
Abstract
Transparent objects are ubiquitous in everyday life, but how to detect them is full of challenges. Transparent objects hardly reflect light, and they usually transmit the appearance of their surroundings, making it difficult to distinguish them from their surroundings. Existing methods usually use only RGB (Red Green Blue) images as input, ignoring the role of depth maps in transparent object detection. In this article, we try to improve the detection performance of transparent objects by fusing RGB and depth information. Specifically, we propose a multimodal fusion network that fuses RGB and depth modalities in a complementary way. Moreover, extensive experiments and ablation studies on the RGB-D (RGB-Depth) transparent object dataset demonstrate the excellent performance of our method.
Introduction
Transparent objects are widely found in daily life, such as mineral water bottles, cups, measuring cylinders, test tubes, etc. Detecting these objects is very important in many practical applications. For example, when intelligent robots are grasping transparent objects such as test tubes and mineral water bottles, they first need to sense these objects. In addition, when intelligent robots are performing navigation and tracking tasks, they need to avoid crashing into transparent objects such as glass doors, windows, and walls. However, the difficulty of distinguishing transparent objects from the background makes detecting and segmenting transparent objects challenging.
There are few studies dedicated to transparent object detection and segmentation, and the mainstream methods for transparent object detection and segmentation are based on RGB information,1,2 and they detect and segment transparent objects by their boundary cues. However, inaccurate results may occur when the light is dim or the boundaries of transparent objects are not clear.
Due to the unique visual properties of transparent objects, the depth map acquired by the depth camera has a depth missing, as shown in Figure 1. However, some recent studies4,5 have shown that the depth discontinuity in the depth map of transparent objects makes the transparent objects have different semantic features from the background. From this perspective, we address the limitations of RGB-based transparent object detection and segmentation methods by fusing RGB features and depth features.

Original depth maps of transparent object, from the TODD 3 dataset.
There have been a number of different proposals for the fusion of RGB and depth maps.6–9 For example, fusing RGB and depth information via BBS-Net, 6 calibrating depth maps with RGB maps and fusing them via a depth calibration module and a cross-reference module, 7 and augmenting RGB features and fusing them with depth maps via the DSA2F framework. 8 However, there are still some challenges in the existing RGB-D fusion methods. The first challenge is the complementary fusion of multimodal features. RGB images contain color and texture information, while depth maps contain the distance between objects and shape of objects. The second challenge is the effective fusion of multi-level features. Low-level features provide rich details that facilitate refinement of segmentation boundaries but contain inherent noise. High-level features contain global information, which is good for object localization, but lack detail information.
To solve the above problem, we propose a new multimodal feature fusion network (MFFNet) to obtain better performance for transparent object detection. As shown in Figure 2, our MFFNet uses an encoding–decoding network architecture
10
with ResNet
11
as backbone in the encoder. And a new feature fusion enhancement module (FFEM) is developed to fuse and enhance RGB and depth features. Our main contributions are summarized as follows:
We designed a dual-stream encoding–decoding framework for MFFNet to handle the detection of common transparent objects. We introduce FFEM to fuse RGB features and depth features in a complementary way. Comparisons with other methods on publicly available datasets demonstrate the excellent performance of our method.

