
Abstract
Lifting path planning is critical for the safety and efficiency of tower cranes operating in dynamic construction environments. This paper proposes a lifting path planner to efficiently generate safe and smooth lifting paths for tower cranes in an unknown construction environment through a deep reinforcement learning (DRL) method. Based on the Twin-Delayed DDPG (TD3) framework, the planner effectively plans a lifting path within constraints of collision avoidance and operational limitations using the local environmental information measured by lidar. A Long Short-Term Memory network is applied in the planner to handle the dynamic characteristics of the obstacles in the construction sites to ensure that the lifting path is collision-free with dynamic obstacles. A discrete-continuous hybrid action space for tower cranes is proposed to optimize planned lifting paths more suitable for practical engineering operations. Moreover, a novel reward function is introduced to optimize the smoothness of the lifting path, which improves the success rate and optimizes the energy and time cost. A new Hindsight Experience Replay algorithm is proposed to address the reward sparsity problem in lifting path planning, which improves the training speed. Simulation results in Webots platform show the presented method effectively reduces the planning time and achieves better performance on online path planning compared with the existing DRL path planning methods.
Introduction
Cranes have been widely used for hoisting and conveying heavy loads in industrial factories and construction sites.1,2 The highly congested and ever-changing conditions of construction sites increase the potential risk of crane operation. Thus, lifting path planning for cranes is a key problem for the safety and productivity of lifting operations. Automated lifting path planners can provide a collision-free optimal path for cranes to improve construction efficiency and safety in crane lifting practices. Lifting path planning should take the kinematics of cranes, mechanical, kinematical constraints of cranes, size of loads, and obstacles in the sites into account, which is more complicated than traditional path planning. In practical engineering, the lifting path planning heavily relies on the experience and intuition of experienced lift engineers, which is both time-demanding and potentially risky. Therefore, a number of lifting planning algorithms are proposed for lifting path planning such as sampling-based algorithms, 3 and graph search algorithms. 4
Some mature robot path planning algorithms have been successfully applied to the research of crane path planning which can quickly and efficiently generate the lifting path in a static environment. The graph search algorithms find a feasible plan in the pre-computation configuration space (C-space) which is among the early efforts. 4 However, this efficiency highly depends on the high quality of the C-space, and the pre-computation of C-space in a dynamic and high DOF environment makes the graph search algorithm inefficient. Due to the strong capability in space exploration, the sampling-based algorithms, Rapidly-exploring Random Tree algorithms, 5 use collision detection of sampling points to explore a feasible path without the explicit modeling of the environment space, which reduces the computation time and resources. However, the lifting path generated by this method is not necessarily an optimal search. The artificial potential field method prevents the robot from colliding with the obstacle by generating a repulsive force from the surrounding obstacles. 6 The aforementioned methods are limited to generating an initial path for a static environment and cannot deal with the dynamic environment with the movement of vehicles and people and the construction of new buildings which are common scenarios in construction sites.
Compared with static environments, fewer studies have focused on lifting path planning in dynamic environments, including a computationally expensive C-space. As for dynamic environments, a new path should be replanned whenever the initial path is infeasible due to the dynamic obstacles appear. Rapid re-planning is essential for lifting in a dynamic environment. The early approaches are to update the map first, and then replan an optimal path from the current state when the environment changes or the paths become unavailable. This method can obtain the optimal path, but the efficiency is grossly inefficient. 7 Focused Dynamic A* (D*) algorithm 7 and Two-Way D* (TWD) algorithm 8 only deal with the affected part of the state space, which greatly reduces the computation time. Sampling-based algorithms9,10 and evolutionary algorithms11,12 are also used in dynamic path planning. Following a re-planning decision system based on a single-level depth map, a master-slave parallel GA based local path re-planner could re-plan a collision-free optimal lifting path in near real-time in a complex construction environment. 13 The above methods need to determine whether re-planning the path according to continuous collision check. The new re-planned collision path may become unworkable while dynamic obstacles are detected the next time, which leads to inefficient replanning.
