
Abstract
This article explores the use of fractional factorial designed experiments to help select the observations that are provided to a reinforcement learning agent for a hexapod robot trajectory-following task. A hexapod robot simulator is developed in the MATLAB Simscape environment and uses a central pattern generator consisting of 6 coupled Hopf oscillators and corresponding joint angle mapping functions to move the robot. The reinforcement learning agent is trained to control the hexapod using the deep deterministic policy gradient algorithm on a trajectory-following task. To test different combinations of seven potential observations, both quarter-fraction and eighth-fraction factorial designed experiments are proposed to reduce the number of runs from the maximum possible 128. Through the implementation of these designed experiments, regression models were formulated to predict which combinations of observations maximize the hexapod training reward. Model predictions were then validated using the simulator, and the corresponding trajectory-following capabilities of the hexapod were demonstrated. For the conditions used in this research, the observations that obtained the maximum final average reward are the hexapod's joint torques, body linear velocities, body orientation, body angular velocities, and body height above the ground.
Keywords
Introduction
Mobile robotics play an increasingly important role to complete dangerous tasks in remote, hazardous, and extreme environments in the fields of surveillance, demining, inspection, rescue operations, and exploratory missions. 1 Such robots must be capable of overcoming difficult terrain in challenging environments without the need for human intervention. Walking hexapod robots are an ideal candidate for these roles as they offer several advantages over other mobile robotics platforms, including excellent maneuverability, versatility over complex terrain, better stability, redundancy to limb faults or failures, and adaptability to specific tasks or environments. 2 Research in the control of hexapod robots has progressed from traditional kinematics- and dynamics-based controllers, to biologically-inspired controllers using central pattern generators, optimization of gaits using genetic algorithms, and, more recently, machine learning using reinforcement learning (RL). 1
The current direction of the literature is for mobile robots to become increasingly independent of human operators using machine learning. Recent works have demonstrated the application of RL to train and control hexapod robots in complex environments for both path-planning navigation and complex locomotion tasks. RL allows a mobile robot to modify its behavior and walking gait in response to changes in terrain, external stimulus, and other inputs. RL agents are trained through a repetitive process where the hexapod must repeat a similar task many times to iteratively modify its behaviour to obtain a maximum reward for the given task. One such RL algorithm that is used in the present work is the deep deterministic policy gradient (DDPG).
There are numerous factors and parameters that influence the success of an RL agent. One of the most important factors is the selection of the observations which correspond to the measurements of the robot state and environment provided to the RL agent. In many machine-learning problems, the maximum amount of data available is provided to the learning algorithm; however, in practice, the observations needed to successfully learn a particular locomotion task will affect the physical hardware required and the design of the robot itself. There may be limitations in hardware cost, physical size constraints, or power requirements that necessitate the selection of a limited number of observations for a hexapod robot. The optimal combination of observations for a given RL task must be determined through testing; however, this process can lead to issues with constraints caused by the length of agent training time. Ibarz et al. 3 discuss the importance of sample efficiency as many widely-used RL algorithms require millions of interactions over the course of training. Training can take a considerable amount of time, even within a simulation environment. This article presents the idea of using a fractional factorial designed experiment to gain insight into the relative importance of different observations using a reduced number of training runs so that engineering decisions can be made about the sensor package to include on a hexapod robot.
Originally developed for use in the fields of agriculture and industrial manufacturing, design of experiments (DOE) is a statistical methodology used to create experiments that are able to provide insight into the effects of various factors on a process result in the most efficient way possible. 4 In the present research, the RL training routine is the “process,” the observations are treated as “process factors,” and the final average reward is taken as the measurable “process result.” With the overall goal of finding combinations of observations that maximize the final average reward, this research explores the potential application of a fractional factorial DOE in the selection of observations for a hexapod locomotion task.
RL in hexapod control
As noted by Coelho et al., 1 the recent trend in controlling hexapod robots shows the emergence and increasing use of RL in the literature over the last half-dozen years. RL has significant advantages over other control methods in terms of reactions to external disturbances and changes to the environment.
A central pattern generator (CPG) can successfully produce smooth walking gaits for a hexapod, and further tuning and optimization of the gait can be performed using genetic algorithms. However, these methods are limited in that, once the gait has been determined, it typically remains fixed throughout deployment and cannot react to disturbances or environmental changes outside of those set in the predetermined gaits. RL agents, however, are able to react to external stimuli and, through varied and extensive training, have been shown to be able to generalize their behaviors to previously unseen circumstances. For example, Heess et al. 5 demonstrated the emergence of complex locomotion behaviors for both a quadruped and a humanoid if provided sufficient observations during training in a complex and diverse simulation environment.
To demonstrate the variety of observations used for RL in the literature, the present authors carried out a systematic review, and the results are presented in Table 1. To narrow the scope of the literature search, this table only includes work which uses a hexapod or quadruped robot platform, as these robot configurations are similar in both performance and control requirements. Note that bipedal robots were excluded from this review as they are not statically stable and thus may require different observations.
Summary of observations used in the literature.

Of key interest for the present research is to keep the sensor and processing power requirements of the robot platform to a minimum; therefore, complex exteroceptive sensors such as cameras or LiDAR are excluded. The review of the current literature focuses on work that utilizes proprioceptive sensors and exteroceptive sensors that require relatively low processing power, such as ultrasonic distance sensors. The hexapod can also be provided with observations which are not measurements but, instead, commands to the RL agent—such as a desired walking direction. In cases where a multi-level RL control scheme is implemented, this review focuses on the lower-level leg control network rather than the higher-level path-planning network.
Table 1 provides a visual representation of the types of observations used in the literature. The table indicates (with a black dot) if the particular observation is used in the given paper. There are also two additional columns on the right-hand side, which indicate if the given paper provides the previous time step's actions back to the RL agent as observations, and if any other unique observations are used. The body displacements category refers to whether the robot is provided with knowledge about its location within the environment according to a reference point. The body height is the distance between the robot's body and the ground.
Table 1 clearly shows that, while some observations may be more common than others, there is no consensus within the literature on which set of observations to use for the RL locomotion of a hexapod or quadruped robot. The present authors propose using a factorial designed experiment to aid in the selection of appropriate observations to use when designing a hexapod robot for an RL-based locomotion task. While methods such as hand tuning or ablation-based pruning of potential observations may yield acceptable results, a designed experiment offers a more systematic approach to gain an understanding of a system and the influence of its factors. This work aims to demonstrate that the knowledge gained through a designed experiment about the effects of observations on the hexapod performance is a valuable tool in aiding with hexapod design for RL.
Simulator development
An 18 degrees-of-freedom (DOF) hexapod simulator was developed in the MATLAB Simscape environment, and DDPG RL was implemented in the simulator using the RL Agent Simulink block. 28 The simulation environment consists of a smooth flat plane with a friction coefficient between the hexapod feet and the ground, modelled after a rubber-tipped foot on a hard industrial floor. The path-following task illustrated in Figure 1 is used as the simulated test case in this article. The hexapod starts at a random offset perpendicular from a desired trajectory line, as shown in the figure. The goal of the RL is for the hexapod to correct its initial offset by tracking towards and then following along the goal trajectory line.
