
Abstract
In recent years, attention has been increasingly devoted to the development of rescue robots that can protect humans from the inherent risks of rescue work. Particularly, anticipated is the development of a robot that can move deeply through small spaces. We have devoted our attention to peristalsis, the movement mechanism used by earthworms. A reinforcement learning technique used for the derivation of the robot movement pattern, Q-learning, was used to develop a three-segmented peristaltic crawling robot with a motor drive. Characteristically, peristalsis can provide movement capability if at least three segments work, even if a segmented part does not function. Therefore, we had intended to derive the movement pattern of many-segmented peristaltic crawling robots using Q-learning. However, because of the necessary increase in calculations, in the case of many segments, Q-learning cannot be used because of insufficient memory. Therefore, we devoted our attention to a learning method called Actor–Critic, which can be implemented with low memory. Because Actor-Critic methods are TD methods that have a separate memory structure to explicitly represent the policy independent of the value function. Using it, we examined the movement patterns of six-segmented peristaltic crawling robots.
Introduction
In recent years, the frequencies of earthquakes, landslide disasters, and flood disasters have increased. Moreover, anomalous weather such as torrential rains tends to occur. When such a disaster strikes, secondary disasters occur, such as those associated with fires and inflammable material leakage, thereby compounding the hazards confronting rescue workers. Therefore, rescue work using robots in place of humans has persistently attracted attention. 1,2 The development of a robot that can move deeply into small spaces is particularly valuable. 3,4
E Movement mechanisms of rescue robots include wheel, crawler, meandering, and multilegged mechanisms. Each presents the benefit of enabling running on rough terrain while executing movements efficiently. However, their posture stability and space necessary for movement become difficult in movement conditions involving narrow spaces in rubble or plumbing. 5,6
Therefore, we specifically examined a mechanism by which the robot can move through a narrow space, peristalsis: a movement method used by earthworms. We devoted attention to this mechanism from early stages and developed various robots. 7,8
Earthworms have slim bodies with numerous segments connected in succession. The body interior is surrounded by bilaminar muscles of longitudinal muscles along the length of the body and ring-like muscles around the diameter. An earthworm can change its body thickness by contracting those muscles. The segments perform an action called retention when contacting a wall or the ground, and then advance by creating a regressive wave. 9,10 Thereby, the earthworm can advance if given a gap into which its own body can invade. Very little space is necessary for its movement. Moreover, because the earthworm maintains a stable posture by fixing a part of its segment by muscle expansion, no risk of falling exists when it moves. Furthermore, because the earthworm can advance merely through segmented expansion and contraction, it needs no complicated mechanism.
Peristaltic crawling robot drive methods include the use of various technologies: vacuum pressure and pneumatic pressure, 11 –14 magnetic fluid, 7 and shape-memory alloy. 15,16 The peristaltic crawling robots that we intend to produce are designed for activity in disaster areas. For that reason, we chose a motor drive for its high responsiveness, ease of control, and wireless operation.
We assume the movement of a robot in an unknown environment such as a disaster area. Therefore, we considered the derivation of movement patterns of the robot through reinforcement learning. 17 Reinforcement learning is used for behavior acquisition of the robot in unknown environments, providing the capability of choosing an action that reclaims an unknown learning arena. 18 –20 Based on this property, reinforcement learning can adapt to unforeseen circumstances such as a malfunction or failure of its equipment. Peristalsis has the important characteristic that the robot is movable if at least three segments work, even if a segmented part does not function. Therefore, the robot can change movement automatically by applying reinforcement learning.
We earlier produced three-segmented robots and derived a movement pattern using Q-learning, a reinforcement learning technique with high convergence. 21 We strove to examine the movement patterns of many-segmented robots from examination of movement when a robot component breaks down. We also sought to improve propulsion. However, the movements a robot can take increase according to the number of segments. With increased computational complexity, Q-learning became unable to execute a program by insufficient memory. Therefore, we devoted our attention in this study to a learning method called Actor–Critic, which can implement behavioral choice with low memory. In the field of application of algorithm of reinforcement learning techniques for robots, four-legged walking and six-legged walking have been investigated. To enable movement while learning independently in a real environment, researchers have shown great ingenuity in finding appropriate learning algorithms. 22,23 Our peristaltic crawling robot has cylindrically shaped segments that are robust against failure. Each segment has paired two-link mechanisms from 180° to the center of the segment. Therefore, each can achieve peristalsis and produce forward motion while directing its head, equipped with camera and other sensors, to the direction of travel. The multi-segmented structure achieves forward motion assuring its contact with the environment by some segments while maintaining its position. This contact eliminates any complicated rule of learning in a real environment. The angle between two links in a segment does not need to be set precisely. It is accomplished by sensing the driving motor amperage, indicating the degree of contact with environment, and presetting threshold values to gripping force. We wish to examine whether our multi-segmented peristaltic crawling robot can find an algorithm for forward movement using Actor–Critic. Our robot has planar symmetric link mechanisms parallel to the plane passing through the center of the robot body. This article is intended to derive a movement pattern to apply to six-segmented peristaltic crawling robots.
Peristalsis movement method
An earthworm consists of numerous body segments arranged in a line. It moves by forward motion with an elastic wave propagating along its body length. We show the modeled movement of the earthworm to apply the movement method to a peristaltic crawling robot in Figure 1. For example, to cite a process (b) to (c), segment 1 and segment 2 expand and maintain retention by coming in contact with a wall surface in (b). When it shifts to (c), segment 1 shrinks. Segment 3 expands simultaneously. Then, segment 2 continues retention. Thereby, the earthworm advances as much as segment 1 lengthened by shifts from (b) to (c). Using this movement pattern, the earthworm can remain mobile if it has at least three segments.
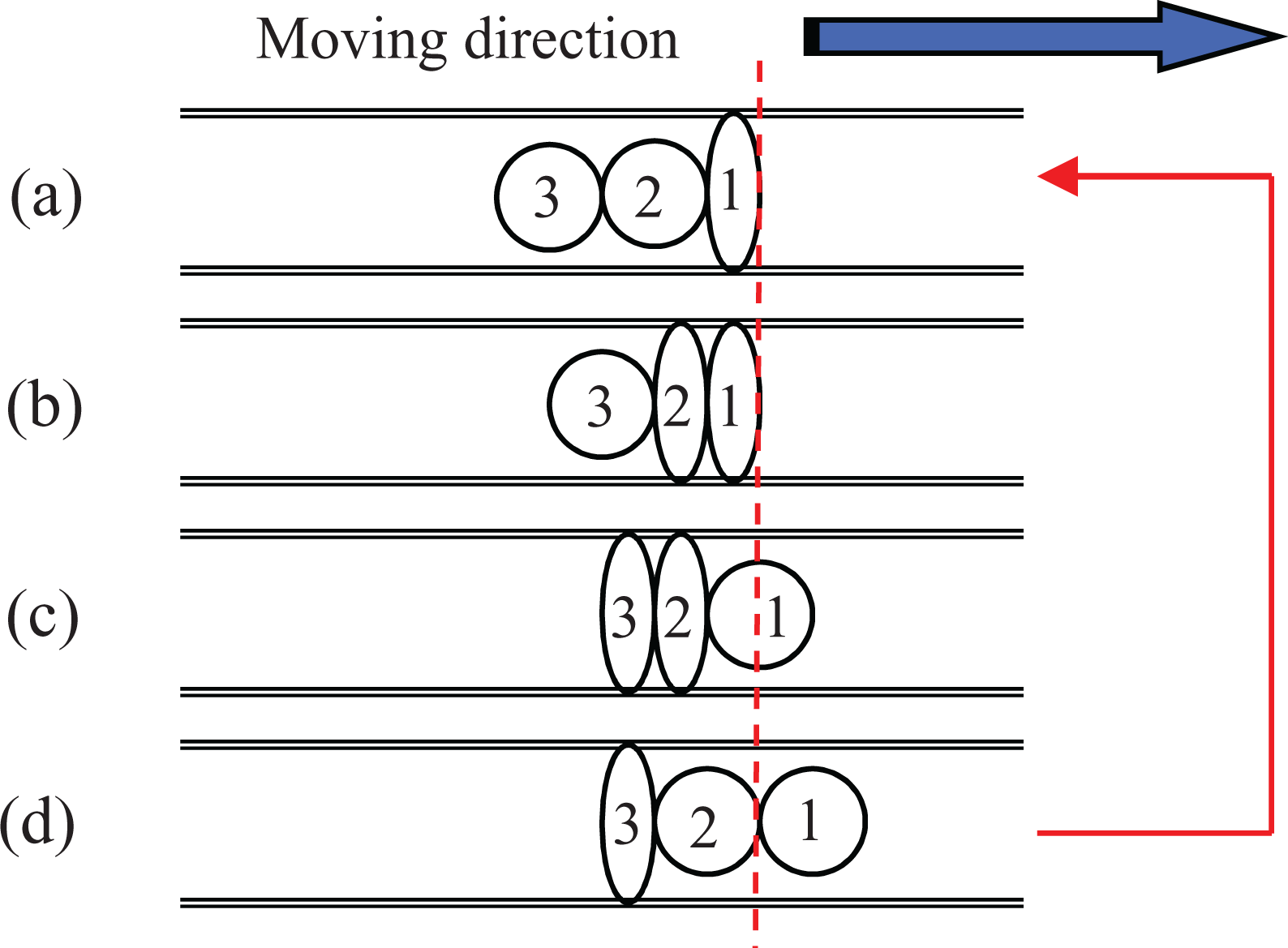
Model of earthworm locomotion.
Peristaltic crawling robot and its drive principle
Figure 2 portrays the peristaltic crawling robot we produced in our laboratory. We use a servo motor (RS601CR; Futaba Co., Japan) for the robot actuator. Servo motor RS601CR specifications include the following.
Max torque: 21.0 (kgf cm)
Max speed: 0.17 (s/60°)
Weight: 93 (g)
Current: 45 (mA) at the time of shutdown (room temperature, under load), 150 (mA) at operating (room temperature, under load)
Voltage: 9.6 (V)
Movable range: 240 (°)
Communication: RS485
Protocol: 8 bits, asynchronous communication

