
Abstract
Traditional manipulator motion planning methods aim to find collision-free paths. But in highly cluttered environments, it is hard to find available solutions. We present a novel motion planning strategy which integrates the sampling-based path planning algorithm with the flexible obstacle avoidance approach for finding the efficient path through changing poses of movable obstacles. Following the resulting path, the manipulator can push the obstacles away and move to the target simultaneously. For dealing with the safety issue of the interaction between manipulator and obstacles, a learning-based motion modeling method is proposed for motion prediction of the obstacles being pushed by manipulator, and then the trained models are utilized in the motion planning. The results from both simulations and real robot experiments show that the proposed method can generate efficient paths which cannot be solved by traditional method.
Introduction
Motion planning is a fundamental problem in robotics. The goal of motion planning is to seek a sequence of pose from the start to the end. We call the sequence of pose as a trajectory. Finding a safe trajectory while avoiding the obstacles is motion planning with obstacle avoidance. Traditional obstacle avoidance method requires to find a collision-free trajectory, in order to guarantee the safety of manipulator and obstacles. However, in some situations, for example, when manipulator fetches something from the refrigerator or from the cupboard with a lot of other things, which is clutter, the contact between manipulator and obstacles is unavoidable. The controller or planner using traditional obstacle avoidance cannot solve this problem.
As shown in Figure 1, when human fetches things from clutter, he may push other obstacles in order to reach the target. Inspired by the human behavior, we present a novel obstacle avoidance method—flexible obstacle avoidance (FOA). By FOA, manipulator can move to the target and push some obstacles simultaneously as well as guarantee the safety of manipulator and obstacles. The motion planning using FOA will solve some problems which were previously unsolvable, for example in clutter, where the contact between manipulator and obstacles cannot be avoided. Using FOA, since the obstacle is pushed to move away, the challenge is how to guarantee the safety of manipulator and obstacles.

