
Abstract
Locking state recognition is one of the key tasks of railway freight monitoring. However, accurate localization and recognition of small locking mechanisms remain major challenges. Current approaches that focus on existing object recognition methods lead to high false detection and miss rates. This paper introduces TrainNet for efficient locking state detection for Open-top wagon doors. A dataset was collected using a robot with a camera to validate our method. We designed an efficient layer aggregation network (ELAN)-S module in our TrainNet, which can be used with YOLOv7. The module efficiently extracts curvilinear features and is integrated into the backbone feature extraction network to enhance the feature representation capability. An LSKCSPC module is also introduced to capture a dynamic receptive field, enabling TrainNet to adjust its receptive field dynamically to the scale of the object, improving its feature representation capacity. Furthermore, the detection head for small-scale objects is redesigned, the feature layer size is increased to enhance the ability to extract and detect fine-grained features. Finally, the loss function is modified to a dynamic fusion-based CNIOU, which reduces the sensitivity of original loss to small objects and improves performance. Experimental results show that the algorithm achieves a mean average precision (mAP50) of 91.5%, which is a 3.6% improvement over the baseline YOLOv7 algorithm. The model weight file size of new algorithm is 60.2MB with 19.5% reduction compared to the baseline. The proposed method achieves 91.5% for detecting the lock status of railway freight open-top wagon side doors, while reducing the complexity of the original algorithm and achieving a real-time detection speed of 39.8fps, meeting the requirements for practical application. The algorithm also exhibits good robustness as demonstrated by experiments on the WiderPerson dataset.
Introduction
The open-top wagon is the most widely used type of vehicle in railway freight transportation, accounting for approximately 60% of the total railway freight cars. To facilitate loading and unloading of goods, each side of an open-top wagon is equipped with six lower side doors and one side door. During railway transportation, the jostling of the wagon can potentially cause the door locks to loosen or even fall off, leading to the dropping of goods onto the track and causing significant safety incidents. 1 The timely and accurate detection of the locked state of the side doors of open-top wagons is crucial in ensuring the safety of railway freight transportation.
Currently, there are two main methods for recognizing the locking state of train doors: manual inspection during train stops and monitoring via surveillance videos with a robotic camera, while the train is in operation. Both methods have their limitations, including time consumption, high workload, and a restricted field of vision for inspection. These issues result in low efficiency in inspections and a high risk of missed or false detections.
The side door locking state recognition has been attained much attention. Yan et al. utilized morphological image processing and an line segment detector-based line detection algorithm to propose a union-find based hierarchical clustering algorithm for detecting the open or closed state of gondola cars. 2 This approach addresses the limitations in generalization capabilities inherent in traditional image detection methods. In the domain of deep learning-based computer vision detection, the YOLO series of single-stage object detection algorithms have been widely applied and recognized for their high detection speed and accuracy. 3 The YOLOv7 is selected as our baseline, due to its performance over its predecessors in conventional object detection tasks. 4 In the task of recognizing the locking state of side doors on open-top wagons, the small-scale objects cannot be well represented due to objects in a clutter background. General object detection often faces challenges in dealing with small objects, leading to a higher rate of false positives and missed detections. Researchers have recently improved small object detection methods. In anchor-based object detection method, the metric commonly used is IoU, which is highly sensitive to small object positional shifts, often resulting in misjudgments. To address this, Wang et al. introduced the NWD loss function, based on the concept of Wasserstein distance, which uses a non-IoU metric to measure the difference between predicted and ground truth boxes, making it more robust to small object positional shifts. 5 Additionally, Tang et al. added a small object detection head to the YOLO detection model and introduced a convolutional feature fusion module between the backbone and neck networks to enhance channel information, and proposed HIC-YOLOv5. 6 Zhang et al. proposed the FFCA-YOLO, which introduces a feature enhancement module, a feature fusion module, and a context-aware module (SCAM) to improve the ability to extract features for small objects, thereby enhancing its small object detection performance. 7 However, in the detection of the lock status of open-wagon side doors, the features of lock are similar to the background, and the performance is often compromised by the complex background. Therefore, this paper aims to optimize and improve the YOLO algorithm for the detection of open-wagon side door lock status, aiming to improve detection accuracy and efficiency.
This paper introduces a new network architecture, called TrainNet, for accurate locking state recognition of railway freight open-wagon doors. We advance YOLO by introducing a curve feature-sensitive feature extraction and dynamic perception into our TrainNet. A curvilinear feature-sensitive feature extraction module, efficient layer aggregation network (ELAN)-S, is proposed and integrated into our main backbone network, which can significantly enhance representational capacity of our method. A feature extraction and fusion module with a dynamic receptive field, LSKCSPC is introduced. This module enables the algorithm to dynamically adjust its receptive field according to the scale of different objects, thereby improving its capability to express features. The detection head for small-scale objects with an increased size of the feature layer aims to enhance the ability to extract and detect fine-grained features. To further enhance the performance, a dynamically adjustable CNIOU loss function is proposed. We introduce Wasserstein distance to calculate the probability distribution matching degree between two bounding boxes. Our new loss function can dynamically integrate both aspects to mitigate the original loss function's sensitivity to small object, thereby increasing the detection accuracy of our method. To validate our method, we collect a dataset to compare our method with baselines, which clearly show that our method can outperform comparative methods in a large margin.
Open-top wagon side door lock state detection dataset
Data acquisition
Due to the lack of experimental datasets in the study of recognizing the locked state of side doors on open-top wagons, we design a line-scan camera mounted on a robot fixed on both sides of the tracks at the entrance and exit of railway freight stations. This setup allows for an automatic capturing of images from passing trains, producing large-scale images with a resolution of 8000 × 2048 pixels. This device can effectively overcome the limitations of traditional cameras, such as limited frame size and motion blur in images of moving objects. High-resolution images of open-top wagon compartments can facilitate detecting the locked state of side doors on open-top wagons. The collected images are shown in Figure 1.

