
Abstract
In this article, we consider the problem of understanding the physical properties of unseen objects through interactions between the objects and a robot. Handling unseen objects with special properties such as deformability is challenging for traditional task and motion planning approaches as they are often with the closed-world assumption. Recent results in large-language model (LLM)-based task planning have shown the ability to reason about unseen objects. However, most studies assume rigid objects, overlooking their physical properties. We propose an LLM-based method for probing the physical properties of unseen deformable objects for the purpose of task planning. For a given set of object properties (e.g. foldability, bendability), our method uses robot actions to determine the properties by interacting with the objects. Based on the properties examined by the LLM and robot actions, the LLM generates a task plan for a specific domain such as object packing. In the experiment, we show that the proposed method can identify properties of deformable objects, which are further used for a bin-packing task where the properties take crucial roles to succeed.
Keywords
Introduction
For robots operating in unseen and unstructured environments, the ability to understand their surroundings is crucial for their autonomous execution. One of the representative approaches for achieving autonomy is task planning. Classical artificial intelligence planning aims to create a sequence of transitions to achieve a predefined goal by abstracting the semantic information of objects and actions into states. They often use formalized languages such as Stanford Research Institute Problem Solver (STRIPS) 1 or Planning Domain Definition Language (PDDL). 2 Many recent works use large-language models (LLMs) for task planning which have the advantages of commonsense knowledge and comprehensive power.3–5 LLMs have shown remarkable performance in context understanding of physical relationships of objects,6,7 which allow them to be used in robotic task and motion planning. 8
LLM-based task planning is particularly effective for robots operating in unstructured real-world environments such as domestic settings. However, existing task planning methods (e.g. Huang et al., 5 Shirai et al., 9 Zhao et al. 10 ) assume known objects. While there have been few recent works on LLM-based task planning with unseen objects,10,11 they do not consider deformability of objects. Since understanding the deformability requires a large amount of data to learn12–14 or an analytic model of object dynamics,15–17 existing methods restrict their coverages to a limited set of objects18,19 or learn how to manipulate deformable objects in an end-to-end fashion 20 in the control level. To the best of our knowledge, there has been no existing work that can reason about the properties of unseen deformable objects to use them in long-horizon task planning.
In this article, we propose an LLM-based method to infer the physical properties of unseen objects (e.g. compressibility, bendability, plastic deformability 21 ) based on simple interactions between an object and a robot. In addition, we show that the discovered properties can be used to generate high-level task plans for a downstream task such as object bin-packing.
As shown in Figure 1, our method consists of (i) the Property Reasoner that detects objects and understands their properties using a visual-language model (VLM) 22 along with an LLM (i.e. GPT-4o), (ii) the Domain Generator which produces actions for task planning and predicates describing object properties, (iii) the Instance Descriptor which generates a problem instance including the initial and goal states, and (iv) the Task Planner that generates a task plan to perform a downstream task where errors in the plan are detected by the Plan Validator.

An overview of the proposed method for understanding physical properties of unseen objects by using the commonsense knowledge of an LLM and the interactability of robots. LLM: large-language model.
The main contributions include:
We propose a method that leverages the commonsense knowledge of LLMs to understand the physical properties of unseen deformable objects by observing a robot which interacts with objects. We present a protocol outlining how the robot interacts with objects, along with LLM prompts to help identify their properties. We develop a pipeline for fully automated task planning that adapts to the discovered properties of previously unseen objects.
Related work
Understanding and planning with previously unseen deformable objects require combining two areas: (i) LLM-based robotic task planning and (ii) physical property inference through perception or interaction. While LLMs excel at reasoning about object relations, existing approaches do not acquire the physical attributes required for long-horizon manipulation. Accordingly, this article reviews work on LLM-based robotics, deformable-object manipulation, and domain-knowledge generation. In addition, we clarify why current approaches cannot support task planning for unseen deformable objects.
