
Abstract
Since performing simultaneous localization and mapping in dynamic environments is a challenging problem, conventional approaches have used preprocessing to detect and then remove movable objects from images. However, those methods create many holes in the places, where the movable objects are located, reducing the reliability of the estimated pose. In this paper, we propose a model with detailed classification criteria for moving objects and point cloud restoration to handle hole generation and pose errors. Our model includes a moving object segmentation network and an inpainting network with a light detection and ranging sensor. By providing residual images to the segmentation network, the model can classify idle and moving objects. Moreover, we propose a smoothness loss to ensure that the inpainting result of the model naturally connects to the existing background. Our proposed model uses the movable object’s information in an idle state and the inpainted background to accurately estimate the sensor’s pose. To use a ground truth dataset for inpainting, we created a new dataset using the CARLA simulation environment. We use our virtual datasets and the KITTI dataset to verify our model’s performance. In a dynamic environment, our proposed model demonstrates a notable enhancement of approximately 24.7% in pose estimation performance compared to the previous method.
Introduction
Light detection and ranging (LiDAR)-derived point cloud data is extensively utilized in robots for simultaneous localization and mapping (SLAM). The method of creating maps and estimating locations through point cloud feature matching, as presented in Zhang and Singh 1 and Shan and Englot, 2 has demonstrated excellent performance and rapid computation. However, the majority of SLAM algorithms have been developed for static environments. Using extracted features from moving objects for feature matching in dynamic environments can result in pose estimation errors. To address this challenge, a technique was introduced in Sun et al. 3 and Rashed et al. 4 to identify and remove moving objects’ corresponding features. To cope with dynamic environments, additional sensors such as radar and camera5,6 can be used to materialize information, or the object’s characteristics can be learned through deep learning. 7 As the number of moving objects increases, removing a larger number of points can lead to the generation of multiple holes. These holes can subsequently result in pose estimation errors.
SAM-Net 8 was initially introduced to address the issue of errors caused by holes. It is a segmentation model that uses a binary mask to isolate movable objects such as vehicles and people, and then employs an inpainting network to restore the masked regions. However, completely removing movable objects through the segmentation process may lead to the loss of valuable information required for feature matching. Moreover, the restored information may not reflect the characteristics of the point cloud, resulting in distortions.9,10
To maximize the number of features utilized for achieving the objective illustrated in Figure 1, we propose an inpainting learning model that focuses on classifying only moving objects, along with a loss function that reflects the point cloud’s characteristics. The proposed model requires a residual image that is obtained by utilizing a continuous point cloud, enabling the classification of moving objects by learning object motion information between continuous point clouds. Additionally, we emphasize the importance of maintaining consistency between the proposed model’s results and the actual background to generate valid feature points. To achieve this, we introduce a loss function that utilizes one of the point cloud’s features, that is, smoothness.1,2 By utilizing the association between multiple points, the proposed loss function generates points that are similar to their surroundings, which results in inpainting and feature points that are more similar to the ground truth compared to the previous model.

