
Abstract
Autonomous vehicles are considered to have great potentials in improving transportation safety and efficiency. Autonomous follow driving is one of the highly probable application forms of autonomous vehicles in the near future. In this article, we aim at the basic autonomous following form with one follower and one leader. Proper longitudinal regulation of the follower vehicle is essential for the driving quality of the two-vehicle platoon. Focusing on this problem, a novel longitudinal control method composing of a learning-based acceleration decision phase and an internal model–based acceleration tracking phase is proposed for the follower vehicle. In the acceleration decision phase, proper acceleration commands of the follower that adjusts the following distance converging to the target value are determined by a near-optimal acceleration policy which is obtained through an online reinforcement learning algorithm named neural dynamic programming. In the acceleration tracking phase, throttle and brake control commands that drive the vehicle as the decided acceleration are derived by an internal model control structure. The performance of our proposed method is verified by simulation experiments conducted with CarSim, an industry recognized vehicle dynamic simulator.
Keywords
Introduction
Due to the great potentials in reducing traffic accidents, saving energy, and improving transportation efficiency, autonomous vehicles have received wide attentions since the DARPA Grand Challenge 1 and the Urban Challenge. 2,3 As one of the highly probable application forms of autonomous vehicles in the near future, autonomous following platoon can maintain more reasonable vehicle space which is important in the future intelligent transportation system. 4,5 In this article, we investigate the basic autonomous following form with one follower and one leader which is the foundation of full autonomous platoons. Specifically, we focus on the longitudinal control of the follower in the two-vehicle platoon.
Different objectives are designed to ensure the safety and smoothness during the follow driving process. In the literature, there are three basic vehicle spacing policies: constant separation, constant time headway, and constant safety factor. 6 For constant separation policy, the vehicle space is expected to be fixed. For constant time headway policy, the desired following distance varies linearly with speed so that the time headway between vehicles is constant. 7 For safety factor policy, the desired vehicle separation changes quadratically with speed so that the following space is proportional to the safe stopping distance. In this article, the constant separation policy is adopted.
In order to control the follower vehicle automatically driving after the leader with target distance, kinds of longitudinal regulation methods are presented. As widely applied methods, Proportional Integral Differential (PID) controllers are designed for the autonomous following problems in the studies by Ioannou and Xu, 8 Lygeros et al., 9 and Guvenc and Kural. 10 But the tuning of control parameters demands a great deal of experience. Virtual bar–based methods which imitate the principle structure of vehicles with a trailer are presented in the studies by Ng et al. 11 and Ng. 12 The intuitive methods are further extended to more flexible versions in which the follower’s acceleration is derived from the elastic deformation of the link bar according to Hook’s law. 13,14
Adaptive cruise control (ACC) and cooperative adaptive cruise control (CACC) are other topics related to intelligent cars. 15 Comparing the autonomous following problem focused in this article, ACC and CACC are only concerned with part speed range. 16 Full-range ACC is a typical application of autonomous follow driving. In these areas, more complicated and advanced approaches are developed. To fulfill the longitudinal control of the follower vehicle, fuzzy logic approaches are proposed in the studies by Muller and Nocker 17 and Chang and Choi. 18 Sliding-model and fuzzy sliding–model controllers are presented in the studies by Fritz and Schiehlen 19 , Xiao and Gao 20 , and Ghaffari et al. 21 In the studies by Moon et al. 22 and Kim et al., 23 a linear optimal control theory–based upper-level controller which outputs the appropriate acceleration is proposed for the full-range adaptive cruise. And a model free low-level controller is utilized to regulate throttle and brake input to follow the desired acceleration. 24 Predictive nonlinear longitudinal control law, of which the control input is the vehicle’s speed, is proposed for the formation control of off-road autonomous vehicles in the studies by Guillet et al. 25 and Bom et al. 26 Model predictive controllers are also widely employed in the studies by Stanger and Re 27 , Shakouri and Ordys 28 , and Moser et al. 29 for the autonomous follow driving. Besides, H∞ controller in Kayacan 30 and smooth trapezoidal speed profile in Li et al. 31 are utilized in the longitudinal regulation for automatic vehicle following problem.
Reinforcement learning (RL) is a new kind of machine learning method distinguishes from supervised learning and unsupervised learning. 32 It is inspired by behaviorist psychology and studies the action policy with different system states. 33 Through iteratively trial and error, rewards are received from the environment. Action policy is improved based on the received rewards. With enough training, optimal or near-optimal action policy can be found. Maximum total rewards will be acquired from the environment when taking action according to the learned policy.
Approximate RL is considered the effective method to solve sequential decision problems with large even continuous action or state space. 34 This kind of approaches can learn the knowledge about the whole space from limited training experience without scanning every system state. According to what is approximated, there are three main kinds of approximate RL approaches including approximate policy iteration methods, policy search methods, and actor–critic methods. 35 For approximate policy iteration methods, the state value function or the action value function is approximated. For policy search methods, the action policy is approximated. Both the value function and action policy are approximated in actor–critic methods. Thus, actor–critic methods are more suitable for problems with little model information. 34 Approximate RL methods have been adopted in the motion control of automated vehicles. 36 –38
Overall
The autonomous following problem of a two-vehicle platoon is illustrated in Figure 1. The leader vehicle can be operated by human drivers or autonomous driving systems. In this article, we focus on the longitudinal control of the follower. Thus, the lateral controllers of both the leader and follower are fulfilled with the CarSim built-in preview distance–based controller, the leader’s speed is regulated with the method presented in the study by Wang et al., 39 and the longitudinal control of the follower is realized with our proposed method. As mentioned in the last section, fixed following distance policy is utilized in this article. Thus, the goal is to keep the following distance d converge to the target value d target with the proper throttle and brake control of the follower. It is assumed that the leader can always be recognized and located with the help of some sensors, like cameras, 40,41 LIDARs, 42,43 sonars, 44 or even vehicle-to-vehicle communication devices. 45 Thus, leader’s speed and following distance can be derived. Besides, the follower’s speed is also supposed to be available with the sensors like odometry and Inertial Measurement Unit (IMU). 46

