
Abstract
We report on the development of an implementable physics-data hybrid dynamic model for an articulated manipulator to plan and operate in various scenarios. Meanwhile, the physics-based and data-driven based dynamic models are studied in this research to select the best model for planning. The physics-based model is constructed using the Lagrangian method, and the loss terms include inertia loss, viscous loss, and friction loss. As for the data-driven model, three methods are explored, including deep neural network, long short-term memory, and XGBoost. Our modeling results demonstrate that, after comprehensive hyperparameter optimization, the XGBoost architecture outperforms deep neural network and long short-term memory in accurately representing manipulator dynamics. With approximately 500k training data points, the XGBoost model closely matches the performance of the physics-based model, as assessed by the root mean square error between actual and estimated manipulator torque. The hybrid model with physics-based and data-driven terms has the best performance among all models based on the same root mean square error criteria, and it only needs about 24k of training data. In addition, we developed a virtual force sensor of a manipulator using the observed external torque derived from the dynamic model and designed a motion planner through the physics-data hybrid dynamic model. The external torque contributes to forces and torque on the end effector, facilitating interaction with the surroundings, while the internal torque governs manipulator motion dynamics and compensates for internal losses. By estimating external torque via the difference between measured joint torque and internal losses, we implement a sensorless control strategy which demonstrated through a peg-in-hole task. Lastly, a learning-based motion planner based on the hybrid dynamic model assists in planning time-efficient trajectories for the manipulator. This comprehensive approach underscores the efficacy of integrating physics-based and data-driven models for advanced manipulator control and planning in industrial environments.
Introduction
Industrial automation has been developed for the past 60 years for various tasks; for example, inspection, 1 machining,2,3 and pick-and-place. 4 Along with high speed, high precision, and low cost, machine intelligence is regarded as one of the key performance indices of robots. Recently, during the fourth industrial revolution (i.e., Industry 4.0), the focus has been on large-scale smart factories, which rely on many factors, such as the Internet of things, cyber-physics systems, big data, and artificial intelligence. 5 All of these require a dynamic model of the machine as a crucial and basic building block. Without an appropriate model, the behaviors of the machine cannot be predicted, planned, and controlled effectively.
The dynamic model of the machine includes various motion effects such as inertia forces, Coriolis forces, gravitational force, and some losses. Traditionally, the model was developed based on the physics principle and phenomenon of the system, using either the Newton–Euler method or the Lagrangian method. However, the model of a complex system, such as a manipulator, is incapable of covering all the physical behaviors of the system, especially nonlinear behaviors, subtle un-modeled dynamics, and manipulator specification variations due to manufacturing processes. For example, the joint of the manipulator may have loss terms other than (Coulomb) friction and (viscous) damping, but in ordinary modeling work, we usually only consider these two because they have the most significant effects. The presence of manipulator specification variations due to manufacturing processes indicates that the commercial manipulator's specifications are not the same as those listed in the datasheet, such as the D-H table. In this case, a data-driven model is quite useful due to its experience-based learning of the phenomenon and the behavior of the manipulator.
In this work, following our initial exploration of developing a physical-based model of manipulators, 6 we extend our exploration to reliable data-driven and hybrid models (i.e., to cover un-modeled loss terms) that were derived using machine learning,7,8 where three methods were explored: deep neural network (DNN), 9 long short-term memory (LSTM), 10 and decision tree. 11 For example, Gillespie et al. 12 and Boucetta and Abdelkrim 13 used DNN to deal with the uncertainty of the dynamic model for flexible and soft robots. In contrast, LSTM, a type of recurrent neural network, is commonly used for situations with time series. For example, Lai et al. 14 described a way to solve the problem of adaptive fuzzy inverse compensation control for uncertain nonlinear systems with generalized dead-zone nonlinearities in uncertain actuators. Thus, the generalized dead zone of the motor has hysteresis, where the values of friction in forward and reverse rotation are different. Without proper suppression, the nonlinear dead-zone may cause more errors and even instability of the system. Therefore, some researchers have tested whether LSTM can make the fitted model more accurate.10,15 Finally, the decision tree approach uses a tree model to determine the consequences of events. The most famous method is XGBoost. 16 It has been widely recognized in many machine learning and data mining challenges, such as Kaggle and the KDD Cup, 17 which shows the potential to handle un-modeling dynamics of robotic systems.
In addition to the dynamic model, a smart manipulator requires the use of many sensors.18,19 Force/torque sensors are a popular choice and have led to many applications that require contact interactions, such as assembly tasks and human–robot collaborations.20,21 For example, peg-in-hole is a common assembly task in factories. Various works have addressed this issue. Lin 22 developed a plug-in system for large transformers using a six-axis robotic arm. Kim et al. 23 developed a hole-detection algorithm for square peg-in-hole applications using force-based shape recognition. Tang et al. 24 developed an autonomous alignment strategy for peg-in-hole. Qin et al. 25 utilized a multi-sensor perception strategy to enhance the autonomy of uncertain peg-in-hole tasks. Beltran-Hernandez et al. 26 developed a variable compliance-control strategy for robotic peg-in-hole assembly. These three works utilized force/torque sensors. Due to the high cost of multi-axis force/torque sensors, other strategies for performing the peg-in-hole task have been proposed. For example, Park et al. 27 developed a low-cost peg-in-hole assembly strategy using contact compliance and without using a physical force/torque sensor. At present, most research on virtual force sensors focus on the safety of human–machine collaboration (such as Yen et al. 28 and Li et al. 29 ). Similar applications often require the establishment of mathematical models and the establishment of compensation for friction to achieve more accurate accuracy. For example, Lai et al. 14 developed a method to compensate the dead zone of the general actuator through the fuzzy adaptive inverse compensation method. This research hopes to establish all models at once through machine learning. Considering the high demand of the force/torque sensing information on the end-effector of a manipulator, virtual force/torque transducers seem to be a worthwhile research topic28,30 and motivated us to initially explore this aspect in this article. One of the popular methods to develop a virtual force/torque sensor of a manipulator is to estimate the force/torque values by subtracting internal torques from measured torques. Estimating the internal torque of the manipulator requires a high-precision dynamic model, so this extension smoothly follows the development of dynamic models reported in this work.
Except for dexterous manipulation, which required force/torque estimations or measurements, trajectory planning is another important issue. Traditionally, the trajectory planning of industrial robots relies on physics models. 31 However, with the advancements in machine learning, the typical trajectory optimization can be achieved by AI algorithms. For example, Tian and Collins 32 and Števo et al. 33 demonstrated the application of genetic algorithms to optimize trajectories for robot arms efficiently. Furthermore, reinforcement learning (RL) algorithms 34 have emerged as another popular method for trajectory optimization. Schulman et al. 35 successfully implemented RL techniques to generate optimal motions for a robot manipulator, particularly in pick-and-place tasks. The RL algorithms aim to learn optimal behaviors in an environment given user defined policy. 36 Thus, the integration of a reliable hybrid dynamic model of a robot arm and RL algorithms forms a trajectory planner, promising enhanced efficiency and adaptability for industrial robots in various tasks.
In short, motivated by the emerging development of data-driven approaches, we reported on developing a reliable physics-data hybrid dynamic model for an industrial robot. The performance investigation of the physics-based and data-driven dynamic models, and the possible hybrid physics-data dynamic models is conducted. While the reported research usually focuses on using a specific modeling method for a specific application, we are interested in finding a reliable and general performance trend of the dynamic model from the aspect of its composition. In addition, following the core development of the data-driven dynamic model of the manipulator, we reported our initial investigation of the manipulation applications and a motion planner using the hybrid dynamic model. The contributions of this work include the following:
Developing an implementable physics-data hybrid dynamic model of the articulated manipulator among various data-driven dynamic models using machine learning techniques, such as DNN, LSTM, and XGBoost and evaluating their performance. Proposing an external torque observer based on the developed data-driven models and then proposing a virtual force/torque sensor via the observed external torque for robotic manipulation. Proposing a sensorless peg-in-hole assembly strategy inspired by human operation. Developing a learning-based time-efficient motion planner based on the physics-data hybrid dynamic model and is validated by experiments.
To position our contributions among existing literature, we compare our approach with others. Reinhart et al.
37
studied data-driven forward and inverse dynamic models of an industrial robot for pure feedforward control. Carron et al.
38
applied a physics-data hybrid dynamic model of a robotic system for tracking controller design. By contrast, we attempt to find an accurate digital twin of the robot arm for sensorless dexterous manipulation and high-performance motion planning. Yu et al.
39
developed a data-driven dynamic model for a fish robot to handle fluid dynamic issues; however, this research aims to compensate for the un-modeled dynamics of an articular manipulator. Xu et al.
40
built a data-driven dynamic model for a cable-driven planar robot to predict its tension and collision conditions. Nevertheless, our data-driven model is not only used to plan motions for a robot arm but also applied to realize a torque observer for sensorless manipulation and learning-based motion planning. Lastly, our previous work
6
proposed a learning-based motion planner, but we implemented a more accurate digital twin with the hybrid dynamic model and adjusted the policy for RL to generalize the previous framework. Overall, a functional physics-data hybrid dynamic model is constructed for sensorless dexterous manipulation and learning-based motion planning of an industrial robot in various industrial applications.
The remainder of this article is organized as follows. “Dynamic models” section introduces dynamic models, and “Performance of the dynamic models” section describes the performance of the dynamic models. “Design of a virtual force sensor” section describes the design of a virtual force sensor. “Design of a motion planner” section displays the design of the motion planner. “Experiment” section reports the experimental results and “Conclusion and future work” concludes this research.
Dynamic models
The dynamic models utilized in this work were developed using two different approaches; one is a physics-based dynamic model, and the other is a data-driven model. The former is intrinsic, which allows us to truly understand the dynamics of the manipulator, but un-modeled dynamics, such as nonlinear terms, are difficult to identify. Furthermore, if the model has time-dependent terms (i.e., after a long operation time, the friction and damping terms are usually different), a remodel of the system is necessary. In contrast, the data-driven model is better able to capture nonlinear terms, but the trade-off is that the data collection and learning processes may take considerable time. While we are aiming at using a complete data-driven model for the tasks in this work, we are also interested in exploring the performance and dynamic characteristics of the physics-based model and the physics-data hybrid model for comparison purposes. Thus, this section describes the construction of the physics-based model and data-driven model separately.
The physics-based models
The physics-based dynamic model of the system was derived using the Lagrangian method. By forming the Lagrangian (