The overall architecture of MFFNet.
The rest of this article is structured as follows. The second section reviews related work. The third section describes our network in detail. The fourth section gives the experimental results and discussion. The last section gives a summary of the work and the outlook.
Related work
Semantic segmentation
Since Long et al. 12 proposed FCN in 2014, most of the current state-of-the-art semantic segmentation methods are based on deep learning approaches. They changed the then classification networks AlexNet, 13 VGG-Net, 14 and GoogleNet 15 to fully convolutional networks for segmentation tasks. Ronneberger et al. 16 proposed to solve the semantic segmentation problem in biomedical field by using U-Net network with skip connection. Badrinarayanan et al. 10 proposed SegNet to introduce the encoding–decoding architecture to semantic segmentation for the first time. The Google team released four versions of the DeepLab series17–20 from 2015 to 2018. However, all the above algorithms are trained and tested based on RGB images.
With the increasing use of depth cameras and thermal imaging cameras, various semantic segmentation algorithms based on RGB-D and RGB-T (RGB-Thermal) have been proposed. Deng et al. 21 proposed a two-stage FEANet with feature enhancement module to enhance features and fuse RGB and thermal information in a complementary form. Sun et al. 22 proposed a RTFNet that fuses RGB and thermal information and designed a new decoder to restore the resolution. Zhang et al. 23 proposed a semantic segmentation method that first reduces modal differences and then fuses them. Hu et al. 24 proposed ACNet to complementarily fuse RGB and depth information by considering the difference of RGB and depth feature distributions. Jiang et al. 25 proposed an RGB-D residual encoding–decoding structure RedNet and solved the vanishing gradient problem.
Transparent object detection
Xie et al. 1 collected Trans10 K, the large-scale transparent object dataset, and proposed a network TransLab that uses boundary cues to improve the segmentation performance of transparent objects. Later, Trans10K-v2 dataset 26 was proposed by extending Trans10 K, 1 and Trans2Seg, a transparent object segmentation network based on Transformer was proposed. DeepLabV3+ 20 with DRN-D-54 as backbone was used in ClearGrasp 27 for segmentation of transparent objects. Mei et al. 28 constructed a large-scale glass detection dataset GOD and proposed a glass detection network GDNet. He et al. 2 solved the segmentation problem of glass-like objects by modeling their boundaries with graph convolutional networks. Lin et al. 5 observed that the depth image generated by the depth camera produces gaps on the surface of transparent objects and used it as a supplement to the RGB image for glass object surface detection. Sun et al. 29 collected TROSD, a large-scale dataset containing transparent and reflective objects, and proposed TROSNet, a transparent and reflective object segmentation network. Zhang et al. 30 proposed Trans4Trans, a lightweight transparent object segmentation network that can be easily deployed to wearable devices.
