
Abstract
The real-time calculations of the positioning error, error correction, and state analysis have always been a difficult challenge in the process of autonomous positioning. In order to solve this problem, a simple depth imaging equipment (Kinect) is used, and a particle filter based on three-frame subtraction to capture the end-effector’s motion is proposed in this article. Further, a back-propagation neural network is adopted to recognize targets. The point cloud library technology is used to collect the space coordinates of the end-effector and target. Finally, a three-dimensional mesh simplification algorithm based on the density analysis and average distance between points is proposed to carry out data compression. Accordingly, the target point cloud is fitted quickly. The experiments conducted in the article demonstrate that the proposed algorithm can detect and track the end-effector in real time. The recognition rate of 99% is achieved for a cylindrical object. The geometric center of all particles is regarded as the end-effector’s center. Furthermore, the gradual convergence of the end-effector center to the target centroid shows that the autonomous positioning is successful. Compared to traditional algorithms, both moving the end-effector and a stationary object can be extracted from image frames using a thesis. The thesis presents a simple and convenient positioning method, which adjusts the motion of the manipulator according to the error between the end-effector’s center and target centroid. The computational complexity is reduced and the camera calibration is eliminated.
Introduction
In computer vision, 3-D reconstruction refers to the process of 3-D scene restoration based on single view or multiple view images. There are four kinds of reconstruction methods: binocular stereo vision, sequential imaging, photometric stereo, and motion view analysis. The binocular stereo method is suitable for larger objects. The sequential imaging method is suitable for small objects. The photometric stereo and motion view analysis methods are suitable for large and complex scene reconstruction. Because single video information is incomplete, reconstruction based on it needs to use empirical knowledge. Multi-view reconstruction is relatively easy. It involves the calculation of the pose relation between the image coordinate frame and the world coordinate frame. Then, 3-D information is reconstructed using the plurality of 2-D images. But the computational complexity and cost is usually high. For 3-D reconstruction using simple depth image apparatus, there are a few studies showing certain results. Izadi et al. 1 propose a new 3-D reconstruction technology based on Microsoft Kinect. However, due to the limitation of the time of flight (TOF) technology, the accuracy of surface texture information is not high. The purpose of 3-D reconstruction is to provide the real-time monitoring of the end-effector positioning process and error. At the same time, it can lay a foundation for the debugging and analysis of the manipulator autonomy job task. Ma et al. 2 propose a gradual human reconstruction method based on individual Kinect. Body feature points are positioned in depth video frames combined with feature point detection and an error correction processing algorithm. The human body model is obtained by estimating the body size. Guo and Gao 3 propose a robust automatic unmanned aerial vehicle (UAV) image reconstruction method using a batch framework. Li et al. 4 find a multi-view reconstruction method from the perspective of motion visual analysis. A sparse point cloud and initial mesh are built using each view bias model. Lv et al. 5 propose a Bayesian network model that describes body joint spatial relationships and dynamic characteristics. A golf swing process 3-D reconstruction system is built based on the similarities of swing movements. The problem of limb occlusion is effectively solved using an easy depth imaging device to capture motions. Lin et al. 6 utilize an adaptive window stereo matching reconstruction method based on the integral gray variance and integral gradient variance. The image texture quality is determined according to the integral variance size. Related calculations are performed if the variance is greater than a preset threshold. The method needs to traverse the whole image to obtain the dense disparity map. Izadi et al. 7 gather point cloud data using a single mobile and four fixed Kinect devices. The point cloud alignment and fitting problems are solved using iterative closest points. Kahl and Hartley 8 convert 3-D reconstruction into a norm minimization problem. A closure approximate solution is derived using second-order cone programming. In the case of known camera rotation, the problem can be solved simultaneously for the shift and space position of the camera. Carbone and Gomez-Bravo 9 introduce a method for the vision-based motion control of robot manipulators. A dynamic look-and-move system architecture is discussed, as a robot-vision system, which is closed at the task level. Kanatani et al. 10 describe techniques for 3-D reconstruction from multiple images and summarize mathematical theories of statistical error analysis for general geometric estimation problems. Gruen and Thomas 11 address the question of where and how an imaged object is located in the object space. Basic component algorithms, such as image matching, segmentation, feature extraction, and so on, are favorably supported and constrained by the use of orientation parameters.
In this article, the target object is determined using back-propagation (BP) neural network recognition. The end-effector is extracted using motion state estimation based on a particle filter (PF). Then, the target centroid (TC) and end-effector center (EEC) are extracted. The spatial coordinates of the EEC and TC are calculated using coordinate frame transforming. The errors between EEC and TC are obtained. The error is mapped to the joint angle by inverse kinematics modeling. Then, the motion of the manipulator is adjusted using forward kinematics modeling. Therefore, autonomous positioning is achieved. The general flowchart is shown in Figure 1. The algorithm effectiveness can be verified using fast surface fitting. General flowchart.
End-effector motion estimation
The position of the EEC can be obtained by motion estimation. The image coordinates of this center point can be transformed into the space coordinates according to hand-eye calibration. Then, an inverse kinematics model is used to transform the space coordinates of the center point into the joint angles. Accordingly, the end-effector is controlled to reach the target position.
The moving object and static background are separated from frame-stream images using the three-frame differencing method proposed by Martin and Robert. 12 The consecutive three-frame differencing method can better deal with the environmental noise, such as the weather, light, shadows, and messy background interference. It is shown to be better than the two-adjacent differencing method in double-shadow treatment proposed by Andre et al. 13 The expressions are as follows

