
Abstract
Recent impressive studies on using ConvNet landmarks for visual place recognition take an approach that involves three steps: (a) detection of landmarks, (b) description of the landmarks by ConvNet features using a convolutional neural network, and (c) matching of the landmarks in the current view with those in the database views. Such an approach has been shown to achieve the state-of-the-art accuracy even under significant viewpoint and environmental changes. However, the computational burden in step (c) significantly prevents this approach from being applied in practice, due to the complexity of linear search in high-dimensional space of the ConvNet features. In this article, we propose two simple and efficient search methods to tackle this issue. Both methods are built upon tree-based indexing. Given a set of ConvNet features of a query image, the first method directly searches the features’ approximate nearest neighbors in a tree structure that is constructed from ConvNet features of database images. The database images are voted on by features in the query image, according to a lookup table which maps each ConvNet feature to its corresponding database image. The database image with the highest vote is considered the solution. Our second method uses a coarse-to-fine procedure: the coarse step uses the first method to coarsely find the top-N database images, and the fine step performs a linear search in Hamming space of the hash codes of the ConvNet features to determine the best match. Experimental results demonstrate that our methods achieve real-time search performance on five data sets with different sizes and various conditions. Most notably, by achieving an average search time of 0.035 seconds/query, our second method improves the matching efficiency by the three orders of magnitude over a linear search baseline on a database with 20,688 images, with negligible loss in place recognition accuracy.
Keywords
Introduction
Visual place recognition is a fundamental problem in computer vision as well as in mobile robotics. Nowadays, it is attracting more and more attention in autonomous vehicles and robots such as self-driving cars and service robots, as it allows these systems to navigate without any human intervention. The goal of visual place recognition is to determine whether the current view of the camera corresponds to a location that has been already visited or seen. 1 To achieve this goal, a visual place recognition system matches the image acquired at the current location with those obtained at previously visited locations. That is, the problem of visual place recognition is essentially one of image matching, which directly relies on the descriptors used for the different locations. Although great strides have been made, visual place recognition is still challenging because a range of environmental and conditional changes usually result in significant variations in image appearances. These changes are due to variations in weather, the time of day, season, camera viewpoint, and so on. As a result, appearance variations make it difficult to develop descriptors that are able to recognize places reliably.
Until recently, there were two popular categories of visual place recognition approaches 1,2 : local descriptor based 3 –6 and global descriptor based. 7 –14 Local descriptor-based approaches use a set of local keypoint descriptors, such as scale-invariant feature transform (SIFT) 15 and speeded up robust features (SURF), 16 to represent an image. These local keypoint descriptors are usually extracted in two phases: (a) the detection phase in which a set of keypoints are first detected and (b) the description phase in which neighbor regions around the detected keypoints are used to create local keypoint descriptors. In contrast, global descriptor-based approaches simply use one global vector, such as GIST 17 and histogram of oriented gradients, 18 to represent an image. A global descriptor is usually computed using an entire image as input. Although these two descriptor categories have achieved tremendous success, each has its own disadvantages, as have been identified in the literature. 1,2 Thanks to the invariance properties of local descriptors, local descriptor-based approaches are usually more robust to occlusions and viewpoint change. However, they are sensitive to illumination change, which generates perceptual aliasing and reduces the discriminative power of local descriptors. In contrast, global descriptor-based approaches have better illumination invariance but offer less robustness to occlusion and viewpoint change. Consequently, neither of these categories are satisfactory in environments that experience a combination of illumination, occlusions, viewpoint, and other changes.