Peristaltic crawling robot of the motor drive.
One segment becomes the symmetric planar link mechanism comprising four motors. One side of the segments uses two motors to impress a force equally upon right and left walls. The robot has a mechanism by which a part called the retentive portion in the center of the segment extends to the outside by motor driving. Because the retentive component comes into contact with a wall, the robot fixes its body by friction and performs retention behavior. Retention is assured by monitoring the motor amperage. The parts to connect to each motor and retentive portion of the robot are made from ABS Plus resin (Stratasys Inc., Eden Prairie, Minnesota, USA). We inferred that the retentive portion made by resin has low frictional force, so we wrapped the retentive portion with an O-ring (ORS30 mm; MiSUMi Co., Japan). We assume that the reference value of the friction coefficient of ABS Plus resin is 0.3 and that the O-ring is 0.5. The robot comprises three segments, which are the minimum necessary to perform peristalsis. Figure 1 shows that each segment can expand and contract independently.
Figure 3 shows that we explain the robot drive principle using a simple model. These alpha characters of model are obverse central segment in Figure 2. It corresponds to one segment. One segment consists of six joints of A·B·C for each two. It is connected by six links. Joints A and C are active joints driven by a motor. B is a passive joint. By turning each joint in a rotary motion, the robot can expand and contract similarly to an earthworm using longitudinal muscles and ring-like muscles. Moreover, ball casters are used to decrease friction. The segmented shape is solely attributable to the motor movement. Using this characteristic, we apply reinforcement learning to a robot model.

