
Abstract
As more and more sensor data have been collected, automated detection, and diagnosis systems are urgently needed to lessen the increasing monitoring burden and reduce the risk of system faults. A plethora of researches have been done on anomaly detection, event detection, anomaly diagnosis respectively. However, none of current approaches can explore all these respects in one unified framework. In this work, a Multi-Task Learning based Encoder-Decoder (MTLED) which can simultaneously detect anomalies, diagnose anomalies, and detect events is proposed. In MTLED, feature matrix is introduced so that features are extracted for each time point and point-wise anomaly detection can be realized in an end-to-end way. Anomaly diagnosis and event detection share the same feature matrix with anomaly detection in the multi-task learning framework and also provide important information for system monitoring. To train such a comprehensive detection and diagnosis system, a large-scale multivariate time series dataset which contains anomalies of multiple types is generated with simulation tools. Extensive experiments on the synthetic dataset verify the effectiveness of MTLED and its multi-task learning framework, and the evaluation on a real-world dataset demonstrates that MTLED can be used in other application scenarios through transfer learning.
Introduction
Nowadays, diverse sensor data are increasingly collected and monitored in various real world applications, including spacecraft monitoring systems, 1 medical diagnosis systems, 2 protection of industrial assets, 3 and etc. Most of these sensor data are in the form of time series and it is of great value to detect and diagnose potential threats in time series data to maintain the security and stability of various systems.
To monitor multi-sensor systems and give early warnings for operators, increasing approaches of anomaly detection, 4 anomaly diagnosis, 5 and event detection 6 are proposed from different perspectives. Anomalies are represented by unusual or abnormal patterns in the data, which can be seen as the omen of faults. Some fault-related events which show no abnormal signs are also of interest to operators and important for system monitoring and fault prevention. 7 When the behavior of a dynamic phenomenon changes enough over time so as to be considered a qualitatively significant change, such a change is called an event. 8 Obviously, an event is not necessarily an anomaly, and vice versa.
Anomaly detection approaches can be roughly divided into unsupervised ones and supervised ones. Unsupervised anomaly detection methods1,9–11 only use “normal” training samples to capture and model the normal behavior of a system. The learned model can be used to predict 1 or reconstruct9–11 the input values or transformed features. When test data exhibit an unusual pattern, the prediction errors between the actual values and the predicted values are far larger than those of normal data, which indicates a potential anomaly. These unsupervised anomaly detection methods can theoretically detect all types of anomalies and be used in various applications without much domain priors, but they cannot provide detailed descriptions of detected anomalies since such information is not provided in the training phase. Besides that, such error-based approaches tend to find merely parts of anomaly sequences where they are most unpredictable, and thus they are also sensitive to noise data. Supervised anomaly detection approaches2,12 use labeled samples for training and they are more robust and superior in accuracy when the quality and quantity of the training samples are guaranteed.13,14 Besides that, they can provide additional information about the detected anomalies. However, in many real scenarios, it is difficult to obtain sufficient abnormal data for training, especially labeled ones. Moreover, these supervised anomaly detection approaches can hardly detect anomalies of unknown types.
Anomaly diagnosis aims to provide diagnosis information for operators to respond to the detected anomalies quickly. The research on anomaly diagnosis is often accompanied with that of anomaly detection, but not vice versa. In fact, most unsupervised anomaly detection approaches and systems only detect anomalies and leave the detected anomalies to additional diagnosis approaches or experts, 15 which may delay the respond to the anomalies. Only a few unsupervised algorithms9,10 consider anomaly detection and diagnosis in one framework. Most of the existing supervised anomaly detection approaches2,16 use classification models to classify the abnormal data into known anomalous classes. The obtained class labels represent the results of both anomaly detection and anomaly diagnosis. Current works regarding to anomaly diagnosis mainly pinpoint the anomalous components or classify the anomalies into known types, but more description information about the detected anomalies are not considered.
Event detection is widely used in various scenarios with different purposes, including multi-sensor system monitoring. 7 Event detection approaches can also be divided into unsupervised ones and supervised ones. Unsupervised event detection 17 can be used to detect usual patterns or anomaly events, while supervised event detection 18 is mainly used to recognize fault-related events of known types. To the best of our knowledge, there is no work in which both anomalies and known fault-related events are considered for system monitoring or fault prevention.
To mitigate and balance the issues mentioned above, a novel scheme which can detect anomaly, diagnose anomalies and detect events simultaneously is presented. In this scheme, a Multi-Task Learning based Encoder-Decoder (MTLED) is proposed for anomaly detection, anomaly diagnosis and event detection. Multi-task learning 19 aims at learning multiple related but different tasks. A large-scale Multivariate Time Series Dataset which contains Anomalies of Multiple Types (MTSD_AMT) is generated so that the proposed MTLED model can be trained with abundant annotated data. The proposed MTLED realizes the following three tasks in parallel and all of them can be implemented in real time due to its end-to-end architecture.
Anomaly detection: to accurately detect abnormal parts in multivariate time series data.
Anomaly diagnosis: to diagnose the anomalies and describe their abnormal information, including the types of anomalies, the severity of anomalies, the state of whether the anomalies end or not, and which channels are related to the occurrence of anomalies. This can help the system operators locate and handle incidences quickly. When the number of sensors in monitoring systems is large, this function is particularly helpful.
Event detection: to detect some events which are related to known fault patterns, such as a sequence of sensor readings have exceeded a preset threshold for a long duration, or the average value of a sensor reading during a period is lower than a certain value. Such events are often used as important criteria for fault forecast and diagnosis, and thus also very important for system monitoring.
In MTLED, input data are fed in sliding windows and corresponding outputs are generated to achieve the above-mentioned functions in real time. MTLED is mainly composed of a task-shared encoder and several parallel decoders. The encoder is mainly composed of a convolutional neural network (CNN) and a Long Short-Term Memory networks (LSTM) module. The biggest difference between MTLED and traditional encoder-decoders 20 is that the feature extracted by the encoder retains the time dimension. Therefore, after encoding, a feature matrix is obtained rather than a feature vector. The main purpose of this design is to make the decoder of anomaly detection utilize the time dimension to achieve point-wise anomaly detection in an end-to end way. In order to realize all the above tasks, a total of five decoders are designed. The first decoder is mainly an LSTM model, which is used for point-wise anomaly detection; the second decoder is a classification model, which classifies the type and severity of anomalies; the third decoder is used to discriminate whether anomalies end in the current sliding window; the fourth decoder is used to detect which channels are related to the occurrence of anomalies and the fifth decoder is used to detect events.
