
Abstract
Rapidly exploring random trees (RRTs) have been proven to be efficient for planning in environments populated with obstacles. These methods perform a uniform sampling of the state space, which is needed to guarantee the algorithm’s completeness but does not necessarily lead to the most efficient solution. In previous works it has been shown that the use of heuristics to modify the sampling strategy could incur an improvement in the algorithm performance. However, these heuristics only apply to solve the shortest path-planning problem. Here we propose a framework that allows us to incorporate arbitrary heuristics to modify the sampling strategy according to the user requirements. This framework is based on ‘learning from experience’. Specifically, we introduce a utility function that takes the contribution of the samples to the tree construction into account; sampling at locations of increased utility then becomes more frequent. The idea is realized by introducing an ant colony optimization concept in the RRT/RRT* algorithm and defining a novel utility function that permits trading off exploitation versus exploration of the state space. We also extend the algorithm to allow an anytime implementation. The scheme is validated with three scenarios: one populated with multiple rectangular obstacles, one consisting of a single narrow passage and a maze-like environment. We evaluate its performance in terms of the cost and time to find the first path, and in terms of the evolution of the path quality with the number of iterations. It is shown that the proposed algorithm greatly outperforms state-of-the-art RRT and RRT* algorithms.
Keywords
Introduction
The optimal path-planning problem, which can be formulated as the task of driving a robot from an initial state
Thus, our goal in this work is to answer the question of how to sample to optimize the selected utility function. Furthermore, the definition of the utility function allows us to formulate a framework that is able to incorporate heuristics that will guide the sampling strategy according to the user requirements. This would enable us to extend the original RRT* algorithm 2 to informative path-planning and exploration applications in unknown environments, where our goal is to sample more often where there is more information, or to employ the user’s prior knowledge to perform a more intelligent sampling that optimizes some predefined criteria, for instance, avoiding harsh terrains in search and rescue missions. This could easily be introduced into our utility function. However, in this work, we focus on the shortest path-planning problem and formulate a utility function that optimizes the path cost with respect to distance. We suggest further extensions of the algorithm in the concluding discussion of possibilities for future work.
Inspired by machine-learning techniques, we augment our sampling strategy by taking the already accumulated samples into account. This can be interpreted as continuous learning of the probability density function, which represents the optimal sampling distribution at each moment and sampling according to it. To determine the optimal sampling distribution, we rely on ant colony optimization (ACO) for continuous domains (ACOℝ). We chose ACOℝ because it offers superior performance compared with both Monte-Carlo methods and other swarm optimization techniques. 3 The ACOℝ algorithm distributes virtual ants according to a utility function that evaluates the ants’ relevance and so determines the sampling distribution (as illustrated in Figure 1). The utility function is constructed to trade exploitation of the state space, that is, optimization of the constructed tree, and exploration of the state space, which favours a growth of the tree in as yet explored regions of the state space. Given the tree we have constructed so far, we analyze: (i) how much the sample exploits the current solution; (ii) how much a sample contributes to exploration of the state space. Based on that, we update our ants, which will modify the sampling distribution and, in consequence, the way we construct our tree to solve the path-planning problem.
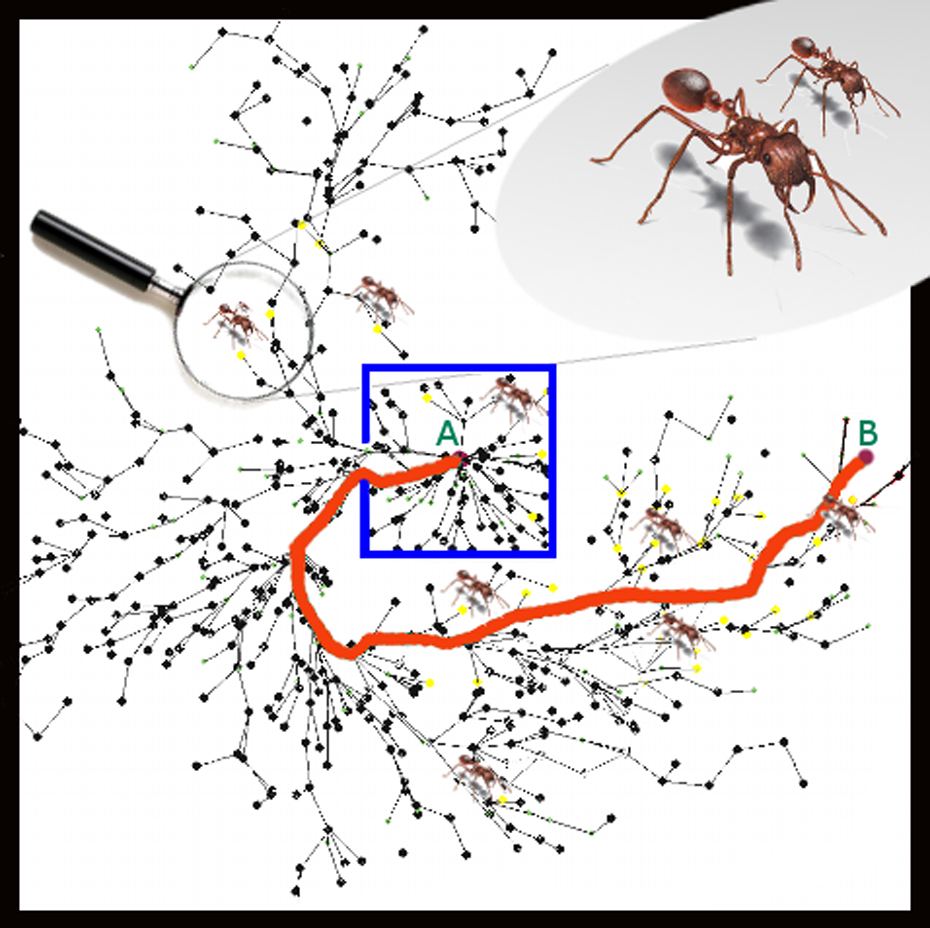
Example of one path generated with the proposed ACO-RRT* algorithm. We build a rapidly exploring random tree based on a modified sampling strategy that learns from previous experience.
Related work
Sampling-based path-planning algorithms are widely used because of their efficiency in providing path-planning solutions in high-dimensional spaces. These methods are well exemplified by probabilistic roadmaps (PRMs) 4 and rapidly exploring random trees (RRTs); 1 a modification of the RRT algorithm, called RRT*, is also known to achieve asymptotic optimality with respect to a given cost function. 2
In recent years, a great amount of sampling-based path-planning algorithms have been proposed. 5 –11 These works have in common that they outperform the RRT* algorithm by modifying and optimizing some of the subroutines that compose the original RRT* algorithm. However, the cited algorithms are specifically designed to solve the optimal shortest path-planning problem under certain restrictions. Here, we aim to go one step further and propose a framework that allows us to introduce some heuristics into the original RRT and RRT* algorithms. These heuristics are incorporated into the algorithm by modifying the sampling distribution, which is learnt online according to those heuristics as we sample the state space. The advantage of defining such heuristics is twofold: (i) it enables the introduction of some additional knowledge to solve the path-planning problem more efficiently; (ii) it could be used in conjunction with any of the aforementioned works to improve their performance. Specifically, in this work we will show that our approach, combined with shortest path heuristics, outperforms the state-of-the-art RRT and RRT* algorithms.