Recent work has shown that convolutional neural networks (CNNs) have the remarkable ability to a variety of visual tasks of mobile robot, 19 –21 including visual place recognition. More specifically, in order to overcome the weakness of existing scene description approaches, the literature 19,20 proposed to directly extract the whole-image descriptors using a pretrained CNN 22 and achieved great success. Most recently, a novel solution has been proposed by Süenderhauf et al. 23 This solution has demonstrated impressive recognition accuracy in a range of challenging environments with significant appearance and viewpoint variations. It makes full use of the power of ConvNet features to match landmarks between images for visual place recognition. Similar to the method by Süenderhauf et al., 23 we refer to this category of approaches as ConvNet landmark-based approaches. Figure 1 shows the examples of ConvNet landmark-based place recognition. Generally, an approach in this category proceeds in three major steps: (a) a number of landmarks are first detected in an image and expressed as bounding boxes (as shown in Figure 1), (b) detected landmarks are then described by ConvNet features, and (c) descriptors based on ConvNet features are matched. One can argue that ConvNet landmark-based approaches lead to good adaptability for place recognition in complex environments. On one hand, by working in a compromised way, ConvNet landmark-based approaches achieve their superiority by enjoying the benefits of both global descriptor-based and local descriptor-based approaches. 1,23 –25 Specifically, since the typical size of the bounding box of a detected landmark is larger than a region used for describing a keypoint, condition invariance of global descriptor-based approaches can be obtained within the bounding box. Conversely, the size of a bounding box is smaller than a full image, so that the viewpoint invariance of local descriptor-based approaches can be retained. On the other hand, compared to handcrafted features used in traditional approaches, ConvNet features have shown a better discrimination capacity, which leads to higher matching rates and fewer recognition errors in visual place recognition. 19,20 For these reasons, ConvNet landmark-based approaches are more likely to overcome the weaknesses of the two categories of approaches mentioned above and achieve robust performance in challenging environments, especially when multiple environmental conditions and viewpoint vary, as illustrated in Figure 1.

Sample examples of matched image pairs produced by a ConvNet landmark-based approach, which is accelerated using our proposed two-stage method. These images come from the testing data sets used in our experiments (see detail in Datasets section). For each example, the bounding boxes with the same color in the two matched images show the landmarks that have been correctly matched via our proposed two-stage method. Best viewed in color. (a) UACampus (06:20 vs. 22:15), its main change includes large illumination. (b) CMU (spring vs. winter), its main changes include large seasonal and moderate illumination. (c) St Lucia (08:45 vs. 15:45), its main changes include moderate illumination and large shadows. (d) Mapillary (mploop1 vs. mploop2), its main changes include large viewpoint and moderate illumination. CMU: Carnegie Mellon University.
However, for satisfactory performance in place recognition, we usually need to detect a sufficient number of landmarks and use ConvNet features of sufficient dimensions (even after dimensionality reduction). For example, in the method by Süenderhauf et al., 23 100 landmarks within each image were detected, and the dimensions of original ConvNet features were reduced to 1024. Consequently, the image matching step using exhaustive comparison is very time-consuming, preventing ConvNet landmark-based approaches from being able to perform place recognition in an environment of even moderate size in real time. So far, no effective solution to improve the computational efficiency of ConvNet landmarks-based approaches has been reported. Therefore, how to perform place recognition with high-dimensional ConvNet features in real time, without losing recognition accuracy, represents a challenge, and it is the focus of this article.
Specifically, we propose two methods in this article to speed up the ConvNet landmark-based place recognition. Our methods achieve their efficiency through tree-based indexing, which is an effective and popular approach for approximate the nearest neighbor (NN) search. Its basic idea is to directly index the K-NN matches of a set of visual features in a tree, a particular data structure for efficient feature matching. Thanks to its efficiency, tree-based indexing has been widely applied in many large-scale vision applications, such as image retrieval
26,27
and object recognition.
28
In addition, two inspirations for our methods are as follows: The effectiveness and applicability of tree-based indexing to visual place recognition have been verified in the work.
29
In that work, randomized k-d tree-based indexing was used for real-time loop closure detection, which is a particular application of visual place recognition in appearance-based robot simultaneous localization and mapping. Although the work
29
relies on local descriptors, that is, directly matching SIFT features using tree-based indexing, its superior performance to bag of words in accuracy and efficiency demonstrates the possibility of tree-based indexing to solve our problem. The landmarks used in ConvNet landmark-based approaches are essentially image patches. With high-dimensional features, tree-based indexing is usually considered to be ineffective. In the extreme case, to achieve good search accuracy, the computational complexity may degrade to that of a linear search. However, it has been shown that this problem does not happen when matching similar image patches with high-dimensional features.
30,31
Specifically, an exciting finding has been observed: In the case of similar image patches, the search efficiency of tree-based indexing does not decrease with dimensionality; on the contrary, the search accuracy may increase to some degree. Because landmarks detected in ConvNet landmark-based approaches are image patches of high dimensions, we believe this finding is also applicable to our case.
Motivated by the above observations, in this article, we explore the possibility of leveraging tree-based indexing to speed up ConvNet landmark-based approaches, while retaining their recognition accuracy. Among various existing tree structures, the multiple randomized k-d trees and the priority search hierarchical k-means tree have been demonstrated the best performance. 30,31 What’s more, the latter has been shown to be more effective than the former when a high search accuracy is required. 30,31 Therefore, we use the priority search hierarchical k-means tree in our methods, although other types of tree structures may also work well. For simplicity, we use the term HKMeansTree for the priority search hierarchical k-means tree in this article.