The main contributions of this study are as follows. Firstly, the shortcomings of the existing early warning methods related to system monitoring are pointed out and analyzed systematically. Secondly, a novel schema which can detect anomalies, diagnose anomalies, and detect event simultaneously is proposed based on multi-task learning. Thirdly, in the proposed model, feature matrix is introduced into the encoder-decoder so that point-wise anomaly detection can be realized with an end-to-end deep learning model. Finally, we make public a large multivariate time series dataset which contains anomalies of multiple types, and experiments on the synthetic dataset and a real dataset demonstrate the effectiveness and generalizability of MTLED.
The rest of the paper is organized as follows. Section 2 presents the most relevant previous work. Section 3 introduces the preliminary works of MTLED and describes the architecture of MTLED as well as its training method. The experimental evaluation and discussions are articulated in Section 4. Conclusions and future directions of our work are given in Section 5.
Related work
The proposed MTLED aims to address the problems of anomaly detection, anomaly diagnosis, and event detection in a harmonized framework for fault prevention. In this section, the most related works regarding to these three parts are analyzed one by one.
Anomaly detection
Most of the unsupervised anomaly detection methods1,9–11 can detect anomalies at the granularity of time points. These point-wise anomaly detection methods usually take two main steps to detect anomalies. Firstly, the anomaly scores are calculated based on the prediction errors between the actual values and the predicted values for each time point. Then, a global threshold9–11 or a dynamic threshold 1 is selected for anomaly scores to detect anomalies. A global threshold is usually learned with validation set which contains some labeled anomalous samples. Dynamic thresholds are set according to statistics in an unsupervised way. Both global thresholds and dynamic thresholds need to be determined by trial and error and cannot guarantee that the best threshold is selected. Different from these methods, the two-stage framework is replaced by an end to end deep learning model in MTLED, which can directly output point-wise results of anomaly detection. For this purpose, each point in sliding windows is classified into “normal” or “abnormal” class by feeding the point-wise features into a decoder whose main component is an LSTM model.
Supervised anomaly detection approaches usually extract features from time series and then classify the normal and abnormal class using feature vectors. A dual channel LSTM model is proposed by Zhao et al. 2 to combine two types of features extracted from time data and force data for classification. Kim and Cho 12 proposed a C-LSTM neural network which combines a CNN and RNN for automatic feature extraction and anomaly detection, where the output of this CNN layer is used as the input for several LSTM layers to reduce temporal variations. MALSTM-FCN combines FCN (fully convolutional network) and RNN features in a another way. 21 Specifically, the state-of-the-art FCN module 22 and LSTM module extract features in parallel and then the concatenated feature vector is passed onto a softmax layer for classification. The feature extraction part of MALSTM-FCN is similar to that of MTLED in that both of them concatenate the features from two parallel feature extraction modules. All the above supervised anomaly detection algorithms extract features and classify at the granularity of sliding windows. Thus, they can only detect anomalies at the granularity of sliding windows. In MTLED, features matrix is extracted without the loss of time dimension so that point-wise anomaly detection can be realized in a supervised learning framework. Besides that, the multi-task learning framework in MTLED can theoretically improve the ability of feature extraction and the performance of each task.
Anomaly diagnosis
Anomaly Diagnosis are divided into two subcategories: unsupervised approaches and supervised approaches. Most unsupervised anomaly detection approaches and systems are proposed to detect potential anomalies and leave the detected anomalies to experts, operators, or additional diagnosis tools. 15 To reduce the response time, several unsupervised algorithms which consider anomaly detection and diagnosis in one framework are proposed. The anomaly diagnosis part merely gives the interpretations of the root causes. 10 Zhang et al. 9 attempt to solve the anomaly detection and diagnosis using a multi-scale convolutional recurrent encoder-decoder. However, its anomaly diagnosis part just pinpoints the root causes according to top-k channels and simply assumes that the severity of an incident is proportional to the duration of an anomaly.
Most of the existing supervised anomaly detection approaches are mainly classification models which classify the abnormal data into known anomalous classes. The obtained class labels represent the results of both anomaly detection and anomaly diagnosis. Machine learning based classifiers are employed to detect and diagnose for cloud services, but only two types of known anomalies can be detected and diagnosed. 16 Three kinds of neurodegenerative disease classes and one normal class are classified using a dual channel LSTM model. 2 In our proposed model, more diagnosis information about the detected anomalies are provided by separate decoders, including the types of anomalies, the severity of anomalies, the state of whether the anomalies end or not, and which channels are related to the occurrence of anomalies. When anomalies occur, these diagnosis results can be obtained with anomaly detection results in the same time owing to the multi-task learning framework and this can greatly ease the burden of system operators.
Event detection
If the temperature of a boiler goes above a certain threshold, then it can be seen as an event. However, in some cases, the rule for determining whether sensor readings should generate an event is not that clear. Improvements in machine learning techniques, such as classification models, have accelerated the progress in event detection. For example, Batal et al. 23 focuses the search on temporal patterns that are potentially more useful for classification and use support vector machine as classifiers. An LSTM model is used for Polyphonic Sound Event Detection. 24 A sound event detection model which combines a convolutional bidirectional recurrent neural network with transfer learning is proposed. 25
In MTLED, event detection is accomplished by an FCN model whose input is the feature matrix shared by the task of anomaly detection and anomaly diagnosis. The feature matrix is trained on the data related to anomaly detection and anomaly diagnosis firstly, and shared as the input of the pre-trained model for event detection. Except the potential performance improvement, such a multi-task learning framework can theoretically alleviate the dependence on the amount of training samples for event detection.
MTLED
In this section, the preliminary works related to MTLED are introduced firstly. After that, the architecture of MTLED is presented. Finally, a three-stage training method for MTLED is described in detail.
Preliminary works
Temporal convolution
Temporal convolution
26
is effective in feature extraction for time series classification problems, and 1-D convolution is widely used to extract temporal features. Given the univariate input signal

