
Abstract
Pointer meter is widely utilized in the fields of modern industry. Nowadays, intelligent inspection robots are gradually employed in place of labors for inspection task. Pointer meter recognition is one of the most important tasks of inspection robots. This article presents a lightweight pointer meter recognition algorithm, which is suitable for deployment on inspection robots. First, pointer meter is identified by pruned YOLOv5. Afterwards, the dial and the pointer are segmented through improved Deeplabv3+ in which the JPU and depthwise separable convolutions are utilized in lieu of dilated convolutions. After perspective transform and central-line extraction of pointer, the reading of the pointer meter can be determined using the angle method. Experimental results verify the FPS of pruned YOLOv5 improves 13.18% compared to original YOLOv5 and the FPS of improved Deeplabv3+ improves 45.74% compared to original Deeplabv3+. Additionally, the reading accuracy of the algorithm is 98.40% and average fiducial error is 0.32%, which indicate good accuracy. The relative standard deviation of reading is less than 1.4%, which indicates good stability of proposed algorithm. This study proposes a lightweight and accurate pointer meter recognition algorithm based on improved Deeplabv3+, the algorithm is ported to NVIDIA Jetson TX2 NX to verify its stability and accuracy.
Introduction
Pointer meters are commonly used in power systems, the mining industry, manufacturing, and other fields because of their simple structure, strong anti-interference capability, and high reliability. The readings of pointer meters are recorded by inspector traditionally. However, manual inspection is restricted by many factors such as efficiency of inspection, error readings and missed inspections.1–3 In addition, it is dangerous for inspectors to inspect in severe weather or dangerous areas such as thunderstorms or high-voltage environments. Due to an aging population, labor costs are increasing continuously.4–6 With the development of science and technology, manual inspection is gradually replaced by inspection robots. The demand for the inspection robots is urgent in substation, nuclear power station, coal mines and other fields.7–9 The tasks of inspection robots mainly include: meter recognition, temperature measurement of equipment, abnormal state identification of equipment, ambient temperature and humidity measurement, gas and dust detection and so on, of which meter recognition is one of the most important tasks of inspection robot.
There are two modes of image processing for pointer meter recognition: one is to transmit images to a back-end computer via wireless network, the other is to process directly on inspection robot. Back-end mode is less stable and reliable than the second one. It is at risks of losing frames and data interception due to network issues, especially in long-distance application scenarios. Consequently, local computing-based recognition is easier to be applied in a variety of environments.
Nowadays, artificial intelligence and neural networks have been widely used in various fields. In pointer meter recognition.10–13 Neural networks have also succeeded with its excellent performance. Yet most of neural networks rely on complex models and computations. 14 Both in training or testing phases, a hardware platform with sufficient memory space and preeminent computing performance is usually necessary. As other calculations such as path planning and environment data analysis are also carried out on the Industrial Personal Computer (IPC) of inspection robot, the computing resources available for meter recognition are limited. 15 However, limited computing resources limit the efficiency of meter recognition algorithm. The same algorithm will take more time to run locally than on the back-end computer. Thousands of meter recognition tasks will be carried out by inspection robots in a routine inspection. The mode of local computing will significantly increase the time for inspection robots to complete an inspection task. This requires the robot to increase the battery capacity to ensure the running time of the robot. The increase of battery capacity will cause the weight increasing of robot, which in turn increases the power of driving motor and bring about a series of effects. Last but not least, the continuous inspection mode is rising, which puts forward higher requirements for the computational efficiency of local computing-based meter recognition algorithm. Therefore, it is vital to develop a lightweight and accurate recognition algorithm for inspection robots.
In recent years, significant research efforts have been devoted to the field of pointer meter recognition. These methodologies can be broadly categorized into two distinct groups: traditional imaging-processing algorithms and modern machine learning-driven approaches.16–18 The traditional algorithms usually utilize template matching to achieve positioning of meter. The pointer is then extracted via the binary method. Afterwards, the deflection angle of pointer is calculated by Hough transform. For example, Chen et al. adopted the Edge-based Geometric Matching (EGM) and Pyramidal Gradient Matching (PGM) schemes are used for detecting the pointer meter region. 19 The mean accuracy of reading was 95% or above. Liu et al. 20 introduced a detection method to automatically read pointer meters in substations. They used Multi-Scale Retinex with Colour Restoration (MRSCR) and Hough transform to detect the position of the pointer. The maximum relative error was 1.378%. Bao et al. 21 introduced a computer vision method to automatically identify the readings of multiple pointer meters. The measurement precision was improved by inverse perspective mapping. Zheng et al. 22 proposed a recognition algorithm for the automatic reading of the analogue measuring meters indication. The MSRCR, perspective transform and Hough transform were utilized to reduce the influence of different brightness levels. The maximum rounding error equalled to 0.36%. Traditional algorithms are more likely to be affected by background environment and illumination, which are less robust compared to modern algorithms. Modern algorithms employ machine learning to build models for data analysis. From a statistic point of view, the model can be learned from data. Then, the model is utilized to predict new data. For instance, Lin et al. 23 suggested a method for automatically recognizing text using deep learning. To enhance the performance of instance segmentation, the PrRoI pooling technique was utilized as a substitute for the Roi Align component in the Mask-RCNN. The challenges of non-uniform illumination, wide-ranging illumination variation, and intricate backgrounds, were effectively resolved. Lin et al. 24 proposed an instrumental intelligent reading algorithm based on CNN. YOLOv3 was utilized to detect a panel area in an image. Then the numerical prediction was obtained by a multi-layer convolution neural network. The pointer meter recognition rate was 98.71%. The reading accurate rate of numerical values was 97.42%. Hou et al. 25 proposed a new method for recognizing pointer meters using Wireless Sensor Networks (WSNs) and CNN. The maximum fiducial error of the recognized result was approximately 0.27%. The payload transmission data of the WSN was reduced from 112.5 kB to 5 bytes. Zhang et al. 26 proposed a method for improving the automatic readability of pointer meters using Yolov7 and Hough transform for recognition. The pointer readings obtained using this method are accurate to a level exceeding 95%. Hou et al. 27 proposed a novel approach based on YOLOX convolutional network and semantic segmentation technology. The fiducial errors of the reading values in this approach do not exceed 0.31%. Despite there are lots of researches on pointer meter recognition, they mainly focus on the accuracy and robustness of readings, with less studies on the light-weighting of pointer meter recognition algorithm.