Different manipulation path between manipulator and human.
Traditional obstacle avoidance seeks a collision-free path. In traditional obstacle avoidance, in order to guarantee the safety of manipulator and obstacles, the contact between manipulator and obstacles is forbidden. Therefore, the state where manipulator collides with obstacle is unavailable, 1 or manipulator keeps a clearance with obstacle. 2 –4 However, in the environment where the distance between obstacles is smaller than the size of manipulator (such as in clutter), there is no solution to find a path.
Many researchers worked on manipulator motion planning in clutter. There are two ways generally: first, manipulator moves the obstacles to get a clear work space and plans a collision-free path; second, manipulator pushes the obstacles away and moves to the target simultaneously.
For the former, navigation among movable obstacles (NAMO) 5,6 method is used for guiding heuristic search in the computationally challenging domain of motion planning among movable obstacles. Dogar and Srinivasa 7 proposed a framework for push-grasping in clutter based on NAMO. Different from Stilman’s method, Dogar added pushing action and addressed uncertainty of action. In these methods, moving obstacles and moving toward the goal are set as separate steps, resulting in wastage of time.
For the latter, the manipulator moves to target and pushes obstacles away simultaneously. The challenge of this method is to guarantee the safety of manipulator and obstacles while pushing. Miyazawa et al. 8 and Makita and Maeda 9 presented a planning method wherein the manipulator which pushed the object to a goal pose well avoided the obstacles using its multi-finger robot hand.
Different from the above-mentioned pushing method, we don’t consider the accurate force analysis between the manipulator and the obstacle, since in our method the contact part is not limited. In our previous work, 10 we presented a control method to implement FOA. Instead of analyzing the forces of obstacle, a cost space was build to represent the risk while the robot interacts with the obstacle. We enhanced the artificial potential field to represent the risk of pushing, and this potential field was used to ensure the safety of manipulator and obstacles. We used quasi-static to model the potential field. However, the modeling method is complex and inaccurate.
Some other researchers worked on grasping in clutter by predicting the motion of obstacles which interacts with manipulator. In Dogar et al.’s work, 11 they used quasi-static to analyze the pushing process. In Kitaev et al.’s work, 12 they used a simulator to simulate the motion of obstacles. Both their work required the physics model of obstacle for prediction. But the physics model is hard to be acquired.
In this article, we use a learning-based method to model the motion of obstacle interacting with manipulator. The motion model of obstacle is learned from training of manipulator pushing the obstacle. Therefore, the model is obtained by manipulator itself without artificial modeling. Then a sample-based planner is used, and the obstacle state in each sample is predicted by the learned model. Our method abandons the physics model of obstacle and the computation is low.
This article is organized as follows. In “Flexible obstacle avoidance” section, we introduce the idea of FOA, and the architecture of motion planning using FOA is presented. How to learn a motion model of obstacle and use it to predict the motion of obstacle interacting with manipulator is described in “Learning-based motion model” section. In “Motion planning using FOA” section, a sample-based motion planner is designed to implement robot motion planning using FOA based on model learning. The comparative study between a traditional approach[ref 1] and the proposed method is shown in “Simulation” section and “Experiment” section, respectively. Finally, this article is concluded in “Conclusion” section.
Flexible obstacle avoidance
Obstacle avoidance is a fundamental problem in robotics. The aim of obstacle avoidance is to ensure the safety of manipulator and obstacles. So the traditional obstacle avoidance method is conducted to find a collision-free path to avoid contact between manipulator and obstacles. But in some special situations, for example, letting the manipulator fetch something from the refrigerator or cupboard with a lot of other things, where the environment is clutter, the manipulator cannot find a collision-free path. Usually, there are two ways to solve this problem. In one way, the manipulator moves other things (called movable obstacle) to another place and clears the path to get the target. Many researchers worked on this method. 5 –7 However, this method requires extra space to keep the movable obstacle, and lot of steps are involved in picking and placing the movable obstacles. So this method results in wastage of time and space. In the other way, the manipulator moves to the target and pushes the obstacle to clear a path simultaneously. We called this method as FOA. Since two actions are performed at the same time, this method saves time and space.
The challenge of FOA is to guarantee the safety of manipulator and obstacles. When manipulator pushes the obstacles, it can result in dangerous situations. For example, obstacles may be toppled, collide with each other, or fall over. So the motion of manipulator should be restricted to avoid such risks.
In this article, we use a sample-based method to plan the motion of manipulator and predict the motion of obstacles in each sample. If the prediction of a sample indicates danger, then the sample is avoided.
Figure 2 is a scene with a manipulator and a few obstacles. The hammer in the scene indicates the target of this task (as a green point in the trajectory). The red “wall” is used to limit the work space. The point cloud is obtained and the semantic map 13 is generated. The semantic map contains the motion model of obstacles. With the motion model, the motion of obstacles pushed by manipulator can be predicted. Then rapidly exploring random trees (RRTs) algorithm is used to sample the whole work space to find an available path. In each step of sampling, the motion of obstacles is predicted. Finally, an available path is found.

Schematic diagram of motion planning using flexible obstacle avoidance. The proposed method is separated into two parts: model learning and motion planning. In model learning, each object is trained by interaction with the manipulator (a to c), and the translation and rotation of object and manipulator are recorded in the data set (d to f). The motion model (g to i) of object under interaction with manipulator is calculated from the data set. In motion planning, the point cloud (k) of experiment scene (j) is obtained by the sensor, and the semantic map (l), including the pose of object and the motion model of object, is generated. Then a sampling-based motion planning algorithm (m) is used to sample the pose of manipulator and predict the motion of objects. The unavailable state, such as the toppled object (n) or out of work space (o), will be abandoned. An available trajectory (p and q) will be found and manipulator will move following the trajectory (r).
How to predict the motion of obstacle is another problem. Some researchers used physics-based method to predict the motion of obstacles. Hence, an accurate physics model is needed for prediction. However, the accurate physical model is hard to be acquired. Using physics-based method requires high volume of computation. 12 So Dogar et al. 11 precomputed the motion and established a database. However, precomputing the database needs huge storage space otherwise it cannot cover all situations. In our method, learning-based approach is used to the motion model of obstacles. Instead of using an accurate physics model as a priori knowledge, a learned model can be obtained by manipulator itself.
Learning-based motion model
Unlike the traditional obstacle avoidance, the obstacles are moved by the interacting with manipulator using FOA. Therefore, the prediction of the motion of obstacles under the interaction of manipulator is the key step in our proposed method. The problem is to predict the trajectory of obstacles by giving the initial pose of obstacles and a trajectory of manipulator. There are many methods to solve this problem. A simulation can be used to compute the motion of obstacles. 12 However, the accurate physical model of obstacles is hard to be acquired, and a real-time simulation needs heavy computation. Additionally, simulating the multiple rigid bodies’ contacting problem is an NP-hard (non-deterministic polynomial-time hard) problem. 14 Quasi-static pushing 11 is a simplification of the above problem, which is less computational. But both of them need the accurate physical model. Similar to our idea, Kopicki et al. 15 proposed a learning method to predict the motion of the object pushed by the manipulator. However, the implementation methods are different and we focus on the integrated algorithm of FOA.
Considering the motion model of obstacle interacting with manipulator as a black box model, the physical process during the interaction between obstacle and manipulator can be ignored. The motion model is shown as

