
Abstract
This article presents a semantic approach for multimodal interaction between humans and industrial robots to enhance the dependability and naturalness of the collaboration between them in real industrial settings. The fusion of several interaction mechanisms is particularly relevant in industrial applications in which adverse environmental conditions might affect the performance of vision-based interaction (e.g. poor or changing lighting) or voice-based interaction (e.g. environmental noise). Our approach relies on the recognition of speech and gestures for the processing of requests, dealing with information that can potentially be contradictory or complementary. For disambiguation, it uses semantic technologies that describe the robot characteristics and capabilities as well as the context of the scenario. Although the proposed approach is generic and applicable in different scenarios, this article explains in detail how it has been implemented in two real industrial cases in which a robot and a worker collaborate in assembly and deburring operations.
Keywords
Introduction
In designing the factories of the future, achieving safe and flexible cooperation between robots and human operators is considered as a way of enhancing productivity. The problem of robots performing tasks in collaboration with humans poses the following main challenges: robots must be able to perform tasks in complex, unstructured environments and, at the same time, they must be able to interact naturally with the workers they are collaborating with, while guaranteeing safety at all times.
The present work describes a natural communication approach between person and robot, as developed within the FourByThree European project. 1 This project aims to create a new generation of modular industrial robotic solutions that are suitable for efficient task execution in safe collaboration with humans, at the same time as being easy to use and program. This work will allow system integrators and end users to develop custom robots that best answer their needs. To achieve this, the project provides a set of hardware and software components, ranging from low-level control to interaction modules. The outcome from the project will be validated in four industrial settings: investment casting, aeronautical sector, machining, and metallic part manufacturing, in which industrially relevant applications are being implemented for human–robot collaboration: assembly, deburring, welding, riveting, and machine tending.
A requirement for natural human–robot collaboration is to endow the robot with the capability to capture, process, and understand accurately and robustly human requests. Using voice and gestures in combination is a natural way for humans to communicate with other humans. By analogy, they can be considered equally relevant to achieve natural communication also between humans and robots. In such a multimodal communication scenario, the information coming from the different channels can be complementary or redundant, as shown in these examples:
Complementary: A worker saying “Take this” while pointing at an object.
Redundant: A worker saying “Stop!” while performing a gesture by lifting a hand and showing the palm.
In the first example, the need for different communication channels complementing each other is evident. However, redundancy can also be beneficial 2 in, for example, industrial scenarios in which noise and variable lighting conditions may reduce the robustness of each channel when considered independently.
In this article, we present a semantic approach that supports the multimodal interaction between humans and industrial robots, in real industrial settings. Our approach relies on the recognition of verbal commands and gestures for requests processing, first independently, and later fusing both channels, managing information that can potentially be contradictory or complementary. Semantic technologies are used to describe characteristics of collaborative robots as well as scenario contexts, being a key component for request interpretation.
This generic approach can be applied to different industrial scenarios by modifying the information about the environment in which the communication takes place. In this article, we validate this approach in the scenario described in the section below. We continue with a brief review of previous work and the description of the main components used in our approach. After describing the performed test and evaluation, the conclusions and planned future work are presented.
Case study
As explained before, the FourByThree project includes four industrial scenarios of human–robot collaboration. For an initial validation of our semantic multimodal interaction approach, we selected an application scenario at an investment casting process at the Spanish manufacturing company “ALFA.” This scenario includes two collaborative tasks: a die-assembly task (involving screwing and unscrewing operations) and the deburring of wax pieces as the second task.
Assembly task: The human worker and the robot worked independently (un)screwing bolts on the four different parts of a rectangular die. The job was shared between person and robot by assigning two of the sides to each of them, as decided by the person. The human worker had to specify which two of the four sides of the die the robot had to operate on. Due to the proximity between the worker and the part, performing a pointing gesture was not considered feasible. Thus, the worker specified the side by voice only.
Deburring task: The human and the robot performed sequential tasks on the same workpiece in a synchronized manner. While the person glued parts and removed burrs that were difficult to access, the robot performed the rest of the deburring. In this case, the person provided instructions to the robot about where to deburr using a combination of speech and gesture.
