
Abstract
The precise bagging of immature peaches by the fruit bagging robot requires the identification of the target young fruits as well as the acquisition of their growth angles. The network models employed in single detection algorithms exhibit complexity and pose challenges for deployment on mobile terminals as they heavily rely on the availability of labeled samples. A semi-supervised learning and lightweight strategy based on YOLOv8n-seg was proposed to identify the growth posture of immature peaches in the work. Firstly, the self-training method and data enhancement in semi-supervised learning were used to generate efficient pseudo-label data. A tremendous labeling workload was solved. Secondly, the YOLOv8n-seg backbone network was replaced with an improved MobileNetv3 structure for better real-time detection on MT to reduce network parameters and calculations. The model was easily deployed with improved detection speed. Meanwhile, the original upsampling module was replaced with the CARAFE module to enhance the recognition capability of global features, which considered the impact of immature peaches on the nearby color background. The CIOU loss function was ultimately substituted with the SIOU loss function to further optimize the boundary frame loss and target detection accuracy. The enhanced model could predict the coordinate information of immature peaches and calculate growth angles. The experimental results show that the improved peach seedling growth posture network model has a weight size of only 23.1% of the original model. Additionally, the algorithm achieved a remarkable rate of 87.8% in identifying young peach fruits, with an average error of ±3.3° in estimating the growth angle. It took an average of 31 ms to detect a 3024 × 4032 pixels image in the edge computing device JETSON AGX ORIN CLB development kits. The method could rapidly identify immature peaches and estimate the growth angle, which ensured accurate bagging.
Introduction
Bagging technology is an important technology for producing green, high-quality, and high-grade fruits and vegetables. Bagging can reduce harm to birds and insects in fruits and vegetables as well as prevent pesticide pollution and sun and wind damage. The enhancement of fruit and vegetable colors is accompanied by preventing scratches and deformation. Bagging is also an essential link in the production process of high-quality peach cultivation. However, young-fruit bagging, like ripe-fruit picking, is seasonal and heavy workload. The current process is mainly carried out manually or with rudimentary machinery, which results in time-consuming and labor-intensive operations as well as inconsistent bagging quality. Aging and insufficient agricultural labor force are becoming increasingly significant, and the price of manual bagging is increasing year by year. The labor cost for manual bagging has been steadily increasing over the years due to the progressively prominent issues of aging and insufficient agricultural labor. The corresponding production cost also increases, which affects market competitiveness. It is of great significance to research the related technology of intelligent bagging robots for immature peaches because of the above situation. The vision system is vital to realizing the intelligent operation of immature-peach bagging robots. The visual recognition technology based on the vision system is important in this system. Postures such as the fruit position and growth angle, are crucial for the immature-fruit bagging process as the bag needs to be placed from the bottom of the fruit upwards. Young fruits are small in size and similar in color to the background of branches and leaves compared with ripe fruits. The acquisition of fruit locations and growth angles is further complicated. 1
Nowadays, computer vision and machine learning technologies are developing rapidly. The deep convolutional neural network (CNN) has strong feature extraction capabilities and better generalization capabilities. Both of them provide a necessary reference for the effective detection of target fruits and vegetables. The CNN has been employed by researchers for target recognition and localization, which significantly improves target detection.2–4 Target detection algorithms are mainly divided into two categories. One is the one-stage detection algorithm with a faster detection speed, including YOLO,5–10 SSD, 11 and Retina-Net. 12 The other approach is the two-stage detection algorithm, such as Faster R-CNN 13 and Mask R-CNN, 14 which initially generates candidate regions and subsequently performs classification and refinement on these regions. Wang et al. 15 proposed a region-based fully convolutional network R-FCN for immature-apple detection. This method can realize the target identification of apples before fruit thinning, which is difficult to achieve by traditional methods. Liang et al. 16 proposed a method for detecting lychee fruits and stems at night based on YOLOv3. Average accuracy is 96.8, 99.6, and 89.3%, respectively, under high brightness, normal brightness, and low brightness. Song et al. proposed an improved YOLOv4 network model (YOLOv4-SENL) with the average accuracy of 96.9% on the test set for the target detection of immature apples. Gong et al. 17 proposed a kiwi flower detection model based on improved YOLOv5 s. Kiwi flowers can be identified in the natural environment with enhanced detection accuracy and speed in a lightweight design. The YOLOv4 network model proposed by Jiang et al. 18 integrates a non-local attention module and a convolutional block attention module to detect immature apples in the natural environment. Young fruits’ missing detection caused by uneven illumination and severe occlusion has been resolved. Background information is redundant in the detected area although the method is good at detecting fruits. Besides, the use of rectangular boxes alone cannot capture the detailed morphological characteristics of the target. Therefore, its application is limited to actual bagging.Target identification and the acquisition of growth angles are essential for bagging robots to precisely bag immature peaches. There are few studies on the visual recognition of growth postures in fruit and vegetable bagging. Yue et al. 19 added a boundary-weighted loss function based on the instance-segmentation Mask RCNN in previous studies. This method makes the boundary detection result more accurate, with a good effect on apple detection. Zhang et al. 20 proposed a tomato string visual positioning and picking attitude estimation method based on the YOLACT instance segmentation algorithm. The method incorporates feature standardization and a mask-scoring mechanism, exhibiting exceptional precision and stability in intricate picking environments. Xu et al. 21 identified truss tomatoes closest to the camera as picking targets based on the improved Mask R-CNN, with the accuracy of 93.76% and a single frame image processing time of 0.04 s.
Research on the identification of young fruits has yielded promising results in case segmentation. However, there are still several unresolved issues that need to be addressed. Firstly, reduced dependence on labeled data to mitigate the expenses and workload of data labeling is a pivotal concern. Secondly, the existing instance segmentation model identifies immature peaches slowly and poses challenges for real-time detection. Its application is challenging due to extensive parameters and substantial computational requirements. The detection of directional targets remains to be solved. A semi-supervised learning and lightweight strategy based on YOLOv8n-seg 22 is proposed to identify the growth postures of immature peaches. The method aims to achieve the precise bagging of immature peaches using bagging robots based on semi-supervised learning and lightweight design. It provides useful references for research and application in related fields. The work includes five parts. The significance of bagging technology, the current situation of growth angle detection, and the method proposed are introduced in section “Introduction.” Section “Method for detecting the posture of immature peaches” elaborates on the posture identification method of immature peaches, including improvement ideas and key technologies. Section “Data acquisition and preprocessing” describes the process of data set collection and preprocessing. Section “Result and analysis” compares the YOLOv8n-seg network model and other classic instance segmentation networks. Besides, the structure optimization of YOLOv8n-seg is analyzed from performance and accuracy. Finally, the main contributions and conclusions are presented.
Method for detecting the posture of immature peaches
Yolov8n-seg network model
YOLOv8n-seg is an instance-segmentation deep-learning model, an improved version of target detection algorithm YOLO (you only look once). The Yolov8n-seg model structure is designed to achieve efficient and accurate instance segmentation. The core idea is to divide the image into grids and predict the category, location, and segmentation mask of the target in each grid. The network structure of Yolov8n-seg consists of input, Backbone, Neck module, and prediction segment. The input terminal mainly performs mosaic data enhancement, adaptive anchor frame calculation, and adaptive grayscale filling processing. The backbone network adopts Conv, C2f, and SPPF structures, and the C2f module is the main module for learning residual characteristics. Model's gradient flow is enhanced through the incorporation of additional branch cross-layer connections, which enhances the network module's capability to represent features. The Neck module adopts the path aggregation network (PAN), which enhances the network's ability to integrate object characteristics across different scales. Predicting end Head gets three eigenvectors of different scales to predict the final result.
Lightweight model design and optimization strategy
The current state of YOLOv8n-seg demonstrates promising segmentation results in natural scenes; however, challenges remain when it is applied to the identification of immature peaches in orchards. The backbone network structure of YOLOv8n-seg is complex, and the high number of parameters is not conducive to mobile deployment. The identification of immature peaches presents a typical challenge in target detection due to the presence of near-color backgrounds and small targets, which significantly increases the difficulty level of identification. The YOLOv8n-seg structure only focuses on local features and ignores the global semantic information of the feature map. The small receptive field cannot accurately reflect the global features of the image, which results in low detection accuracy. Therefore, the work enhances the YOLOv8n-seg framework and proposes a lightweight strategy for identifying immature-peach growth postures within the framework. The aforementioned practical challenges in the visual identification of immature peaches can be addressed. Figure 1 shows the structure of the improved lightweight model.