LLM-based robotic tasks
Research on leveraging LLMs for robotics spans several major directions, including perception and grounding, interactive perception, policy and skill generation, code and tool use, safety and verification, and planning. Perception and grounding research examines how robots link language to objects and scenes,23,24 while interactive perception explores physical interaction to reveal latent object properties that cannot be inferred from passive observation.25,26 Code and tool use focuses on generating structured function calls or task scripts to extend robot abilities.27,28 Safety and verification evaluate whether LLM-guided actions remain safe and constraint-compliant.8,29 Finally, LLM-based planning investigates how language models generate high-level task structures and symbolic action sequences.30,31
Perception and grounding research converts sensory data into scene representations using VLMs to interpret objects, relations, and task-relevant scene elements. Several approaches combine language knowledge with pretrained robotic skills or value functions to ensure that high-level commands remain feasible,32,33 and other methods train models that jointly handle observations, instructions, and action tokens in a unified format to improve generalization and long-horizon reasoning.34,35 Another direction uses hierarchical control where a high-level LLM coordinates lower-level modules and incorporates feedback from their execution results to refine subsequent steps. 36 However, reliance on static visual inputs and category-level supervision restricts the ability to infer detailed physical properties. This limitation motivates interactive perception, where robots actively probe objects to obtain richer physical signals.
To overcome these limitations, recent interactive perception research integrates LLMs with robot interaction to acquire physical information that static images cannot reveal. For example, the work of Sripada et al. 25 makes use of LLMs to detect physical properties such as surface stiffness, material type, and contact responses through robotic interactions with visual, tactile, and auditory sensing. Another method employs an LLM to explore in three-dimensional (3D) environments, where the model selects the targets and the controller performs interactive actions to reveal shapes, object boundaries, and orientations. 37 Interactive manipulation frameworks leverage LLM-based reasoning to identify affordance regions and probing strategies that probe object geometry, poses, and properties that influence manipulation outcomes.38,39 Despite these advances, most approaches estimate properties for short-horizon control. Unlike prior work, we focuses on interaction-derived physical probing to support long-horizon symbolic reasoning.
Skill and code generation research investigates how LLMs produce executable robot behaviors through pretrained skills and code synthesis. Some approaches leverages LLMs as a planner that selects pretrained skills, 4 while others train vision-language action (VLA) models with action tokenization so that a single policy can convert language commands into action outputs. 35 Additional studies prompt LLMs to derive structured subtasks that a lower-level controller executes through learned policies.3,40 Another direction generates code or solver calls for external tools to solve optimization, constraints check, or motion planning.27,28 Some methods define reward functions through LLMs to guide model-predictive controllers without manually engineered primitives. 41
LLM-based research on safety and verification aims to ensure that robot actions generated from language models remain safe, consistent, and aligned with user-defined constraints. Recent work explores ways to augment LLM planners with auxiliary safety modules that predict risks, filter unsafe behaviors, or revise plans before execution. For example, several approaches introduce safety predictors or parallel safety agents that supervise LLM-generated plans and suppress unsafe actions.42,43 Other methods translate natural-language instructions into formal safety constraints, such as temporal logic formulas, to guarantee that generated task plans satisfy user-specified rules.8,44 Additional lines of research focus on detecting execution failures, revising actions based on environmental feedback, or synthesizing guardrails that intervene during runtime to prevent safety violations.29,45–47
LLM-based planning research investigates how LLMs generate high-level task plans from natural-language instructions by leveraging their pretrained world knowledge. Earlier work demonstrates that LLMs can translate user goals into structured action sequences. 48 Subsequent approaches further refine the planning process by incorporating consistency checks or iterative reasoning mechanisms to improve reliability in long-horizon tasks. 30 Another method adopts a neuro-symbolic perspective, decomposing complex tasks into subgoals using an LLM and assigning each subgoal to an LLM-based search procedure. 31 Despite these advances, existing LLM-based planners largely rely on a closed-world assumption and cannot robustly adapt their plans to previously unseen objects or novel physical attributes. To overcome this limitation, our framework uses an LLM to convert interaction-derived physical properties into symbolic knowledge, and the planner directly uses the expanded knowledge base to produce updated task plans without any additional design effort.
Deformable object manipulation
Research on manipulating deformable objects has traditionally been studied at the motion level,12,20 which needs prior knowledge of the physical properties of objects. Based on the knowledge, they control robots to guide the objects toward the goal state. Learning-based methods14,49–51 are proposed which have the ability to understand physical properties of deformable objects with a priori. For example, Fu et al. 52 propose a method for unfolding clothes that learns the state classification and region segmentation of folded objects to guide the unfolding process. However, all the aforementioned methods are not easily applicable to unseen objects as they need prior knowledge or laborious data collection and training. While few methods (e.g. Shridhar et al., 53 Bartsch and Farimani 54 ) leverage foundation models to manipulate unseen deformable objects, they work in an end-to-end manner without understanding the physical properties of the objects, which can be further used for long-horizon task planning.