where
As shown in Figure 1, the convolution result of input data is obtained by sliding convolution kernel with sliding stride

The illustration of 1-D convolution operation.
LSTM
With the rapid development of deep learning, Recurrent Neural Networks (RNN), especially Long Short-Term Memory networks (LSTM), have been widely used for many sequence learning tasks, including speech recognition, natural language processing, and anomaly detection of time series.27,28 Compared with traditional RNN, LSTM improves the long-term memory by introducing a weighted self-loop which allows LSTM to forget past information in addition to accumulating it. The computation at each time step can be formulated as follows:






where
Attention mechanism
In recent years, attention mechanism 29 has been widely used in various fields of deep learning, including computer vision, speech recognition, and natural language processing. Attention mechanism originates from the study of human vision, and draws lessons from human attention mechanism. Due to the bottleneck of information processing, human beings will selectively pay attention to some information according to their experience while ignoring other information. From the physical sense, attention mechanism can be understood as the similarity measurement between current input and historical information. From the mathematical formula, attention mechanism can be understood as the weighted sum of input data according to the historical state and the characteristics of current input data.
The temporal attention computes the attention weights based on the previous hidden state and represents the input information as a weighted sum of the encoder hidden states across all the time steps.
The weighted sum of each input

The weight,

Where the alignment model,
The architecture of MTLED
MTLED uses a shared encoder to obtain the feature matrix, based on which several task-related decoders are used to generate their own output, including results of anomaly detection, anomaly diagnosis and event detection. The MTLED network architecture is shown in Figure 2.