Side view of the carriage of the open-top wagon.
During the transportation of open-top wagons, there is a high risk of the doors becoming unlocked during transit. This can lead to the dropping of goods onto the railway tracks, posing a serious threat to railway transport safety. Therefore, in accordance with relevant railway freight transport safety inspection regulations and practical operational requirements, we categorize the objectives of side door lock status detection into six types, such as the normal and abnormal states of bottom side door lock binding and reinforcement, side door pin, and side door lock binding and reinforcement, as shown in Figure 2.

Locked state of the side door of the convertible.
In this paper, the labeling image annotation software is used for manual annotation of the collected images. The dataset comprises a total of 1016 images, with the overall number of object instances amounting to 14224. The objects are annotated using rectangular bounding boxes and saved in the txt format annotation files suitable for the YOLO model. The specific number of objects is detailed in Table 1.
Distribution of data set instances.

Dataset balancing
Table 1 shows that the original collected dataset exhibits an imbalance between positive and negative samples, which may lead to a poor performance during training due to insufficient learning of negative samples. Therefore, this paper adopts the copy-paste method to preprocess the dataset. 8 The object objects in the training set images are cut out and pasted onto other training set images to create new training images. Since the number and spatial distribution of detection objects in the images are relatively regular, the position-constrained copy-paste method is more consistent with the actual detection task. Specifically, the object images of the corresponding categories selected randomly are used to replace the corresponding objects in the original images to synthesize new sample images. The processed images are shown in Figure 3, where the lock object in the green annotated box is replaced with the lock object in the red annotated box.