To accommodate language requirements from the end users, we implemented the speech processing for Spanish.
Related work
Over the last two decades, a considerable number of robotic systems have been developed that include human–robot interaction (HRI) capabilities 3,4 Although recent robot platforms integrate advanced human–robot interfaces (incorporating body language, gestures, facial expressions, and speech), 5,6 their capability to understand human speech semantically remains rather limited. Endowing a robot with semantic understanding capabilities is a very challenging task, although an important one. For instance, previous experiences with tour-guide robots 7,8 showed the importance of improving natural HRI in order to ease the acceptance of robots by visitors. In Jinny’s HRI system, 8 voice input was converted to text strings, which were decomposed into several keyword patterns and a specialized algorithm found the most probable response for that input. With this technique, two questions like “Where is the toilet?” and “Where can I find the toilet” are interpreted in the same way, since keyword patterns that included “where” and “toilet” are extracted from both cases.
Gesture and posture recognition is commonly supported by 3-D cameras (stereo vision) and other sensors providing point clouds (e.g. LEAP motion) and 2-D color cameras. 9 Other wearable approaches, based on, for example, accelerometers and gyroscopes, are also used for very specific applications. 10,11 Fang et al. 12 present a data glove which can capture the motion of the arm and hand by inertial and magnetic sensors. The proposed data glove is used to provide the information of the gestures and teleoperate the robotic arm–hand. The use of vision-based gesture analysis has the advantage of not needing the user to wear any additional sensor. Gesture information is derived from, for example, depth segmentation and skeleton tracking, 13 3-D sensing or from color segmentation (detection of hands, head, or tags) 14 with 2-D.
Human–robot natural interactions have also been researched in industrial scenarios. For instance, Bannat et al. 2 introduced an interaction that consisted of different input channels such as gaze, soft buttons, and voice in an industrial scenario. Although voice constituted the main interaction channel in that use scenario, it was solved by command-word-based recognition.
SHRDLU is an early example of a system that was able to process instructions in natural language and perform manipulations in a virtual environment. 15 Later on, researchers extended SHRDLU’s capabilities to real-world environments. Those efforts branched out into tackling various subproblems, including natural language processing (NLP) and robotics systems. Notably, MacMahon et al. 16 and Kollar et al. 17 developed methods to follow route instructions provided through natural language. Tenorth et al. 18 developed robotic systems capable of inferring and acting upon implicit commands using knowledge databases. A similar knowledge representation was proposed by Wang and Chen 19 using semantic representation standards such as the W3C Web Ontology Language (OWL) to describe an indoor environment.
Recent research projects in different fields 20 –23 show how combining different interaction channels outperforms the accuracy and robustness of the interaction with respect to the individual use of each channel. Dobrišek et al. 20 show how audio and video combination for emotion recognition increases the performance to 77.5%, increasing in 5% with respect to the best of the individual channels, that is, audio. Liu et al. 21 use visual information in combination with information from tactile sensors to capture multiple object properties, such as textures, roughness, spatial features, compliance, and friction, bridging the gap for objects that are not visually distinguishable, leading to better recognition results without any relevant drawback in execution time.
Rossi et al. 24 addressed a multichannel fusion problem aimed for a robust communication between human and robot. In the case study that they presented, they described a generic and extensible architecture that included gesture and voice recognition, plus a fusion engine to improve the robustness of the interpretation of the human–robot communication. Their implementation was able to recognize seven different gestures and it was based on hidden Markov models. Voice recognition is frame based, where a simple action or a directed action and its corresponding target object are extracted from the instructions conveyed in speech. The fusion engine is a support vector machine (SVM)-based model that delivers the final output considering both input channels, gesture, and voice. Their evaluation showed that interaction accuracy increased when combining both inputs (91%) instead of using them individually (56% in the case of gestures and 83% for voice). Furthermore, the average time for processing both channels was similar to the time needed for speech processing.
Our work is based on this extensible architecture approach, combining gesture and speech channels. However, unlike in Rossi et al., 24 we add semantics both for voice interpretation and for the fusion step. With this, we aim to ensure the coherence within each channel and in the final combination of both, thus avoiding logical contradictions as well as taking advantage of complementary information.