To reduce the computational cost of modeling the whole environment, some path-planning algorithms for unknown environments have been proposed in recent years. These kinds of algorithms use robot sensors to obtain information about the environment around the robot to achieve path planning. Recently, path planning methods for unknown environments such as genetic algorithms,14,15 ant colony optimization, 16 bacterial foraging optimization are used. 17 Neural networks have been wildly applied for path planning algorithms in unknown environments due to their strong environmental adaptability and autonomous learning ability.18,19 A feedforward neural network with a sonar signal is used to navigate the robot from any current position to the goal position. 20
However, the aforementioned supervised learning requires a lot of training data representing all possible situations. Due to the strong perceptual ability and decision-making ability, deep reinforcement learning (DRL) algorithms, an unsupervised learning method, have also been tried out for path planning by several researchers.21–24 Limited work has been reported on lifting path planning for cranes in dynamic environments. Guo et al. 25 use Deep Q-network (DQN) with Resnet block to achieve real-time path planning for crawler cranes by taking lidar signals as input. However, the DQN can only output discrete actions and requires pre-training with an artificial potential field method.
After a careful literature review, there are still many crucial aspects of crane path planning that still require further improvement, which are summarized as follows. (1) Many path-planning algorithms still require significant time and memory to generate maps. Especially in dynamic environments, these methods must update the map and then replan the path when new obstacles are detected, which greatly reduces the efficiency of path planning. (2) Many crane path-planning methods treat the crane as a mobile robot. However, the operation of tower cranes primarily involves jib rotation, trolley translation, and cable lifting, which differs from the omnidirectional movement of mobile robots. This discrepancy makes it challenging for mobile robot path planning algorithms to generate smooth lifting paths for cranes. (3) Due to the complex construction environment, lifting path planning of tower cranes is a complex sequential manipulation task with sparse reward, presenting significant difficulties for the training process in reinforcement learning.
In order to overcome those problems, this paper proposed a DRL based lifting path planning algorithm for tower cranes in unknown dynamic environments using the Twin-Delayed DDPG (TD3) framework. The input of the DRL network is local environmental information measured by a lidar mounted above the hook. The output is the crane movements with its speed. The mapless online lifting path planner is trained end-to-end from scratch through the TD3-based DRL method.
The main work of this paper can be concluded as follows: (1) The path planning algorithm developed in this work does not rely on global environmental modeling and only requires local environmental information measured by lidar. (2) Combined with the operating characteristics of tower cranes, a discrete-continuous hybrid action space for tower crane control is proposed to smooth the generated lifting paths of tower cranes. A new reward function is designed to improve lifting path efficiency by considering energy, path smoothness, and time cost. (3) A Hindsight Experience Replay (HER) strategy is proposed for the training of the lifting path planning networks, which can improve the convergence speed of the model in the training process.
Path planning for tower cranes
Problem description of tower crane lifting path planning
As shown in Figure 1, the operations of tower cranes can be represented as four fundamental operations (Dofs): slewing (angular movement of a crane arm), trolley movement (along the slewing arm), hoisting (sling extension or retraction), and hook (load) rotation. The rotation of the load (hook) in practical engineering is not controlled by the crane, so its rotational motion is not considered in this paper. Therefore, the load position can be represented as the tower crane posture

The fundamental operations and structures of the tower crane.
Different from traditional path planning methods, the proposed method does not rely on global environment modeling, so it is more efficient to obtain collision-free lifting paths in unknown dynamic environments. The input of the tower crane is only the entire points cloud of the surrounding environment measured by the lidar. To obtain complete information, the lidar is mounted on the hook above the load as shown in Figure 1. The following assumptions regarding tower cranes are used in the lifting path planning:
To simplify the research, the lifting rope is assumed to be a rigid rod without dynamic characteristics, which is widely used in lifting path planning studies.26–28 Therefore, smooth velocity changes and load swing suppression are also not taken into account. In our study, the proposed method aims to provide a desired collision-free path for crane transport tasks. Crane can utilize a swing suppression control system to track the planned collision-free path while suppressing load swing. The speeds of fundamental operations (slewing, trolley movement, hoisting) are unchanged in each time step.
