
Abstract
User detection, recognition, and tracking is at the heart of human–robot interaction, and yet, to date, no universal robust method exists for being aware of the people in a robot’s surroundings. The present article imports into existing social robotic platforms different techniques, some of them classical, and other novel, for detecting, recognizing, and tracking human users. The outputs from the parallel execution of these algorithms are then merged, creating a modular, expandable, and fast architecture. This results in a local user mapping through fusion of multiple user recognition techniques. The different people detectors comply with a common interface called PeoplePoseList Publisher, while the people recognition algorithms meet an interface called PeoplePoseList Matcher. The fusion of all these different modules is based on the Unscented Kalman Filtering technique. Extensive benchmarks of the subcomponents and of the whole architecture demonstrate the validity and interest of all levels of the architecture. In addition, all the software and data sets generated in this work are freely available.
Introduction
Social robotics aims at making daily companion robots that interact with human users, helping and entertaining them in their everyday life. Consequently, they must follow social behavior and rules, spanning a wide range of applications and types of users. Examples include helping children with their homework, taking care of elderly people, giving information and advice to people in public places, and so on. 1,2 The relation between the human user and the robot can be short term, such as a robot giving directions at a shopping mall, 3 or long term, for instance, a robot delivering mail and food to employees in a lab on a daily basis over a period of several months. 4 The relation between human users and robots, called human–robot interaction (HRI), is at the core of social robotics: A social robot aims at helping users and, as such, it needs to attain a user awareness. This consists in the robot’s having knowledge about how many users are around it, where they are, and who they are. The goal of the research presented in this article is to endow social robots with these abilities, something which is still a challenging problem for the robotics community.
There are works pointing out that humans attain their user awareness following a divide and conquer strategy, 5 that is, splitting this difficult task into independent subtasks of lesser complexity that are easier to achieve. Some patients who have suffered different types of accidents, such as seizures or head trauma, have had some very specific parts of their brain damaged, leaving the rest intact. This helps to understand the way our brain works, and especially where the different functions are located and how the whole system is articulated. For instance, patients of the so-called prosopagnosia, also called face blindness, cannot recognize the identity of known faces although the rest of the brain’s functionality is intact, such as object recognition or even face detection. 6 The way people awareness is achieved in the brain can be divided into three modules: (i) people detection, which consists in locating people around us from the instantaneous data stream of our sensory system; (ii) people recognition, dealing with knowing who they are; and (iii) people tracking and mapping, which is a higher level understanding of people’s motion to maintain spatial and temporal coherency. Therefore, considering this idea as an inspiration, the local mapping of users for a social robot can be split into three subtasks: user detection, user recognition, and user tracking and mapping (by using data fusion). This decomposition constitutes one of the main novelties of this article, which is the fusion of algorithms for user mapping instead of just fusing sensor information.