In terms of the number of candidate image matches, we present a one-stage method and a two-stage method. The one-stage method applies tree-based indexing to find the top match as follows. First, we directly retrieve the approximate NN matches of ConvNet features of a query image in an HKMeansTree structure, which is constructed over ConvNet features of database images in an off-line process. Then the retrieved matching features vote for the corresponding database images, according to a prepared lookup table which stores the mapping from each ConvNet feature to its corresponding database image. Finally, we consider the image with the highest vote as the final match. By extending the one-stage method, our two-stage method uses a coarse-to-fine search scheme. In the coarse step of the method, we use the one-stage method as above to find the top-N candidate database images, where N > 1. In the fine step, we perform a fast-linear search in Hamming space, based on hash codes of these candidates, to determine the final match of the query image.
To verify the effectiveness of our methods, we perform a thorough empirical evaluation using five data sets of different sizes involving changes in various environmental conditions. Experimental results show that our methods can significantly reduce the recognition time with negligible decrease in search accuracy. Specifically, compared to the linear search baseline, our two-stage method achieves 1360× speedup, with nearly no performance loss in recognition accuracy. On average, the search time is 0.035 seconds/query on a database with 20,688 images. To the best of our knowledge, this is the first time that tree-based indexing has been successfully used for ConvNet landmark-based visual place recognition. Furthermore, this is also the first reported work of real-time search performance in visual place recognition using ConvNet landmarks. Our work demonstrates the practicality of ConvNet landmark-based approaches in visual place recognition.
The remainder of this article is organized as follows. Background section briefly reviews the main components of a ConvNet landmark-based place recognition system and tree-based indexing. Proposed methods section presents our proposed methods in detail. Experiments and results section presents the experimental results on five data sets to demonstrate the effectiveness of our methods, and the last section provides the conclusion.
Background
In this section, we briefly review the background research, including ConvNet landmark-based place recognition and HKMeansTree-based indexing. For more detailed description and discussion of relevant techniques, one can refer to the literature. 23,31
ConvNet landmark-based visual place recognition
Assume we are given a query image, Iq, and a set of M database images,
Step 1:
Step 2:
Step 3:
As already discussed in the introduction, Step 3 is the most time-consuming step. Hence, it is important to develop efficient methods to reduce the search time for a query and make ConvNet landmark-based place recognition practical.
It is worth noting that the search scheme proposed by Süenderhauf et al.
23
is theoretically unable to achieve real-time performance with today’s computing technology. The reason is that it uses bidirectional matching based on a linear NN search to match landmarks. In particular, by using a linear NN search based on the cosine distance, matched landmark pairs are identified with a bidirectional matching scheme. This scheme works as follows: if
HKMeansTree-based indexing
Tree-based indexing for the approximate NN search can be defined as follows. Given a set of n features
HKMeansTree, proposed by the literature, 30,31 is a special case of partitioning trees based on hierarchical k-means clustering. It has been widely used to approximate the NN search, demonstrating better performance than hashing-based methods. 30,31 The HKMeansTree is constructed by recursively partitioning the feature space at each level of a tree into k distinct subspaces (i.e. cluster centers) using k-means clustering. In particular, features are first partitioned into k distinct subspaces to generate the nodes of the first level of the tree. Then the same process is recursively applied to the associated features in each subspace, in order to partition the feature space at the current level into k distinct subspaces. These distinct subspaces form the nodes of the next level of the tree. This recursion continues until the number of features in a subspace is no more than k. To find the NN of a query in HKMeansTree, a depth-first searching procedure is commonly used. In addition, to further improve the search efficiency, priority search based on a priority queue is used. The priority queue, which is dynamically built while the tree is being searched, stores the distances of the unvisited branches of the nodes along the path from the query. Thus, after checking which branch is with the closest cluster center to the query feature at each inner node, only unvisited branches are searched in the order of their distances. In this way, both search speed and accuracy can be improved. Note that the term “branching factor” is used to describe the number of distinct subspaces to use when partitioning the feature space at each level and that a search algorithm often limits the maximum number of leaves to examine, L, in order to constrain the search time.