where

where

Then, the morphology erosion and the dilation are applied to the binary image to remove holes.
The motion state is estimated after the moving end-effector is extracted. So, it is convenient to calculate the position error between the end-effector and target object. The motion of the end-effector is nonlinear in video frames. The PF state estimation is adopted in the study by Suman et al.
14
A series of random particle sets

where xt denotes the end-effector’s position state at time t, and y0:t denotes the observation sequence {y0,y1,…,yt} from the beginning time to the current time t. {y0,y1,…,yt} corresponds to the position distribution sequence {x0,x1,…,xt}. The state equation describes the state transition probability
In addition, assume that the target state follows a Markov process, namely, the current state depends only on the previous state. When the conditional probability

where

In equation (5),

When the number of particle sets is large enough, these particles are set to replace the true posterior probability distribution. The end-effector’s posterior probability distribution

where

where
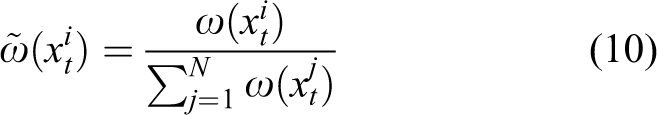
So,
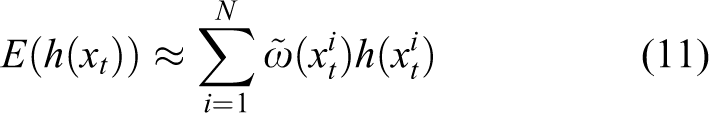
When the sampling data
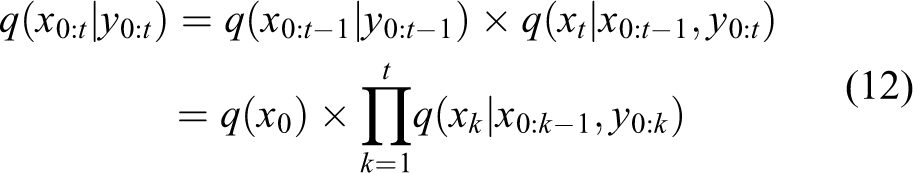
The recursive calculation of weight

Object recognition
Image preprocessing
This section describes preprocessing based on Kinect RGB images. Target recognition is illustrated by an example using a cylindrical target object (CTO). The end-effector and CTO appear in the same video. First, image gray processing is carried out to convert color images to gray ones in order to reduce computation. The gray image gradation is 0–255. The grayscale method, Gray = 0.114B+0.587G+0.299R, is used, as in the study by Refael and Richard. 15
Second, image median filtering is carried out. It is a type of nonlinear smoothing methods. Chang et al. 16 find that it cannot blur edges while suppressing random noise. The gray values of pixels are sorted in a sliding window. The original gray value of each pixel in the window center is substituted by the median.
Third, mathematical morphology operations are carried out. Dilation and erosion operations are used in the study by Chang et al.
17
They are widely used in edge detection, image segmentation, image thinning, noise filtering, and so on. Assume that Morphology dilation Morphology erosion