where o is the pose of the obstacle and u is the interaction between manipulator and the obstacle.
In order to simplify the variables of motion model, considering o as object current state and

When the manipulator contacts the obstacle, the speed of obstacle

Combining equation (2) with equation (3), and setting τ as 1, we get

Although the motion model
In machine learning, 16 GMM is used for supervised learning and regression. In robotics, GMM is a useful tool for robot learning from demonstrations. 17 In our approach, GMM is used to estimate the motion model of obstacles by a training set.
We assume the joined variables

where

where d is the dimensionality of the vector v. The mean vectors μk and covariance matrices Σk can be separated into their respective input and output components


The GMM is trained by k-means and EM (expectation-maximization) algorithm.
18
The k-means is used to find the center of each Gaussian model, while the mean and the covariance of each Gaussian model are calculated by EM algorithm. The GMM motion model generates a joint probability density function for u and o, so that the probability of o conditioned on u is a GMM model. Therefore, the estimated

where hk(u) is given by

The tilde sign means expectation values.
The motion model of obstacle is used to compute the obstacle trajectory under the following assumptions: All obstacles lay on a plant surface. The manipulator moves at a low speed, so dynamics is not considered. The obstacle’s geometry, frictional, and mass properties are invariant. The manipulator contacts the obstacle with only one point. Do not consider multiple obstacles contacting problem. No bounce (obstacle always contacts with the manipulator once they contact each other).
As shown in Figure 3,



Diagram of the parameters of the motion model.
Since the predictor works only when the manipulator touches the object, it cannot predict the motion of object if the object is toppled. But the predictor knows whether the object is toppled by the threshold of inclination of the object, which is recorded when the object is toppled in training.
Motion planning using FOA
Our solution has three parts: training, recognition, and planning. First of all, the GMM model is trained off-line: setup the system, including manipulator and one obstacle, and control manipulator to push the obstacle from different directions. The trajectories of manipulator and the obstacle are recorded as a training set
Semantic mapping
Semantic map provides the semantic and geometrical information of recognized objects. Semantic information includes category, size, color, and other properties as well as the motion model of this object.
Our semantic mapping method mixes rule-based reasoning and recognition. For room-level structure extraction, the object is larger than the view range of the sensor, and the observation is incomplete and only captures a part of object. This object usually lacks features of recognition, such as a wall. However, this object usually conforms to special shape rules and can easily be extracted by the reasoning-based method.
Reasoning-based method has two steps. First, the input 3-D point cloud is segmented into candidate units by shape. Usually, for the room-level structure such as wall, floor, cell, and door, candidate units are plane. Then, features of candidate units are extracted. Taking plane as an example, the features include area, size, and position. And features of relationship such as the connectivity and relative position between two planes are also used in reasoning. A forward chaining is used to reason the category and other semantic information of an object.
For the details of this method, please refer to our previous works. 13,19
Sampling-based motion planning
Our planner is based on RRTs algorithm. 1 RRTs algorithm can generate a tree covering the state space of manipulator by random sampling in the state space. Usually, each node in the tree stores the state of manipulator. However, in our method, the environment is changing when the manipulator is moving. Therefore, we have to store the state of environment in addition to the state of manipulator. The state of environment contains the pose of obstacles oi. As shown in Algorithm 1, there are four kernel steps in the proposed planner: SAMPLING, NEAREST_NEIGHBOR, NEW_STATE, and CHECK_AVAILABLE.