The sketch of the autonomous following problem. The follower vehicle is expected to run after the leader with a target following distance in this article.
The overall framework of our longitudinal controller for the autonomous following problem is indicated in Figure 2. According to the mechanical theorem, driving distance of the vehicle is the integration of vehicle speed, the quadratic integration of acceleration. To ensure the smoothness during the regulation process of autonomous following, we focus on the adjustment of follower’s acceleration instead of speed. The longitudinal controller is divided into two phases: acceleration decision and acceleration tracking. As shown in the red dotted block in Figure 2, an acceleration policy is used to determine the appropriate acceleration of the follower according to the current following state. A neural dynamic programming (NDP) 47 based learning mechanism is employed to update the acceleration policy. Unlike the supervised actor–critic algorithms, 37 teaching controllers are unnecessary to the primary NDP method. Details of the acceleration policy and learning process are introduced in the third section. The acceleration tracking phase, as indicated in the blue dashed block in Figure 2, controls the vehicle’s throttle or brake to drive the follower with the decided acceleration. Because of the complex dynamic of the vehicle’s longitudinal system, an internal model structure is utilized to obtain proper control value to fulfill the desired acceleration. The design of the acceleration tracking controller is introduced in the fourth section. Details of the internal model–based speed or acceleration controller can be also referred to our previous research. 39