In this work, the derivation of EOMs was carried out for a 6-DOF articulated and collaborative manipulator (TM5-700, Techman Robot Inc.). The CAD model and configuration of the manipulator are shown in Figure 1. This robot is utilized as the experimental testbed for the proposed methodology. Using the joint angles of the manipulator (

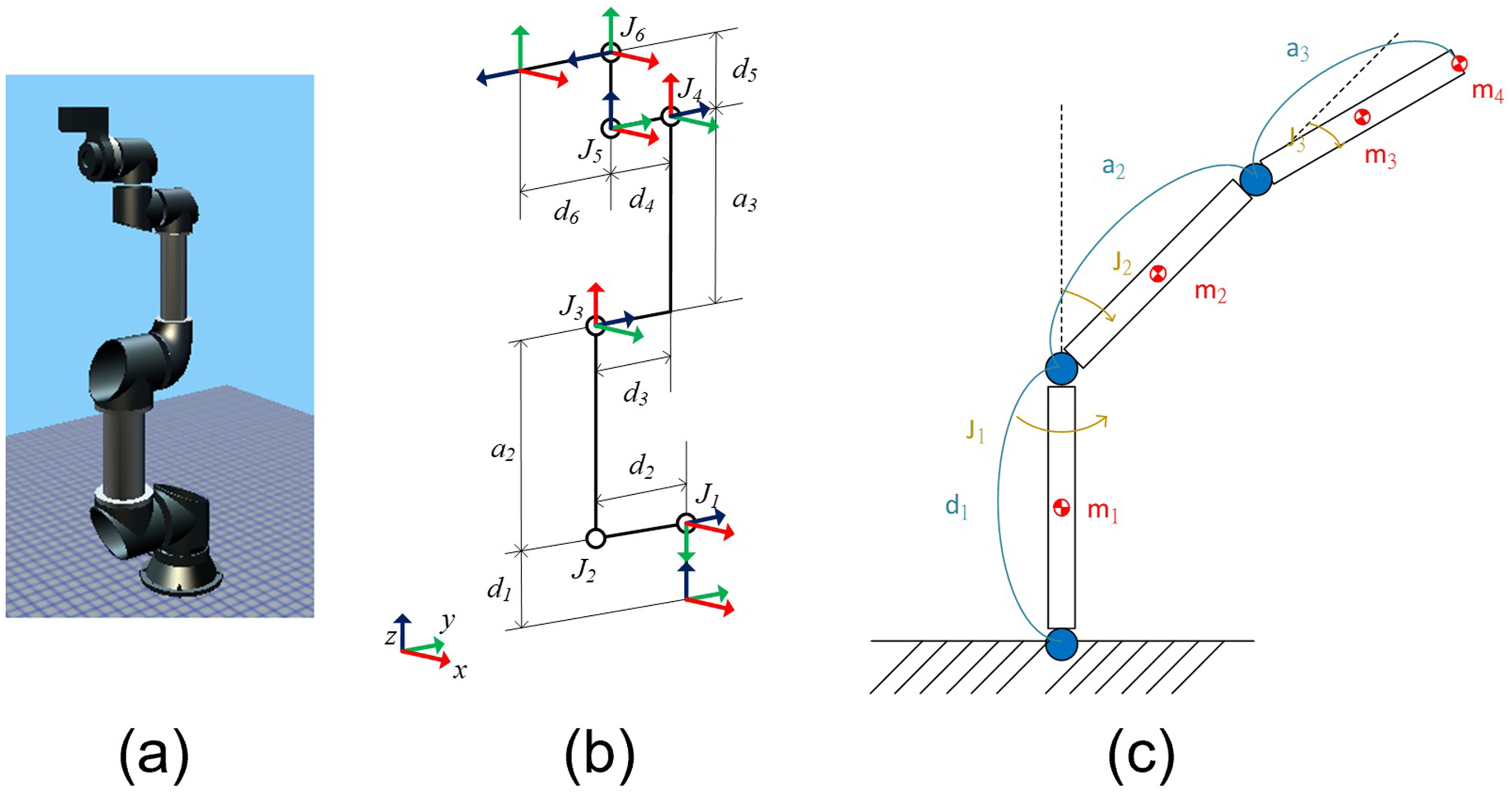
The manipulator TM5-700: (a) the CAD model, (b) the configuration, and (c) the simplified dynamic model.
For the ideal manipulator without loss, the non-conservative force

In contrast, the empirical manipulator generally has loss, so the non-conservative force


The data-driven models
In addition to constructing the model using physics principles, the model can also be data-driven. Following a similar form as the EOM shown in (2), the data-driven EOM can be expressed as

