
Abstract
Flame and smoke detection is a critical issue that has been widely used in various unmanned security monitoring scenarios. However, existing flame smoke detection methods suffer from low accuracy and slow speed, and these problems reduce the efficiency of real-time detection. To solve the above problems, we propose an improved YOLOv7(You Only Look Once) algorithm for flame smoke mobile detection. The algorithm uses the Kmeans algorithm to cluster the prior frames in the dataset and uses a lightweight CNeB(ConvNext Block) module to replace part of the traditional ELAN module to accelerate the detection speed while ensuring high accuracy. In addition, we propose an improved CIoU loss function to further enhance the detection effect. The experimental results show that, compared with the original algorithm, our algorithm improves the accuracy by 4.5% and the speed by 39.87%. This indicates that our algorithm meets the real-time monitoring requirements and can be practically applied to field detection on mobile edge computing devices.
Introduction
Fire is one of the most influential and destructive disasters in modern society, and the characteristics of flames and smoke are uncertain, complex, and rapid. Accidental fires pose a huge threat to people’s lives and property safety as well as social harmony and stability [1, 2]. Therefore, timely detection and control of fires in the early stages are of great significance. However, the current fire detection methods still rely mainly on traditional smoke, temperature, and light sensors, which can only effectively detect when the sensor is close to the fire or smoke source, and further activate the alarm and fire suppression system. In literature [3], the RGB-HIS color model was used to segment suspected flame areas, while stereo cameras and laser ranging were used to capture flame features. Research [4] proposed a flame recognition algorithm based on the color and texture features of flames. This algorithm uses a block-based LBP(Local Binary Pattern) histogram feature combined with an LPQ(Local Phase Quantization) histogram feature, which can reduce false alarms caused by flame-like interference sources Wang et al. proposed a highway tunnel early flame recognition method based on multi-feature flame images and the AdaBoost algorithm [5]. By studying the static and dynamic features of uncontrolled flames, this method can effectively eliminate false alarms caused by interference such as flame-like car lights. A real-time smoke segmentation algorithm based on multi-resolution representation was proposed, which extracts semantic information by parallel extracting multi-resolution feature maps [6]. A smoke detection algorithm based on smoke-enhanced color transformation and MSER(Maximally Stable Extremal Regions) detection was proposed, which is used to detect small areas and slowly moving smoke features [7]. The relationship between CO concentration and smoldering time was studied using a broadband infrared thermal source and a dual-channel thermoelectric detector, and a method of detecting fires by the change of CO concentration was proposed, but this method is difficult to apply in environments with smooth airflow [8]. These methods are robust but have some delay and are easily affected by environmental factors such as wind in outdoor flame and smoke detection, resulting in a deviation from the detection range of traditional sensors, leading to missed detection. Machine vision technology enables computers to understand environmental visual information, including image recognition, object detection, instance segmentation, etc. Among them, object detection allows computers to recognize key information in images and is one of the basic technologies for visual understanding, with very important research significance. At present, target detection based on deep learning to gradually become mainstream, such as R-CNN (Convolutional Neural Network) [9], Faster R-CNN [10], LSTM [11], etc., in which the role of R-CNN and Faster R-CNN is generally based on feature extraction, while the LSTM(Long short-term memory) is usually used as an auxiliary means, based on the target’s time series information to help improve the accuracy and stability of the target detection. Common target detection algorithms include two-stage detection algorithms and one-stage detection algorithms. The first step of two-stage algorithms is to train the RPN(Region Proposal Network), and the second step is to predict the classification and location information of the target by CNN. Literature [12] uses R-CNN to obtain suspicious regions for fire features, after which a LSTM network is used to accumulate aggregated features within the bounding box in consecutive frames, which are later classified in terms of whether or not a fire has occurred in the short term. Huang et al. [13] proposed an anchor strategy based on color guidance, which uses the color of flames to constrain anchor box generation and improves the efficiency of detecting flames in images. To reduce the false alarm rate in video smoke detection, The research [14] proposed the YdUaVa color model for characterizing the spatial domain distribution properties and temporal domain variation properties of smoke and combined it with MobileNetv3 to extract smoke features for identification.
Target detection methods based on machine vision have gradually been applied in fire detection. Single-stage algorithms dominated by the YOLO algorithm family omit the RPN structure and use the idea of mathematical regression to determine the category probability and position coordinates of the object. Compared with the former, the detection accuracy is slightly lower but the speed is greatly improved [15-18]. The ViBe algorithm was improved based on smoke color features for extracting moving smoke in videos, and the YOLOv3 algorithm was used for smoke detection [19]. Masoom et al. used PCA (Principal Component Analysis) for image preprocessing and added detection dimensions in the YOLOv3 algorithm to detect small smoke in outdoor environments [20]. The study [21] combined the YOLOv3 algorithm with the EfficientNet method to extract features from the input image to detect forest fires. Wang et al. proposed a deep separable attention module and bidirectional FPN (Feature Pyramid Network) structure applied in the YOLOv4 algorithm for detecting smoke and flame features [22]. Wu et al. introduced the dilation convolution module in the YOLOv5 algorithm, used GELU as the activation function, and used DIoU NMS to predict bounding boxes, improving the robustness and reliability of fire detection [23]. Lin et al. combined Transformer and CNN for flame and smoke feature extraction, and integrated CA(Coordinate attention) attention mechanism and ASFF(Adaptive Space Feature Filtering) to filter out useless information, making it more focused on detecting forest fire targets [24]. The YOLO series algorithm also has a wide range of applications in other industrial and agricultural fields, such as automatic and assisted driving [25, 26], defect detection [27], remote sensing information identification [28], and smart agriculture [29, 30], with high reliability and applicability. With the large-scale popularity of video surveillance, detection methods based on machine vision have the advantages of wide detection range, strong anti-interference ability, low installation cost, and can provide fire location and propagation direction information compared to traditional detection methods. Rapid detection in the early stages of a fire is extremely important as flames easily ignite surrounding combustibles, making improving detection speed while maintaining detection accuracy a key issue to be addressed.