Peristalsis one-segment model using the link mechanism.
Reinforcement learning and Q-learning
Purpose and characteristics of reinforcement learning
Reinforcement learning is established to examine the action learning of animals using optimum control theory and to realize it with a computer using various quantitative analytical approaches.
24,25
Reinforcement learning is called “unsupervised learning”. Unlike supervised learning, which shows the right behavioral manifestation for the status input explicitly, the agent cannot estimate whether an action is right. Instead, the agent relies upon “reward” information and learns from that reward. An agent determines “how it can be true” by learning automatically if a designer of the algorithm orders “what must be done” to the agent for rewards. Consequently, reinforcement learning has the following characteristics: It can produce a better solution than an expert had thought possible. It can choose an action in response to an unexpected environmental change.
Moreover, the purpose of reinforcement learning is to learn a policy function that maximizes the final accumulation reward that an agent obtains from the environment. Reinforcement learning obeys Markov decision processes to predict the state and reward of the next time according to the current state and action. A Markov decision process relies on a probability that the state transition depends only on a state and action at that time and has no relations with the state and action preceding it. Therefore, the accumulation reward to be provided in the future is given in equation (1)

Therein, T is the last time, r is the reward every time, and γ is the discount factor (0 ≤ γ ≤ 1). In addition, the expectation of the reward in next state s′ is given in equation (2) when the current state s and action a are given

Moreover, state-value function V(s) indicating the expectation of the reward to be provided in the future by being in state s is defined using accumulated rewards Rt. At the time of state, π is assumed to be a parameter to expressing a policy to take action. Then, the state-value function can be formulated as a function to express the value in state s under policy π, as in equation (3)

These value functions, which begin in arbitrary state s, can be interpreted as a function to output the expectation of the reward to be provided when policy π is obeyed. In other words, the purpose of reinforcement learning is to demand the most suitable policy to maximize the value function.
Temporal difference method
A method used centrally in the field of the reinforcement learning is the temporal difference (TD) method, which combines dynamic programming and Monte Carlo method. 26 –28 The TD method sets up the most suitable state-value function by updating equation (4)
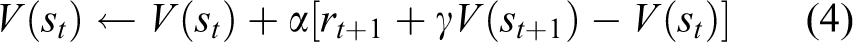
Therein, (0 < α < 1) is called the learning rate. It performs weighting of the learning. If the value of α is large, then the learning advances rapidly. The learning becomes slow if the value is small. In addition, (0 < γ < 1) is called the discount rate. The agent considers long-term rewards if γ is large and chooses an action considering short-term rewards if γ is small. Therefore, reinforcement learning necessitates derivation of an appropriate learning rate and discount factor through a trial and error process with regard to the number of trials. This technique, based on the TD method, includes off-policy TD and on-policy TD.
Characteristics of Q-learning
Q-learning has been used for generating movement patterns of three-segmented robots that we produced because it is used generally and because it has certain convergence by parameter adjustment. Q-learning is called off-policy TD. The update of the value function is independent of the policy. The value function is updated according to an original policy. 7 General reinforcement learning is intended to demand the most suitable policy, but Q-learning is intended to yield the most suitable value function Q (Q value). The Q-learning algorithm is presented in Table 1. It finds the most suitable solution by updating the Q value according to equation (5).
Algorithm of Q-learning.