Equation (7) is utilized as the data-driven EOM, where the manipulator states
The complete dynamic model contains 6 DOFs, and the training process is divided into subgroups to reduce the model's complexity and the required dataset size. The 6-DOF articulated manipulator is generally designed to use the first three axes for translational motion (i.e., joints 1–3) and the last three axes for rotational motion (i.e., joints 4–6). The last three axes are compactly designed to have their rotational axis orthogonally intersected with each other, so Pieper's solution can be deployed to algebraically or geometrically solve the inverse kinematics problem of the manipulator. Because of orthogonality, joints 4 and 5 were trained individually, yet the position states of other joints were imported so that the gravitational effects could be correctly considered. In contrast, the first three axes have a broad motion range, and their motion dynamics are highly coupled, especially the second and third axes. Therefore, the first three axes are trained together. Furthermore, because the motion of the last three axes is comparably small compared to that of the first three axes, in the training process of the first three axes, the motion of the last three axes was ignored and could be regarded as a small point mass; m4 is the sum of the last three axes’ mass, mounted at the end of manipulator as shown in Figure 1(c). The machine learning models of axes 1, 2, and 3 are established separately from the models of axes 4 and 5. We had tried to train the model by including all axes of the manipulator as inputs. However, the model's performance was not promising, even when the data number was doubled. Because the first three axes are for translational motion of the manipulator, the effects of the axes are definitely coupled and should be trained together. Axes 4 and 5 are designed for rotational motion within a small range, so their effect can be separated from the first three axes to include training efficiency.
As described in the introduction, three methods (DNN, LSTM, and XGboost) were explored to evaluate their performance in constructing a data-driven dynamic model of the manipulator, whose structure diagrams are shown in Figure 2. The neuron of LSTM is different from DNN. LSTM layers whose cell is memorable and composed of an input gate, a cell state, forget and output gates.
15
XGBoost (Extreme Gradient Boosting) is a gradient-boosted decision tree. Each time the original model is kept unchanged, and a new function is added to the model to correct the error of the previous tree to improve the overall model. The structure shown in the far right side of Figure 2 is a set of classification and regression trees. Each leaf of the regression tree corresponds to a set of values, which are used as the basis for subsequent classification. The rightmost circles in the figure may be the output of the XGBoost model, which depends on the result of the final judgment of the input value in the decision tree to determine which rightmost circle is the final output.
16
Note that the utilized DNN package (keras) and XGBoost package (xgboost) have different architecture,41,42 where the former supports multiple outputs, but the latter does not. Therefore, the three estimations (
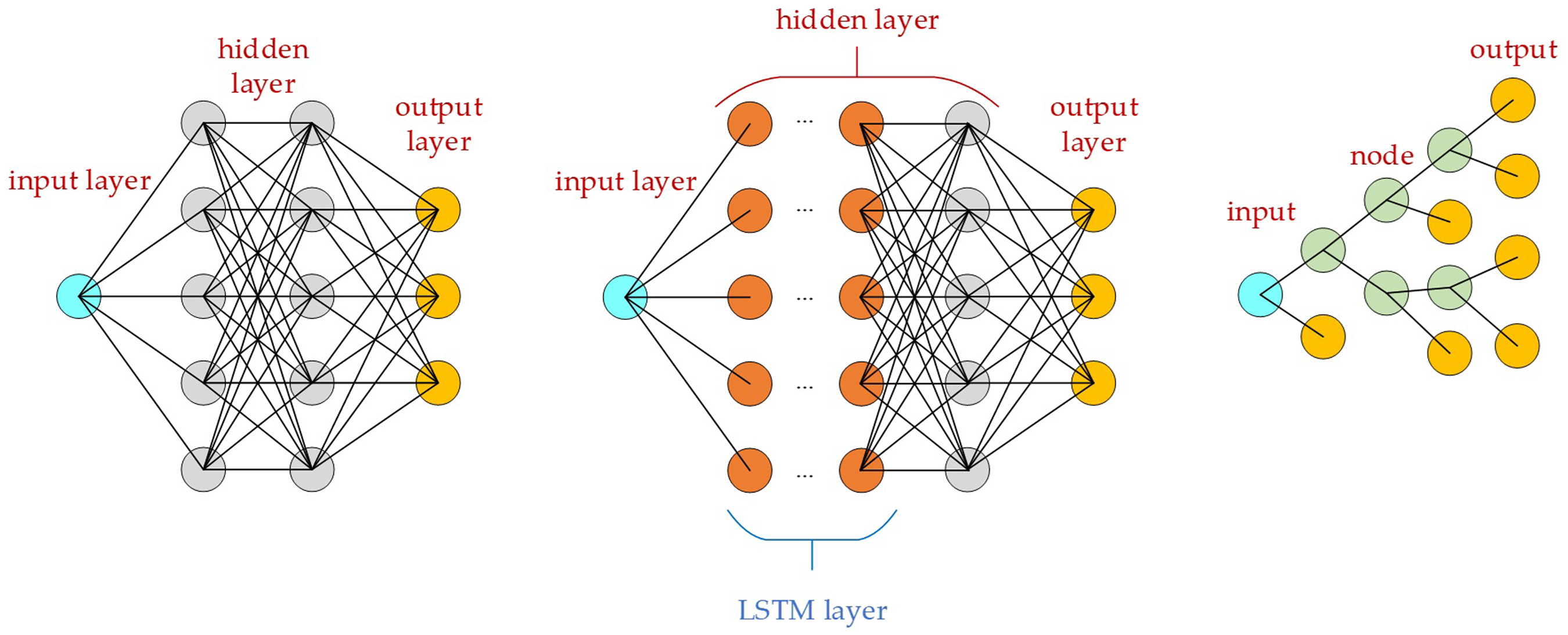
Structural diagrams of (a) DNN, (b) LSTM, and (c) XGBoost. The leftmost and rightmost circles represent the input and output of the model, respectively. In the case of XGBoost, shown in (c), only one of the outputs is the actual output, depending on the result of the final judgment of the input value in the decision tree.
The features and labels of the manipulator used for training.

Unlike the DNN, which uses states of one moment to predict the states of the next moment, the LSTM uses time sequence as input data, and the XGBoost can be modified in the same manner. The structure of LSTM replaces neurons in the original hidden layer of the DNN model with LSTM units; thus, the underlying learning strategy was completely different. The LSTM is prone to overfitting, so the architecture is more complicated than the previous DNN, and dropout and recurrent_dropout must be considered. While the states of a series of timestamps were fed into the model, the input became two-dimensional as shown in Figure 3(a). For any predicted torque at any timestamp [k] shown in the blue block, the model requires the states at timestamp [k-n] to [k]. In our implementation using the LSTM method,

The inputs/features and outputs/labels of the model using the LSTM method (a) and XGBoost method (b).
After describing the model construction, as well as its features and labels, the following paragraphs in this section will describe the selection of hyperparameters, which need to be set before training. If we use LSTM as an example, the hyperparameters include several factors, such as the learning rate, number of iterations, number of layers, and number of neurons in each layer. The choice of hyperparameters seriously affects the capability and performance of the model, but the selection of high-quality hyperparameters is very complicated. Thus, a methodical search strategy is crucial.43–45 Four methods are commonly used to adjust hyperparameters: manual, grid search, random search, and Bayesian optimization. The manual method mainly relies on a variety of different architectures to test and train individually and finally adjust the hyperparameters according to the result of the loss function or objective function. The grid search method sequentially defines the values to be searched according to the type of hyperparameter. The program runs through all the hyperparameter combinations to test and select the best parameters based on the loss function or objective function, which is time-consuming because every Cartesian product of a hyperparameter combination must be tried. Although this brute-force method is time-consuming, it can find the best solution as long as the exhaustive hyperparameters are sufficiently comprehensive. The random search method is similar to the grid search method. The difference is that it randomly selects a combination of parameters to search. Relatively speaking, it may be more economical in time and computing resources than the grid search method, but the search may be insufficient. Finally, the essence of Bayesian optimization lies in the verification of previous results and probability to select hyperparameters for the next iteration. 46
This work used two methods to adjust the hyperparameters of machine learning. One was grid search due to its complete search in the parameter space, and the other was Bayesian optimization due to its efficiency. The work then compared the performance of the manipulator models using these two adjusting methods. GridSearchCV in the scikit-learn module was utilized.
47
For a DNN model with multiple hidden layers and a large amount of training data, a grid search is time-consuming and impossible to run simultaneously. For example, a model with 10 hyperparameters, each with nine variations, would have to run
Automatic independent hyperparameter grid search

The Bayesian optimization search method, in contrast, establishes a probability model through the corresponding relationship between the loss function results obtained by the model with the previously generated hyperparameters. Thus, each time the hyperparameters were adjusted, a probability model was attempted to estimate the minimum loss function, where the adjustment of the hyperparameters was executed more efficiently.41,44 The objective function of the Bayesian optimization used in this work was L2 loss or mean square error (MSE):
The physics-data hybrid models
While either the physics-based model or the data-driven model can be separately utilized to model the manipulator's dynamic behaviors, these two models can also be combined, forming the so-called physics-data hybrid model. In this method, the data-driven part acts as the compensation term to cover the un-modeled dynamics ignored in the physics-based part. This is advantageous because inclusion of the data-driven part increases the model accuracy, yet the required data size is not as large as the pure data-driven model which requires a large data set to capture the complex dynamic behavior of the manipulator.
Various compositions could be utilized to form the hybrid models. The first trial in this work involved taking all the physics-based terms from (3) and (6) into account and using a data-driven model (

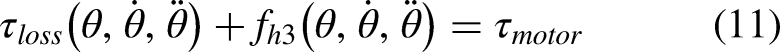
Composition of various models with physics-based and/or data-driven portions.