Network architecture of MTLED.
The overall framework of MTLED is a Multi-Task Learning based Encoder-Decoder. The encoder is mainly composed of a CNN and an LSTM module. Both modules extract features without losing the time dimension and their extracted features are concatenated along the time dimension. Then, a temporal attention mechanism is applied to select relevant features across all time steps and the feature matrix is obtained. In order to achieve all the above functions, five decoders are designed: one Decoder for Anomaly DEtection (Dec_ADE), three Decoders for Anomaly DIagnosis (Dec_ADI), which provide anomaly types, anomaly states and anomaly channels respectively, and one Decoder for Event Detection (Dec_ED). The details of the encoder and decoders in MTLED are discussed below.
Task-shared encoder
A CNN and an LSTM module are used in the encoder for feature extraction. The CNN module consists of three stacked convolutional blocks. Each convolutional block consists of a one-dimension convolutional layer, which is accompanied by batch normalization
30
followed by the ReLU activation function. The number of convolution kernels used for each convolutional layer are represented as

The illustration of dimensions change in the encoder.
As can be seen from Figure 3, both feature extraction modules retain the time dimension in the whole process, so that their features can be concatenated and still retain the features for each time point. This is the basis of the point-wise anomaly detection in our model.
Decoder for anomaly detection
Different from error-based anomaly detection methods which need to select thresholds for anomaly score sequences, MTLED classifies each time point into “normal” or “anomalous” class directly. All the anomalous time points are labeled 1, while all the other normal points are labeled 0. Dec_ADE is mainly an LSTM followed by a dropout to output the initial anomaly detection results. LSTM is chosen due to its memory and the continuity of the output in the time dimension to prevent a continuous anomaly sequence being split into too many segments.
To accelerate the training phase and regularize the anomaly detection results, the initial anomaly detection results are concatenated with the final outputs of the last sliding window as the auxiliary input, and a dense (fully connected) layer with “sigmoid” as activation function is used for the final anomaly detection result of the current window. Given that the input feature matric is

The detailed description of how to obtain
Decoder for anomaly diagnosis
All the three decoders for anomaly diagnosis (Dec_ADI) are classifiers. Since multiple anomaly types and anomaly channels are allowed in one sliding window, multi-label classifiers 32 are applied for anomaly type and anomaly channel. On the contrary, only one anomaly state is defined for each sliding window, and thus a multi-class classifier is more appropriate and adopted. These decoders share a similar structure, that is, a global average pooling (GAP) layer followed by a dense layer. The multi-label classifiers use “sigmoid” as activation function while the multi-class classifier uses “softmax” (see Figure 2).
The decoder for classifying anomaly types can recognize four typical anomaly types and detect other anomaly types. The typical anomaly types include “point,”“shift,”“trend,”“variance,” whose definitions are given in the next section. The severity of these typical anomaly types is classified into two groups “subtle” and “severe.” For example, a “severe point” anomaly deviate from their adjacent values more noticeably than a “subtle point” anomaly. All the other anomaly types except the four typical types are merged into one class to reinforce the generalization ability of the decoder so that anomalies of unknown types can also be detected. Thus, nine classes of anomaly types are considered and predicted by the decoder: subtle point, severe point, subtle shift, severe shift, subtle variance, severe variance, subtle trend, severe trend, and others.
Obviously, an on-going anomaly is more threatening than an ended one. The decoder for anomaly state analysis is used to distinguish whether anomalies end at the end of each sliding window. These two kinds of states, represented by 0 and 1, can be easily discriminated and important for system monitoring.
The decoder for pinpointing the root causes or the anomaly channels is used to locate the anomaly channels which are related to the anomaly parts in the current sliding window. Only the channels closely related to the anomalies are denoted as 1 while others are denoted as 0.
Decoder for event detection
Unlike anomalies, events related to corresponding known faults are usually defined according to different domains, thus the event detection part can hardly be shared across different applications. To make the event detection part have a wider application prospect, it is important to alleviate its dependence on labeled data for training. A decoder for event detection (Dec_ED) relying merely on a small amount of training samples is designed.
First of all, several data augmentation strategies for time series are used to increase the number of training samples. Secondly, the training of decoder makes use of the encoder pre-trained on the anomaly detection and diagnosis parts. Lastly, an FCN model whose input is the feature matric is used for further feature extraction and classification. The FCN consists of a convolutional block and a GAP layer followed by a sigmoid dense layer for classification (see Figure 2).
The training of MTLED
The training phase needs two training sets Tr1 and Tr2. Tr1 contains sufficient multivariate anomalous samples with anomaly annotation, and it is to train the sections of MTLED which are related to anomaly detection and anomaly diagnosis. Tr2 contains a few multivariate samples with event labels and is used to train the sections of MTLED which are related to event detection.
There are three stages in the whole training process of MTLED. In the first training stage, the encoder, Dec_ADI and Dec_ADE without the auxiliary input are trained, that is, the sections of Dec_ED and the auxiliary input in Dec_ADE are ignored in this stage. After that, the model
In the second stage, the initial predicted output obtained from Dec_ADE with
In the last stage, data augmentation is used for Tr2 to mitigate the problem of small sample size of training data for event detection. Some commonly use strategies, including cropping, jittering, and time warping, 33 are applied to generate Tr2′. The training of Dec_ED makes use of the encoder pre-trained on Dec_ADE and Dec_ADI by fine-tuning on Tr2′.
Since multi-task learning is applied in MTLED, the loss for each task is defined firstly. Among the five decoders we use, only the one for anomaly state is a multi-class classifier, while the other four are multi-label classifiers. For the multi-class classifier, a “categorical cross entropy” loss is defined as follows:
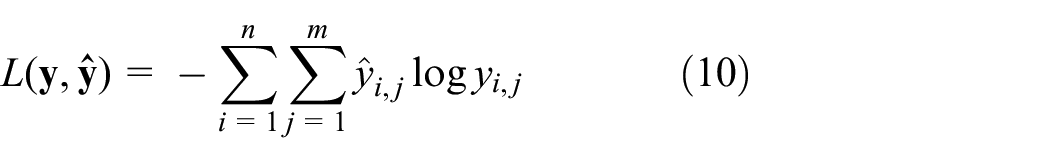
Where n is the number of training samples for the multi-class classifier, and m is the number of classes. For the multi-label classifiers, a “binary cross entropy” loss is defined as follows:

where o is the number of training samples for the multi-label classifiers, and p is the number of classes.
For simplicity, all the decoders are given the same weight. In the first two stages of training, the sum of loss for Dec_ADE and Dec_ADI is optimized, and the loss for Dec_ED is optimized in the last training stage. Mini-batch stochastic gradient descent together with the Adam optimizer 34 is used to minimize the loss function.
Experimental evaluation
MTLED needs to be trained in a supervised manner. To this end, the synthetic dataset MTSD_AMT which contains all kinds of annotation labels needed is introduced and MTLED is evaluated on MTSD_AMT. After that, MTLED is evaluated on a real-world dataset through transfer learning.
MTSD_AMT
To the best of our knowledge, there is no existing public dataset which contains enough annotated anomaly samples to enable a thorough empirical evaluation for the proposed MTLED. Thus, a large-scale multivariate time series dataset which contains anomalies of multiple types is generated with the help of the simulation tools (Agots-master 1 and DeepADoTS-master 2 ). These simulation tools take the correlation of variables into consideration and all the labels needed can be acquired easily without expert priors. In Agots-master, four typical sensor-level anomaly types are defined: “point,”“shift,”“variance,”“trend.” Point anomalies are single values that noticeably deviate from their adjacent values, shift anomalies are sequences that noticeably deviate from their surrounding sequences, variance anomalies are sequences that oscillates within a large range, and trend anomalies are sequences which show an obvious trend of ascending or descending. The severity of the generated anomalies can be controlled by the parameter in the simulation program. Besides that, other anomaly types such as the sinusoidal waves with white noises, and other harmonic signals are generated by DeepADoTS-master, and all the other anomalies except the above four typical types are labeled as “other” class.
Figure 5(a) shows an example of multivariate time series including a point anomaly (x4), a variance anomaly (x3) and another anomaly like a sinusoidal wave (x5). In Figure 5(b), an example of a trend anomaly (x2) and a shift anomaly (x1) is shown.

Some examples of the anomalies: (a) anomaly sample containing “point,”“variance,” and “other” anomalies and (b) anomaly sample containing “shift” and “trend” anomalies.
Each of the four typical anomalies is further classified into two classes according to its severity. Thus, in our annotation, a total of one normal class and nine classes of anomaly type labels are given: subtle point, severe point, subtle shift, severe shift, subtle variance, severe variance, subtle trend, severe trend, and others.
Two events are defined manually for the experiments regarding to event detection. Event 1 occurs when the minimal reading of second sensor in a duration (lasting more than 120 time points) exceeds the threshold 0.75. Event 2 occurs when the average value of third sensor in a duration (lasting more than 150 time points) is lower than −0.5. Only a few samples are provided for training the sections related to event detection to demonstrate that it is feasible to apply MTLED in various scenarios where abundant annotated data are not always available.
Table 1 describes the brief information of MTSD_AMT. MTSD_AMT is available on https://github.com/jlro001/MTSD_AMT.
The brief information of MTSD_AMT.

