
Abstract
Although the importance of contextual information in speech recognition has been acknowledged for a long time now, it has remained clearly underutilized even in state-of-the-art speech recognition systems. This article introduces a novel, methodologically hybrid approach to the research question of context-dependent speech recognition in human–machine interaction. To the extent that it is hybrid, the approach integrates aspects of both statistical and representational paradigms. We extend the standard statistical pattern-matching approach with a cognitively inspired and analytically tractable model with explanatory power. This methodological extension allows for accounting for contextual information which is otherwise unavailable in speech recognition systems, and using it to improve post-processing of recognition hypotheses. The article introduces an algorithm for evaluation of recognition hypotheses, illustrates it for concrete interaction domains, and discusses its implementation within two prototype conversational agents.
Introduction
Human speech recognition makes extensive use of the listener’s expectations of what the speaker could say in the current situation. To maximize recognition accuracy, the listener takes into account contextual information related to domain of interaction, interlocutors’ intentions, history of interaction, and so on. Thus, it appears uncontroversial that, if we aim at reducing the existing performance gap between humans and conversational agents, our systems should integrate contextual information as well. Still, contextual information remained clearly underutilized, even in state-of-the-art speech recognition systems. This article addresses this desideratum. It introduces a novel, methodologically hybrid approach to the research question of context-dependent speech recognition in human–machine interaction. In addition, the proposed approach is illustrated with two prototype conversational agents.
The rest of the article is organized as follows. ‘Related work and contributions of this article’ summarizes relevant research, points out the disadvantages of the currently dominant approaches relying on the currently prevalent statistical paradigm, and motivates extensions to these approaches. ‘Revising the focus tree model’ provides a framework for our approach. ‘Algorithm for evaluation of recognition hypotheses’ introduces the algorithm for evaluation of recognition hypotheses. ‘Prototype A: Illustrating the algorithm’ reports on a prototypical speech recognition system and practically illustrates the introduced algorithm. ‘Prototype B: Assessing the accuracy of the algorithm’ reports on another prototype speech recognition system and assesses the accuracy of the algorithm. ‘Conclusion’ discusses the computational appropriateness and generalizability of the proposed algorithm.
Related work and contributions of this article
The proposed approach makes contributions in two aspects: the methodological development and the architectural organization of conversational agents.
The methodological aspect
The reasons for the underutilization of contextual information in automatic speech recognition lie in the methodology. Currently, the dominant approaches are statistical. Much of the popularity of the statistical pattern-matching paradigm among researchers is due to the fact that it does not require deep understanding of a particular language or the human language processing system to produce practical speech recognition systems. At the same time, it is precisely this feature that makes the statistical approaches inappropriate for addressing the more general research question of modelling context in human–machine interaction. The reason is quite simple and often unduly neglected. Linguistic corpora that are used to train statistical models cannot encapsulate all relevant context-dependent dialogue phenomena, such as various cohesive relations between dialogue acts, and so on. 1 , 2
Statistically based speech recognition is, of course, not entirely without a context. However, its context is significantly reduced. In commonly used statistical approaches – based on the Bayesian conceptualization of probability, n-grams, hidden Markov models, and so on – the research question of recognition of utterance W is reduced to the question of finding the most probable sequence of words

