
Abstract
Hierarchical federated learning (HFL) is an effective “cloud-edge-device” distributed model training framework that protects data privacy. During HFL training, poisoning attacks on local data and transmitted models can affect the accuracy of the global model. Existing methods for defending against unauthorized attacks primarily rely on single-feature anomaly detection approaches, such as calculating distances or densities between data or model parameters. These methods fail to integrate multiple characteristics and metrics to capture anomalous model updates,thus exhibiting significant limitations in model robustness and accuracy. Therefore, we propose a robust hierarchical federated learning method with a dual-layer filtering mechanism (DF-HFL). This method first uses Kernel density estimation to infer the approximate data distribution of devices, ensuring minimal differences among devices within each cluster. It then calculates the density weight of each cluster and the local weight of each device, comparing the difference between local and global weights. Anomalous weights are filtered through a threshold during aggregation. DF-HFL amplifies the distance between malicious updates and normal updates using the dual-layer filtering mechanism, effectively identifying anomalous weights that do not significantly deviate from the normal weight distribution. This helps in accurately detecting anomalies. Additionally, mean filtering is employed to reduce the impact of anomalous data on the original normal gradients, enhancing system robustness. To demonstrate the effectiveness of the proposed method, experiments were conducted on MNIST, FMNIST, Heart Disease and Bank Market datasets. Compared to existing methods like FedAvg, Krum, Random, and Multi-Krum, the global model accuracy improved by 5.18%, 38.98%, 29.96%, and 6.44%.
Introduction
With the development of wireless communication technology and the increasing emphasis on data privacy and security, the hierarchical federated learning (HFL) framework based on “cloud-edge-end” collaboration has received more and more attention 1 and is widely used in scenarios such as smart transportation, 2 industrial internet of things monitoring, 3 and smart medical care. 4 Under this framework, the global model training requires uploading the local model trained on the local device (MD) to the edge server (ES), which is closer to the device, for partial aggregation, and then uploading the aggregated model to the cloud server (CS) for global aggregation, which is able to realize the model training and updating while protecting the privacy of data.5,6
However, the multi-tier architecture of HFL inherently increases its vulnerability to attacks. Attackers can launch poisoning attacks during model updates or transmissions at different layers, which leads to the propagation of these malicious updates at different layers, gradually affecting the global performance and reliability of the model.7,8
Therefore, the defence means of HFL is crucial for the accuracy and convergence of the global model. Traditional distance-based or density-based methods remove anomalous clients to enhance the robustness of the model by directly calculating the variability between the local gradients of different clients, but this single robustness method cannot cover all anomalies.9,10 For example, the distance-based anomaly detection method makes it difficult to find a uniform distance metric when the data distribution varies greatly, resulting in some benign clients being misjudged as anomalous clients, which in turn cannot participate in the training of the global model. Density-based anomaly detection mechanisms may incorrectly misclassify local anomalies as global anomalies, resulting in benign clients not being able to participate in the training either.11,12 In addition, the effectiveness of these methods may diminish when the attacked data or gradient is less different from the normal data. For example, gradient tampering attacks can affect the model without significantly deviating from the normal data distribution by creating small perturbations on the global model that gradually deviate from the correct optimization direction and are difficult to identify by a simple disparity metric.13,14
We propose a robust hierarchical federated learning method with a two-layer filtering mechanism named DF-HFL. This method investigating from two dimensions of data distribution and gradient, we adopt the method of combining distance and density as the anomaly scoring mechanism for data security and construct a filter federated learning algorithm, which is able to amplify the difference between anomalous and normal participants and reduce the influence of anomalous data on the system, and enhance the system’s overall robustness. It mainly includes: in order to ensure the security of the real data of MDs, the kernel density estimation algorithm is utilized on the server side to approximate the data distribution of MDs by updating the gradient, and the K-means clustering algorithm is used to classify the MDs with similar data distributions into the same cluster in order to effectively identify potential malicious updates in the case of non-uniform distribution. Then the KL scatter metric is utilized to calculate the variability of different MDs with respect to the local cluster distribution, and this is used as the anomaly scoring criterion. To further enhance anomaly detection, we propose a two-layer filtering anomaly detection mechanism. The first layer uses a maximal filter to amplify the distance between anomalous and normal updates to ensure that the system can correctly reject malicious updates. The second layer then applies a mean filter to the model gradient to highlight the overall trend of the data and help separate malicious updates from the global update trend. This not only makes the model updates smoother and more continuous but also achieves privacy protection by enhancing the robustness of the gradient while safeguarding the model performance. The method implements a multi-dimensional security assessment to accurately detect and discard malicious updates by measuring data distribution and gradient differences.
In summary, in real-world scenarios, DF-HFL can be applied to various large-scale data collaborative training scenarios. For example, in smart transportation scenarios, DF-HFL monitors traffic flow, surveillance videos and other data collected by road test units and edge devices, and analyzes them to identify abnormal data. At the same time, during the collaborative training process, it ensures that the model is trained towards the optimal goal to avoid the impact of abnormal updates on the model.