Then, the weighted fusion between the input image and its “canny” operator detection is conducted. The threshold segmentation of the fusion image is carried out. Image segmentation is a basis for determining feature parameters. The whole contour of the object is obtained after image segmentation. An example is demonstrated in Figure 2. The shaded area represents the boundary. Finally, this should make the system possess capable of automatically extracting geometric features. These features should stay invariant when the image is transformed by translation, rotation, twisting, scaling, and so on. Calculation example of feature parameters.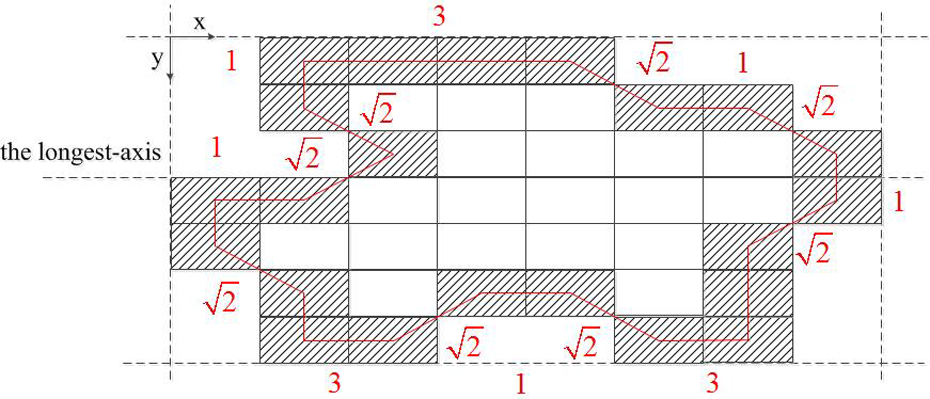
There are two kinds of CTO feature parameters: edge contour features and shape parameters. The parameters of contour points are edge contour features. Shape parameters include the perimeter, area, longest axis, azimuth, boundary matrix, and shape coefficient. (I) Contour points represent the required number of pixels which can outline the contour. The number of contour points is 22 in Figure 2. (II) The perimeter represents the contour length of the outer boundary. It can be calculated as the sum of the distances between two adjacent pixels on the outer boundary. Assume that the distance between two edge pixels sharing a side is 1, otherwise it is (III) The area can be represented as the number of pixels in the target region. So, the area is 41 in Figure 2. (IV) The longest axis denotes the maximum extension length of the target region, that is, the connection line of the maximum distance between two pixel points on the outer boundary. So, the longest axis is 8 in Figure 2. (V) The azimuth represents the angle between the longest axis and the x-axis in the target region. So, the azimuth is 0 in Figure 2. (VI) The boundary matrix denotes the minimum matrix encompassing the target region. It is also the intuitive expression of the flat level of the target region. It is composed of four outer boundary tangents. Two of them are parallel to the longest axis, and the other two are perpendicular to the longest axis. So, in Figure 2, the boundary matrix is

(VII) The shape coefficient denotes the ratio of the area to the square of the perimeter. So, the shape coefficient is 0.0639 in Figure 2.
Neural network recognition
This section describes recognition based on Kinect RGB images. A BP neural network learning algorithm is used in this article. This network can learn and store a large amount of input–output mappings. It is also a mathematical equation that does not use the description of these mappings in advance. Its learning rule is the gradient descent method. The mean square error (MSE) is minimized by adjusting the network weights and thresholds continuously. The network topology includes the input layer, the hidden layer, and the output layer.
Feature vectors are extracted as a training sample. The neural network is used as a classifier instead of the Euclidean distance method to implement target recognition.
The design of the input and output layers is as follows. The number of nodes is 7 in the input layer. The elements of the input vector are {contour points, perimeter, area, longest axis, azimuth, boundary matrix, and shape coefficients}. The number of nodes is 3 in the output layer. The elements of the output vector are {cylinder, square, and spherical}. The normalized values of the output are 0.1, 0.2 and 1, respectively. The design of the hidden layer is as follows: There are two hidden layers which include a logarithmic characteristic function and “purelin” function. The number of nodes is 20 in the first hidden layer. The number of nodes is 3 in the second hidden layer. A linear excitation function is used in the output layer. The number of hidden layers is related to the number of neurons and specific issues. At present, it is difficult to provide an accurate function to describe this relation. Experiments show that the accuracy of the network does not necessarily increase when the number of hidden layers and neurons is increased. The initial number of the hidden layers can be selected as