Probabilities P(X|W) and P(W) are derived from the underlying acoustic and language models, respectively. Both these models are corpus-driven, that is, equation (1) returns the most probable sentence out of all feasible sentences in a given search space
(i) Acoustic models take into account an intra-word context. The observation likelihood P(X|W) in equation (1) represents the likelihood of the observed acoustic feature vectors derived from speech signal X for given linguistic units contained in a sentence of words W. To estimate P(X|W), the user’s utterance is matched against acoustic representations of words in a system’s vocabulary. Each word is defined as a sequence of phone-like units, and represented by a hidden Markov model whose states correspond to these units. A common conceptualization of phone-like units is the triphone model that represents a current phone with its left and right phone contexts in a given word. In other words, acoustic models make use of only phone context.
(ii) Language models take into account intrasentential context. The prior probability P(W) in equation (1) represents how likely a sequence of words W is to be in a given language. The estimation of this probability is based on n-grams language models. The underlying assumption is that the probability of a word only depends on the previous n − 1 words, where n is finite. For most practical applications of n-grams, n is set to two or three (i.e. bigrams and trigrams), which reduces the context to one or two preceding words. In any case, n-gram language models capture, in terms of probability, syntactic rules covering a word’s usual place in a sentence, but do not account for lexical correlations between dialogue acts, or for semantic roles of words.
(iii) Neither of these models take into account contextual information at the dialogue level. The lack of dialogue context is evident even for extremely large training data sets containing billions of words. 4 It is a significant factor that makes speech recognition systems too restrictive, even for cooperative users. 5 , 6 Thus, despite the substantial improvements in the last two decades, speech recognition systems still suffer from robustness problems when applied beyond the scope of training corpora. Degraded acoustical conditions (e.g. background noise), foreign accents and unexpected topic shifts are just some of the causes of critical recognition errors. 7 , 8 Recent approaches to automatic speech recognition recognize the importance of accounting for contextual information. However, they still rely on the statistical paradigm or account for a context in an ad hoc (i.e. domain-dependent) manner. 9 –13
To reduce the limitations of the statistical approach, we employ a representational approach based on the focus tree model of attentional information in human–machine interaction. Various adaptations of this model were successfully applied in several prototypical conversational agents for the purposes of natural language understanding and dialogue management. 2 , 14 –16 However, in this contribution, we extend it for the purpose of modelling and dynamically prioritizing contextual information in automatic speech recognition (see ‘Revising the focus tree model’ and ‘Algorithm for evaluation of recognition hypotheses’).
The architectural aspect
Approaches to computational architectures of conversational agents vary a great deal with respect to the underlying practical requirements, with no agreement between researchers on the most productive approach. At one end of the scale is a typical architecture of a conversational agent, depicted in Figure 1, that is often mentioned in the literature (Jurafsky and Martin, 3 pp. 821–822 and Jokinen and McTear, 17 pp. 4–5). This architecture contains six modules, each of which corresponds to a certain cognitive aspect underlying the human language processing system. The speech recognition and natural language understanding modules extract meaning from the user’s input. The dialogue management module controls the dialogue flow. It accepts interpreted dialogue acts as input, interacts with external knowledge resources (e.g. a task management component), decides on which dialogue acts should be generated, formulates their meaning, and so on. The natural language generation and speech synthesis components map from meaning to speech. This architecture is rather general, that is, not based on particular requirements. It encapsulates the common foundation of different conversational agents, and can be adapted to various conversational scenarios.

At the other end of the scale, there are a number of more elaborate architectures in terms of an increased number of modules that implement additional functional requirements (e.g. emotion recognition, multimodal interaction, etc.). The requirements on such architectures arise from particular scenarios of use. The advantage of these architectures is that they are based on (more or less) well-defined requirements. The disadvantage is that they are not really applicable to other scenarios. The trade-off between the two ends of the spectrum is apparent, and researchers tend – for obvious practical reasons – to focus on scenario-specific design.
However, it is important to emphasize that speech recognition modules are usually architecture-agnostic all over this scale. In other words, the research question of speech recognition is usually considered outside of an architectural context. The researchers take into account dimensions of variation in speech recognition tasks such as vocabulary size, fluency of speech, variation in channel and noise, and speaker-class characteristics. 3 Still, none of these dimensions is related to the architecture of a conversational agent. The only specification requirement related to the architecture is that a speech recognition module should take audio input and return a string of words.
In our approach, the speech recognition and natural language understanding modules are not independent. The novel architectural aspect of a conversational agent is depicted in Figure 2. It deviates from the standard architecture in that it recognizes the feedback loop between the speech recognition and natural language understanding modules. This enhancement of the standard architecture is derived from one particular aspect of the reported methodological approach – the modules for speech recognition and natural language understanding share the same contextual representations, that is, a focus tree. In this architecture, automatic speech recognition includes two submodules:
a standard speech recognizer (i.e. statistically based and dialogue-context-independent) that provides a set of speech recognition hypotheses;
the representational and dialogue-context-dependent evaluator of recognition hypotheses introduced in this article.

Feedback loop between the speech recognition and natural language understanding modules.
The following section provides a framework for our approach.
Revising the focus tree model
Focus tree is a cognitively inspired representational computational model of working memory. In contrast to other computational models of working memory, the focus tree model is intentionally designed to capture the meaning of spontaneously produced linguistic inputs in human–machine interaction. For a detailed discussion of this model, the reader may consult Gnjatović and Delić, 14 , 15 Gnjatović et al., 16 and Gnjatović and Borovac. 2 This section considers only selected aspects of the model that are important for this contribution.
A focus tree is a hierarchical structure that supports a cognitive conceptualization of working memory as a functional state that allows direct access to the activated part of long-term memory. 18 Each node of a focus tree represents a specific semantic entity in the long-term memory. Each top-down path starting at the root node is a mental representation. For example, if node n2 is a descendant of node n1, it means that the mental representation assigned to node n2 integrates and extends the mental representation assigned to node n1. At every moment of interaction, the current focus of attention is placed on exactly one node of the focus tree. In other words, the focus of attention corresponds to the currently activated mental representation. If the focus of attention is placed on node n, this means that the semantic entities represented by node n and its antecedents are retrieved in the working memory.
Without loss of generality, we illustrate this model for the dialogue domain of one of the prototype conversational agents reported in this article. This prototype system manages natural language interaction between the user and a robotic system intended to be used as an assistive tool in therapy for children with cerebral palsy 19 (see Figure 3). Here, we consider the following simplified interaction domain:

The head of the assistive conversational robot MARKO. 19
the robot can move in four directions: forward, backward, left and right;
the robot can separately open and close its eyes.
The focus tree that represents this interaction domain is depicted in Figure 4. Each node of the focus tree, except the root node, represents an activated mental representation (see the first two columns of Table 1). It should be noted that only mental representations assigned to terminal nodes contain all the necessary information that the conversational agent needs to unambiguously determine the user’s dialogue act.

The focus tree representing the simplified interaction domain.
Mental representations and vocabulary assigned to the focus tree.

The focus tree model also encapsulates a vocabulary. Each node is assigned a set of keywords and nonrecursive phrases that, at the surface level, explicitly relate to it (see the third column of Table 1). For example, keyword ‘step’ is assigned to node M, while keyword ‘open’ is assigned to nodes ⊙ L and ⊙ R . We refer to these words and phrases as focus stimuli.
The processing of the user’s dialogue acts in human–machine interaction is always context-dependent, that is, the currently activated mental representation (i.e. the focus of attention) is updated with the dialogue act of the user. The algorithm for mapping the user’s dialogue acts is discussed by Gnjatović and Borovac,
2
Gnjatović and Delić
14
and Gnjatović et al.
16
in detail. At the processing level, the focus tree model differentiates between four types of dialogue act: complete dialogue act – the updated focus of attention is assigned to a terminal node; incomplete dialogue act – the updated focus of attention is assigned to an inner node; ambiguous dialogue act – the updated focus of attention may be assigned to more than one node; semantically irregular dialogue act – the semantic representation of such a dialogue act does not match any mental representation encapsulated in the focus tree. Since the focus of attention cannot be assigned to any node of the focus tree, it is placed on the root node.
Based on the focus tree model, two electrophysiologically inspired parameters of dialogue act complexity – the retrieval (ρ) and integration (η) costs – are introduced by Gnjatović and Delić 15 and revised by Gnjatović and Borovac. 2 To the extent that these parameters are electrophysiologically inspired, they mimic the values of the N400 and P600 components of electroencephalographic signals, respectively. 20 –23 Following Gnjatović and Borovac 2 and Gnjatović and Delić, 15 the retrieval (ρ) and integration (η) costs are defined as follows