This paper proposed a mobile monitoring algorithm for flame and smoke based on the improved YOLOv7 algorithm. To solve the problem of complex and variable feature information of flame and smoke, an innovative feature extraction module CNeB was added, while Kmeans algorithm and Soft CIoU-NMS were used to enhance the training effect to strengthen the algorithm, aiming to capture the feature information of fire and delay. The improved structure diagram is shown in Fig. 1. The improvements made in this paper mainly include the following three aspects:
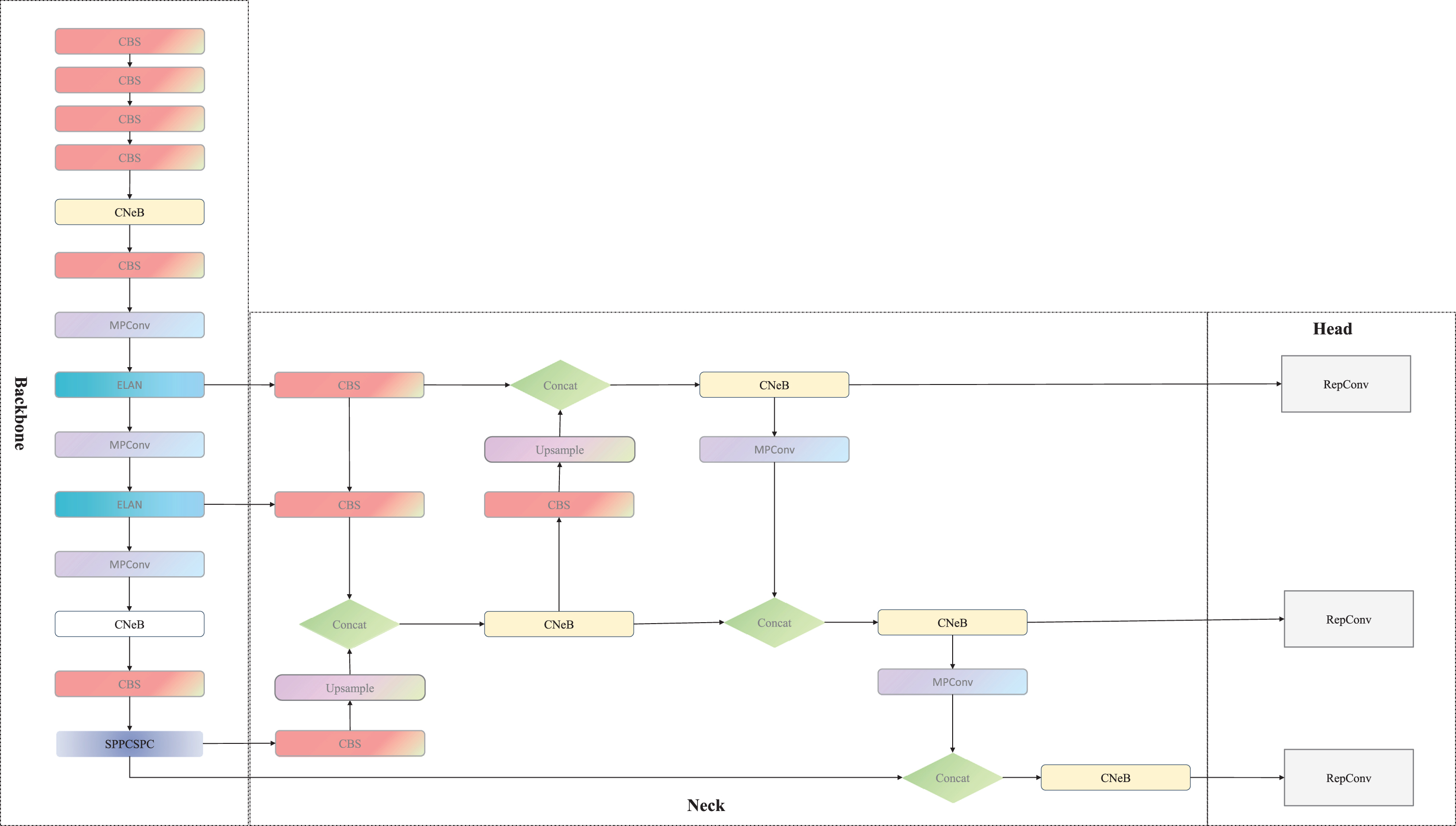
CNeB-YOLO Structure diagram.
(1) To deal with the uncertainty and complexity of target location changes in the flame and smoke dataset, the Kmeans algorithm is used to cluster the anchor box coordinates in the self-built dataset to obtain prior anchor box coordinates suitable for this dataset, which improves training speed and model accuracy.
(2) The innovative replacement of the computationally intensive ELAN module with the lightweight CNeB module enhances feature extraction and reduces the model size, making it better suited for deployment on edge devices for detection, lowering the operating costs of the algorithm model, and improving detection real-time performance.