As might be expected from equation (5), Q-learning can rate an action directly because it rates with the state and action as a set. In addition, the Q value has a convergence theorem that converges in the most suitable Q value with probability 1 in the behavioral choice of the agent when all actions are chosen a sufficient number of times and learning rate α is the function of time t satisfying equation (6)

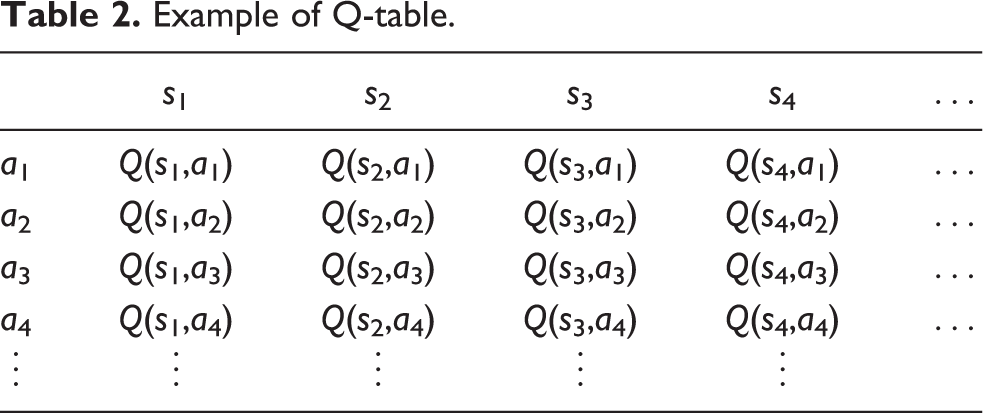
Moreover, Q-learning has the property by which a list of all combinations of action a and state s, called a Q-table, as shown in Table 2, must be made and stored in memory in the program kernel. For example, if the number of states is 10,000 ways and the number of actions is similar, then all combinations of the state and action become 10,000 × 10,000 = 100,000,000. Q-learning presents the important shortcoming that it cannot execute a program when the number of states increases because the Q-table size becomes a huge number. In fact, when we applied Q-learning to a six-segmented peristaltic crawling robot, the Q-table became too large for the available memory. Therefore, we examined an algorithm that can be executed using little memory.
Example of Q-table.
Characteristics of Actor–Critic
The algorithm that we used is the Actor–Critic learning method, a so-called on-policy TD for which application to the continuous state-action space is accomplished easily by reinforcement learning based on the policy gradient method. 25 This learning method standardizes estimation of the evaluation value of each state under some policy and improves a policy according to that value. The Actor–Critic algorithm is presented in Table 3. Actor–Critic can be implemented with low memory. Its learning is extremely rapid because it does not find the most suitable pair of the state and action after estimating the evaluation value of all the state-action pairs as Q-learning does. In addition, because Actor–Critic can use some probability distribution function and a probability density function for the policy function to characterize the behavioral choice, application to the consecutive action space is easy if it uses a simple calculation distribution such as a normal distribution. This approach might fall into a local solution, but it is often used in reinforcement learning to have higher dimensional space because its structure is simple but strong. 29,30
Algorithm of Actor–Critic.