Path planning in unknown environments can be regarded as a Markov decision process (MDP) defined using a tuple
TD3 algorithm for lifting path planning
TD3 is an actor-critic reinforcement learning framework, which consists of critic (value) networks and actor (policy) networks. The actor network
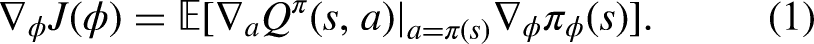

For a large state space, the value function

In order to alleviate the overestimation of the value function, the TD3 algorithm introduces two independent critic networks:


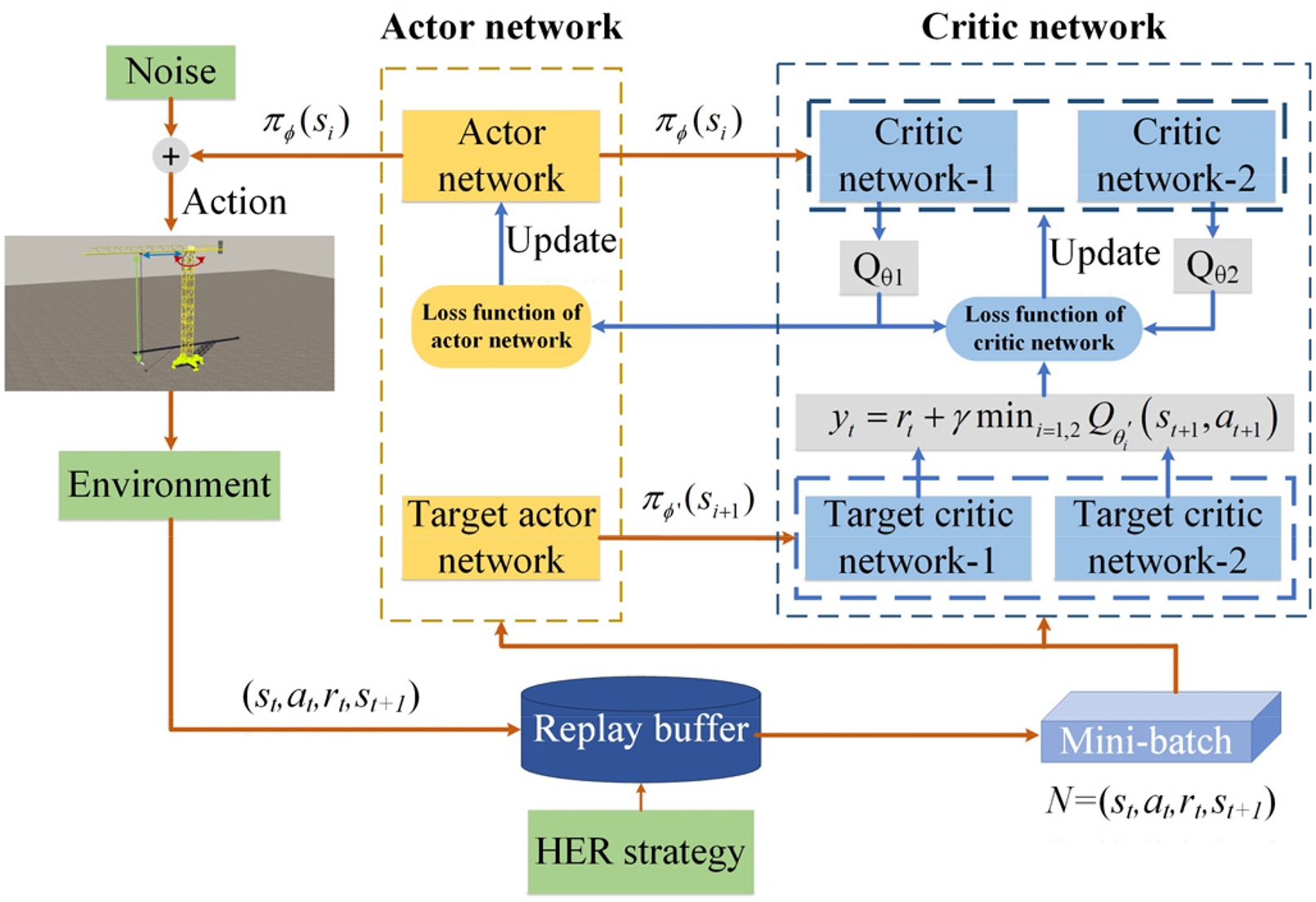
Overall workflow of the proposed TD3-based lifting path plan method.
The parameters of target critic networks

It should be noted that the TD3 is updated in an off-policy manner. As shown in Figure 2, the agent controlled by actor network interacts with the environment to generate a series of transition tuples
Path planning method based on DRL
In this section, a DRL method is proposed based on the Twin Delayed Deep Deterministic Policy Gradient (TD3) framework to obtain a collision-free planning path in unknown construction environments. First, we propose a new action space for tower crane operations. Then the TD3 method used for real-time lifting path planning and network architecture is introduced. A reward function for smoothing the lifting path is proposed. Finally, a novel HER strategy is introduced to accelerate the training speed.