Copy-paste composite image.
The original dataset was divided into a training set and a validation set in a 7:3 ratio. After applying the position-constrained copy-paste method to balance the positive and negative samples in the training set, the distribution of instances in the dataset is shown in Table 2. The dataset contains 1784 images, of which 1477 are in the training set and 307 are in the validation set.
Distribution of dataset instances after balancing.
TrainNet
The key to recognizing the locked state of open-top wagon side doors lies in accurately locating the position of the side door locks and discerning whether they are properly bounded. This paper introduces the design and implementation of TrainNet, a detection network tailored for the task of detecting the locked state of open-top wagon side doors. TrainNet is based on YOLOv7. It incorporates a well-designed feature extraction module during the feature extraction phase and utilizes a dynamic receptive field module in the feature fusion stage. This enables the network to input the side view of an open-top wagon and output the position and locked status information of the door locks. The detailed structure of the TrainNet algorithm is depicted in Figure 4.
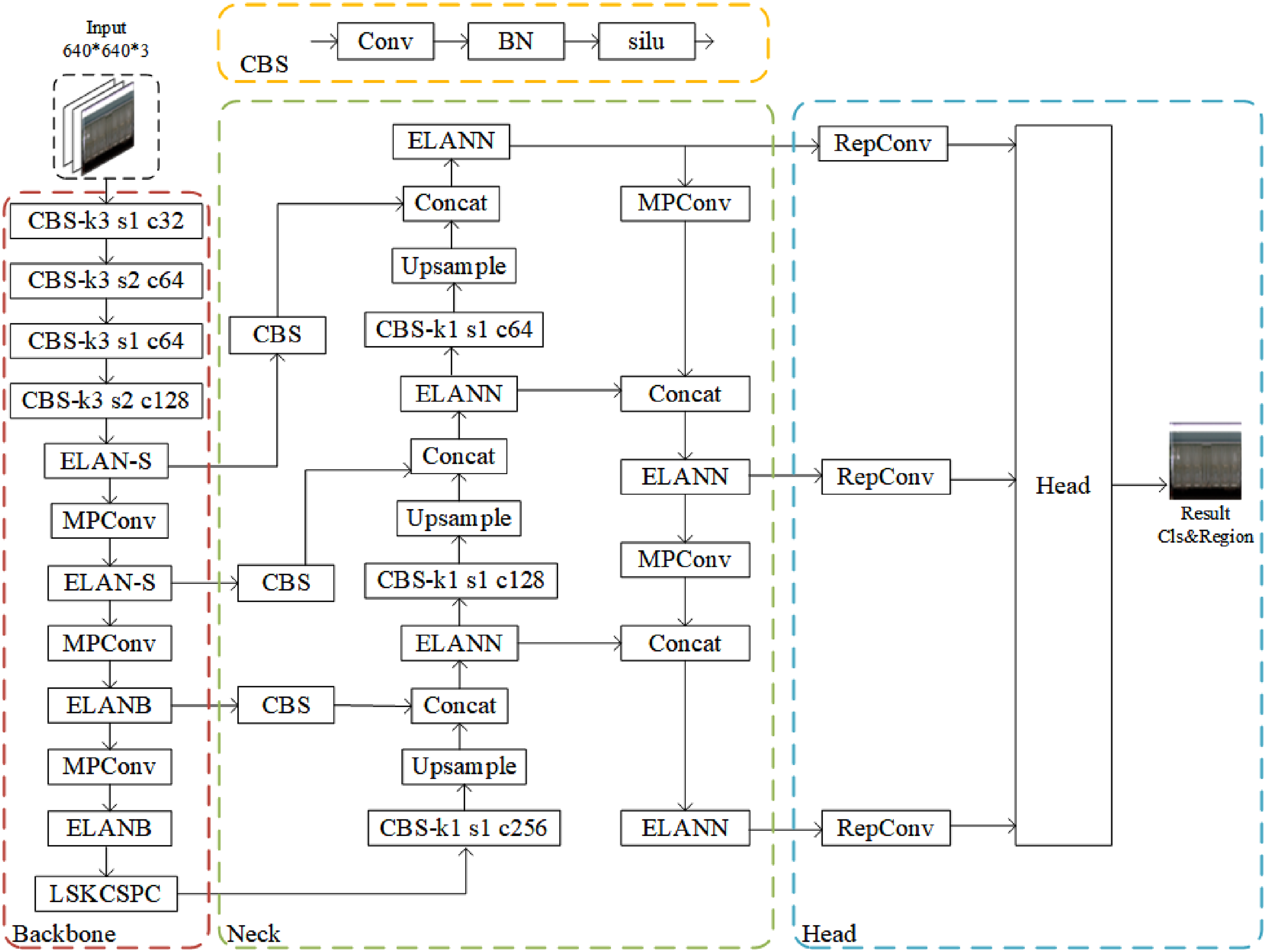
Trainnet network structure.
Curve-sensitive feature extraction module ELAN-S
The open-top wagon side door lock status detection dataset contains a significant amount of key features such as bundled wires and pins, which are slender and varied in form, as shown in Figure 2. Traditional convolutional neural networks, employing standard convolution, are capable only of extracting fixed local spatial features, thereby overlooking the continuous variation in linear features and exhibiting weak extraction capabilities for such features. In [
9
], they introduce a Dynamic Snake Convolution (DSConv), effective in segmenting linear features like blood vessels and roads in medical and remote sensing images.
9
However, the core feature extraction module ELAN, used in the baseline network's feature extraction backbone, primarily composed of standard convolution, shows limited learning capability for linear features such as bundled wires and pins, and struggles to adapt to the variable nature of linear features. Therefore, this paper proposes a feature extraction module ELAN-S, which is sensitive to linear features. The module consists of two branches. After input feature X enters the module, it is divided into two branches. The first branch uses the ELAN to extract general features, 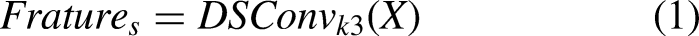