TD: temporal difference.
Based on this property, we used Actor–Critic for reinforcement learning in this study and applied it to the six-segmented peristaltic crawling robot having many behavior patterns.
As its name implies, the Actor–Critic algorithm comprises the Actor part and the Critic part. The Actor part, which has a structure to express a policy, is used for the behavioral choice. The Critic part has a structure to predict a value function. It evaluates an action that the Actor part chose. Therefore, the structure to express the policy becomes independent from the value function. TD error given in equation (7) is used for action evaluation.
Creating the simulation models
Definition of the robot-segmented model
In the simulation model, state s of the robot is expressed as the combination of each segmented shape. Figure 4 shows a simple segmented model of a robot. As a premise, the segment of the robot is assumed to work in symmetry. The segmented state is expressed using a segmented exterior angle θt on simulation (θt = θ1 = θ2). For reduction of the simulation cost, we define the range on the exterior angle as 0–100°, and set it every 20°. In other words, exterior angle θt takes a value from six ways of 0°, 20°, 40°, 60°, 80°, and 100°. Therefore, the number of one-segmented states becomes six. The number of the actions becomes six ways, too.
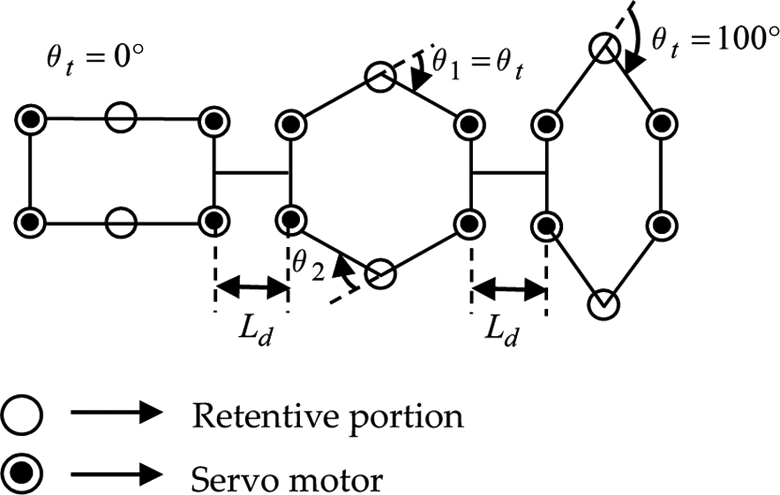
Change of the exterior angle of the robot model.
As the number of the segments increases, the state and action patterns also increase. A robot of the n-segmented structure will have the pattern of 6n ways. Here, 0° expresses the state in which the segment of the robot shrinks completely. The retentive portion lengthens outward as it becomes large. Moreover, joint length Ld between each segment is constant.
Relations of a simulation model and running course
Figure 5 shows the relations of the peristaltic crawling robot model and the running course. As shown, we define the coordinate system. The robot is located in the running course of the constant wall width such that the top of the robot points the positive direction of the x-axis and the tail of the robot is at the origin. The initial state of the robot is the state in which all segments shrink in the x-axis. The robot task is to get closer to the target position put on the x-axis. However, we define the target position as sufficiently more distant than the total robot length. Therefore the x-coordinate of the target position is 3000 mm and the wall width is 250 mm because the purpose of the learning expresses the generation of the movement pattern used to advance.
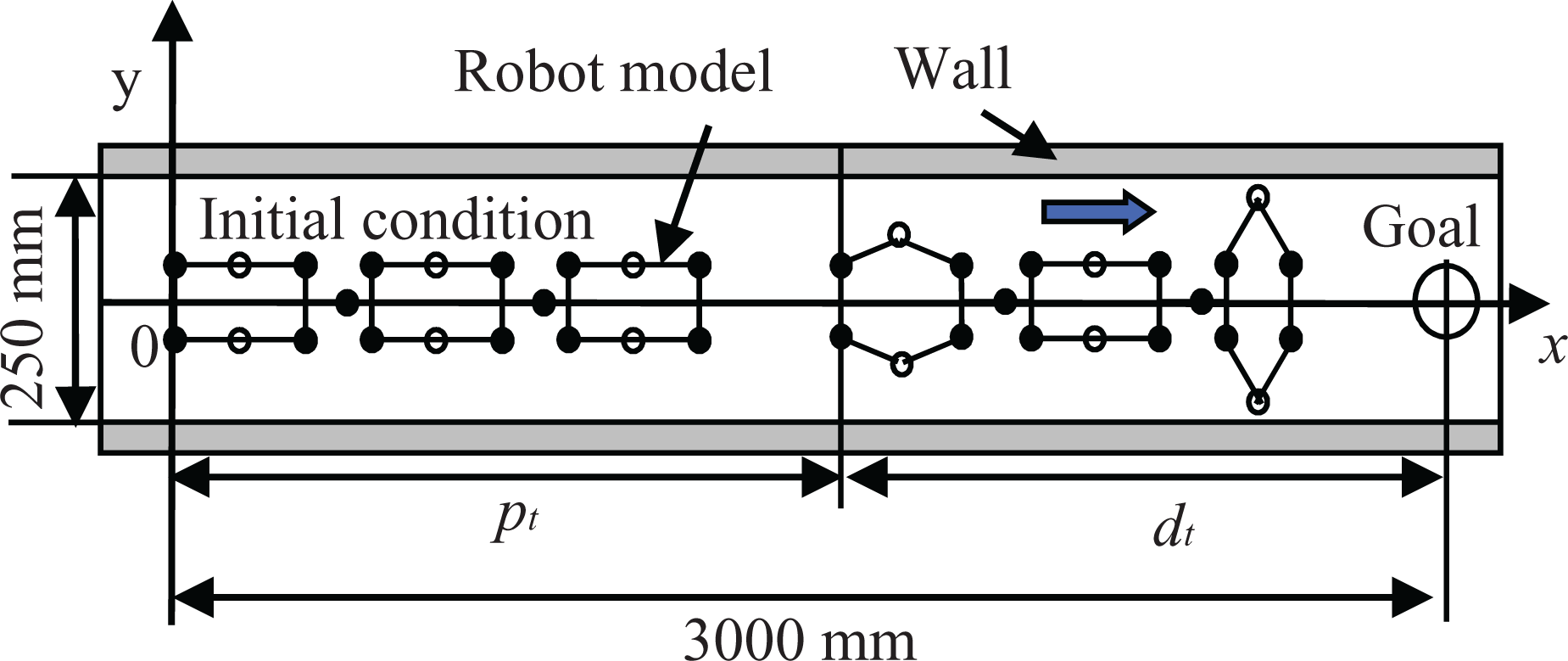
Simulation model of the robot.
When the movement distance from the tail of the robot to the start position at time t is pt , then the distance dt to the target position is expressed as shown below