First, SAMPLING step samples in the state space to get a random state xrand. Since we use a two-link manipulator as an example, the state space in our method is in xoy plane limited by work space of manipulator. SAMPLING step directly returns xgoal in a rate a, otherwise returns a sample in the whole work space by uniform distribution. In this article, a is set at 0.2.
Second, NEAREST_NEIGHBOR finds a node xnear in the existing trees which is the nearest to xrand. In our method, Euclidean distance is used to compute the distance between xnear and xrand.
Third, NEW_STATE computes the system state of new node. In our method, the system state contains two parts: manipulator state and environment state. For manipulator state, if the distance between xnear and xrand is shorter than δ, the new node xnew is set as xrand. If not, the new node xnew is set as the node on the direction from xnear to xrand with a distance δ. For environment state, new oi is estimated by equation (4) where u is computed by xnear and xnew. As shown in the middle-bottom of Figure 2, environment state is predicted in each step.
Finally, CHECK_AVAILABLE checks whether xnew is available by the following rules: No obstacle is toppled. No multi-obstacle contacts. No obstacle falls over.
If xnew is available, xnew and the edge between xnew and xnear are added to the tree. If not, the algorithm returns to SAMPLING step and finds a new xrand.
When K nodes have been sampled or the last node arrives xgoal, the algorithm is terminated. If the last node arrives xgoal, the edges connecting from xinit to xgoal is the path, following which manipulator can move from the start pose to the target safely.
Simulation
In this approach, the control software is based on robot operation system (ROS) 20 and point cloud library (PCL). 21 Gazebo is used as the simulator. The control processes and user interface are programed in ROS. The semantic mapping is realized with PCL. Gazebo can simulate the physical world with collision and force between different objects. Sensor can also be simulated in Gazebo. ODE (open dynamics engine) 22 is the default engine of Gazebo.
The simulated environment is shown in Figure 4. A two degrees of freedom (DoFs) manipulator is used (on the right of Figure 4, which is indicated in orange and black). The two joints of manipulator are along the vertical axis and the end effector of manipulator can move in horizontal plane. The work space of the end effector is limited by the red box. The red cube in the red box indicates the target of task. Several objects are used to simulate the obstacles. The centers of mass of the objects are the same with the geometry centers. Objects are put on a table to simulate the friction force which is necessary to test the pushing motion. And a simulated Kinect is used as a sensor to obtain the environment information (in the upper left corner of Figure 4).

Simulated environments.
Training
In the training, only one obstacle is left on the table. The manipulator moves in random path and pushes the obstacle. The pose of obstacle is got from the ground truth feedback (a visual position sensor) from the simulator. The trajectories of manipulator and obstacles are recorded and the trajectory is split into slices. In each slice, the end effector moves 1 mm. The motion of obstacle and manipulator is computed in each slice, which constitutes the training data set.
For each obstacle, the training data set contains more than 50,000 slices.
Result of object motion prediction
The performance of object motion prediction is tested on three objects: a beer can, a Coke bottle, and a milk box (as shown in Figure 4). We test one object in five random motions and recode the trajectories. Then the predicted trajectories are made with the GMM model of the object. The comparison between real trajectory and predicted trajectory in both translation and rotation is shown in Figures 5(a) to 7(a) and Figures 5(b) to 7(b). The dash lines in Figures 5(a) to 7(a) and Figures 5(b) to 7(b) are the real trajectories of object, and the solid lines are the predicted trajectories from the same start position. The comparison result shows that the predicted trajectory almost always follows the real trajectory, and the end pose of object is also almost the same.