Improved YOLOv8n-seg lightweight model.
The growth-posture identification method for immature peaches based on the YOLOv8n-seg lightweight strategy proposed aims to reduce parameters and computational load. Besides, the feature extraction capabilities of the model can be improved. The backbone network in the YOLOv8n-seg model is replaced with an improved MobileNetv3 structure for this goal. Meanwhile, the original SPPF module is retained. The act is to reduce the complexity of the model and improve its real-time performance on the mobile terminal. The identification accuracy of immature peaches may decrease due to an improved MobileNetv3 lightweight network. Therefore, further optimization is carried out. Firstly, the interpolation upsampling module 23 is replaced by the CARAFE upsampling module 24 in the neck layer of the YOLOv8n-seg model. The CARAFE upsampling module can generate different upsampling cores based on different features, which enhances the identification of global features and the detection accuracy of the model. The CIOU loss function is replaced with the SIOU loss function to mitigate the significant fluctuations caused by minor adjustments in the bounding box. The accuracy of target detection can be improved.
Backbone network architecture
The existing instance segmentation model exhibits problems such as low accuracy, high amount of parameters and calculations, large memory consumption of model weights, and unfavorable mobile deployment when identifying immature peaches. Lightweight research on the segmentation model of immature-peach blossoms is carried out. MobileNet25,26 is widely used in instance segmentation as a representative of lightweight CNN networks, which was proposed by the Google team in 2017. The MobileNetv3 lightweight networks can decrease the number of parameters and computations in the model compared with traditional CNNs. The reduction in the weight size of the model has a negligible impact on model accuracy. This allows deep learning networks to be applied in real-world engineering scenarios.
The MobileNetv3 architecture incorporates existing lightweight model concepts and employs a specialized bottleneck structure to enhance both identification accuracy and computational efficiency. The Bottleneck layer is used for feature extraction of each feature layer in MobileNetv3. The dimensionality reduction of images is performed at the input end through the Conv_BN_HSwish layer to improve the Bottleneck layer. The first Bottleneck layer extracts features through DW convolution. The h-swish activation function (Eq. (1)) and the ENet (squeeze and excitation) attention mechanism are introduced to improve feature extraction from small targets. Then the 1 × 1 convolution layer is used for dimensionality reduction, which removes the redundant structure in the original Bottleneck layer. The number of network parameters is reduced and the operation speed of the network is improved by modifying the convolution layer and mode. The network is enabled to prioritize valuable channel information and dynamically adjust the weighting of each channel. Dimension is first