Discrete-continuous hybrid action space
Since cranes are not as flexible as robots, the continuous action space of robots is not suitable for crane operation. Moreover, the discrete action space can only use a few operations that are specified in advance, which is not efficient for transportation. Therefore, a discrete-continuous hybrid action space consisting of discrete action space K and continuous action space X is introduced. Firstly, the discrete action space K denotes the fundamental operations of the tower crane (slewing, trolley movement, hoisting). k is a selected fundamental operation of a tower crane from discrete action space K at each time step. It should be noted that for the sake of construction safety, multiple operations are not allowed to be performed at the same time. Secondly, the continuous space X represents the speed of each fundamental operation at each time step. Therefore, the hybrid action space A can be written as follows:

Network architecture
The network structure is depicted in Figure 3. The input of the actor network is a point cloud around the load measured by the lidar with the size of 126 × 16. To avoid loss of target information, the goal position and current position are also input to the actor network as a vector. Due to the complexity of the lidar points cloud, the three convolutional layers are used to extract the feature representations from the lidar data. The three convolutions with different kernel sizes (i.e. 8 × 4, 4 × 2, and 3 × 1) increase the channels to 64. The Rectified Linear Unit (ReLU), a nonlinearity activation function, is adopted after each convolution layer to increase the nonlinearity for better data fitting. Subsequently, the feature representations of lidar and the load position are concatenated together and input into one Long Short-Term Memory (LSTM) layer with 1088 input size and 256 output size, which can handle the processing sequence data. The activation function in the LSTM model is ReLU. LSTM in the model is used to predict the dynamic obstacle information to optimize the lifting path. Finally, the data is fed into three fully connected layers to output a 1 × 3 vector x representing the moving speed of three fundamental operations.

The network structure of the actor and critic network.
The critic network structure is the same as the actor network. The vector x output from the actor network is input to a final fully connected layer of the critic network. The output of the critic network is also a 1 × 3 vector representing the evaluation value of the three operations (slewing, trolley movement, hoisting) in discrete action space. We select the operation with the highest evaluation value as the operation k executed at this time step. Then the execution action

Reward function
The reward function greatly influences the decision of the agent. As mentioned above, the optimal path planning problem is to find the optimal path in terms of energy, transportation time, and the smoothness of the path. The energy of the path is determined by the sum of the movement distances of fundamental operations (slewing, trolley movement, and hoisting). Since each action takes the same time step, transportation time depends on the number of actions. To improve the quality of the path, a new reward function has been designed. The reward function is defined with three different conditions which can be written as:




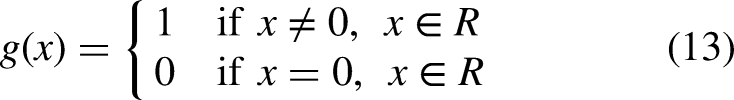
HER for path planning task
For the lift path planning problem of reinforcement learning, the tower crane has lots of states in a lifting path with a long planning distance which leads to the reward sparsity problem. This causes the network cannot get positive feedback effectively resulting in inefficient neural network training. Therefore, HER method 30 is introduced in this model to handle the reward sparsity problem. The basic idea of HER is to learn useful information from experiences that failed in the lifting path. A lifting path that does not reach a goal position can still guide another path-planning task, that is, the current position in a lifting path could be the goal position in another task.
During training, a large number of lifting paths are first generated and stored in the replay buffer. In the early stage of training, the network basically selects actions randomly, so most of the lifting paths fail. Assuming a generated path
In the original experience replay, the new goal position is selected randomly. However, the appropriate selection of the position
Therefore, a priority-based goal position selection strategy is proposed. In the early stage of training, the strategy preferentially selects the path position that is close to the starting state as the new goal position to improve the training speed. After the planner has learned how to reach the nearby position, the probability of selecting the farther positions as the new goal point is then increased. In this paper, the path positions within 15 steps of the starting point are considered as closer positions, which are preferentially selected at the beginning of training with a probability of 0.7. Then the probability that a nearby path position is selected after 10 epochs of training is reduced to 0.3.
Experimental studies
In this section, the implementation detail of our method is first introduced. Then the training process demonstrates that the HER strategy proposed in this paper can greatly improve the training speed. Finally, the proposed method is compared with the existing DRL-based lifting path planning algorithms.