Motion data generation of the manipulator
Data collection is one of the key elements of the machine learning process, and its quality strongly determines the performance of the learned model. This is especially true for complex dynamic systems, which have many states coupled with each other. The manipulator in this work is a typical complex dynamic system, whose complete global training data is difficult to collect. 48 Coupled states are especially difficult to collect because they include not only position but also velocity and acceleration data. While data diversity is crucial, efficiently collecting a sufficient amount of data with broad diversity is very important. In this section, the trajectory generation method, which quickly generates a diversified training data, is described.
Motion data generation of the manipulator includes three steps. First, the motion range of each joint of the manipulator is digitized into a selected angular interval, so the original infinite possible joint angles are transformed into finite angular configurations. For example, if all six joints of the manipulator are digitized into N segments, there exists
The empirical implementation of trajectory generation on TM5-700 is described as follows. First, the rotation ranges of the first to the sixth joints are
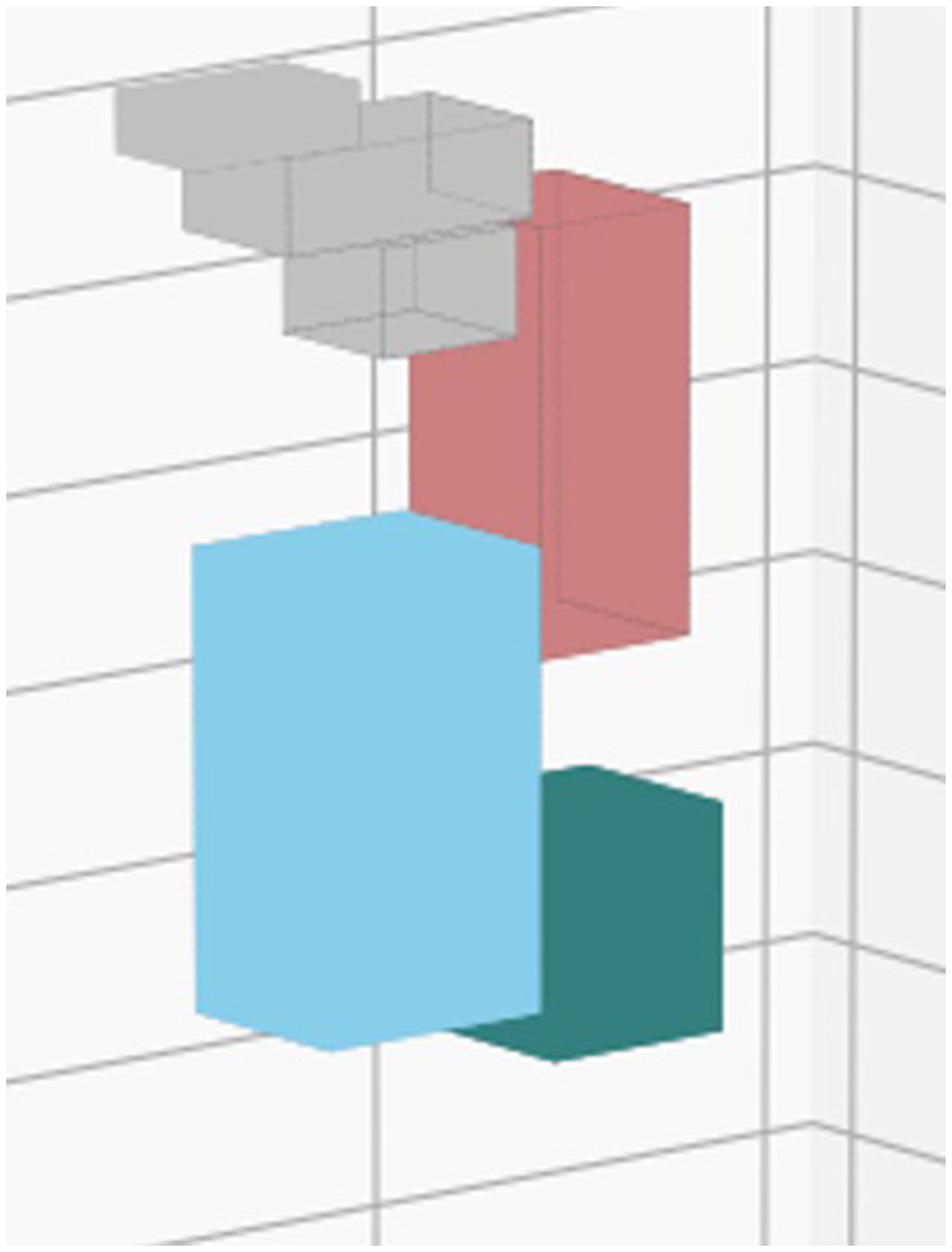
The combination of simplified bounding-box model of the manipulator and hybrid dynamic model of the TM5-700 as a simulator.
Performance of the dynamic models
Performance comparison of physics-based, data-driven, and hybrid dynamic models
The models listed in Table 2 were trained using the DNN-based data-driven model with empirical motion data of a TM5-900 manipulator. The features and label details are listed in Table 1. The DNN architecture used a hidden layer with seven layers. Each hidden layer used batch normalization, which speed up training completion, reducing the need for dropouts, and increased the likelihood of early stopping. The number of neurons in each layer was 512, 1024, 1024, 1024, 1024, 1024, 512. The activation function was tanh, the last layer was the output layer, the activation function was linear, the loss function was the average absolute error, the optimizer was adam, and the validation_split = 0.2, which indicated that 80% and 20% of the data were training and verification data, respectively.
The evaluation was executed using the motion of the first three axes of the manipulator (i.e., joints 1–3), which were highly coupled and dynamic. A total of 23,598 training data points were collected and shuffled before feeding them to the models. In addition to the training and verification data, test data were generated using six randomly selected manipulator motion trajectories, where each ran five times. Thus, 90 joint trajectories in total were used for testing. For each trajectory, the root mean square error (RMSE) between the true torque generated by the manipulator (
Table 3 lists the performance of the various models constructed in “Dynamic models” section. The results reveal that the physics-based model without loss (i.e., P1) is not realistic and has large RMSEs. The added physics-based loss term greatly improves the model's performance (i.e., P2). Furthermore, the added data-driven part further improves the model's performance (i.e., H1), which indicates that the DNN captures the un-modeled dynamics of the manipulator. The hybrid models H2 and H3 separately used the data-driven model to compensate for the physics-based loss terms or the motion dynamics of the model, respectively. However, given the same dataset for training, the added unknown model dynamics decreases the performance of the models. H3 performing worse than H2 indicates that motion dynamics are more complex and difficult to learn than loss dynamics.
Statistical performance of various models based on RMSEs between the torque generated by the manipulator and estimated by the models (unit:N·m).