In addition, reward rt at time t is expressed as

Moreover, when action at+ 1 at time t + 1 is equal to action at at time t, the TD error δ becomes −1 as a penalty. When the TD error is a negative value, the action is chosen only rarely. Simulation was done using a computer: core i7 960 3.20 (GHz) CPU, 9.00 (GB) memory and Windows 7 (64 bit) OS. The software is MATLAB (ver. 7.11.0 (R2010b); MathWorks, Natick, Massachusetts, USA).
Parameters in Actor–Critic
We intended to execute a program using little memory. Reinforcement learning accomplishes behavioral choice by producing a random number based on a normal distribution. The value of an action for each state sn is expressed using a normal distribution. The amount of necessary memory becomes the “number of states × 2” because the normal distribution is expressed only by the central value and standard deviation. Therefore, the memory requirement is less than that for “number of action” × “number of states” of Q-learning. The algorithm provides the standard deviation and central value for each state of the robot model sn . It also updates those values using the TD error at every step. If the standard deviation is small, then the distributions become narrow, and the constant value becomes chosen easily. For example, if the algorithm produces a normal random number for state s 100, then action a 50 is chosen. Consequently, if the TD error is a positive value, it updates the parameter to close the central value to a 50 because evaluation of the action is high, which raises the probability that a 50 is chosen. By producing the uniform random numbers at the beginning of the program, the agent takes a random behavioral choice because