where:
n – node of the focus tree;
nFA – node that represents the currently activated mental representation (i.e. the current focus of attention);
N– set of all nodes that may represent the updated mental representation when a user’s dialogue act is processed; A(n) – set that contains node n and all of its ancestors in the focus tree; T(n) – set that contains all terminal nodes that are descendants of node n (if n is a terminal node, T(n) = ∅);
At the conceptual level, the retrieval cost (ρ) reflects the cognitive load related to the retrieval of lexical information from long-term memory, and the integration (η) costs reflects the cognitive load related to the semantic integration of the activated lexical information. 2 , 15 We discuss these conceptualizations in the context of the focus tree model.
For any given moment of interaction, the current focus of attention nFA represents the activated mental representation, and set A(nFA) represents the content of working memory. When an ensuing dialogue act is processed, each node n ∈ N may represent the updated mental representation. This means that mental representations assigned to nodes in set union
To discuss the conceptualization of the integration cost, we recall that a mental representation assigned to an inner node of a focus tree is incomplete. To complete such a mental representation, the focus of attention must be transited to a terminal node that is a descendant of the observed node. In other words, the integration cost of node n is equal to the number of elements in set T(n), that is, the number of all terminal nodes that are descendants of node n. In a general case, when a dialogue acts is processed, set N contains all nodes that may represent the updated mental representation, so the integration cost of the observed dialogue act in a given moment of interaction is equal to the number of elements in set union
The values of the retrieval and integration costs always lie within the range [0,1]. The minimum value of the retrieval cost signals that the processing of a dialogue act either did not change the currently activated mental representation (i.e. the focus of attention remains on the same node), or that it reduced it (i.e. the focus of attention is transited on some of its ancestors). The minimum value of the integration cost signals a complete dialogue act. It means that the focus of attention is placed on a terminal node, and that the conversational agent has all the necessary information to unambiguously determine the user’s dialogue act. For both parameters, the maximum value of 1 signals a semantically irregular dialogue act – in this case, the focus of attention is placed on the root node. The values between zero and one evaluate incomplete and ambiguous dialogue acts. To the extent that these parameters are context-dependent, their values depend not only on a focus tree (i.e. the interaction domain) and a vocabulary, but also on the current focus of attention (i.e. history of interaction).
For the purpose of this contribution, we introduce the third parameter of dialogue act complexity – the lexical matching (λ). The lexical matching of a dialogue act depends only on a vocabulary encapsulated in a focus tree. For a given dialogue act, the value of this parameter is equal to the ratio of the number of words in the dialogue act that belong to the vocabulary over the dialogue act length. For the focus tree described in Table 1, the lexical matching of dialogue act ‘please
Algorithm for evaluation of recognition hypotheses
The input parameters of the algorithm for evaluation of recognition hypotheses are:
F – focus tree describing a given interaction domain and a vocabulary; nFA – focus of attention, describing the currently activated mental representation;
The output parameter is recognition hypothesis
The main idea underlying the algorithm for evaluation of recognition hypotheses can be summarized as follows. The system reduces the set of recognition hypotheses according to the following selection criteria.
Criterion 1 – Minimum semantic integration difficulty. The system selects the recognition hypotheses with the minimum semantic integration difficulty, that is, the minimum integration cost. If there is only one such hypothesis, it is selected as the most probable in the given context. Otherwise, the second criterion is applied.
Criterion 2 – Maximum new information. From the subset of recognition hypotheses with the minimum integration cost, the system selects hypotheses that provide the maximum new information, that is, the maximum retrieval cost. In other words, for a set of dialogue acts of equal interpretation difficulty, the system prefers a dialogue act whose interpretation is the most informative in a given context. If there is only one such hypothesis, it is selected as the most probable in the given context. Otherwise, the third criterion is applied. Note that our notion of new information is in line with Halliday’s distinction between Given and New in information structure in spoken language; see Halliday,
24
p. 91. According to him, given information is presented by the speaker as recoverable from the preceding discourse (e.g. mentioned before), while new information is non-recoverable (e.g. not mentioned before, unexpected, etc.). Still, while Halliday relates to phonological categories, we relate to semantic categories.
Criterion 3 – Maximum lexical fit. From the subset of recognition hypotheses with the minimum integration cost and the maximum retrieval cost, the system selects hypotheses with the maximum lexical matching. If there is only one such hypothesis, it is selected as the most probable in the given context. Otherwise, the last criterion is applied.
Criterion 4 – Maximum probability of occurrence. From the subset of recognition hypotheses with the minimum integration cost, and the maximum retrieval cost and lexical matching, the system selects the recognition hypothesis that is assigned the highest probability by the automatic speech recognition system.
Now we can introduce the actual algorithm. For the purpose of easier representation, we define
1. Group the recognition hypotheses according to the anticipated update of current mental representation. We define the following equivalence relation ≃ on the set of recognition hypotheses

In other words, the set of recognition hypotheses

If there is only one equivalence class
2. For each equivalence class H, calculate the integration cost η(H) and retrieval cost ρ(H).
From definition (4), it follows that all recognition hypotheses in an equivalence class have equal integration and retrieval costs
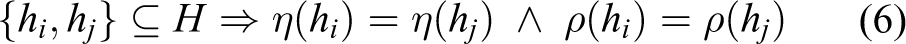
We refer to these values as η(H) and ρ(H).
3. Select the equivalence classes with the minimum integration cost, that is, the classes with the minimum semantic integration difficulty

If there is only one equivalence class Hx ∈ I with minimum integration cost, jump to step 4. Otherwise, jump to step 5.
4. Select recognition hypotheses from equivalence class Hx with the maximum lexical matching
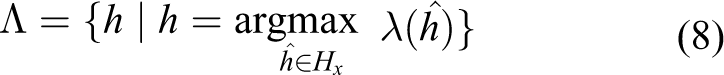
then jump to step 7.
5. If there is more than one equivalence class with the minimum integration cost, select the classes among them with the maximum retrieval cost, that is, the classes that provide the maximum new information