Domain generation
Research on automated generation of knowledge base enables an autonomous agent to explore unseen environments. Generally, the agent expands a separated knowledge base through reasoning about its environment. For example, Hanheide et al. 55 propose a knowledge hierarchy which allows assumption-based reasoning in uncertain environments. On the other hand, recent works leverage foundation models to recognize unseen objects from visual observations.56–58 In Liu et al., 30 an LLM is used to generate domain knowledge for a given task from natural-language instructions, where the knowledge is further used for task planning. Although these methods demonstrate the ability to generalize to unseen environments and objects, they may inaccurately predict the properties of objects because they rely on predefined object sets or built-in commonsense knowledge of LLMs. Consequently, their ability to understand the physical properties of unseen deformable objects is limited due to their lack of capability to interact with and reason about their surroundings.
Recently, there has been a growing interest in identifying the physical properties of objects. Using fine-tuned LLMs trained on curated datasets, one line of research focus on estimating object properties by mapping target objects to known categories and predicting its properties based on similar examples. For instance, Gao et al. 59 demonstrate the limitations of VLMs in capturing physical characteristics and introduce a dataset specifically designed to address this gap. Similarly, Xie et al. 60 propose a grasping strategy to estimate properties such as friction, mass, and spring constant. These approaches require additional training for high-level reasoning and often struggle to generalize across diverse object categories. Another line of research focus on inferring physical properties through direct robot–object interactions. For example, Zhao et al. 26 leverage LLMs in conjunction with multimodal sensors including sound, torque, and tactile data to reasoning the materials. Likewise, Lai et al. 61 proposes a multimodal reasoning method that integrates visual and haptic signals, using a robotic shaking action to identify liquid-containing objects. Despite their promise, these methods often depend on prior knowledge of specific physical properties and require additional training, which limits their adaptability to diverse and unstructured environments.
Our goal is to address the challenge of understanding the physical properties of unseen deformable objects without fine-tuning, enabling their use in long-horizon task planning. We aim to combine the commonsense reasoning of LLMs with physical interactions between a robot and objects.
Problem formulation
Our goal is to understand physical properties of unseen objects to generate a grounded robot task plan for

To generate
We want to construct a knowledge base
To determine
Method
As shown in Figure 2, we develop a framework which consists of the property reasoner, domain generator, instance descriptor, task planner, and plan validator. The first three components generate a planning instance and a domain knowledge whereas the last two generate and validate task plans.
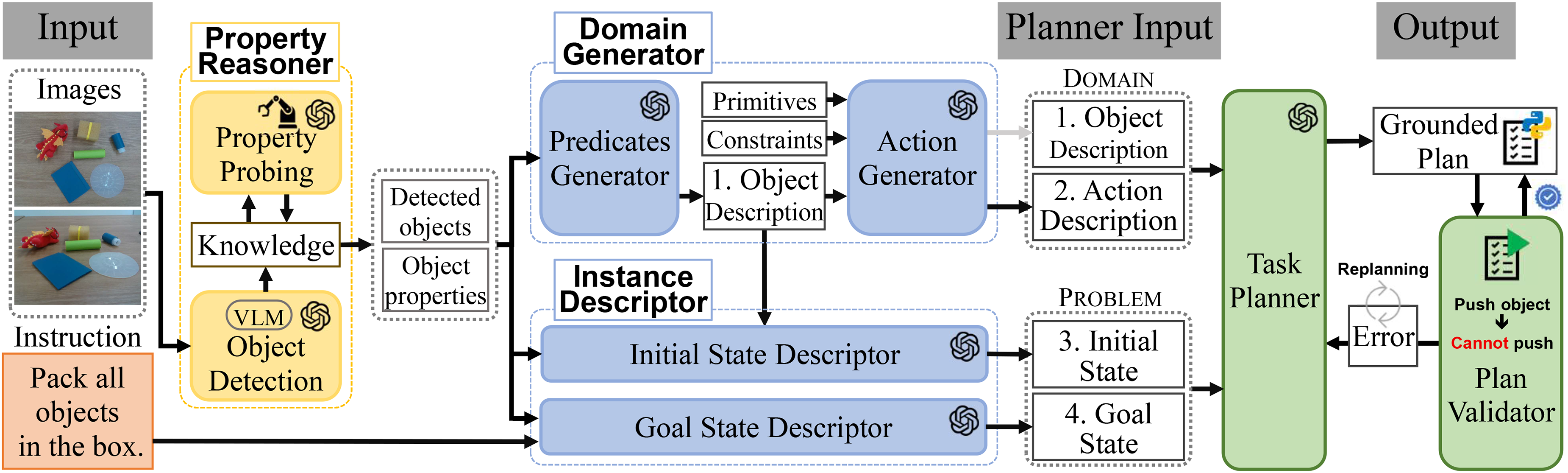
The overall procedure of our method for the bin-packing domain involves autonomously investigating object properties to expand domain knowledge using a robot. The property reasoner gathers visual information about objects (e.g. color, dimensions, shape). If the knowledge base lacks the physical properties of the objects, the reasoner uses images of the objects interacting with the robot to probe these properties. Using the object information and a language instruction, the domain generator and instance descriptor create structured data for task planning. The generated task plan is then validated by the plan validator to check for syntax and semantic errors.