The shading results are either have better result or have important discovery.
Architecture and hyperparameter adjustment of the data-driven models
Table 3 also reveals that with the same dataset, the pure data-driven model D1, which needs to learn all the dynamics of the manipulator, has the worst performance among all models with different compositions, which are listed in Table 2. This result suggests that the amount of training data may not be inadequate, or the chosen hyperparameters are unsuitable for learning manipulator dynamics. Therefore, additional evaluations were executed to address these concerns. Table 4 shows the performance of the data-driven model with different training data and the same DNN architecture. The first two rows are identical to the data shown in Table 3 as the reference. The table clearly shows that the means of RMSE decrease when the amount of training data increases. The increase in training data effectively improves the performance of the data-driven model, but it is still not as good as the physics-based model P2.
Statistical performance of the DNN-based models with different amounts of training data (unit:N·m).
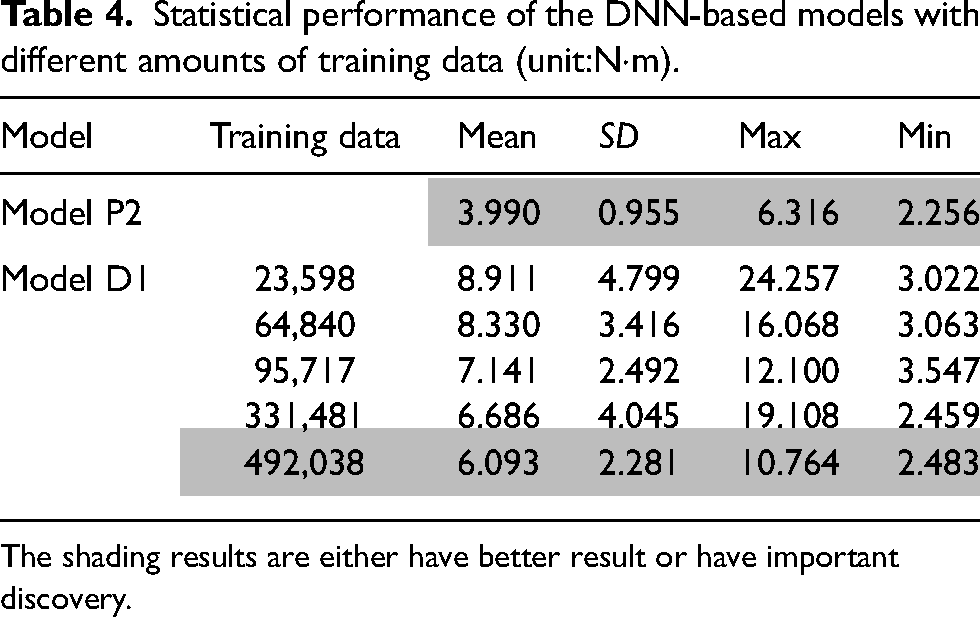
The shading results are either have better result or have important discovery.
Following the results shown in Table 4, the hyperparameters of the DNN-based model were adjusted using a grid search and Bayesian optimization. Meanwhile, the variations of the model with different loss functions and layers were evaluated. The DNN-based models with hyperparameter adjustment are hereafter referred to as Model D2. In addition to the 7-hidden-layer architecture and L2 loss utilized in the model, the 3-hidden-layer architecture and L1 loss were evaluated, where the L1 loss represents the mean absolute error (MAE):
Statistical performance of the DNN-based models with different architectures and hyperparameters (unit:N·m).

The shading results are either have better result or have important discovery.
Table 5 reveals that the mean values of RMSE of the D2 models whose hyperparameters were adjusted using grid search or Bayesian optimization of hyperparameters are similar, and they are all smaller than that of model D1. This indicates that the grid search adjustment of hyperparameters is very helpful in improving learning performance. The table also shows that the model with MSE loss is slightly better than the one with MAE loss. The table also reveals that the model with a 3-hidden layer can achieve a similar performance as the model with a 7-hidden layer. In the current setup, the model using more than three hidden layers does not improve performance and just increases the amount of training and tuning. The adjustment of hyperparameters using Bayesian optimization performs similar to the grid search. However, the parameter search time was reduced from 48 h for the grid search to 4 h, so it is a very time-effective method. In addition to the reported models, we tried many other DNN-based models with different settings, but the performance of the models seemed limited. Therefore, other variations of the model were then explored.
The LSTM-based model takes a sequence of historical data as the input, which intuitively helps to capture the dynamics of the manipulator. The utilized LSTM model is a two-layer LSTM, where Gaussian noise was stuffed between the two parts and the last two fully connected layers. The LSTM model is referred to as model D3. Table 6 shows the results, where the first two rows are identical to the data shown in Table 5 as reference. The table shows that the LSTM model (i.e., model D3) can indeed reduce the overall average RMSE, which confirms that time-serial features can improve machine learning performance. However, although the LSTM model performs better than the DNN model, it is still not as good as the physics-based model. Therefore, data-driven models with different architectures and principles were then explored.
Statistical performance of the models (unit:N·m).
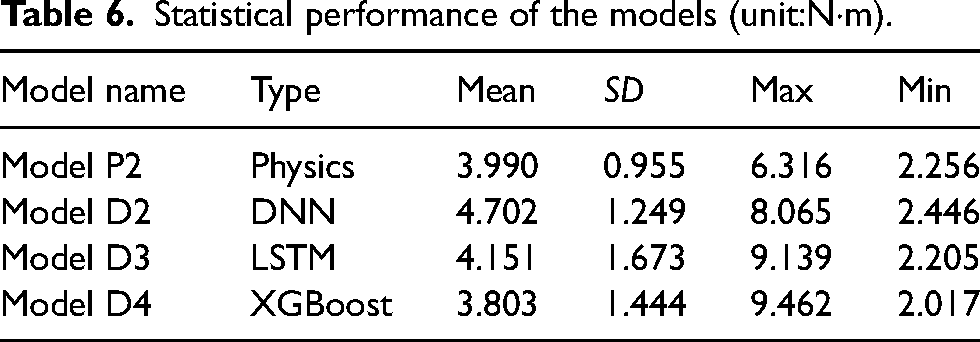
The XGBoost method is developed, and its performance was compared using the DNN and LSTM models. The architecture of the decision-tree models is relatively simple, so the hyperparameter search is much easier than the NN method. There was no need to define each hidden layer, select an order arrangement, or, for example, decide whether to use dropout or batch normalization or which activation function to use. The XGBoost model in this work included the adjustment of the following 10 hyperparameters: learning_rate, max_depth, min_child_weight, colsample_bytree, subsample, reg_alpha, reg_lambda, gamma, n_estimators, and seed. The XGBoost model is hereafter referred to as Model D4. Table 6 shows that although the RMSE standard deviation and RMSE maximum of the XGBoost model are relatively larger than those of the physics-based model, the RMSE means are smaller than those of the latter. This indicates that the pure data-driven model can effectively model the complicate dynamic motion of the manipulator.
In summary, the results reported in this section led to the following conclusions. First, with about 500k of training data, the XGBoost model (i.e., model D4) performs similar to the physics-based model with both motion dynamic terms and loss terms (i.e., Model P2), based on the judgment of RMSE between the actual manipulator torque and the estimated one using the model. Second, the hybrid model with physics-based and data-driven terms (i.e., Model H1) has the best performance among all models based on the same RMSE criteria, and it only needs about 24k of training data. From the aspect of training data collection and training time, this is a very effective method to model the manipulator dynamics when compared to the pure data-driven model. The construction of the physics-based model of the manipulator is not trivial, either. Third, based on the amount of training data used for testing, increasing the amount used improves performance, which matches the general observation of the learning model. Fourth, the adjustment of hyperparameters also improves the model's performance. Bayesian optimization performs similar to the grid search methods but requires much less time. Fifth, given the same dataset, the LSTM with sequential data performs better than the DNN with instant data, and XGBoost outperforms the LSTM model.
Note that many data-driven models were evaluated in this work. The fundamental idea was that we wanted to determine which data-driven model is suitable for modeling ordinary differential equations (ODEs). Once a suitable model is found, the work can be easily extended to other systems that move, as all movable systems obey Newton's Second Law and can be expressed as second-order ODE systems. However, because movable systems appear in many different forms or compositions, only some of them have physics-based models constructed. If a new system is designed, especially a high DOF system, it is also challenging to construct its physics-based model. Therefore, we think that the data-driven approach has merit and is worth trying.
Design of a virtual force sensor
The states of the end effector and its force interaction with the environment are important information for manipulator operation. While the states of the end effector can easily be observed using the manipulator joint configuration with forward kinematics, the force interaction is difficult to obtain, as it includes three forces and three sources of torque. One general approach is to install a six-axis force sensor on the end effector. However, this greatly increases the hardware cost of the manipulator. 28 Following the modeling work presented in previous sections, the estimated joint torque of the manipulator using machine learning is further developed into estimation of interaction forces between the end effector and the environment. This includes two steps: estimating the required torque at the joints, which are utilized to generate the required forces at the end effector and establishing the mapping between the former and the latter.
The external torque observer
As described in (5), if the manipulator moves freely within the workspace with states 