6. Select recognition hypotheses from equivalence classes in set Q with the maximum lexical matching
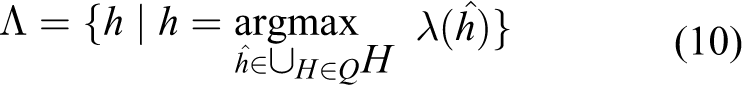
7. Select the recognition hypothesis hχ from set Λ that is assigned the highest probability by the automatic speech recognition system

Terminate the algorithm.
The next section illustrates the implementation of the introduced algorithm in the prototype conversational agent that manages dialogue between the user and the robotic system intended to be used as an assistive tool in therapy for children with cerebral palsy (see Figure 3).
Prototype A: Illustrating the algorithm
The introduced algorithm is implemented for the focus tree and vocabulary whose simplified versions are described in Figure 4 and Table 1. Although the actual focus tree and the vocabulary used by the prototype system are significantly larger, the discussion is, for the purpose of clarity and without loss of generality, focused on their simplified versions. The prototype system also integrates a Serbian large vocabulary continuous speech recognition system 25 trained to recognize words within the vocabulary of 10,000 words. To illustrate that our approach can be applied for an arbitrary speech recognition system, we intentionally use a speech recognition system whose vocabulary is significantly larger than the vocabulary of the observed dialogue domain.
In addition, for a given user’s utterance, this speech recognition system returns up to N best-ranked recognition hypotheses. In our prototype system, we set N to five. For example, during the testing of the prototype system, the set of recognition hypotheses for the user’s dialogue act ‘levo oko zatvori’ (literal translation in English: left eye close) is given in Table 2. The hypotheses are sorted by their probability of occurrence – h1 is the most probable, and h5 is the least probable. Therefore, without taking the dialogue context into account, the speech recognition system would select hypothesis h1, although hypothesis h3 is true.
Recognition hypotheses for the user’s dialogue act ‘levo oko zatvori’ (literal translation in English: ‘left eye close’).
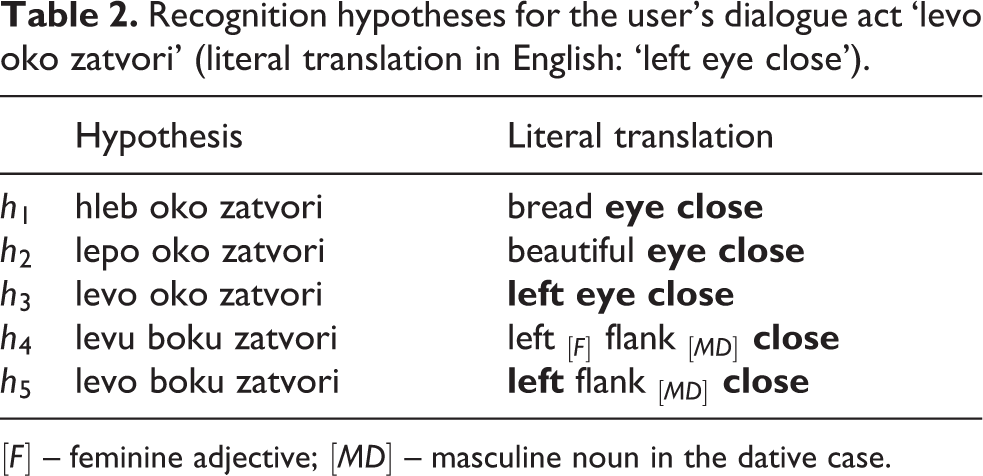
[F] – feminine adjective; [MD] – masculine noun in the dative case.
However, when the dialogue context is taken into account, the interpretation of the recognition hypotheses is changed. To illustrate this, we report on how the prototype system evaluates these hypotheses for three different moments of interaction between the user and the system. All three interaction moments are within the same dialogue domain, described in ‘Revising the focus tree model’. However, they differ with respect to the immediate dialogue history, that is, the current focus of attention. In the first interaction moment, the focus of attention is placed on node S, that is, no particular semantic entity is in the focus of attention. For example, it may be the beginning of interaction between the user and the robot. In the second interaction moment, the focus of attention is placed on node ⊙
R
, in other words, the robot’s right eye has just been opened. For example, the user instructed the robot to open its right eye in his previous dialogue act, or the robot took the initiative and opened its right eye according to its interaction strategy. In the third interaction moment, the focus of attention is placed on node L, in other words, the robot’s left eye has just been brought into the focus of attention. For example, the user mentioned the robot’s left eye in his previous dialogue act, but did not specify an action on it.
Following the algorithm introduced in the previous section, hypothesis h3 is correctly selected for all three interaction moments. However, the execution trace of the algorithm for different interaction moments (i.e. different foci of attention) is worth discussing in more detail.
(i) The algorithm trace for the first interaction moment, that is, the focus of attention is placed on node S.
Although there are five recognition hypotheses, at the semantic level the system differentiates between two equivalence classes. The first equivalence class H11 contains recognition hypotheses h1, h2 and h4. These hypotheses are mapped onto the focus tree in the same way as an ambiguous command that has two possible interpretations: close left eye or close right eye (see Figure 5(a)). The second equivalence class H12 contains recognition hypotheses h3 and h5. These hypotheses are mapped onto the focus tree in the same way as complete command close left eye (see Figure 5(b)). The integration and retrieval costs for the equivalence classes are calculated; see Table 3. The system selects the equivalence class with the minimum integration cost – that is, H12. Recognition hypothesis h3 has the maximum lexical matching in H12, so it is selected in Λ. Since recognition hypothesis h3 is the only element in Λ, it is selected as the most probable in the given context.