raised using 1 × 1 convolution, and then features are extracted by DW convolution for the remaining Bottleneck layers. The SE attention mechanism and h-swish activation function are incorporated to enhance the capacity for capturing local channel information. The irrelevant characteristic information not relevant to the current task can be suppressed. Finally, the 1 × 1 convolution layer is used for dimensionality reduction, which minimizes the model's parameters and calculations as well as exerts a minimal impact on detection accuracy. Figure 2 shows the structure of the improved bottleneck layer; Figure 2(a) represents the improvement of the first bottleneck layer; Figure 2(b) depicts the structure of the remaining bottleneck layers.
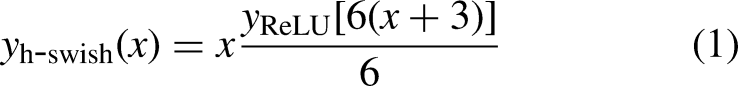
Botteneck structure of improved MobileNetv3.
Upsampled network structure
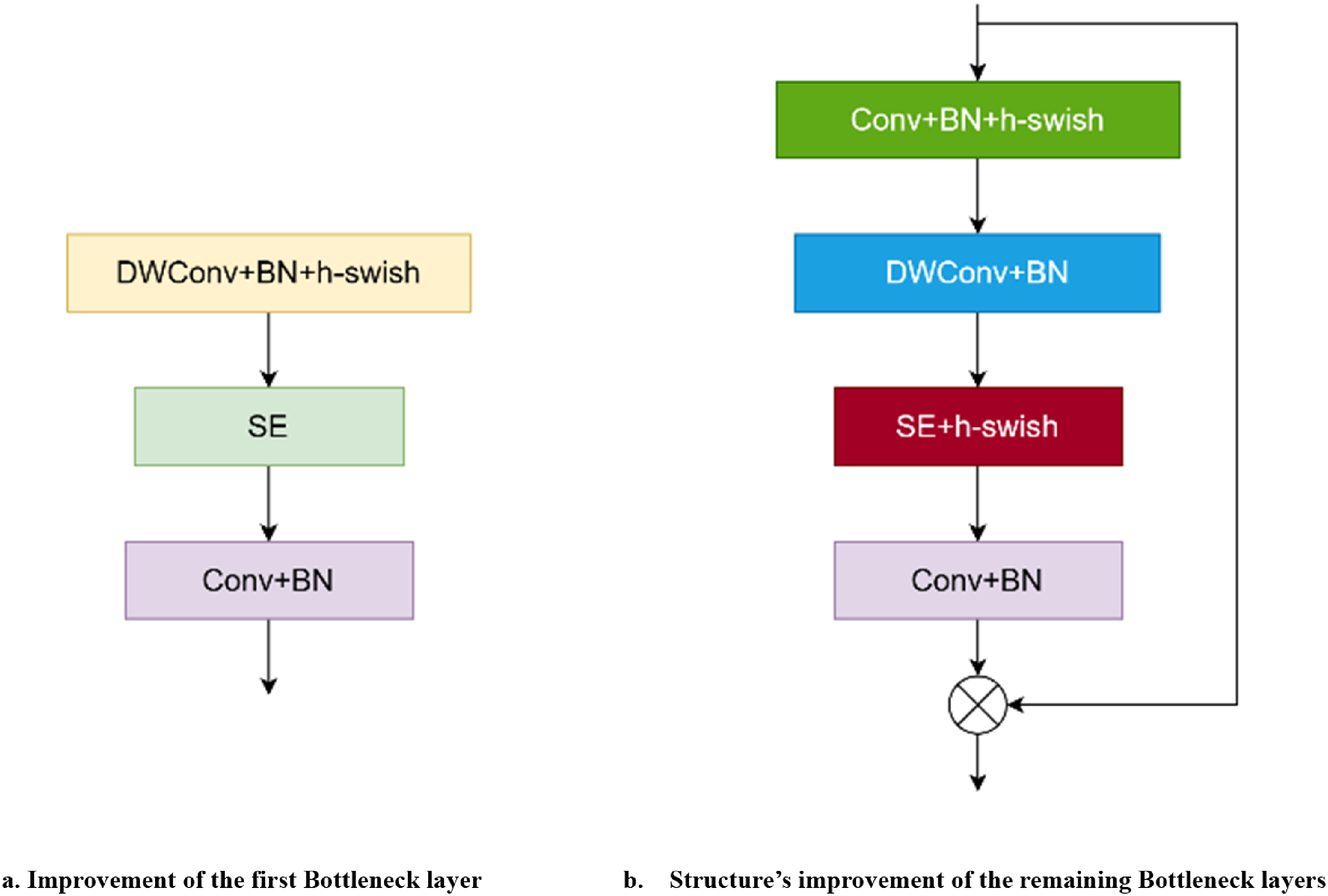
The immature peach in the natural environment is a typical target of a near-color background with a small form. The process of upsampling is a key operation to distinguish immature peaches from the background better and extract their features more effectively. In particular, it is widely used in feature pyramid networks (FPNs). At present, the mainstream upsampling methods can be divided into deconvolution upsampling and interpolation upsampling. The deconvolution upsampling technique employs the identical convolution kernel for feature map upsampling, which lacks flexibility in adjusting features. The neglect of certain semantic features in the image results in the incorporation of a significant amount of parameters and computational complexity. Training time increases, which is not suitable for lightweight network models. The interpolation upsampling method includes nearest neighbor upsampling and bilinear upsampling. However, these methods only determine the upsampled kernel by the spatial position of the pixel point. The semantic information of the feature map is disregarded, which resembles a form of uniform upsampling. The perceptual domain is usually small and cannot accurately capture the global features of the images. The CARAFE upsampling module leverages semantic information from the feature map to improve the recognition capability of global features by comparing the above two up-samplings. The target recognition of immature peaches is improved. Therefore, the CARAFE upsampling module is used to replace the original interpolation upsampling module. Figure 3 shows the specific structure of the CARAFE upsampling module.
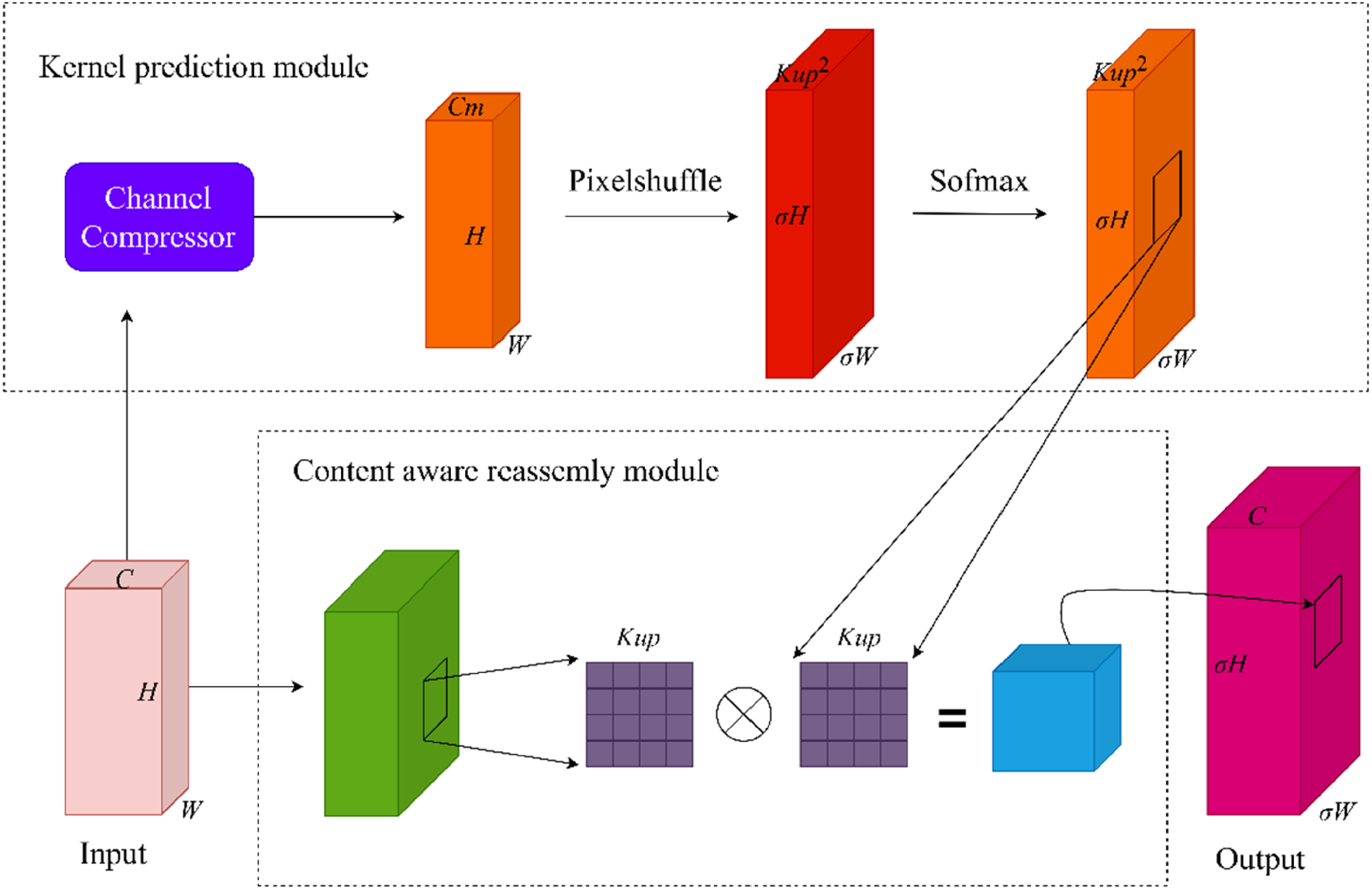
CARAFE module.
CARAFE consists of the upsampled kernel prediction module and the content-aware reassembly module. First, the feature map is passed into the kernel prediction module, which uses a 1 × 1 convolution check feature for compression processing. The number of channels C is compressed into Cm that represents the number of channels in the feature layer after compression. Compression processing aims to minimize computational requirements and parameter count, which enhances subsequent operations in processing the feature map (Figure 2).