In this study, we propose a new deep-learning algorithm based on Deeplabv3+ for pointer meter recognition, focusing on the light-weighting of the model. First, the YOLOv5 is utilized to identify the target meter. The YOLOv5 is pruned by network slimming to compress computation consumption. Afterwards, the binary masks of dial and pointer are obtained by improved Deeplabv3+. In improved Deeplabv3+, the dilated convolutions are replaced by Joint Pyramid Upsampling (JPU) and depthwise separable convolutions. What’s more, the loss function is improved based on distance map for better segmentation accuracy. Subsequently, the perspective transform matrix is calculated to eliminate errors caused by shooting angle. The centroid of pointer binary mask is utilized to extract pointer’s central-line. Eventually, the reading of pointer meter is calculated via angle method.
The remainder of this paper is structured as follows. Section “Recognition algorithm of pointer meter” provides a detailed explanation of the proposed approach. A series of experiments and discussions are carried out to evaluate the performance of the methodology in Section “Experiments and Discussion”. In Section “Conclusion,” the conclusion and future work are introduced.
Recognition algorithm of pointer meter
The approach is composed of five principal components: target recognition, segmentation of dial and pointer, perspective transform, central-line extraction of pointer and reading calculation. The five steps of proposed algorithm are illustrated in Figure 1, and the pseudocode is shown in algorithm 1.
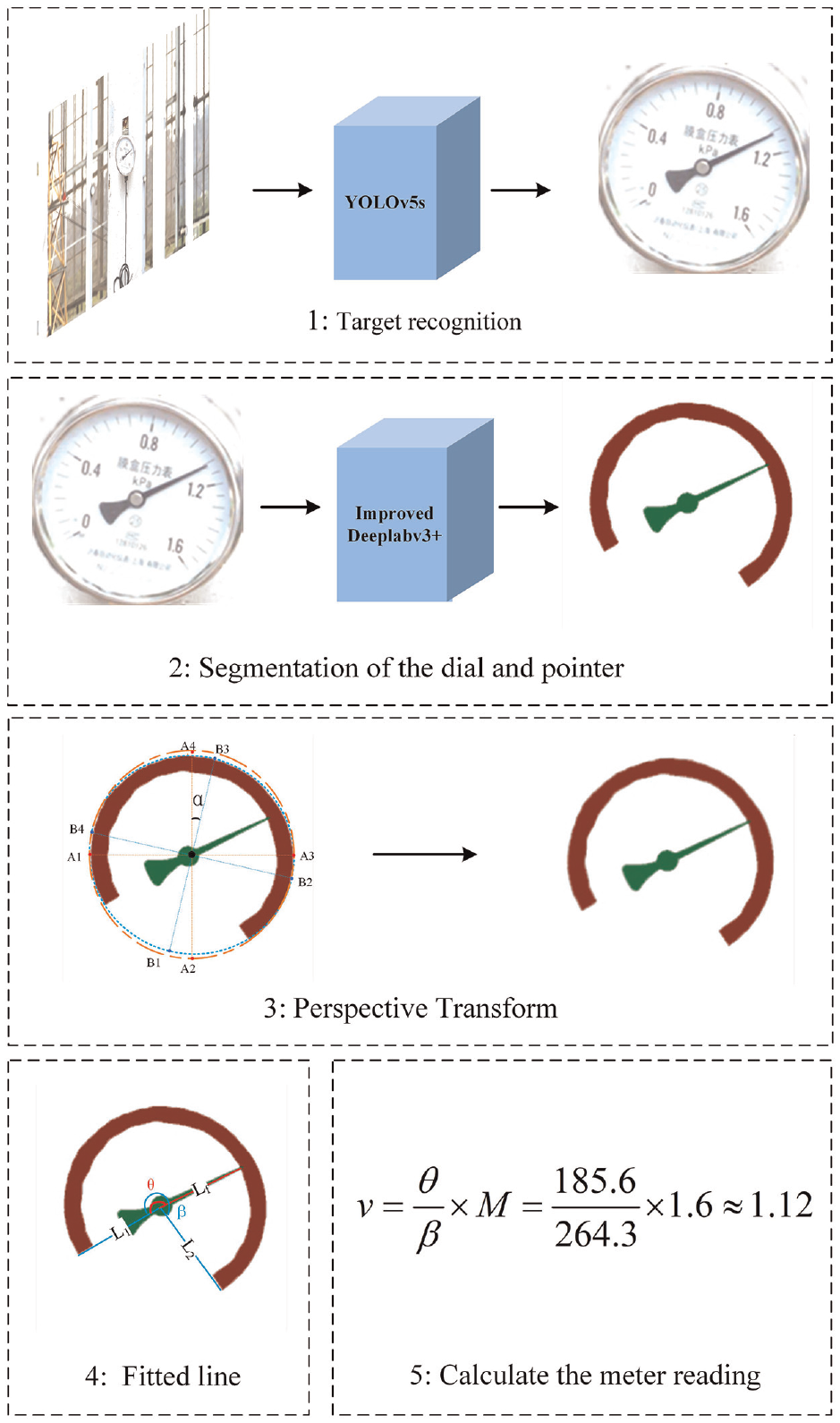
The architecture of the proposed pointer meter recognition algorithm.

Recognition of pointer meter by pruned YOLOv5
You Only Look Once is well known as the state-of -the-art object detector. Compared to YOLOv4, YOLOv5 is more lightweight in model size. At the same time, its detection accuracy is comparable to YOLOv4. It consists of three general modules: backbone for feature extraction, neck for improving diversity and robustness of feature, and output for object detection. 28 There are four types of YOLOv5: YOLOv5s, YOLOv5m, YOLOv5l and YOLOv5x. The YOLOv5s is appropriate for deployment on inspection robots due to its simple structure.