The main contributions of this article are as follows:
This article proposes a robust hierarchical federated learning method with a dual-layer filtering mechanism. At the edge server (ES), Kernel density estimation (KDE) is used to approximate the original data distribution of mobile devices (MDs) and K-means clustering is applied to group MDs into clusters, ensuring that the differences between MDs within each cluster are minimized to accurately identify anomalies during training. The article introduces a dual-layer scoring mechanism based on distance and density to detect anomalies. The cluster density weight for each cluster is obtained through clustering, and each MD’s local weight is derived based on KL divergence. Then, the anomaly score for each MD is calculated by multiplying the difference between the MD’s local gradient updates and the global gradient by the weight. The dual-layer filtering mechanism is employed to filter out anomalous data. A gradient amplifier is used to enlarge the distance between normal updates and anomalous updates, enabling accurate differentiation between anomalous and normal data. Mean filtering is used to highlight the overall data trend, reducing the influence of outliers and identifying potential anomalous updates. The effectiveness of DF-HFL was validated on the MNIST and FMNIST datasets. Experimental results show that the global model accuracy of DF-HFL increased by 23.71% and 47.58% compared to other methods.
Related work
Existing HFL anomaly detection methods typically calculate differences in data distribution or gradient updates using evaluation metrics such as distance or density, then use these differences for anomaly scoring, and finally select normal data distributions or gradient updates for the global model based on the scoring and filtering mechanism.15–17
The basic idea of distance-based detection mechanisms is to use the distance or similarity between samples to determine whether there is an anomaly or malicious behavior. Common distance metrics include Euclidean distance, Manhattan distance, cosine similarity, and so on.18,19 In literature Arias et al., 20 researchers used a nearest-neighbor approach to calculate anomaly detection scores and proposed a nonparametric detection algorithm that combines distance and isolation metrics to represent the most relevant features of anomalies. Although this method can detect different types of anomalies, it is easy to cause misjudgments due to the lack of a unified distance metric in non-IID scenarios. Therefore, Velliangiri et al. 21 proposed a feature distance map-based measurement method to identify denial of service (DoS) attacks in networks, using min–max normalization to standardize identified features and mark correlations between features, which reduces computational complexity and system error rate. Meanwhile, many researchers have used triangular region map techniques to model real-world environments and segment them into different regional structures based on extracted features or content, using support vector machines (SVMs) based on the distance to associate data samples with cluster centers, enhancing detection accuracy. 22 In Li et al., 23 researchers proposed a segmented detection method based on the local malicious factor, identifying malicious participants by estimating the distance between data distributions. Building on this, Gong et al. 24 proposed amplifying the most active features in each local update to better distinguish between malicious and benign updates, improving overall system efficiency. Although these methods can identify potential malicious attacks by analyzing the characteristics of data and gradients, distance-based detection methods struggle to accurately calculate differences between participants’ data and gradients in high-dimensional data spaces. Additionally, if the training dataset is unevenly distributed or contains significant noise, the distance calculation will be affected, leading to a decline in detection performance.
Reputation-based detection mechanisms guide the identification of malicious participants through methods like setting reputation score thresholds and implementing reputation reward-punishment mechanisms.25,26 The trust score-weighted mean update then incentivizes the training of the global model. However, these methods overlook the uncertainty of clients in the FL training environment, as they do not consider that reliable clients may randomly switch from trustworthy to malicious behavior during the training process. Thus, Al-Maslamani et al. 27 proposed allowing the server to select devices for training based on the client’s reputation scores to update the global model, using a reinforcement learning algorithm to adaptively choose the optimal reputation threshold. Additionally, researchers addressed the real-time dynamic changes in vehicular networks, proposing a logarithmic normalization scheme based on reputation updates to accurately handle scaled gradients from malicious vehicles, thereby improving system robustness. 28 Although these methods can filter out malicious participants through reputation scoring mechanisms to ensure correct model training, most current methods do not consider the personalized adaptive adjustment of reputation thresholds, which prevents the setting of personalized threshold parameters for specific client groups, affecting the model’s performance.
Model framework
In this section, we describe the proposed hierarchical collaborative federated learning (FL) model training framework, as shown in Figure 1. First, the central cloud server (CS) in hierarchical FL sends the initialized global model to each participating edge server (ES), and the ES then forwards the initialized global model to each mobile device (MD) participating in local training. Second, the MDs use their own datasets to begin training the model. After a certain number of training rounds, the local model updates are uploaded to the connected ES for aggregation. Finally, the partially aggregated models from the ES are uploaded to the CS for global aggregation. The notation used in this article is explained in Table 1.