Structure of ELAN-S module. ELAN-S: efficient layer aggregation network-S.
Dynamic perception module LSKCSPC
The detection of different types of objects depends on different contexts. Especially, smaller sized objects contain limited feature information, and more representative features are needed for our task. Therefore, the feature extraction and fusion with fixed effective receptive fields are difficult for the recognition of small objects. In [
10
], researchers proposed an effective receptive field selection module, which can dynamically adjust the effective receptive field of feature extraction, and better address the limitations of fixed-receptive field for feature extraction of different objects.
10
The feature extraction module SPPCSPC consists of two parts: spatial pyramid pooling (SPP) and cross stage partial connection (CSPC). SPP can increase receptive field and feature diversity through pooling at different scales, and use a convolutional layer to fuse features at different scales together, so that the network can adapt to objects at different scales.
11
CSP can divide the input feature map into two parts, one is directly passed to the next layer, and the other is fused with the previous part after multiple convolutional layers, which can reduce feature redundancy and calculation, while retaining low-level and high-level feature information.
12
However, the SPPCSPC module also has some limitations; the SPP part operates with fixed pooling size and step size, which cannot adapt to its optimal effective receptive field range for objects of different sizes and shapes. Therefore, this paper introduces the concept of dynamic effective receptive fields to improve the SPP component of the SPPCSPC module, proposing the Large Selective Kernel and Cross Stage Partial Channel Fusion Module (LSKCSPC) module. The SPP component of the module adopts a two-branch structure to extract features from the input feature map while adjusting the effective receptive field. The first branch is the spatial pyramid feature pooling and fusion module, which incorporates an effective receptive field adjustment module. The effective receptive field adjustment part controls the size of the convolutional effective receptive field using convolution kernel size and dilation rate. It extracts features with different effective receptive fields from the input feature map X.
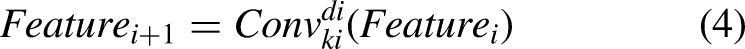







Structure of LSKCSPC module.
Detection heads for small objects
Recognizing the locking state of the open-top wagon side door is challenged by small object detection. As shown in Figure 7, in the open-car side door closing state detection data set, the ratio of length and width to sample size of the object is large.