To further compress the model and reduce its computational cost, network slimming is used to prune the YOLOv5s in this study. The principle of network slimming is shown in Figure 2. A scaling factor is reused from a batch normalization layer. Then it is associated with each channel in convolutional layers. During training, sparsity regularization is applied to these scaling factors to identify unimportant channels which is in orange color in Figure 2. The channel with scale factor below the threshold will be pruned. The computational consumption is decreased in this way. 29
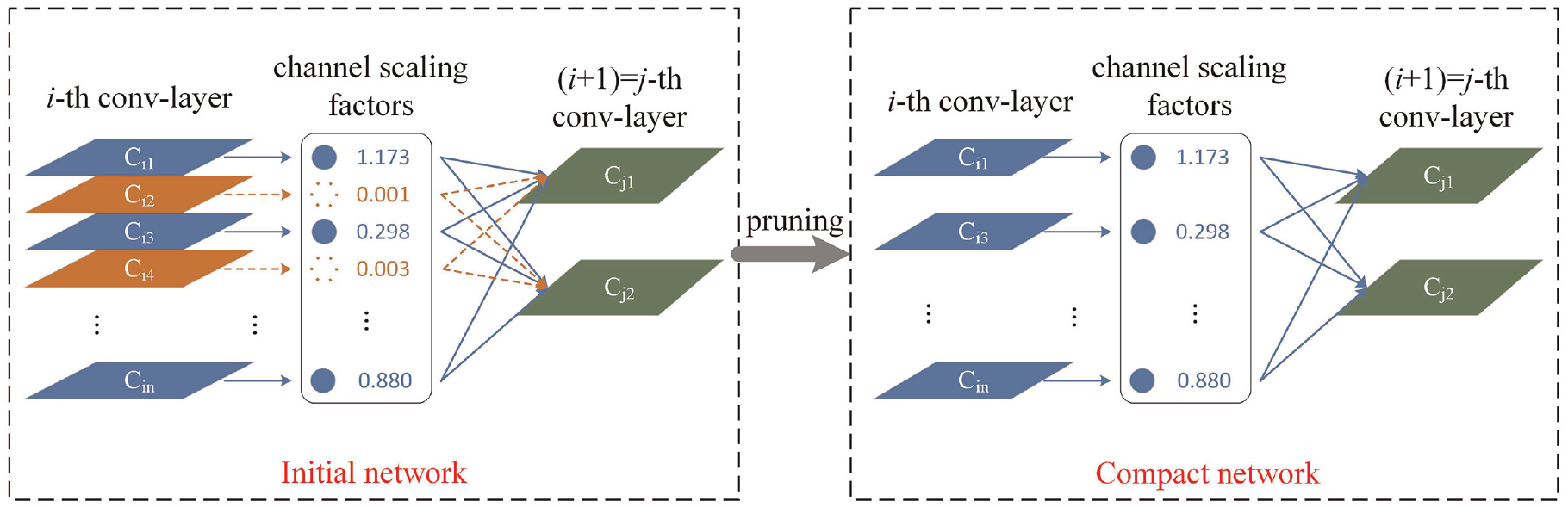
The pruning principle of network slimming.
Segmentation of dial and pointer by improved Deeplabv3+
Deeplabv3+ 30 is extensively implemented in many fields due to its excellent performance.31–34 It is composed of encoder-decoder structure, which helps the model work efficiently. The model utilizes dilated convolutions in the encoder module to effectively handle multi-scale contextual information. Additionally, the decoder module enhances segmentation performance by concentrating on object boundaries. Therefore, this study adopts the encoder-decoder approach. The framework of the improved Deeplabv3+ is illustrated in Figure 3. Compared to original Deeplabv3+, the dilated convolutions of Deep Convolutional Neural Network (DCNN) are replaced by JPU. 35 The dilated convolutions of Atrous Spatial Pyramid Pooling (ASPP) are replaced by depthwise separable convolutions, which help compress computation. The FLOPs of the improved model is 260.15642624G, and the number of parameters is 59.234773M. Meanwhile, to improve the segmentation performance of model, the improved loss function is utilized to increase the loss weight of edge pixels.
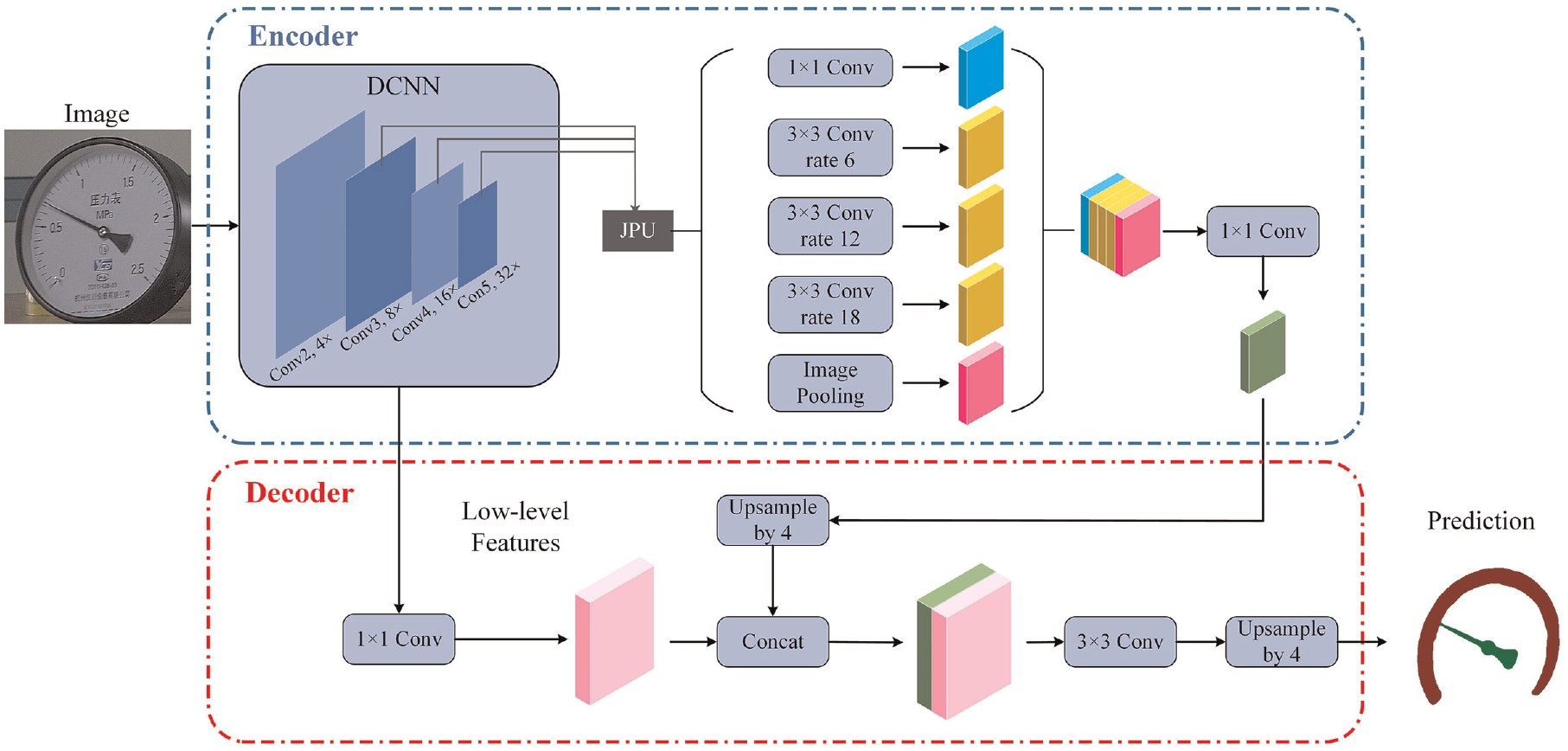
The framework of improved Deeplabv3+.