The framework of the longitudinal controller for autonomous following. The longitudinal controller is composed of two phases: acceleration decision and acceleration tracking. The desired acceleration for the follower is decided in the acceleration decision phase. While the decided acceleration is tracked by controlling the throttle and brake in the acceleration tracking phase.
Acceleration decision based on NDP
The acceleration decision phase is realized with the NDP algorithm, which is an effective RL method as mentioned above. To apply such an RL mechanism, the Markov decision process (MDP) model of the acceleration decision problem should be established first. For the integrity of the descriptions, the basic theories of MDPs are simply introduced at the beginning of this section. Then, MDP modeling of the acceleration decision problem is illustrated in detail. Based on the aforementioned works, the scheme of learning the acceleration policy with NDP is designed carefully.
Markov decision process
MDPs, as the mathematical foundation of RL methods, depict the interacting process between the agent and the environment and provide a framework for modeling and analyzing sequential decision-making problem. 33
An MDP can be described with a five-tuple (S, A, P, r, J). 48 In the tuple, S denotes the environment state space, A indicates the system action space, and P(s, a, s′) ∈ [0, 1] represents the probability of system state transiting from s to s′ with action a. r(s, a, s′) : S × A × A → ℝ is the immediate reward when the system state transiting from s to s′ by executing action a. J is the objective function for the decision problem 49 and parameter γ ∈ (0, 1] is introduced to balance the immediate and the long-term rewards for J. Comparing r and J, r is a shortsighted evaluation for the action, while J is a farsighted observation of the problem.
The action policy is defined as π : S × A → [0, 1], π(s, a) means the probability of choosing action a in the state of s. Action value function of MDP denotes the expectation of cumulative rewards with policy π starting from state–action pair (s 0, a 0), as defined in the below equation

According to the definition, action–state function Q π(s, a) satisfies the Bellman equations 50

where R(s, a) = ∑s′ ∈ SP(s, a, s′)r(s, a, s′) is the expectation of rewards when performing action a in the state of s. Since future rewards are taken into consideration as in equation (1), action value function can be regarded as a kind of objective functions of the MDP problem. And then policy π* which maximizes the action value function Q π is an optimal action policy for the MDP, 51 as in the below equation

Modeling the acceleration decision problem with MDP
The leader vehicle is supposed as running with known constant velocity in every short period. Under this assumption, and considering the ideal discrete situation, the deviation between the following distance and the preset target value ed = d − d target is updated according to the running acceleration as in the below equation

where v, a, and T represent speed, acceleration, and time step, respectively. Superscripts k or k + 1 mean different time steps. Subscripts l and f correspond to the leader and follower vehicle, respectively. Thus, the following distance regulation process satisfies the Markov property which indicates that the next state of an MDP is only determined by the current state and action. And the following distance regulation process can be modeled as an MDP. The proper definition of MDP for acceleration decision during autonomous following should be firstly fulfilled before the online learning task.
Acceleration decision stage determines proper acceleration to drive the follower vehicle to keep the given distance from the leader. In this article, the following distance deviation ed is regarded as one of the states of the MDP for the acceleration decision problem. Besides, since the relative speed ev = vf − vl is a direct influence factor to the following distance, it is also added to the MDP state. Therefore, the state of the MDP for the acceleration decision problem is defined as

The action of the MDP is regarded as the acceleration af of the follower vehicle. Immediate rewards of the acceleration decision MDP are designed as the negative weighted sum of the quadratic forms of follower’s relative speed ev , the following distance deviation ed , and the changing of the follower’s acceleration Δaf

where k 1, k 2, and k 3 are positive parameters. By carefully setting these coefficients, deviations of the following distance, the relative speed, or large changing of the follower’s acceleration will be punished. Improvement of action policy will be guided by this reward to achieve better vehicle following performance.
Learning the acceleration policy with NDP
After the establishment of the MDP model of the acceleration decision problem, the NDP algorithm presented in the work by Si and Wang 47 is employed to learn the acceleration decision policy for the autonomous vehicle following problem.
The NDP algorithm is a typical actor–critic method and composed of two components: the critic and the actor.
52
Figure 3 illustrates the structure of the critic network. Current MDP states st
and the selected action at
are inputted into the critic network. For the acceleration decision problem mentioned above, st
is defined as equation (5) and the action at
is the acceleration af
of the follower vehicle. In actor–critic algorithms, the critic component is applied to approximate the action value function. Thus, the output of the critic network is the estimation of the action value function, noted as

The structure of the critic network. The feedforward neural network with three layers is employed for the critic in this article.
The objective of the critic network is to minimize the approximate error, for the convenience of computation, the quadratic formation is adopted as

where
The structure of the actor network is described in Figure 4. Current MDP states including follower’s relative speed ev and following distance deviation ed are inputted into the actor network. In actor–critic methods, the actor component is utilized to approximate the action policy of the MDP problem. Thus, the action at is set as the output of the actor network.