Sampling-based path planners consist of several subroutines that can be optimized individually to improve the algorithm’s performance, which also make the methods very attractive. Denny et al. proposed a ‘lazy planning’ to improve the collision checking by the assumption that only 10% of the collisions checks are positive. 12 Conversely, algorithms like RRT connect 13 and the one proposed by Urmson and Simmons 14 increases the algorithm performance by heuristically biasing the tree growth. This tree growth has also been adapted by Denny et al., 15 who adapted the branch size according to the space in heterogeneous environments. In contrast to previous works, here we focus on a modification of the sampling strategy. Essentially, if we can identify regions of higher importance, that is, regions in the state space that could help us to improve our current path, then we should sample these regions more often.
It is possible to dichotomize sampling strategies for path planning into importance sampling and adaptive sampling. Importance sampling methods exploit some predefined a-priori sampling strategy. Examples include goal-biased sampling, 16 medial-axis sampling, 17 where samples are taken from the medial axis of free space, and the bridge test, 18 which is designed to solve narrow passage problems. These methods are specifically designed to solve concrete problems. Alternatively, in adaptive sampling methods, the samples are drawn from a distribution that is adapted based on the information obtained from previous samples, which makes them more flexible. Siméon et al. propose the visibility PRM algorithm, 19 which just takes samples from the unexplored area within the planner visibility region. Although the constructed roadmaps are significantly smaller, the computation of the visibility region is expensive. Adaptive dynamic domain RRT adapts the previous concept to the RRT algorithm. 20 In this work, we additionally consider the importance of the previous samples, which are not necessarily within the visibility region. This is exploited for PRMs through an utility-guided sampling by Burns and Brock. 21 There, the authors do not aim to learn the sampling distribution, but to perform a Monte-Carlo sampling and select the samples with a higher utility. However, our focus lies in rapidly exploring random trees, owing to their efficiency, since they do not require any pre-computation time, as in PRMs. Adaptive sampling within the RRTs framework has also been exploited in recent works. 22 –25 In contrast to our algorithm, these are able neither to incorporate nor to learn arbitrary heuristics.
The work of Rickert et al. 26 inspires the definition of our utility function. In their work, Rickert et al. propose the exploring-exploiting tree algorithm, which balances exploitation and exploration to construct the tree more effectively. Yet this method requires some environment-dependent pre-computing time to grow the tree, which does not make it suitable for online planning. The exploration-exploitation trade-off has also been employed in several works. 27 –29 Alterovitz et al. 28 propose the rapidly exploring roadmaps algorithm. This algorithm first finds a solution, as in RRTs, and then refines this solution. Balancing exploration and exploitation is also employed by Persson and Sharf, 29 who generalize the A* algorithm to allow sampling-based motion planning. Also Akgun and Stilman 27 have developed an algorithm that trades off exploration and exploitation to improve the RRT* in high dimensions. This is done by introducing sampling heuristics. Our algorithm is also based on sampling heuristics, which are learnt using machine learning. In contrast to the aforementioned studies, 27 –29 our framework allows us to introduce sampling heuristics that are not just specifically designed for the optimal shortest path planning but also for different applications.
Our goal in this paper is not just to define a framework that can incorporate arbitrary heuristics. In addition, we aim to learn the sampling distribution of the planning algorithm that better fits the user-defined heuristics. This is done by introducing machine-learning techniques. Morales et al. 30 divide the planning problem into several subproblems, and then employ machine learning to select a roadmap from a set that is more adequate to solve each of the subproblems. In the last step, the selected roadmaps are fused to obtain a global one. Machine learning is also introduced by Diankov and Kuffner 31 into A* to select the best heuristic from a set in order to improve the algorithm performance. Both of these algorithms 30,31 require a discrete predefined set from which they select the best roadmap or heuristic, respectively. In contrast, we aim to apply machine learning to learn not a discrete set but a continuous distribution.
This paper is strongly influenced by the idea of cross-entropy motion planning outlined by Kobilarov. 32 Here, Kobilarov 32 learns the sampling distribution from previous samples by evaluating its entropy. Its limitation comes from the high computational requirement to calculate the sampling distribution for the environment, which does not make it feasible for real-time applications. We improve this concept by using an ant colony optimization algorithm to learn the sampling distribution. 3 Ant colony optimization has also been used, by Mohamad et al., 33 in the context of PRMs. The goal of Mohamad et al. 33 was to reduce the number of intermediate configurations from an initial to a goal position. Although it has a different objective, that work serves as an inspiration to incorporate the ACO into a sampling-based path planner. Learning the sampling distribution, together with the definition of a novel utility function, lets us derive a scalable algorithm suitable for real-time path-planning applications.
In the remainder of this paper, we briefly describe the rapidly exploring random trees and ant colony optimization algorithms that serve as the basis of our work. We then introduce the proposed algorithm and extend it to allow an anytime implementation. We evaluate and discuss the algorithm performance and finally draw conclusions and discuss avenues for future work.
Background
Rapidly exploring random trees
The rapidly exploring random trees (RRTs) algorithm is a solution to the path planning problem in complex high-dimensional spaces.
1
The RRT algorithm iteratively constructs a graph