Ratio of object instance width and height to sample width and height in the dataset.
In the tail distribution, most object instances in the data set belong to small objects, 14 and the ratio of length and width to sample size is lower than 0.1. The object of this scale has a small number of pixels in the image and is easily affected by noise and blur. The general object detection head is generally poor on small-scale object detection, because their receptive field is large, and they cannot effectively capture the detailed characteristics of the object.
In order to improve the detection performance of the network for small objects, a 160 × 160 small-scale object detection head is introduced into the detection network to replace the 20 × 20 large-scale object detection head in the baseline network, which increases the feature size in the detection network, thereby reducing the receptive field of the detection head to give more attention to fine-grained features. The improved structure is shown in Figure 8. In this way, the detection network in this paper can better adapt to the object scale distribution of the open-top wagon side door lock state detection dataset and improve the detection accuracy.
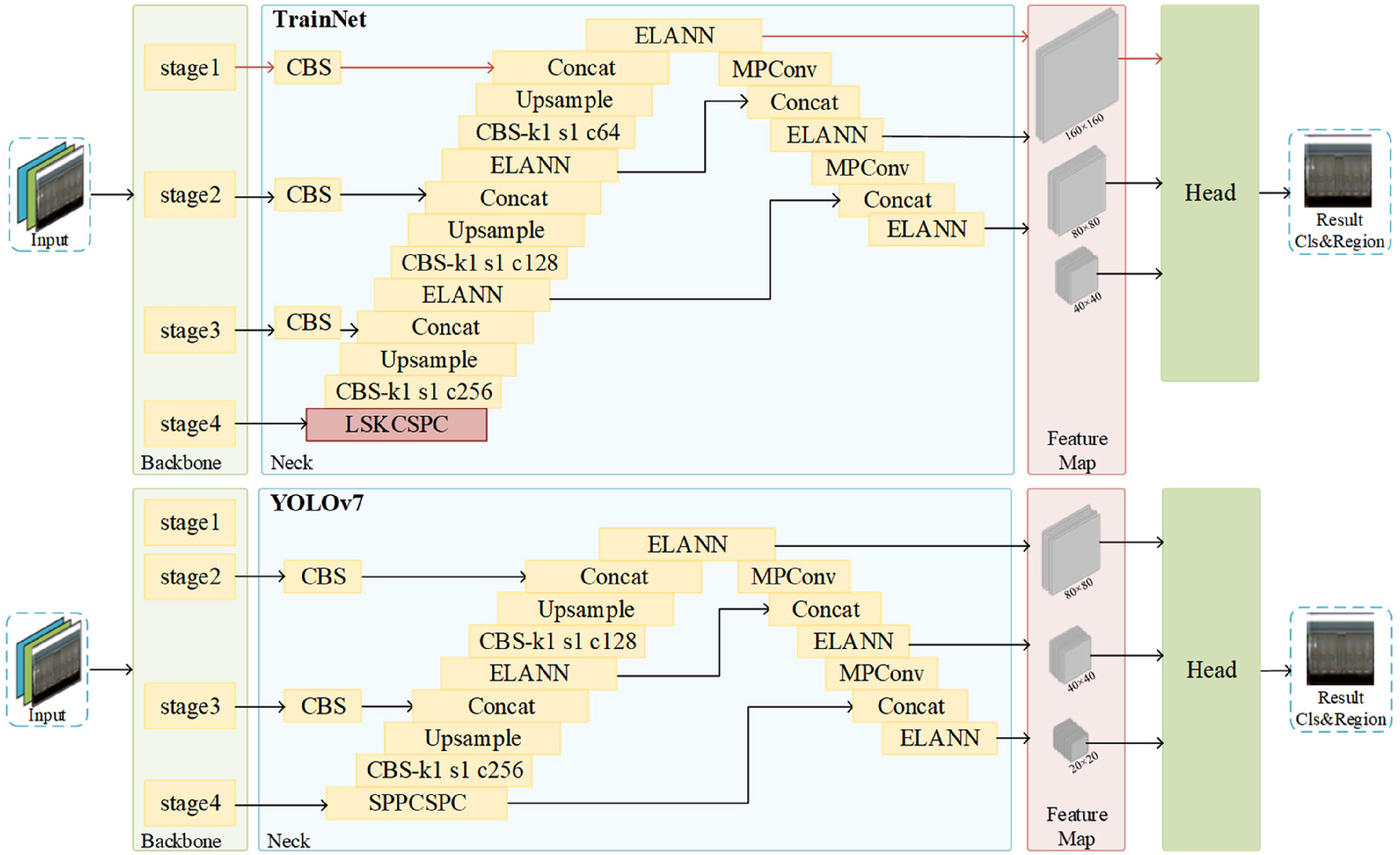
Comparison of detection networks (top:YOLOv7; bottom:TrainNet).
CNIOU loss function
The IOU-based loss function is sensitive to the position deviation of the predicted bounding box and the true bounding box in the detection task of small objects. IOU only considers the overlap area of two bounding boxes, but ignores their relative position and scale. Figure 9 shows the values calculated by IOU when the small object prediction bounding box deviates from the regular object prediction bounding box by 1 pixel and 4 pixels in the diagonal position. Small position deviations of small objects lead to significant drops in IOU values, which may cause the predicted bounding box to be incorrectly assigned to the corresponding true bounding box or to be incorrectly considered as background, thus affecting the detection performance. In [ 5 ], researchers introduce a loss function based on the similarity of bounding box probability distribution, which calculates the optimal transmission distance of two bounding box distributions as a loss avoidance problem, but its performance in the detection of open-wagon side door lock state was not ideal in the experiment.

IOU values at different position deviations for object prediction bounding boxes at different scales.
In order to improve the accuracy and robustness of object detection and reduce the influence of small-scale object position deviation on the value of loss function, this paper proposes a new loss function, called CNIOU loss function. The CNIOU loss function is based on the original loss function CIOU, and the NWD loss function is introduced to increase the matching degree of the bounding box probability distribution and reduce the sensitivity of the original loss function to the position deviation. At the same time, the NWD loss function does not consider the shape and aspect ratio of the bounding box, which may cause the detected object shape to be inaccurate. Based on the IOU loss function, the CIOU loss function adds the penalty term of the distance between the center points and the aspect ratio of the two bounding boxes to consider the similarity of the position and shape of the bounding boxes.
15
The NWD is a loss function based on the optimal transmission distance, which can measure the distance between two probability distributions and thus reflect the degree of offset and scaling of the bounding box. Different from the traditional fusion loss function with fixed weight, the CNIOU loss function adopts a strategy of dynamic weight, adaptively adjusting the proportion of CIOU and NWD loss functions according to different training samples, so as to balance the advantages of both and avoid their disadvantages. Through experimental verification, we validate the effectiveness and superiority of CNIOU loss function. Compared with CIOU, NWD and fixed fusion CIOU and NWD loss functions, it can achieve better performance on the same data set and evaluation index. The loss function is defined as in (11).