the probability of all actions becomes uniform. The standard deviation becomes smaller at every updating of the policy. Therefore, the ranges of the distribution finally become a line and the algorithm comes to output one value. Figure 6 presents an example of the change of the distribution in the case of applying the algorithm to the three-segmented robot model.
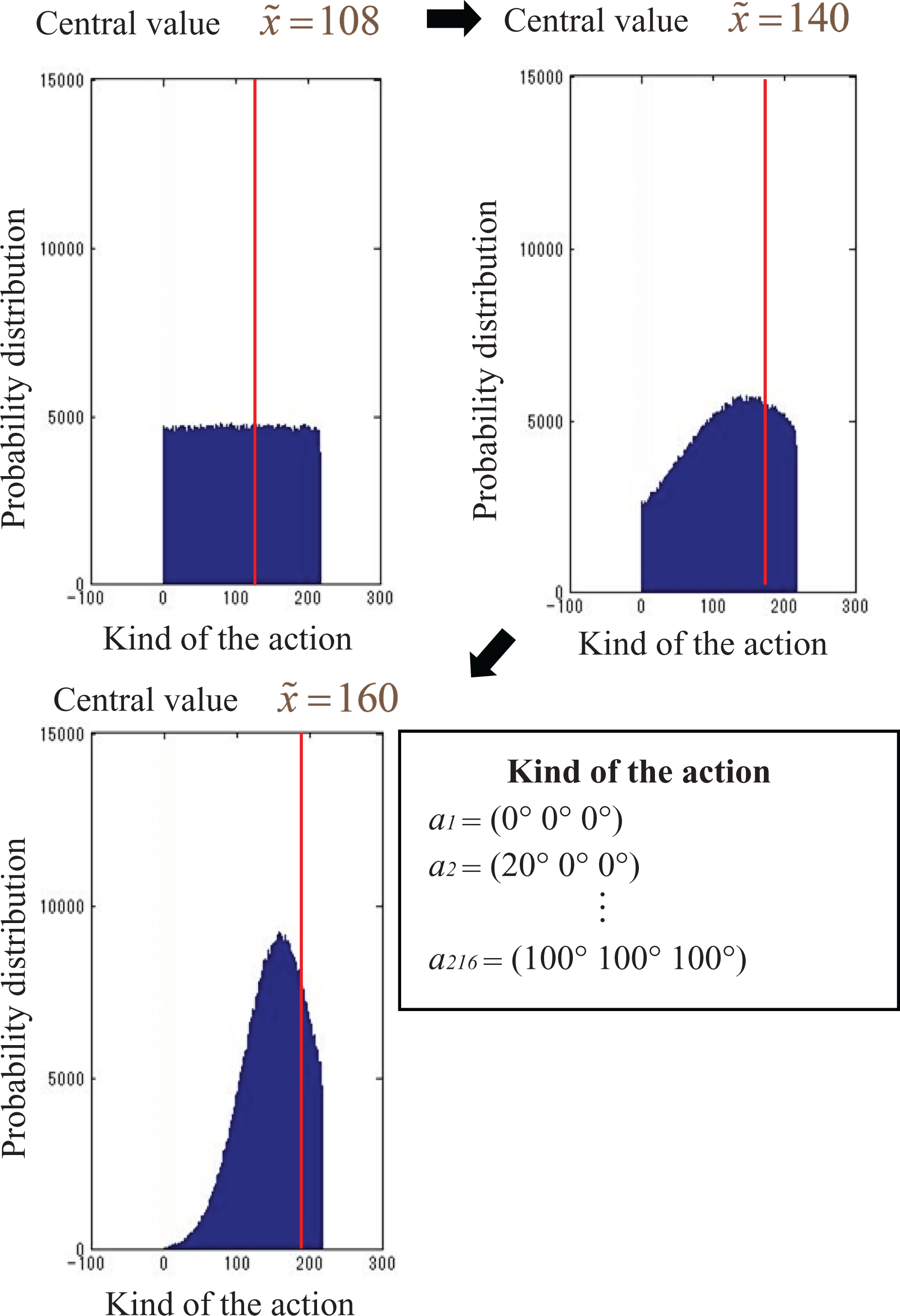
Simulation results of the probability distribution by the behavior selection. (Case: three-segmented robot.)
Comparison between Q-learning and Actor–Critic in three-segmented robot models
We compare each algorithm of Q-learning and Actor–Critic for derivation of the movement pattern of the three-segmented peristaltic crawling robot model. The learning target is defined for both as the derivation of the movement pattern to obtain the greatest movement distance. We ascertained the visible differences under the conditions of 40 steps and 3000 trials. As a method of each behavior choice, Q-learning is used with Boltzmann selection. Actor–Critic is used as the behavior choice based on a normal random number.
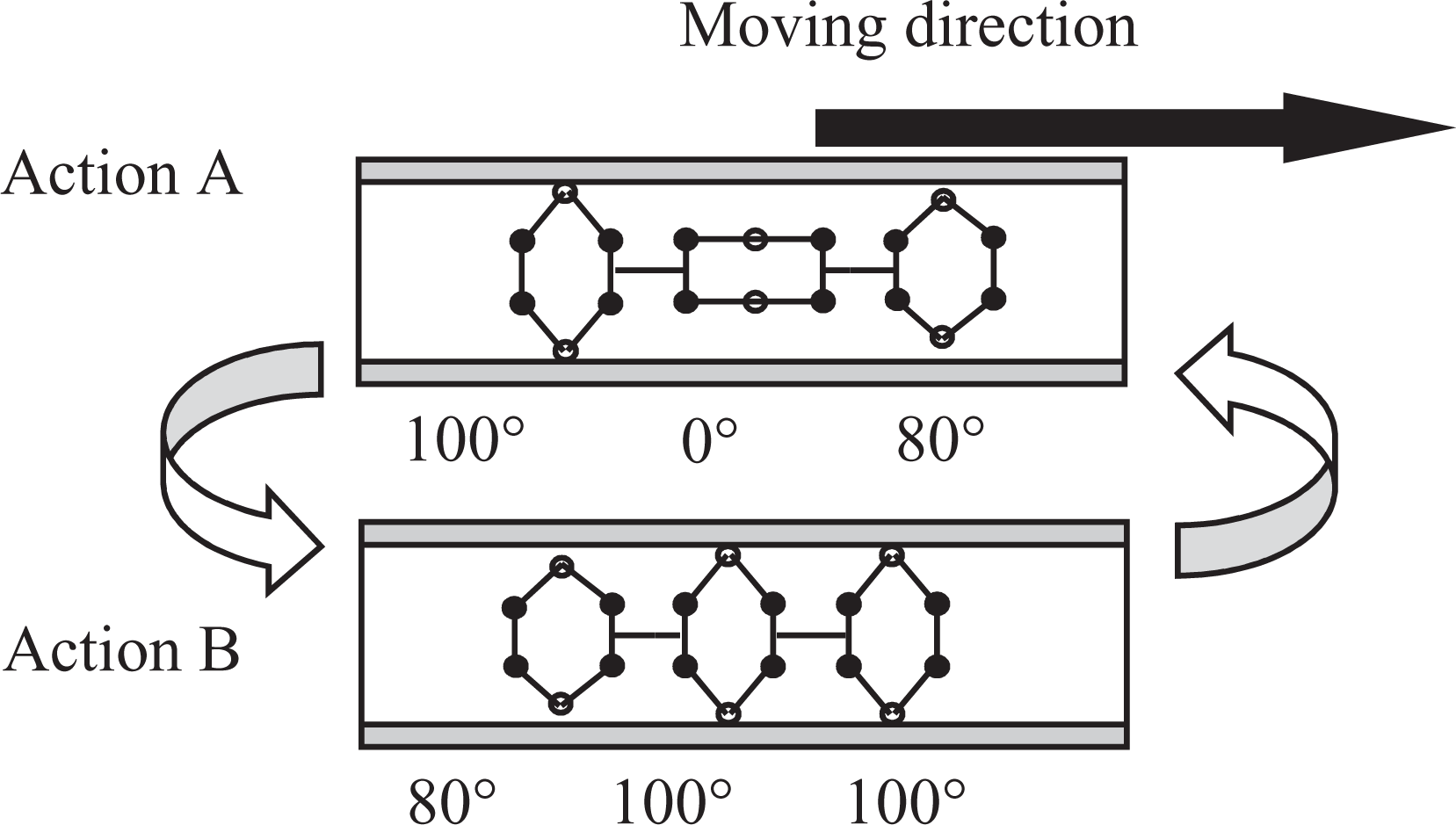
By tuning up the learning rate and discount factor, results showed that Q-learning converges when α = 0.7, γ = 0.4. Actor–Critic converges when α = 0.6 and γ = 0.9. Figures 7 and 8 show simulation result of the summation of the rewards. A great difference is apparent in a mode of the convergence because of the difference in parameters. However, the simulation result of movement patterns shown in Figures 9 and 10 output identical movement patterns. If this movement pattern is applied to the robot, it performs as shown in Figure 11.