As stated by Liu and Kavakli 25 in their survey, it is possible to identify three main levels of fusion strategies: signal level fusion (signals of different input devices are merged); feature level (early fusion that concatenates the feature vectors from multiple modalities to obtain a combined feature vector which is then used for the classification task); and the last level that includes several different features and is sometimes named as decision-level fusion, late fusion, or even semantic-level fusion where each input channel is treated independently and the output of each of those interpretations integrated sequentially.
According to Atrey et al., 26 at the feature-level fusion, the features extracted may be extracted from different modalities such as visual, audio, text, motion, or metadata. This approach presents the advantages that it makes use of correlation among different sources of data available and it requires only one learning phase for the combined features. However, it also presents the important drawback that it makes the time synchronization between the features very hard to handle. The decision-level fusion is the most extended one in the field of human machine interaction, due to its easy scalability.
Different variants of the late fusion method have been proposed, the following three categories being the most relevant ones: rule based, as described by Holzapfel et al. 27 and Burger et al. 28 ; estimator based, like in the study by Wagner et al. 29 ; and classification based, as described by Kessous et al. 30 and Wu et al. 31 In the latter, SVMs are used as a super-kernel algorithm to fuse the decisions of the previous individual classifiers. In the rule-based case, in contrast, feature-level fusion and decision-level fusion are compared, both based on Bayesian classifiers. In the feature-level approach, the Bayesian classifier is used for the fusion itself, while in the decision level, a Bayesian classifier is modeled for each channel interpretation and their outputs are later fused based on an estimation strategy. Both fusion strategies outperform significantly the mono-channel system performances (the best with 67.1%) reaching up to 78.3%.
In the study by Ngiam et al., 32 deep networks to learn features over multiple modalities are presented, building deep bimodal representations by modeling the correlations across the learned shallow representations.
Multimodal interaction semantic approach
The approach proposed in this work contributes to create a safe human–robot collaborative environment in which interactions between both actors happen in a natural way, that is, communication based on voice and gestures in this case. Some examples of this natural interaction could be human operator asking the robot to complete a certain task; robot asking for clarification when a request is not clear; in some specific scenarios in which human intervention is necessary during an automatized robot task execution; the robot asking the operator to complete some tasks; and once that is done, the operator informing the robot that it can resume its task. This natural communication facilitates the coordination between both actors, enhancing the safe collaboration between robot and human.
To address such a natural communication, we propose a semantic multimodal interpreter that is able to handle voice- and gesture-based natural requests from a person and combine both inputs to generate an understandable and reliable command for industrial robots, facilitating a safe collaboration.
For such a semantic interpretation, we have developed four main modules, as it is shown in Figure 1: a knowledge manager module that describes and manages the environment and the actions that are affordable for robots, using semantic representation technologies; a voice interpreter module that, given a voice request, extracts the key elements on the text and translates them into a robot-understandable representation, combining NLP and semantic technologies; a gesture interpretation module to resolve pointing gestures and some simple orders like stopping an activity (out of the scope of the work presented in this article); and a fusion engine for combining both mechanisms and constructing a complete and reliable robot-commanding mechanism.

Multimodal semantic approach architecture
These modules are described in detail in the following subsections.
Knowledge manager
The knowledge manager uses an ontology to model the environment and the robot capabilities as well as the relationships between the elements in the model, which can be understood as implicit rules that the reasoner exploits to infer new information. Thus, the reasoner can be understood as a rule engine in which human knowledge can be represented as rules or relations. Ontologies are reusable and flexible at adapting to dynamic changes, thus avoiding to have to recompile the application and its logic whenever a change is needed. Being in the cloud makes ontologies even more reusable, since different robots can exploit them, as it was demonstrated by Di Marco et al. 33
Through ontologies, we model the industrial scenarios in which robots collaborate with humans. The model includes robot behaviors, actions they can accomplish, and the objects they can manipulate/handle. It also considers features and descriptors of these objects. We distinguish two main kinds of actions: actions that imply a change on the status of the robot operation, for example, start or stop, and actions involving the robot capabilities, for example, screw, carry, or deburring. This is shown in Figure 2.

An excerpt of the knowledge manager ontology.