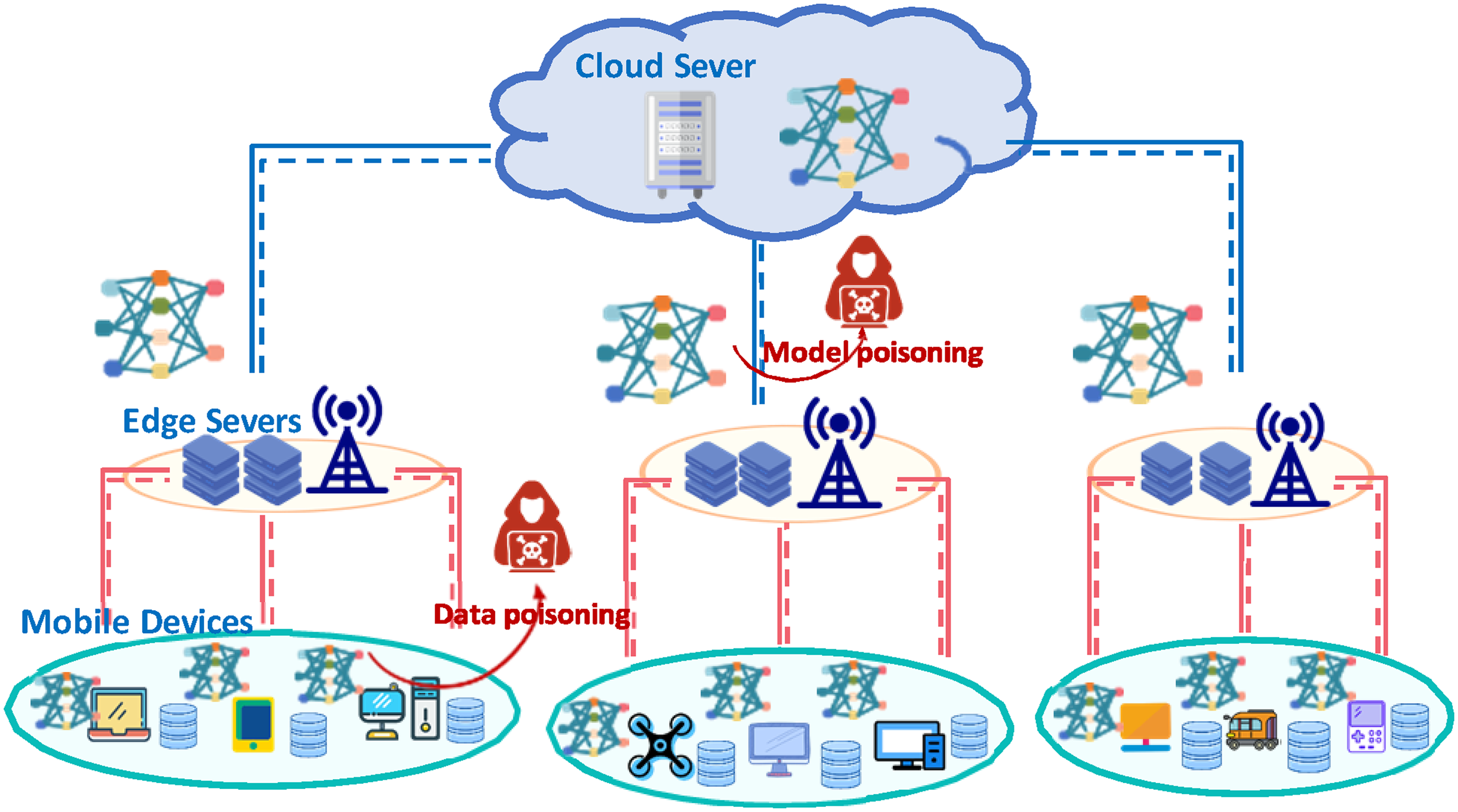
HFL modeling framework.
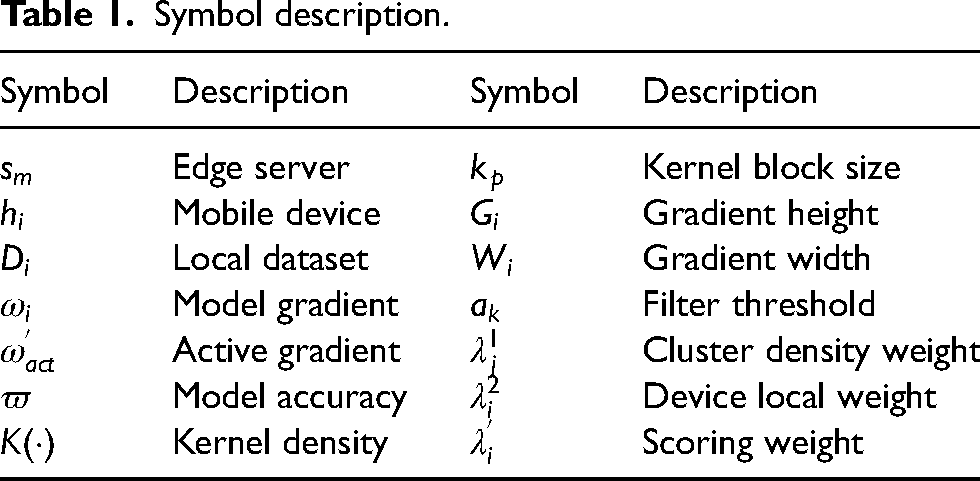
Symbol description.
This work considers a layered FL framework for cloud-edge-end collaboration that contains a central cloud server, M edge servers
Robust hierarchical federated learning with dual-layer filtering mechanism
When applying HFL to practical distributed computing environments, the system faces issues of malicious tampering or illegal attacks on device data during training and communication. 28 Attackers can inject new malicious clients or manipulate existing clean clients to generate poisoned local training updates, affecting the model’s training outcome. During local training, attackers may inject incorrect labels or misleading features into real local data, distorting the model’s understanding and learning process, which leads to inaccurate predictions. Additionally, attackers may modify or replace gradients during transmission or processing, altering the model’s update direction or causing the model to converge to incorrect local optima, resulting in a deviation from the correct parameter updates and reducing model performance and accuracy.29,30
While HFL can mitigate the impact of illegal attacks by applying data filtering and gradient validation at different levels, there remain threats from multi-level, multi-node, and multi-type poisoning attacks, such as data poisoning on end devices or model poisoning at the edge server. To minimize poisoning attacks and the security risks of hierarchical propagation in HFL, ensuring the security and trustworthiness of the training process and the reliability of the final global model, we propose a robust HFL framework with a dual-filtering mechanism. This mechanism employs an anomaly detection approach based on distance and density, jointly evaluating the security level of training clients from both data distribution and gradient perspectives, as shown in Figure 2.