The CARAFE upsampling method requires the feature map's height, width, and number of channels to be reorganized before performing the reshape operation in a specified manner. The reorganization process can be implemented using the PixelShuffle method.
27
The feature map's height, width, and number of channels, are rearranged as
Loss function
Immature peaches exhibit complex background traits and small sizes, which makes them susceptible to obstruction by surrounding foliage. The work replaced the CIOU loss function in the YOLOv8n-seg model with the SIOU loss function
28
to further improve the identification accuracy in the unstructured field growing environment. The conventional CIOU loss function failed to consider the directional discrepancy between the actual frame and the predicted frame, which led to sluggish convergence and suboptimal efficiency. The SIOU loss function incorporated the angular disparity between the actual and predicted bounding boxes, which encompassed the angle loss, distance loss, shape loss, and IOU loss. The angle cost describes the minimum angle between the center point (Figure 4) connection and the x–y axis. The angle loss is 0 when

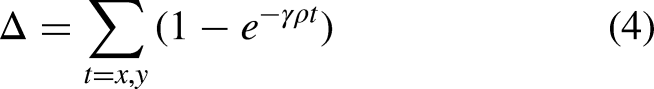
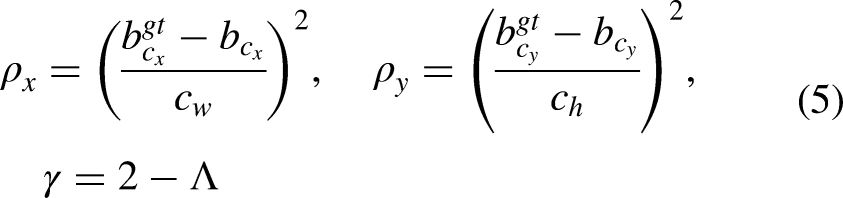
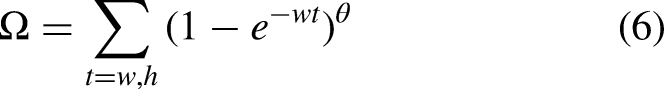



Angle cost.