Property reasoner
Object detection and naming
The property reasoner detects
Property probing
The physical properties of detected objects are reasoned by the LLM where the objects interact with a robot physically. If the number of properties is excessive, the LLM is likely to have hallucinations. Thus, we limit the set of object properties depending on the task domain. As a running example, we use the bin-packing domain where a set of objects are packed into a bin. In this domain, we focus on deformability of objects to pack objects while preventing plastic deformation of objects. To do so, we introduce a set of five properties which are rigidity, bendability, foldability, compressibility, and irreversible deformability. An object can be classified as either rigid or nonrigid based on whether it maintains its shape when subjected to external forces. Nonrigid objects can exhibit deformation properties that depend specifically on their dimensions. One-dimensional (1D) objects such as a string or a needle can be bendable. Two-dimensional (2D) objects like a sheet of paper or a dish plate can be either foldable. 3D objects such as sponges can be compressed. If a deformed (i.e. bent, folded, and pushed) object cannot be recovered to its original state, it is plastic deformable regardless of its dimension.
The properties impose constraints or objectives for safe and space-efficient bin-packing: (i) Bendable (1D) objects can be bent to fit the size of the bin. (ii) Foldable (2D) objects can be folded to utilize the bin space as much as possible. (iii) Compressible (3D) objects can be compressed to secure more space for packing. Also, they can be used to protect objects that can have plastic deformation. (iv) Plastic deformable objects can be easily damaged. Protecting them using compressible objects can be beneficial for packing tasks. Note that rigid objects can be placed in a bin without constraints.
To probe these properties, we define a set of probing actions

The decision tree approach for determining object properties. (a) By applying a series of actions, one of the properties at the leaf nodes is determined. (b) Depending on the dimension of objects, a dual-arm robot performs appropriate probing actions. For example, the property of
We develop two approaches to utilize images for reasoning with the LLM. In the first approach, the LLM is directly queried about the properties using three images, with each image labeled to indicate the action that produced it. The second approach employs a decision tree (Figure 3(a)) based on property definitions provided by
Our overall procedure for the property reasoning method is described in Algorithm 1 and prompts are provided in online Appendix A.2. In line 3, the VLM draws bounding boxes of objects in

Task planning
Domain generator
Task planning requires a domain description (
A domain description
The domain generator receives the knowledge obtained by the property reasoner. It uses the predicate generator and the action generator (which belong to the domain generator in Figure 2) to generate
The action generator produces the action description
Instance descriptor
An instance description
Task planner and plan validator
By the domain generator and instance generator, all necessary components for task planning are prepared. The task planner generates a grounded task plan, while the plan validator checks its validity. If the plan is found to be invalid, it is fed back to the task planner for replanning.
The LLM as the task planner produces a plan
The plan validator (also the LLM) examines the task plan by executing the Python script and looking at the execution result denoted by
Therefore, if a semantic error is detected, we regenerate
Experiments
We design a set of experiments to show the performance of the proposed method where metrics are (i) the accuracy of the property reasoner in probing the physical properties of objects and (ii) the success rate of the task planner given the physical properties of objects.