Implementation detail
A 100 m × 100 m virtual construction environment with various obstacles is generated in the Webots platform as shown in Figure 4. In order to better describe the obstacle locations and lifting paths, we simplified the environment, retaining only the obstacle information, and reproduced the simplified map in Figure 4(b), where the red plus sign is the location of the tower crane. To ensure the diversity of the environment and avoid the insufficient generalization of the training model, 20 different environments are generated for training. Each environment has 18 groups of obstacles, consisting of 6 dynamic obstacles (represented by green cuboids) and 12 fixed obstacles (represented by cuboids in gray, cyan, and black color). The positions of obstacles are randomly generated. Additionally, dynamic obstacles are set to move back and forth along a straight line, and the line direction and distance are randomly generated within a certain range. It should be noted that the start and target positions for each transportation task are randomly selected after generating the environment. Since the obstacles and start/goal states are all placed on one side of the tower crane, the slewing range of the tower crane is [0–180°]. The lifting height of the crane is [0–45 m], and the range of trolley movement is [0–40 m]. The lidar is installed above the center of the lifted load to measure the surrounding environment information. The field of view and the vertical field of view are set to 6.28 and 0.8 for lidar, respectively. The maximum ranging distance of the lidar is set to 15 m and the minimum distance range to 0.1 m. The horizontal resolution of the lidar is 128 and the number of layers is 16.
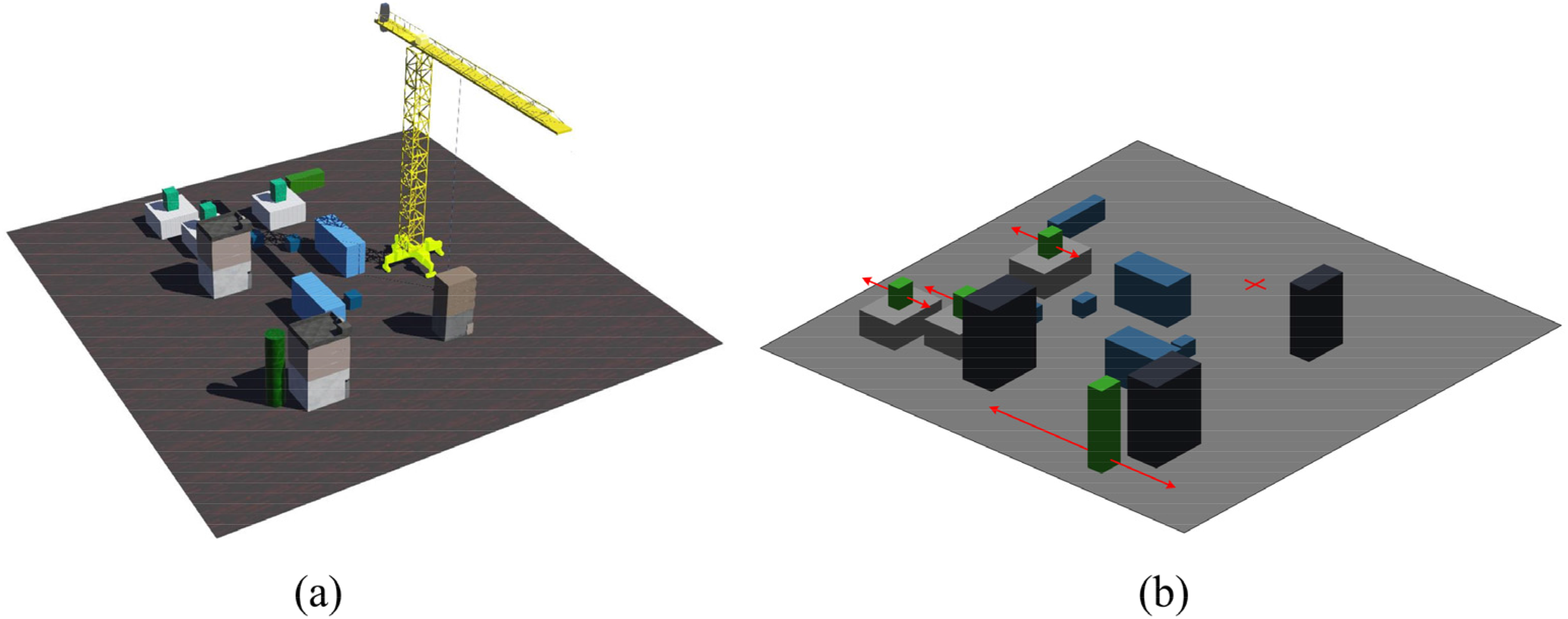
Crane model and training environments. (a) Virtual environments in Webots. (b) Simplified environment in Matlab (Red plus sign represents the position of the tower crane).