Purpose of this paper. After determining and removing moving objects from the point cloud, the proposed model restores the hidden points through the inpainting process.
To train the proposed model, we created a new dataset using CARLA simulation because the existing dataset lacked ground truth for the regions obscured by moving objects, despite containing labels for the moving objects themselves. The moving objects were classified using CARLA’s semantic sensors, and a moving object label was assigned based on their speed.
The proposed model has the following contributions:
Our proposed inpainting model uses residual images to generate labels for moving objects, thereby reducing the loss of points and errors in pose estimation caused by the identification of movable objects. The smoothness loss function relies on planar and edge feature points obtained through point association to produce results that seamlessly integrate the static background with the inpainted regions. To improve the inpainting model’s performance and overcome the limitations of artificial data generation, we created a realistic dataset using the CARLA simulator. The model learns from various situations in this dataset, which aids in accurately classifying moving objects.
The remainder of this paper is organized as follows. Section “Related works” describes the use of LiDAR sensors for feature and SLAM, including an explanation of the reason for SLAM performance degradation in a dynamic environment and the proposed method for solving it. In addition, the prior inpainting model is described and a method to improve it is proposed. Section “Proposed model” Section explains the data generation methods, input data changes, and new loss functions of the proposed model. In Section “Experiments,” Section the segmentation, inpainting, and SLAM performance of the proposed model and the prior model are compared using the generated CARLA dataset. The suitability of the proposed model is then verified not only in the simulator, but also in the real environment using the KITTI
11
benchmark dataset. Finally, Section “Conclusion” Section provides the conclusion and outlines the future directions of this work.
Related works
Feature extraction with LiDAR
A LiDAR sensor retrieves three-dimensional (3D) points indicating the position of point clouds on surfaces detected by the sensor. This output can be utilized for feature extraction of important surrounding objects. However, complete processing of LiDAR sensor data can be costly. To enhance processing speed, research has focused on selecting feature points to represent point clouds, rather than utilizing all points. For instance, the normal aligned radial feature 12 can reliably extract normal vectors in environments with distinct changes between point clouds, while the fast point feature histogram 13 employs multiple histograms to expedite calculations. However, these methods are primarily applicable in environments with sensors that yield dense point clouds, such as red–green–blue-D (RGB-D), and may pose challenges when applied to external environments using LiDAR. Recently, a prominent approach for feature extraction involves the utilization of the PointPillars14,15 model. This method, however, has limitations, including difficulties in effectively handling multiple nearby objects and reduced reliability in regions with sparse features. To address this challenge, a method 1 was employed to extract surfaces and edges representing point clouds by expressing point associations. In this paper, we incorporate the corresponding feature points into a loss function to ensure continuity between the existing background and the inpainting result.
LiDAR implementation in SLAM
Generating feature maps from LiDAR output is challenging due to its limitations. To produce precise LiDAR maps, traditional methods often involve applying filters.16,17 However, these methods are restricted to two-dimensional (2D) points and are inefficient for generating 3D maps. To address these challenges, several studies have explored leveraging feature or semantic information to enhance SLAM performance while reducing computational costs. For instance, LiDAR odometry and mapping (LOAM) 1 extracts surfaces and edges using the smoothness feature of points and creates a map in real-time through feature matching. Its extension, LeGO-LOAM, 2 improves SLAM performance by removing redundant ground point information and optimizing with the Levenberg–Marquardt algorithm. However, in complex environments, such as urban areas, SLAM performance deteriorates due to the assumption of static surroundings.
Recent studies3,18,19 have proposed approaches to remove dynamic objects and improve SLAM performance in dynamic environments. For instance, SUMA++ 20 uses deep learning to label objects and generates surfel-based maps from continuous scans. By identifying changes in the surfels of dynamic objects in the generated map, moving objects can be removed. However, this method may create holes where dynamic objects were removed, leading to errors in pose estimation.9,10,8
Inpainting method
In recent years, deep learning-based inpainting methods using generative adversarial networks (GANs) have been proposed for filling holes in images.21–23 In the context of SLAM, an inpainting model based on image features has also been introduced.24,25 This model utilizes an Oriented FAST and Rotated BRIEF-based loss to minimize feature distortion in the inpainted results, resulting in improved performance in place recognition and visual odometry. Several SLAM algorithms exist that incorporate inpainting results, similar to the approach described in Ai et al. 26 and Bescos et al. 27
With the inpainting model, LiDAR and RGB images can be utilized to enhance the point cloud density via deep learning.28–30 However, rather than creating points directly in obscured areas, this method involves filling in empty spaces due to the low density of the point cloud. In the field of LiDAR superresolution, a learning-based model31–33 is employed to transform low-resolution LiDAR point cloud data into high-resolution data. This approach aims to increase the resolution by directly generating points, prioritizing resolution enhancement rather than filling in occluded areas. SAM-Net 8 has introduced a novel approach to restoring parts covered by objects using LiDAR point clouds through learning. Nonetheless, this model has some limitations as it removes points without taking the object’s motion into account and the restoration process may not fully reflect the point cloud’s characteristics.
Proposed model
LiDAR point preprocessing
In order to utilize 3D point cloud data in deep learning applications, it is necessary to convert it into 2D range images. This conversion not only simplifies the data interpretation process, but also enables the use of various 2D convolutional neural networks designed for image processing, which can yield valuable insights. Range images are a popular method used in LiDAR-based learning models,7,34 which we will briefly discuss in this paper.
To define a single LiDAR point

The range image has vertical and horizontal dimensions denoted by
The previous network only relied on this method as input throughout the model’s process. However, it is challenging to identify crucial feature points for pose estimation, especially those associated with stationary vehicles, when removing all movable objects. Furthermore, using only the gradient loss function proved ineffective in restoring feature points in range images, as 3D point clouds were compressed into 2D depth images. Therefore, our proposed model employs a residual image as additional input, denoted as
Residual images are created to capture the differences in distances between two point clouds in 2D, facilitating the network’s ability to learn the motion of objects by using only LiDAR data. To generate a residual image, the point cloud
The residual information of a single LiDAR point

Model
In this section, we present the proposed model, which is an extension of a previous network 8 with input data and loss function modification. Our model aims to distinguish and remove moving objects using segmentation while restoring the background using inpainting. To achieve this, we employ a single encoder and two decoder modules to detect moving objects and generate new points through inpainting. Figure 2 illustrates the proposed model’s framework and output.