The result of object motion prediction of a Coke bottle. (a) Comparison between real trajectory and predicted trajectory in translation of a Coke bottle. (b) Comparison between real trajectory and predicted trajectory in rotation of a Coke bottle. (c) The prediction error of translation and rotation under different k.
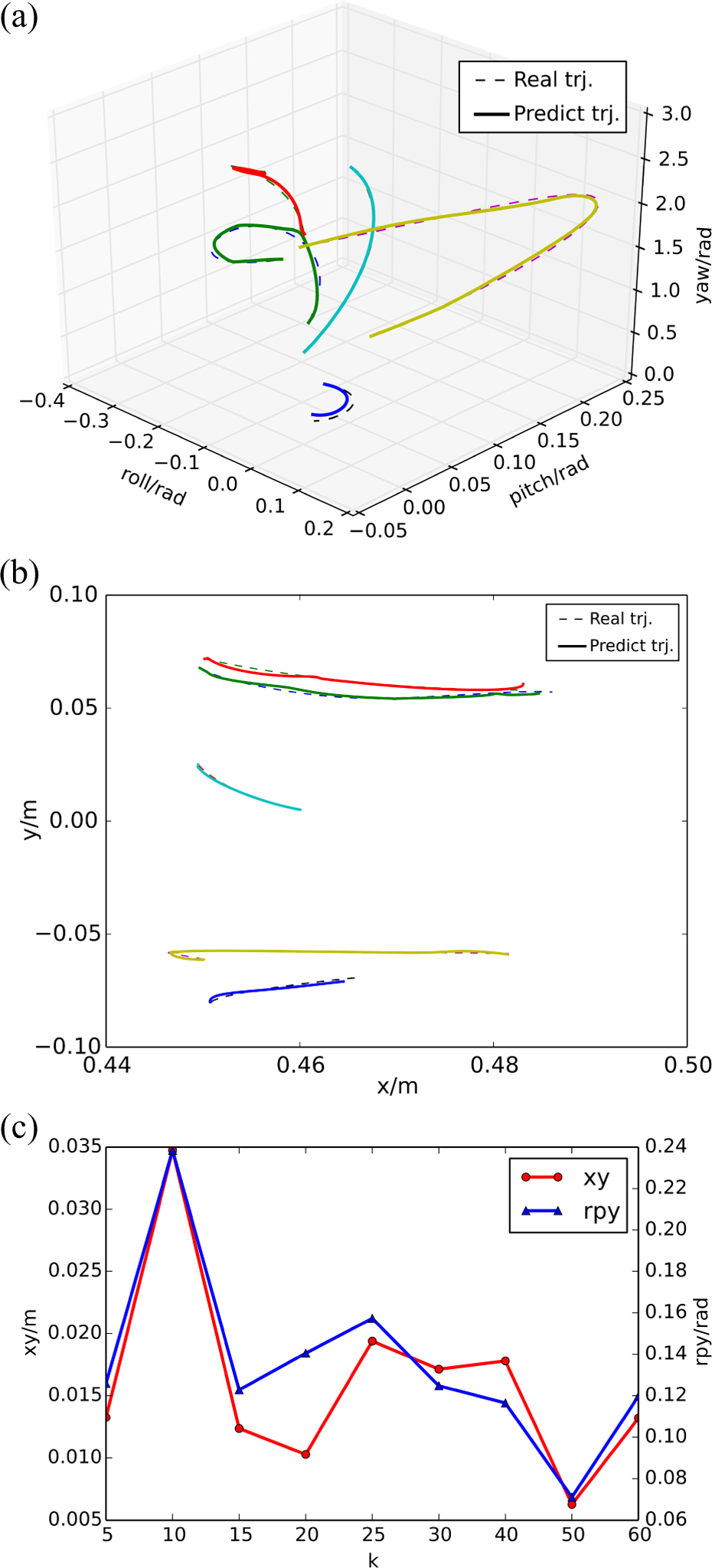
The result of object motion prediction of a beer can. (a) Comparison between real trajectory and predicted trajectory in translation of a beer can. (b) Comparison between real trajectory and predicted trajectory in rotation of a beer can. (c) The prediction error of translation and rotation under different k.

The result of object motion prediction of a milk box. (a) Comparison between real trajectory and predicted trajectory in translation of a milk box. (b) Comparison between real trajectory and predicted trajectory in rotation of a milk box. (c) The prediction error of translation and rotation under different k.
The k is an important parameter in GMM model. We discuss the effect of k on the prediction error. The prediction error, including translation error and rotation error, is the average of all the absolute error on each step between real trajectory and predicted trajectory. As shown in Figures 5(c) to 7(c), the general trend is that as k increases, the error decreases. However, with k increasing, the system real-time performance reduces. In this article, k is set as 50.
Because of the accuracy of prediction, the manipulator does not keep touching the object during the prediction. The manipulator may leave the object or penetrate the object in prediction. When the manipulator leaves with object, the point on the manipulator that is closest to the object is used as the contact point. When the manipulator penetrates the object, the point on the manipulator which is the farthest from the surface of the object is considered as the contact point. Therefore, the predictor still works when the manipulator does not touch the object, and the comparison result shows the effectiveness of prediction.
Result of motion planning
Work space of test (the red box in Figure 8) is about 0.9 m long and 0.54 m wide. The manipulator and obstacle cannot move out of the work space. Target pose of robot is indicated by the red cube. The poses of obstacles are generated randomly.