Using OWL equivalentClass built-in property, ActionOverPoint and ActionOverObject classes have also been defined. Both are ModeAction subclasses, with the following restrictions: for a start, the action must be related to a point (defined by hasEffectOnPoint min 1 Point restriction in the ontology). In addition, the action must be related to an object (defined by hasEffectOnObject min 1 Object restriction in the ontology). This way, applying a semantic reasoner able to interpret this OWL statements, it will infer that a ModeAction instance like deburring with hasEffectOnObject burr property also belongs to the ActionOverObject class. The same inference effect for ModeAction instances with hasEffectOnPoint point1 property defined that will also be considered instances of ActionOverPoint.
For each individual action or object, we include tag property data for listing the most common expression(s) used in natural language to refer to them, including reference to the language used. An automatic semantic extension of those tags exploiting Spanish WordNet 34 is done at initialization time. In this way, we obtain different candidate terms referring to a certain concept.
Besides task/programs and objects, the ontology also includes relations between the concepts, as it is shown in Figure 3. These relations are used by the interpreter for disambiguation at run-time. This ability is very useful for text interpretation because sometimes the same expression can be used to refer to different actions. For instance, people can use the expression remove to request the robot to remove a burr, but also to remove a screw, depending on whether the desired action is deburring or unscrewing, respectively. If the relationships between the actions and the objects over which the actions are performed are known, the text interpretation is more accurate; it will be possible to discern in each case to which of both options the expression remove corresponds. Without this kind of knowledge representation, this disambiguation problem is more difficult to solve. These relations are formally modeled in the ontology as it is shown in Figure 3.

An excerpt of the FourByThree semantic interpreter knowledge base: disambiguation.
For our current implementation, the two contexts described in the “Case study” section have been considered. The possible tasks the robot can fulfill in both scenarios have been identified and a knowledge base (KB) created, populating the knowledge manager ontology with instances representing those tasks. The KB also includes the elements that take part in both processes as instances of Object and Point classes as well as the relationships they have with respect to the tasks. This KB is published in StarDog 4.0.5 Community version 35 and extended with WordNet as explained before.
In this way, the semantic representation of the scenarios will be available to support the request interpretation process, not only to infer which is the desired action to perform but also to ensure that all the necessary information is available and coherent in order to be possible for the robot to perform it. Furthermore, the information is coherent as a whole. For instance, when someone asks the robot via voice to Remove the bolts from that piece, pointing at a position where a piece without bolts is placed, the multichannel interpreter will first use the semantic representation as explained before to select the action that best matches among the feasible ones described in the KB (unscrew), thus taking advantage of the semantic relations between actions, working-pieces, and the objects in scope. Once the piece pointed at is recognized through vision, and after fusing channels, the interpreter will (in the case of this example) decline the petition due to incoherence, since performing unscrewing actions on a piece without bolts is impossible. This kind of apparently evident incoherence detection requires the semantic representation of the scenarios also to be detectable by machines.
Voice interpreter
Given as input a human request in which a person indicates the desired action via voice, the purpose of this module is to understand exactly what the person wants the robot to do and, if the information is complete, to generate the corresponding command for the robot. For instance, if a worker says Remove the burrs from there, the voice interpreter should interpret that the verb remove corresponds to the deburring action and check if it is a feasible action in the current collaborative robot application. If affirmative, it should then generate the necessary information for the robot to execute the request.
For such an interpretation, the module follows three main steps: an initial speech recognition step that deals with the voice-to-text transcription; following, a rule-based step for the extraction of key elements from the transcribed text; and finally, the matching between the key elements and the tasks that is feasible for the robot, based on the KB.
The speech recognition step is based on the Google Speech API. 36 A recorded audio file including the request of the operator is sent to the Google Speech API, which returns the corresponding text.
For the second step (extraction of the key elements from the text transcribed in the previous step), NLP techniques are used. The main idea is to use syntactic information by means of rules for the extraction of key elements. In our current implementation, the Spanish version of FreeLing (an open source suite of language analysis tools 37 ) is used for this structural analysis.