(3) An optimized Soft CIoU-NMS is used to reduce the number of suppressed boundary boxes, improving the accuracy of object detection. These improvements make this algorithm more effective in capturing the feature information of flames and smoke on edge devices.
The content arrangement for the remainder of this paper is as follows: In Chapter 2, we will introduce the YOLOv7 algorithm and provide a detailed account of the improvements and innovations we have made to it. In Chapter 3, we will demonstrate the superiority and practical detection effectiveness of the proposed new method through experiments and data analysis. In Chapter 4, to validate the feasibility of our proposed method in real-world applications, we employ TensorRT for acceleration and deploy it on Nvidia Jetson for simulating the running performance in practical monitoring scenarios. In the final section, we will summarize the preceding content and discuss the future prospects of this method.
YOLOv7 network model
The YOLO series algorithms are a classic type of one-stage algorithm for object detection. They partition images into different-sized anchor boxes and perform regression operations on them for object detection. As an end-to-end algorithm, the YOLOv7 network model is mainly divided into four parts: Input, Backbone, Neck, and Head. The Backbone part is the main network for target feature extraction. YOLOv7 introduces a new multi-branch stacked ELAN module in this part. In this module, the output feature information from the upper layer is divided into multiple branches, and different numbers of convolutional operations, normalization operations, and activation operations are performed on them. Finally, the feature information of different depths from each branch is stacked and then convolved again to obtain the overall feature information of different dimensions. The multi-residual structure module inside the ELAN module uses multiple skip connections, which can greatly alleviate the problem of gradient disappearance caused by increasing depth in deep neural networks. The ELAN structure is shown in Fig. 2.

Structure diagram of the ELAN module.
The innovative approach in this study involves using the MPConv(Max Pooling convolution) hybrid convolutional module for down-sampling the feature information, the detailed structure is shown in Fig. 3. This method combines two common down-sampling methods, by branching the image information and using a 3x3 convolutional kernel with a stride of 2x2 and a max pooling operation with a stride of 2x2. The results of both operations are then stacked to obtain more diverse and informative down-sampling feature information.

The structure diagram of the MPConv module.
The Neck part utilizes the FPN to enhance feature extraction. After obtaining three different depth feature layers from the Backbone part, the features are first divided into two parts through the CSP (Cross Stage Partial) module. One part only undergoes basic convolution activation operations, while the other part is processed by the SPP (Spatial Pyramid Pooling) module, which applies four different scales of max pooling layers to distinguish large and small targets and greatly enhances the receptive field of the model. Then the two parts are merged, greatly reducing the computational complexity, and improving training speed and model accuracy. The detailed structure is shown in Fig. 4.

Structure diagram of sppcspc module.
In this paper, a novel CNeB module with a more ingenious structural design is introduced into the YOLOv7 algorithm by us, which has streamlined logic and efficient operation. The improved CNeB-YOLO architecture diagram is shown in Fig. 6. The CNeB module employs DW (Depth Wise) convolution, which, compared with traditional convolution operations, only requires independent calculations within each channel during the convolution process, resulting in smaller computation costs and less information loss, and is beneficial for extracting richer and more accurate features. This method can significantly reduce computational costs and improve computational speed when running on mobile devices. Meanwhile, a 7*7 convolution kernel is also used, which enlarges the receptive field compared with the traditional 3*3 kernel and has an advantage in detecting large smoke and flames. Additionally, the use of a larger convolution kernel can better capture image details and texture information, thereby improving the accuracy of the model. The DW convolution structure is shown in Fig. 5, after applying the convolutional operation to a three-channel color input image with the same number of convolutional kernels as the number of channels, an equal number of feature maps are generated. Each convolutional kernel performs convolution independently on its corresponding input channel, resulting in a set of feature maps equal in number to the input channels.
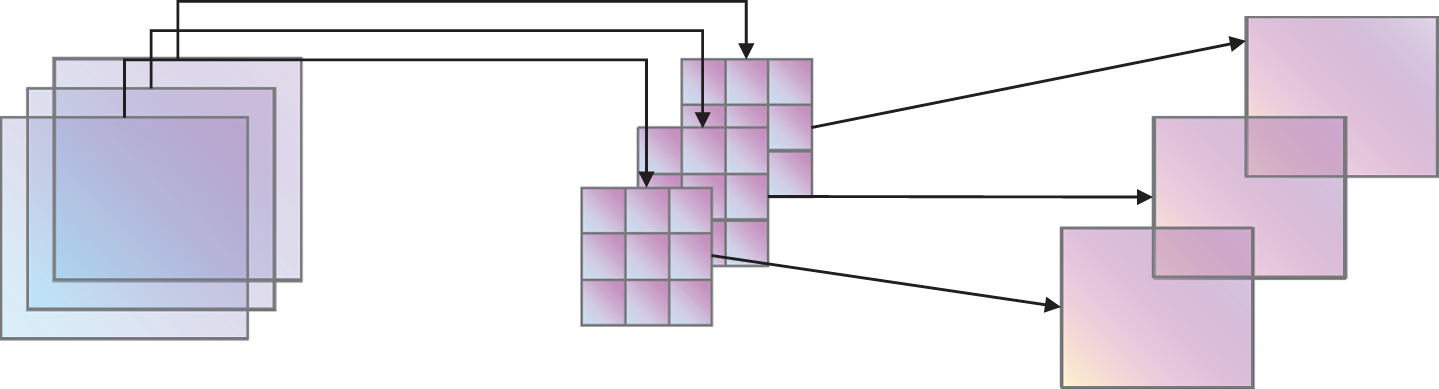
DW Convolutional structure.