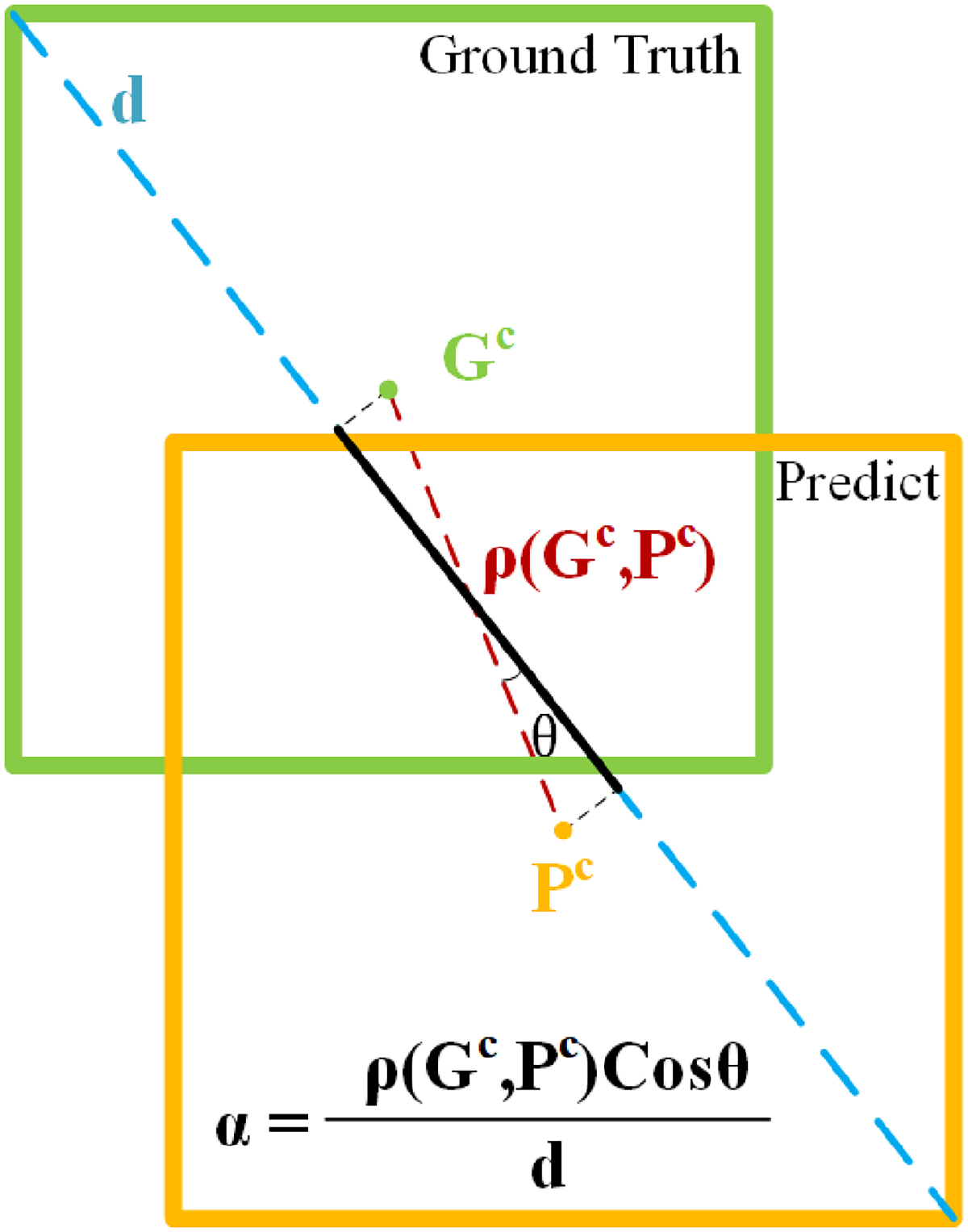
Calculation of
Experiment and conclusion
Experimental setup and evaluation index
The experiment uses the open-top wagon side door lock state detection data set and divides the data set according to the ratio of 8:2 to conduct the experiment, forming the training set, test set, and validation set, respectively. The main software and hardware environment settings of this experiment are as follows: the processor is Intel Xeon Gold 5218, the graphics card is Nvidia Tesla V100-SXM2(16GB), the operating system is Ubuntu 20.04, and the deep learning platform is Pytorch1.9.0. The experimental hyperparameter configuration is as follows: initial learning rate is 0.01, momentum is 0.937, weight decay is 0.0005, stochastic gradient descent optimizer SGD
16
is used, batch size is 16, Epoch is 300, and the rest of the parameters are the default values. The experiment uses the mean average precision (mAP) of each class when IOU is 0.5 and 0.5:0.95 to measure the detection performance of the model, which is calculated as follows.