Distance cost.
The final SIoU loss function is defined by

Estimation of immature-peach growth angles
The appropriate bagging posture is key to achieving efficient and undamaged bagging according to the growth angle of fruits. The work uses the segmentation network model to identify immature peach images, which ensures the bagging of multi-angle them. Then the target key point coordinates are obtained. The target region of immature peach is composed of



Estimation of immature peaches’ growth angles.
Coordinates A and B are obtained by calculating the distance of
Data acquisition and preprocessing
Image acquisition and preprocessing of immature peaches
Immature-peach images were used as the data set in the work. The collection site was Shengjiatou Peach Garden, Xueyan Town, Changzhou, Jiangsu Province, and the shooting date was from mid-May to early June 2021. The shooting device was a camera, and the resolution of the shooting lens was 3024 × 4032 pixels. The shooting was conducted under different weather conditions to ensure the diversity of samples, including sunny, cloudy, morning, and afternoon. A total of 2985 images of immature peach growth were collected. Three hundred images were selected as the test set, and the remaining 2685 images were used for model training.
Image enhancement was performed on the training data set to improve the robustness and generalization of the algorithm. Several enhancement methods were used to increase the diversity of the dataset, including contrast enhancement factor set to 1.5, brightness enhancement factor set to 1.5, cross-cutting, flipping, rotation, and adding Gaussian noise. Finally, a total of 10,740 images were obtained for the subsequent training and parameter optimization verification of the deep network. The enhanced image has richer details and diversity, which can improve the robustness and generalization ability of the algorithm (Figure 7). Image enhancement enables the effective processing of images depicting immature peaches in diverse scenarios. The model can identify accurately under different conditions, which improves the performance and reliability of the whole algorithm.

Image enhancement mode.
Data labels under semi-supervised learning
Currently, deep learning algorithms require extensive manual labeling of data when performing classification tasks. However, the marking process of immature-peach images faces numerous challenges such as overlapping, blocking, insufficient lighting, and other factors, which pose significant obstacles to manual marking. The images frequently portray numerous fruit trees bearing dozens of fruits, which engenders a laborious and error-prone manual marking process. A self-training method based on semi-supervised data enhancement is used to reduce the dependence of the segmentation model on labeled samples. Model's robustness is enhanced by introducing perturbations to input data during training. The crucial factor in data enhancement lies in guaranteeing the consistent output for the same input. The disturbance only increases the diversity of data and maintains output distribution invariant. The algorithm consists of data acquisition, semi-supervised model training, and algorithm detection. Figure 8 shows the specific process.

Semi-supervised object detection process based on pseudo labels.
First, the data set is prepared and a small number of randomly selected images are labeled with immature peaches using annotation tool Labelme (Figure 9). Labeled data are forwarded to the supervised network for training. Subsequently, the trained supervised model is utilized to generate pseudo-labels for semi-supervised learning. A confidence threshold of the network is 0.8 and the prediction results of unlabeled data are used as pseudo-labels to acquire efficient pseudo-labeled data. Unlabeled data should be enhanced and utilized to generate pseudo-labels simultaneously. An extended training data set is formed by combining labeled and unlabeled data with pseudo-labels, which are input to the network for semi-supervised loop learning. Finally, the optimal model is ultimately chosen based on average accuracy and F-Score metrics.

Images of immature-peach masking labels.
Dependence on labeled samples can be reduced with this algorithm. The model is trained using a semi-supervised learning approach that incorporates labeled and unlabeled data. It enhances the identification performance of immature peaches.
Result and analysis
Experimental platform
NVIDIA Tesla V10032G was utilized in the test process, with Ubuntu 16.04 as the operating system, Intel Xeon Gold 5117 as the processor, and a memory capacity of 32 GB. Network model training, using PyTorch 1.7.0 as a deep learning framework, was supported by the Pycharm compiler and Python programming language. The deep learning framework used for training the network model was PyTorch 1.7.0, which was supported by the PyCharm compiler and the Python programming language.
Model parameter
The stochastic gradient descent (SGD) algorithm was used for end-to-end joint training of the network in the work. All the input images were adjusted to 640 × 640 pixels to improve the detection accuracy of the model. Network parameters were optimized using the SGD optimizer. The initial learning rate was configured as 0.001, with a weight decay rate of 0.005, a momentum coefficient of 0.9, and a validity period of 20. The accuracy of the training model is evaluated 20 times per iteration on the verification set by the network. The division ratio of the training set to the verification set was 8:2. The training process should be terminated once model accuracy reached convergence. The trained model was preserved after the training process, and its validity was confirmed through testing with 300 test sets.
Performance evaluation indices
Network performance evaluation indices
The detection effect of the model is evaluated using indices precision (P), recall rate (R), F1, and mAP to analyze its performance. Eqs. (12)–(15) show its definition. The higher P, R, F1, and mAP, the higher the accuracy of network detection. The FPS (frames per second) is used to evaluate the detection speed of the model.



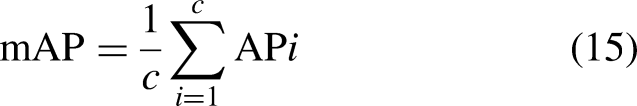
Identification of performance evaluation indices
The recall rate, accuracy rate, average accuracy rate, and average error of the angle estimation are utilized to assess the actual identification performance of the model. The actual efficacy of the model in visually identifying immature peach growth posture can be further validated (Eqs. (16) and (17)).
Average accuracy of detection is defined by The average error of the angle estimation is defined by


Effect analysis of the semi-supervised learning method
The work utilized 365 labeled examples for initial training to verify the validity of semi-supervised learning. The model was used to generate 10,375 pseudo-labels for the prediction results of the unlabeled examples. The confidence threshold was set to 0.8 to obtain high-quality pseudo-label examples. An extended training dataset was formed by merging labeled and unlabeled examples with pseudo-labels. The training set and the validation set were divided in an 8:2 ratio. Finally, the model was iteratively trained with the extended training data set until the model reached saturation. The same data set was used to conduct semi-supervised learning training on Deeplab (resnet50), unet, Mask-rcnn, YOLOv5-seg, YOLOv7-seg, and YOLOv8n-seg networks. Table 1 shows the training result.
Performance comparison of different algorithm models.