The structure of the actor network. The feedforward neural network with three layers is employed for the actor in this article.
The goal of the actor network is to approximate the optimal action policy which maximizes the objective function of MDP problem. Since the reward function is always negative if any relative follower’s speed or following distance error exists as defined in equation (6), quadratic formation objective function is employed as

where ea
(t) = J(t) − Uc
(t) is the deviation between the approximate objective J and the desired ultimate objective Uc
.
47
As mentioned above, the reward function is no larger than zero, thus the desired ultimate objective Uc
is set to zero in this article. Since the action value function is a kind of objective functions for MDP, J(t) is approximated as
According to the structure definition of the critic and actor networks, weight parameters updating rules for the two networks are illustrated in equations (9) and (11). Related gradients utilized for weight updating can be derived as equations (10) and (12), respectively. 38,47
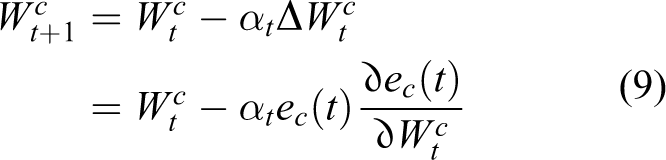

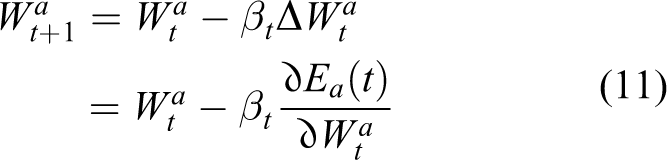
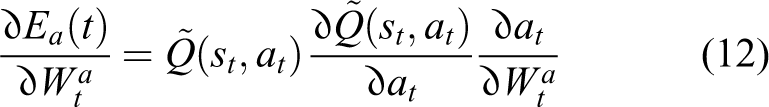
where αt and βt are learning rates for the critic and actor networks. Partial derivatives at the right side of equations (10) and (12) can be solved according to the definitions of the networks.
Up to the present, the MDP definition of acceleration decision for the autonomous following problem has been developed. Weight updating rules have been derived for the actor and critic networks of the NDP algorithm. With these preparations, the training process of the two networks can be started. Action value function Q(s, a) and action policy π(s, a) for the acceleration decision problem will be approximated and improved gradually.
Acceleration tracking
Acceleration tracking is the consequent phase after the acceleration decision, which realizes the determined acceleration for the follower vehicle with proper control of throttle and brake. In this article, we assume that the transmission keeps unchanged all along. The acceleration tracking is implemented with an internal model control (IMC) structure, which is proposed for the speed tracking control of autonomous land vehicles in our previous work. 39 In this section, IMC structure and the design of our acceleration tracking controller are introduced in detail.
The IMC method relies on the internal model principle which indicates that accurate control can be achieved only if the control systems encapsulate some representation of the plant to be controlled. 53 Thus, IMC is a model-based method, and the basic structure is illustrated in Figure 5. The control command u is derived by the controller, which is always the inverse model of the plant to be controlled. Meanwhile, a forward model of the plant is utilized to identify the noise introduced into the system by either internal or external sources. The difference between outputs of the actual plant and the forward model is fed back to the reference as an input to the controller.

Basic IMC structure. IMC: internal model control,
In our problem, the control reference is the follower’s acceleration. If we assumed that the mass of the vehicle is unchanged, then the acceleration equivalent to tractive force and the feedback acceleration deviation can be directly compensated to the reference acceleration. Thus, the IMC structure is suitable for the acceleration tracking problem. The IMC structure for acceleration tracking is illustrated in the blue dashed block in Figure 2.
The longitudinal system of land vehicles is composed of the engine, transmission, tires, and so on. 54 Due to the strong nonlinear and obvious delay characteristic, it is difficult to found the mechanistic model. Thus, a nonparametric longitudinal dynamic model is utilized in the IMC acceleration tracking structure. According to the intuitive experience that certain throttle or brake applied to the vehicle at different vehicle speeds will obtain different accelerations, we regard the longitudinal system as a black box and formulate the relationship between the current speed vc , current control input u, and the next acceleration a as