Framework of the proposed model. The proposed model learns the movement of moving objects through inputs including residual images and generates a binary mask using a segmentation module. The results of the encoder and segmentation module are used to remove moving objects and restore the points of the hidden static part through the inpainting module.
The encoder network comprises five convolution layers. The first convolution layer extensively scans a large area to increase receptive fields. The following convolution layers generate a feature map containing the characteristics of moving objects from the residual images as the input. This whole process of the encoder modules produces a feature map with 128 depth channels, serving as the input for the segmentation and inpainting network. Additionally, each convolution layer that generates a feature map is connected to the inpainting network as a skip connection for reconstructing the object-segmented area.
The segmentation process resembles the precursor model, which acts as a decoder of the model. The model consists of four upsample groups and a single refine group. Each upsample group contains two convolutional layers followed by a nearest neighbor upsampling layer. The single refine group consists of two convolutional layers, serving as the refinement process for segmentation. It is worth noting that every convolutional layer in the segmentation utilizes LeakyReLU as the activation function, as the range of images retrieved ranges from
After the segmentation process, the output will result in a binary mask containing background information (as shown by the black region in Figure 2). The inpainting network will use this as one of the inputs along with the result from the encoder. Specifically, the inpainting network consists of three fusion blocks. Each fusion block receives inputs from three sources: the feature map from each encoder stage, the binary mask from segmentation, and the previous fusion block. This process enables reconstruction of the missing regions. 8
By maintaining these modules, the proposed approach effectively reduces pose estimation errors and improves the overall accuracy of the system. Finally, to restore feature points, we use a loss function that reflects the correlation of distances between multiple points, as described in section “Smoothness loss
Smoothness loss
Smoothness feature points are crucial in 3D LiDAR SLAM for accurate pose estimation by identifying edges and planes of corresponding points. These feature points have demonstrated their effectiveness in LOAM, LeGO-LOAM, and other studies. In this section, we explain how to obtain smoothness and how to apply a new loss function to these feature points.
After converting LiDAR points to a range image, we can define the query point

To formulate (3) as a loss function, as shown in Figure 3, we employ max pooling and convolutional layers. However, in the case of LiDAR points, some pixels in the range image lack depth information due to the low density of the sensor data. To address this issue, the approach of obtaining the maximum depth value using max pooling is applied and the range image is compressed to exclude these pixels. Following that, a novel kernel inspired by Bescos et al.
25
is utilized to calculate the smoothness of all points in the row direction. Finally, the comparison of smoothness generated from the inpainted image


Structure of smoothness loss. By max pooling,
The use of max pooling can result in data compression and loss. To mitigate this issue, a
Total loss
To perform inpainting of the region where the deleted moving objects are located, GANs are employed. The generator and discriminator are trained using the same hinge loss, as in SAM-Net, which is a model that utilizes the structural information of images based on structural similarity index measure.
35
The goal of SAM-Net is to remove static objects and restore empty regions in images. The training process involves utilizing the hinge loss, denoted as



Generating the data
The data required to specify a dynamic object and proceed with inpainting includes ground truth data without dynamic objects, raw LiDAR data with dynamic objects, and labels that distinguish dynamic objects. However, existing datasets such as KITTI and Oxford Car 36 do not provide semantic information for dynamic objects, and it is challenging to use them to train an inpainting model since obtaining ground truth data for the parts occluded by dynamic objects is difficult. Furthermore, Semantic KITTI 37 does not meet our requirements as it provides labels for dynamic objects but does not supply static LiDAR point information for the occluded regions. To tackle this issue, a previous study 8 proposed a dataset generation method using KITTI. However, it is challenging to create a dataset that closely resembles an actual driving environment because this method relies on an artificial arrangement of the object’s point cloud in an empty space.
To overcome the limitations of previous datasets and data generation methods, and to train the proposed model to handle moving objects and the occluded parts caused by them, we present a new dataset created using CARLA. 38 Initially, a raw dataset, including moving objects such as various vehicles and pedestrians, is generated through LiDAR and LiDAR semantics. A point cloud can be obtained through LiDAR, and the ground truth labeling that classifies moving objects can be obtained using LiDAR semantics. Then, to obtain the ground truth data for the parts covered by the dynamic object, a LiDAR point cloud is created through simulation, excluding the dynamic object in the same environment. In two separate simulations, the location of the vehicle with LiDAR attached is recorded in frame units. By comparing the poses recorded and matching the frames with the same pose, the input and ground truth data required for learning can be generated. The dataset was created by driving in two different environments. The LiDAR settings 39 were the same as those used in KITTI, the most commonly used dataset for evaluating the performance of algorithms using LiDAR. This allowed us to generate data, including natural situations in the real world, such as overlapping or overtaking vehicles, as shown in Figure 4, which influenced the classification of dynamic objects by learning models.