The developed model is trained in 50 epochs, and each epoch consists of 25 episodes. Each episode performs optimization steps on minibatches of size 256 sampled uniformly from a replay buffer. During training, the initial learning rate is 0.001, and an Adaptive moment estimation (Adam) is used as the optimization algorithm. The max time step of each episode is 150, which means that the crane explores at most 150 steps in each episode. The ratio of HER is set to 0.8. The target networks are updated after every cycle using the decay coefficient of 0.995. The target noisy and exploration noisy are set to 0.1. The training is performed using Pytorch on a Dell T7920 workstation with an Intel Xeon (R)E5 2699v4 CPU, 128GB RAM, and 44 cores.
We use three HER strategies to train the network, and the average epoch reward and the success rate are shown in Figure 5. It can be seen that the initialized planner selects actions almost randomly in the early stages of training, resulting in little reward and little success rate. The planner without the HER algorithm can hardly learn useful information from a failed lifting path, which ultimately leads to the failure of training. The red curve with Strategy 1 indicates that the HER algorithm only considers the path positions near the sample positions as the new goal position. The network can learn about the successful experience more easily at the beginning of training, and thus the reward and success curve increase faster in the early stage. However, the learning efficiency of the network gradually decreases as the epoch increases. This is because the planner only learns how to reach the nearby positions, but has no experience in reaching the more distant goal position. Therefore, the HER strategy proposed in this paper is preferred to select positions near the sample as new goal positions to accelerate the network convergence at the early stage of training and then select farther path positions as new goal positions in the last part of training. Figure 5 shows that the HER with strategy 2 makes the network converge earlier.

Convergence results for three HER strategies (Strategy 1: HER algorithm only considers the path positions near the sample positions as the new goal position; Strategy 2: HER algorithm is more likely to select path positions near the sample position as the new goal position in the early stage, and select more distant path positions as the new goal position in the later stage).
Algorithm performance analysis
In this section, we employ Monte Carlo simulations to verify the consistency, reliability, and general performance of the proposed algorithm. We randomly selected 10 transportation tasks with different start and target positions in each of the six scenarios. Each task is repeated 10 times, resulting in a total of 600 trials.
Figure 6 illustrates the path lengths for different transportation tasks (labeled as T1 to T10) across six random environments (labeled as ENV1 to ENV6). Additionally, horizontal lines indicate the maximum, minimum, and average path lengths for each task. For most tasks, the path lengths remain relatively consistent in the 10 repeated trials, indicating the stability and reliability of the path planning algorithm. There is a noticeable variation in path lengths among different tasks. This variation can be attributed to the differing complexities and distances of the start and target positions in each task. In some tasks, outliers are observed where a few trials resulted in significantly shorter lifting paths, such as T1, T6 in ENV 1; T1, T10 in ENV 4; and T9 in ENV 5. These outliers indicate occasional failures in path planning trails such as collisions with obstacles under certain conditions.

Path length results of 600 trials across six scenarios.
To ensure that path planning failures do not threaten the safety of crane operations, we summarized the reasons for path planning failures from several instances of failed path planning cases. The failure of the lifting path planning is primarily attributed to the complex environment surrounding the target points, which leads to potential collisions between the load and obstacles. Figure 7 shows that the load collided with obstacles around target positions in ENV 1. Although the simulation results indicate that collisions occur between the load and obstacle, in practice, no actual collisions happen. This is because when the load is less than 0.5 m away from the obstacle in the experiment, the system detects the collision and stops the movement. Therefore, this distance threshold of 0.5 m could effectively ensure that actual collisions do not occur. Additionally, the proposed path planning method designs the action space and reward function in accordance with crane operation protocols, ensuring smoother and safer crane paths.