Proposed method
In this section, we introduce the overall architecture of MFFNet, which comprises two feature extraction networks, an FFEM and an output decoding network. To fully fuse the complementary features from RGB and depth features, we propose FFEM to fuse and enhance multimodal features to achieve good performance in transparent object detection. We describe in detail the FFEM that fuses RGB features and depth features.
Overall architecture
Figure 2 shows the overall framework of our proposed RGB-D transparent object detection, which consists of three parts: a dual-stream encoder, a FFEM and a decoder. The dual-stream encoder extracts different levels of features
Encoder
In our proposed MFFNet, multi-level RGB and depth map features are extracted in the dual-stream encoder, and the process is shown in Figure 3. The figure shows that the second column extracts low-level features that contain detailed edges, colors, textures, and so on. And the model begins to extract higher-level features that increasingly contain rich semantic information as the depth of the network increases. Specifically, we use ResNet-50 11 as the backbone for RGB and depth map feature extraction. Since the output of the first stage (Layer0) contains more raw noise, we only use the output of the last four stages (Layer1, Layer2, Layer3, Layer4). We add an FFEM that we designed after the output of each stage to fuse and enhance multimodal features. The enhanced RGB features and depth features are used as inputs for the next stage. ResNet-50 11 is designed for three-channel RGB image feature extraction, while the depth map is a single-channel map. Therefore, in the depth feature extraction network, we modify the number of input channels of the first convolution to one, so that it is applicable for a single-channel depth map. Finally, Layer4 is modified to atrous convolution 20 to maintain the same output dimension as Layer3, and the final pooling layer and full connection layer of ResNet-50 11 are deleted.
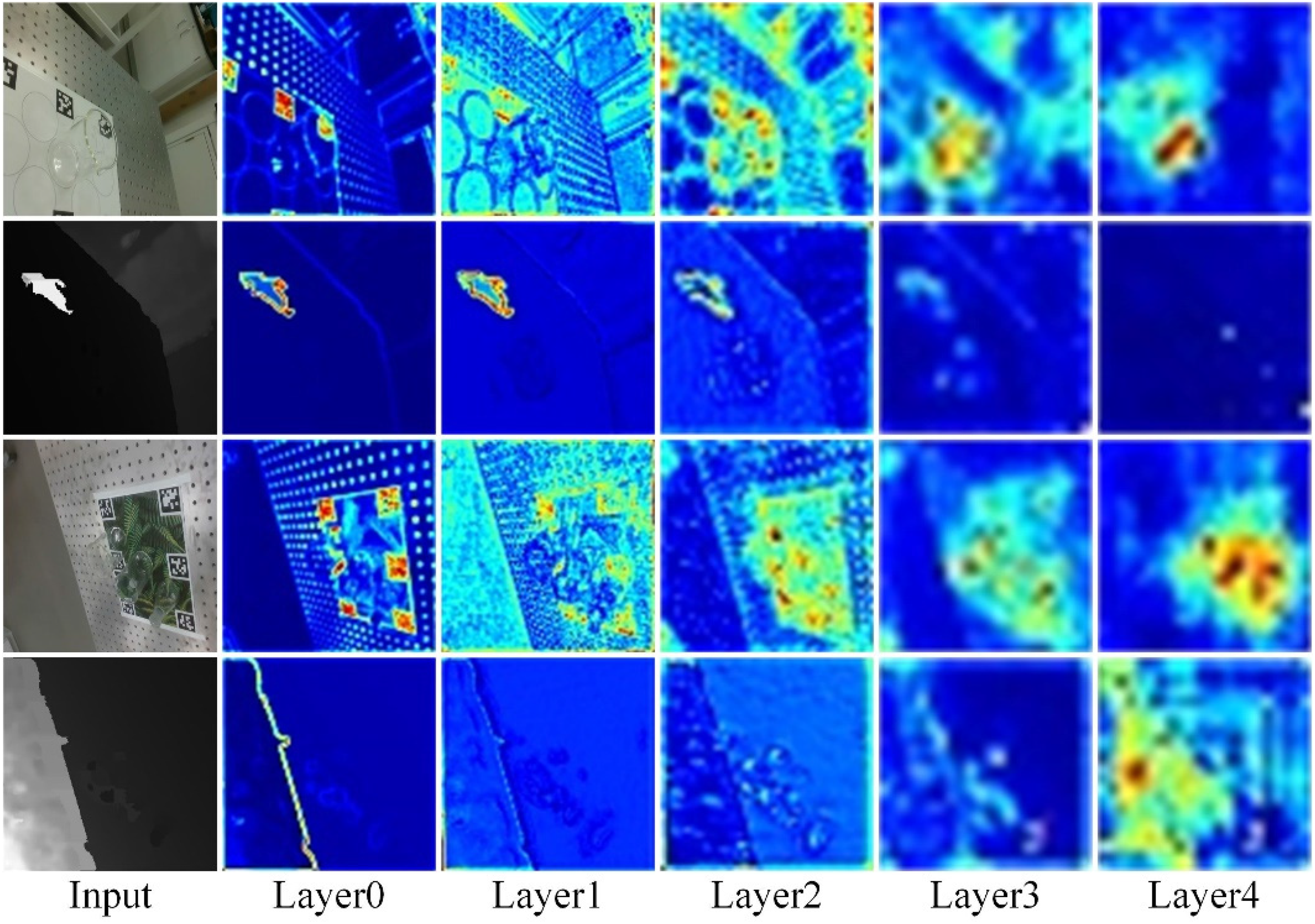
RGB images and depth maps for different level features.
Feature fusion enhance module
How the complementary fusion of RGB features and depth features is our focus. RGB and depth map have color texture information and position information. Some differences that are difficult to find in RGB image can be easily found in depth map. The depth map is sent to the dual-stream encoder along with the RGB image to generate multi-level features
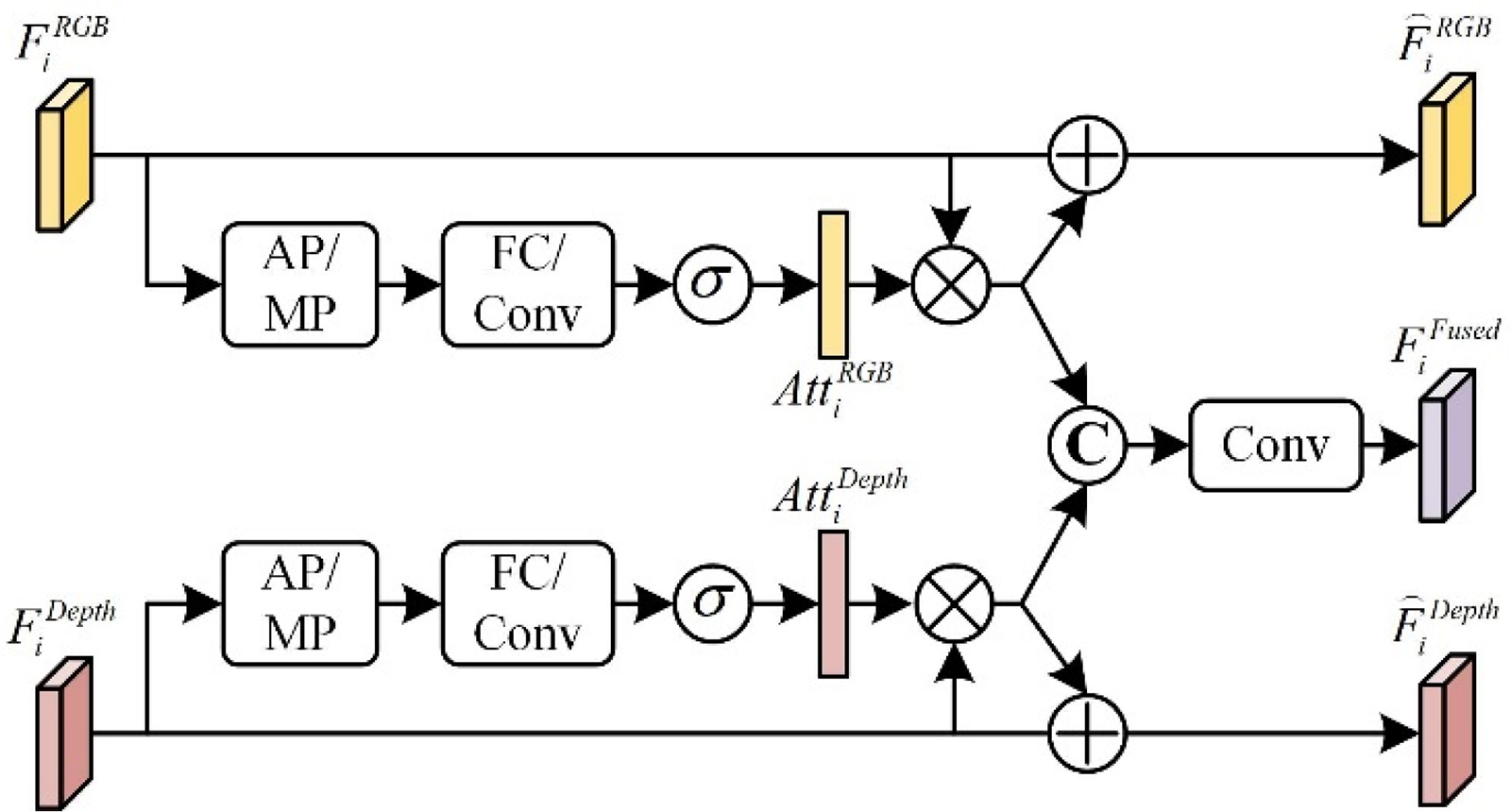
The architecture of FFEM.
We designed the FFEM to extract more detailed and complementary features from the input RGB image and the depth map. More specifically, the output features