The algorithm is realized as follows. We draw a sample
The RRT* algorithm is an evolution of the RRT algorithm, which has been shown to be asymptotically optimal.
2
We describe the RRT* in Algorithm 2. It differs from RRT in two aspects: choosing a parent and rewiring. In contrast to RRT, we choose the parent of

with

where

Ant colony optimization for continuous domains
Ant colony optimization is a nature-inspired algorithm to solve hard combinatorial optimization problems. 34 Its driving principle comes from the behaviour of ants when searching for food. First, they leave the nest walking in random directions. Once they find a food source, they come back to the nest, leaving a pheromone trail on the ground. The pheromone deposited depends on the quality and quantity of the food and guides the other ants to the food source. Based on the same principle, ant colony optimization for continuous domains (ACOℝ) is proposed to solve continuous optimization problems. 3 This work inspires our sampling strategy, in which the ants, according to their utility, will decide where to sample next.
The ants are stored in a table

The algorithm works as follows. First, we take a sample
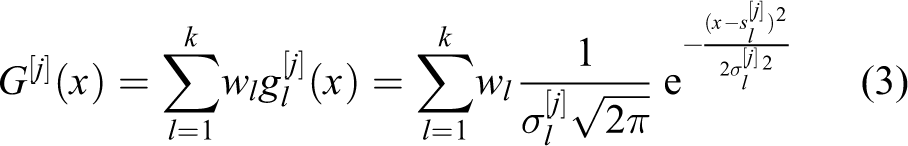
with

where ξ > 0 is the pheromone evaporation rate, which avoids the algorithm converging too quickly before approaching the optimal solution. The parameter wl from

where q is a user-defined parameter. When q is small, the best ranked solutions are strongly preferred. The vector of weights
Next, we sort the table
ACO-RRT* algorithm
In this work, we propose the ACO-RRT* algorithm, which aims to improve on the RRT and RRT* performance by modifying the sampling distribution using ant colony optimization for continuous domains. Our motivation lies in learning from the experience. This means that, after sampling, we evaluate how much that sample contributed to improve our current path. This evaluation will influence how we obtain the next sample.
The algorithm consists of five steps (see Figure 3). First, we initialize the ants that will generate future samples. Second, we sample from the distribution described by the current ants. Then we update our tree according to the original RRT/RRT* algorithm. After that, we calculate the utility of that sample based on how much it could improve the current path. This is divided into two factors: (i) exploitation of the current solution and (ii) exploration of the state space to find a new, better solution. Based on that utility, we update the ants and resample according to the new distribution. The algorithm is formulated in Algorithms 3, 4 and 5, and is described in detail in the following subsections.