Proposed methods
In this section, we present our methods to speed up the image matching step in ConvNet landmark-based visual place recognition. We first describe how to construct the HKMeansTree-based index used in our methods and then detail our one-stage and two-stage methods.
Construction of an HKMeansTree-based index
In our methods, HKMeansTree is utilized to construct the search index. Specifically, an HKMeansTree-based index is constructed in an off-line preprocessing phase. First, all dimension-reduced ConvNet features
One-stage method
Our one-stage method performs the NN search only. Note that it uses HKMeansTree to carefully check a relatively large number of leaves in the tree, in order to obtain a satisfactory recognition accuracy. The detailed steps of this method are presented in the following section and in algorithm 1.
Step 1: Searching the K-NNs of the query features using HKMeansTree-based indexing. For each feature
Step 2: Voting for the corresponding database images. The following processing is applied recursively to each feature in
Step 3: Finally, we choose the database image with the highest number of votes of matched landmarks as the final match of the query image. In the case of that multiple database images have the highest number of votes of matched landmarks, we select the database image with the maximum similarity as the final match. One-stage method.

Two-stage method
So far, we have presented the one-stage method. However, as we will show later in the experiments, a relatively large number of leaves, L, in HKMeansTree needs to be checked for recognition accuracy to be satisfactory. This comes at the expense of long search time. To overcome this weakness and further improve the search speed, we extend the one-stage method into a coarse-to-fine, two-stage search method. Specifically, it consists of the following steps, some of which are shared with the one-stage method. To avoid redundancy, we will not repeat the shared steps and describe only the difference.
In the coarse stage of this method, we apply the one-stage method in a coarse step to find the top-N candidate database images, which have a high probability of containing at least one ground truth database image. By coarse, we mean that only a small number of leaves in the HKMeansTree are checked to optimize for efficiency.
Step 1: Searching K-NNs of the query features using HKMeansTree-based indexing. This step is the same as step 1 in the one-stage method but with two different parameters: (a) we use K = 5 and (b) we set L to a lower value so that we examine only a small number of leaves.
Step 2: Voting for the corresponding database images. This step is exactly the same as step 2 of the one-stage method. After finishing this step, we can obtain the voting result imIDX, which stores the number of matched landmarks between the query image and the database images.
Step 3: Selecting the top-N candidate database images. We first sort
In the fine stage of this method, we perform an exact search to determine the final match of the query image among the top-N candidate images obtained in the coarse stage. In this article, we implement the fast exact search in Hamming space. Specifically, the query feature is first encoded into a binary code using the same hash function that encodes the database features to codes. Then we find the NN of the query feature by computing the Hamming distance between the query code to all the database codes. Finally, with the computed Hamming distance, we use a linear search to find the NN of the query. Using hash code, the linear search can be performed efficiently. The fine stage is detailed as follows.
Step 4: Searching the 1 − NN of the query features using a fast exact search in Hamming space. The purpose of this step is the same as that of step 1 of the one-stage method. However, we find the 1 − NN of the features using the fast exact search in Hamming space, instead of using HKMeansTree-based indexing. For each feature of the query image, we search its 1 − NN in the database features, which come from the top-N candidate database images obtained in the coarse stage.
Step 5: Voting for the corresponding database images. This step is exactly the same as step 2 of the one-stage method.
Step 6: Finding the best match. This step is also exactly the same as step 3 of the one-stage method.
As we will show in the following section, compared to the one-stage method, the two-stage method can not only further speed up recognition but also improve search accuracy.
Experiments and results
Experimental setup
Data sets
In order to evaluate the effectiveness of our proposed methods under different conditions, we ran experiments on five data sets that exhibit typical changes present in real-world place recognition applications. From the summary of their main characteristics listed in Table 1, we can divide these data sets into three categories of changes. The first three data sets present different kinds of significant appearance change but without viewpoint variation, the fourth data set mainly exhibits large viewpoint change, and the fifth data set covers both aforementioned categories of changes. Figure 1 shows the sample images of each data set.
The UACampus 32 data set was collected with a Husky A200 mobile robot on the campus of the University of Alberta, Canada. The robot was equipped with a forward-facing camera (ASUS Xtion PRO LIVE), which was configured to acquire the images of 640 × 480 pixels at 30 Hz. In order to create illumination variation, the robot was driven through the same route (about 650 m) at five different times of the day (between 06:20 and 22:15). In our experiments, we used two subsets that exhibit the greatest relative illumination change, that is, two subsets at 06:20 and 22:15. Their images are manually matched to generate the ground truth.