Comparative experiment analysis
The experiments are done by comparing different conventional object detection algorithms to evaluate the performance of the proposed algorithm. The experimental results are shown in Table 3.
Comparison experiment of conventional object detection algorithms.

mAP: mean average precision; FPS: frames per second.
The experimental results show that, compared to the baseline models, the proposed algorithm improves mAP50 and mAP50:95 by 3.6% and 0.59%, respectively. At the same time, the number of parameters is reduced by 19.8%, and the model size is reduced by 19.5%, achieving better detection performance with lower complexity. However, the detection speed is lower than the baseline model, but it still meets the requirements for real-time detection. Compared to other models, the proposed algorithm shows varying degrees of performance improvement.
The P-R curve is used to measure the performance of the detection algorithm by the accuracy and recall rate, and the area enclosed by the curve represents the average accuracy AP of the algorithm for the category of detection. The P-R curves of the baseline model and the proposed TrainNet are shown in Figure 11.

P-R curve (left :YOLOv7; right :TrainNet).
The figure shows that the P-R curve of the proposed TrainNet is higher than that of the baseline model in all six categories. Therefore, compared with the YOLOv7 benchmark model, the TrainNet in this paper has higher accuracy and better detection performance under the same call rate.
To compare the performance of the proposed algorithm with other small object detection methods, experiments are conducted to compare different small object detection methods on the open-wagon side door lock status detection dataset. The results are shown in Table 4. The results show that, compared to these small object detection methods, the proposed algorithm has better detection accuracy and can meet the requirements for real-time detection.
Comparison experiments of small object detection algorithms.

FPS: frames per second.
Module effectiveness comparison experiments
Comparative experiment of data set balance processing
In order to verify the effectiveness of the location-limited copy-paste method for data set balancing, the YOLOv7 model is used to complete the training on the original data set and the data set after data set balancing, and the performance evaluation is carried out on the test set. The results are shown in Table 5.
Comparison experiment of dataset before and after balancing.

mAP: mean average precision.
The experimental results show that the detection performance of YOLOv7 detection model on the balanced data set is significantly improved compared with that on the non-balanced data set. The mAP50 of YOLOv7 training on the balanced data set is 5.1% higher than that on the original data set. The location-constrained copy-paste method is used to balance the data, which can effectively improve the performance of the model to detect the locking state of the gondola car side door.
Effectiveness of the linear feature extraction module
To verify the effectiveness of the proposed linear feature extraction module in extracting linear features, this paper uses GradCAM 19 to visualize the feature maps during inference. The feature heatmaps are compared to assess the attention to different regions. The experiments are conducted using the baseline model, the improved small object detection network, and the improved small object detection network with the ELAN-S module added. The heatmap visualization results are shown in Figure 12.

Heatmap of feature map.
The results show that the baseline model can roughly locate the position of the door lock objects, but its attention to the main features of the door lock objects is not concentrated, resulting in inaccurate localization of small objects and susceptibility to additional feature information, which affects the detection performance. After improving the small object detection network, the ability to extract fine-grained features is enhanced, and the localization of small object features is more precise, but it is still susceptible to interference from other features in the background. After adding the ELAN-S module, the ability to extract linear features of the door locks is significantly enhanced, and it filters out features that are not related to the door locks. In a summary, the ELAN-S module proposed in this paper has better learning capabilities for features compared to the ELAN module in the baseline network.
Comparison experiment of loss function effect
In order to verify the effectiveness of dynamic fusion loss function CNIOU, we conduct experiments to compare the effect of TrainNet network using CIOU, NWD, fixed fusion CIOU with NWD and using CNIOU four loss functions, and the comparison results are shown in Table 6.
Comparison experiment of loss function.