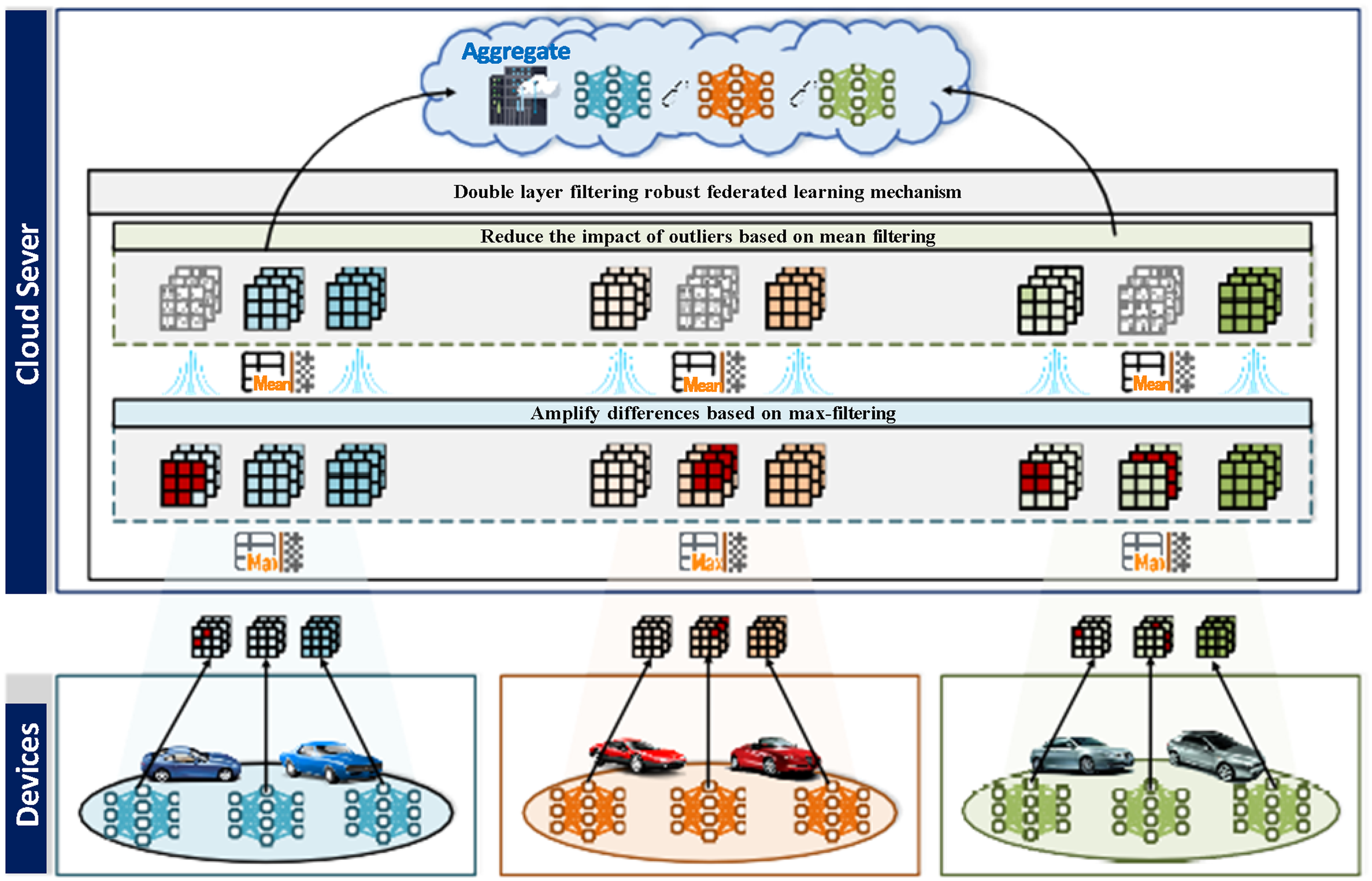
Robust hierarchical federated learning method process for dual-layer filtering mechanisms.
The specific training process of this scheme includes: (a) uploading the local client training model to the base station and estimating the data distribution of all participating clients using kernel density estimation; (b) grouping the participating local MDs using K-means clustering based on the obtained data distribution to ensure that the data in each cluster has the maximum similarity; (c) assigning cluster weights based on the cluster density, and also computing the global distribution; (d) use the KL scatter of each MD distribution and the global distribution as the scoring value, which is assigned as the local weight of the MD; (e) add the local weight of the MD with the weight of the cluster in which it is located and normalize it to get the final scoring weight; (f) amplify the gradient features from the perspective of spatial features of the gradient based on the maximal filter (which makes the distance between abnormal data and normal data become larger), and solve for the MD parameters and the global model parameters, multiply the difference value with the MD scoring weights, and select the MD with the smallest distance to be aggregated; (g) filter the model parameters to be aggregated by mean value filtering to enhance the robustness of the gradient. This two-layer filtering mechanism based on filtering can make appropriate filtering decisions to defend against multiple types of poisoning attacks according to the poisoning of different training levels, ensuring the security and accuracy of the global model.