For the definition of rules, use FreeLing for the morphosyntactic analysis and dependency parsing of a set of request examples obtained from different persons. We revise the complete information manually and identify the most frequent morphosyntactic patterns that are relevant for extracting the key elements: elements denoting actions, objects/destinations (target onward), and explicit expressions denoting gestures, such as there and that. Finally, we implement those patterns as rules. In this way, given a Spanish FreeLing-tagged sentence, it is possible to extract the key elements present in it during execution. In the future, it will be possible to use this process to extend the interpreter to other languages.
Once the key elements are extracted, it is necessary to identify which one of the tasks that the robot is able to perform suits the request best. We undertake this last step by making use of the KB information described above. First, we verify if the identified actions were among the feasible tasks described in the KB, accessing the tag data property of the actions in the KB using the semantic query language, SPARQL. 38 Then, we apply a disambiguation step using the target information, as explained before (taking advantage of the OWL logic inference capabilities). The final output from the voice interpreter consists of frames, one for each potential task candidate, including information denoting gestures, if any exists.
As an example, for the request in Spanish Quita las rebabas (Remove the burrs), the system would check, via a SPARQL query, which actions in the KB contained tag data property with the value quitar (remove). This would return unscrew and deburring as potential actions. In the following step in which key elements were extracted, burrs would be recognized as target element. This element would be checked back with the KB via SPARQL in order to see if any of the two candidate tasks was related to it, which would return deburring as directly related. As a result, the module would discard unscrew as potential action, leaving deburring as the only eligible potential task.
The following example illustrates yet another instance in which the disambiguation capability could be exploited. Let us consider these two similar but different requests: Acércate (come here) and Acerca la caja (bring the box closer). In both sentences, the element to look for among tag data properties of the tasks represented in the KB would be acercar (the infinitive form of the verb), which would match with the tasks go and bring. As it is shown in Figure 4, both belong to the ActionOverPoint class, while the latter also belongs to the ActionOverObject class. Making use of this information (and although box is not explicitly represented in the KB, it would have been identified as the target element in the previous step), the interpreter would be able to infer that bring fitted as a task better with this request than go.

An excerpt of the FourByThree semantic interpreter knowledge base: Go and Bring.
If the verb did not match any of the tasks in the KB or if no verb was identified in the request but some target or pointing information had been extracted in the preceding step, then the interpreter was able to generate task suggestions, based on the relations and equivalences defined in the KB. For instance, if tornillo (bolt) was the only information extracted from the voice request, the interpreter would be able to generate screw and unscrew as potential task candidates. With this information, the robot could potentially request the worker to help with the disambiguation process.
For the sake of illustration, Figure 5 presents the example of asking a robot to deburr a piece starting from a certain point (Remove burrs starting here).

Voice interpreter execution sequence.
Gesture interpretation
Two kinds of gestures are addressed within the FourByThree project: pointing gestures and gestures for simple commands such as stop or start. This article only deals with pointing gestures that are recognized by means of point-cloud processing. The system is able to handle different pointing gestures that are performed within a certain temporal window, providing the x, y, and z coordinates of the target position.
The setup used consists of a collaborative robot and a sensor capable of providing dense point clouds, such as the ASUS Xtion sensor, the Microsoft Kinect sensor, or the industrial-grade Ensenso system by IDS. The camera is placed pointing toward the working area of the robot in the region above the human operator. Thanks to this configuration, the point cloud obtained contains information about the working area and part of the human body (in particular, the arm and hand used to perform the gesture; see Figure 6).