ACO-RRT* algorithm block diagram. Each of the five blocks points to its respective lines from Algorithm 4.
Initialize ants
The first part of the algorithm consists of filling the table

Sample ACO
Given the table

with we given by equation (5) and

This modification of the sampling strategy implies that the algorithm cannot guarantee the theoretical asymptotic optimality from RRT*. However, simulation results suggest that the proposed algorithm is able to approach the optimal solution. The explanation for such behaviour lies in the fact that the ants are associated with Gaussian probability density functions. Samples extracted from such a function can take values from an infinite domain that results in sampling over the complete state space. Even in the worst case, when all ants could converge to a single point, the variance of the distributions associated with the ants will be always slightly greater than zero. This fact guarantees that the state space will always be fully sampled and, therefore, the algorithm will approach the optimal solution.
Construct tree
The next step is to construct the tree according to the basic rapidly exploring random tree path planner. This step corresponds to lines 4–8 in Algorithm 1 (RRT) and lines 4–23 in Algorithm 2 (RRT*). This function needs the
Calculate utility
The key part of the algorithm is the calculation of the utility of the

where α models the trade-off between exploitation and exploration,
Exploration utility
The exploration utility
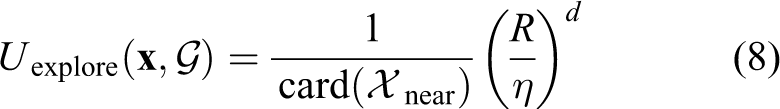
with
The first term of the product models a decay of the exploration utility as proportional with respect to the number of elements in Xnear. That implies that a sample that has a low number of neighbours in the current tree G will have a high exploration utility. Therefore, the exploration utility function will bias the exploration towards the not-yet-sampled state space. However, the number of neighbours of a sample depends on the connection radius R given by the RRT/RRT* algorithm. The bigger the connection radius, the higher the probability of having a larger number of neighbours. As the tree growths, the connection radius decreases. To make the exploration utility independent of the tree’s current state, we introduce a second term
Exploitation utility
The exploitation utility takes advantage of the acquired knowledge about the state space. Here, we distinguish two modes: no path found and path found, so that we can incorporate the information about the current solution. To add more flexibility to the algorithm, we assign to it the parameter α, which trades off exploitation and exploration in equation (7), one of the two possible values: (a)
No path found
Before finding a first path, we bias the sampling to connect the state

where the cost to go directly to the goal from
Path found
Once we have found a path, we can exploit this information to derive a richer exploitation utility function. We consider two possible situations: path improvement (see Figure 4(a)), and no path improvement (see Figure 4(b)).

Graphical representation of the exploitation utility in the path found mode: (a) path improvement; (b) no path improvement. The black square represents an obstacle. The red dot corresponds to the sample
Consider that sample

with
In contrast, if sample

It is important to note that, once we have found a first path, we only introduce the ant in table
Update ants
The last step is to update the ants in table