Grouping of MD under Kernel density estimation
Based on the privacy and security properties of federated learning, ES is unable to obtain the real dataset distribution of local clients. Therefore, in order to obtain the data distribution of local clients while avoiding exposing sensitive data directly to an insecure network environment, we analyze the uploaded gradient data at the edge server side to obtain the predicted data distribution. Although the defender does not have access to the true statistical distribution of the participants
Therefore, we design a density measurement component to complement the conventional distance-based mechanism. Taking advantage of the property that malicious gradients tend to be sparsely distributed while benign gradients are denser, the density of the neighborhood around each data (both data distribution and gradient) is evaluated, where the neighborhood is defined as the set of
We consider the case where the defender is unaware of the number of malicious participants present in the HFL system and define the neighbor domain of each participant as
In the process of kernel density estimation of the gradient parameters, we define the set of 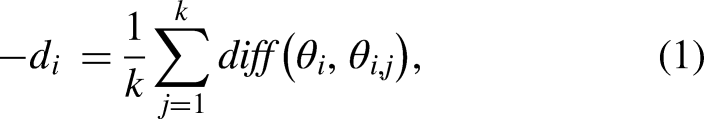

For each participant 
In this context, 
DF-HFL, in the first layer of filtering, approaches from the data dimension by obtaining the estimated client data distribution based on the uploaded gradient updates. It then calculates the KL divergence between different data distributions to identify malicious clients under attack, ensuring the security and reliability of the training process.
In data poisoning attacks, malicious attackers may intentionally tamper with their local data or inject false data to degrade the global model’s performance. When data is poisoned, originally similar distributions may become dissimilar, resulting in non-independent and identically distributed (non-IID) data. DF-HFL groups the participating MDs according to the heterogeneity of the data distributions, making it easier to identify when user data is subject to poisoning attacks.
At the initialization stage of the group training, we first consider all devices under each ES as a whole. Then, DF-HFL iteratively assigns data points to 
Then update the cluster center after every MD assignment: for the centroid of the
For the divided clusters, calculate the weight of each cluster:
Distance and density-based filtering mechanism
In the training process, selecting benign participants and eliminating malicious ones requires a suitable scoring mechanism. Traditional distance-based scoring mechanisms require the data distributions of participating MDs to remain uniform, and the datasets affected by malicious attacks should exhibit significant differences from benign datasets. As noted in the literature, 31 under conditions of independent and identically distributed (IID) data, the data distribution learned by a local model subjected to data poisoning attacks no longer aligns with the original IID data, resulting in non-independent and identically distributed (non-IID) scenarios. However, this is not always the case; in current practical environments, most clients have non-IID data distributions. In such cases, distance-based detection mechanisms may struggle to effectively identify malicious updates. Meanwhile, density-based detection mechanisms are another mainstream approach for anomaly detection. This method can group participating training clients through clustering to identify abnormal updates. When handling data, regions with lower density are typically considered noise or local anomalies, but sometimes these noise points may be incorrectly classified as global anomalies.32,33 Additionally, in cases where local density varies significantly within the dataset, this method might mistakenly label regions with lower local density—though not anomalous on a global scale—as anomalies, thus affecting the final training results. Therefore, how to jointly apply both distance-based and density-based anomaly detection mechanisms is crucial for accurately identifying malicious participants. 34
We adopt a combined distance and density approach as the data security filtering method in the DF-HFL framework, relying on measuring pairwise distances and density differences between local updates to identify and discard malicious updates. Each ES discards updates that fall outside a specified range, thereby mitigating the impact of malicious data. The specific solution process is shown in Algorithm 1.
1:
2: Upload gradient updates to ES after device local training
3: Let ES approximate the original data distribution based on the gradient through Equation (2)
4: The K-means clustering algorithm was utilized to classify the MD into different clusters through Equation (4)
5: Calculate cluster weights for each cluster
6: Differences between different MDs in each cluster were calculated and anomaly scored using KL scatter through Equation (6)
7: Calculate the local weight of the MD
8: Filter Amplifier Amplifies Normal Update and Abnormal Update Distance
9: Select the top ak MD aggregations of the anomaly score
10: Mean value filtering reduces the impact on normal data after removing anomalous data
11:
In general, if a participant is subjected to common data poisoning attacks, such as label flipping or malicious data injection, the participant’s data distribution may change, and its KL divergence could increase. KL divergence is a metric that measures the difference between two probability distributions, essentially quantifying the information loss or error introduced when one distribution is used to approximate another. When data distribution changes, the dependencies between variables may increase, causing the KL divergence to grow. The changes introduced by poisoning attacks are malicious and may cause the model to perform worse on affected participants. Therefore, we use KL divergence as a metric to evaluate the distance between participants in order to address attacks at the data poisoning level.
We consider two random variables: local data distribution 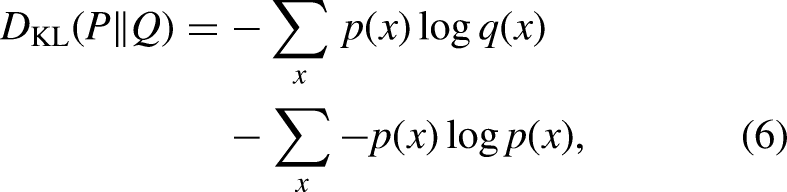
By calculating the KL divergence between data distributions, we can identify data points that may differ from others due to malicious attacks, data poisoning, or other abnormal situations. This allows us to promptly detect non-independent and identically distributed (non-IID) data, helping to identify potential malicious or anomalous data, thus improving the model’s robustness and security.