Experiment setup
The length of the input sequence equals to the size of the sliding window and is set as 200 provided a balance between performance and training time. The stride of the sliding window for training and test is set to 10. We set the batch size as 128 for training, and run for 200 epochs with early stopping and an initial learning rate of 0.001 which decays every 10 epochs. All the dropout rates in MTLED are set to 0.3. A magnitude scale is specified first and is used to normalize the input multivariable time series.
Point-wise evaluation metrics are used to compare MTLED with unsupervised anomaly detection methods. The number of true positives (TPp) are the number of predicted “anomalous” points which belong to “anomalous” sequences. The number of false positives (FPp) are the number of predicted “anomalous” points which do not belong to “anomalous” sequences. The number of false negatives (FNp) are the number of predicted “normal” points which belong to “anomalous” sequences.
For supervised anomaly detection methods which do not tell the exact part of anomalies, we take a sliding window as a sample. A true positive is recorded if a predicted “anomalous” sliding window contain any true labeled sequence, a false positive is recorded if a predicted “anomalous” sliding window contain no true labeled sequence, and a false negative represents a predicted “normal” sliding window which actually contains any true labeled sequence. The number of these true positives is denoted as TPS, the number of false negatives is denoted as FNS, and the number of false positives is denoted as FPS. The performance evaluation on anomaly diagnosis and event detection also takes each sliding window as a sample.
The metrics used for evaluation include the following:
Precision (P):
Recall (R):
F-measure (
F-measure considers Precision and Recall simultaneously without any bias, and it is used to evaluate the overall performance. Pp, Rp, and Fp represent the metrics used in the point-wise evaluation, while Ps, Rs, and Fs evaluate the performance with a sliding window as a basic unit. All the experiments in this work are repeated five times and the average results are reported for a fair comparison.
Evaluation on MTSD_AMT
The performances of anomaly detection, anomaly diagnosis, and event detection are evaluated on MTSD_AMT. After that, several variants of MTLED are compared to analyze the internal components of MTLED.
Anomaly detection result
To demonstrate the effectiveness of MTLED, we first compare it with several state-of-the-art unsupervised anomaly detection approaches. These baseline methods are listed as follows.
EncDec-AD 11 : An LSTM based encoder-decoder is used to reconstruct the input sequence, and the resulting reconstruction errors are modeled as a multivariate Gaussian distribution and is used to detect anomalies.
LSTM-NDT 1 : A stacked LSTM model is used to predict the future values using the current sequences, and the prediction errors are smoothed using exponential weighted moving average (EWMA), 35 based on which dynamic thresholds according to statistic information are selected to detect anomalies.
OmniAnomaly 10 : VAE and GRU (a variant of RNN) are integrated in a novel way such that the temporal dependence and stochasticity of time series can be explicitly modeled. The reconstruction probabilities and the threshold selected according to the principle of extreme value theory are used to detect anomalies.
All these unsupervised models are firstly trained on normal samples before the anomalies are injected in MTSD_AMT. LSTM-NDT and OmniAnomaly can determine thresholds without any positive samples, while EncDec-AD select the threshold based upon the training on anomaly samples.
As can be seen from Figure 6, MTLED outperforms all the baseline methods significantly when point-wise metric is applied for anomaly detection. Among the baseline methods, LSTM-NDT and OmniAnomaly get similar results. They have lower recall compared with EncDec-AD, and it is mainly because EncDec-AD can utilize the anomaly information in MTSD_AMT. We argue that these error-based methods tend to find just parts of anomaly sequences where they are most unpredictable, while MTLED can treat each point of the anomaly sequence equally. Besides that, error-based methods are relatively sensitive to noise data, which leads to more false positives. In general, the multi-task learning framework based model shows an obvious advantage over the methods which merely concentrate on anomaly detection.

Performance comparison of point-wise anomaly detection methods.
Supervised anomaly detection methods usually take each sliding window as a sample and use classification models for anomaly detection. As argued in Fawaz et al., 36 FCN achieved the best performance for time series classification among nine commonly used MTS classification methods. LSTM is the most successful variant of RNN, and is also widely used as a baseline in supervised MTS classification. 37 C-LSTM combines a CNN and RNN for automatic feature extraction and anomaly detection, 12 in which the output of this CNN layer is used as the input for several LSTM layers. Another state of the art MTS classification model, MALSTM-FCN, is proposed in Karim et al. 21 MALSTM-FCN concatenates feature vectors from a fully convolutional block and an LSTM block and uses a softmax layer for the final classification.
The above methods are compared with MTLED and their results are presented in Figure 7. Among all these methods, although MTLED achieves the highest precision, its overall performance (F) is still lower than MALSTM-FCN because of its lower recall. In general, MALSTM-FCN show a slight better performance than other methods including MTLED. This may attribute to the extra squeeze and excite block 38 used in MALSTM-FCN. Although MTLED did not achieve the best performance among the supervised methods, the performance difference between MTLED and MALSTM-FCN is very little. More importantly, MTLED can detect the exact part of anomalies, while these supervised methods can only classify sliding windows as “abnormal” or “normal.” The great improvement of MTLED on point-wise anomaly detection can overshadow its ordinary performance among these supervised methods.
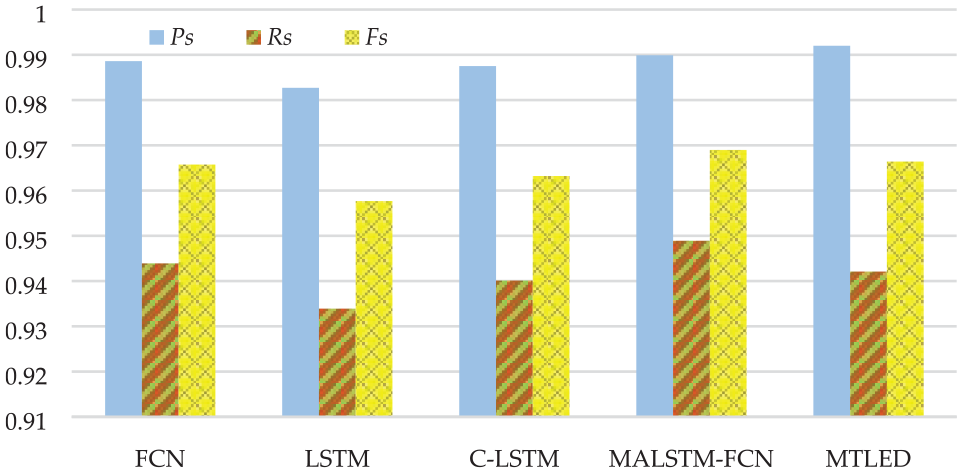
Performance comparison of supervised anomaly detection methods.
Anomaly diagnosis result
Three respects of anomaly diagnosis are included: anomaly type, anomaly state, and anomaly channel. Since all these diagnosis tasks are realized by classification models, the baseline models used for supervised anomaly detection comparison are also used for evaluating the performance of anomaly diagnosis. In the three diagnosis tasks, anomaly type classification is more challenging than the other two tasks because the severity of the anomalies is also considered in the anomaly type classification for the four typical anomalies.
Table 2 reports the performance comparison of each respect of anomaly diagnosis where the best scores are highlighted in bold-face. In terms of precision, different methods achieve the highest score on each task and no one is significantly better than others. MALSTM-FCN seems to show a slight advantage with respect to recall (
Anomaly diagnosis result of MTLED and other baseline approaches.