Dataset created through CARLA. Acquire a natural point cloud as a dataset for inpainting. (a) Overlapping objects move with each other according to frame conversion. (b) The object overtakes, changing its speed according to the environment.
Experiments
Setting
To verify the performance of the proposed model, we check the performance of segmentation, inpainting, and location estimation. Segmentation and inpainting performance are compared with SAM-Net and pose estimation performance is compared with LeGO-LOAM and the method adding LeGO-LOAM and the proposed model. Finally, to evaluate the performance of the proposed model in the real environment, the performance of location estimation is verified using KITTI’s road data.
The dataset was created using CARLA, simulating a scenario in which a hundred vehicles are moving in Town 1 and Town 4. This implementation was chosen due to the diversity of dynamic object appearances provided by this dataset. The dataset has the capability to produce random natural behavior and movement for vehicles and pedestrians. For instance, vehicles are programmed to follow lanes, respect traffic lights, adhere to speed limits, make decisions at intersections, and avoid pedestrians. Meanwhile, pedestrians are set to wander around the town map, along sidewalks, marked road crossings, and avoid each other and vehicles. Based on these scenes, LiDAR and LiDAR semantic data were used to generate the dataset, producing range images and residual images. The range images are reshaped into
The proposed model is labeled “Proposed” and the comparison algorithm is labeled “SAM-Net.” Segmentation results are compared through precision
Segmentation performance
The output of both models consists of binary masks, which are compared at the pixel level with the ground truth for the purpose of detecting moving objects. A higher precision implies that the model exhibits fewer instances of erroneously labeling non-moving regions as objects. On the other hand, a higher recall indicates that the model successfully identifies a significant portion of the actual moving object areas.
Figure 5 and Table 1 show the performance of the proposed and SAM-Net models in a dynamic environment. The ground truth labels were trained to classify moving objects, and the difference between residual image and single image learning methods is demonstrated. The proposed model achieves high performance by generating a binary mask that extracts the motion of an object through residual images. In contrast, SAM-Net, which uses a single image, struggles to learn the motion of objects and cannot effectively extract features for moving objects or classify them. In broader impact, this improved segmentation performance has implications for obstacle avoidance. Therefore, enhancing segmentation is crucial as it directly benefits scenarios requiring obstacle avoidance.

Segmentation results on several dynamic cases. The figure on the left (a) describes a pedestrian in the distance with a queue of cars. The figure on the middle (b) shows the dynamic scene of a solely car in the front. The figure on the right shows (c) shows more crowded cars, which are coming along two directions, aligned and perpendicular with the view moving direction.
Comparison of the precision