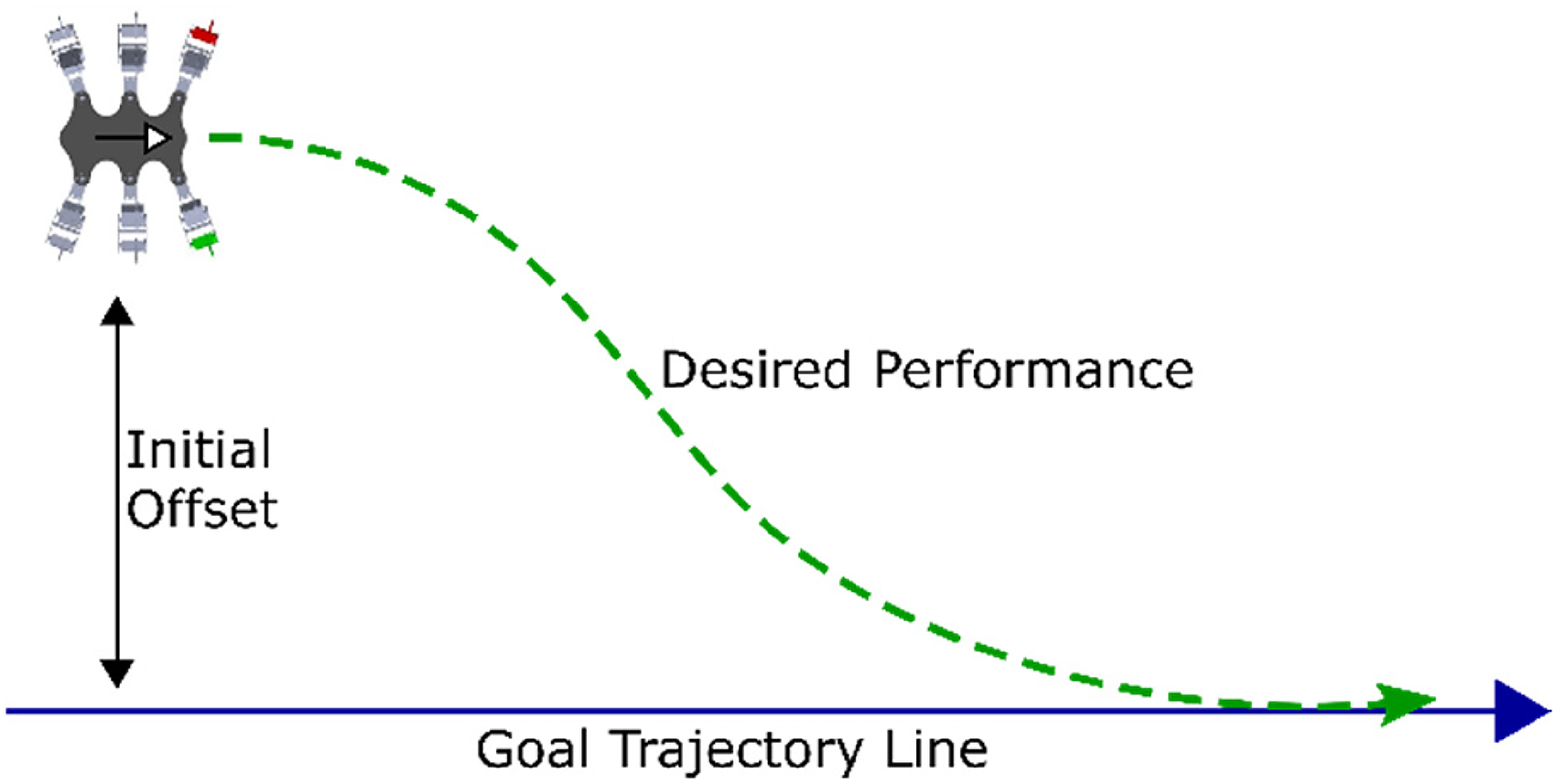
Desired hexapod trajectory tracking behavior for the 18 degrees-of-freedom (DOF) hexapod (six legs and three DOF per leg).
Action space and central pattern generator
The action space of the hexapod control system uses a CPG in combination with a set of mapping functions to produce smooth joint angle signals while offering precise control over the motion. The oscillators and mapping functions described by Wang et al. 29 for use with a genetic optimization algorithm are extended in this work to function with an RL agent.
The CPG consists of six coupled Hopf oscillators, which, through the adjustment of their parameters, offer control over the amplitude, frequency, and phase angle between the hexapod's six legs. The Hopf oscillator is a proven basis for central pattern generation applied to hexapod robots.9,14,29,30 Each leg of the robot is controlled by an individual oscillator, and the inter-oscillator coupling determines the phase differences between the hexapod's legs. Each of the six coupled Hopf oscillators is described by the following equations9,29: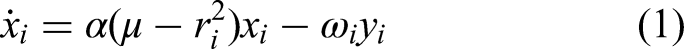
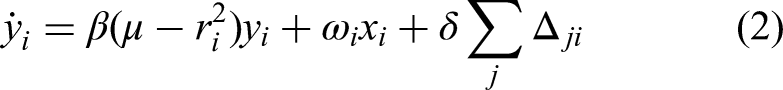
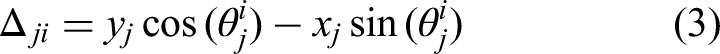
Mapping functions are used to transform the Hopf oscillator x and y signals into joint angle signals for each of the hexapod's 18 DOF. There are six sets of mapping functions (one for each individual leg). The mapping functions take the state variables x and y from the Hopf oscillator and convert them into three angle signals for the hip, knee, and ankle joints of the corresponding leg. The mapping functions presented by Wang et al.
29
utilize piecewise functions for both the knee and ankle angles to differentiate between the swing and stance phases of the leg motion. In the present work, these piecewise functions are replaced with a single function for all conditions, as the RL agent should be able to infer when each leg is in a swing or stance phase from the provided observations, and the agent can also adjust the mapping function parameters in reaction to external stimuli. The mapping functions corresponding to each Hopf oscillator are as follows:

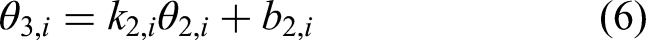
Observations
The observations considered in this research utilize sensors that are internal to the hexapod robot, meaning that the hexapod could be operated in an unstructured environment. There are some observations which are always used and are, therefore, not included as “factors” in the designed experiment. These observations are considered essential for achieving the desired performance of the hexapod or are readily accessible without the need for additional sensors.
The observations that are included in all the designed experiment runs are the joint angles (3 joint angles per leg × 6 legs = 18 joints), the joint angular velocities (18 joints), the Hopf oscillator x and y parameters (x and y parameters × 6 coupled oscillator = 12), the previous time step actions (30 parameters in the action space), and the offset from the goal trajectory line (one distance measurement).