When the focus of attention is placed on node S: (a) hypotheses h1, h2 and h4 are mapped onto the focus tree as an ambiguous dialogue act that has two possible interpretations: ‘close left eye’ or ‘close right eye’; (b) hypotheses h3 and h5 are mapped onto the focus tree as complete dialogue act ‘close left eye’.
Evaluation of the recognition hypotheses in the case when the focus of attention is placed on node S.

(ii) The algorithm trace for the second interaction moment, that is, the focus of attention is placed on node ⊙R.
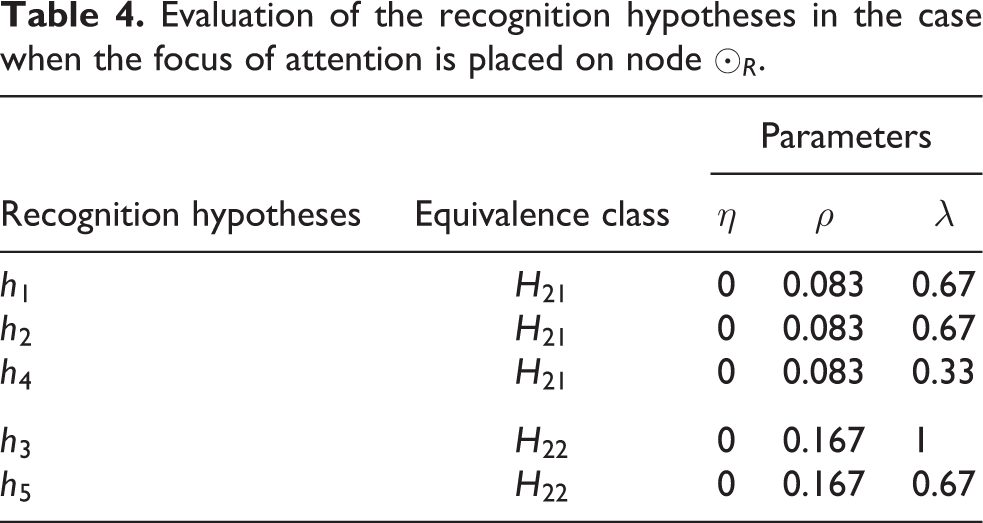
The system differentiates between two equivalence classes. The first equivalence class H21 contains recognition hypotheses h1, h2 and h4. These hypotheses are mapped onto the focus tree in the same way as complete command close right eye (see Figure 6(a)). The second equivalence class H22 contains recognition hypotheses h3 and h5. These hypotheses are mapped onto the focus tree in the same way as complete command close left eye (see Figure 6(b)). The integration and retrieval costs for the equivalence classes are calculated; see Table 4. Both equivalence classes have the same interaction cost, so this parameter is not discriminative in this case. Therefore, the system selects the equivalence class with the maximum retrieval cost – that is, H22. Recognition hypothesis h3 has the maximum lexical matching in H22, so it is selected in Λ. Since recognition hypothesis h3 is the only element in Λ, it is selected as the most probable in the given context.

When the focus of attention is placed on node ⊙ R : (a) hypotheses h1, h2 and h4 are mapped onto the focus tree as complete dialogue act ‘close right eye’; (b) hypotheses h3 and h5 are mapped onto the focus tree as complete dialogue act ‘close left eye’.
Evaluation of the recognition hypotheses in the case when the focus of attention is placed on node ⊙ R .
(iii) The algorithm trace for the third interaction moment, that is, the focus of attention is placed on node L.
In this case, there is only one equivalence class – all hypotheses are mapped onto the focus tree as complete command close left eye (see Figure 7). Recognition hypothesis h3 has the maximum lexical matching in H13, so it is selected in Λ (see Table 5). Since recognition hypothesis h3 is the only element in Λ, it is selected as the most probable in the given context.