mAP: mean average precision.
The experimental results show that the CNIOU loss function can achieve the best performance on the same data set and evaluation indicators. The mAP50 of the model using NWD loss function is increased by 2.1%compared with that using CIOU, and mAP50:95 is decreased by 9.7%under the condition of NWD loss function. The mAP50 of the CIOU and NWD fusion loss function with fixed coefficients is 1.4% higher than that of CIOU, while mAP50:95 is 1.4% lower than that of CioU. The mAP50 under the condition of CNIOU loss function in this paper is 1.7% higher than that under CIOU, and mAP50:95 does not decrease. This shows that the CNIOU loss function can effectively employ the advantages of the two loss functions while avoiding their disadvantages, thus improving the accuracy and robustness of object detection.
Ablation experiments
To verify the effectiveness of the proposed improvements, seven sets of ablation experiments were designed, where A is the improved small object detection network, B is the introduction of the ELAN-S module, C is the introduction of the LSKCSPC module, and D is the introduction of the CNIOU loss function. The experimental results are shown in Table 7.
Ablation experiments.

mAP: mean average precision; FPS: frames per second.
The experimental results show that the proposed improvements have a higher accuracy compared to the baseline model. The final TrainNet algorithm proposed in this paper, especially in terms of mAP, shows a significant improvement. Specifically, the mAP50 of the proposed algorithm reaches 91.5%, an improvement of 3.6% over the original algorithm. The mAP50:95 is 66%, an increase of 0.59% over the original algorithm. Additionally, the model parameters and computational load of the TrainNet algorithm are significantly reduced. The size of the weight file for this algorithm is only 60.2MB, a 19.5% reduction compared to the original model. These results clearly demonstrate that the proposed algorithm improves accuracy while also reducing model complexity and resource consumption.
Detection results
TrainNet detection results are shown in Figure 13, where UP, MID, and SIDE correspond to the side door pin, SIDE door lock, and bottom side door lock, respectively. OK and NG correspond to lock binding state normal and abnormal, respectively. As shown in the figure, the TrianNet detection results show that there are 7 bottom side door locks and 1 side door lock that is not bound and reinforced. A side door pin is not properly locked; 5 bottom side door binding reinforcement is normal.

Detection results by TrainNet.
Comparative experiments based on the WiderPerson dataset
The generalization ability of the proposed model was tested on the WiderPerson public dataset. The WiderPerson dataset is a benchmark dataset used for human detection in complex real-world scenes and also belongs to the category of small object detection tasks. The images in this dataset have diverse and complex scenes with dense and varied human objects. The dataset contains 13,382 high-resolution images, with 8000 in the training set, 1000 in the validation set, and 4382 in the test set. Comparative experiments were conducted on this dataset, and the results are shown in Table 8. The results show that the proposed algorithm has significant advantages. Specifically, compared to conventional object detection networks, the proposed algorithm has better detection performance with lower model complexity. Compared to small object detection networks, the proposed algorithm has higher detection accuracy, but the model complexity is also relatively higher. Overall, the proposed algorithm also demonstrates a good performance on other object detection tasks.
Comparison experiment on WiderPerson.

mAP: mean average precision.
Discussion and conclusion
In this paper, we propose an improved object detection algorithm based on YOLOv7 network, called TrainNet. The algorithm improves the detection accuracy and efficiency by introducing a curve-sensitive feature extraction module and a dynamic perception module. In order to verify the performance of the algorithm, this paper conducts experiments on the open-top wagon side door lock state detection dataset collected by ourselves and compares it with YOLOv7, YOLOv5 and other methods. The experimental results show that TrainNet can effectively reduce the complexity and running cost of the model while ensuring the detection accuracy, and it has strong practical value and application prospect.
Footnotes
Acknowledgements
Jiangxi Province Technology Innovation Guidance Project (Science and Technology Cooperation Special Project) (20212BDH80008); Open Fund of Jiangxi Province New Energy Process and Equipment Engineering Technology Research Center in 2022 (JXNE2022-06); Jiangxi Province Science and Technology Plan Project (Key Research and Development Plan) (20232BBE50013);
Authors’ note
NX was involved in conceptualization, methodology, and software; CK was involved in data curation, creation and presentation of the published work. ZS written the original draft preparation. LX was involved in development or design of methodology and creation of models. LY was involved in formal analysis and writing—reviewing and editing.
Declaration of conflicting interests
The authors declare that there is no conflict of interest.
Ethical statement and conflict of interest statement
No conflict of interest exits in the submission of this manuscript, and manuscript is approved by all authors for publication. I would like to declare on behalf of my co-authors that the work described was original research that has not been published previously, and not under consideration for publication elsewhere, in whole or in part. All the authors listed have approved the manuscript that is DrawingNet for Communication Tower Drawings Recognition.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.