The observations (and associated number of measurement signals) which are used as “factors” in the designed experiment to study their relative effect on RL performance are the joint torques (18 joints), the body linear velocities (three axes), the body orientation (four parameters in the form of a quaternion), the body angular velocities (three axes), the body height above the ground (one distance measurement), the magnitudes of the leg tip ground contact forces (6 normal + 6 frictional = 12 forces), and the leg tip ground contact binary signals (6 leg tip contacts, +1 if contact, 0 if no contact). All observations are normalized to lie between ±1 before being passed to the neural network.
The reward function
The reward function is designed to train the hexapod to follow the desired trajectory line. The reward function contains positive reward terms to encourage positive actions, and negative reward terms to discourage undesirable actions. The total reward is calculated as shown in equation (7), with the individual reward terms detailed in Table 2. Note that the C parameters in Table 2 correspond to reward term scale factors.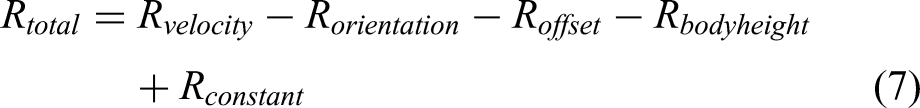
Detailed breakdown of reward function terms.

The reward function terms were chosen in order to achieve the path trajectory following goal. The forward velocity and offset from the goal trajectory line terms directly reward the hexapod for the desired behavior. The body orientation and body height penalties provide additional feedback to help produce a gait with a smoother motion of the hexapod body, which could be carrying a payload and/or sensors during deployment. The constant term added to the reward function helps the RL agent at the start of training to encourage the agent to utilize the entire training episode without triggering an early termination (due to, for example, flipping upside down to avoid future penalties). The reward term scale factors are of similar magnitude and were determined through manual tuning and remain fixed for the entirety of this work. While changing the weighting of the reward terms can affect the resulting performance of the hexapod, in this work, the decision was made to focus the designed experiments on the selection of observations while keeping the reward function fixed.
The RL agent
The hexapod is controlled by an RL agent trained using DDPG, 31 which has been proven effective for legged robotics locomotion applications.8,12,14,15 The actor and critic networks applied in this work utilize the same structure and size as those found in Mathworks, 32 which applies RL to a quadruped robot with a similar number of observations and actions.
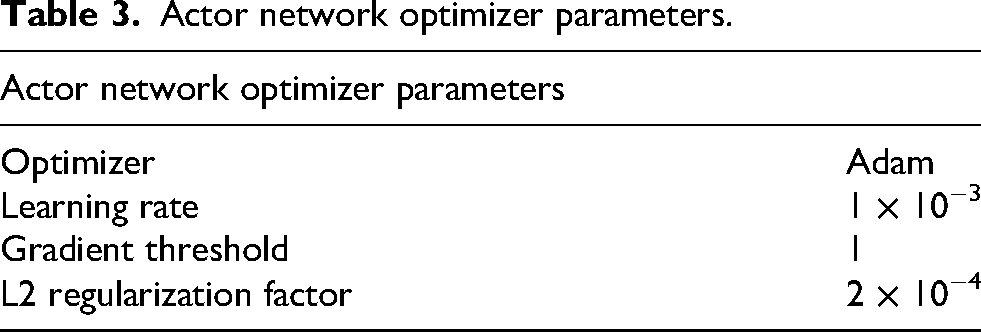
The actor network takes as input the observations from the hexapod simulation and outputs the next time step actions with the goal of maximizing hexapod performance on the trajectory following task. As shown on the left-hand side (LHS) of Figure 2, the actor network consists of an input layer for the observations, two fully connected hidden layers, and a fully connected output layer. The input layer size changes based on the number of observations used in the trial, but the remaining layers maintain a fixed number of nodes. The two hidden layers and output layer have 400, 300, and 30 nodes, respectively. The hidden layers utilize a rectified linear unit (ReLU) activation function, while the output layer uses a hyperbolic tangent activation function to produce the 30 actions with values constrained between ±1. The optimizer parameters set in the MATLAB simulation driving script for the actor network are listed in Table 3.

Actor (LHS) and critic (RHS) network flowchart representation.
Actor network optimizer parameters.
The critic network takes as input the observations from the hexapod simulation and the action signals produced by the actor network, and outputs the expected reward that will be obtained using the given actions. As shown on the RHS of Figure 2, the critic network consists of two initially separate branches that merge to produce a single output. The first branch has an input layer of the observations, followed by two fully connected hidden layers of 400 and 300 nodes. The second branch takes as input the 30 actions from the actor network and has a fully connected hidden layer of 300 nodes. Both branches of the network are connected with an additional layer that appends the two branches into a single layer of 600 nodes. Following this layer is a fully connected layer of a single node, which produces the critic output. All hidden layers use ReLU activation functions, while the final output layer does not have any activation function to generate the critic output. The optimizer parameters set in the MATLAB simulation driving script for the critic network are listed in Table 4.
Critic network optimizer parameters.

RL training routine
Each RL training routine consists of 1000 individual episodes. Each episode lasts 15 seconds. The RL training hyperparameters are shown in Table 5. These values were determined by starting with the values used in Mathworks, 32 and then fine-tuning them by hand before completing the designed experiment study. The parameters in Tables 3 to 5 remained fixed throughout the designed experiments.
DDPG learning hyperparameters set in the driving routine.

The designed experiment
The observations which are varied in the designed experiment (called factors) are given an indicator letter as follows: joint torques (A), body linear velocities (B), body orientation in the form of a quaternion (C), body angular velocities (D), body height from the ground plane (E), magnitudes of the leg tip ground contact forces (normal and frictional) (F), and leg tip ground contact binary signals (G). The seven possible observations each have the option of being on or off (used for learning or not); therefore, they are two-level factors.
Seven two-level factors lead to 128 possible unique combinations from which an optimal set of observations for the given locomotion task can be selected. In addition, due to the inherently-random nature of RL, multiple repetitions (called replicants) of each case were carried out to help distinguish between the performance of different combinations of observations. For this work, 10 replicants were selected for each case to help ensure that there is a statistical significance when comparing learning results.
A quarter-fraction factorial designed experiment was tested, which consists of 32 separate cases to be run. This number is significantly lower than the 128 required for the full factorial designed experiment. With 32 cases for the quarter fraction designed experiment and 10 replicants per case, a total of 320 separate RL runs were needed. The quarter-fraction factorial design was selected as it is an IV resolution design where no main factors are aliased with any first-order interactions. As sensor measurements on the hexapod can be physically related (e.g. ground contact of the feet can affect the body tilt), it is desirable that no interactions are confounded with any of the main effects. The design generators for the quarter-fraction experiment using the principal fraction are
An eighth-fraction factorial design was also tested to determine if the number of cases to run could further be reduced to 16 while still maintaining a suitable level of accuracy. The IV resolution eighth-fraction design has generators:
Both factorial designs were set up using the Minitab statistical software. 33 Tables 6 and 7 show the design table for the experiments generated using Minitab, where each case was repeated for 10 replicants to account for the random nature of RL. A plus sign in the tables indicates that the observation will be used for the specific case, while a negative sign shows when the observation is turned off. The only changes to the hexapod simulation throughout this study are the set of observations used (according to Tables 6 and 7), which, in turn, affects the number of nodes in the input layer of both the actor and critic networks. All other aspects of the simulation remain fixed.