where m denotes the number of neurons in the input layer, n denotes the number of neurons in the output layer, and a denotes an integer from 1 to 10. Here, n′ is set to be 15.
The sample set is collected from a shooting scene of Kinect. In Figure 3, there are cylindrical objects, square objects, and spherical objects. There are 30 cylindrical objects (Figure 3(a)), 10 square objects (Figure 3(b)), and 10 spherical objects (Figure 3(c)). For each target object, there are 20 different viewing angles (the schematic diagram is shown in Figure 3(d) to (f)). So, the numbers of cylindrical objects, square objects, and spherical objects are 600, 200 and 200, respectively, in the sample set. In Figure 3(g), the edge contour is extracted. For the number of samples, there is no exact formula in any references. But, it is not the case where more is better. There are 970 samples in the study by Shi et al.
18
and 150 samples in the study by Liu and You.
19
In addition, Hao and Jiang
20
prove that the sample size 1000 seems reasonable according to the sample choice method. Image preprocessing. (a) 30 kinds of cylindrical objects. (b) 10 kinds of square objects. (c) 10 kinds of spherical objects. (d) RGB images and binary segmentation of cylindrical objects from different perspectives. (e) RGB images and binary segmentation of square objects from different perspectives. (f) RGB images and binary segmentation of spherical objects from different perspectives. (g) Edge contour extraction.
Network training: The weights of the neurons are adjusted in the training process. The training stops when the MSE reaches 10−7. The maximum number of iterations is set to 10,000. The momentum constant is set to 0.8. The initial learning rate is 0.01. The ratio of increase in the learning rate is 1.05. The decrease ratio of the learning rate is 0.7. The sample set is normalized. The range is [0,1]. The normalization function is

The TC is calculated after target identification. The shape of the target object is regular, so the spatial position of the TC is the destination of the end-effector positioning. The TC is calculated as follows

where ib and ie denote the minimum pixel and maximum pixel of the target object, respectively, along the row direction, jb and je denote the minimum pixel and maximum pixel of the target object, respectively, along the column direction, T denotes the adaptive threshold, and pij denotes the grayscale value.
Autonomous positioning
Point cloud acquisition
The motion end-effector extracted from image frames belongs to the active object in the positioning system. Target objects identified from image frames belong to the passive object in the positioning system. After the active object and passive object are determined in the sections “End-effector Motion Estimation” and “Object Recognition,” their point cloud data (also called the target point cloud, TPC) is obtained by Kinect. It contains the 3-D coordinates and RGB information of each point.
The point cloud library (PCL) is an open-source point cloud processing library. It includes point cloud data acquisition and processing, filtering, feature extraction, surface reconstruction, point cloud registration, point cloud integration, and so on. The OpenNI is used as the system I/O interface in the PCL. Richard et al. 21 suppose that the distance is d raw from a point P to camera in the Kinect measurement space. According to the 3-D coordinate extraction method provided by Zhu et al., 22 the actual position of point P in the space is

where d and d raw are in centimeters, H = 3:5 × 10−4 rad, K = 12.36 cm, O = 3.7 cm, and L = 1.18 rad. Then, the coordinate (x, y, z)/cm is extracted as