When the focus of attention is placed on node L: all hypotheses are mapped onto the focus tree as complete dialogue act ‘close left eye’.
Evaluation of the recognition hypotheses in the case when the focus of attention is placed on node L.

These examples illustrate the fact that the proposed algorithm prioritizes the parameters in the following order: the integration cost, the retrieval cost, the lexical matching and the probability assigned by the automatic speech recognition system. It is clear that the probabilities assigned by the speech recognizer are not reliable in these examples. But it can also be observed that the lexical matching is the most discriminative parameter in these examples – there is only one recognition hypothesis (h3) that has the maximum lexical matching (see Tables 3, 4 and 5), and it also represents the correct recognition hypothesis. The question arises whether the lexical matching of a dialogue act could have been prioritized over the interaction and retrieval costs. It is important to note that the answer is negative. In general, the integration and retrieval costs of a dialogue act depend on the topology of the focus tree (i.e. interaction domain), the vocabulary and the current focus of attention (i.e. history of interaction). In contrast to them, the lexical matching of a dialogue act depends only on the vocabulary – which is a reduced conceptualization of context. If the lexical matching was the most important parameter in the algorithm, the first reduction of the set of recognition hypotheses would be performed taking only the vocabulary into account, while other important aspects of interaction context would be omitted. This conceptual explanation is practically illustrated by the following example. For dialogue act ‘napravi korak levo’ (literal translation in English: make step leftward) uttered during the testing of the prototype system, one of the incorrect recognition hypotheses was ‘napravi oko ka levo’ (literal translation in English: make eye toward left). Although this hypothesis has the maximum possible lexical matching in the given interaction domain (see Figure 4 and Table 1), it is also semantically incorrect – and should not be selected as correct.
Prototype B: Assessing the accuracy of the algorithm
The focus tree observed in the previous section was intentionally small in order to illustrate the proposed algorithm for evaluation of recognition hypotheses in detail. However, two important questions remain to be addressed: what is the accuracy of the proposed algorithm for a realistically sized focus tree, and to what extent does it improve the standard statistically based approach in a realistic scenario? These questions are addressed in this section.
The second prototype system demonstrates automatic speech recognition in the context of a speech-based interface between the user and a mobile phone. 26 The goal of this interface is to enable the user to utter verbal commands to her mobile phone, for example to show the unread messages, to send a message to a person in the address book, to add a note, and so on. This interaction domain is modelled by a focus tree that contains 175 nodes.
To evaluate the performance of the prototype system, we produced a speech corpus. Sixty-four healthy, nave and native speakers of Serbian (31 female, 33 male) participated in the study. Independently of each other, the subjects were instructed to self-select a subset from a set of 85 predefined sentences (see Table 6) and read them over the telephone and cell phone networks. The produced speech corpus consists of 1544 utterances: 772 utterances were recorded using landlines, and 772 utterances were recorded using the cell phone network. The average number of recorded utterances per subject is 24.1, with standard deviation 7.1. The total number of words is 5373. The average number of words per utterance is 3.48, with standard deviation 1.31.
This table shows six of 85 predefined sentences read by the subjects while producing the speech corpus.

The prototype system integrates a statistically based, Serbian large vocabulary continuous speech recognition system trained to recognize words within the vocabulary of 5000 words, and set to return up to five best recognition hypotheses. Similarly to in the previous example, we intentionally used a speech recognition system whose vocabulary is significantly larger than the vocabulary of the observed dialogue domain. In addition, we use the utterances collected over the cell phone network in order to simulate realistic situations as acoustic models underlying speech recognition modules are not usually trained in real-world conditions (including ambient noise, the use of different microphones, variable distance from the microphone, etc.).
The main purpose of the speech recognition performance evaluation was to contrast the statistical approach to speech recognition with the hybrid approach introduced in this article (i.e. including also dialogue-context-dependent evaluation of recognition hypotheses). Therefore, there were four experimental contrasts derived from a 2 × 2 design (see Table 7):
speech recognition was performed either by the statistically based recognizer, or by the statistically based recognizer combined with the context-dependent evaluator of recognition hypotheses;
the performance evaluation of speech recognition was performed either on all sentences comprised in the speech corpus, or only on those sentences from the speech corpus for which the statistical automatic speech recognizer provided a correct recognition hypothesis (which is not necessarily the best-ranked hypothesis).
Four experimental contrasts in a 2 × 2 design.