In the empirical implementation, because the external torque 
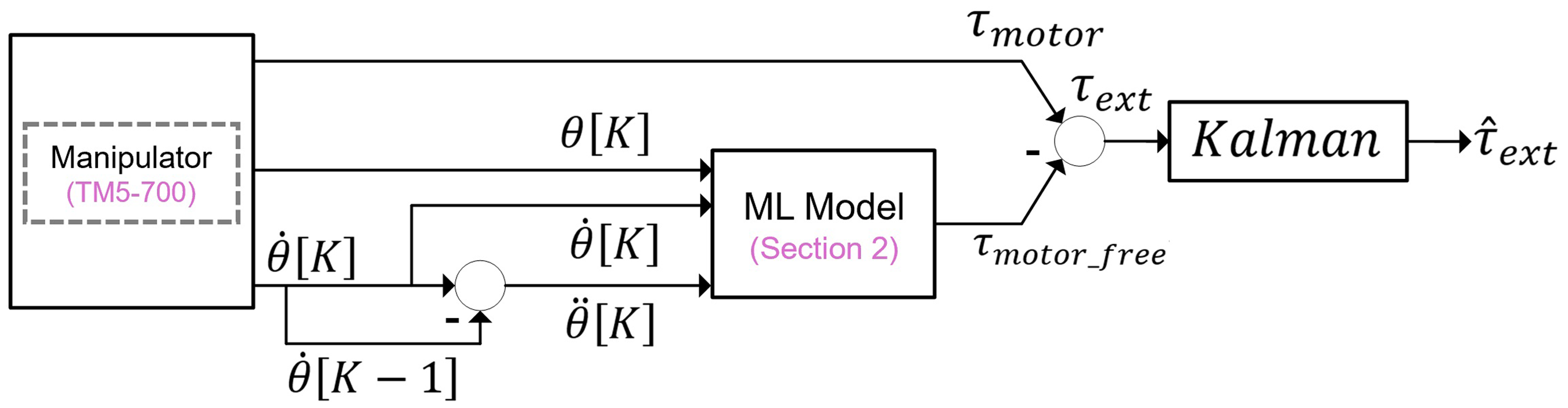
The architecture of the external torque observer.
Virtual force sensor
The virtual force sensor uses XGBoost models, which has the best analysis effect above. Given the estimated external torque
In this work, a three-axis virtual force sensor was developed using a data-driven model, including a normal force and two tilting moments of the end effector as shown in Figure 6(a). While the manipulator was posed in certain configurations, the forces/torque on the end effector can be roughly approximated using a simpler static force relationship. This work utilized a peg-in-hole application to demonstrate the virtual force sensor, and the most common configuration of the manipulator in this application is shown in Figure 6(b). In this configuration, the estimation of two moments (

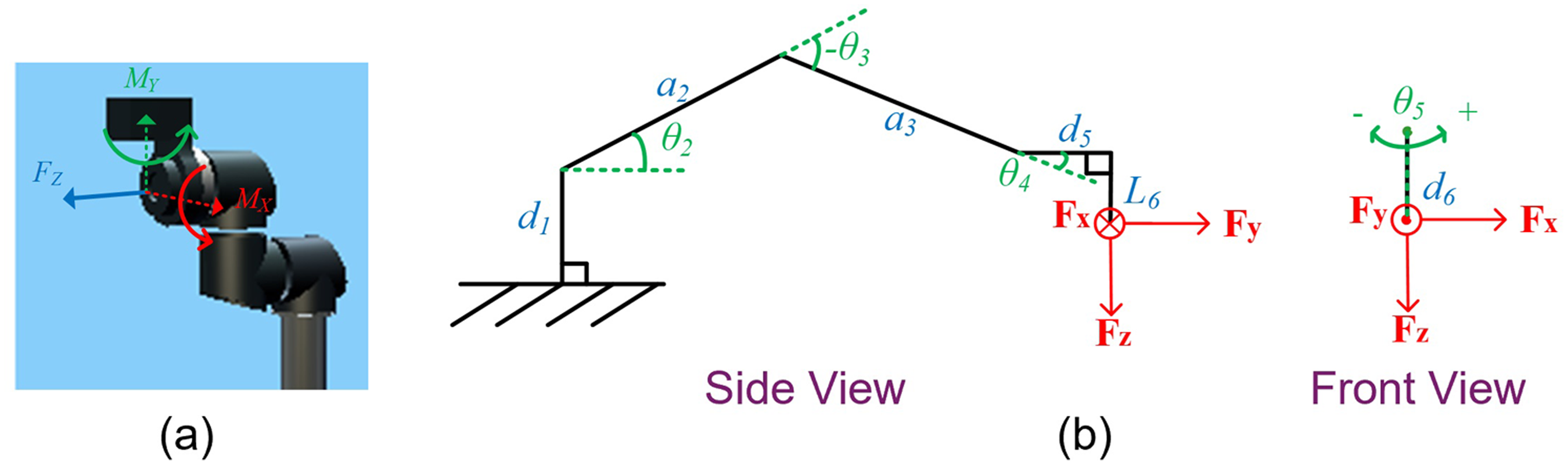
The three-axis virtual force sensor developed in this work: (a) notations of the three estimated axes; (b) the major configuration of the manipulator when the sensor was utilized.
As for the normal force 
To collect labeled data as the training dataset of the models shown in (18)–(20), a commercial six-axis force sensor was installed on the end effector as the ground truth (WEF-6A200-4-RCD, WACOH Inc.), as shown in Figure 7. During the training process, the end effector was posed in various configurations with forces/torque at different levels, and a total of more than 260,000 data points were collected for training. In the experiment, we tried to select five postures to apply force on the force sensor and observed the force sensor values and results predicted by the model (20). The force applied by the hand ranges from 0 to 75 N. The largest difference in force is mainly between 0 and 20 N. The maximum error is about 20 N, as shown in Figure 8, and the average error is about 9.4 N. The maximum force error is 20 N because the empirical system is affected by inertia, which is also supported by the physics-based models. Therefore, the estimation would be imprecise in the very beginning and then improve, as shown in Figure 8. Furthermore, LSTM is a time-series model that uses a period of past data as the inputs, so the model takes time to converge for operation. The figure also shows that the model can capture the dramatic changes of the force, which indirectly indicates that the estimation system has sufficient bandwidth. However, the estimation of the force in a small magnitude is less accurate. We believe this phenomenon results from the manipulator's mechanical properties (e.g., the dead-zone of the joint, static friction, viscous damping forces), as well as the accuracy of the mechatronic systems (e.g., accuracy of the current measurement).