The set of 14 objects used in the experiments is shown in Figure 4 including rigid and nonrigid objects with different dimensions. Our object set consists of objects that are difficult to recognize in their physical properties if visual information is solely given. For example, predicting the properties of Objects 1 and 2 is difficult due to a lack of visual features. Using selected objects, we generate 38 bin-packing random instances where each instance is with 3 to 7 objects. Since the LLM could produce different answers even for the identical prompt, we repeat testing the same instance 10 times to obtain the statistics.

The set of 14 objects used in the experiments. The dimensions and physical properties of them are listed in the second and third columns of Table 1(a).
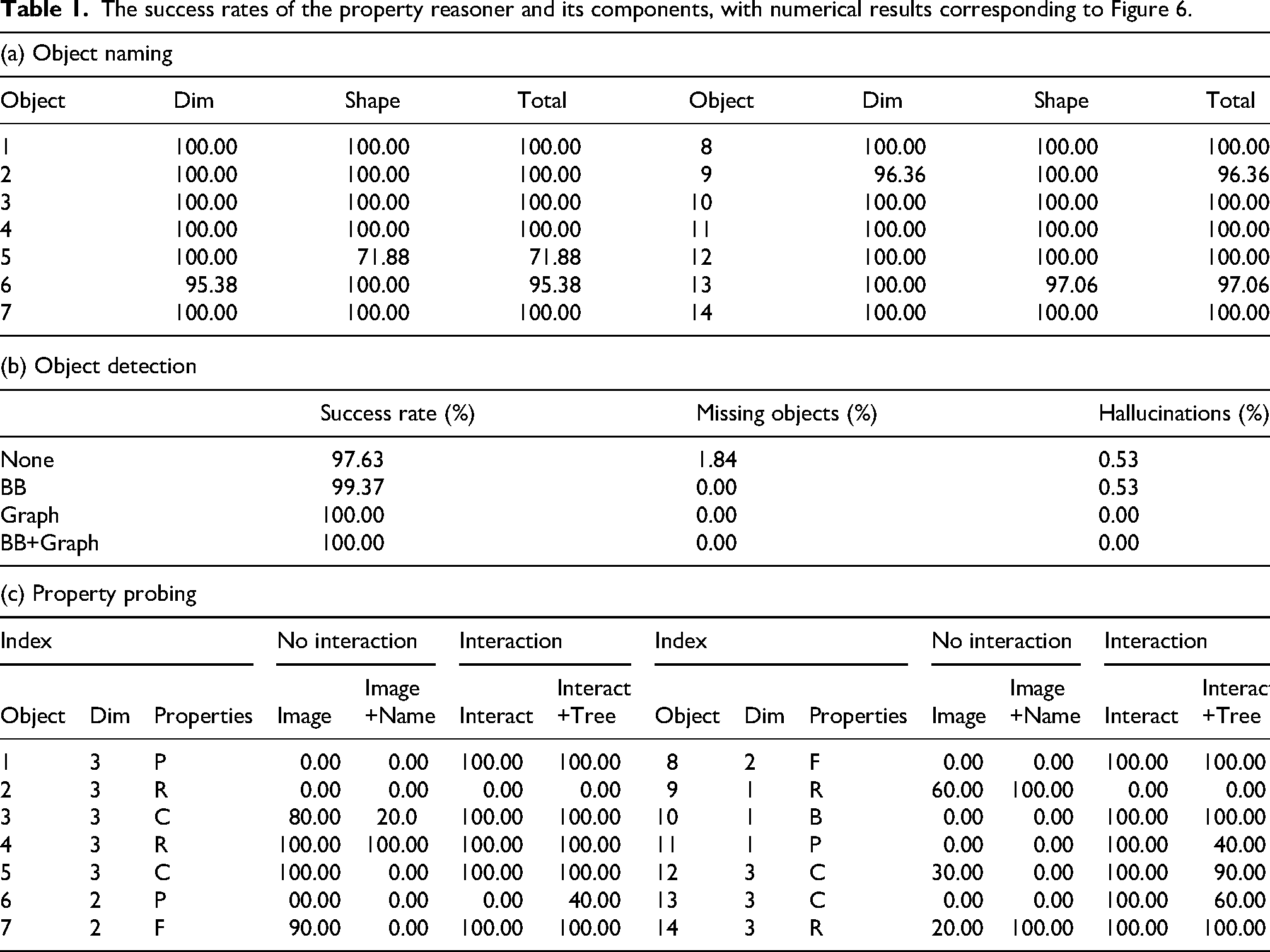
The success rates of the property reasoner and its components, with numerical results corresponding to Figure 6.