The structure of this article is as follows: in “Related work” section, we will review how user awareness is achieved in other social robots. In “Problem statement” section, we design our strategy to achieve a generic user awareness architecture as well as hardware and software constraints. In “Approach” section, we present the approach and structure designed to obtain user awareness given the defined strategy and constraints. The experimental results obtained following this approach are presented in “Experimental results” section. Finally, in “Conclusions” section, some conclusions are drawn and future research is outlined.
Related work
Giving user awareness to social robots is a challenging problem that has been tackled already by numerous authors and with a wide range of sensors and techniques. In this section, we will review the current trends in user awareness for social robots. Some of them are barely aware of their environment, similarly to mechanical puppets, while others perceive and recognize their users. This leads to a classification with different levels of user awareness.
There are proposals with no long-term memory about the users interacting with the robot. For example, the robot Aibo 7 was equipped with a variety of sensors and buttons on its body. When one of these buttons was pressed, the robot knew that there was a user nearby and started behaving accordingly. RHINO 8 is an interactive robot guide for museums. To interact with the robot, the users have to press buttons on the onboard interface, which will make the robot deliver information about the museum in a unidirectional fashion.
Additionally, there are robots that detect users automatically without needing them to take any explicit action. This is the case with the social robot Kismet, 9 which can perform a closed-loop active vision by using face and eye detection. Roboceptionist helps users to find their way in offices. 10 The interaction is short term, as users usually ask a few questions of the robot and then leave for their destination. Geiger et al. 11 presented the social robot ALIAS as a gaming platform for elderly people. The user is detected by using voice detection and a face detection algorithm, but no recognition whatsoever is performed. The HRI is made through the use of the tablet computer. The STRAND 12 project includes short-term user awareness using Red Green Blue (RGB)-D and laser information for detection with a Kalman filter that provides the tracks of the users in the space. In a similar line, the project CompanionAble, 13 focus on the use of social robots for elderly people, presents a perception approach that uses multiple cues based on histogram of oriented gradient (HOG) and shape models for people tracking through a Bayesian filter. The MOnarCH 14 project proposes another approach for a mobile platform for edutainment activities in a pediatric hospital. In this case, the user awareness of the robot is provided using an RGB-D camera placed on the robot and omnidirectional cameras placed in the environment.
The previous references presented robots that are able to detect and interact with users on
a short-term basis, that is, if the same user happened to come back later, the robot would
not remember their former interaction. Nonetheless, it is because we are able to identify
individuals that we can develop a unique relationship with each of them.
Valerie is one of the first robot receptionists, used at Carnegie Mellon university.
15
Valerie was involved in long-term interactions, and as it stood for several months in
a booth at the entrance to offices. User recognition was made possible by using the use of a
magnetic card reader: The users were unambiguously identified by swiping their ID card. In
Kanda et al.,
16
the authors study the evolution of the relationship over time in an 18-day field
trial between 119 first- and sixth-grade students and a humanoid robot. They chose to
perform user recognition using wireless radio frequency identification (RFID) tags and
sensors. Jibo (Jibo homepage:
Problem statement