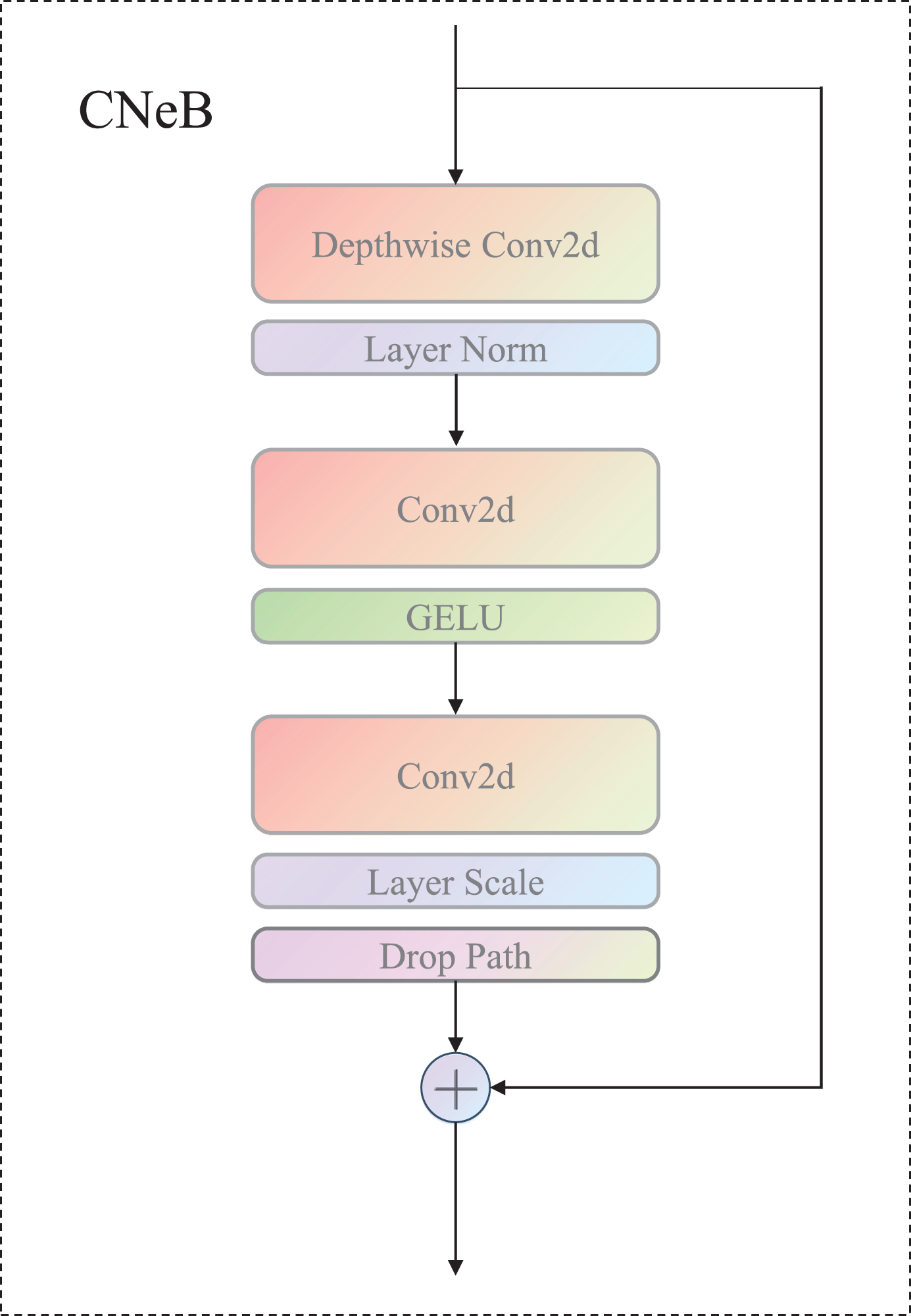
CNeB module structure.
In addition, the original ReLU activation function was replaced by us with the GELU activation function, and it was only applied to the first fully connected layer, greatly reducing the proportion of activation function layers in the entire network structure. Batch Normalization (BN) is a commonly used operation in traditional convolutional neural networks, which can accelerate network convergence and reduce overfitting. In the CNeB module, the Layer Normalization (LN) operation commonly used in NLP was borrowed by us in the ViT (Vision in Transformer), and the BN operation was replaced with the LN operation for all features.LN operation normalizes all features within a sample, while BN operation normalizes each feature in a batch-size sample. To better extract the feature information of flame and smoke, the CNeB module is employed to replace certain ELAN modules in the original algorithm. The multi-branch structure in the CNeB module is designed to adapt to the feature extraction requirements of irregular flame and smoke at different scales. Additionally, the introduction of interaction and integration between channels promotes information transmission and communication among different channels, leading to a more comprehensive understanding of the semantic and structural information of input data. Moreover, through feature integration operations, the feature information from different branches is connected, effectively preserving the feature representations from different branches and providing richer and more comprehensive feature information. In particular, compared to the ELAN module, the CNeB module exhibits lower computational complexity, reducing the number of channels while maintaining the integrity of information. This is particularly advantageous in scenarios with complex backgrounds and significant occlusions between objects. The CNeB module helps the algorithm adapt better to different scenes and backgrounds, improving the robustness of the algorithm model and enabling it to achieve good detection performance in various scenarios.