Settings
We use two Agile-X 6-DOF manipulators for the experiments to perform property probing and task execution. The robot for both property probing and task planning are generated by human teaching, which is called Programming by Demonstration (PbD) paradigm, where each action trajectory is recorded through human teleoperation and subsequently replayed by the robots. The LLM used in the experiments is GPT-4o where the parameters are set to the default values except for temperature set to
Property reasoning
The performance of property reasoning heavily depends on the performance of object detection and naming. Thus, we first measure the success rates of object detection and naming. Then we measure the accuracy of property probing for those objects that are successfully detected and named.
For each bin-packing instance among 38, our method uses two images from different perspectives that are top and side views as shown in Figure 5. The two images contain the same objects. The object detection is successful if all objects in the images are detected without any false positives. In other words, a successful object detection must not have a missing object and a hallucination. To test the effects of the bounding boxes and the graph, we compare four methods for object detection which are None (raw images), BB (bounding box only), Graph (graph only), and BB+Graph (both). Each instance is tested 10 times with an identical prompt so a total of 380 trials. Figure 5 shows the bounding boxes and graph. As summarized in Table 1b and Figure 6(b), Graph and BB+Graph achieve 100.00% of the success rate. While None and Graph achieve high success rates, providing additional visual information helps improve the detection performance of the LLM. Specifically, providing spatial information (i.e. using the graph) about the objects plays a crucial role in detecting missing objects and preventing hallucinations.

An example of a set of images processed by a VLM and a connection graph. Since the objects are unknown yet, their labels are determined arbitrarily. The graph helps the LLM understand the spatial relationship between objects which reduces the hallucination. VLM: visual-language model; LLM: large-language model.

The success rates of the property reasoner and its components. (a) The high success rate of object naming shows that the LLM can recognize the shape and dimension of objects consistently. (b) The effectiveness of the additional visual information (the bounding boxes and graphs) is shown. (c) The physical interactions with objects greatly help in understanding the properties of objects. (a) Object naming, (b) object detection, and (c) property probing. LLM: large-language model.
We measure the success rate of object naming where objects are detected by BB+Graph. A successful naming should provide both the correct dimension and the shape of the object in the name. The object color is not considered as color is not used in the bin-packing task. The 38 instances have 184 objects in total including duplicates (i.e. the same object is counted twice if it is in two instances). By repeating 10 trials for each instance, we have a total of 1840 resulting names to measure the success rate. As shown in Table 1a and Figure 6(a), object dimensions and shapes are correctly identified in most cases. While most objects achieve success rates close to 100%, Object 5 is occasionally misclassified as a cuboid (28.12%) despite being cylindrical. We believe this is due to the ambiguity of the shape as it is not a perfect cylinder, as it features partial angulations. Its translucency and lack of texture add further complexity to the shape recognition process of the LLM.
Finally, we measure the performance of the property probing given the satisfactory performance of the object detection and naming. We have 10 trials for each of 14 objects, so 140 test cases. The deforming actions (e.g.
We compare four different methods; Image, Image+Name, Interact, and Interact+Tree as follows:
Image: Does not use the probing actions but use the LLM only for reasoning about the properties. Image+Name: Same as Image, but includes the object label identified by a pretrained Vision Transformer.
65
Interact: Uses three images showing the state of the object before, during, and after interaction. Interact+Tree: Same as Interact, but additionally uses the decision tree described in Section “Property Probing.”
We note that the image used in Image and Image+Name is the same as the before probing image used in Interact and Interact+Tree.
The result shown in Table 1c and Figure 6(c) demonstrates that our interaction-based methods achieve accuracy up to 78.57% across all objects. In contrast, the noninteraction methods, Image (34.29%) and Image+Name (22.86%), show a significant limitation in predicting physical properties as they do not involve physical interactions with the objects. The lower success rate of Image+Name indicates that providing object names to the LLM could bias the reasoning of it. The Interact (78.57%) method outperforms Interact+Tree (73.57%) slightly. This result indicates that using the decision tree could limit the flexibility of the reasoning process of the LLM. While the experimental results show that robot interactions significantly help the LLM reason about the object properties, imposing constraints (i.e. object names, decision trees) appears to restrict the reasoning capabilities of LLMs, leading to reduced performance. The reduced accuracy of the decision tree approach results from its inability to support joint analysis of the probing images. Moreover, the hand-designed branching rules constrain the flexibility of the LLM to adapt its visual analysis to subtle differences in material behavior. In contrast, the free-reasoning variant allows the LLM to integrate information across all probing observations without predefined decision rules. As multimodal LLMs continue to advance, prompting strategies that restrict the flow of information are expected to offer diminishing benefit compared to open-ended reasoning.
