario, the information distance is approximated by the sum of the determinant of FIM, which sometimes reduces the estimation accuracy for some scenarios. However, as shown in Figure 5(a) and (b) and Table 2, the IG-based algorithm performs better for high-order motion system, such as the circular motion target. Nevertheless, the IG-based method is more time-efficient than the KF-based method, which is more suitable for practical applications, especially when the computational resource is limited.
Statistical results of average computation time and average tracking error.

KF: Kalman filter; IG: information geometry.
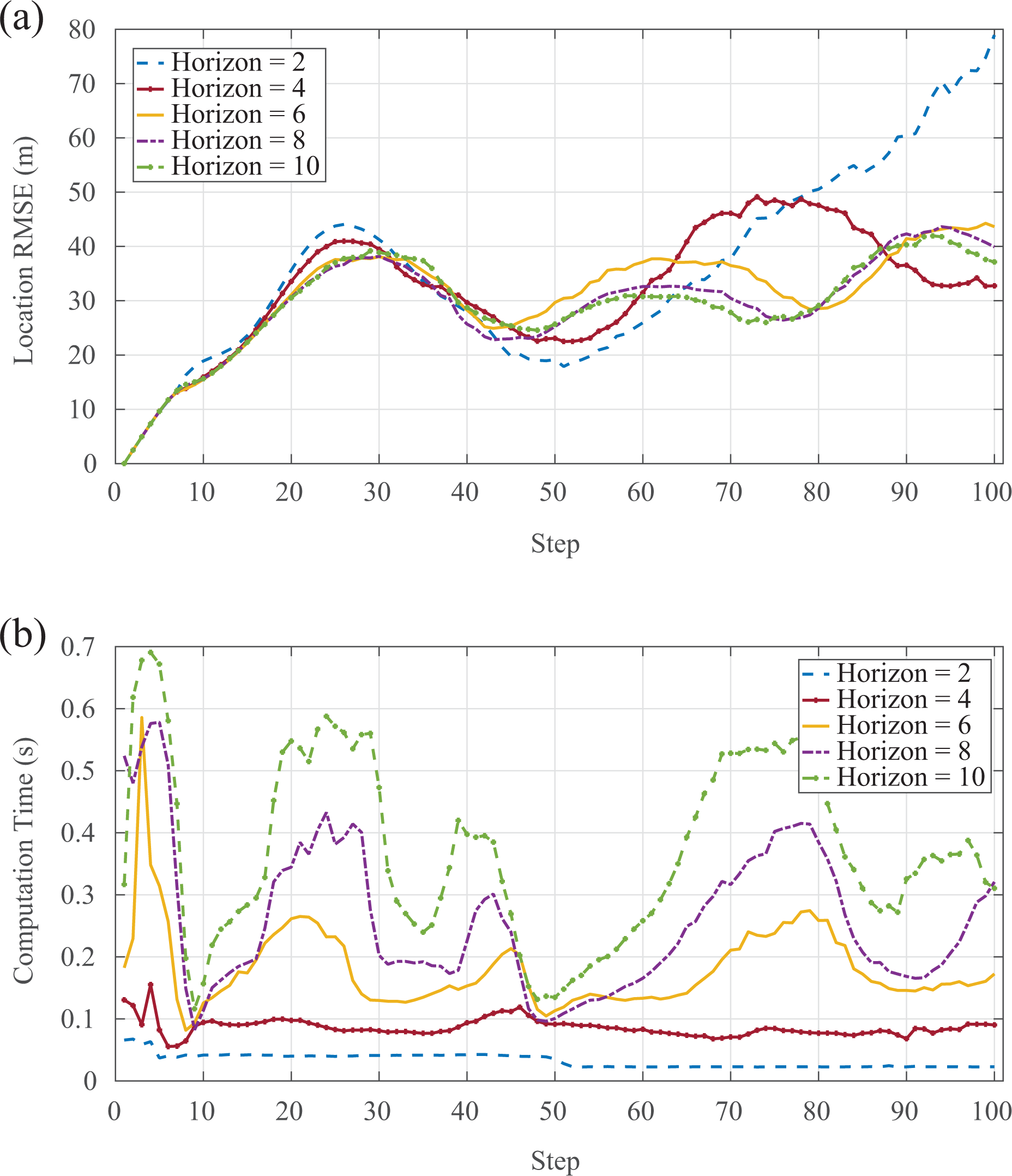
In order to study the effect of different prediction horizons on computation time and tracking performance, we also carry out two groups of experiments. In these two groups, the movement of the target is different and each group including 200 times Monte Carlo simulations at different time horizons. The average computation time and the location RMSE of tracking for these 200 experiments with different time horizons are presented in Figures 7 and 8.

The UAV tracks the target of linear motion with different time horizons, (a) the RMSE of tracking and (b) the computation time. RMSE: root-mean-square error; UAV: unmanned aerial vehicle.
The UAV tracks the target of circular motion with different time horizons (a) the RMSE of tracking and (b) the computation time. RMSE: root-mean-square error; UAV: unmanned aerial vehicle.
These figures reflect that the computation time reduces and the tracking performance gets worse with the time horizon decreasing. Therefore, when we select the time horizon, it need to make a trade-off between the computation load and the tracking performance.
Conclusion and future work
In this article, we have studied the moving ground target tracking problem of a fixed-wing UAV. More specifically, a POMDP-based action decision-making method has been proposed, which gives the optimal sequence to maximize the target information observed by the radar. In this method, we have introduced the FIM as the criterion of the proposed method with the aid of IG. Simulation results corroborate the effectiveness of our proposed method; and show that compared to the classical KF-based method, our method has higher time-efficiency in computations. In our future work, we would extend our method to multi-target tracking scenarios.
Supplemental material
Supplemental_material - Information geometry-based action decision-making for target tracking by fixed-wing unmanned aerial vehicle: From algorithm design to theory analysis
Supplemental_material for Information geometry-based action decision-making for target tracking by fixed-wing unmanned aerial vehicle: From algorithm design to theory analysis by Yunyun Zhao, Xiangke Wang, Yirui Cong, and Lincheng Shen in International Journal of Advanced Robotic Systems
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplementary material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.