In all these cases, the speech recognition performance was evaluated by using the National Institute of Standards and Technology Scoring Toolkit. The results reported in Table 8 show that the combined recognizer clearly outperforms the statistically based recognizer.
Evaluation results. All numbers are rounded to the first decimal digit.

The performance of the statistically based speech recognizer may be summarized as follows. It correctly recognized 818 of 1544 sentences (sentence error rate for case STAT-ALL was 47%), and for 980 of 1544 sentences it provided a correct recognition hypotheses which was not necessarily the best-ranked hypothesis. When the performance evaluation was performed on the latter set of 980 sentences, the accuracy of the statistically based speech recognizer was 83.4% (the sentence error rate for case STAT-CORR was 16.6%), while the accuracy of the combined recognizer was 96.5% (the sentence error rate for HYB-CORR is 3.5%).
But even in the cases when the performance evaluation was performed on all sentences from the speech corpus, the combined recognizer performed better (see cases STAT-ALL and HYB-ALL). It should be noted that for 36.5% of sentences (i.e. 1544 − 980 = 564 sentences), the statistically based recognizer did not provide a correct recognition hypothesis. For these sentences, the combined recognizer could not select correct hypotheses, simple because there were no correct hypotheses. However, when compared to the statistically based recognizer (the word error rate for case STAT-ALL was 29.5%), the reduced word error rate of 24% for the combined recognizer (see case HYB-ALL) reflects the fact that the combined recognizer favoured those recognition hypotheses with smaller edit distances, in words, to the reference sentences.
At the methodological level, these significant reductions of the sentence and word error rates for the combined recognizer are due to context-dependent evaluation of recognition hypotheses. At the algorithmic level, the introduced algorithm for evaluation of recognition hypotheses has proved to be effective in this realistic scenario.
Conclusion
This article introduced a hybrid methodological approach to the research question of context-dependent speech recognition that integrates aspects of both statistical and representational paradigms. We extended the standard statistical pattern-matching approach to speech recognition with a novel, cognitively inspired and analytically tractable algorithm for evaluation of recognition hypotheses. The novelty of the proposed algorithm lies in two aspects. The first aspect is that it allows for accounting for contextual information (i.e. dialogue domain and the focus of attention) which is otherwise unavailable in speech recognition systems, and using it to improve post-processing of recognition hypotheses. We illustrated the algorithm for concrete interaction domains, and discussed its implementation within two prototype conversational agents. The second aspect is that the proposed algorithm is not limited to these particular interaction domains. We briefly discuss the generalizability of the approach, at the conceptual and architectural levels.
At the conceptual level, the proposed evaluation approach is generalizable to different task-oriented interaction domains. The definitions of the parameters of dialogue act complexity (i.e. lexical matching, retrieval cost and integration cost) are applicable to an arbitrary focus tree. The algorithm for evaluation of recognition hypotheses is not constrained to a particular structure of the focus tree or content of the vocabulary. Thus, the proposed approach is applicable to any interaction domain that can be modelled by a focus tree. Gnjatović and Delić 14 and Gnjatović et al. 16 argue that the focus tree model provides a scalable and domain-independent approach to meaning representation in task-oriented human–machine interaction that is sufficiently general both from the engineering and linguistic points of view.
At the architectural level, the proposed algorithm for evaluation of recognition hypotheses can be applied to an arbitrary speech recognition system. The output of virtually all speech recognition systems today can be classified in two main categories: n-best recognition hypotheses, and word lattices, that is, directed graphs that represent possible word sequences. In both cases, the output of a speech recognizer can be considered as a set of word sequences which can serve as the input to the proposed algorithm. We recall that the algorithm does not take into account details of the decoding processes underlying statistically based speech recognition. In line with this, in the reported prototype systems, automatic speech recognition includes two submodules: an architecture-agnostic, statistically based speech recognizer, and the evaluator of recognition hypotheses based on the generalizable focus tree model (see Figure 2). It should be noted that these submodules are independent. A statistically based speech recognizer is, as usual, unaware of the further processing of its recognition hypotheses, while the evaluator takes a set of recognition hypotheses as an input parameter, but is not constrained to a particular implementation of the speech recognizer.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The presented study was sponsored by the Ministry of Education, Science and Technological Development of the Republic of Serbia (research grants III44008 and TR32035), and by the intergovernmental network EUREKA (research grant E!9944). The responsibility for the content of this article lies with the authors.