Overall, the utilization of the CNeB module in the algorithm enhances the extraction of flame and smoke features by providing a multi-branch structure, facilitating inter-channel interaction and integration, and enabling better adaptation to different scenes and backgrounds. The CNeB module reduces the computational burden, maintains information integrity, and improves the algorithm’s robustness, thereby enhancing the detection performance in different scenarios.
Traditional NMS(Non-Maximum Suppression) algorithm uses IoU (Intersection over Union) to determine bounding boxes, which is an important metric used to measure the degree of overlap between predicted and ground-truth boxes in object detection. IoU is the intersection over the union of the two boxes, and it is scale-invariant and non-negative. However, it cannot accurately reflect the degree of overlap when the two boxes do not intersect. Therefore, the optimized Soft CIoU-NMS introduces the Euclidean distance between the centers of the two boxes and adds a loss function for the scale of the detection box. Compared with the traditional IoU loss function, Soft CIoU-NMS has stronger discrimination and solves the problem of unstable training caused by gradient disappearance, making the predicted box more consistent with the ground-truth box. It not only improves the accuracy but also increases the convergence speed of the model.
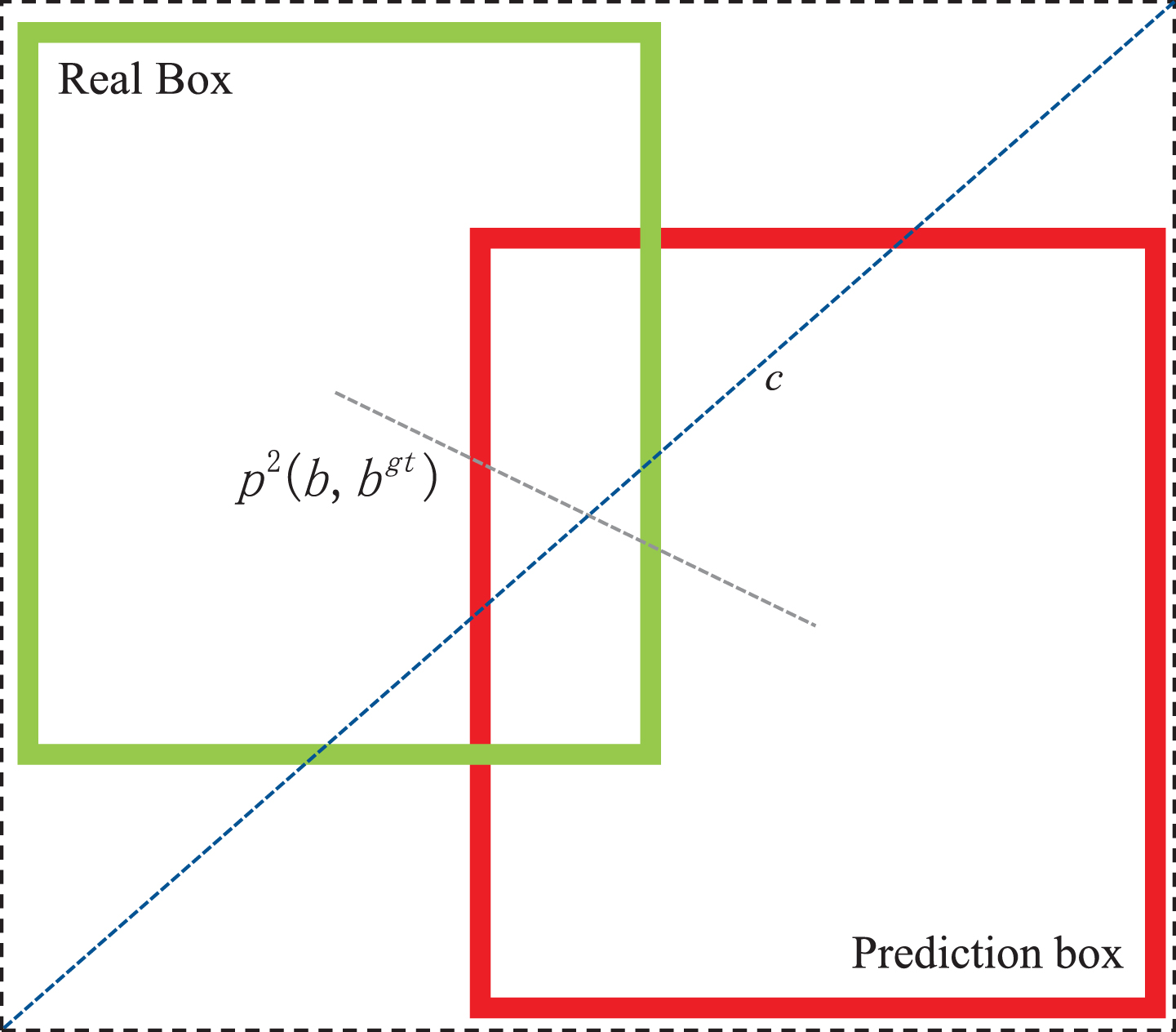
Schematic diagram of CIoU.
In single-stage object detection algorithms, the size and number of prior boxes have a significant impact on the detection results. The YOLOv7 algorithm first generates candidate regions (Anchor Boxes) for object detection, which are fixed-size rectangular boxes used to identify objects in the image. Usually, fixed anchor boxes generated based on the COCO dataset are used for training. However, in the combustion process of flame and smoke, unlike other fixed-shaped objects, the shape changes are complex and drastic, with great uncertainty at different stages of combustion. Therefore, this method uses the K-means algorithm to re-cluster the feature target positions in the dataset, and adaptively generate the best size and number of prior boxes according to the target shape and size in the training data. The dataset anchor boxes based on the combustion features of flame and smoke are used for training, which improves the algorithm’s generalization ability and significantly enhances training speed and model accuracy. The clustering results using the Kmeans algorithm are shown in Fig. 8. The maximum values of the horizontal and vertical coordinates represent the image input size for this algorithm. Clustering was performed based on the flame smoke locations of all markers in the dataset and nine cluster centers were obtained, represented by the x symbol.