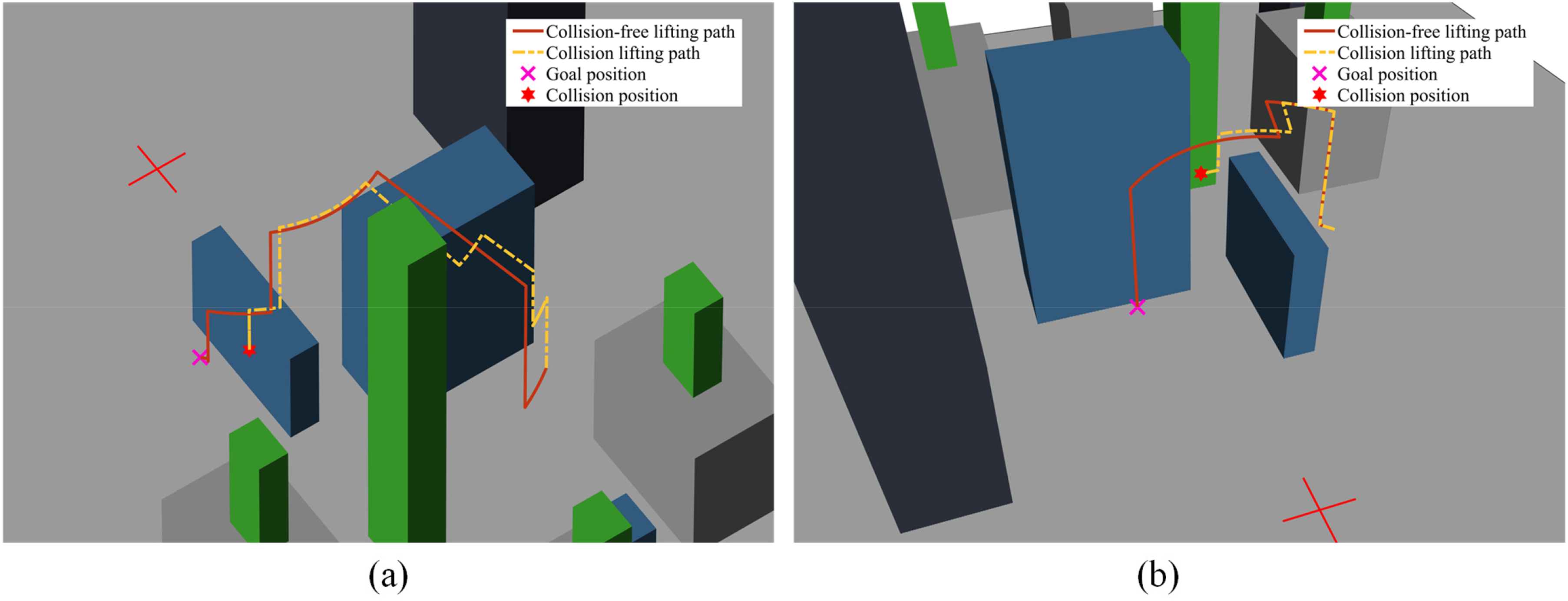
Illustration of collisions between load and obstacle in failed path planning cases. (a) lifting path for Task T7 in Environment 1; (b) lifting path for Task T10 in Environment 1.
In summary, the proposed method effectively plans the collision-free lifting path with safety standards, thereby ensuring the stability and reliability of the path planning process.
Comparison with the DRL methods
Three DRL methods are trained in the construction environments to validate the performance of the method presented in this paper. The first DRL method proposed by Guo et al. 25 is based on the Duling-DQN algorithm and uses discrete actions to control crane movement. The discrete action space consists of 10 actions: clockwise/counter-clockwise slewing, the backward/forward motion of the trolley, the lifting/lowering with cable, and the combination of trolley movement and slewing movement. The slewing step is 1°, and the step of trolley motion and lifting motion is 1 m. The second method is the original TD3 algorithm with a continuous action space which allows the crane can perform three fundamental operations simultaneously. The third method is our TD3-based algorithm with the hybrid action space. The hybrid action space consists of a fundamental operation and a corresponding speed of movement.
All the above three methods are trained in the Webots virtual environment and achieved a success rate of more than 80% in the testing datasets. To validate the generalization capability, the above three trained methods are evaluated in six new random environments. We randomly selected 10 transportation tasks with varying start and target positions for path planning tests. In each episode, the maximum length is set to 150, which means that the planner must find a successful lifting path within 150 steps or it is considered a failure. Three evaluation values are proposed to evaluate the performance of the planning path methods, which are success rate, path length, operation complexity, and transportation time. It should be noted that all parameters, except the success rate, are calculated in the episode where the lifting paths are successfully planned by all three methods to ensure fairness.