To measure the vehicle’s response to different control inputs and establish the nonparametric model, 13 off-line experiments are taken in the reference environment with flat, straight, and level roads. Details about collecting the longitudinal response data of the vehicle can be found in the study by Wang et al. 39
Simulations and discussions
To validate the performance of the proposed method, experiments are carried out on our simulation platform, which is constructed based on the high-fidelity vehicle dynamic simulator, CarSim. As a well-recognized tool in the automotive industry, CarSim can deliver accurate, detailed, and efficient methods for simulating the performance of passenger vehicles. 55 Our longitudinal controller is implemented with MATLAB and exchanges data with the vehicle simulation solver by the provided API. 56
Before the learning process starts, structures of the actor and critic networks should be defined clearly. In this article, both actor and critic adopt feedforward neural networks with three layers. Ten neural nodes are set to the hidden layers for the two networks. Activation functions of hidden and output nodes in the actor network are with sigmoid type. Hidden nodes of the critic network are also set as the sigmoid-type activation function. While activation functions of the output nodes in the critic network are with linear type. Both the learning rates αt and βt for the two networks are set as 0.01. Discount factor γ which balances the immediate and long-term rewards is set as 0.9. All weight parameters are initialized randomly before training begins.
Since vehicle speed and following distance are continuous, there are infinite initial states with different follower’s speed, leader speed, and initial following distance. Thus, in each learning episode, the initial state is determined by randomly setting the follower’s speed, leader’s speed, and initial following distance. The target following distance for each episode is also confirmed randomly.
After the iterative training procedure, a near-optimal acceleration decision policy is derived. Near-optimal follower’s acceleration actions for a different following state under the learned policy are illustrated in Figure 6. To verify the performance of learned acceleration decision policy, tests are conducted with three representative scenarios. Meanwhile, the smooth trapezoidal curve–based approach (noted as the trapezoidal method below) presented in the study by Li et al. 31 is also tested in the same scenarios for comparing.

Follower’s acceleration actions for different states under the learned policy.
Firstly, it is a challenging test (noted as test A), in which the follower’s initial speed is zero and leader’s initial speed is 54 km/h constantly. Initial following distance is 30 m and the target value is 15 m. Since the initial speed of the follower is far less than the leader, and the target follow space is also less than the initial value, the follower vehicle should speed up quickly to catch up to the leader. Regulating process and following results of test A are described in Figure 7.

The regulating process and following result of test A. Top: leader’s and follower’s speed. Bottom: actual and target following distance.
The upper sub-figure of Figure 7 shows the speed regulation process in test A. The corresponding relations between curves and variables are indicated by the legends in the figures. Both follower’s speeds regulated by our method and trapezoidal method are increased rapidly. Follower’s speed by our method converges to the leader after about 35 s, which is slower than the trapezoidal method (about 20 s). Similar phenomenon and converging time can be found in the lower sub-figure, which describes the regulation process of the following distance.
Follower’s acceleration commands generated by the two compared methods are shown in the left sub-figure of Figure 8. It can be found that the acceleration commands derived by the proposed method are obviously smoother than outputted by the trapezoidal method. Smooth desired acceleration is important to the comfort and safety of vehicle driving. The right sub-figure displays the actual normalized throttle and brake control value exported from CarSim. For convenience, the brake states are multiplied by −1 and shown as negative values. As the dotted blue curve records, sudden brake and throttle are taken by the trapezoidal method. This is uncomfortable and dangerous during driving on the road, especially with high running speed. In contrast, the control states of throttle and brake by our method are milder and more acceptable.