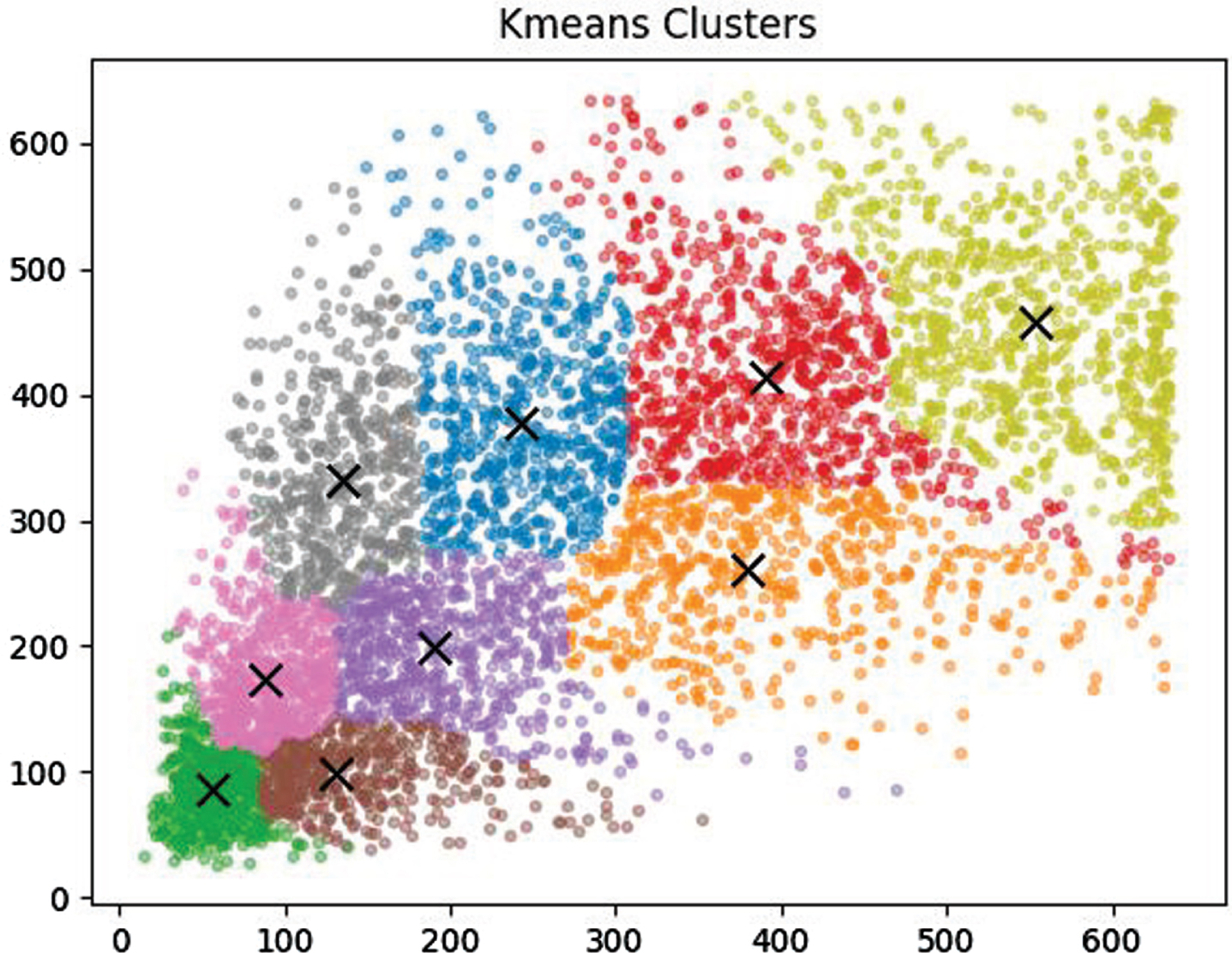
Kmeans cluster center.
Dataset collection and preprocessing
Datasets according to different stages of combustion were collected by us to address the characteristics of flame and smoke combustion. Emphasis was placed on selecting images with clear flames and dense smoke to construct the dataset. To ensure the quality of training and practical application, Images with both width and height greater than 600 pixels were selected by us and rotations and flips were performed to increase the dataset. Finally, A dataset of 10,311 images was obtained by us.
Experimental platform and evaluation indicators
The training and testing were conducted in the same environment with the following hardware configuration: CPU: Intel(R) Xeon(R) Gold 6130H, GPU: NVIDIA RTX3090 (24GB), and 32GB of running memory. The software environment was Windows with the PyTorch deep learning framework. For the classification problem of detection targets, examples can be classified into four categories: true positive (TP), false positive (FP), true negative (TN), and false negative (FN) based on the real classification and the detected classification by the model. In this experiment, mean average precision (mAP), precision, recall, and the harmonic mean of precision and recall (F1) were used as evaluation metrics.