According to the KL divergence, the local weight distribution of MD is calculated:
Add the local weight of MD to the cluster weight of its cluster to get the final score weight:
Abnormal detection based on dual-layer filtering
DF-HFL uses a two-layer filtering mechanism to identify abnormal updates and reduce the impact of such updates on the original gradients. The first layer employs a maximum filter amplifier to identify active gradients and amplify the difference between abnormal and normal gradients, helping to detect abnormal updates. The second layer applies mean filtering to smooth the filtered gradients, further reducing the impact of noise and other malicious attacks on the gradients, ensuring that gradient updates are more continuous, and making the model updates smoother and more consistent, as shown in Figure 3.

Abnormal filtering based on dual-layer filtering.
Filter amplifier
The heterogeneous nature of data distribution may cause the uploaded gradient directions to become disordered, making it difficult to filter out abnormal gradients. In DF-HFL, the local updates uploaded by clients are collected at the ES, consisting of gradient updates from each participant’s local model training. These updates may contain both benign gradients and traces of malicious gradients. DF-HFL uploads the aggregated gradients from the ES to the CS, where maximum filtering is applied to the uploaded gradient updates to identify the most active feature gradients. Cosine similarity between the active gradients and all received gradients is used to filter out abnormal gradients, ensuring that the model training remains on the correct trajectory.
Upon receiving the updated gradients 

By combining active feature extraction with maximum filtering, this method enhances the model’s sensitivity to gradients. Thus, it improves the model’s ability to detect and resist malicious attacks, ensuring its safety and stability.
For each gradient vector in the amplified gradient set, the cosine similarity with other gradient vectors is calculated, and a threshold is set to determine whether the gradient vectors are abnormal. For those gradient vectors with cosine similarity below the threshold, they are regarded as abnormal gradients and filtered out. The abnormal gradients are also removed from the gradient set. The cosine similarity between the gradient vector 
Through this hierarchical filtering mechanism, abnormal MD data distributions and gradient updates can be filtered out layer by layer, preventing malicious attackers from providing false data or tampering with real data and gradients, which could affect the accuracy of model training. This ensures the safety and accuracy of the global model.
To find the difference between the MD gradient updates and the global model gradient updates, the difference value is multiplied by the MD’s scoring weight:
Mean filter
DF-HFL uses mean filtering to average multiple gradient data points to smooth the gradient data of MD, so as to effectively suppress the influence of noise or outliers. Although DF-HFL identifies abnormal updates through the first layer, so that the gradient abnormality of a certain MD is weakened in the first layer of mean filtering, there may still be some residual abnormal influence. Therefore, DF-HFL can eliminate this long-tail effect through further smoothing in the second layer, ensure more stable gradient updates, and reduce the excessive impact of a single client upload.
The original gradient of MD is represented as a matrix, and DF-HFL defines a convolution kernel sliding filter window to perform a sliding mean filtering operation from left to right and from top to bottom on the original gradient tensor
The computational burden of DF-HFL mainly exists in the two-layer filtering mechanism. The first is the maximum filtering mechanism, which requires dividing the gradient of each MD into blocks, taking the maximum value and reconstructing the gradient. The computational complexity is
Performance analysis
This section introduces the experimental results of the proposed method. First, we introduce the simulation environment and hyperparameter settings of the DF-HFL anomaly recognition algorithm. Secondly, we verify the recognition performance of the DF-HFL method for malicious updates during FL training by increasing the attack ratio and attack intensity and comparing the performance with other baseline algorithms.
Simulation settings
The performance of the experimental platform used in this study is as follows: Intel(R) Xeon(R) Gold 6330 CPU @ 2.00 GHz, with a base processor frequency of 2.00 GHz and memory of 32
Dataset and parameter settings: To verify the resilience of DF-HFL against different attacks, we conducted experiments on the following three datasets:
MNIST
35
: This dataset contains approximately 70,000 handwritten digit image samples, with 60,000 images used for training and 10,000 for testing. All images are grayscale with a size of 28 Fashion-MNIST(FMNIST)
36
: This dataset contains grayscale images of various clothing and accessory items, totaling 10 categories. Each category has 6,000 images, with a total of 60,000 training images and 10,000 test images. Each image is sized at 28x28 pixels, with grayscale levels ranging from 0 to 255. Heart Disease
37
: This dataset is a classic medical dataset that is often used in machine learning and statistical modeling research to predict the presence or risk of heart disease. Bank Market
38
: This dataset is used to predict customer responses in bank marketing activities. Specifically, the dataset records the bank’s interactions with customers during telephone marketing.
Potential attacks and comparison methods: This article evaluates the detection performance of DF-HFL against malicious attacks during model training from five aspects: the selection of aggregation threshold parameters, the convergence performance of DF-HFL under different malicious attack ranges, ablation experiments on the effectiveness of each module in DF-HFL, comparisons of the time required for each training round across different methods, and computational overhead, as well as the global model accuracy under varying malicious attack ranges and intensities.