The Carnegie Mellon University (CMU) 33 data set was collected with a vehicle made by CMU in Pittsburgh, PA, USA. The vehicle, which had a pair of Point Grey Flea 2 cameras mounted on the left and right sides, was driven along an 8.8-km route. The cameras were set to collect the images of 256 × 192 pixels at 15 Hz. In our experiments, all images were resized to 640 × 480 pixels. The same route was traversed 16 times under varying environmental and climatological conditions over the course of a year. To evaluate the performance in the case of seasonal change, we used two subsets in our experiments. Those subsets were collected in the spring and the winter. The spring subset was obtained on April 4, 2011, which was a cloudy day. The winter subset was obtained on February 2, 2011, when there was light snow fall and some snow was on ground. We used only the images captured by the left camera when the vehicle was moving. The ground truth was created with Global Positioning System (GPS). Two images within 10 m are considered to be the same place.
The St Lucia 34 data set was collected using a car in the Brisbane suburb of St Lucia, Australia. A forward-facing web camera (Logitech QuickCam Pro 9000) was mounted on the car, with 640 × 480 pixel resolution at 15 Hz. In order to capture the difference in appearance between early morning and late afternoon, the route was traversed at five different times during 2 days over 3 weeks, for a total of 10 subsets. We used two subsets that exhibit the greatest relative appearance changes caused by illumination and shadow, that is, two subsets at 08:45 and 15:45 on September 9, 2010. In our experiments, we use 10,000 images uniformly sampled from the subsets. The ground truth was created with GPS. Two images within 20 m are considered to be the same place.
The Mapillary data set was downloaded from Mapillary, 35 which is a service similar to Google Street View. A number of driver users share their geotagged photos captured when driving along a road. Usually, many roads would be traversed by more than one user under different environmental conditions. More importantly, these revisits do not drive accurately along the same wheel ruts. For example, they may drive in different lanes. We specifically downloaded 2028 image pairs with different viewpoints across several countries in Europe. Therefore, this data set exhibits a significant viewpoint change as well as some appearance changes due to variations in the weather. All images were resized to 640 × 480 pixels in our experiments. A GPS reading is attached in each image, but each reading is quite inaccurate. Therefore, we first use the coarse GPS readings to create the initial ground truth and then refine the initial ground truth manually to make it accurate.
The FullSet is a combination of the above four data sets. Its main purpose is to evaluate the search efficiency on a bigger data set containing tens of thousands of images.
Summary of the main characteristics of five data sets used in our experiments.a

a“No.” indicates the number of images in a subset. For each data set, two subsets with extreme changes are listed below and will be matched in our experiments. CMU: Carnegie Mellon University.
Implementation details
In all experiments, we followed the method used by Süenderhauf et al. 23 to perform the first two steps (as described in ConvNet landmark-based visual place recognition section) of ConvNet landmark-based place recognition. In the first step, we detected 100 landmarks per image using EdgeBoxes, 36 which is a popular object proposal method in object detection application. EdgeBoxes has demonstrated the outstanding repeatability under different imaging conditions (e.g. illumination, rotation, scaling, and so on). 37 Thanks to its good repeatability, impressive recognition accuracy in the presence of severe environmental changes has been achieved in the work by Süenderhauf et al. 23
In the second step, we extracted one ConvNet feature for each landmark from a pretrained CNN known as AlexNet. 22 Note that, unlike the method by Süenderhauf et al., 23 we extracted features from the pool5 layer instead of the conv3 layer. As we know, the pool5 layer has more pooling operations than the conv3 layer, and the pooling operation is commonly used to achieve better invariance to image transformations. Therefore, it is reasonable to believe that the features from the pool5 layer are better at handling the localization errors of detected landmarks than those features from the conv3 layer, and that this superiority of the pool5 layer will bring better recognition accuracy in ConvNet landmark-based place recognition. Actually, this point has been confirmed by our experimental evaluation, though we will not show the results of this evaluation in this article because it is beyond the scope of this article. The dimensionality of extracted ConvNet features was then reduced. Except that in the second stage of the two-stage method, the ConvNet features were encoded as 1024-bit hash binary codes using locality-sensitive hashing (LSH). 38 In all other cases, the ConvNet features were reduced to 1024 using Gaussian random projection (GRP). 39,40 Note that the LSH employed in this article is very naive because it is simply based on random unit-norm projections followed by signed binarization. Better hash codes, which may bring higher recognition accuracy and/or faster search, could be obtained by applying more sophisticated hashing methods.