The sample
This complete loop is repeated during n iterations. The output of the algorithm is the trajectory
Anytime ACO-RRT*
The main drawback of the ACO-RRT* algorithm is that it needs more time to find a first path than does the basic RRT/RRT*. This is because of the time needed by the ants to converge the first time. However, the solution obtained has a better quality; that is a smaller cost. There are situations, for example in search and rescue missions, where finding a first solution rapidly is crucial. Then, if we had more time, we could improve it to reach our goal faster. Inspired by Ferguson and Stentz,
35
we exploit this concept in our anytime ACO-RRT* algorithm. First, we run the fastest algorithm (RRT) to find a first solution
Simulations and discussion of results
We tested the ACO-RRT* algorithm performance with a holonomic robot in three simulated scenarios (see Figure 5). We chose a holonomic robot, since it enables us to abstract the algorithm capabilities from the robot’s kinodynamic constraints. We assume that the robot corresponds to a single point. However, more complex robot shapes could easily be introduced within this framework. The three scenarios correspond to realistic scenarios that could be encountered while navigating an indoor facility. Moreover, similar scenarios have been considered to evaluate some of the most recent state-of-the art methods.
7,24
Analysis in more complex scenarios and the consideration of kinodynamic constraints is left for future research. All scenarios measure 100 m × 100 m and the goal is to find the optimal path that goes from
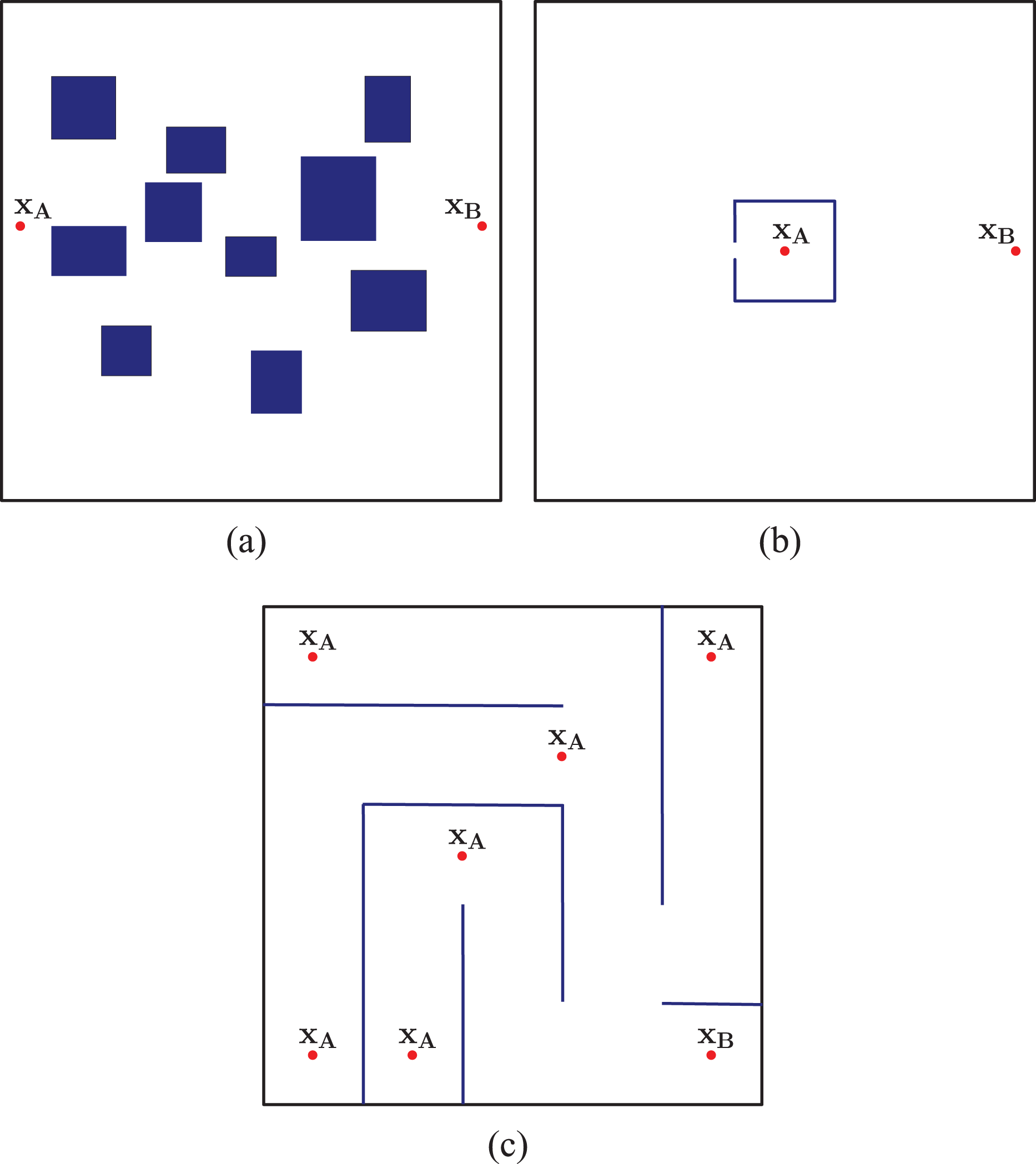
Tested scenarios: (a) Scenario 1; (b) Scenario 2; (c) Scenario 3. We aim to find the optimal path that goes from
We carried out the simulations using a Intel Xenon E31225 processor at 3.10 GHz with 8 GB of RAM. We ran each simulation 100 times, according to the parameters shown in Table 1.
Simulation parameters. For each simulation, we ran the algorithm for 220 s.