According to practical engineering experience, the crane operation of each foundation cannot be frequently switched. Therefore, we propose a coefficient of operation complexity to evaluate whether the planned path is suitable for the practical lifting operation. The operation complexity coefficient is the switching times of fundamental operations in the whole lifting path. For example, if the crane operation in the
The average results of the three path planning methods in the test environment are shown in Table 1. Overall, the proposed method is superior to existing reinforcement learning-based lifting path planning algorithms. It can be seen that the path planning success rate of the method proposed in this paper is the highest. The average path length is just slightly longer than that of the method proposed by Guo et al., 25 and the operational complexity is the smallest of the three methods. The path transportation time (the number of path steps) is slightly more than the continuous action space but far less than the Guo et al. 25 method.
Comparison of average results between the proposed method and existing methods.

To better interpret the comparison results in Table 1, 12 groups of lifting paths planned by three methods in the six test environments are shown in Figures 8 and 9. It can be seen that the method proposed in this paper prefers to perform lifting operations to avoid collision with obstacles when encountering them, which is more consistent with the operation logic in practical engineering. However, this operation strategy sometimes leads to a larger path length than the other two methods, such as the lifting path in Figures 8(b) and 9(a). The method with continuous action space and with Guo et al. 25 prefers to bypass the obstacles without lifting the load height. As a result, the latter two methods are more at risk of colliding with obstacles, resulting in a lower success rate.

Comparison of lifting path generated by three DRL-based methods in test environments (Env1– Env3).

Comparison of lifting path generated by three DRL-based methods in test environments (Env4–Env6).
The hybrid action space, which performs only one operation at each time step, combined with the reward function for path smoothing, makes the paths generated in this paper smoother and more consistent with practical engineering applications. The method with continuous action space produces more complex trajectories, such as abrupt turns shown in Figures 8(b) and 9(d). Since three fundamental operations (slewing, trolley movement, hoisting) can be performed simultaneously, the method with continuous action space has the longest path length but the least transportation time (number of path steps). The action space of Guo et al. 25 method is a discrete space where the movement distance in each time step is fixed, so collisions are more likely to occur at narrow channels leading to the failure of path planning. Moreover, the fixed movement distance at each step results in a larger time cost in an open environment than the other two methods, because those methods with continued action space can increase the movement speed in the absence of obstacles nearby.
Since the reward function in our method takes into account the reward function of path smoothness, the lifting path generated by our method is simpler to implement in practical engineering. The other two methods will frequently switch the crane operation leading to the occurrence of danger, especially with large inertia of heavy weight loads.
Conclusion
In this paper, a new lifting path planning method based on reinforcement learning for the tower crane in an unknown construction environment is proposed. Different from traditional path planning which requires complete environmental information, the proposed algorithm only required the signal from the lidar mounted above the hook. Aiming at the operation characteristics of tower cranes, a hybrid action space is proposed, where one fundamental operation (slewing, trolley movement, hoisting) is selected in the discrete space, and the movement speed is generated in the continuous space. Moreover, the algorithm takes into account the operational smoothness reward function to improve the smoothness of the path. A novel HER strategy is developed to accelerate the convergence of the training process. Simulation results in Webots platform show that the proposed method has a shorter path length and less execution time than the existing reinforcement learning path planning methods. Most importantly, the generated paths are more consistent with the operational characteristics of tower cranes in practical engineering. In future work, we will consider the dynamic characteristics of cranes, such as rope flexibility and load swing, into models to more align with practical applications.
Highlights
The path planning algorithm developed in this work does not rely on global environmental modeling and only requires local environmental information measured by lidar.
Combined with the operating characteristics of tower cranes, a discrete-continuous hybrid action space for tower crane control is proposed to smooth the generated lifting paths of tower cranes. A new reward function is designed for lifting path planning of tower cranes by considering energy, path smoothness, and time cost.
A Hindsight Experience Replay (HER) strategy is proposed for the training of the lifting path planning networks, which can improve the convergence speed of the model in the training process.
Footnotes
Author contributions
All authors have taken due care to ensure the integrity of the work and substantial contributions. Kai Wang: investigation, software, validation, writing—original draft. Jing Li: methodology, formal analysis. Zhiyuan Yin: writing—reviewing and editing, formal analysis. Jiankang Zhang: formal analysis, methodology. Xin Ma: conceptualization of this study, project administration.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the Key Research and Development Project of Shandong Province under Grant 2021CXGC010701, in part by the Central Guidance for Local Scientific and Technological Development Funding Projects of Shandong Province under Grant YDZX2023042, and in part by the Joint Fund of the National Nature Science Foundation of China and Shandong Province under Grant U1706228.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.