Precision, in the context of our study, refers to the ratio between the number of samples correctly predicted as positive (TP) and the total number of samples predicted as positive by the model (TP+FP). A higher precision indicates fewer instances where negative samples are incorrectly predicted as positive, thus reducing the occurrence of false positives. Recall, on the other hand, represents the ratio between the number of samples correctly predicted as positive (TP) and the total number of actual positive samples (TP+FN). A higher recall indicates that the model can accurately capture a larger proportion of positive samples, thereby minimizing instances of false negatives. To comprehensively evaluate the performance of the model, we introduce the weighted harmonic mean of precision and recall, known as the F1 score. The F1 score balances the accuracy and recall of the model, with higher values indicating better overall detection performance. It serves as a valuable measure for assessing the model’s ability to simultaneously achieve high precision and recall.
The initial stage of weight model training uses the training weights obtained from YOLOv7 based on the COCO dataset for transfer learning. This can improve the convergence speed of the model on the flame and smoke dataset, reduce the training time, and enhance the training results. The entire experimental process lasted for 100 training epochs, with a confidence threshold set to 0.5 and a total of 300 training epochs. The batch size was 8 and the input size of the data was 416 x 416. The optimizer used was SGD.
Analysis of experimental results
To demonstrate the superiority of the proposed CNeB-YOLOv7 algorithm in this paper, it was compared with classical two-stage algorithms, the original unimproved algorithm, and lightweight algorithms using the same dataset throughout the entire experimental process. Table 1 presents a comparison of various performance parameters in the experimental results, and Fig. 9 shows a comparison of the actual detection results of the unimproved algorithm, lightweight algorithm, and improved CNeB-YOLO algorithm. The CNeB-YOLOv7 algorithm showed significant improvements in accuracy. From Table 1, it can be seen that classical two-stage object detection algorithms and previous YOLO series algorithms have low detection accuracy and high computational complexity, which makes them unsuitable for deployment on mobile devices with limited computing power. The improved CNeB-YOLOv7 algorithm had significantly reduced parameter quantity, floating-point operation times, and weight size while improving the mean Average Precision (mAP) of all categories by 5.8 percentage points compared to the unimproved algorithm, and by 28.6 percentage points compared to the lightweight YOLOv7 algorithm. Figure 10 shows the classification parameters of the model and its mAP. GFLOPS is an important indicator for measuring the computational complexity of deep learning models, and the improved CNeB-YOLO algorithm has lower GFLOPS, enabling it to process more sample data in the same amount of time, increasing the model’s throughput. Therefore, the CNeB-YOLO algorithm perfectly balances accuracy and speed. Higher accuracy can reduce the actual false positive rate during usage, while the lightweight design enables more efficient operation, saving energy and resources, making it more suitable for deployment on mobile devices for real-time monitoring.
Comparison of evaluation indicators before and after network model improvement
Comparison of evaluation indicators before and after network model improvement

Comparison of experimental results.
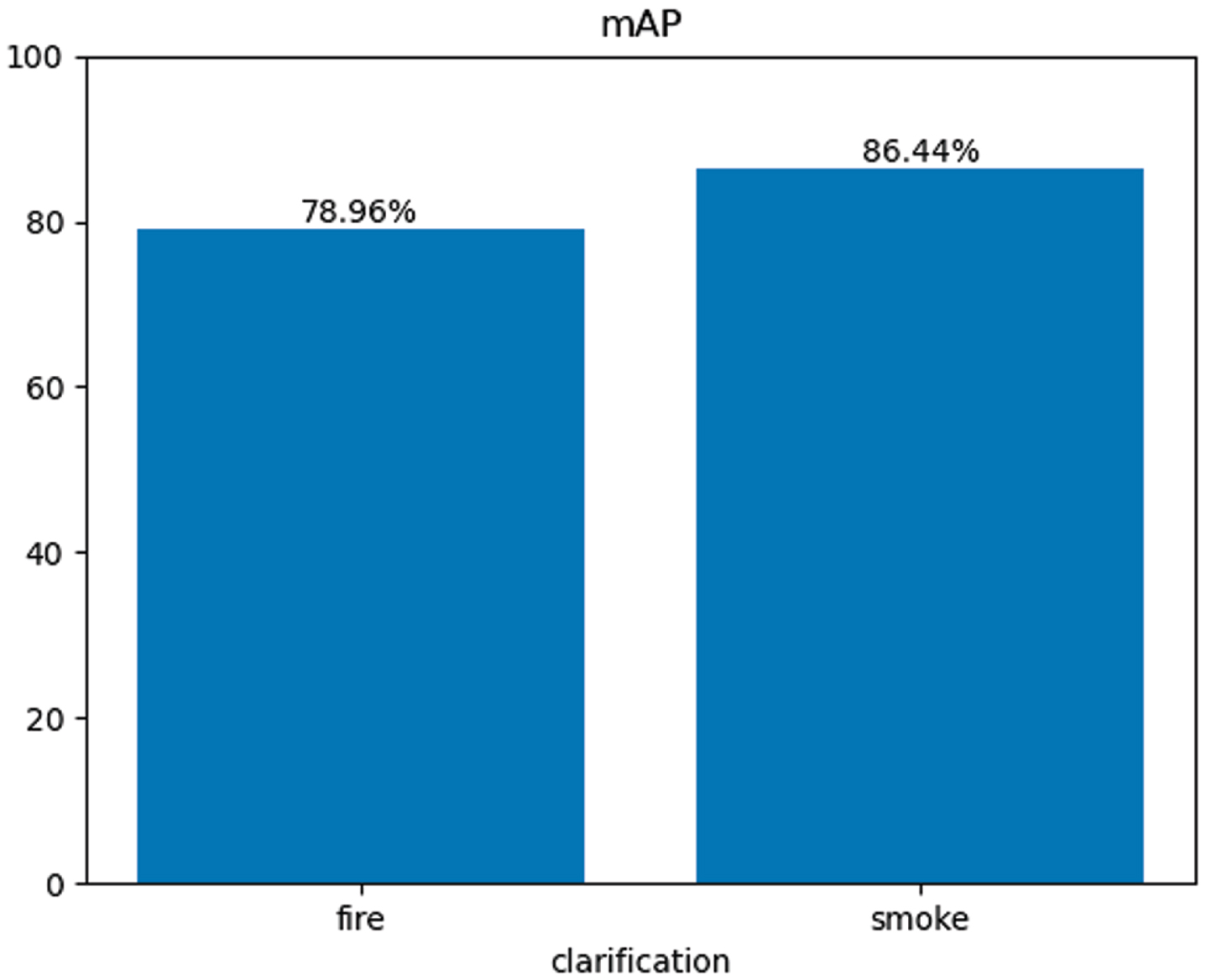
Classification mAP.