We employed Gaussian noise attacks, which can lead to misjudgments in anomaly detection models, incorrectly identifying normal data as anomalous or failing to correctly detect actual anomalous data. We varied the variance of the Gaussian noise, which represents the intensity of the attack. To validate the adaptive real-time resistance capability of DF-HFL against attacks of varying intensities during training, we defined the intensities of malicious attacks as 0.3, 0.4, and 0.5. Here, higher values indicate stronger attack intensities.
We compared DF-HFL with the following four methods:
FedAvg
39
: This method averages all received local updates at the cloud server without performing any malicious gradient detection operations. Random
39
: In this method, for the gradient updates received by the cloud server, a random selection of updates is made for aggregation in each round, with a new random selection in every round. Krum
10
: This method filters out anomalous models by calculating the differences between the model updates provided by each participant and the other model updates using Euclidean distance. Multi-Krum
40
: A robust aggregation algorithm for aggregating client gradients. It calculates the distance between the gradient update uploaded by each client and the gradient updates of other clients based on the Euclidean distance, and selects the client with the closest distance to aggregate.
Simulation results
In this section, we evaluate the performance of DF-HFL and four other methods in resisting malicious attacks during HFL training.
Threshold parameter selection
DF-HFL selects the top
Global model accuracy for different aggregation thresholds.

Global model convergence of DF-HFL
We first verify the convergence performance of DF-HFL on four datasets, MNIST, FMNIST, Heart Disease, and Bank Market. In order to verify the ability of DF-HFL to withstand different levels of attacks, we fix the attack range as 10%, 20%, 30%, and 40%, and the attack intensity as 0.3, 0.4, and 0.5. The percentage of the attack range denotes the ratio of the MDs that have been maliciously attacked to those that have participated in the training of the HFL model during the training process. Meanwhile, the attack intensity denotes the variance of Gaussian noise attack as 0.3, 0.4, and 0.5. We plot the convergence results of DF-HFL in Figure 4. DF-HFL can maintain convergence on both datasets. Meanwhile, under the MNIST dataset, DF-HFL can maintain convergence with 40 rounds of iterations when the attack intensity is 0.3. When the attack intensity is 0.1, and the attack range is 10% to 40%, the DF-HFL can be maintained at a lower level after 50 rounds of iterations, and the DF-HFL fluctuates when the attack intensity is 0.5, and the attack range is 40%, but it always stays at a lower level. It can be seen that DF-HFL can always reach convergence with fewer training rounds for different strengths and different ranges of malicious attacks.

Convergence of DF-HFL under different attack intensities. (a) MNIST-0.3 attack intensity; (b) MNIST-0.4 attack intensity; (c) MNIST-0.5 attack intensity; (d) FMNIST-0.3 attack intensity; (e) FMNIST-0.4 attack intensity; (f) FMNIST-0.5 attack intensity; (g) Heart Disease-0.3 attack intensity; (h) Heart Disease-0.4 attack intensity; (i) Heart Disease-0.5 attack intensity; (j) Bank Market-0.3 attack intensity; (k) Bank Market-0.4 attack intensity; (l) Bank Market-0.5 attack intensity.
Accuracy of global models with different malicious attack range
We verified the resistance of DF-HFL compared to FedAvg, Krum, Random, and Multi-Krum under different ranges of malicious attacks on the datasets MNIST, FMNIST, Heart Disease, and Bank Market. We fixed the attack intensity to 0.3, respectively, and compared the global model accuracy change curves for 300 rounds of iterative training with different methods under 10%, 20%, 30%, and 40% attack ranges. According to the experimental results in Figure 5, on the one hand, under the MNIST dataset, when the attack range is small, the global models of DF-HFL, FedAvg, and Random can quickly converge to a high accuracy. The accuracy of the global models of FedAvg and DF-HFL with 12 rounds of iterative training can be maintained at around 0.95, Random needs 65 rounds of iterative training to maintain convergence, and Multi-Krum needs 95 rounds of iterative training to maintain convergence, but Krum needs 280 rounds of iterative training to converge to lower accuracy. On the other hand, when the attack range is increased to 40%, DF-HFL can still converge to a higher accuracy with fewer iterations, and the final accuracy of its global model is higher than that of the other methods. Although Random can converge, its accuracy is lower, as is that of Krum. This is because DF-HFL scores the MDs involved in training abnormally jointly based on distance and density methods and amplifies the distance between normal and malicious updates through a dual-layer filtering mechanism, which helps to better identify abnormal updates and ensures the accuracy of the global model.

Accuracy of DF-HFL under different attack range. (a) MNIST-10% attack range; (b) MNIST-20% attack range; (c) MNIST-30% attack range; (d) MNIST-40% attack range; (e) FMNIST-10% attack range; (f) FMNIST-20% attack range; (g) FMNIST-30% attack range; (h) FMNIST-40% attack range; (i) Heart Disease-10% attack range; (j) Heart Disease-20% attack range; (k) Heart Disease-30% attack range; (l) Heart Disease-40% attack range; (m) Bank Market-10% attack range; (n) Bank Market-20% attack range; (o) Bank Market-30% attack range; (p) Bank Market-40% attack range.