To further validate the effectiveness of property probing through robot–object interactions, we conduct additional experiments using objects with similar visual appearances but differing physical properties. We select five objects for evaluation, Object 5 and Object 7, along with their visually similar counterparts, Objects A and B for Object 5, and Object C for Object 7, as described in Figure 7(a). Objects 5, A, and B are labeled

Property probing for similarly shaped objects (e.g.
Task planning and plan validation
Real-world bin-packing scenario
We examine the resulting task plans to see if the plans comply with
We first measure the success rate of Case I (i.e. violating

The task planning result. (a) The success rates of task planning where replanning has shown the effectiveness of correcting errors. (b) The real-world implementation demonstrates that the probed properties can be effectively utilized in task planning. (a) The success rates of task planning and replanning and (b) the real-world execution of the task planning.
There are eight instances which belong to Case II. The most common failing instances involve Object 10 (
To illustrate how the discovered object properties can influence the result of task planning, we execute task plan examples as shown in Figure 8(b). (Refer to online Appendix D.3 and Supplemental video for full task planning execution.) All grounded actions in the plan such as “
Additional scenarios
To examine whether the proposed framework generalizes beyond the bin-packing domain, we conduct additional simulation experiments across several task settings that require deformable object reasoning. The evaluation includes three representative tasks, namely RopeFlattening, ClothFolding, and a Blocksworld domain. Figure 9 illustrates simulation settings for property probing.

Simulation environments for deformable-object tasks. The figure illustrates the three simulated domains used to evaluate generalization: RopeFlattening (left), ClothFolding (center), and Blocksworld with deformable constraints (right).
In the RopeFlattening task, the agent straightens the rope when the rope is bendable. If the rope is not bendable, the agent arranges it without flattening. In the ClothFolding task, the agent folds every object that is identified as foldable and removes any object that is not foldable from the plan. In the Blocksworld task, the planning rule requires every deformable cube to appear at the top of the final stack.
We first evaluate the accuracy of property probing in each domain using 10 simulation trials. The probing success rates are 100%, 40%, and 100% for RopeFlattening, ClothFolding, and Blocksworld, respectively. We then measure the task planning success rates under the condition that all required properties are correctly inferred. As shown in Table 2, the initial planning success rates are 70%, 100%, and 40% for RopeFlattening, ClothFolding, and Blocksworld, respectively. After five replanning query, the success rates increase to 100%, 100%, and 60% for the same domains. This result shows that our framework operates consistently across various planning tasks. Notably, for the ClothFolding domain, the accuracy of the property probing achieves 40%. This result suggests that the visual ambiguity of partially folded or wrinkled cloth states makes it difficult for LLMs to consistently distinguish foldable objects from plastic deformable ones. In the Blocksworld domain, the planning success rate remains limited even after multiple replanning steps because the task requires long-horizon decisions. In addition, the LLM often violates symbolic rules in stacking steps, such as the correct update of clear statuses (e.g. the lower block should become false and the upper block should become true). These observations indicate that the difficulty of the task and the clarity of the probing signal both influence downstream planning performance, showing where additional structure or feedback may be required.
Planning success rates (%) across simulation tasks.

Discussion
Planning behavior
While the success rate of task planning exceeds 95% after a few iterations, the first planning query does not give a sufficiently good performance. This limitation might come from the ambiguity in the prompts, limited domain knowledge of the LLM, incomplete understanding of physical or contextual understanding of the LLM, etc. For example, the term ‘plastic’ might provide an ambiguous signal to the LLMs, interpreting it as a material type rather than its intended concept of ‘plastic deformable’ in mechanics. In addition, our method consists of several sequential processes where the result of preceding processes significantly impacts the following processes.