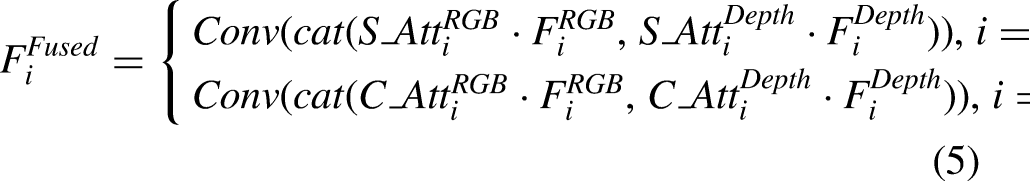
Decoder
After fusing the multi-level RGB features and depth features from the dual-stream encoder, the multi-level fused features are fed to the decoder to restore the resolution to the input image. Since high-level features help to localize transparent objects and low-level features help to refine the boundaries of transparent objects, our decoder is designed to efficiently utilize multi-level features for mask refinement.
Specifically, we utilize all levels of fused features



Loss functions
To obtain good performance of our network, we used the SoftCrossEntropy Loss
21
and Dice Loss
31
to supervise the training of transparent object detection and weighted them to obtain the final loss function. SoftCrossEntropy Loss in the case of binary classification can be written as:
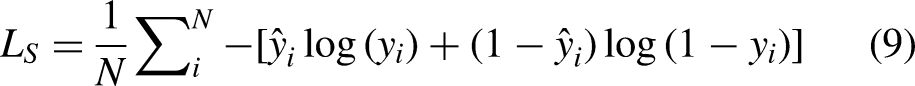
Dice Loss is calculated as follows:

The total loss function is:

Experimental verification
Datasets
To evaluate the performance of our proposed MFFNet, we chose the RGB-D dataset of transparent objects in TODD 3 for validation. The TODD dataset contains a total of 14,659 images, with 10,302 images in the training set and 4357 images in the validation and test sets according to the official classification.
Evaluation metrics
For a comprehensive evaluation, we used not only the Intersection-over-Union (IoU), a common metric for semantic segmentation, but also the F-measure, mean absolute error (MAE), and balance error rate (BER), common metrics for saliency target detection and shadow detection. In calculating the IoU, we only calculate the IoU values of transparent objects and ignore the background. The IoU is calculated as:
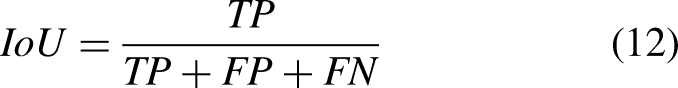
MAE is calculated as follows:

BER is calculated as follows:

The F-measure is calculated as:

Implementation details
We implemented MFFNet with PyTorch
33
and trained it using an RTX 3060 GPU with 12GB memory starting from pre-trained weights on ImageNet. All images used for training and testing are set to 352 × 352. Throughout the entire training process, the initial learning rate is 1 × 10−4, the optimizer is chosen as the Adam optimizer, the learning rate decreases to 0.1 times the original after every 7 epochs, and the Batch Size is set to 8. Empirically the weight
Comparative experiments
Our proposed method is compared with other semantic segmentation, saliency target detection, and transparent object detection/segmentation methods, as shown in Table 1. We chose DeepLabv3+ (ResNet50), 20 DeepLabv3+ (Xception), 20 DeepLabv3+ (MobileNet), 20 U-Net, 16 FCN, 12 ICNet, 34 CSNet, 35 PGSNet, 32 GDNet 28 methods. We retrained each model on the training set of the TODD dataset and evaluated it on the test set. To be fair, we set the size of all images used for training and testing to 352 × 352.
Quantitative comparison of results on test datasets using IoU, MAE, BER, and F β .

Table 1 shows quantitative comparisons with other methods. Compared with other methods, our method has obtained optimal results in IoU, MAE, BER, and F β (see bold values). And some comparison results with other methods are visualized, as shown in Figure 5. It can be seen from the figure that our method obtains a clearer boundary and a more complete mask.

Visual comparison of MFFNet to other methods.
Ablation study
First, to verify the role of depth information in transparent object detection, we conducted an ablation study of the input RGB and depth information. Table 2 compares the results for different modal inputs: (1) MFFNet-R means that we use the RGB image as the input to the RGB channel and the all-zero tensor as the input to the depth channel; (2) MFFNet-D means that we use the depth map as the input to the depth channel and the all-zero tensor as the input to the RGB channel.
Comparison of different input modes on the test datasets.