where (u, v) denotes the projection position of point P in the image frame

is the official calibration data. fx and fy denote the conversion factors between the imaging plane pixel and space physics length. u 0 and v 0 denote the image origin.
Point cloud processing
The number of the TPC is of order 106 in each frame. The processing of huge and unordered data consumes a lot of time and hardware resources. It affects the speed of the algorithm. He et al. 23 find that noise in a point cloud can be removed by preprocessing based on density analysis. The point cloud distribution obtained from Kinect is not uniform. The average distance between each point and its neighborhood points follows approximately Gaussian distribution. There are some outliers in the point cloud data. Their neighborhood points are always closer. The neighborhood average distance (NAD) s is generally large. If the average distance is not in the standard range determined by the mean μ and standard deviation σ, the point is defined as an outlier, and it should be removed. The probability density function of the NAD is
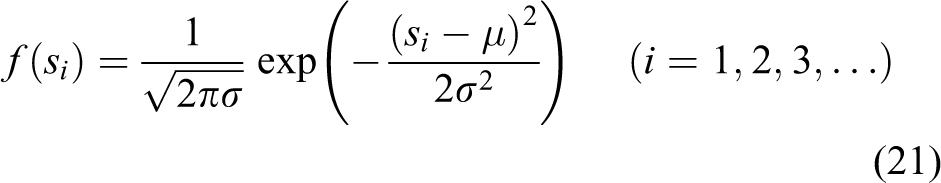
where si denotes the NAD of any point, μ denotes the mean of the NAD, and σ denotes the standard deviation. The number of neighborhood points is set to m. The multiple of the standard deviation is set to n. When the NAD of a point exceeds the global average distance nσ, the point should be marked as an outlier and removed. When m increases and n decreases, the noise determined to be outliers is lower. m and n are set to 25 and 4, respectively, by experiments.
TPC data compression
In order to achieve fast 3-D surface fitting, TPC data compression is necessary. Merry et al. 24 propose a 3-D mesh simplification algorithm based on the average distance between points. The 3-D mesh can be assumed to be a cube surrounded by the 3-D coordinates of the point set. The side length of the cube is the maximum coordinate difference between the 3-D data points. In the smallest mesh, the average distance method proposed selects a part of feature points instead of all data points. The accuracy of simplification is determined by the size of the mesh. When the cube mesh is smaller, the simplification precision is higher.
The idea of the average distance method is that when the point cloud density is higher, the distance between points is smaller. Otherwise, the size of the point cloud density can also be determined by the distance. According to the size of the point cloud density, the number of points to delete is chosen. The steps are as follows: (I) Define the side length L of the cube mesh. Define the rate ξ between the expected simplification data and original data. (II) Assume that a random point P is a starting point. The remaining point set is (III) The average distance of P is

(IV) All point sets in the mesh are calculated according to the above steps. The points with the minimum average distance are simplified by ξ. Therefore, point cloud data compression is realized.
Coordinate frames transforming
In section “Point cloud acquisition,” the TPC extracted describes the positional relationship between the camera coordinate frame {c} and target coordinate frame {t}. However, this is not enough. According to the principle of inverse kinematics, the TPC needs to be transformed into the base coordinate frame. Thereby, the system can control the trajectory of the manipulator. The forward kinematics model describes the relative position of the end-effector coordinate frame {e} and base coordinate frame {b}. Now, the TPC is mapped to the spatial coordinates relative to {b}. The origin of the world coordinate frame {w} is set at the base. {b} and {w} coincide. Coordinate frame transforming is shown in Figure 4.

Coordinate frame transforming.
The homogeneous transformation matrix describes the relative position of the two coordinate frames with dimension 4 × 4.
Definition: CTB denotes the position of {c} in {b}, CTE denotes the position of {c} in {e}, and ETB denotes the position of {e} in {b}. Coordinate frame transforming is

where
The spatial coordinates of the TPC are mapped to the rotation angles of each joint by inverse kinematics modeling. 26 The corresponding command is sent out to control the movement of the manipulator. The end-effector reaches the target position using forward kinematics. Therefore, autonomous positioning is achieved.
Finally, surface fitting is made as in the study by Bloomenthal 27 to validate the correctness of the proposed positioning method.
Experiment and analysis
The experimental platform consists of a computer (AcerTMP455, 16G memory, 500G SSD), manipulator system, and a simple depth imaging device Kinect, as shown in Figure 5. Kinect work principle specification is described on the corresponding webpage. The software includes VC++2010, OpenNI, MATLAB 2012a, and Kinect for Windows SDK v1.7. Experimental platform.
Kinematics analysis
The proposed method is illustrated using the example of a five-degree-of-freedom manipulator, as shown in Figure 6. There are five rotation axes, five joints, and three links. Five joints are the waist rotation joint (the first joint, J1), arm pitching joint (the second joint, J2), forearm pitching joint (the third joint, J3), wrist pitching joint (the fourth joint, J4), and wrist rotation joint (the fifth joint, J5). The DH parameters are determined as shown in Table 1, where θi denotes the rotation angle along the z-axis, αi denotes the rotation angle along the x-axis, ai denotes the distance along the x-axis between two neighbor z-axes, di denotes the distance along the z-axis between two neighbor x-axes, r1 denotes the arm length, r2 denotes the forearm length, and r3 denotes the wrist length.

Manipulator diagram.
DH parameters.