The acceleration commands and control states of the follower vehicle in test A. Left: decided acceleration and actual acceleration. Right: actual throttle and brake exported from CarSim.
In the second test (noted as test B), the initial speed of the follower is 54 km/h. Leader’s speed is 25 km/h constantly. Initial following distance is 25 m and the target value is set as15 m. Since the follower’s initial speed is obviously larger than the leader, a strong speed reduction should be applied at the very start. Regulating process and following results of test B are described in Figure 9.
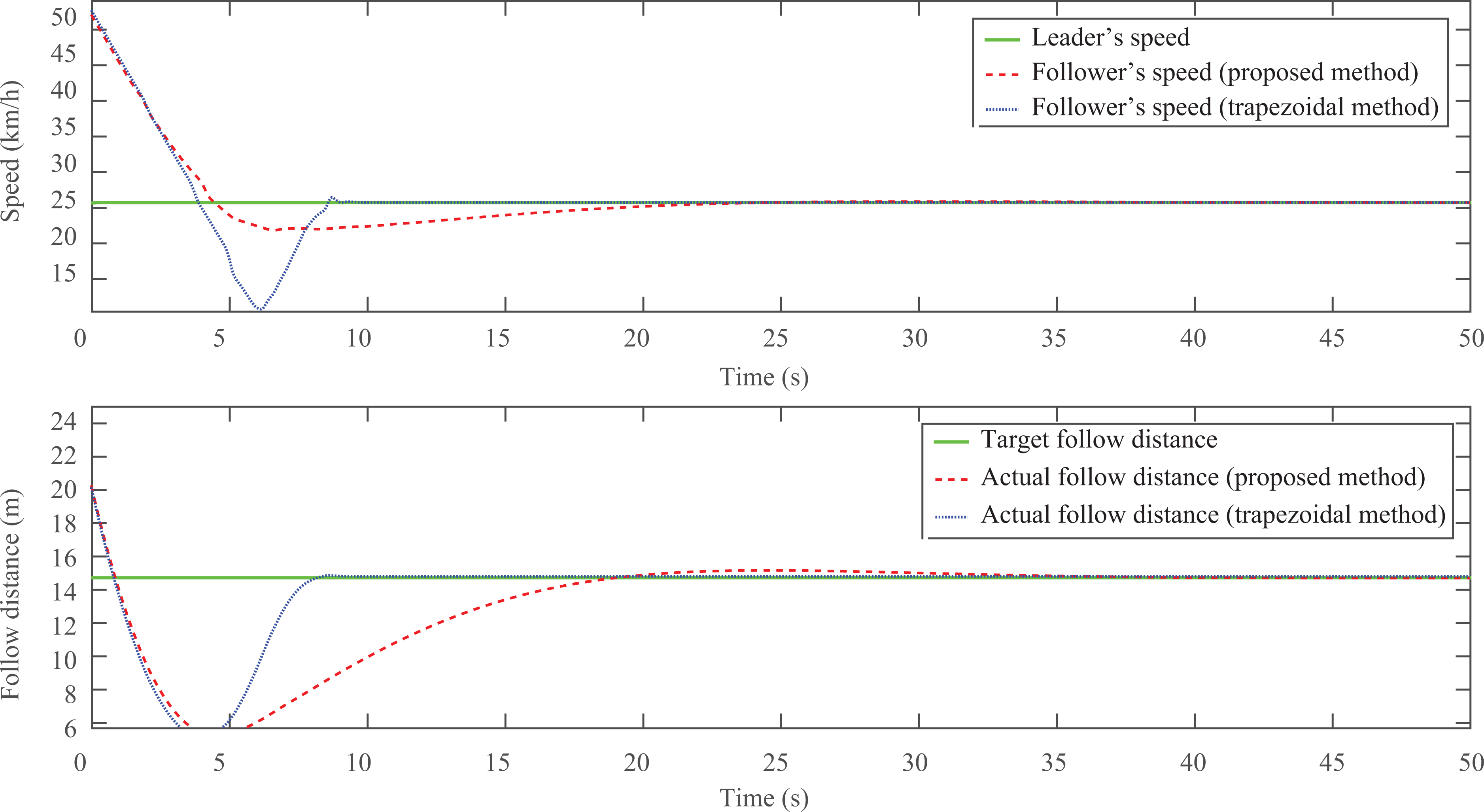
The regulating process and following result of test B. Top: leader’s and follower’s speed. Bottom: actual and target following distance.
From the speed curves described in the upper sub-figure of Figure 9, both the follower’s speeds regulated by the two compared methods are decreased as quickly as expected. Follower’s speed and following distance controlled by the trapezoidal method converge to the leader and target space value at about 10 s, which is far faster than the proposed method (about 30 s). The cost of the fast convergence with the trapezoidal method is the violent driving behavior. This is displayed in Figure 10, which records the desired accelerations and actual throttle/brake states.