JPU module
The differences between dilated convolutions and JPU lie on the last two convolution stages of DCNN. In the 4th convolution layer (Conv4), for example, the input feature map is first processed by a regular convolution layer, followed by a series of dilated convolutions (dilated rate = 2). Differently, the JPU first processes the input feature map with a stride convolution (stride rate = 2), and then generates the output via several regular convolutions. 35
As presented in Figure 4, the JPU module is constructed via three stages. Concretely, in stage (a), the input feature maps are firstly processed by convolution blocks for better fusion. Then, the feature maps generated by stage (a) are upsampled and concatenated, resulting yc. The features of yc are extracted by four separable convolutions with different rates (1, 2, 4, and 8). Consequently, multi-scale textual information can be obtained on a multi-layer feature map. Finally, the features are converted into predictions using a convolution block.
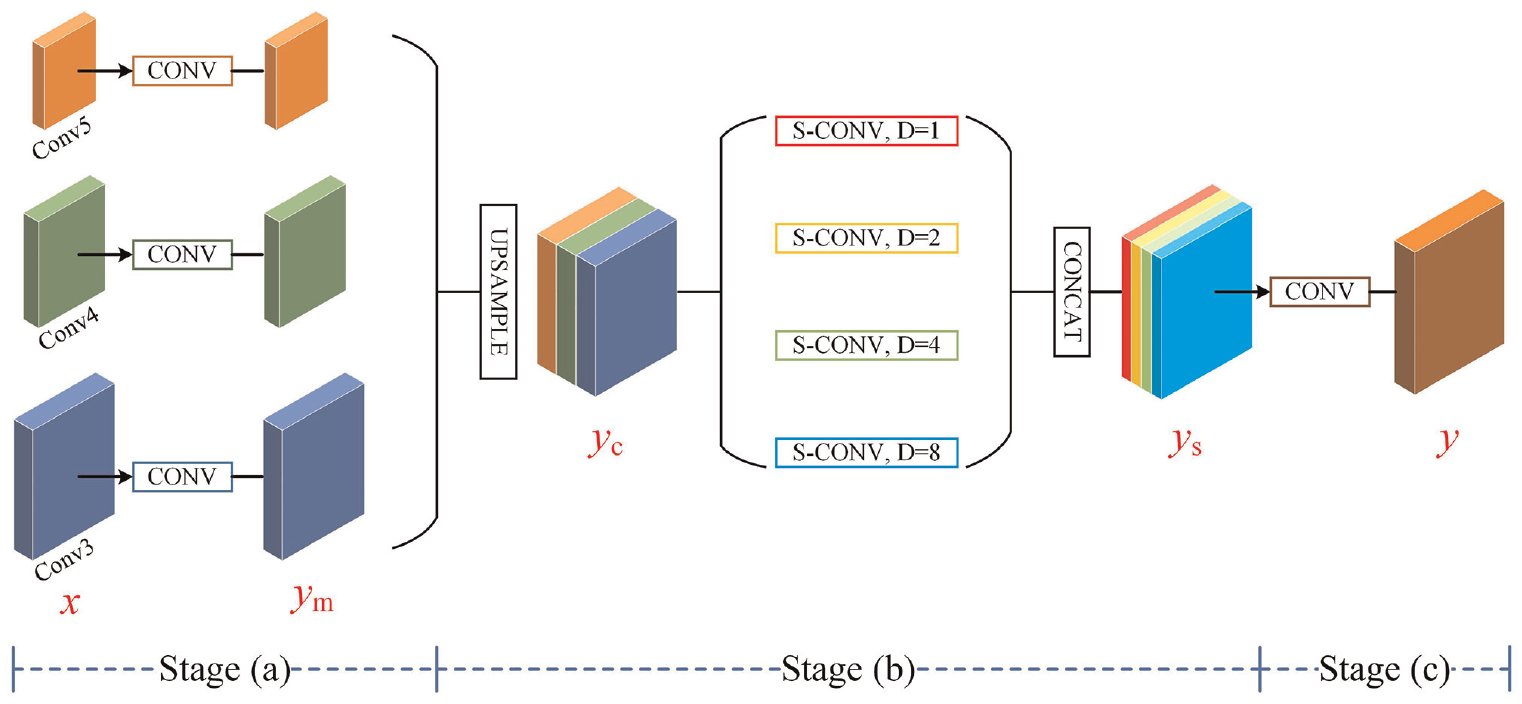
The joint pyramid upsampling.