The goal of this research is to endow robots with user awareness by detecting the users in the vicinity of the robot, recognizing them, and building a consistent representation of this knowledge on a map. The number of users, their positions, and who they are is a set of unknown variables that we regard as the state of the system. For each user around the robot, the system must create and maintain a set of data that we call a track: The user’s identity, position, and trajectory.
We use an approach based on divide and conquer, as presented in the “Introduction” section, and split the user awareness into three modules: people detection, people recognition, and people tracking and mapping. These three tasks are executed simultaneously when the robot interacts with users. To make things clearer, let us consider the fictional case of Figure 1(a). The robot here, drawn as the dark blue and white shape in the middle, is surrounded by three users. Figure 1(b) illustrates the process of creating user awareness. User detection consists in detecting, in the sensor data stream, the users around the robot, and knowing where they are. Each of them can then be identified by a temporary ID. Those detections are shown in Figure 1(b) as pink crosses. The fields of view of the different sensors are drawn as angular ranges.
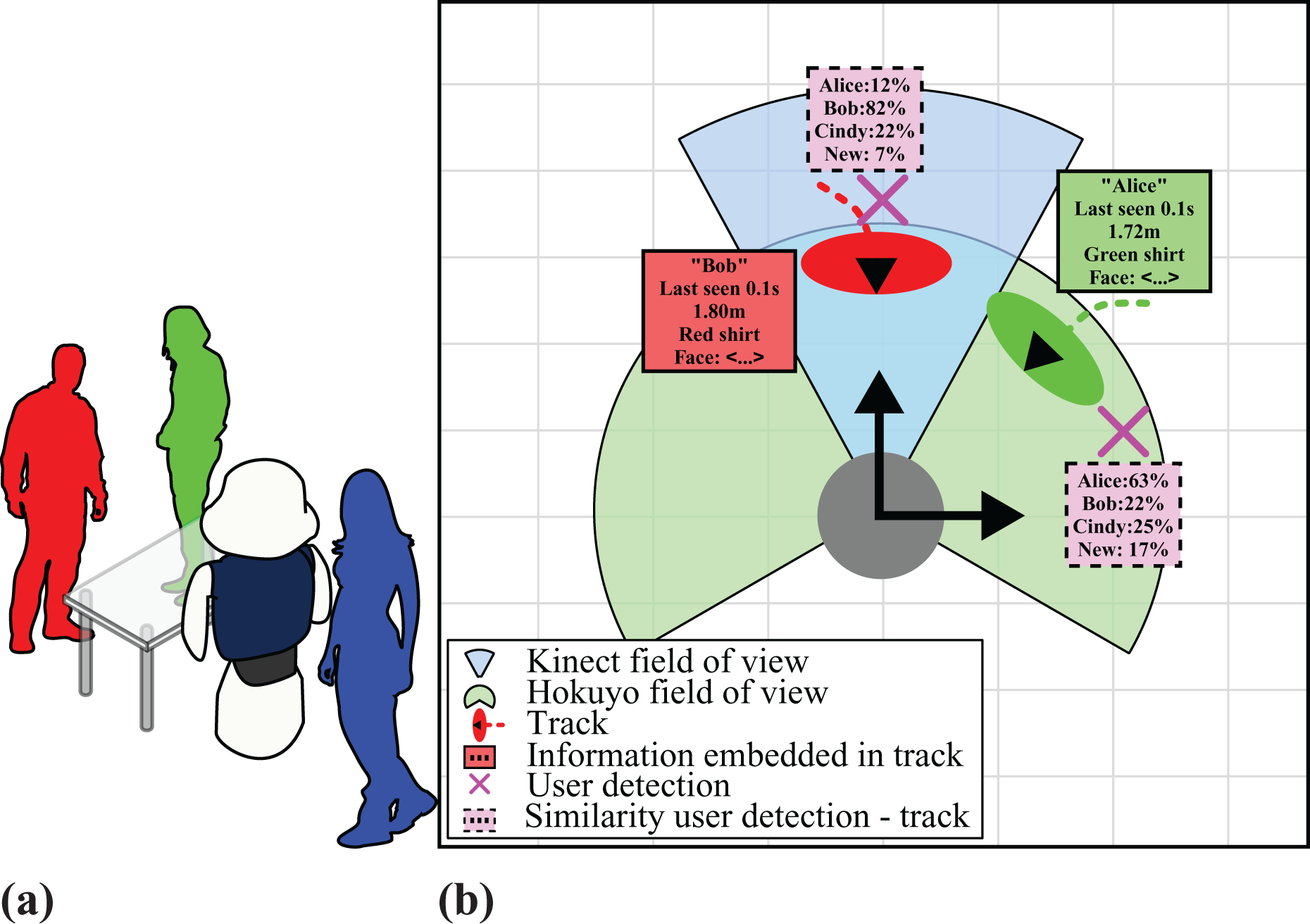
(a) A fictional situation of user awareness around a robot. (b) Knowledge representation of the user awareness in this situation.
For each user, its track contains the user’s identity, previous positions, and so on. Note that the user highlighted in blue is out of the sensors’ field of view; therefore, the robot is not yet aware of that user’s presence. In Figure 1(b), an ellipse shows the position of each track, associated with the uncertainty of its position, and a dashed line shows its previous positions. The additional knowledge in each track is depicted next to the track ellipse in the colored frame box with a solid border.
User recognition aims at obtaining a long-term coherency with the way it detects the users, in other words, matching the temporary IDs to a permanent identity. User recognition is used to match detections and tracks: The higher the similarity, the more probable the detection corresponds to the track. The similarity between each user detection (a pink cross) and the set of tracks, obtained by user recognition, is in the pink rectangle with a dashed border next to this cross.
After the user recognition is performed, through Kalman filtering and multimodal data fusion algorithms, each track can be updated with the matching user detection, by using the similarities computed by the user recognition. The set of tracks constitutes the user mapping.
This work has been carried out using Robot Operating System (ROS), 18 a software architecture specifically developed for use with robots. To sum-up the ROS landscape and glossary, processes are called nodes. They are independent and run in parallel. They can exchange data via messages sent on topics, data channels uniquely identified by their name. A function of a given node can be called from other nodes using a service, uniquely defined by a string name and a pair of strictly typed messages: One for the request and one for the response. ROS topics are many-to-many communication mechanisms, while ROS services are many-to-one.
Approach
The proposed approach is made of several steps, described in the following sections: First,
in “A common data structure” section, we define a common ROS data structure, called
A common data structure
Common practice in computer science consists in standardizing the communication layer and
the data that are exchanged by the different modules, more so than the particular
structures of these modules. For this reason, we designed a common data structure that
describes the information associated to a user detection and this will be the output of
any user detector that we want to integrate: the
The