The acceleration commands and control states of the follower vehicle in test B. Left: decided acceleration and actual acceleration. Right: actual throttle and brake exported from CarSim.
Finally is a comprehensive test (noted as test C), in which initial speeds of the follower and leader are zero and 20 km/h. Initial following distance is 35 m and the target value is set as 25 m. Unlike the above two tests, leader’s speed changes with the running time during test C. The acceleration policy should deal with this additional disturbance. Regulating process and following results of test C are described in Figure 11.

The regulating process and following result of test C. Top: leader’s and follower’s speed. Bottom: actual and target following distance.
Leader’s speed is a timely changed curve as the green solid curve in the upper sub-figure of Figure 11. In the first 100 s, leader’s speed is 20 km/h, then it increases to 50 km/h for the next 100 s. In the third 100 s, it goes back to 30 km/h. Finally, it rises up to 55 km/h. From Figure 11, for both methods, the follower’s speed tracks the changing leader’s speed with small overshoots at every transition position. Following distance converges to the target value after a short regulation at the beginning of every 100 s. Figure 12 shows the acceleration commands and the control states of follower vehicle in test C.

The acceleration commands and control states of the follower vehicle in test C. Left: decided acceleration and actual acceleration. Right: actual throttle and brake exported from CarSim.
Comparing with the two tested methods, regulation process of the trapezoidal method is more decisive, while the proposed learning-based method is smoother. This difference is reflected obviously in the desired acceleration results as the left sub-figures of Figures 8, 10, and 12, in which the magnitudes and regulation of the desired acceleration commands derived from the trapezoidal method are larger than the proposed method. With the drastic acceleration action, the trapezoidal method can regulate to the steady state more quickly. But, this kind of behavior may lead to the ride comfortlessness and unsafety during the following process. On the other hand, desired acceleration commands of our method in this article are smoother and more human-like. This advantage is mainly achieved by the punishment component on the changing of the acceleration actions in the reward function as in equation (6). Consequently, the proposed method needs more regulating time and small overshoots exist due to the mild acceleration behavior. This is acceptable considering the safety and smoothness. From the tests above, the performance of the presented longitudinal control approach for the autonomous following problem is well demonstrated. Compared to the trapezoidal method, our approach can ensure the smoothness, comfort, and safety during the autonomous follow driving process.
Conclusions and future work
The autonomous follow driving problem of two-vehicle platoon is investigated in this article. The longitudinal control of the follower vehicle is divided into two phases: acceleration decision and acceleration tracking. NDP, an actor–critic RL algorithm, is utilized to learn a near-optimal acceleration decision policy through iteratively trial and error. An IMC structure is designed to adaptively control the follower vehicle as the decided acceleration. Acceleration decision policy learning and performance verification tests are conducted with CarSim. From the test results, it can be found that the proposed method is competent for the autonomous following problem.
For the proposed method, there are small overshoots during the following distance regulation process, especially when large deviations from the initial state and target state exist. This is partly because of the near-optimal property of the NDP algorithm. Thus, more intelligent learning approach will be employed in the future. And more ingenious reward functions of the autonomous following MDP should be designed to deal with these shortcomings and further improve the performance. Besides, the longitudinal regulation method in this article will be combined with proper lateral controllers to construct a complete autonomous following system. And more experiments will be conducted on real vehicles to verify the performance of the proposed longitudinal control approach.
Footnotes
Acknowledgements
The authors would like to thank the anonymous reviewers for their valuable comments.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work is supported by National Nature Science Foundation of China under grant no. 61375050.