We evaluated the following parameters: (i) time to find the first path and its associated cost; (ii) evolution of the cost of the best found path over time; (iii) performance of the anytime implementation; (iv) influence of the different parameters in the algorithm performance.
Time to find first path and associated cost
One of the key figures to evaluate the performance of the path-planning algorithm is the number of iterations needed to find a first path. This is strongly correlated with the cost associated to that path. In Figure 6, we evaluate both indicators for Scenarios 1, 2 and 3. For Scenarios 2 and 3, we represent the time instead of the number of iterations, to demonstrate the algorithm’s performance in an actual system. We compared the ACO-RRT* algorithm with the ACO-RRT, RRT* and RRT algorithms. We did not perform a comparison against the cited state-of-the-art works because they follow a different goal, that of approaching the optimal solution to the path planning problem as quickly as possible. By contrast, the objective of our paper is to show that our algorithm is able to learn some user predefined heuristics and then use them to improve the solution of the original RRT/RRT* algorithms.
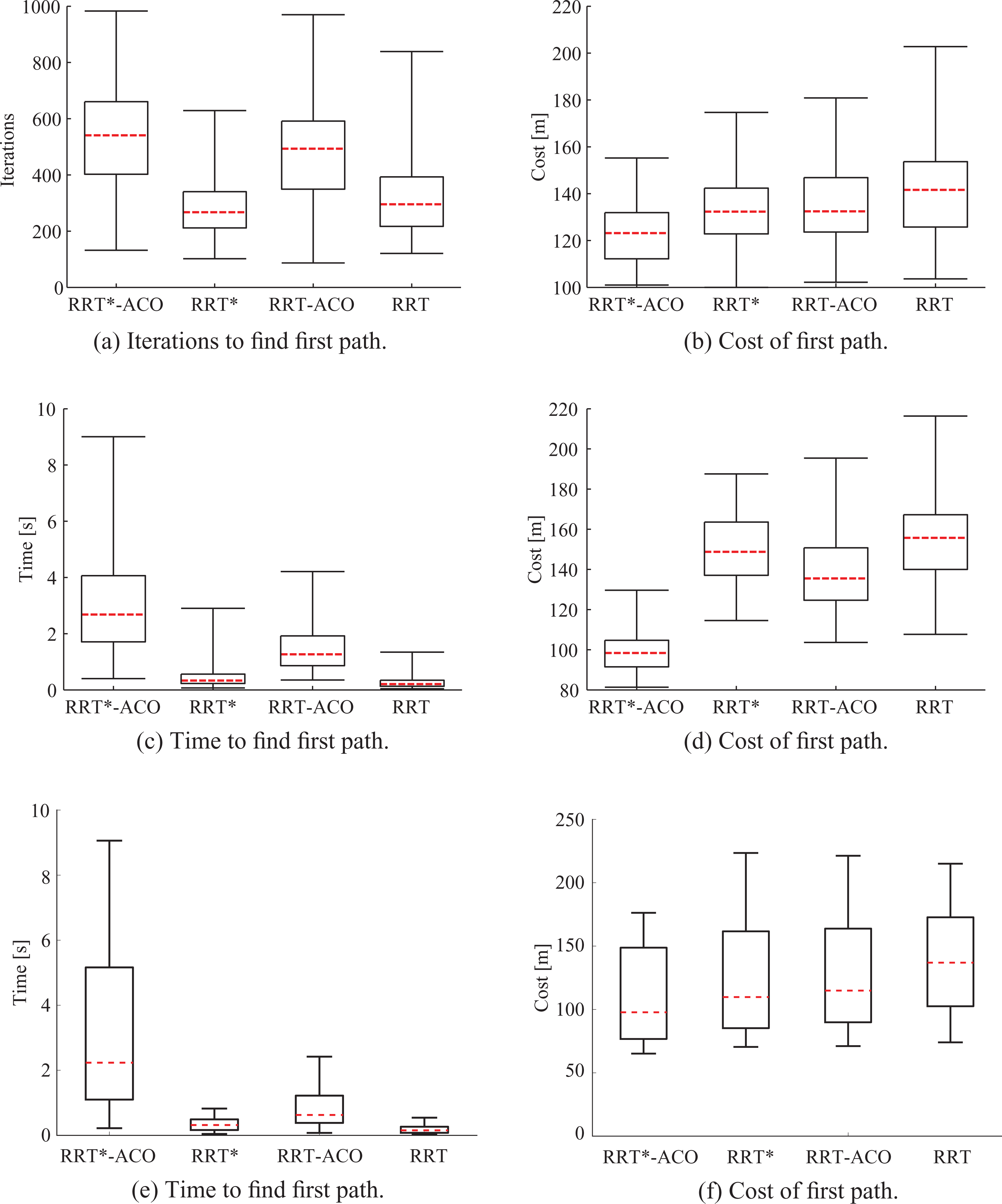
(a, b) Scenario 1. Multiple rectangles. (c, d) Scenario 2. Narrow passage. (e, f) Scenario 3. Maze. Box plot representation of the number of iterations and time to find a first path and its associated cost.
Figure 6 shows a box plot representation of the obtained results, where the dashed red line is the median of the data, the bottom and top of each box represent the 25th and 75th percentiles, and the two strokes encompass the minimum and maximum values. We observe that the ACO-RRT* algorithm finds a better, but slower, solution when compared with the other algorithms. The ACO-RRT* algorithm is slower because the ACO requires some time to place the ants in the best positions to guide the tree’s growth. During the first iterations of the algorithm, the ants are not correctly placed and therefore the planner cannot find a path between the initial and goal position. Conversely, we can conclude that RRT is the fastest algorithm to find a first solution to the path-planning problem, although it has the highest cost. We exploit this capability in our anytime implementation to find rapidly a first solution.
Algorithm performance with time
Once we have found a first path, we aim to improve it to reach the optimal solution. Figure 7 shows the evolution of the best path found over the number of iterations and time. We accompany these figures with a simulation of the algorithm’s complexity for the three scenarios. The results of the proposed ACO-RRT* algorithm are compared with ACO-RRT, RRT* and RRT algorithms.