Application platform
To test the real-time flame and smoke monitoring performance of the improved YOLOv7 algorithm model in actual electric vehicle charging stations, It was deployed by us in NVIDIA’s Jetson Xavier NX edge computing device. The Jetson Xavier NX has a 6-core NVIDIA Carmel ARM v8.2 64-bit CPU, 384 CUDA cores, 48 Tensor Cores, and 2 NVDLA engines, providing 21 trillion operations per second at 15 watts of power. This device maintains a compact form factor while having powerful edge AI computing performance, providing a solution for large-scale deployment of AI-accelerated edge object detection and simultaneously processing multiple cameras, with a high cost-performance ratio. An AI monitoring camera was assembled by us through conducting secondary development on the Jetson Xavier NX. The AI monitoring camera consists of four parts: the Jetson Xavier NX device, a high-definition camera module, a display module, and a WIFI signal transmission module.
Tensor RT acceleration
TensorRT is a high-performance inference engine developed by NVIDIA, based on deep learning and GPU hardware acceleration, aimed at optimizing and accelerating the inference process of deep learning. It is widely used in computer vision, natural language processing, and speech recognition fields. To verify the acceleration effect of TensorRT, the algorithm model was exported by us in the engine type using TensorRT, and experiments were conducted on the test dataset using the TensorRT framework. The experimental results are shown in Table 2.
Comparison of evaluation indicators before and after network model improvement
Comparison of evaluation indicators before and after network model improvement
Based on the data in Table 2, it can be concluded that the engine type algorithm model exported using TensorRT is accelerated, reducing inference time by 7.6ms and improving inference speed by 50%. The time for non-maximum suppression (NMS per image) was reduced by 0.8ms, resulting in a speed improvement of 22%. The number of images detected per second (FPS) increased from the original 65.79 to 131.58. The improved CNeB-YOLO algorithm has greatly improved detection speed and accuracy compared to the YOLOv7 algorithm. Although the detection speed of the CNeB-YOLO algorithm is not as fast as that of the YOLOv7-Tiny algorithm, it has higher detection accuracy under the same real-time monitoring conditions. This means that the CNeB-YOLO algorithm can play a greater advantage in real-time detection tasks that require higher detection accuracy.
To further validate the practicality of the CNeB-YOLO algorithm, It was applied by us to a simulated fire detection environment. Due to the suddenness of fires and the difficulty in obtaining real-time monitoring video streams of ongoing fires, local video streams are more suitable as a feasible alternative. Therefore, a video recording of a fire scene was selected for simulation.
Figure 11 shows a simulation of video monitoring, depicting the practical use of the CNeB-YOLO algorithm in real-world fire detection scenarios. The video footage used for the simulation was captured at the scene of an electric car fire. Image (a) in the figure detects the release of smoke caused by the out-of-control electric car in the first instance. The subsequent images successfully detect the target information of flames and smoke, with real-time tracking of the targets. The algorithm performs well in detecting small flame targets, enabling early recognition and warning in the initial stages of a fire, exhibiting high sensitivity and excellent real-time performance.

Video surveillance simulation diagram.
To solve the limitations in flame smoke detection, an improved YOLOv7 algorithm is proposed in this paper. Firstly, the flame smoke dataset is self-constructed and the a priori frames in the dataset are clustered by the kmeans algorithm to better fit the morphological features of flame smoke to improve the accuracy of training; the CNeB module is used to replace the traditional ELAN module to significantly improve the fusion effect of the extraction of the irregular features; and the loss function is improved to use the CIoU to optimize the match between the predicted frames and the real frames. The article conducts sufficient comparative experiments on the same dataset, which improves 5.8 percentage points over the unimproved algorithm, and the mAP exceeds the current mainstream target detection algorithms, which proves the excellent performance of the proposed method in the detection of flame smoke. With the intelligence of monitoring systems, edge computing in mobile devices is gradually increasing. To test the actual detection performance of the improved algorithm, the algorithm model is deployed into NVIDIA’s Jetson Xavier NX edge computing device, and the algorithm model is accelerated using TensorRT, which increases the inference speed by 50% and reduces the inference time by 7.6ms, which significantly improves the detection performance, enhances the detection ability of the algorithm in the mobile terminal and reduces the computational cost, which can meet the needs of real-time detection. This paper contributes a novel and effective approach to the field of unmanned fire detection and also demonstrates the potential of this approach in future unmanned security alerting fields such as fire detection. In our future work, we will aim to reduce the false alert rate in non-normal environments and multi-source environments to bring more advanced and effective solutions to real-world problems in this field.