The People Pose message.
Not all the fields of the message are necessarily filled by all the methods: For
instance, a people detector based on the information of a two-dimensional (2-D) laser
range finder will not use the image fields. A detector can detect several users at once
with a single data input. For instance, a face detector can find several users in the same
RGB image. The different
User detection
An algorithm capable of generating

An example of distributed people detection by using several
The integration of the user detection algorithms
The architecture integrates a series of user detection algorithms that make use of the most common sensor technologies in social robots, such as RGB images, 3-D depth, and 2-D lidar information.
Improved Viola–Jones face detection–based PPLP s
The depth data are useful to discard false positive detectionsz given by the
classical RGB Viola–Jones classifier for face detection.
19
To ease the integration, this detector is wrapped as a
Improved HOGs PPLP s
A HOG is a feature used in computer vision for object detection.
20
It has turned out to be a very efficient technique for the detection of human
shapes. The basic idea underlying this concept is that objects within an image can be
described through the distribution of edge directions or intensity gradients. In a way
similar to the face detector presented before, the original algorithm needs an RGB
image as input and returns as output the rectangular estimates of the people. Unlike
the face detector, the rectangle returned by the 2-D detector is usually bigger than
the person and not centered on her. For this reason, we compute the biggest 3-D
cluster of the 3-D cloud, then threshold the bounding box of this biggest 3-D cluster.
The resulting HOG detector, along with the false positive removal, was wrapped as a
NiTE-based PPLP s
The patented PrimeSense NiTE middleware,
21
freely distributed under Apache License, version 2.0, allows detecting and
tracking human shapes from depth maps. The NiTE middleware supplies a data structure
that a system module converts into a
Polar-Perspective Map-based PPLP
This people detector, introduced for a pedestrian detection system by, 22 uses the idea that a person appears as a set of points tightly close one to another in the 3-D point cloud given by the range imaging device. When projecting these 3-D points on the ground plane, these clusters will be projected onto the same area, thus generating a sort of high-density blob on the ground plane. Standing persons can then easily be characterized by the size of the blob. The so-called Polar-Perspective Map (PPM) is an occupancy map based on the polar coordinate system: It uses a regular grid based on the bearing of the points and their inverse distance to the device.
Tabletop PPLP
The tabletop
Leg pattern–based PPLP
With the information that has been structured and associated to a metric dimension
provided by the 2-D laser range finders, we obtain a direct understanding of the scene
in front of the robot in the laser plane. Since laser range finders are typically
mounted at the level of the legs of the users, that is, about 40 cm high, user
detection is made through the detection of their legs. Many leg pattern–based
detection algorithms exist. We chose the one described in Bellotto and Hu
25
for its simplicity and the overall good performance claimed by its authors. It
was integrated as a
User recognition
In our architecture, each user detector seen in “User detection” section publishes
independently the instantaneous positions of the detected users, shaped as
Throughout this section and the following ones, we denote by
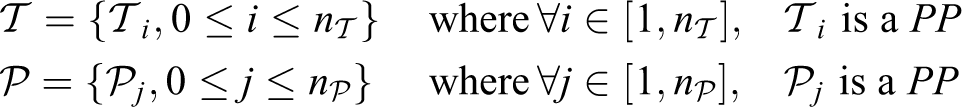
The idea for integrating the different user recognition algorithms is the following: A
user matching algorithm M is defined as a normalized distance that takes
a track and a detection
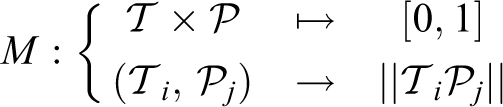
Given tracks
We call a
Integration of user recognition algorithms
From the information provided by the different user detection algorithms, several
recognition techniques have been shaped as
Euclidean distance PPLM
The simplest method to estimate the likelihood of a track against a detected