A commercial six-axis force sensor (WEF-6A200-4-RCD, WACOH Inc.) was installed on the end effector to collect ground truth data for training and quantitative experiment validation.
Time-series data of the estimated force (dashed curve) and the measured force (solid curves).
Data-driven models for the 4th and 5th joints of the manipulator
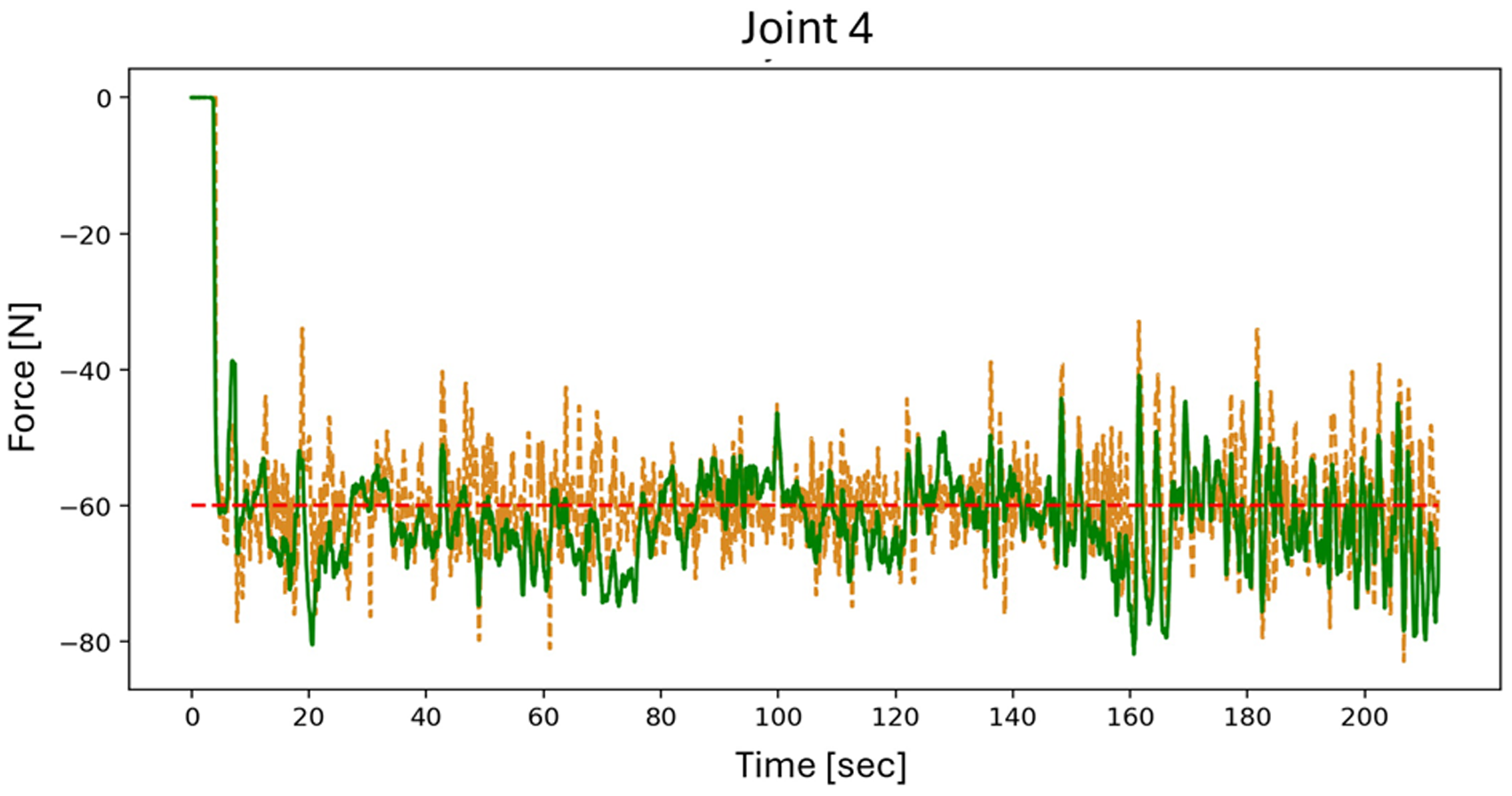
After describing the development of various models for the first three axes of the manipulator, this section focuses on the model development of the 4th and the 5th joints of the manipulator. As mentioned previously, due to orthogonality and the intersected joint axis, modeling of the 4th and the 5th joints was executed separately. In addition, because these joints of the manipulator are close to the end effector, instead of generating test data for evaluation, the performance of the joint torque estimation was directly observed using a multi-axis force sensor mounted on the end effector (WEF-6A200-4-RCD, WACOH Inc.), the ground truth. Figure 9 shows the manipulator layout for experimental validation of the 4th and the 5th joint models, respectively. Joint 5 could be posed in two configurations as shown in Figure 9(b) and (c). The joint torque was transformed to be represented as the force of the end effector using the method described in “Virtual force sensor” section, so the measured data could be compared with that of the ground truth data. Note that the joint torque of the manipulator contributes to two tasks; external torque contributes to the forces/torque on the end effector, which interacts with the surroundings, and internal torque is utilized for manipulator motion dynamics and for compensating internal loss. Subtracting the internal torque (i.e., derived by the data-driven model) from the total joint torque (i.e., torque measured at the joints) yields the external torque, which is then transformed to the forces/torque at the end-effector using Jacobian forces. The Jacobian defines the “instant” relationship between the joint torque and the forces/torque at the end-effector, which, when viewed from the perspective of geometry, can be considered a virtual force with geometrical considerations. Figure 10 shows the estimated force from the virtual force sensor and measured force from the six-axis force. The RMSE of the estimated force in joint 4 and 5 experiments were

Experimental setup for validating the performance of the model for the 4th joint in (a) and the 5th joint in (b)–(c), which has two operating configurations.

Comparison of the estimated force from the virtual force sensor (x-axis) and measured force (y-axis) from the six-axis force sensor. The dashed line represents ideal conditions.
Table 7 lists the performance of the XGBoost model for the 5th joint. Here, the averaged error, standard deviation of the error, and maximum error between the real force measured by the multi-axis sensor and the force estimated by the model were utilized as the criteria. Four different settings were explored. Trial 1 utilized instant input data (i.e., no sequential data). Trial 2 used the same setup but with data normalization using
Performance of the model for the 5th joint using different model settings (unit:N).

Trial 3 utilized sequential data inputs, where 10 timestamps were imported, the same number as the LSTM model. Trial 4 used the same input data as Trial 3, and the data were normalized, similar to the process in Trial 2. The table shows that using sequential data helps to improve the performance of the XGBoost model, and data normalization is unnecessary. The general normalization method is to normalize the data to a distribution with a mean of 0 and a variance of 1. This is mainly for the effectiveness of the gradient, but here, we found that the normalization effect will not improve. The main reason may be that the original scaling value is compressed to between −1 and 1; thus, the resolution of the data value becomes smaller, so the effect is not improved.
Design of a motion planner
In “Performance of the dynamic models” section, the accuracy and ability of the physics-data hybrid model to capture the dynamics of the articulated robot have been verified. Except for manipulation, an industrial robot relies on trajectory planning to pick and place objects. The physics-data hybrid model, therefore, is utilized to build a motion planner for the robot arm as Figure 4. The motion planner here focuses on speed optimization of the robot arm and aims to reduce the elapsed time of a chosen trajectory. The experimental results can be observed in “Speed optimization of trajectories” section.
Deep RL was employed for trajectory optimization due to its ability to streamline complex constraint settings and analytics while still yielding comparable results. The specific algorithm utilized in this context was proximal policy optimization (PPO), introduced by OpenAI in 2017. 35 PPO operates on an actor-critic architecture, where the actor determines actions, such as adjusting the positions or timestamps of via points. Subsequently, the critic evaluates the actor's actions, assigning a score to guide the actor toward actions that lead to higher scores. In this scenario, the reward is designated for speed optimization, with trajectories receiving higher rewards for shorter elapsed times. The trajectory yielding the highest reward is considered the optimal one.
The motion planner here is to reduce the elapsed time from the start point, via the point, and end point of the trajectory. The reward function of RL is set as:
This reward function (22) attempts to penalize when torque exceeds the limit. The reward will be negative as the torque exceeds the limit. The more it exceeds the limit, the more negative rewards it obtains. The
Experiment
The developed virtual force sensor described in “Design of a virtual force sensor” was evaluated using two experiments. The first one, wiping a table, involved moving the end effector of the manipulator on a flat surface with constant normal force,
Wiping the table
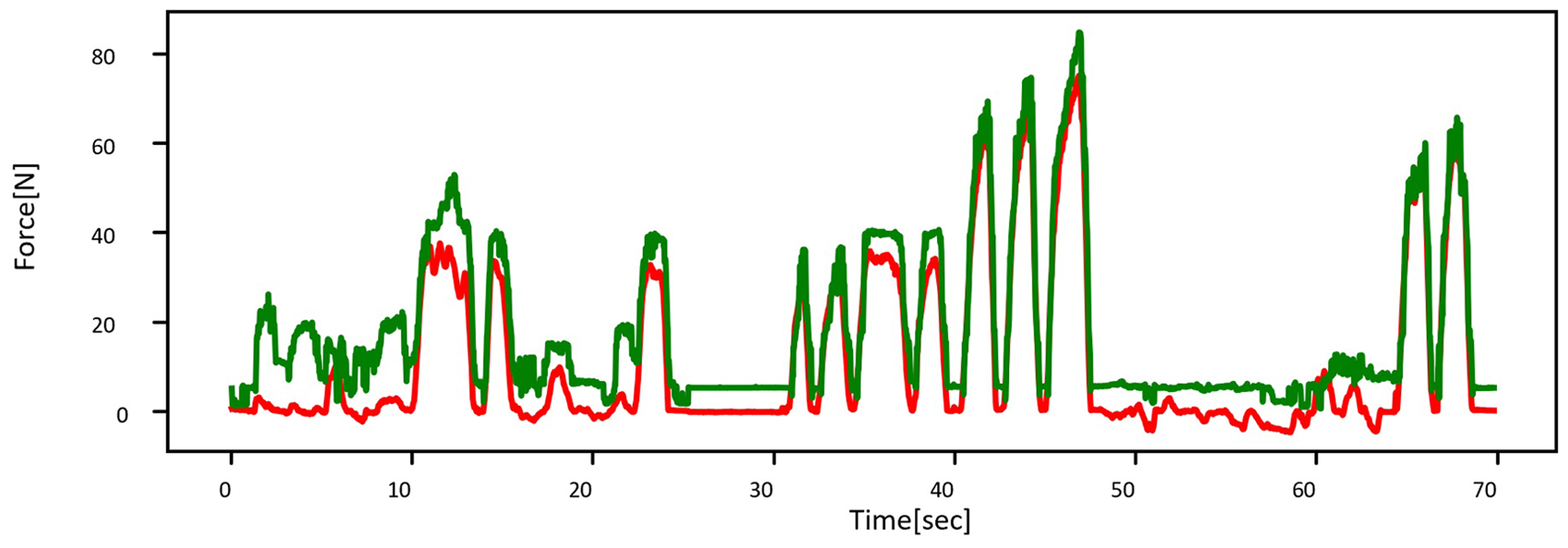
The robot was set to move on a flat surface according to the trajectory, as shown in Figure 11(a). The same commercial six-axis force sensor was also mounted on the end effector to provide the ground truth force data as shown in Figure 11(b). The robot was set to apply 60 N on the surface, and Figure 12 shows the results. The average error and standard deviation of the errors between the estimated and measured forces are 7.995 and 5.843 N, respectively. Wiping the table was the first set of experiments conducted to evaluate the performance of the virtual force sensor. Unlike the peg-in-hole task, which utilized impedance control, simply digitized position control was utilized in this set of experiments, where the compensated displacement was directly determined by the force error without using impedance.