The YOLOv8n-seg network has optimal performance according to the results in Table 1. mAP of the YOLOv8n-seg network model is higher than that of Deeplab_v3, unet, Mask-rcnn, YOLOv5-seg, and YOLOv7-seg network models, respectively, which increases by 11.9, 7.1, 5.9, 1.0, and 0.5%, respectively. P increased by 13.5, 7.1, 1.9, 0.6 and 1.1%, respectively. R is 13.7, 11.9, 10.0, 6.3, and 1.9% higher compared with Deeplab_v3, unet, Mask-rcnn, YOLOv5-seg, and YOLOv7-seg network models, respectively. F1 is improved by 16.6, 12.6, 7.4, 4.6, and 2.7%, respectively. The model size is reduced by 304.7, 10, 221.8, 146.2, and 52.5 M, respectively. The detection speed is increased by 47.6, 3.9, 41.8, 14.9, and 8.7 FPS compared with the other five models, respectively.
Performance evaluation and analysis of lightweight models
The performance of the processor (CPU or GPU) was also a key factor in the operation of the algorithm. The processor's workload was alleviated during the operation of the network model. The architecture of the YOLOv8n-seg network was enhanced by incorporating the lightweight MobileNetv3 model as its backbone structure. CARAFE upsampling was substituted for upsampling in the Neck layer. The precision of the model was improved by reducing the number of parameters and calculations, which made it more suitable for accurately identifying and subsequently deploying immature peaches. The network optimization was achieved by substituting the CIOU loss function with the SIOU loss function. Then the convergence speed and overall detection performance of the immature peaches detection model were enhanced.
Comparative analysis of different lightweight models
The enhanced lightweight network model was compared with other existing lightweight network models to analyze the performance disparities among different algorithms. Therefore, the advantages of the proposed improved algorithm were investigated. The selection of experimental subjects considered the current mainstream lightweight structural algorithms, such as PP-LCNet, 29 EfficientNet, 30 ShuffleNetv2, 31 MobileNeXt, 32 and the improved MobileNetv3 architecture. Comparison tests were carried out in the same YOLOv8n-seg network model test. Figures 10 and 11 show the loss curve and mAP curve, and Table 2 shows the test results.
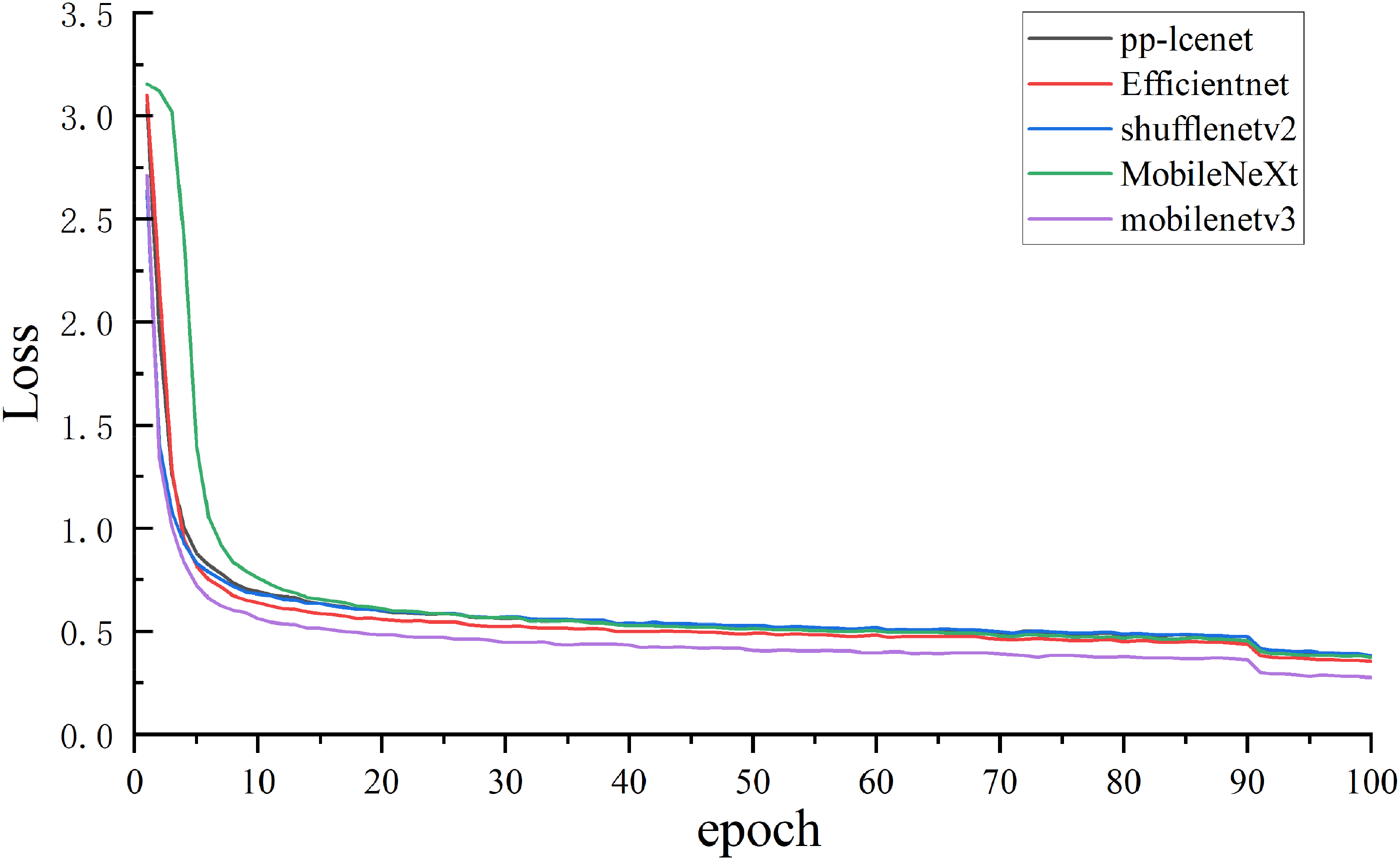
Loss curves of different algorithm models.
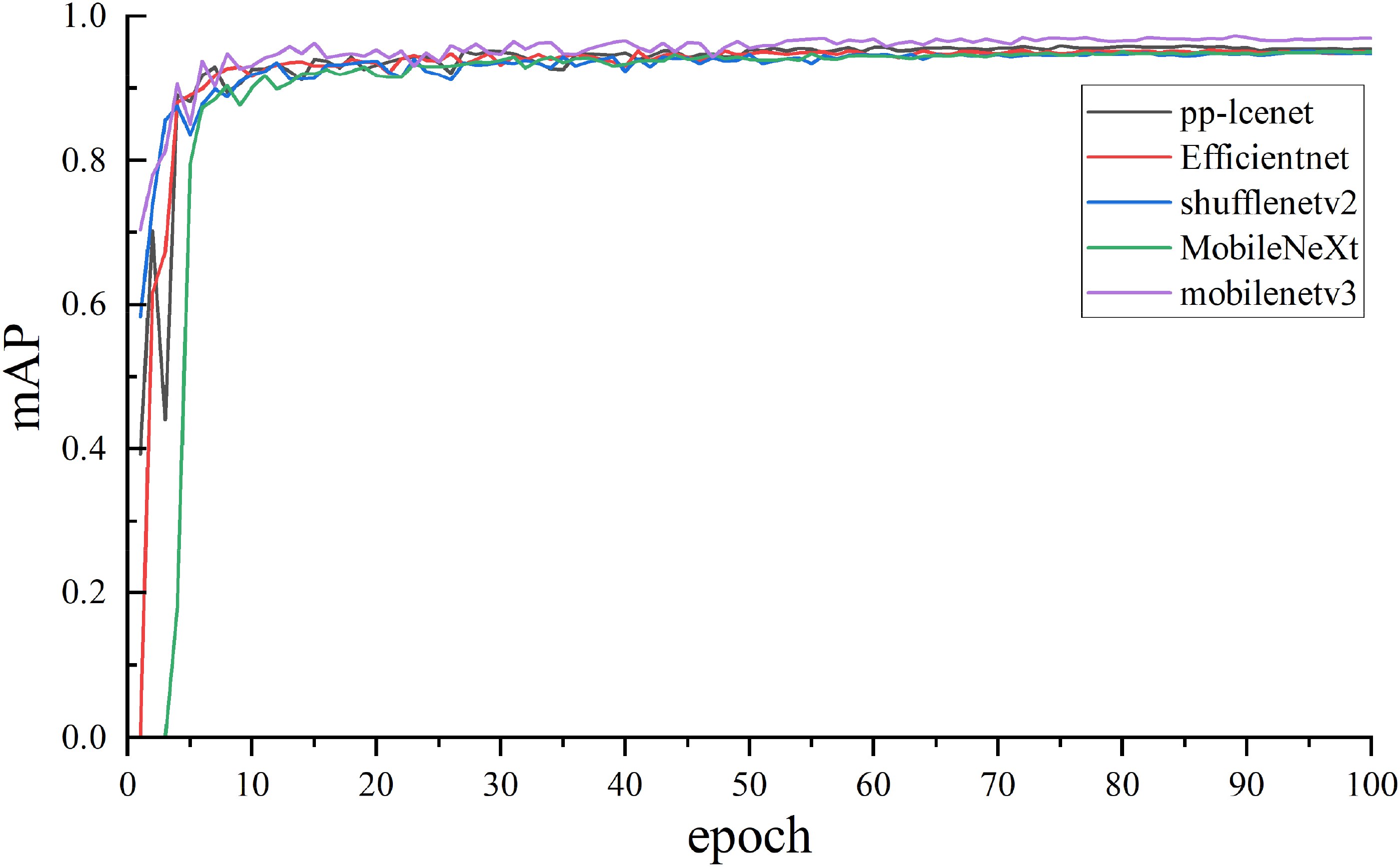
map curves of different algorithm models.
Test comparison of different lightweight structures in the yolov8n-seg framework.