The constant D is a distance threshold, in meters, and is introduced for normalization. This likelihood estimation needs to choose a distance function. We used the Euclidean L 2 norm, as it corresponds more accurately to the standard definition of the distance between 3-D positions.
Face recognition–based PPLM
The visual appearance of the face is key information that humans use extensively to discriminate between people. For this reason, we use the Fisherfaces algorithm, 26 a face recognition method that uses dimensionality reduction.
There are other methods, such as Eigenfaces
27
and Local Binary Pattern Histogram,
28
but based on other publications that compare their performance, Ahmed and Amin
29
and Belhumeur et al.
26
decided to use the Fisherfaces algorithm. The face recognition–based
As said before, the more similar are two

Height-based PPLM
The height of the users is a good metric not only because it helps recognize one from another but also since the height of unknown users may help to determine their gender, as men tend to be taller than women. We used a novel method for estimating the height of the user, 30 which deals with poses beyond standing straight, such as being slighty stooped or lifting an arm for greeting. Provided the depth image and user mask image, the height is obtained by computing the length of a line that goes from the head of the user to the feet, going through the middle of the body shape, and as such, this method requires that the user be entirely visible in the image stream. The vertical field of view (FOV) of the device being 50°, the method requires the user to be further than approximately 2 m. This strong assumption can be checked thanks to the distance of the user in the depth image.
It first performs a morphological thinning on the user mask image,
31
which generates the skeleton of the image. Then, the length of the skeleton
from head to feet is computed. This gives us a pixel height of the user, that is
converted into a metric one by using the depth information. User matching is then
performed by evaluating the user height on both tracks

NiTE multimap–based PPLM
The raw output of the NiTE algorithm, presented in “The integration of the user
detection algorithms” section, is shaped as a user multimap. The cost of matching a
given detected

PersonHistogramSet-based PPLM
Color histograms have been used extensively for user recognition. 32,33 However, they often do not take into account the fact that this color data in a person is naturally structured: A possible segmentation relies on three parts, the head, the upper body (torso and arms, covered by a shirt or another item of clothing), and the lower body (trousers, skirt, etc.).
Some articles represent the user’s color distribution as a set of histograms, but
with a constant height step,
32
therefore the slices do not correspond to physical body parts (head, torso,
limbs, etc.). We developed a novel method for user recognition based on color histograms,
30
by generating a set of three Hue histograms structured so as to represent the
previously mentioned natural segmentation of the human body. Once the
PersonHistogramSets (PHSs) are computed for both a track and a
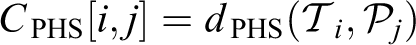
User mapping, using the data fusion based on Kalman filtering
We have defined a common structure for matching algorithms for
From now on, the processing block in charge of retrieving all cost matrices and
performing the multimodal fusion, structured as a ROS node, will be referred to as the
fusion node. The fusion node has the set of tracks corresponding to the
tracked users in memory
First, in the gating process,
35
user detections that cannot correspond to tracks are kept away, being stored in the
so-called gating buffer. This is determined by computing the Euclidean distance between
each track and the detection and comparing it with the maximum distance that a human
person running could go in the time elapsed since the last update of the track. Because of
gating, in each received
Once the gating is done, in this matching phase, for the remaining

Similarly to each cost matrix, the more a detection
The fusion node computes the linear assignment corresponding to this cost matrix with the Jonker–Volgenant algorithm. 36 This assignment determines an optimal track-to-detection assignment (an injective function)

that minimizes:
Finally, the updated set of tracks, which is also shaped as a
“User recognition” section presented how each

Diagram of the dataflow between the fusion node and the different
Configuration of multiple PPLP s and
PPLM s
The user awareness described in this article can be adapted to different sensors,
hardware configurations, and computing capabilities. A set of

Multimodal fusion using all implemented
Experimental results
In this section, we present the robotic platform employed in the experiments in “Robotic platform” section and the acquisition of a realistic data set in “RoboticsLab People Dataset (RLPD): A realistic HRI-based people data set” section. The data are used to test the performance of the presented algorithms for user detection (see “Benchmarking of user detection algorithms with RLPD” section) and user recognition (see “Benchmarking of user recognition algorithms with RLPD” section). “Architecture output: Sample data based on multimodal fusion” section presents a sample output of the architecture and, finally, the performance of the overall user awareness architecture is evaluated in “Benchmarking of multimodal fusion configurations with RLPD” section.
Robotic platform
Our tests have been run using the Kinect camera integrated in the social robot Mini developed at our lab (see Figure 5 for more details about its sensors and actuators).