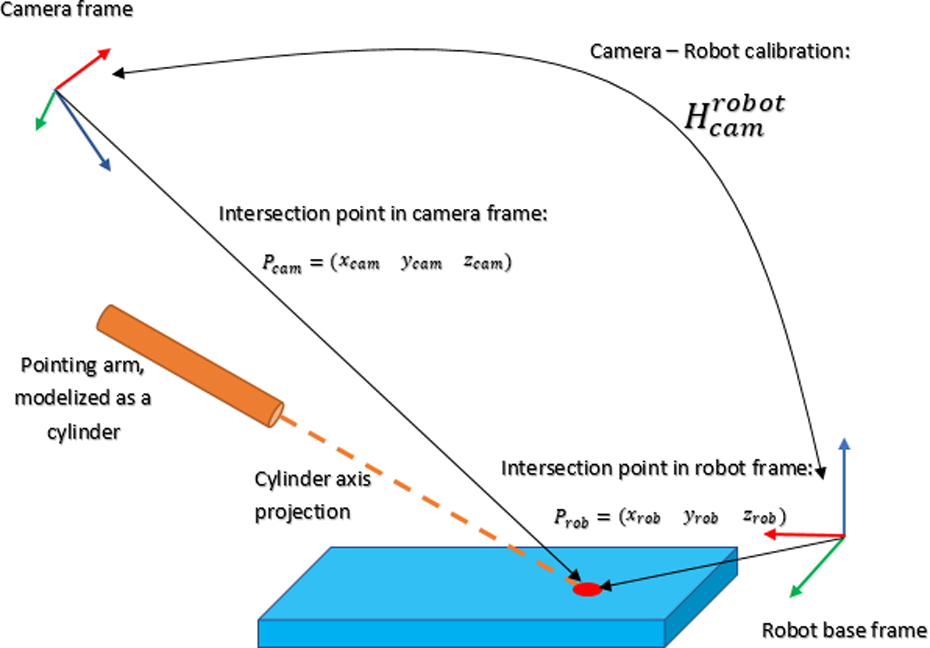
Worker and target frames.
Two cuboid regions of interest (ROIs) are then defined in the point cloud, one for the operator’s pointing gesture detection (which essentially includes his/her forearm) and a second ROI where the intersection area (i.e. the target point) has to be identified.
With this setup, two main problems need to be solved for the interaction between the person and the robot to succeed:
Robust estimation of the pointing gesture
The ROI for the pointing gesture detection is initially defined by specifying in the environment a cuboid with respect to the reference frame. In this case, the reference frame is the sensor frame, but it can also be defined using another working frame, provided a transformation exists between the frame used and the sensor frame. For robustness, the pointing gesture is defined using the forearm of the human operator. To identify the arm unequivocally, a Euclidean cluster extraction is performed.
Intersection of the pointing gesture with the working area of the robot
The main objective of a pointing gesture is to determine the point on the working area that is being pointed at. To identify this point, the points in the cloud corresponding to the pointing line are selected, from the furthest one all the way to the origin of the line that corresponds to the pointing arm. For each one of the points, a small cuboid is defined, and the ROI of the working area of the robot is filtered with it. If more than N points of the working area are present inside the small centered cuboid defined in the points of the projection line, an intersection has been found. The final intersection point that is published is the closest one to the origin of the projection line. As a threshold, a minimum Euclidean distance value is defined in order to avoid detecting intersections corresponding to the point cloud of the arm that generates the pointing gesture.
To detect gestures within a time frame, we have implemented spatial filtering to distinguish between real stable pointing gestures and natural arm movements. The system monitors the intersection points obtained by the algorithm, and once a valid intersection point is obtained, the spatial filtering monitoring is launched. To detect a stable gesture, N consecutive intersection points must be contained in a defined cube, the centroid of which is the first intersection point obtained. The number of consecutive intersection points and the side of the filtering cube are defined as parameters. A pointing gesture is considered stable and valid if it fulfills the previous condition. If not, the points from the last filtering operation are discarded. Valid points are queued during the time frame and returned at the end of the acquisition time according to the format described below.
{“points”: [
{“x”: “x1”,”y”: “y1”,”z”: “z1”},
…,
{“x”: “xN”,”y”: “yN”, “z”: “zN”}
]}
Fusion engine
The fusion engine aims to merge both the text and the gesture outputs in order to deliver the most accurate request to the execution manager, the element in the robot control architecture in charge of controlling the execution of commands. The engine considers different situations, according to the complementary and/or contradictory levels of both information sources.
As a result, the fusion engine will send to the execution manager the most coherent and reliable request that is understandable by the robot if no incoherence is found. Otherwise an error is returned.
The decision strategy of the fusion engine is summarized in Figure 7.

Fusion engine decision strategy.
Semantic multimodal interpreter testing
This section summarizes the results that we obtained after testing the semantic multimodal interpreter with different types of requests comprising different voice and gesture inputs.