Figures 10 and 11 show the loss and average accuracy results on the five model validation sets obtained by training with the same parameters. The training results of the five models indicate that MobileNetV3 exhibits optimal performance.
The structural model of MobileNetV3 is optimal according to the experimental results in Table 2. The average accuracy improved by 1.0, 0.7, 1.0, and 1.6% compared with PP-LCNet, EfficientNet, ShuffleNetv2, and MobileNeXt structural models, respectively. P is increased by 0.8, 0.6, 1.0, and 0.1%, respectively. R is improved by 0.6, 1.3, 0.5, and 2.0% compared with PP-LCNet, EfficientNet, ShuffleNetv2, and MobileNeXt models, respectively. The MobileNetV3 model takes an average of 7.2 ms to detect a test set image. From the perspective of detection speed and accuracy, the MobileNetV3 model emerges as the most compact and lightweight option for seamless integration into portable systems.
The YOLOv8n-seg model using the MobileNetV3 backbone network structure exhibits a reduced network size compared with the original YOLOv8n-seg network in Table 1. Specifically, it accounts for only 23% of the size of the original model. Meanwhile, reasoning time is shortened from 16.3 ms (FPS = 61.2) to 7.2 ms, which saves 9.1 ms. It significantly improves the possibility of model deployment.
Comparative analysis of different loss functions
The work aimed to verify the effects of different loss functions on the optimization of the YOLOv8n-seg-MobileNetV3 network model. The comparative analysis was performed by simultaneously employing loss functions CIOU, DIOU, 33 SIOU, GIOU, 34 EIOU, 35 WIOU V1, 36 WIOU V2, and WIOU V3 37 with the consistent structure of the target detection networks (Table 3).
Comparison of each loss function.