Main components of the social robot Mini.
Although the computational needs of the architecture would allow performing the whole operation entirely on the robot, we traditionally use a distributed architecture that prevents overloading the robot, which could affect its reactivity. In the evaluation described in this article, two computers are used: the embedded computer of the robot (acting as a master) and a remote desktop computer for computation. The former is an Intel i5 quadcore CPU @ 3.30 GHz and embeds the driver for the sensors and a depth imaging device. The latter is an AMD Athlon 64 Dual Core @ 2.7 GHz and contains the user awareness architectures: PPLPs, PPLMs, and the fusion node. Both are on the same Ethernet network, which alleviates the issues due to network performance. During the development and testing phases, the architecture proposed in the article and the network were fast enough to process the data at the rate of the data set, which is roughly 5 Hz.
RoboticsLab People Dataset (RLPD): A realistic HRI-based people data set
There are academic data sets adapted for the evaluation of people detection, recognition, and tracking, such as DGait 37 and Kinect Tracking Precision (KTP). 38 They allow a faithful measurement of the performance of the user awareness system, make the comparison with other similar systems easier, and ensure that the measurements can be repeated in the same context.
However, even though our system was designed in a fashion as generic as possible, it has been tested in a social robot. For this reason, we decided to acquire real data from the robot Mini, and with users that fit best the target audience: people from Spain, with a variety of genders and shapes. In addition, the actors do not wander randomly on the stage, as they do in the KTP data set: We designed scenarios that mimic a realistic HRI situation in which one or several users interact naturally with the robot: addressing the robot, using gestures, respecting the proxemics distance, and so on.
Data set summary
The data set represents three users interacting with a robot that integrates a Kinect camera. They move on the stage according to a script that was previously defined and is made of three scenarios of increasing difficulty. Their motion is challenging: They get in and out of the room, there are occlusions and partial views.
The data set is meaningful if and only if the real positions of the users are known. We first thought of using markers, such as ARToolkit markers. 39 However, the imperfect detections could not guarantee an accurate ground truth concerning the users’ positions in each frame. For this reason, in each of the 600+ frames, the ground truth user positions have been manually labeled.
This data set is licensed under the terms of the GNU General Public License version 2 as published by the Free Software Foundation and freely available for downloading along with images and videos (https://sites.google.com/site/rameyarnaud/research/phd/roboticslab-people-dataset).
Input frames
Each frame is labeled with a time stamp. The time stamp is expressed in milliseconds elapsed after the beginning of the recording, using six digits with leading zeros. For instance, frame 065514 was recorded 1 min and 5 s after the beginning of the recording. In total, we have 647 frames for 133 s (2 min 15 s roughly), which is, on average, 5 frames per second.
Acquired data
For each frame, we have four images and one data file: (i) The RGB image (“XXXXX_rgb.png”, lossy JPG compression, quality: 85); (ii) The depth image (“XXXXX_depth.png” and “XXXXX_depth_params.yaml”, lossy affine depth-as-PNG compression); (iii) The user mask obtained as output of the Kinect API, called NiTE. This image stream is synchronized with the RGB and depth streams of the Kinect and indicates, for each pixel of each frame, whether this pixel belongs to a detected user using the NiTE algorithm presented in “The integration of the user detection algorithms” section (“XXXXX_user_mask_illus.png”, lossless PNG compression); and (iv) the hand-labeled ground truth user mask. This image stream has the same purpose as the NiTE user masks, but it has been manually annotated, so that it contains the exact ground truth concerning the position of each user in each depth image (“XXXXX_ground_truth_user.png”, lossless PNG compression).
The data set also supplies the camera info of the depth imaging device. It is made up of the camera’s intrinsic parameters and allows converting 2-D pixels into 3-D points. The calibrations for both the RGB and depth (infrared) cameras are available.
Data set annotation
The ground truth user positions have been labeled manually in each frame, using both RGB and depth contents to create a “perfect” user mask. We developed a Graphical User Interface shaped as a raster graphics editor that allows the manual labeling of each pixel of a depth image.
Like the data set, these tools are licensed under the terms of the GNU General Public License version 2 as published by the Free Software Foundation, and freely available for downloading at the same URL.
Data set analysis
The data set was recorded on July 2014. It is made of about 650 frame acquisitions, each of them consisting of four images, that is, about 2600 images. The data set is roughly 65 megabytes. These images can be easily imported into any programming language, such as C++ or Matlab. The complete data set takes 133 s and the total number of frames is 647, and 548 of them have several PPs. Some samples are visible in Figure 6.