For HKMeansTree, we used the publicly available implementation in the FLANN library (http://www.cs.ubc.ca/research/flann/). To compute the Hamming distance of hash binary codes, we used the open-source code of Yael (http://yael.gforge.inria.fr/). All experiments in this article were conducted on a desktop PC with eight cores of CPU@4.00 GHz, 32 GB random-access memory (RAM) memory. We used the maximum number (16) of physical threads for parallelization. Streaming SIMD Extensions 4 (SSE4) instructions were used to accelerate the computation of the Hamming distance.
Evaluation protocols
For each data set in Table 1, we consider the first subset as the query set and use the second subset as the database set. For example, in the UACampus data set, the subset collected at 06:20 is the query set and the subset collected at 22:15 is the database set. Each image in the query set is required to find its similar image that is likely to correspond to the same place in the database set. The ground truth is used to determine the correctness. We use two metrics to evaluate the performance in terms of recognition accuracy and search efficiency: (a) the Precision–Recall curve is commonly used as a standard criterion for assessing recognition accuracy in the visual place recognition community 1 ; and (b) search time for per query is used to measure search efficiency. Note that the search time reported in this article is an average time for searching all query images of a data set.
Baseline
As described previously, our aim is to speed up the image matching step in ConvNet landmark-based visual place recognition, ideally without losing original recognition accuracy. Consequently, we need to establish the baseline of recognition accuracy in the first place. The method proposed by Süenderhauf et al. 23 is the latest representative of ConvNet landmark-based approaches. It has shown state-of-the-art recognition accuracy, so we have implemented it and run it on our data sets to produce the precision–recall curves. We consider those precision–recall curves produced by the method of Süenderhauf et al. 23 as the baseline of recognition accuracy. For the sake of convenience, we denote these curves as Baseline-Accuracy. It is expected that our proposed methods could achieve real-time search performance under an important condition, that is, keeping almost the same recognition accuracy as Baseline-Accuracy.
To validate whether this condition could be satisfied, we compare the recognition accuracy of Linear-GRP with Baseline-Accuracy. Note that the results of Linear-GRP are actually produced by our one-stage method with a linear NN search, instead of HKMeansTree-based indexing. Theoretically, Linear-GRP shows the best recognition accuracy that could be achieved by our proposed methods when using HKMeansTree-based indexing. Results on four data sets are shown in Figure 2. Compared to Baseline-Accuracy, Linear-GRP shows almost the same recognition accuracy in environments without viewpoint change (as shown in Figure 2(a) to (c)) and better accuracy in environments with large viewpoint change (as shown in Figure 2(d)). This confirms that it is possible to satisfy the important condition on performance.

Comparison in terms of place recognition accuracy between the state-of-the-art method by Süenderhauf et al. 23 (denoted as “Baseline-Accuracy”) and our one-stage method with a linear NN search (denoted as “Linear-GRP”). (a) UACampus. (b) CMU. (c) St Lucia. (d) Mapillary. CMU: Carnegie Mellon University.
It is worth noting that we use Linear-GRP instead of Baseline-Accuracy as the baseline in terms of recognition accuracy and search efficiency in the following experiments. Two reasons for this are (a) the place recognition accuracy of Linear-GRP is almost the same as that of Baseline-Accuracy and (b) more importantly, Linear-GRP is more fair than Baseline-Accuracy when comparing search efficiency with our proposed methods. Because we implement the method by Süenderhauf et al. 23 in MATLAB without optimization, however, we produce the results of Linear-GRP using the fast-linear search implementation in the FLANN library.
Results and summaries
The results with respect to place recognition accuracy are shown in Figure 4, and the corresponding search times are listed in Table 2. It is known that HKMeansTree has a set of adjustable parameters that have a significant influence on search performance. Naturally, there is a trade-off between place recognition accuracy and search efficiency in our proposed methods. Therefore, we first give the parameter selection in the experiments before discussing the results.