Simulation result of summation of the rewards. (Case: Q-learning, three-segmented robot.)

Simulation result of summation of the rewards. (Case: Actor–Critic, three-segmented robot.)

Simulation result of each segment angle. (Case: Q-learning, three-segmented robot.)
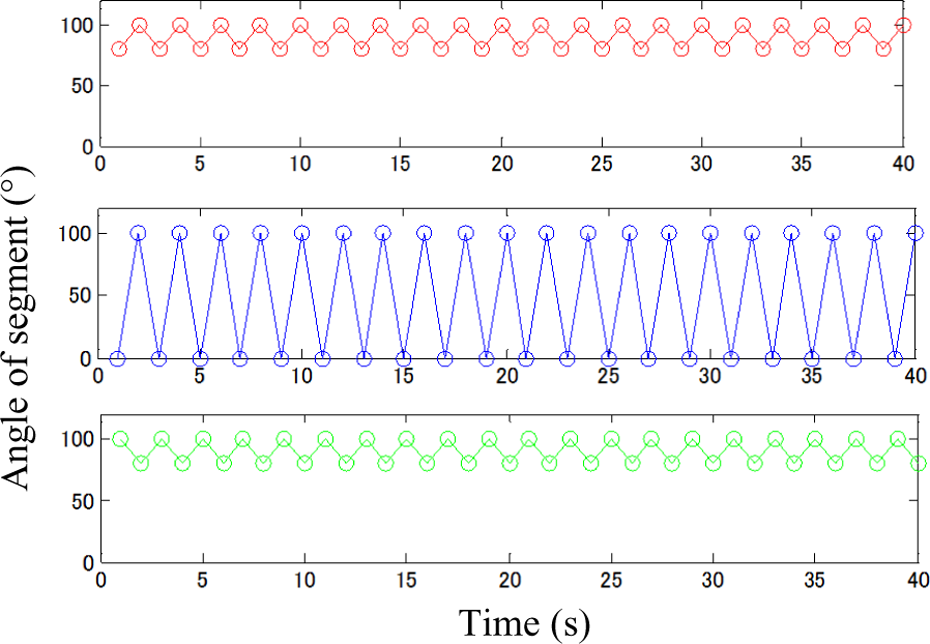
Simulation result of each segment angle. (Case: Actor–Critic, three-segmented robot.)
Three-segment robot motion. (Case: three-segmented robot.)
As the figure shows, the robot model repeats the two patterns of action A and action B. Central segments and top segments begin the expansion when the robot shifts from action A to action B. Then the top segment comes in contact with a wall earlier than central segments and can pull in central segments. Moreover, the tail segment comes in contact with a wall when the robot shifts from action B to action A, and central segments are pushed. Action A performs (a) and (b) in Figure 1 simultaneously. Action B performs (c) and (d) simultaneously. We infer that this movement is equal to the movement pattern of peristalsis that is provided.
Therefore, Actor–Critic can be confirmed as effective as an algorithm for use as a Q-learning substitute. In addition, the behavior choice method affects the difference in the mode of the convergence. As the number of trials increases in Actor–Critic, the standard deviation becomes small. The chosen value approaches the central value. However, the value near the central value is chosen easily. Actions of the value near the central value are not necessarily as good as the action of the central value. A rather bad action might be chosen. When the standard deviation becomes sufficiently small that only the central value is chosen, the agent chooses a suitable value and Actor–Critic converges completely. Therefore, the accumulation reward does not increase until immediately before the convergence.
We implemented the pattern of action thus learned in our prototype robot through the AD/DA board from the PC and tested its performance to confirm forward movement similar to that shown in Figure 11.
Simulation results in a six-segmented robot
The movement pattern shown in Figure 12 was provided after simulating a six-segmented robot model using Actor–Critic instead of Q-learning. As parameter settings of the simulation, 45,000 trials were done, with 140 steps. The learning rate was α = 0.4. The discount factor was γ = 0.7. We set these parameters according to results of trial and error because infinite combinations of values of the parameters exist. In fact, deriving good combinations of the parameter values is difficult. We pulled out a part of the provided movement pattern of each segment angle and located it to the right in Figure 12. Results show that the top and tail segments repeat 100° and 80° in turn and that the central segments repeat 100° and 0° simultaneously. Therefore, the top and tail segment repeat the wiggle angle change for retention with a wall. The central segments repeat the wide angle change for advancement. The movement pattern to liken the central segments to one segment and create a regressive wave occurs when we conduct simulations for four-segmented and five-segmented robot models. Therefore, we understand that the most suitable movement patterns of peristaltic crawling robots exhibit some regularity.

Simulation results of the segment angles. (Case: Actor–Critic, three-segmented robot.)
However, this study provides not a movement pattern by the simple regressive wave, but a special movement pattern in which the central segments behave as if they were one segment by performing the same movement. When a six-segmented peristaltic crawling robot creates a regressive wave for every segment, six movement patterns are necessary, as shown in Figure 13. However, if the robot moves using the movement pattern of Figure 14, it can advance through the same distance by two movements. Therefore, we can ascertain the most suitable movement pattern using reinforcement learning.

Motion pattern using regressive wave. (Case: six-segmented robot.)

Six-segmented robot motion.
Conclusion
This study derived a movement pattern for application to a many-segmented peristaltic crawling robot using Actor–Critic. Q-learning was unable to perform calculations because of lack of memory, but Actor–Critic can derive the movement pattern algorithm of a six-segmented robot. Results show that the robot can advance with two motion patterns by moving central segments simultaneously. An effective movement pattern is provided from simulations because the movements are fewer than under real peristalsis. This movement pattern is a new movement that is not used for traditional peristaltic crawling robots.
As future work, we plan to produce six-segmented robots and to examine whether robots can function according to the movement patterns found from this study. Using this derivation method, all segments of the robots other than the top and tail segments are expected to perform the same movement even if the number of the segments is increased. For that reason, only the top or tail segments will maintain retention. Therefore, safety aspects will be insufficient. We intend to resolve this difficulty by considering conditions such as the robot dead weight. Additionally, we plan to examine a movement change algorithm to be used in times of trouble. Thereafter, we shall improve it for use in various environments.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.