Voice interpreter testing
We designed a simple experiment to test three different features of the voice-based interaction: time needed to understand a voice command; accuracy of voice request understanding; and performance of simple multilingual approach.
As the procedure, we fed the system with recorded voice commands (with different lengths and complexities) that corresponded to the ALFA scenario, so that it could run its semantic interpretation.
Time needed to understand a voice command
The first objective of this test was to measure the time needed to transform a voice command into a request understandable by the robot.
The process to interpret a request includes an initialization step and the interpretation itself. The initialization is done simultaneously with the robot initialization and it involves creating the KB and extending it with WordNet. It takes between 15 and 25 s (depending on the number of instances that the KB has to extend, which is closely related to scenario requirements). As the process is done only once during the robot’s boot process, it does not affect the user experience.
Table 1 shows the total time required to process the different requests tried out in the experiment as well as the partial time used by each of the three components of the system, that is, Google API for speech to text transformation, FreeLing for morphosyntactic analysis, and Understanding for the semantic interpretation.
Voice interpreter disaggregated times (s).

GSA: Google Speech API; SemInt: Semantic Interpreter.
Time variation is due to the different complexity and length of the speech petition. As it is shown in Table 1, Google Speech API is the most time-demanding process, which takes between 1.8 and 2.7 s to process each petition, similar to the tests reported by Rossi et al. 24 In contrast, the sum of FreeLing and Understanding is under 200 ms in most of the cases, depending on the amount of elements to handle and the disambiguation step required.
Voice request understanding performance
The second objective of this test was to evaluate the performance of the text interpreter: given a text request, it was considered that the system had provided a semantically correct result if the following features were properly identified:
StatusAction: Verbs that modify the status of the operation a robot is doing or has to do, for example start, pause, and stop.
ModeAction: Actions identifying an operation the robot can do, for example screw and debur.
Target: The element the identified ModeAction applies to.
Target attribute: Any qualifier of the target, such as color, size, geometry, and so on.
OriginPointing: An expression inside the request denoting the starting point for the ModeAction or the origin position of the target. It is relevant when a pointing gesture is used in combination with the voice command.
DestinationPointing: An expression inside the request denoting the destination or end point of the ModeAction. It is relevant when a pointing gesture is used in combination with the voice command.
Although these last two features are not required in the current scenarios, we consider they can be very relevant in other scenarios and have been included in the evaluation.
In our test, 18 of 20 requests were correctly interpreted, that is, the key elements were correctly identified and they created a coherent request in a given context. This final affirmation would not be possible without using semantic technologies that relate possible actions and robot capabilities, actions on specific targets, and so on. Furthermore, these descriptions lead to an information inference that would not be possible without their semantic representation. Therefore, many requests would not be possible to interpret due to a lack of information, implicit in the request.
The origin of the two errors in the interpretation of the requests are due to mixing up features of the origin and the destination. In the request Empieza con la pieza que está
Performance of simple multilingual approach
The objective of this test was to measure the reusability of the core component, that is, the text interpreter, when the input was done in a different language. To this aim, Google Translator was used to automatically translate from English into Spanish and then apply the Spanish semantic interpreter. We used 24 Spanish requests that the Spanish text interpreter could already solve correctly. For the experiment, the requests were translated manually into English and the resulting text was introduced in the system. Google Translator was then used to translate those requests from English into Spanish, and the interpreter was then applied on those. We found that 14 of 24 initial English requests were properly interpreted, while the remaining 10 were erroneously done. The errors can be classified into three groups:
Error type 1: Mistranslation of demonstrative, resulting in an expression with the target missing (which was relevant in pointing gestures). For instance, that was automatically translated into la (the) instead of esa (that).
Error type 2: The form of the Spanish verb automatically translated was not included in the KB. As a result, the interpreter did not return any action.
Error type 3: The resulting Spanish expression, even if correct, did not have the expected form and the interpreter was not able to provide a result.