The transforming matrices are obtained as
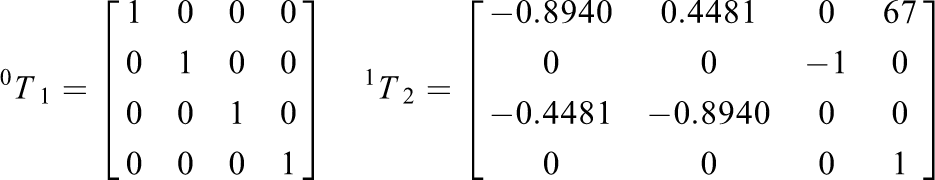



Because the origin of the base coordinate frame is set at the center of J1, and the waist length is 76 mm, the space motion range of J1 is (0, 0, 38 mm). The range of J2 is (0, 0, 76 mm). The space trajectory range of J3 is shown in Figure 7(a). The space trajectory range of J4 is shown in Figure7(b). The space trajectory range of the end-effector is shown in Figure 7(c). Joint motion trajectories. (a) Motion range of J3. (b) Motion range of J4. (c) Motion range of the end-effector.

End-effector state estimation
The video is transformed into the image frame format (480 × 640 × 3) as shown in Figure 8(a). There are 73 frames in total. The binary threshold T is set to 0.0118. The static background is extracted using the three-frame differencing method as shown in Figure 8(b). When the end-effector is moving, its moving area is extracted from each frame. It is marked with green squares as shown in Figure 8(c). Target Separation. (a) Image frame. (b) Static object extraction. (c) End-effector extraction.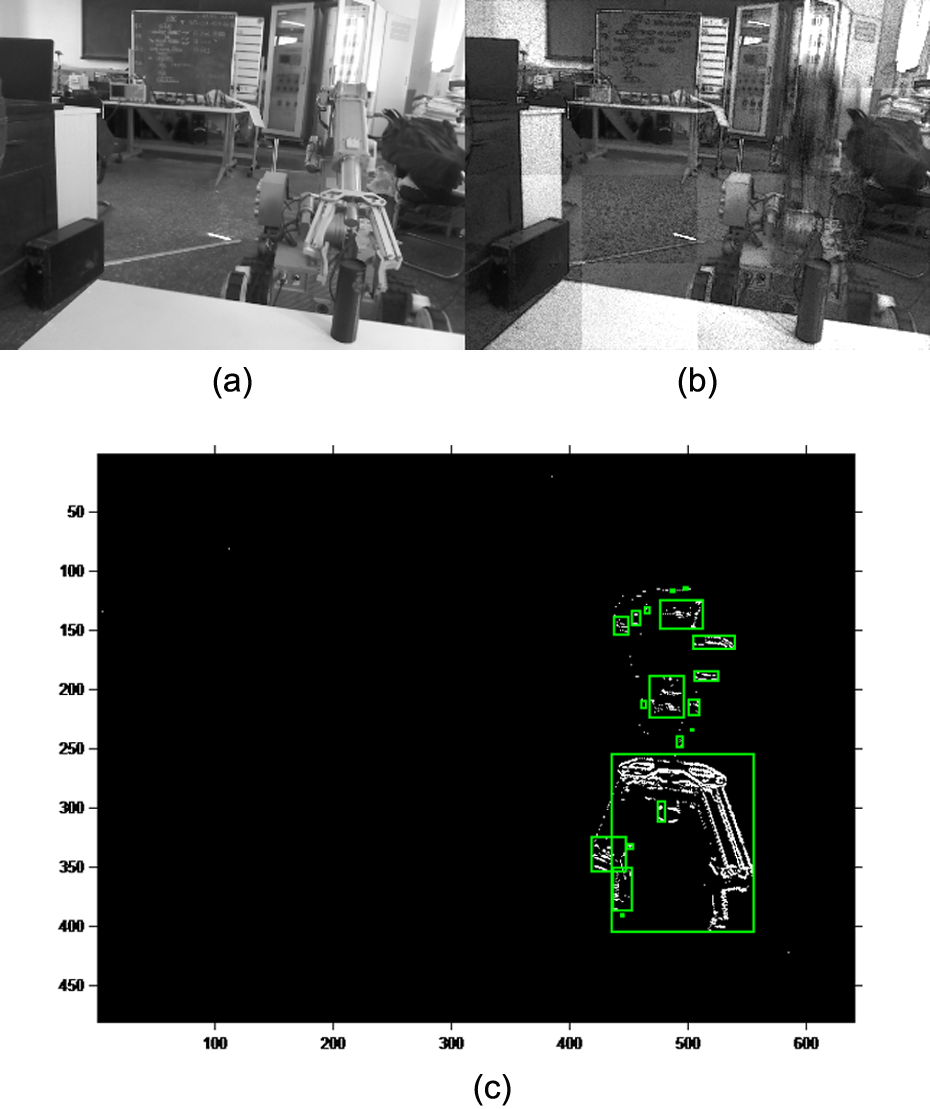
In the PF, the number of particles is M = 100. The process noise covariance is 10. The measurement noise covariance is 1. The initial state of the EEC and particles is shown in Figure 9(a). Red “·” denotes the EEC’s initial position. Black “·” denotes the distribution of 100 particles. Blue “·” denotes the geometric center of the particles. State estimation of end-effector. (a) Initial position of EEC, particles distribution, and initial position of particle center. (b) Motion of EEC is tracked by center of particles.
The tracking process of the end-effector using the PF is illustrated in Figure 9(b). Red “·” denotes the state change of the EEC. Black “·” denotes the state change of the particles. In the process of tracking, all particles are clustered. Blue “·” denotes the state change of the particle center. The clusters of the particles and their centers coincide substantially. During the end-effector moving, the center of the particles approaches the EEC gradually. Their centers almost coincide. The state trend is also almost the same. So, the EEC can be approximated using the geometric center of the particles. Therefore, the position of the end-effector can be obtained in real time.
The general trends of the actual position and estimated position coincide. This indicates that this algorithm can predict the end-effector’s position. At the same time, the experiment shows that the adaptability of the system is improved. While the static background is extracted, the moving end-effector is also detected and tracked in the scene.
Target recognition experiment