Comparison of search times (seconds/query).a
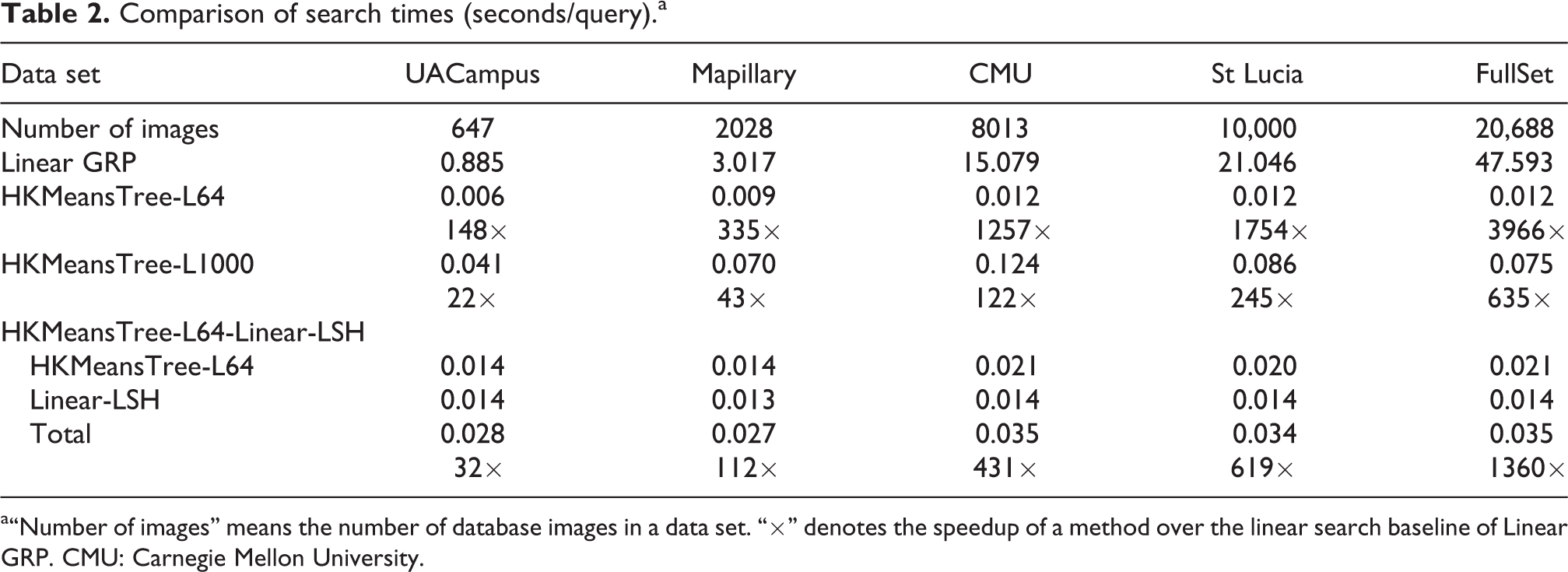
a“Number of images” means the number of database images in a data set. “×” denotes the speedup of a method over the linear search baseline of Linear GRP. CMU: Carnegie Mellon University.
Tuning parameters
Since our aim is to achieve real-time search performance while keeping the original recognition accuracy, we carefully tuned the parameters following a rule: increasing parameters that contribute to improving search accuracy until the recognition accuracy is close to that of the baseline linear GRP. The final parameters that were used to produce the results in Figure 4 are summarized below. We ran all experiments using the same parameters across all data sets. When constructing an HKMeansTree, the branching factor was 64 and the maximum number of iterations for the k-means clustering was 30. When searching a constructed HKMeansTree, the search performance in accuracy and efficiency mainly depends on the maximum number of leaves to examine L. A higher L would bring better search accuracy but also take more time. For our one-stage method, L was gradually increased from 64 to 1000. When L = 1000, the recognition accuracy was close to the baseline. In Figure 4, we show the precision–recall curves of using L = 64 and L = 1000, which are, respectively, named HKMeansTree-L64 and HKMeansTree-L1000. For the first stage of our two-stage method, we used L = 64. The precision–recall curves produced by our two-stage method, shown in Figure 4, are named HKMeansTree-L64-Linear-LSH. In the first stage of our two-stage method, we need to determine the number of ranked database images used in finding the final match in the second stage. To find an appropriate N, we calculated the recall curve at various values of N, which is a common measure for evaluating the performance of an image retrieval system. In our case, recall is defined as the proportion of query images for which its ground truth database image is ranked in the top N positions of ranked database images. This measure is commonly denoted as Recall@Top-N. We plotted this Recall@Top-N curve of HKMeansTree-L64 on each data set in Figure 3. It clearly shows that the recalls on all data sets are stable at the highest level when N = 200. Therefore, we used N = 200 of ranked database images as the candidates of the experiments.