Inpainting performance
The output generated by the inpainting network includes

The result of inpainting. The figure on the left shows raw including moving objects, ground truth with moving objects removed, inpainted image obtained through the model used, and diff, which is the difference between ground truth and inpainted image. The right side is a three-dimensional (3D) point cloud representation. Blue points are static points, orange points are ground truth, and red points are the result of inpainting.
Quantitative analysis of RMSE (mm), MAE (mm), iRMSE (1/km), iMAE (1/km) upon the depth of the proposed model against SAM-Net.
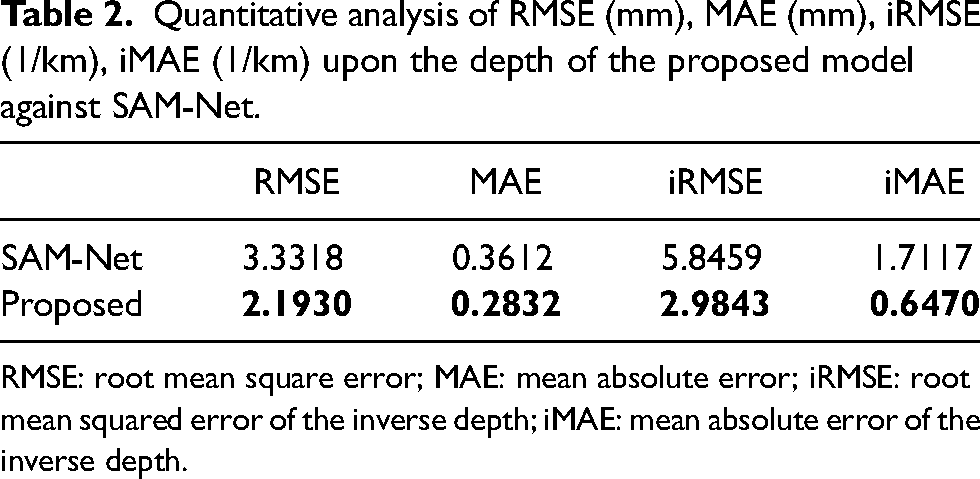
RMSE: root mean square error; MAE: mean absolute error; iRMSE: root mean squared error of the inverse depth; iMAE: mean absolute error of the inverse depth.
For further analysis, the inpainting output of 3D points is also examined. In this aspect, the proposed model outperforms the SAM-Net model. The proposed model’s 3D points output maintains surface and edge characteristics more effectively than SAM-Net. This is demonstrated by the alignment of the inpainted 3D points (red points) with the ground truth (blue points), where the proposed model shows superior performance compared to SAM-Net. This improvement is primarily due to the enhanced smoothness loss function, which prevents abrupt changes in the gap region, and the implementation of the Steganalysis Rich Models kernel 25 in the inpainting process. Consequently, the proposed model performs better at interpolation. For a clearer comparison of the 3D points, refer to Figure 7.

Three-dimensional (3D) result of inpainting. Blue points are static points, orange points are the ground truth, and red points are the result of inpainting.
SLAM performance
Table 3 shows a comparison between LeGO-LOAM and the proposed when used together with LeGO-LOAM. When the proposed is used together with LeGO-LOAM, it shows better performance in environments with many moving objects. In particular, when surrounded by multiple moving objects, a better pose is estimated by removing the moving objects and creating new points for feature matching. Figure 8 show the estimated route for Town_1 and Town_4. In the case of Town_4, the overall performance of position estimation deteriorates as moving objects rotate at high speeds. However, while LeGO-LOAM judges it to be a straight path due to being surrounded by moving objects in a rotating situation, the proposed correctly rotates by removing the moving object and restoring new points.

Trajectory of Town1 (a) and Town4 (b).
Comparison of root mean square error (RMSE) [m, degree] of the proposed method against LeGO-LOAM.

Performance on KITTI
To validate the performance of the proposed method in the real world, we experimented on 2011_09_26_drive_0015(seq_30), 2011_09_26_drive_0028(seq_32), and 2011_09_26_drive_0029(seq_33). 20 Figure 9 shows the estimated trajectory of the LeGO-LOAM and the proposed method, and Table 4 is the comparison result. The LeGO-LOAM accumulated errors due to the position estimation based on features extracted from moving objects. In contrast, the proposed method for seq_30 and seq_32 can achieve better results by removing invalid feature points and restoring the background to recover valid points. On the other hand, for seq_33, not only the moving object but also the surrounding background is erased in the segmentation result initially, resulting in an error in pose estimation due to the loss of feature points. To address this issue, it is necessary to improve the method’s generalization performance by training it on a larger and more diverse dataset.

Trajectory of seq
Comparison of root mean square error (RMSE) [m, degree] of the proposed method against LeGO-LOAM in KITTI.

Conclusion
This paper presents a novel LiDAR point cloud inpainting model that effectively removes moving objects in a dynamic environment and restores valid points. Our proposed model differs from existing models by selectively removing only the moving objects from the potentially mobile ones, thereby preserving valid information to the maximum extent. Additionally, to better distinguish moving objects, we utilize residual images to generate a binary mask through the segmentation decoder. This mask is then employed to remove the moving objects and restore the empty areas using the inpainting decoder. To produce more natural results than previous models, we incorporate a smoothness loss into our model. Our proposed model demonstrates superior performance in moving object segmentation and inpainting on two datasets generated via the CARLA simulator, and it also improves the performance of the SLAM algorithm. We validate the effectiveness of our model on the KITTI dataset and show a promising result as well.
As future work, the model requires an improvement toward the ability to align the correct points in the further distance in order to obtain a more robust mapping process in terms of point cloud usage. For broader implications might also be found to use the model in moving obstacle avoidance, since it has good performance in detecting any moving object based on residual images. All of these improvements will be a great thing for the implementation of this model.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.