Pointing gesture testing
The performance of the pointing gesture was already validated in the context of the European Union funded EUROC project. 39 This project aims at “sharpening the focus of European manufacturing through a number of application experiments, while adopting an innovative approach which ensures comparative performance evaluation.” As part of the evaluation, each participant team proposed different FreeStyle experiments and the corresponding metrics. Then, external evaluators verified the achievements. The pointing gesture was proposed as one of the experiments and the validation took place in September 2016 at Fraunhofer IPA facilities.
Experiment description
In flexible manufacturing cells, tombstones are used to mount parts that have to be machined. In the context of future human–robot collaboration, the operator will need to indicate the position within the tombstone on which the robot has to operate, performing tasks such as loading/unloading parts, inspecting or measuring the part on that position, and so on.
An RGB-Depth (RGBD) camera was placed above the working area to monitor the person’s arms as well as the tombstone. The RGB-D camera was calibrated with respect to the robot base, and the point cloud obtained was referred to this new coordinate frame. Taking the robot’s base as reference, two ROIs were defined in the point cloud: the first one to identify the pointing gesture and the second one, containing the tombstone, to identify the cell pointed at on it. The target cell was then obtained by the intersection of the pointing gesture projection and the point cloud corresponding to the tombstone.
There were 12 different positions in the tombstone arranged in 4 rows (labeled from 1 to 4) and 3 columns (labeled from A to C). The external evaluator chose on the spot which position had to be pointed at (e.g. A1 and B3). The worker then pointed at it, and the system identified the target position and generated the robot movement to place the tool center point in front of the corresponding position. This was repeated twice for each of the 12 possible positions, in a random sequence.
The sequence is presented in Figure 8: on the left picture, the worker is pointing at one of the 12 possible target positions in the tombstone and on the right picture, the robot is positioned on the cell pointed at.

Pointing gesture identification validation setup.
Results achieved
Two metrics were used to measure the performance of the system: time needed to identify the pointing gesture and target accuracy.
According to Nielsen, 40 in human–machine interaction, 0.1 s is about the limit for having the user feel that the system is reacting instantaneously, meaning that no special feedback is necessary except to display the result. In addition, 1 s is about the limit for the user’s flow of thought to stay uninterrupted, even though the user will notice the delay. Normally, no special feedback is necessary during delays of more than 0.1 but less than 1.0 s.
The system succeeded in identifying all the target points without any error, employing 0.49 s as an average value for target identification with a standard deviation of 0.11 s. From this, we can already conclude that the performance observed for pointing gesture detection in our implementation was satisfactory for natural interaction. It is important to underline that only 3 of 24 of the gesture identifications required more than 0.5 s. Although we did not record the different styles of performing gestures utilized by the workers, it is possible that this parameter had some influence on the recognition time variations that we observed.
Conclusions and future work
We have presented a semantic-driven multimodal interpreter for human–robot safe collaborative interaction, with a focus on industrial environments. The interpreter relies on text and gesture recognition for request processing. It deals with the analysis of the complementary/contradictory aspects of both input channels, taking advantage of semantic technologies for a more accurate interpretation due to the reasoning capabilities that it provides.
This article has presented the validation of each individual mechanism and the fusion of complementary information provided by both communication channels, that is, voice and pointing gestures. Nine of 18 well-interpreted voice commands can only be disambiguated by using the pointing gesture as a complementary source. For instance, the command “remove that burr” can only be completely disambiguated if the fusion module uses the target position provided by the pointing gesture module. In the coming months and in the context of this project, the use of gestures other than just pointing will be integrated and used for interactions in which the two sources of information are redundant, such as when saying “stop” while raising the hand.
This validation of the whole system performance and its benefits will be measured in real working conditions, in the pilot application at ALFA.
The use of semantic technologies to describe robot characteristics and capabilities as well as the context of the scenario makes this approach generic and scalable: by including the scenario context information and the robot capabilities in the KB, the solution will be ready to reuse without any code modification or recompilation. Even if in very different collaborative scenarios a deeper KB extension would be necessary, potentially no code modification would be necessary to get it working. This approach is, therefore, generic and it can be applied in different industrial scenarios.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: FourByThree has received funding from the European Union’s Horizon 2020 research and innovation program, under grant agreement no. 637095. EuRoC has received funding from the European Union’s Seventh Framework Programme for research, technological development, and demonstration under grant agreement no. 608849.