Quarter-fraction factorial designed experiment test plan (× 10 replicants).

Eighth-fraction factorial designed experiment test plan (× 10 replicants).

The recorded performance metric used as the response in the analysis of the designed experiments is the final average reward at 1000 training episodes. This performance metric was selected because after 1000 episodes, the learning of the RL agent has generally plateaued, and the agent has reached its maximum potential for the given set of observations. When training in simulation to deploy on physical hardware, the final performance of the RL agent was considered more important than its learning speed, so 1000 episodes were used to ensure the RL agent could reach its peak performance.
Analysis of results
This section presents and analyzes the results of the designed experiments. Detailed step-by-step analysis of the quarter-fraction factorial designed experiment data is presented in this section, with the analysis of the eighth-fraction experiment following an identical procedure. Using the gathered data, a regression model is formulated to model how the observations affect the hexapod performance. This model is then used to predict which combination of observations yields the highest rewards during training. The metric used to evaluate the performance of the RL agent using different observations is the final average reward after training for 1000 episodes. The model predictions and corresponding trained agent are then validated within the developed hexapod simulator.
To evaluate the regression model fit, the following three R2 statistics are used. 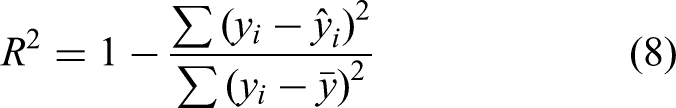
The adjusted statistic 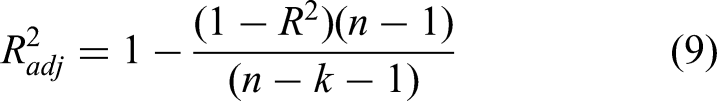
The third statistic is the predicted R2 value 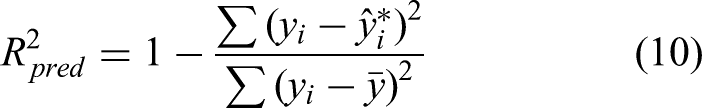
The resulting learning curves for each of the 10 replicants for a given case (corresponding to a particular combination of observations) can be plotted together on a single graph to visualize the repeatability of the learning process. Figure 3 shows the 10 replicants for case 5 of the quarter-fraction experiment as a representative example. The moving average reward curves are plotted as a function of training episode and shown in Figure 3 as black lines. An overall average reward curve is shown by the thicker red line. Figure 3 shows that, for case 5, eight out of the 10 replicants follow a very similar learning curve, while two of the replicants failed to learn and appear as outliers in the data. A similar spread of learning curves and outliers obtained for multiple repetitions of the same DDPG learning process were also observed by Naya et al. 15 and Schilling et al. 21 The learning routine includes several randomized processes, such as initialization of neural network weights and biases, as well as noise artificially introduced for exploration of the possible action space. As a result of the stochastic nature of RL, some outliers in the data are inevitable.

Learning curves for all 10 replicants of case 5.
Table 8 summarizes the results of the quarter-fraction designed experiment showing, for each case, the average final reward of 10 replicants. Referring to this table, it is interesting to note that using the maximum number of observations (case 32) does not achieve the highest learning performance. Case 32 (which contains all seven observations) yielded an average final reward over 10 replicants, which is lower than cases 6, 8, 14, 16, 21, 22, 28, 30, and 31 (which all contain different combinations of fewer than seven observations).
Summary of results of the one-quarter fraction designed experiment.

Cases with rewards in bold font have average final rewards that are higher than case 32 (which contains all seven observations).
A regression model was fit to the data to model how the seven studied observations affect the hexapod performance. As the designed experiment featured 32 separate cases, the regression model can have a maximum of 32 terms. The fit of the regression model is evaluated using R2 values as well as studying the distribution of the model residuals.
The model residuals for the initial fit can be illustrated using a histogram plot as shown in Figure 4. The residuals are grouped into 20 bins of equal width over the total range of average final reward values, with the frequency in each bin shown on the vertical y-axis. Figure 4 clearly shows that the initial regression model generated in Minitab is not a good fit to the final reward data since, instead of a zero-mean normal distribution, the residuals’ distribution is skewed to the left and the peak of the distribution is shifted to the right of zero.
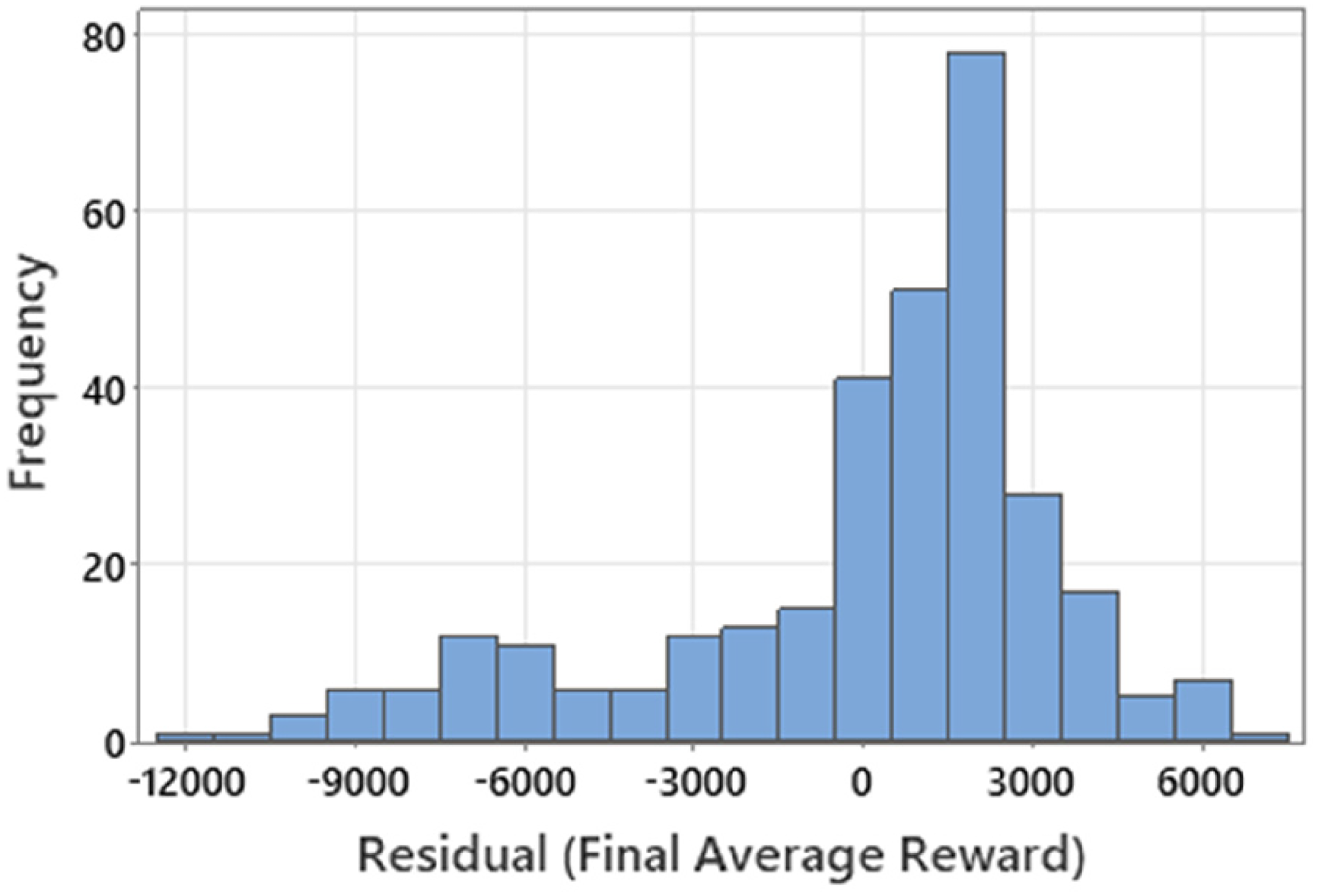
Histogram of residuals for the initial model fit.