Recall@Top-N of HKMeansTree-L64 in the first stage of our two-stage method. (a) UACampus. (b) CMU. (c) St Lucia. (d) Mapillary. (e) FullSet. CMU: Carnegie Mellon University.
Comparison and summaries
From Figure 4 and Table 2, we can arrive at some conclusions, as summarized below. Comparison of HKMeansTree-L64/L1000 in the one-stage method clearly shows the effect of increasing the number of leaves to examine L on the search performance. That is, a higher L gives better search accuracy but takes more search time. In particular, the search speed of L = 64 is extremely fast, but its recognition accuracy is much worse than that of L = 1000. In contrast, HKMeansTree-L1000 achieves expected recognition accuracy that is quite close to that of the baseline Linear-GRP. Its search time on the FullSet data set is as little as 0.075 seconds/query. Compared to the one-stage method, our two-stage method, HKMeansTree-L64-Linear-LSH, achieves better recognition accuracy that is nearly the same as that of the baseline. Furthermore, the two-stage method is faster than the one-stage method of HKMeansTree-L1000, with an average search time of 0.035 seconds/query on the FullSet data set. Note that this average search time is 1360× speedup over a linear search baseline. The total search time per query of the two-stage method consists of two parts: to search the HKMeansTree and to perform the fast-linear search in Hamming space. The second part is a constant, which in our experiments is only about 0.014 s when using top-200. Note that the Hamming distance was computed by the code of Yael using a single thread. Theoretically, the second part of the time can be further optimized by applying a multithread processing. The first part of the time is a fraction of the one-stage method of HKMeansTree-L1000. For example, compared to HKMeansTree-L1000, the first part of two-stage has 3.6× speed improvement on the FullSet data set. While the 3.6× improvement might seem a small improvement, for real-time applications it will still be significant. In summary, both of our proposed methods have achieved real-time search performance on all data sets used in our experiments. From the above comparison, our two-stage method is not only more accurate but also faster than our one-stage method. Comparison in terms of place recognition accuracy. Best viewed in color. (a) UACampus. (b) CMU. (c) St Lucia. (d) Mapillary. (e) FullSet. CMU: Carnegie Mellon University.

Discussion
We discuss the limitations of our methods in this section. As we have shown, compared to the one-stage method, our two-stage method is superior in both place recognition accuracy and search efficiency. However, the two-stage method also has its deficiencies. First, it needs more storage space for saving the hash codes of the ConvNet features, although these hash codes are binary and very compact. Second, for reducing Input/Output access time, the hash codes are usually loaded into the memory (RAM). As a result, the two-stage method consumes more memory than the one-stage method. Therefore, one should choose one method or the other depending on the specific application scenario. Generally, we suggest that the one-stage method may be preferable in an environment of moderate size, while the two-stage method may be better when the size of an environment becomes large.
Another limitation of our proposed methods is due to the need to perform hierarchical k-means clustering to construct the search tree. While this is not an issue in applications such as place recognition or robot localization in a fixed environment, for other applications that involve an environment that grows over time, the time complexity of hierarchical k-means clustering prevents our methods from being real time.
Conclusion
In this article, we have proposed two methods, that is, the one-stage method and the two-stage method, to speed up the visual place recognition using ConvNet landmarks. We exploit the efficiency of tree-based indexing to achieve the speedup. The one-stage method applies tree-based indexing and uses the top-ranked image as the result of the recognition system. The two-stage method performs a coarse-to-fine search scheme. Specifically, the top N candidate images are first retrieved using the one-stage method in a coarse step and then the final winning match of the query image is found with a fast-linear search in Hamming space. Extensive experiments were conducted on five data sets with various environmental changes, and our methods achieved real-time search speed, with only negligible loss in the place recognition accuracy. Compared to the one-stage method, we found the two-stage method to be not only more accurate but also faster. For the largest data set with 20,688 database images, our two-stage method achieved 1360× speedup over a linear search baseline, with an average search time of 0.035 seconds/query. We believe this work has made ConvNet landmarks-based approaches to be more practical in visual place recognition.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: The authors gratefully acknowledge the support from the Hunan Provincial Innovation Foundation for Postgraduate (CX2014B021), the Hunan Provincial Natural Science Foundation of China (2015JJ3018), and the Fund of Innovation of NUDT Graduate School (B140406). This research is also supported in part by the Program of Foshan Innovation Team (grant no. 2015IT100072) and by NSFC (grant no. 61673125).