The edge contour of the target object is extracted according to the section “Object recognition.” Then, the shape parameters (seven kinds) are calculated to obtain the sample set. The dimension of the sample set is 1000 × 8 (cylindrical 600, square 200, and spherical 200). The dimension of the training set is 900 × 8 (cylindrical 540, square 180, and spherical 180). The dimension of the test set is 100 × 8 (cylindrical 60, square 20, and spherical 20). The normalization processing of the sample set is carried out. The situation with the BP network training is shown in Figure 10. This training takes 5 s with 47 iterations. The blue line represents the convergence of the training sample. The red line represents the convergence of the test sample. The network stops training when the MSE reaches 1.24 × 10−8. The test set converges when the MSE reaches 7.84 × 10−5. The function gradient decreases from 1.49 to 9.41 × 10−6. The dotted line denotes the preset MSE of the stopping training. Convergence of BP neural network training.
The results of the identification are shown in Figure 11. The horizontal axis denotes the number of test samples (per group). The vertical axis denotes the classification (identification result). Blue “.” denotes the network predictive result. Red “○” denotes the actual classification. If the classification is equal to 0.1, the target is a cylindrical object. If the classification is equal to 0.2, the target is a square object. If the classification is equal to 1, the target is a spherical object. From Figure 11, there is probably a one-to-one correspondence between the network classification and actual results. Fifty-nine cylindrical objects are identified correctly, one is identified to be square (probability 98.3%). Twenty square objects are all identified correctly (probability 100%). Twenty spherical objects are all identified correctly (probability 100%). So, the recognition rate is 99% for the test sample. Further, a cylindrical object is selected randomly from the test sample. Its coordinate of the TC is (507 pixels, 306 pixels) according to equation (18). Recognition results.
The high recognition rate shows that the features extracted are comprehensive and critical. It also indicates that the design of the BP network is rational. This algorithm does not require a precise mathematical model and is able to adapt to changes in the scene. At the same time, it has the learning ability and improves the intelligence level of the system. However, there are some shortcomings. First, there is no universal theoretical guidance for the selection of the network structure. Therefore, it takes a long time to carry out preliminary experiments. Second, the learning ability and convergence of the neural network are closely related to the sample.
Positioning experiment
According to the section “Coordinate frames transforming,” we obtain the following results

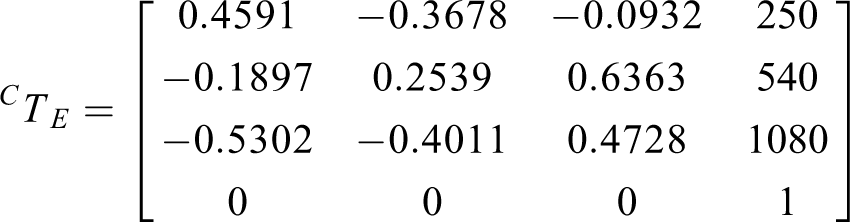

The 3-D coordinates of the end-effector and target object are obtained by the PCL acquisition, removing outliers, data compression, and so on. For the video (including 73 frames), the 3-D coordinates of the EECs are shown in Table 3. (x, y, z) denote space coordinates of EECs in the base coordinate frame. Before data compression, the TPC is shown in Figure 12(a). After data compression, the TPC is shown in Figure 12(b). The 3-D coordinates of the cylindrical TC are (214.2 mm, −3.9 mm, 825 mm).