Some samples of the RLPD. From left to right: column 1: the RGB image; column 2: the depth image; column 3: the manually labeled user map; and column 4: the NiTE (Kinect API) user map. The data set has some challenging features: partial (second row) or complete occlusions (third row), user not fully visible (fourth row). Note how the manual color indexing of the users is consistent (third column): the same user always corresponds to the same color. On the other hand, the NiTE algorithm performs swaps and creates new users, or even merges users (fourth column).
Benchmarking of user detection algorithms with RLPD
We benchmarked the different user detection algorithms on this new data set. These
algorithms were all wrapped with a common interface,
Benchmark results for the

We calculated the accuracy and the hit rate of each algorithm. Accuracy refers to the percentage of correctly evaluated frames (see equation (1)). The hit rate measures the number of people successfully detected considering the frames that certainly contain at least one person (see equation (2))


We can see first that no detector has a very good performance by itself. As explained
before, the RLPD has a high level of complexity: The occlusions are frequent, the users
are sometimes partially shown in the images, and in general, they are somewhat far away
from the camera. This underlines the fact the we cannot only use one
The NiTE
In conclusion, concerning the
Benchmarking of user recognition algorithms with RLPD
In this section, we assess the performance of each user recognition algorithm, structured
as a
Benchmark results of each
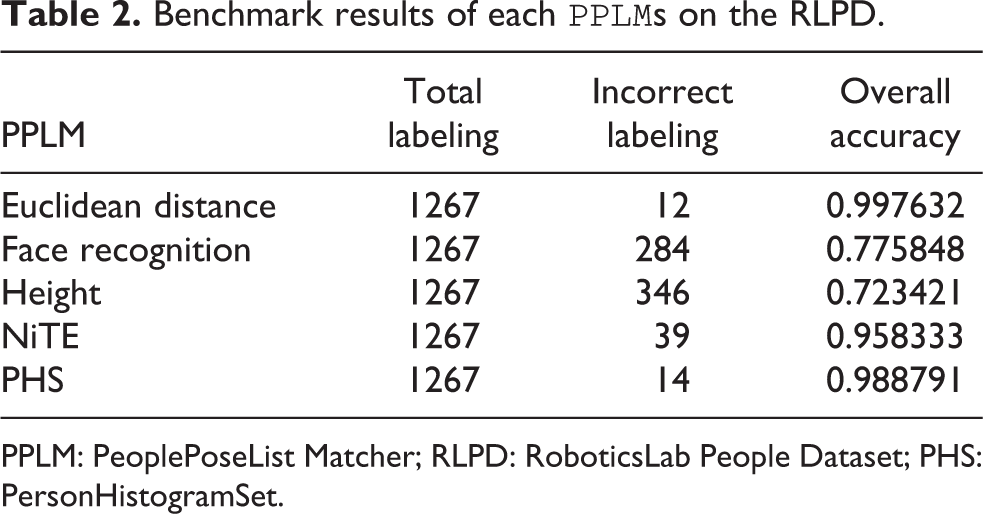
PPLM: PeoplePoseList Matcher; RLPD: RoboticsLab People Dataset; PHS: PersonHistogramSet.
We see that the Euclidean distance
The face recognition–based
The height-based
The performance of the NiTE
Finally, the PHS
Architecture output: Sample data based on multimodal fusion
A sample

A sample PeoplePoseList message.