Improved loss function
The edge segmentation accuracy of pointer and dial is directly related to reading accuracy. However, the dial is not distinct compared with background in actual pictures. In order to improve the segmentation performance of edge pixels, an improved loss function is deployed into Deeplabv3+ model. The loss penalty term derived from distance map is induced into loss function, 36 which can increase the loss weight of edge pixels. The error-penalizing distance map is presented in Figure 5. As shown in Figure 5, the pixels closer to the edges of the pointer and dial are weighted more, and pixels farther away are weighted less. The improved loss function is formulated as:
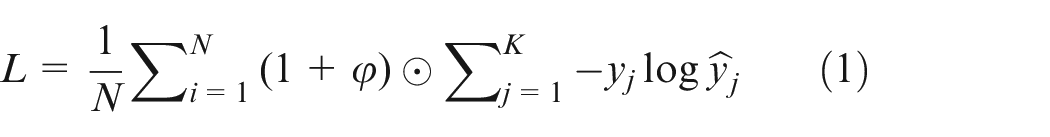
Where
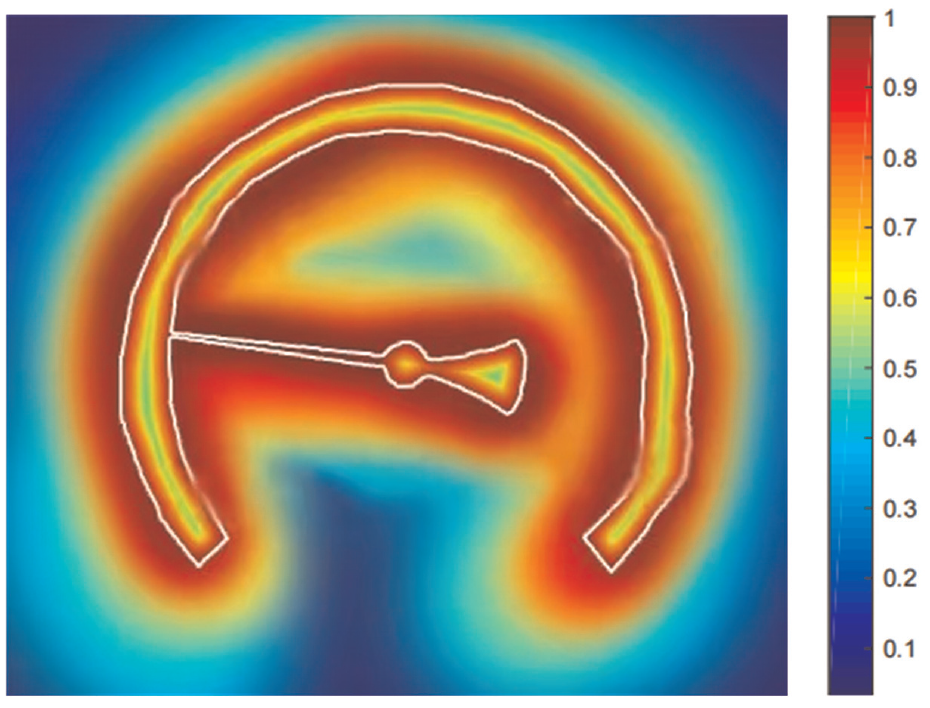
The error-penalizing distance map.
Correcting meter mask by perspective transform
When the inspection robot captures the meter image, shooting angle between the camera and the pointer meter always exists. Thus, the pointer meter in captured image is an ellipse rather than a circle. Therefore, the perspective transform is applied to calibrate the shooting angle for better accuracy. The principle of the perspective transform is illustrated in Figure 6.
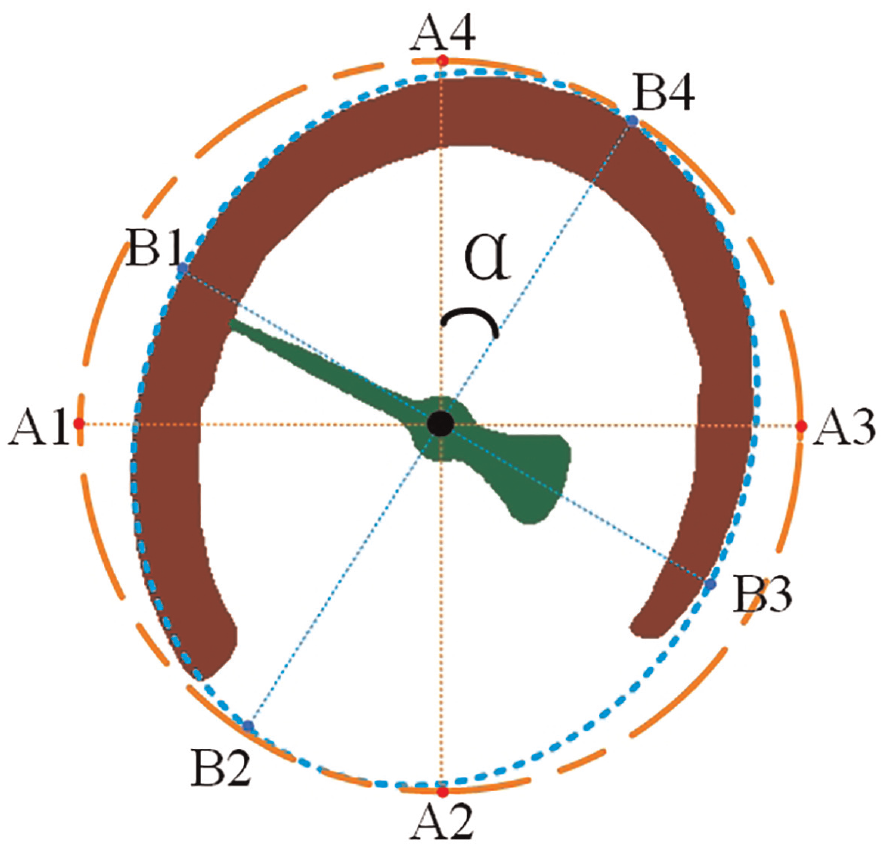
The principle of perspective transform.
The minimum enclosing circle and the minimum enclosing ellipse of the dial mask are fitted, respectively. A1–A4 denote the four intersections of the circle with horizontal and vertical lines; B1–B4 indicate the four intersections of the ellipse with long axis and short axis; O is the center of the circle; α means the deflection angle of ellipse. The parameters of circle and ellipse are denoted as
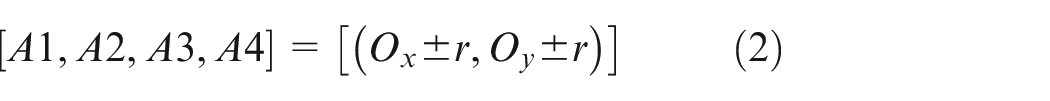
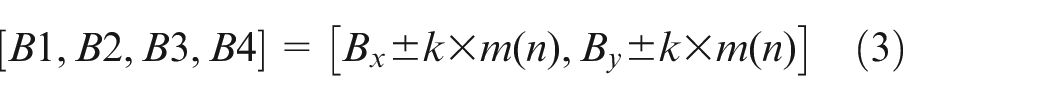
Where
Based on the coordinates of the eight points, we can calculate the perspective transform matrix A using the following formula.

With the perspective transform matrix A, the masks of pointer and dial are modified. The correction effect is presented in Figure 7.