Fitting results. (a) TPC before data compression. (b) TPC after data compression. (c) Triangular facets and morphological processing.
3-D coordinates of EECs in base coordinate frame.

From Table 3, the EEC gradually approaches the TC in the time domain. The absolute errors are 214.2 − 212.6=1.6 mm, −3.5−(−3.9) = 0.4 mm, and 825 − 823.9=1.1 mm along the x-, y-, and z-axes, respectively. The theoretical values are constant along the x-axis. But the experimental data fluctuate within a certain range. The maximum random fluctuation is 225.5 − 208.3 = 17.2 mm. The theoretical values decrease along the y-axis. The experimental data also decrease. The theoretical values increase along the z-axis. The trend of the experimental data is not increasing. The data are sometimes unchanged or fluctuant in some consecutive frames. The reason for the deviation is the low pixel accuracy of Kinect.
The deviation between the EEC and TC represents the positioning error. It provides reference data for the manipulator’s motion control. Under ideal conditions, the positioning is successful if the TC coordinates coincide with the EEC coordinates. But in the experiment, it is normal if there is a certain deviation. A known condition: The clamping mechanism has the maximum opening range 287 mm. According to the actual positioning requirement, the maximum permissible errors are 20 mm, 25 mm, and 20 mm along the x-, y-, and z-axes, respectively.
The surface fitting is implemented using triangular facets and morphological processing as shown in Figure 12(c). The article only shows the fitting results for the 5th, 25th, 45th, 65th, and 73rd frames. This process verifies the correctness of the kinematic model and the effectiveness of the autonomous positioning algorithm. At the same time, it provides a convenient way for the visual monitoring of the positioning process.
Comparative analysis
In sections “Kinematics Analysis,” “End-effector State Estimation,” and “Target Recognition Experiment,” the active and passive objects are extracted from the scene based on the PF, BP recognition, and PCL technology. The position of the end-effector is adjusted using the error between the EECs and TC as a reference. Comparative experiments are carried out as shown in Table 4.
Algorithms comparison.

The accumulated error cannot be corrected in the study by Izadi et al. 1 The 3-D reconstruction based on the monocular camera only relies on the mathematical model in the study by Li et al. 4 The requirement for the light source is harsh. The 3-D reconstruction based on the binocular vision requires pattern matching and a lot of computations in the study by Lin et al. 6 The effect of the reconstruction is significantly reduced in the case of a large baseline distance. The error of the position estimation is close to one reported in Carbone and Gomez-Bravo. 9 The real time of the point cloud fitting is higher than that in the study by Kanatani et al. 10 The recognition rate of 99% based on the BP neural network is higher than 90% based on the study by Gruen and Thomas. 11 The visual calibration is not required and calculations are clearly simplified in this article compared with that reported in Hu and Li. 28
The following conclusions are obtained from the comparative analysis.(I) Calculations are simplified using the PCL acquisition and data compression.(II) The hardware system has low light source demanding, mainly affected by direct sunlight. The reason is that Kinect uses near-infrared light. The solar spectrum interferes with Kinect.(III) The neural network recognition reduces the reliance on a mathematical model.(IV) The reconstruction accuracy is close to one reported in Izadi et al. 1 and Lin et al. 6 The camera pixel accuracy, target recognition, and end-effector’s extraction all affect the accuracy of the surface fitting. In summary, the system efficiency improves significantly.
Conclusion
The article proposes a PF based on three-frame differencing to detect and track the end-effector’s motion in a static background. The target objects are identified based on the BP neural network classification idea. The coordinates of the TC are calculated. The positioning is successful when the positioning error is within an allowed range. Then, the TPC is collected based on the PCL technology. Outliers are removed, and data compression is carried out. The coordinate frame transforming model is established. TPCs are transformed into the base coordinate frame from the camera coordinate frame. Therefore, the coordinates are meaningful for the manipulator motion control. Finally, the surface fitting of the TPC is achieved.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.