Simulation task 1.
A scene set with 100 random scenes is generated. 27% scenes of the set can be solved by traditional obstacle avoidance (the RRTs method in reference 1 is used) and all of them are executed successfully. Our method can find the solution for 79% scenes and 89.9% of them are executed successfully. As shown in Table 1, success ratio, toppling ratio, and colliding ratio are based on the solved scenes. Compared with traditional method, our approach can solve more scenes although the solution of our approach may fail in executing. Toppling ratio is higher than colliding ratio, since predicting the rotation motion is more difficult than transform motion.
Outcome comparison of the traditional motion planning and the proposed approach.

In Figures 8 to 12, five successful scenes are shown. The subgraph (f) shows the trajectory of manipulator and obstacles, in which red rectangle indicates the work space, red marker represents the target, white points are trajectory of manipulator end effector, and blue markers are trajectory of obstacles. The subgraphs (a to e) show the execution scenario in chronological order.

Simulation task 2.

Simulation task 3.

Simulation task 4.

Simulation task 5.
Experiment
We performed experiments on an ABB IRB 120 23 manipulator. As we assumed in the previous sections, a tube is equipped on the end of arm as an end effector, and the motion of end effector is limited in xoy plane. The box simulates a restricted work space and the red can indicates the target of this task. The Kinect in the right of Figure 13 is used in this experiment (the Kinect on the arm is not used).

Experiment environment.
Since highly precise pose of the object is needed in training, the model used in experiment is trained in simulator. An object model is built in the simulator with the similar shape, mass, moment of inertia, and coefficient of friction as the real object, and the object model is used to train the GMM model which is used in experiment.
The arrangement of obstacles is randomly set by human. Pose and category of the obstacle are detected by our semantic mapping method. The pose and category are fed to the FOA motion planner in order to set the position of GMM motion models. Our motion planer generates the Cartesian path of end effector and sends the path to the controller of manipulator. Five examples of the successful execution results from experiments are shown in Figures 14 to 18. Task 1 and task 2 are easy with three obstacles, of which only one moved. There are at least two obstacles moved in other examples. In Figure 16(b), the white bottle is tilted. All of these five tasks have no solution using traditional method.

Experimental task 1. It is an easy task with three obstacles, and only one obstacle is moved. The milk box is rotated with an angle and manipulator moves through the space after the milk box is moved.

Experimental task 2. It is an easy task with three obstacles, and only one obstacle is moved. The juice bottle is slided with a distance and manipulator moves through the space after the juice bottle is moved.

Experimental task 3. It is a hard task with five obstacles, and two obstacles are moved. The candy bag is rotated with an angle and the yogurt bottle is tilted a little.

Experimental task 4. It is a hard task with four obstacles, and two obstacles are moved. Both milk box and chips bottle are slided in a distance.

Experimental task 5. It is a hard task with four obstacles, and two obstacles are moved. Both juice bottle and beer bottle are slided in a distance.
Conclusion
In this article, we presents manipulator motion planning strategy using FOA based on model learning. Flexible obstacle avoidance is a novel obstacle avoidance method, by which manipulator moves to the target and pushes the obstacles away simultaneously while the safety of manipulator and obstacle is guaranteed. And the motion model for prediction is learned from experiments by manipulator itself. The sample-based motion planner computes the states of obstacles and manipulator to check the availability for each sample. The results from both simulations and real robot experiments show that the proposed method can generate efficient paths which cannot be solved by traditional method.
There are several open problems for future work. In this work, one of the assumptions is that the obstacle is pushed by only one contact point. Under this assumption, our approach cannot solve the problem with multiple objects contacting. For example, the pushed obstacle may also contact other obstacles. Our approach cannot solve such problem. Another open problem is the motion planning for a multi-DoF manipulator. Since our approach is a variant of sample-based motion planner, it is possible to be applied to multi-DoF manipulator. A SCARA-like manipulator is used in our approach because the manipulator contacts the obstacle with the same part, which is easy to compute the position of contact point. Technically, if the geometry model of manipulator and obstacle is known, it is possible to get the position of contact point. Therefore, our approach is suitable for any manipulator. How to avoid the manipulator penetrating the object in the prediction is also a problem. Training and result statistics in real experiments will be performed in the future.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is partly supported by the Natural Science Foundation of China under grant 61573243 and the Science and Technology Commission of Shanghai Municipality under Grant 15111104802.