Comparison of global model accuracy under different attack ranges and attack intensities
In order to verify the ability of DF-HFL to resist malicious attacks under different attack ranges and attack strengths, we fixed the attack strengths to 0.3, 0.4, and 0.5, and fixed the attack ranges to 10%, 20%, 30%, and 40% on the datasets MNIST, FMNIST, Heart Disease, and Bank Market, and compared the global model accuracy of DF-HFL with FedAvg, Krum, Random and Multi-Krum after 300 rounds of iterative training. According to the experimental results in Figure 6, under the Mnist dataset, when the attack intensity is 0.3, the global model accuracies after 300 rounds of training can reach more than 0.9 for all methods except Krum, but as the attack intensity increases, the global model accuracies of the other methods are lower than that of DF-HFL, for example, at an attack intensity of 0.3 and an attack range of 40%, the DF-HFL s global model accuracy is 5.63%, 16.46%, 23.32%, and 8.59% higher than the other four methods, respectively. In summary, DF-HFL calculates the data of the MDs involved in training, the anomaly scores of the gradient updates from multiple perspectives, and amplifies the gap between the anomaly updates and the normal updates through the dual-layer filtering mechanism while reducing the impact of the removed anomalies on the correct data, so that it can maximize the retention of the effective training information and improve the accuracy of the global model while identifying the malicious attacks.
Accuracy under different attack ranges and attack intensities. (a) MNIST-0.3 attack intensity; (b) MNIST-0.4 attack intensity; (c) MNIST-0.5 attack intensity; (d) FMNIST-0.3 attack intensity; (e) FMNIST-0.4 attack intensity; (f) FMNIST-0.5 attack intensity; (g) Heart Disease-0.3 attack intensity; (h) Heart Disease-0.4 attack intensity; (i) Heart Disease-0.5 attack intensity; (j) Bank Market-0.3 attack intensity; (k) Bank Market-0.4 attack intensity; (l) Bank Market-0.5 attack intensity.
Computational overhead
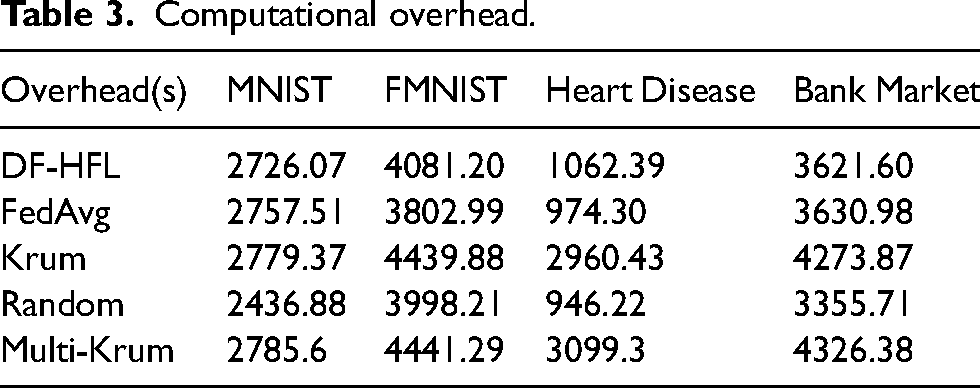
We compared the computational overhead of DF-HFL with FedAvg, Krum, Random, and Multi-Krum on the datasets MNIST, FMNIST, Heart Disease, and Bank Market for 300 epochs. We set the attack range to 10% and the attack intensities to 0.3. According to the experimental results in Table 3, the computational overhead of DF-HFL for 300 epochs is slightly higher than that of FedAvg and Random because it needs to perform a double-layer filtering anomaly detection mechanism to identify anomalies, while FedAvg directly trains all data samples and aggregates all updates without doing any anomaly detection. Random minimizes the computational overhead by selecting only one update to aggregate in each round. However, through the above experiments, the accuracy of FedAvg and Random is much lower than that of DF-HFL. Therefore, DF-HFL only needs a little more computational overhead to obtain a global model with much higher accuracy than other methods.
Computational overhead.
Conclusions
In this article, we study the anomaly filtering problem under the HFL framework, which aims to avoid operations such as malicious attackers providing false data or tampering with normal gradient updates to degrade the accuracy of the global model by identifying illegal attacks during model training and transmission. Therefore, we propose a robust hierarchical federated learning method with a two-layer filtering mechanism, which gets rid of the limitations imposed by the original method of identifying malicious attacks by using only the distance or density gaps in the data distributions or gradient updates, and approximates the data distributions by the updated gradients through a kernel density estimation method, and classifies the devices with similar distributions into the same cluster. A two-layer filtering mechanism is used to identify malicious updates while reducing the impact of malicious data on the normal gradient. In this process the distance between malicious updates and normal updates using maximum filtering method strips the malicious updates from the overall trend of the gradient. Mean value filtering is also used to make the filtered model updates smoother and more continuous, to enhance the robustness of the gradient and to guarantee the balance between model performance and privacy protection.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the Joint Key Project of National Natural Science Foundation of China under Grant U2468205, in part by the Researchers Supporting Project number (RSPD2025R681) at King Saud University, Riyadh, Saudi Arabia, in part by the National Natural Science Foundation of China under Grant 62202156, Grant 62472168, Grant 62473146 and Grant 62072056; in part by the Hunan Provincial Key Research and Development Program under Grant 2023GK2001 and Grant 2024AQ2028; in part by the Hunan Provincial Natural Science Foundation of China under Grant 2024JJ6220; in part by the Key Project of Natural Science Foundation of Hunan Province under Grant 2024JJ3017; and in part by the Research Foundation of Education Bureau of Hunan Province under Grant 23B0487.
Data availability statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.