Three steps were taken to improve the model fit and produce the final regression model. First, the worst three replicants of each run were removed from the analysis to eliminate the worst outliers. Fitting the model to the best seven replicants of each run effectively removed the long tail on the LHS of the residual distribution and centered the residuals about zero as desired.
Given that the goal of this research is to explore the potential for the application of a designed experiment in the selection of observations for deployment on a physical robot hexapod, it is reasonable to remove outlying replicants because, in a deployment scenario, only the best RL agents would be considered for the hexapod from multiple learning routines.
Next, the final average rewards were transformed using the following nonlinear transformation to further improve the model fit:
Finally, the 32-term model was reduced to 13 terms by eliminating interaction terms having less than a 5% significance to arrive at the final regression model. The histogram of residuals for the final model is shown in Figure 5. This histogram displays a wide peak centered around zero, which shows that the model is a good fit to many of the experimental data points. There are only three residuals skewing the LHS of the distribution, which would be expected from runs with combinations of observations that result in inconsistent and poor learning.
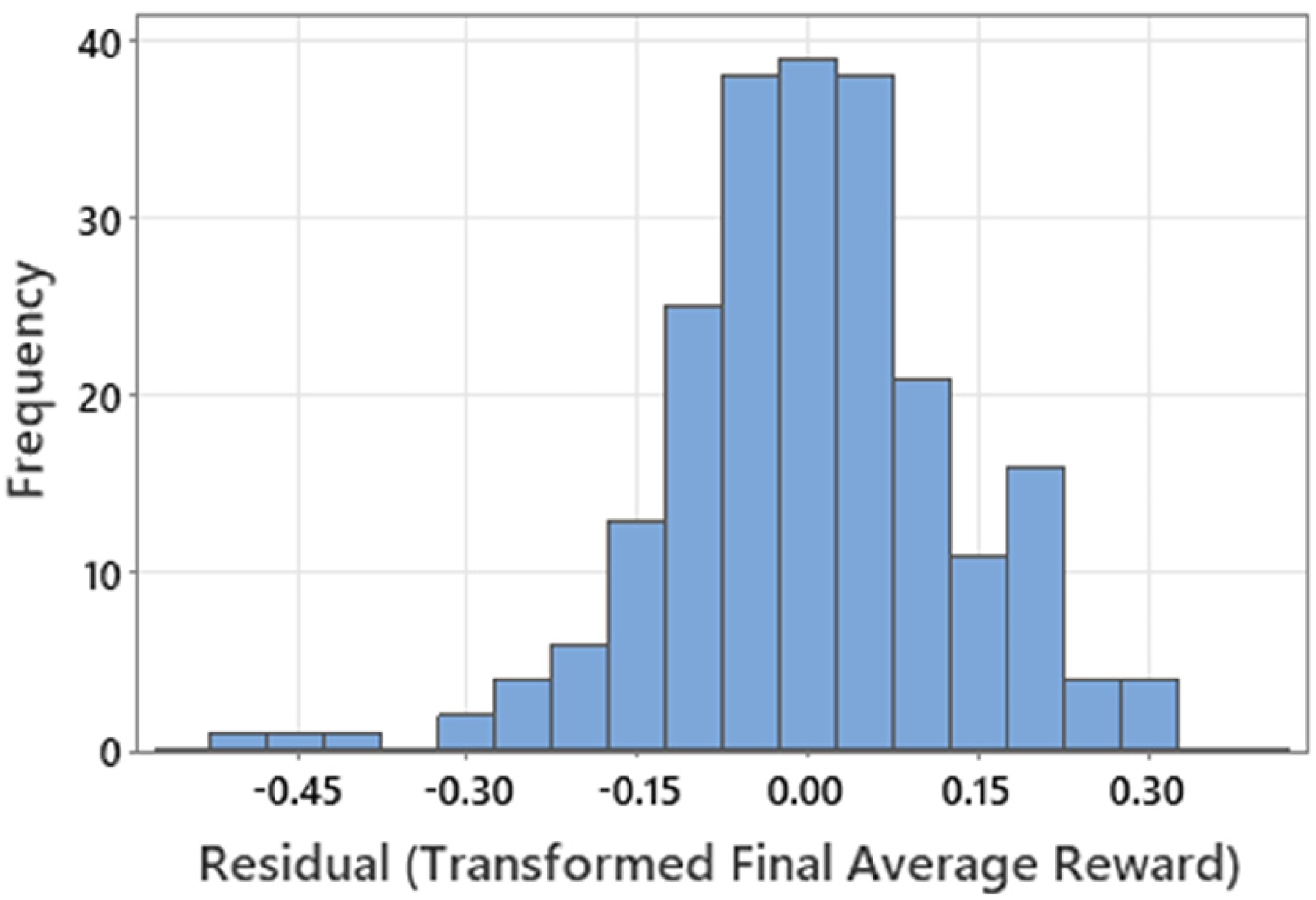
Histogram of residuals for the final model.
The residuals of the final model are also plotted on a normal probability plot as shown in Figure 6. A normal probability plot shows how the experimental data differs from the desired normal distribution by illustrating deviations from the diagonal red line (where the red line represents a random normal distribution). It can be seen in Figure 6 that the blue residuals closely follow a normal distribution, confirming the successful fit of the final model.