From the results in Table 2, we can find that the depth information is helpful for the detection of transparent objects. Figure 6 visualizes some comparison results.
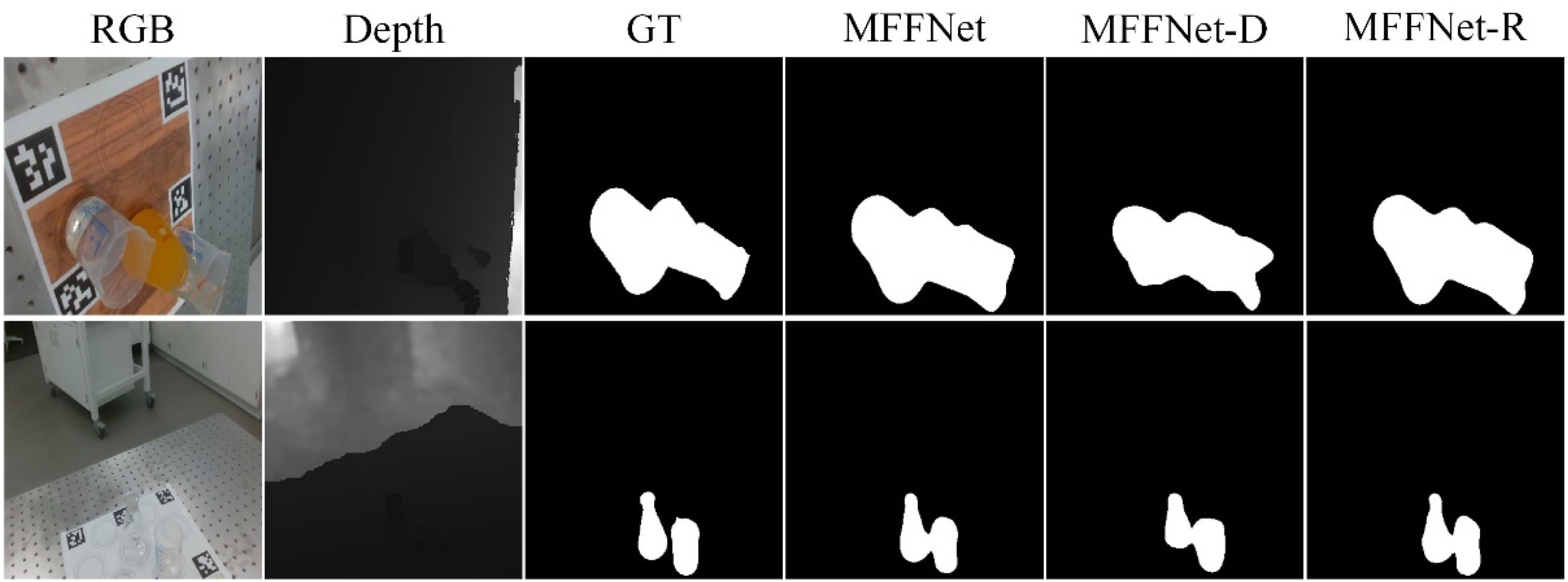
A visual example of ablation study of the input RGB and depth information.
Finally, we performed an ablation study for each module to verify its effectiveness. Table 3 compares the results of different modules: (1) Baseline means that FFEM is deleted, and for RGB features and depth features, we directly fuse them by adding, and for encoder, we only use
Comparison of different modules on the test datasets.

The results in Table 3 show that our final model exhibits optimal performance on all four metrics. Figure 7 visualizes some of the comparison results, and we can see that both FFEM and encoder we designed can help us improve detection performance.

A visual example of ablation study of different modules.
Robot grasping
The performance of MFFNet in robot operation can be verified by combining MFFNet with a robot grasping task. After detecting a transparent object, an end-to-end network was used to directly regress the 6-degrees-of-freedom grasping pose. Finally, a panda robot arm was used to perform the transparent object-grasping task, as shown in Figure 8.

Robot grasping process.
Conclusion
In this thesis, we propose a multimodal fusion framework for transparent object detection. The framework employs a dual-stream encoder–decoder-based framework, and the three components: the feature extraction backbone network, the FFEM, and the decoder are described step by step. Comparison with other deep learning-based methods is performed on the challenging RGB-D transparent object dataset. The IoU of our method is improved by 5% compared to the glass detection method GDNet and by 3.9% compared to PGSNet. Compared to the semantic segmentation method DeepLabv3+, the IoU value of our method is improved by 1.36%. However, the current RGB-D transparent object public dataset only includes some simple transparent objects and a single scene, and we will collect a new large-scale RGB-D transparent object dataset as future work.
Footnotes
Authors contributions
Li Zhu and Tuanjie Li proposed the main idea of this article, and Li Zhu also wrote the programming related to multimodal feature fusion network. Yuming Ning debugs the relevant programs under the PyTorch framework. Yan Zhang revised the whole manuscript and gave detailed suggestions related to the experiments. All persons who have made substantial contributions to the work reported in the manuscript, including those who provided editing and writing assistance.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the National Natural Science Foundation of China under Grant 51775403, the Proof-of-Concept Foundation of Xidian University Hangzhou Institute of Technology under Grant GNYZ2023QC0404, and the Fundamental Research Funds for the Central Universities under Grant YJSJ24001.