The best performance indicators are displayed in bold.
Event detection result
The event detection performance of MTLED and the state-of-the-art classification models are shown in Figure 8. For a fair comparison, data augment is used for all these methods.

Comparison results of event detection.
From Figure 8, we can easily find that all the methods show a similar result on precision, while MTLED shows a relatively significant improvement on recall than all the other methods, and thus obtaining a better F-measure. Different from other baseline methods, MTLED utilizes the model pre-trained on the tasks of anomaly detection and anomaly diagnosis, and this might be the main reason that MTLED shows a better performance on the task of event detection and validates the effectiveness of the multi-task learning framework in MTLED.
Internal analysis of MTLED
Feature matrix is important in our model because that is the basis of the point-wise anomaly detection in an end-to-end way. In this subsection, we mainly discuss the function of the auxiliary input in Dec_ADE, the temporal attention mechanism and the multi-task learning framework. We denote MTLED without auxiliary input as MTLED_aux, MTLED without attention layer as MTLED_att, and the model without auxiliary input and attention layer as MTLED_aux_att. The model which ignores the sections of other tasks other than anomaly detection is denoted as MTLED_MTL. For a fair comparison, all the other parts of each models except those mentioned above are exactly the same.
As shown in Figure 9, the best results in terms of all metrics are achieved by MTLED. In general, the overall performance of MTLED is improved when the attention layer, the auxiliary input, and multi-task learning are applied. More specifically, MTLED_aux_att performs the worst in terms of precision, and both MTLED_aux and MTLED_att have a lower precision than MTLED. It indicates that both the attention layer and the auxiliary input can improve the precision of MTLED. MTLED_MTL achieves the lowest recall, which demonstrates that other related tasks, such as anomaly diagnosis and event detection, contribute much to improve the recall of anomaly detection. This result further verifies the effectiveness of the multi-task learning framework in MTLED.