(a, b) Scenario 1: multiple rectangles. (c, d) Scenario 2: narrow passage. (e, f) Scenario 3: maze. Evolution of the best path cost over time and iterations after finding a first solution. The right hand side shows an evaluation of the algorithm time complexity. (a) Path cost versus iterations. (b, d, f) Time versus iterations. (c, e) Path cost versus time.
The curves in Figure 7 correspond to the mean value calculated over 100 runs. For each of the curves in Figures 7(a), (c) and (e), we have considered the worst case; that is each of the curves starts when a path was found in all the 100 runs. We observe that the ACO-RRT* algorithm offers a superior performance over time. However, for scenario 3, the performance is similar to the one offered by RRT*. This is because Scenario 3 is more structured and therefore, once the algorithm finds a first solution, it has little room for improvement. These results naturally led us to formulate the anytime ACO-RRT* algorithm. Although the solution offered by the RRT algorithm in the first place is of worse quality, we expect to improve it using ACO-RRT*. We expect this combination to incur an increase in performance over time.
Note that the introduction of the ACO increases the algorithm’s computational complexity. This is mainly because of the time needed to compute the ant’s utility and update the table that contains the ants. However, this additional complexity is beneficial, since the ACO-RRT/RRT* offers a better performance.
Anytime ACO-RRT* performance
Figure 8 shows the performance of the anytime implementation of the algorithm. We would assume that the RRT and anytime curves should start at the same position, since both of them start running the RRT algorithm. However, here we represent the first moment in which we have found a path for all the 100 algorithm runs. They would then start at the same point if the number of runs approaches infinity. This algorithm is the fastest to find a first path (equal to RRT) and has the same evolution of the performance over time (equal to ACO-RRT*).

Scenario 1: multiple rectangles, anytime ACO-RRT* performance. (a) Box plot representation of the time to find a first path. (b) Evolution of the best path cost over time once we have found a first solution.
Performance with respect to algorithm parameters
For Scenario 1, we evaluated the evolution of the path cost over time with respect to the number of ants, the exploitation–exploration trade-off parameter, and the evaporation rate; while keeping the not-analyzed parameters constant, according to Table 1. We did not simulate the influence of varying q, since this is strongly correlated with k. This allows us to keep q fixed and just modify the number of ants k.
Figure 9 shows the performance with respect to the number of ants. We also performed simulations with a smaller number of ants but the algorithm was not able to converge to any solution in the given planning time. We observe as well that 50 ants corresponds to the best solution. Increasing the number of ants, however, incurs a decrease in performance. The explanation of such behaviour comes from the trade-off that exists between including more ants to better learn the sampling distribution, and the complexity added at the sampling procedure when increasing the number of ants.
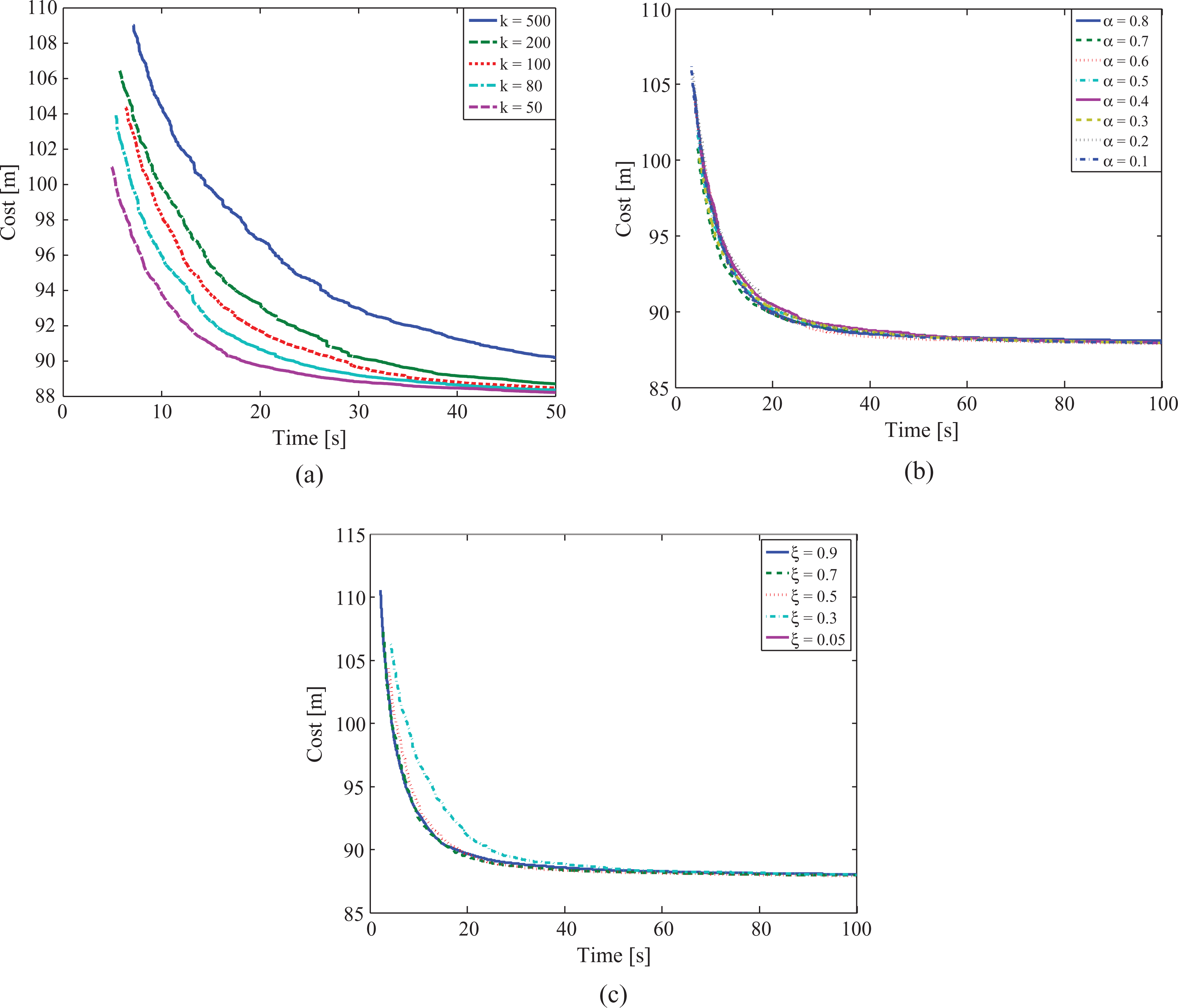
Scenario 1: multiple rectangles; Analysis of the algorithm performance with respect to: (a) number of ants, k; (b) the exploitation–exploration trade-off parameter once we have found a first path,
To analyze the impact of the α factor in the algorithm performance over time, we keep constant
In Figure 9, we observe as well that the algorithm does not converge only for the extreme values of the convergence rate ξ. As in the previous case, it is important that performance does not drastically change as we vary this parameter.
Examples of paths planned with the ACO-RRT* algorithm
We have analyzed the different parameters that influence the algorithm’s performance. In addition, we include in Figure 10 three snapshots of the paths planned after running our proposed ACO-RRT* algorithm. The figures show the resulting trajectory, the samples that conform the tree, and the ants at the end of the algorithm’s execution. We can observe that most of the ants are placed in the region of the state space that contains the optimal trajectory. This results in the presence of more samples in this region, which is the goal of our algorithm. For Scenario 3, it can be seen that the first path found is already very close to the optimal path.