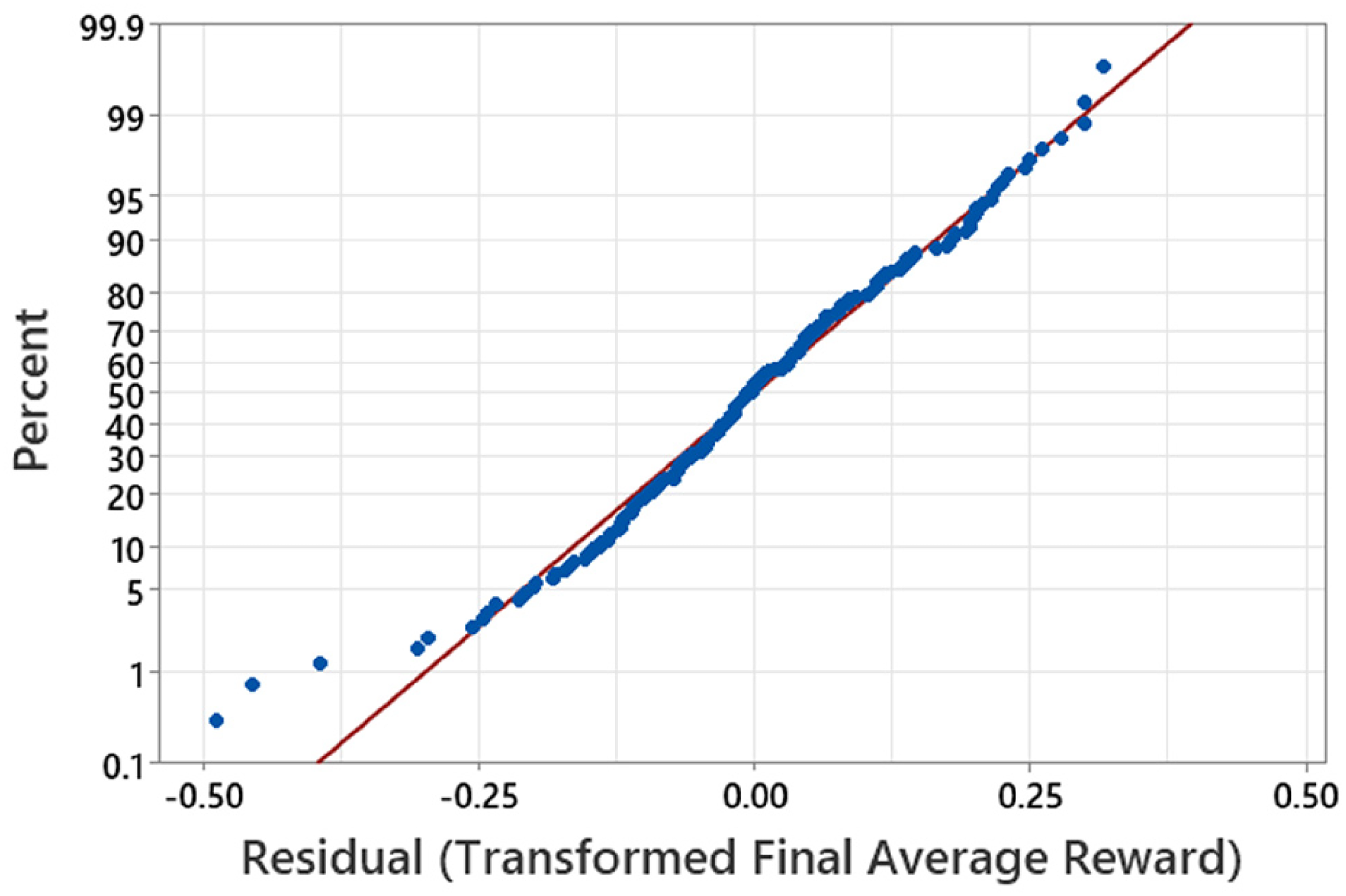
Normal probability plot for the final model.
Table 9 summarizes how the
Improvement in model fit with each key step in the analysis.

The final regression model determined using the quarter-fraction experiment design is given by equation (12), where each letter would be replaced with either the number 1 if the observation is present, or −1 if the observation is turned off.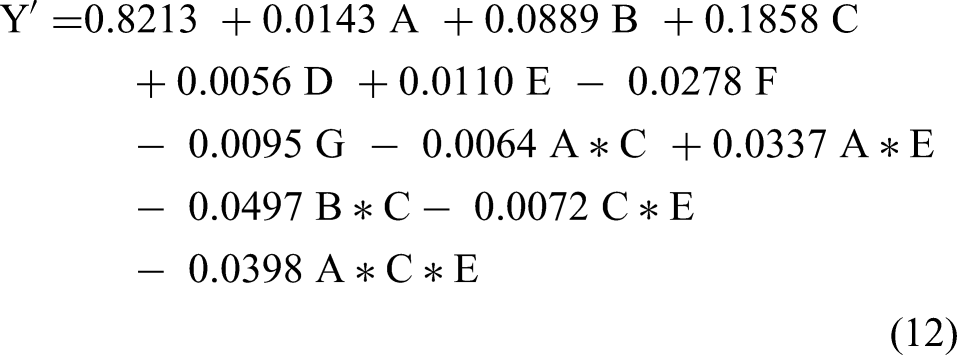
The resulting data generated through the quarter-fraction designed experiment can be compared to that from the eighth-fraction experiment. Figure 7 shows the mean effect of each observation calculated from the data of both designed experiments, along with the associated standard errors. The mean of all experimental runs, which both included and excluded each given observation are plotted to show the average effect of the observation. Figure 7 demonstrates how the mean effects captured in the experimental data are comparable for both quarter and eighth fraction designed experiments, as they have overlapping error bars for all seven observations—an indication that even 16 runs can be sufficient to model the effects of the observations. As can be seen in the figure, for the simulation conditions used in this work, the body orientation (observation C) proved to be the most important factor for maximizing hexapod performance.