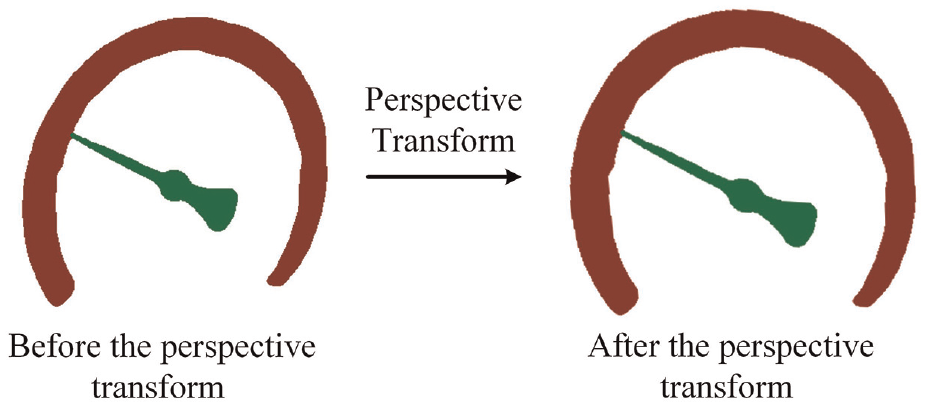
The perspective transform for correcting masks of dial and pointer.
Central-line extraction of pointer
Central-line is commonly extracted via the least squares method. 37 However, the least squares method cannot extract vertical lines. What’s worse, the more vertical the pointer is, the worse performance the least squares method is on central-line extraction.
In this work, the centroid-based line extraction method is proposed for better accuracy. The convex hull of the pointer can be obtained by the method in literature, 38 and the minimal enclosing triangles of the pointer can be obtained by the method in literature. 39 The minimum circumscribed triangle of the pointer binary mask is fitted. As illustrated in Figures 8 and 9.

The acquisition process of the convex hull of the pointer and the minimal enclosing triangles of the pointer.
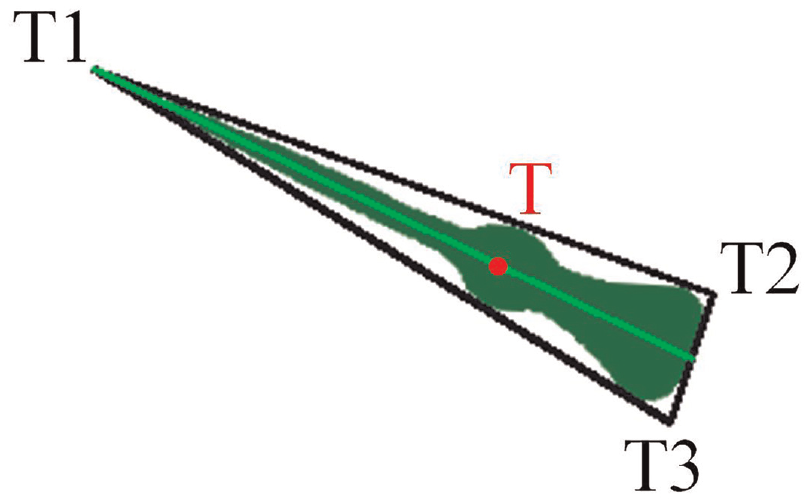
The diagram of central-line fitting for pointer.
The three vertices of the triangle are noted as
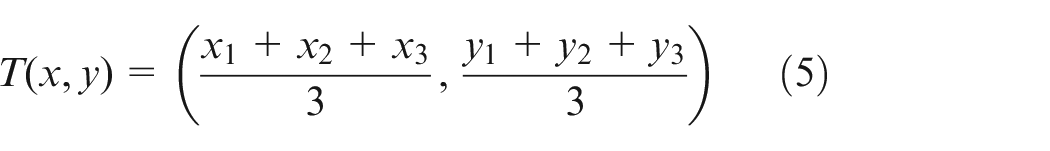
Then, the distances from three vertices to point T are calculated, respectively. T1 is the point which is farthest from point T. Subsequently, the central-line is extracted by connecting point T1 and point T.
Reading calculation
The reading is calculated via rotation angle of pointer as shown in Figure 10. The coordinate system is established by taking the pointer’s centroid as origin. Lf represents the extracted central-line of pointer; the points of dial mask with the minimum y-axis coordinates in the third and fourth quadrant are recorded as P1 and P2, respectively; L1 and L2 denote the lines from P1, P2 to point O, respectively;
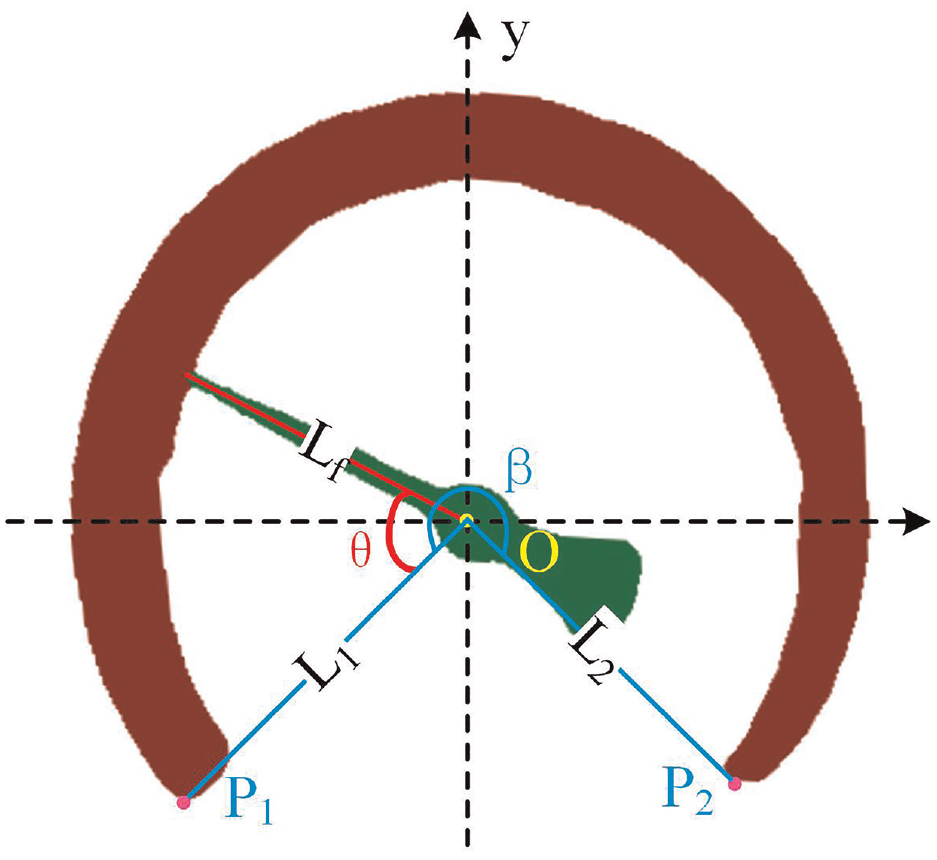
The schematic of the reading calculation.