The SIOU loss function demonstrates superior performance when incorporated into the YOLOv8n-seg-MobileNetV3 model according to Table 3. The SIOU loss function can significantly improve the average accuracy of the mAP 0.5 by 0.3, 1.7, 1.4, 1.0, 1.8, 1.6, and 2.1%, respectively, compared with the other seven loss function models. The SIOU loss function is improved by 0.2, 0.5, 0.3, 0.4, 0.3, 0.2, and 0.3% in P, respectively. The SIOU loss function is increased by 0.9, 1.4, 1.8, 1.1, 2.5, 1.9, and 3.1% in R, respectively, compared with CIOU, DIOU, GIOU, EIOU, WIOU V1, WIOU V2 and WIOU V3 models. The SIOU loss function can enhance the detection performance of the network model, which yields a favorable impact on the target detection task.
Ablation test
The ablation test was performed to further analyze the superiority of the improved algorithm. The work integrated the YOLOv8n-seg model, the enhanced MobileNetv3 architecture, the CARAFE upsampling module, and the SIoU loss function. Table 4 shows the ablation test results.
Ablation test results of the lightweight model.

Note: YOLOv8n-seg indicates the original network; M-YOLOv8n-seg indicates the backbone network in the YOLOv8n-seg network; C-YOLOv8n-seg indicates that the upsampling module is modified in the YOLOv8n-seg network; MCS-YOLOv8n-seg indicates that the backbone network, up-sampling module, and loss function are modified simultaneously in the YOLOv8n-seg network; “×” indicates that the module is not used; “✓” indicates that the module is used.
The lightweight immature-peach target detection model based on YOLOv8n-seg is optimized in the work by the improved method of Mobilenetv3-SIoU-CARAFE (Table 4). The improved model's weight size is only 23.1% of the original model compared with the YOLOv8n-seg network model. P and mAP of the improved model are increased by 0.9 and 0.4%, respectively. Therefore, the enhanced approach can improve the identification accuracy of immature peaches with lightweight.
Identification and verification experiment of immature-peach growth postures
The network's identification results on 300 test sets were analyzed to verify the identification performance of the YOLOv8n-seg lightweight model studied in the work. The 300 test sets covered a variety of different scenarios, including 459 immature peach targets. A total of 403 immature peach targets were accurately identified after the network's identification. Table 5 shows the specific test results.
Visual identification test of immature peaches.

The corresponding actual angles were recorded and compared with the predicted results of immature peaches by pre-labeling these test images. The average accuracy rate achieved a remarkable 87.8%, with the angle estimation error averaging less than ±3.3° in the validated dataset of immature peaches (Eqs. (16) and (17)). The model exhibited favorable performance in accurately identifying the visual cues associated with the growth postures of immature peaches.
Edge computing end test platform deployment
The improved YOLOv8n-seg model was deployed on JETSON AGX ORIN CLB development kits to evaluate the accuracy of immature peach identification in real-world experiments. The immature peach images were examined using the Ubuntu 20.04.6 LTS operating system, Python 3.8 programming language, and PyTorch-1.14 environment.
The improved YOLOv8n-seg lightweight model achieved an average detection time of 31 ms for a 3024 × 4032 pixels image on JETSON AGX ORIN CLB development kits, which facilitated real-time immature peach detection. The processing capability of 32.15 FPS enabled it to meet the real-time detection requirements. The model could realize the real-time detection task of immature peaches in natural scenes on JETSON AGX ORIN CLB (Figure 12).

Identification effect of the model deployment to JETSON AGX ORIN CLB development kits.
Conclusion
The work focused on immature peaches and proposed a method for identifying the growth posture based on YOLOv8n-seg semi-supervised learning and a lightweight strategy.
A method called semi-supervised learning was employed to address high labor costs and extensive workloads in traditional instance segmentation by identifying immature peaches. Pseudo-labels were generated by the supervised model through semi-supervised learning and data enhancement. The model was optimized using the self-training method to mitigate dependence on labeled data and alleviate the costs and workload associated with data labels. A lightweight structural model based on YOLOv8n-seg was proposed to realize the real-time measurement on the mobile terminal. The model incorporated the lightweight concept of the MobileNetv3 network, which resulted in a significant reduction in computations. As a result, the improved model weighed only 23.1% of the original model. It took 31 ms on average to detect a 3024 × 4032 pixels image in the edge computing device JETSON AGX ORIN CLB development kits. The real-time detection of immature peaches in natural scenes was achieved. The network model was optimized by introducing the CARAFE module and SIOU to replace the original up-sampling module and loss function. The capability of global feature identification was enhanced to reduce the boundary frame loss and improve detection accuracy. The improved model was used in the work to predict the coordinate information of immature peaches and calculate their growth angles. The method has achieved remarkable results on 300 test images with an average accuracy of 87.8%. The average error of growth angle estimation was less than ±3.3°, proving the efficacy of the method for accurately identifying the growth postures of immature peaches.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Jiangsu Agriculture Science and Technology Innovation Fund (JASTIF), Postgraduate Research & Practice Innovation Program of Jiangsu Province (grant numbers CX(22)3104, KYCX22_3057).