Performance comparison between variants of MTLED on anomaly detection.
Evaluation on space shuttle
To validate that MTLED can also be used for real scenarios, comparison experiments are also conducted on a real-world dataset. Space Shuttle contains the telemetry data about the Energize/De-Energize cycle of space shuttles. TEK 14 and TEK 17 are used in this experiment and both samples contain 5 periodic sequences with 1000 points per cycle. The train-test split is consistent with that of the work of others. 3 Only “normal” samples are included in the training set and the amount of training data is relatively limited. To solve the problem of class imbalance and data insufficient in the training set, only five training epochs are used to fine-tune the MTLED model pre-trained on MTSD_AMT to find a balance between precision and recall. The telemetry values about the normal part of the dataset have strong periodicity, but the anomalies are very different and the change of values is relatively subtle. Space Shuttle is more challenging than MTSD_AMT and is mainly used to further verify the effectiveness and generalizability of MTLED.
Since the number of channels in Space Shuttle is less than that of MTSD_AMT, zero padding is used to adjust the input data to the model pre-trained on MTSD_AMT. The dataset contains no ground-truth annotation about anomaly diagnosis or event detection, thus we merely report the anomaly detection performance of MTLED and other baseline methods. Because EncDec-AD provides no method for choosing anomaly score threshold when no anomaly sample is available for training, all possible anomaly score thresholds are enumerated to search for the best F-measure, which is presented in Figure 10.
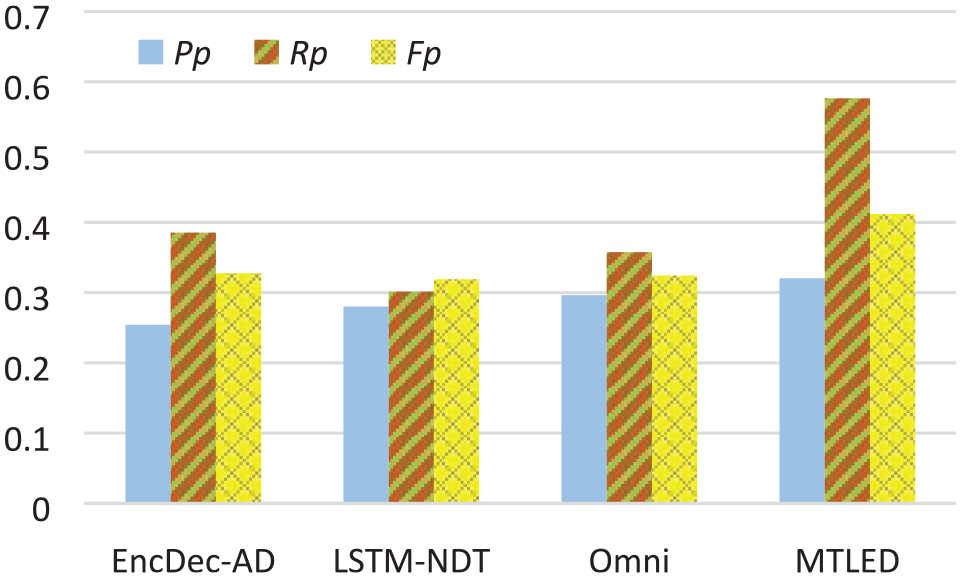
Comparison results of anomaly detection on Space Shuttle.
As can be seen from Figure 10, MTLED shows a significantly higher recall than all the other baseline methods, and thus obtain a better overall performance. Even the best F-measure of EncDec-AD is still lower than the F-measure of MTLED. This is reasonable in that it is much easier for MTLED to detect more parts of the anomalies than other baseline methods which confront the problem of decreasing the precision when improving the recall. On the other hand, the anomalies in Space Shuttle are relatively subtle, which makes it more difficult to select a proper threshold for error-based anomaly detection methods. Such a result validates that MTLED pre-trained on MTSD_AMT can also be used for real scenarios effectively through fine-tuning on a few samples.
Conclusions
In this paper, the shortcomings of mainstream detection and diagnosis methods for multi-sensor data are summarized and analyzed from their own perspectives. In summary, the single task, such as anomaly detection, anomaly diagnosis, or event detection, can hardly satisfies all the needs in system monitoring and fault prevention. In order to solve these issues, MTLED which can detect anomaly, diagnose anomalies and detect events simultaneously is proposed in a multi-task learning scheme. A large-scale multivariate time series dataset MTSD_AMT with sufficient annotation information is generated to enable an adequate supervised pre-training of our proposed model.
In MTLED, feature matrix is introduced into an encoder-decoder framework for the purpose of extracting features at the granularity of time point so that point-wise anomaly detection can be realized naturally. The encouraging results of point-wise anomaly detection of MTLED demonstrate the value of the feature matrix. In the meantime, other decoders based on the same feature matrix is used for anomaly diagnosis and event detection. Experiments on MTSD_AMT show that MTLED shows a significant advantage on anomaly detection, a comparable performance on anomaly diagnosis and a slight improvement on event detection. Furthermore, internal analysis on the variants of MTLED verifies the respective functions of its multi-task learning framework, attention mechanism and the auxiliary inputs. On the real dataset Space Shuttle, the superiority of MTLED on anomaly detection is validated and it also demonstrates that MTLED can be used for various domains by fine-tuning on small-scale samples.
MTLED provides an intuitive and effective way to realize various tasks related to system monitoring and early warning in one deep learning model. As the cost of the function perfection and performance improvement, the training of MTLED is more complicated and it needs to take more computational overhead than trivial models mainly due to the feature matrix. While the training phase is more time-consuming than most approaches, MTLED can still be used for monitoring the multi-sensor data in real-time. There is much research works can be done to optimize the proposed model, such as the addition of squeeze and excite block for improved feature extraction. Reducing the computational overhead is also very important so that such a detection and diagnosis system can be deployed in various application scenarios.
Footnotes
Handling Editor: James Baldwin
Author contributions
The individual contributions of the authors are as follows: conceptualization, J.W., L.Y., and L.Z.; methodology, J.W., L.Y., L.Z., and B.L.; software, J.W. and Z.D.; formal analysis, J.W., L.Y., and B.L.; investigation, J.W., L.Z., and Z.D.; writing—original draft preparation, J.W.; writing—review and editing, J.W., L.Y. and B.L.; supervision, L.Y.; project administration, B.L.; funding acquisition, L.Y.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The presented work is framed within the Research Project under Grant GK2019A010296. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the funding agencies.