The measurement range of meter M is obtained from priori information. Therefore, the reading
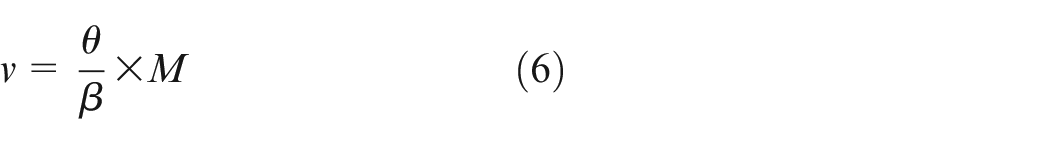
Experiments and discussion
Experimental settings
Dataset
The dataset used in this study contains 5764 RGB images. Each image in the dataset has a resolution of 2560 × 1440 pixels, and the dataset is divided into two subsets at a 3:1 ratio. To enhance the robustness of algorithm and its adaptability to the environment, the dataset covers pointer meter images with complex backgrounds, multiple scales, different angles and so on. Some of the datasets are presented in Figure 11.

Part of the images in the dataset.
Experiments setting
To assess the performance of the proposed method in recognizing pointer meters, several experiments are conducted to show its superiority. We compared the performance of pruned YOLOv5 with original YOLOv5. We also compared the performance of improved Deeplabv3+ with classic semantic segmentation models, namely UNet, 40 PSPNet 41 and FCN. 42 We used the same settings (hyperparameters) for all models: 500 epochs; a learning rate of 0.0001; batch size of 8; base size of 513; crop size of 513; Adam optimizer, momentum of 0.9. All the models are run on Pytorch1.9 and Python3.6. During the training phrases, the hardware platform is NVIDIA GeForce GTX 1070 GPU. After training, the trained models are ported on NVIDIA Jetson TX2 NX for testing, which is widely utilized as embedded device.
Evaluation index
The format of our dataset closely resembles that of the well-known PASCAL VOC dataset. Average Precision (AP) and Average Recall (AR) are utilized to verify the performance of pruned YOLOv5. The Frames Per Second (FPS) is employed to assess the computational complexity of models. Higher FPS means less computation consumed by model. In the Intersection Over Union (IOU) range from 0.5 to 0.95, the average of all accuracies is denoted as AP; the average of all recalls is denoted as AR. The precision and recall are calculated as follows:


Where TP represents the count of positive samples predicted as positive by YOLOv5; FP represents the count of negative samples predicted as positive; FN represents the count of positive samples predicted as negative.
In order to analyze the performance of improved Deeplabv3+, Pixel Accuracy (PA), FPS and Mean Intersection Over Union (MIOU) are calculated as evaluation standards. PA represents the ratio of pixels marked correctly to total pixels. MIOU denotes the ratio of intersection to union between true values and predicted values. The PA and MIOU are respectively calculated by:

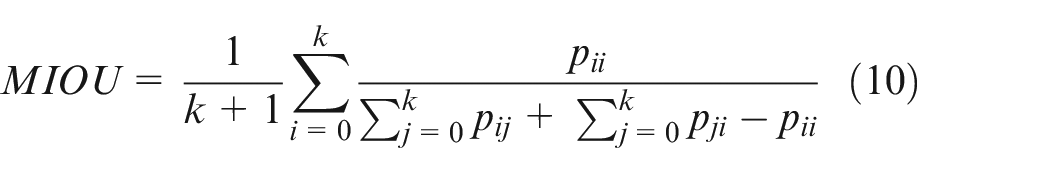
Where
In addition to the above indexes, the relative standard deviation is utilized to assess the stability of the algorithm. The fiducial error is utilized to assess the accuracy of the algorithm. The relative standard deviation
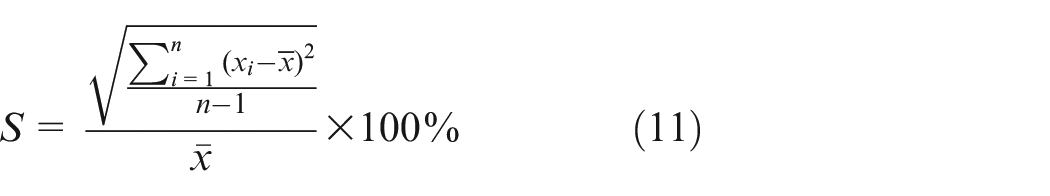
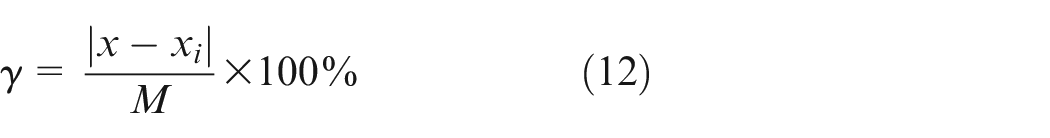
Where
Experimental results and discussion
Performance evaluation of pruned YOLOv5
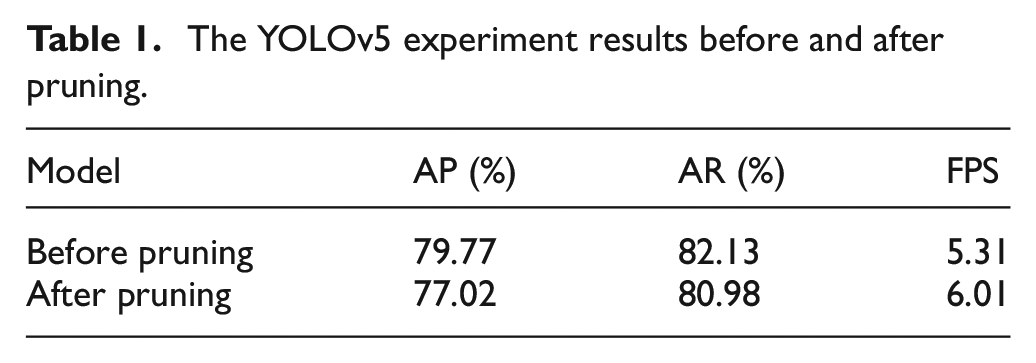
The first experiment aims to analyze the performance of the pruned YOLOv5 in pointer meter detection. The experimental results, as presented in Table 1, indicate that the FPS improved by 13.18% after pruning. The AP and AR decrease by 2.75% and 1.15%, respectively. It can be attributed to the pruning of unnecessary parameters, which reduces the computation consumption. At the same time, detection performance is slightly degraded. Due to there is only one target to be detected, the problems caused by the degradation of model performance can be alleviated by adjusting the confidence threshold. Thus, the pruning of YOLOv5 will not affect the final result in this study.