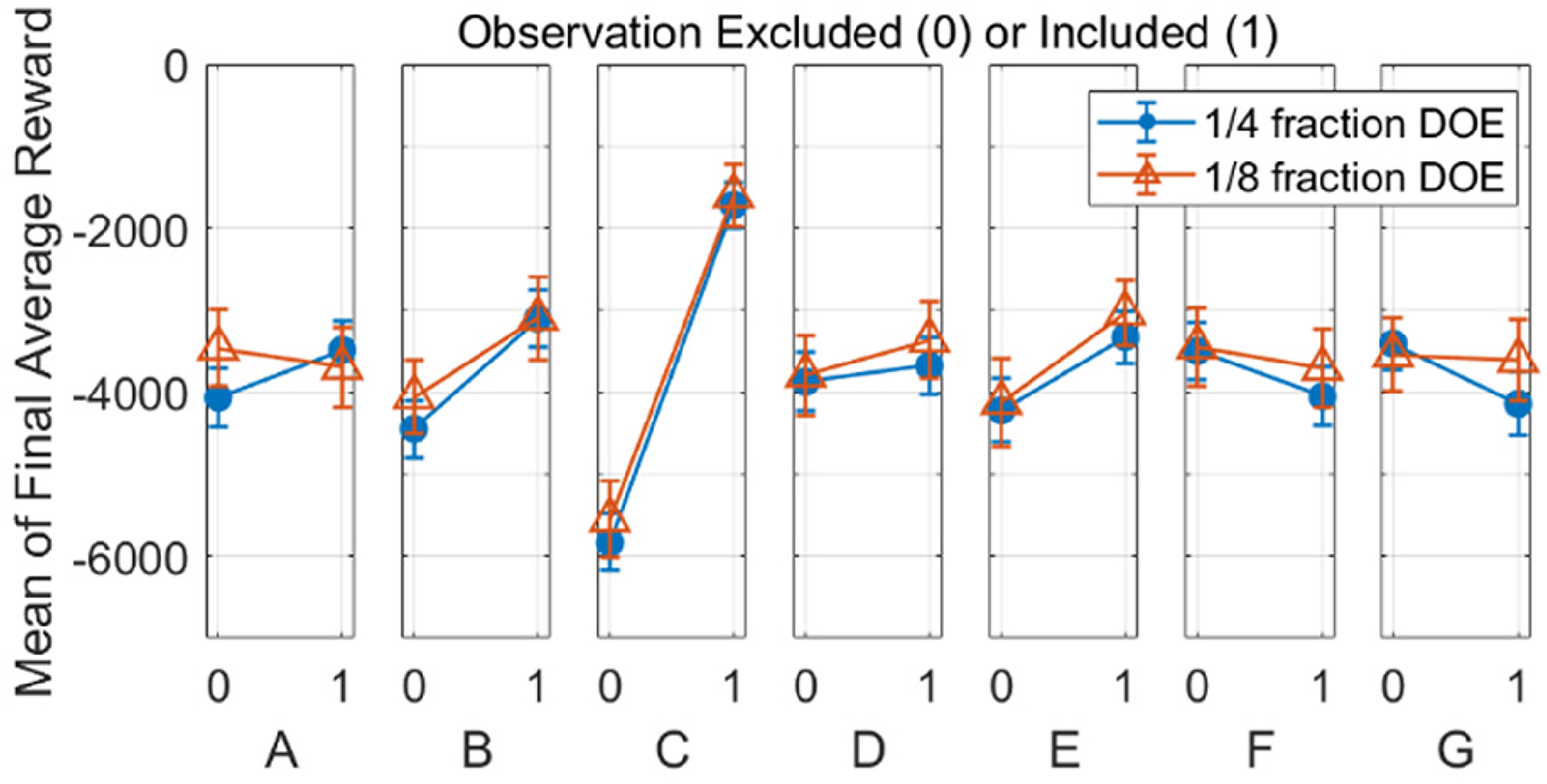
Mean effect of observations on the final average reward as calculated from the 1/4 and 1/8 fraction experiments’ data.
Through an identical analysis method to that previously described for the quarter-fraction experiment data, the regression given by equation (13) can be determined from the data of the eighth-fraction designed experiment.
Both models from equations (12) and (13) are then used to predict the hexapod performance for all 128 possible combinations of observations from the small subsets tested in the designed experiments. Figure 8 shows the predicted final average rewards for all combinations in order of performance with the associated 90% confidence intervals in the predictions. Figure 8 shows that the predictions from both the quarter (blue dots) and eighth (red triangles) fraction designed experiments have overlapping 90% confidence intervals across the entire range of performance. Combinations of observations that are close in ranked performance have overlapping confidence intervals due to the stochastic nature of RL. If tested, one could expect that any given combination of observations could change in ranking based on the overlap with nearby confidence intervals. In practice, one might test the top 5 to 10 predicted combinations and select the final set of observations based on these validation tests.
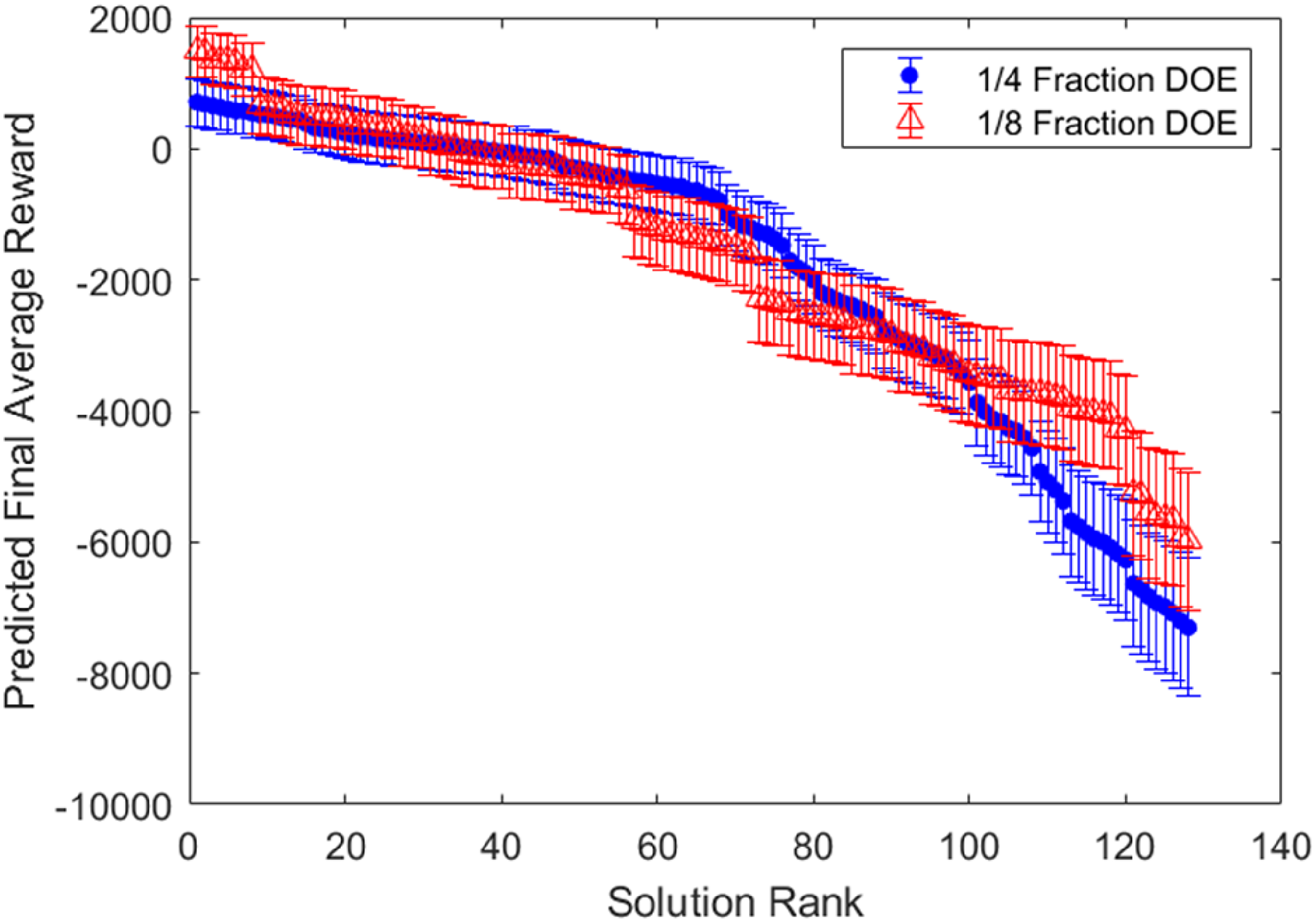
Predicted final average reward for all 128 combinations of factors in order of performance with associated 90% confidence intervals.