Example of one path planned with the ACO-RRT* algorithm for each of the analyzed scenarios: (a) Scenario 1; (b) Scenario 2; (c) Scenario 3. The large pink dot is the starting position. The red square is the goal region. The final path is coloured red. The black dots are the samples generated by the algorithm. The yellow and pink dots represent the ants’ positions at the end of the algorithm’s execution. The ants represented with the pink dots are the ones that were placed on top of an obstacle during the algorithm’s execution.
Conclusions and future work
In this work, we have proposed and analyzed a novel path-planning algorithm (ACO-RRT*) based on rapidly exploring random trees (RRTs). We have modified the RRT algorithm sampling strategy so that the current tree influences the sampling. This is done by defining a novel utility function in combination with the ant colony optimization algorithm. The utility function is defined to trade off between (i) exploiting the current solution and (ii) exploring the states’ space. We have compared the ACO-RRT* algorithm performance with the RRT and RRT* algorithms in three challenging scenarios. The proposed algorithm is able to find a higher quality first path than the other alternatives (improvement factor between a 1.08 and 1.5). In addition, the results suggest that our algorithm approaches the optimal solution 3.6 faster than the RRT* algorithm. However, it takes more time to find the first path. To reduce this time, we extended the algorithm to an anytime version. Here, the algorithm searches a first path as quickly as possible regardless of the path’s cost, and then improves it using the ACO-RRT* algorithm. Simulations results demonstrate that this anytime ACO-RRT* outperforms the state-of-the-art RRT/RRT* algorithms. We also compared the algorithms’ performance, by varying the different parameters that conform the algorithms.
Future steps are to encompass the experimental validation of the algorithm with a robot-in-the-loop. We also aim to learn the optimal algorithm’s parameters. This could be done by reinforcement learning, where the robot could automatically tune these parameters by analyzing the current solutions as it moves. We are working to extend this framework to handle more complex objective functions; for example autonomous exploration and handling model uncertainty. In addition, a future goal is to perform path planning in an environment populated with obstacles and moving agents that can cooperate. In this situation, we believe we could obtain a great improvement by exchanging ants between agents. Here, we have proposed a framework to treat the rapidly exploring random trees algorithm. We believe that incorporating some of the state-of-the-art methods in this framework, by the definition of proper utility functions, will lead to a greatly superior performance.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: The work of author L. Merino is partially funded by the European Commission FP7 (grant number 611153 TERESA)