The trajectory and setup of the wiping the table experiment.
In the wiping the table experiment, the manipulator was set to wipe the table with constant 60 N force (dashed line). The dashed-dot and solid curves represent the estimated and measured contact forces between the robot and the table, respectively.
Peg-in-hole
The virtual force sensor was then applied in the peg-in-hole manipulation task, which requires force/torque sensing information. As stated in the literature,22–24,27 the peg-in-hole task was designed to be utilizable in the following circumstances: (i) no requirements for the models of the peg, the hole, or the environment; (ii) the peg and hole should be nearby initially, but their relative position and orientation are unknown; (iii) the hole does not have a guiding edge or a chamfer for easy assembly.
The peg-in-hole process involves multiple contact scenarios where the force/torque conditions vary. If the force/torque of the virtual sensor
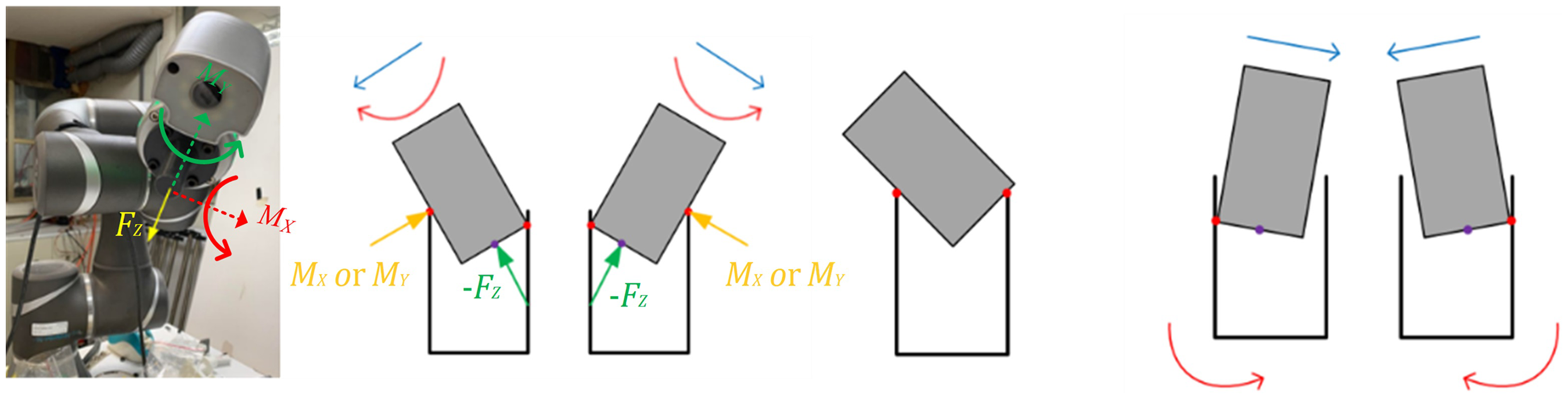
The peg-in-hole process: (a) approach the hole and two contact scenarios, (b) stuck outside the hole and (c) stuck inside the hole.

The control strategy of the peg-in-hole task; (a) the overall control structure; (b) the control flow chart.
During the peg-in-hole process, impedance control was utilized.52,53 The system was modeled as a spring-damper mass system:


After understanding the main three contact states of peg and understanding how to convert the force change into position control (impedance controller), then look at the detailed description of the control strategy of the peg-in-hole task in Figure 14. When starting to execute the strategy loop of the control strategy of the peg-in-hole task, the state of the manipulator (including the angular position of each joint, angular velocity, angular acceleration
The peg-in-hole strategy, which utilizes information derived from the virtual force sensor, was experimentally evaluated. The depth and diameter of the hole were set to 30 and 21.8 mm, respectively. Figure 15 shows snapshots of the experiments using a peg 40 mm in length and 220 mm in diameter. The MAE of the force/torque values between the commercial sensor and virtual sensors is 0.378 Nm (

Snapshots of the peg-in-hole experiment.

The top 6 subfigures illustrate the displacement and direction of peg (the coordinate information is defined in Figure 1(b)). The bottom 3 subfigures display the force signal of the peg (the coordinates are defined in Figure 6(a)).
Speed optimization of trajectories
The optimized trajectories were first learned and simulated with the physics-data hybrid dynamic model (simulator) and then the experiment was conducted with the TM5-700 manipulator to verify the trajectory planner. The baseline trajectory was generated by selecting three trajectories as in Table 8 (Trajectory 1, 2, and 3). Each trajectory was planned with the simulator and the experimental results are in Table 8. The “Original” represents the elapsed time without speed optimization and the “Optimized” stands for the time with speed optimization. The speed optimization method successfully reduced the elapsed time by an average of 20% for three trajectories. To conclude, the motion planner developed in “Design of a motion planner” section is functional and succeeds in reducing the elapsed time of two selected trajectories.
Trajectories before and after speed optimization (unit:sec).

Conclusion and future work
In this article, we reported on the development of a virtual force sensor and a motion planner of a manipulator based on the physics-data hybrid dynamic model. The hybrid model has the best accuracy compared to the physics-based model and requires less training data compared to the data-driven model. Furthermore, the modeling results reveal that among the tested DNN-based, LSTM, and XGBoost architecture with hyperparameter optimization, XGBoost performs the most accurate modeling of the manipulator dynamics including un-modeled dynamics.
The external torque of the manipulator is then derived by subtracting the derived internal torque from the total motor torque. The external torque is further transformed into a three-axis virtual force/torque on the end effector through a geometrical relation and machine learning technique. Finally, the virtual sensor is utilized in two applications. For wiping the table task with a designated normal force of 60 N, the average error and standard deviation of the errors between the estimated and measured forces are 7.995 and 5.843 N, respectively. For the peg-in-hole tasks, a peg 48 mm in length and 21.4 mm in diameter is able to be plugged into a hole 30 mm in depth and 21.8 mm in diameter. The MAE of the force/torque values between the commercial sensor and the virtual sensors is 0.378 Nm (
We are in the process of refining the model so that it can compensate for the dead zone or friction effector of the manipulator more accurately. The model will be evaluated using different states as well. Furthermore, we plan to design an advanced controller and sim-to-real skill transfer for the manipulator based on the developed hybrid dynamic model (digital twin).
Footnotes
Authors’ contributions
All authors contributed to the study conception and design. Material preparation, data collection, and analysis were performed by Jyun-Ming Liao and Wu-Te Yang. The first draft of the article was written by Jyun-Ming Liao, and it was revised by Wu-Te Yang. The final article was written by Pei-Chun Lin. Pei-Chun Lin also acquires funding and supervises and manages the project. All authors read and approved the final article.
Preprint acknowledgement
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the National Science and Technology Council (NSTC), Taiwan, under contract: MOST 110-2634-F-007-027- and MOST 111-2634-F-007-010-.
Data availability
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.