The three highest-ranked solutions that were predicted by the quarter-fraction model were tested in the simulation environment to validate the results. These solutions are summarized in Table 10 and correspond to the three highest predicted final average rewards on the LHS of Figure 8.
Summary of the three highest-ranked solutions predicted by the ¼ fraction experiment model with associated 90% confidence intervals.

When tested, all three solutions achieved final average rewards within the predicted confidence intervals. During this validation testing, the second solution achieved the highest reward of all cases completed in this work, without being a part of the initial cases from the designed experiment. Since the confidence intervals are overlapping between adjacent solutions, and the learning results will always contain some level of noise, any one of the top three solutions could have produced the highest average final reward—in this instance, it was solution #2. These results demonstrate that a designed experiment could potentially be a valuable tool when selecting and optimizing the observations needed for a hexapod locomotion problem. Based on these validation tests, for the conditions used in this research, the observations achieving the highest average reward correspond to solution #2 as follows: the joint torques (A), body linear velocities (B), body orientation (C), body angular velocities (D), and body height (E).
Finally, the trained RL agent was deployed within the simulator to demonstrate the ability of the hexapod to follow a moving goal trajectory line. Figure 9 shows a top-down view of this case study in the x–y plane, where the goal trajectory line alternates at regular intervals between
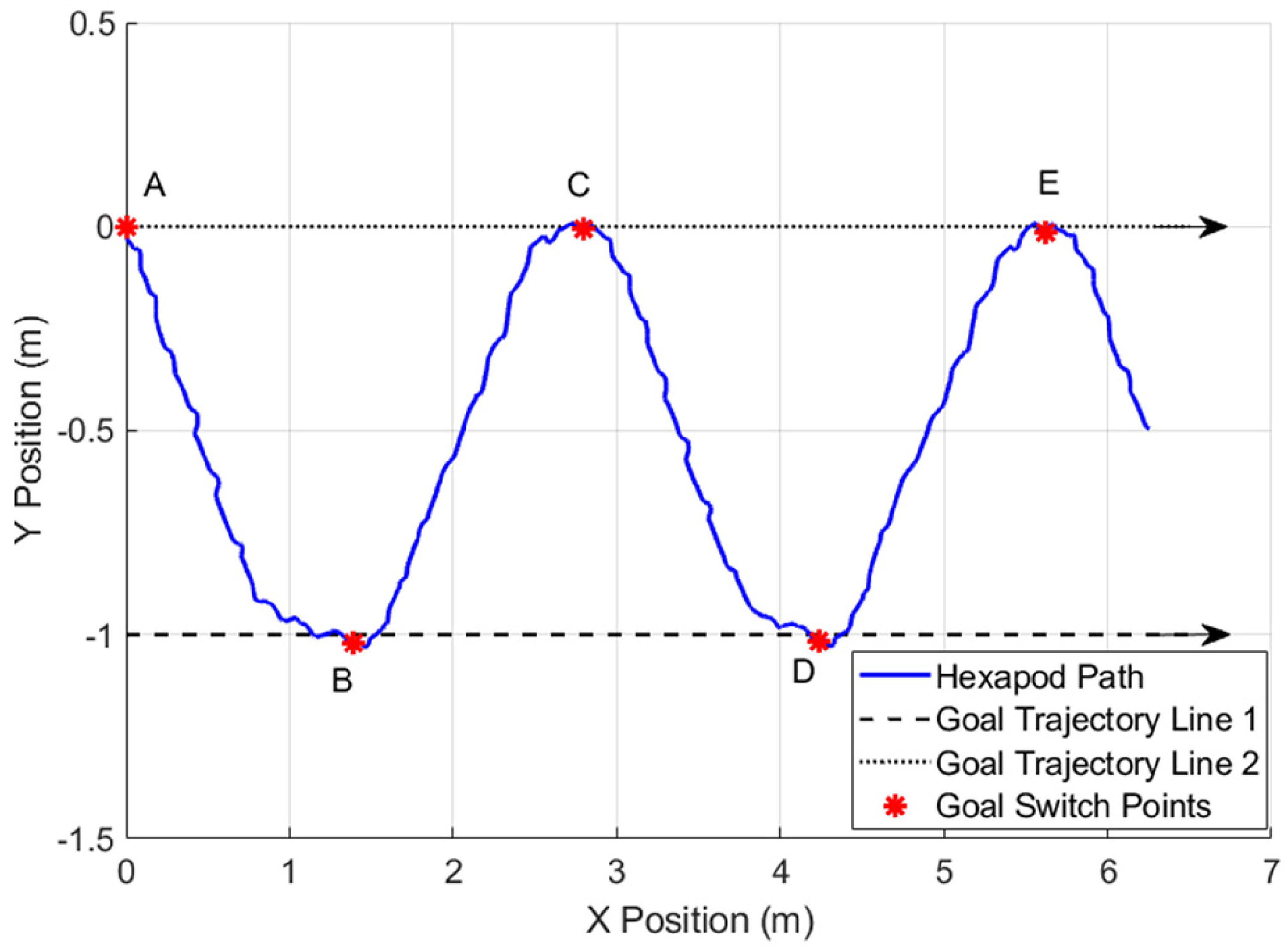
Hexapod trajectory following task.
Conclusions
A thorough examination and survey of the current literature related to RL applied to hexapod robots revealed a wide range of RL agent observations, without a clear method of justification for these choices. The observations provided to the RL agent are important because they affect hexapod performance, hardware cost, power requirements, and computational load. This work presented the use of fractional factorial designed experiments as a tool to aid in the selection of observations.
A hexapod simulator was developed using a CPG control scheme consisting of six coupled Hopf oscillators and associated mapping functions. Quarter-fraction and eighth-fraction factorial designed experiments were carried out using the hexapod simulator to explore the effect of seven potential observations on the hexapod's walking performance.
The factorial designed experiments were able to generate regression models that provided insight into the seven studied observations. For the conditions used in this research, the observations that obtained the maximum final average reward correspond to the joint torques, body linear velocities, body orientation, body angular velocities, and body height.
Further research should be conducted to explore this potential. Recommended areas of future research include exploring the application of this methodology for selecting observations of different RL algorithms, such as proximal policy optimization or soft actor-critic. The effect on performance of the weighting of terms in the reward function could also potentially be explored using a designed experiment, using the reward term scale factors as the factors of the designed experiment. Finally, since optimal observations may differ between tasks for the same hexapod, the use of a designed experiment for observation optimization could be further studied by modifying the simulator environment to test the hexapod in a variety of scenarios, such as traversing rough terrain, climbing stairs, transporting a payload, or walking with a damaged leg.
Footnotes
Acknowledgments
Not applicable.
Ethical considerations
Ethical approval was not required.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors received financial support from the Natural Sciences and Engineering Research Council of Canada (NSERC) (grant number 07025-2020).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
Not applicable.