In the experiments, we use the PbD method to generate motions for probing actions and task execution, without any learning or generalization. Although achieving full autonomy is not the focus of this work, we briefly attempted to apply the state-of-the-art imitation learning method ALOHA. 66 However, the method did not perform reliably for our tasks, which involve fine manipulation of deformable objects, such as ‘bend’ or ‘fold’ actions. Given these considerations, record-and-replay (i.e. PbD) serves as a fast and efficient solution for the scenarios in this study. Looking forward, the success of our simple probing actions suggests that our approach could be extended by combining it with advanced models such as VLA or imitation learning to achieve more robust autonomy. We note the code in online Appendix E.
Generalization scope
Compared with classical or learned pipelines, our LLM-based approach offers practical advantages across multiple dimensions that are relevant for reasoning about previously unseen objects. First, our pipeline does not require task-specific training datasets or annotated material labels, which are often necessary in supervised or feature-engineered systems. This property allows the framework to scale to new domains without requiring additional data collection. Second, the LLM can interpret ambiguous or underspecified descriptions through linguistic priors, enabling our pipeline to handle uncertainty more flexibly than rule-based models. Third, our method generalizes naturally to unfamiliar objects and varied task settings, whereas classical pipelines remain constrained by predefined categories and domain-specific features. Classical approaches still provide strengths such as low-computational latency, strong safety guarantees, and high reproducibility through deterministic rules, but these benefits come with limited adaptability when environments contain diverse objects or shifting task conditions. In contrast, LLM-based reasoning draws on broad semantic knowledge and adapts more effectively to unfamiliar or uncertain situations, which becomes especially valuable in open-ended environments. Overall, our pipeline offers clear advantages in settings that are unstructured, include previously unseen objects, or require flexible reasoning beyond the capabilities of classical methods.
We conduct experiments with 14 objects that have different material properties under a fixed camera setup and a bin-packing task. Although the evaluation is limited to this setting, the same framework can be used in broader conditions. The possibility of generalization can be examined in several directions, including a wider range of object types, changes in camera positions or sensor viewpoints, variations in prompt wording, and the use of different task domains. Future evaluations may also use more complex everyday objects such as laptops or headsets that include multiple parts or mixed materials. This setting can show whether the framework can handle objects that do not have uniform structure. Additional sensing inputs such as touch, sound, or temperature may help in cases where visual information is not enough. It is also useful to examine how much the results change when the prompt wording changes. Finally, using the framework in other tasks can show whether the inferred physical properties support planning in situations that require different types of actions.
Future directions
The proposed approach presents several challenges that remain for future work. First, the validator component needs better scalability to handle a larger number of objects and more detailed physical attributes. Second, the system connects physical reasoning to task planning but does not yet link this reasoning to motion level execution in a direct way. Third, the current pipeline requires noticeable computation time, which limits its use in real-time settings. The reliability and reproducibility of LLM-based inference also change with the choice of model version, decoding settings, and prompt wording. These forms of variation are not present in classical deterministic pipelines and therefore introduce additional sources of uncertainty in the reasoning process.
As an initial attempt to understand the physical properties of previously unseen objects, our work still leaves room for improvement. In particular, generalization can be extended to cover a broader range of object properties (such as fragility or elasticity) and different types of manipulation tasks (such as cooking or household activities). Another direction is to detect irreversible properties without prior knowledge or specialized sensors without causing damage to the object. Finally, although we include a decision tree variant as an ablation, we intentionally restrict our analysis to a single hand-designed structure. Exploring richer or learned tree designs remains an interesting direction for future work but lies beyond the scope of this study. In the future, we will develop more general probing skills applicable to a wider range of physical properties.
Conclusion and future work
In this article, we propose an LLM-based reasoning method to understand the physical properties of unseen objects through the interactions between the objects and a robot. Experimental results demonstrate the effectiveness of the proposed method in task planning with iterative improvements.
In future work, we plan to extend the framework to a broader range of objects with varied material behaviors and to evaluate it in more complex manipulation tasks, such as household tidying where robots must handle fragile and deformable items. We also intend to explore additional sensing modalities such as tactile or force sensing to enrich the inferred physical representations and further enhance the robustness of the planning process. We also plan to bridge task-level plans with the execution layer so that the robot can carry out the actions with more consistent motion performance.
Supplemental Material
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Research Foundation of Korea (NRF) grants funded by the Korea government (MSIT) (No. RS-2024-00411007 and No. RS-2024-00461583).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.