Sample pictures of our user awareness architecture with the RLPD. RLPD: RoboticsLab People Dataset.
Note on user labeling
Depending on the
Benchmarking of multimodal fusion configurations with RLPD
The performance of the data fusion node according to its set of
Benchmark results for different configurations of
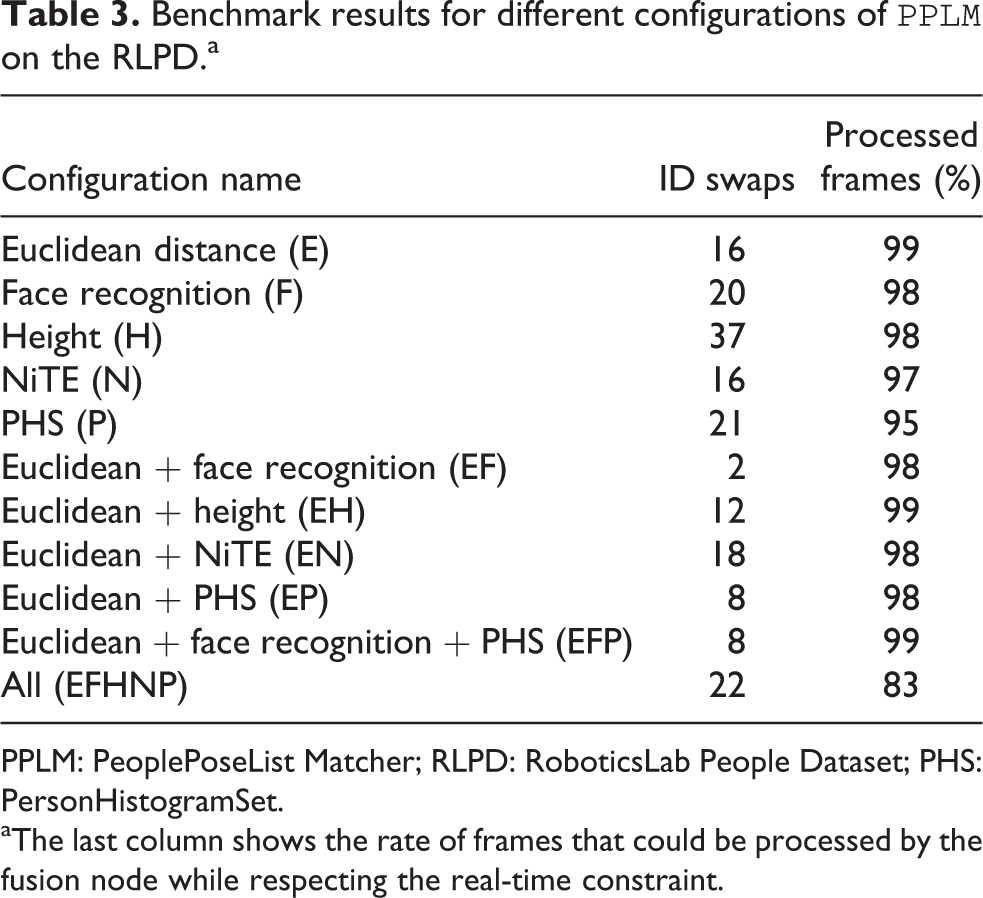
PPLM: PeoplePoseList Matcher; RLPD: RoboticsLab People Dataset; PHS: PersonHistogramSet.
aThe last column shows the rate of frames that could be processed by the fusion node while respecting the real-time constraint.
First, the table confirms the conclusions of the benchmarking of the
Second, the table also assesses the performance of the configurations relying on several
When we increase the number of
Indeed, in the challenging parts of the data set, while one of the trackers correctly
matches the current users to the tracks, the others get mixed up: The rate of incorrect
hints given to the fusion node increases, and the final result is erroneous. Furthermore, an
increased number of
Conclusions
In this article, we tackled the challenge of giving user awareness to social robots. To do
so, the problem was split into three subproblems: user detection, user recognition, and user
tracking and mapping. A common data structure was designed, called
The strength of the proposed architecture lies in its modularity: It is easy to add or remove modules, and more generally to design a configuration that fits both the robot’s hardware and software requirements, as well as the properties of its environment. This modularity allows the use of the architecture on a variety of platforms that differ in both their hardware capabilities and the way in which they interact with users.
A specific data set of images was created, called RLPD, which corresponds to scenarios of user detection and recognition in a realistic HRI context, acquired on a real robotic platform. The performance of all modules was assessed by using this data set. We also demonstrated that the performance of the mapping is improved by using several algorithms in parallel.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research leading to these results has received funding from several projects: from the project called: Development of social robots to help seniors with cognitive impairment—ROBSEN, funded by the Ministerio de Economía y Competitividad (DPI2014-57684-R); and from the RoboCity2030-III-CM project (S2013/MIT-2748), funded by Programas de Actividades I+D en la Comunidad de Madrid and cofunded by Structural Funds of the EU.