The YOLOv5 experiment results before and after pruning.
Performance evaluation of improved Deeplabv3+
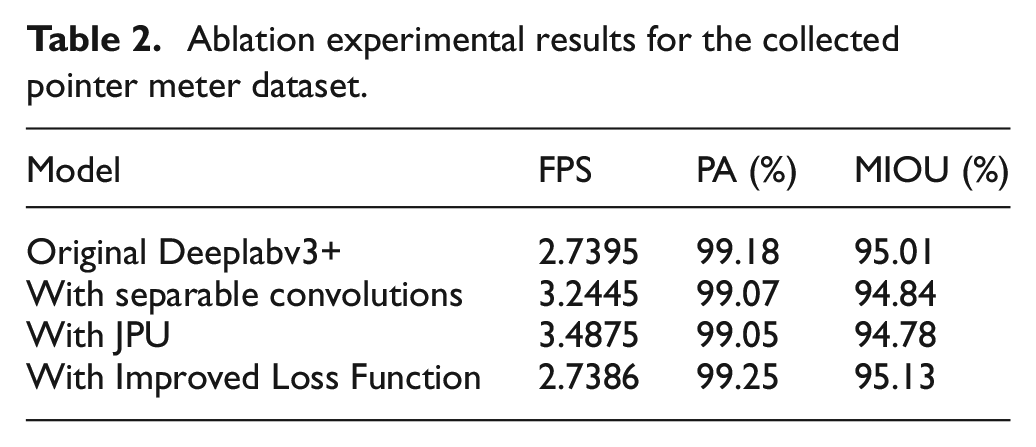
To analyze the role of the three improvements on Deeplabv3+, the ablation experiment is designed. Three improvements are applied to Deeplabv3+ model for evaluation, respectively. The model in which ASPP is replaced by depthwise separable convolutions is called With Separable Convolutions. The model with JPU is called With JPU. The model with improved loss function is called With Improved Loss Function. The experimental results are listed in Table 2. The results indicate that the depthwise separable convolutions and JPU reduce the computational consumption of Deeplabv3+. Furthermore, there is no significant decrease in PA and MIOU. The improved loss function slightly improves the PA and MIOU of Deeplabv3+.
Ablation experimental results for the collected pointer meter dataset.
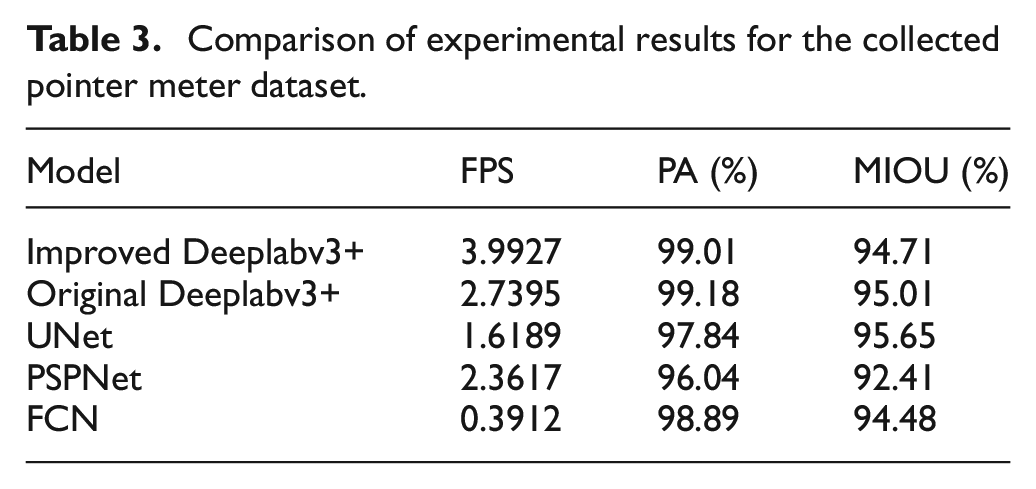
To verify the performance of improved Deeplabv3+, comparison experiment is conducted on original Deeplabv3+, UNet, PSPNet and FCN under the same conditions. The experimental results are listed in Table 3. The PA, MIOU and FPS of the improved Deeplabv3+ are up to 99.01%, 94.71% and 3.9927, respectively. As expected, the improved Deeplabv3+ achieves highest FPS, which is improved 45.74% compared to original Deeplabv3+. High FPS means lighter model. It can be attributed to the substitution of dilated convolutions by JPU and depthwise separable convolutions. We should highlight that the PA and MIOU of improved Deeplabv3+ are the second compared to other models, which are 0.17% and 0.3% lower than the original Deeplabv3+. It means the segmentation accuracy is comparable to original Deeplabv3+. It can be attributed to the improved loss function which enhances the loss weight of edge pixels and mitigates the degradation of segmentation accuracy. According to the experimental results, the amount of increase of the FPS is far greater than the amount of decrease of segmentation accuracy. Moreover, the slight decrease of segmentation accuracy has little effect on the recognition accuracy of meter pointer reading.
Comparison of experimental results for the collected pointer meter dataset.
Partial segmentation results are presented in Figure 12. The results predicted from two Deeplabv3+ models are superior. While the results predicted from other models have issues such as rough dial edge segmentation, incomplete pointer segmentation and incorrect segmentation, which are marked by white circle in the figure.
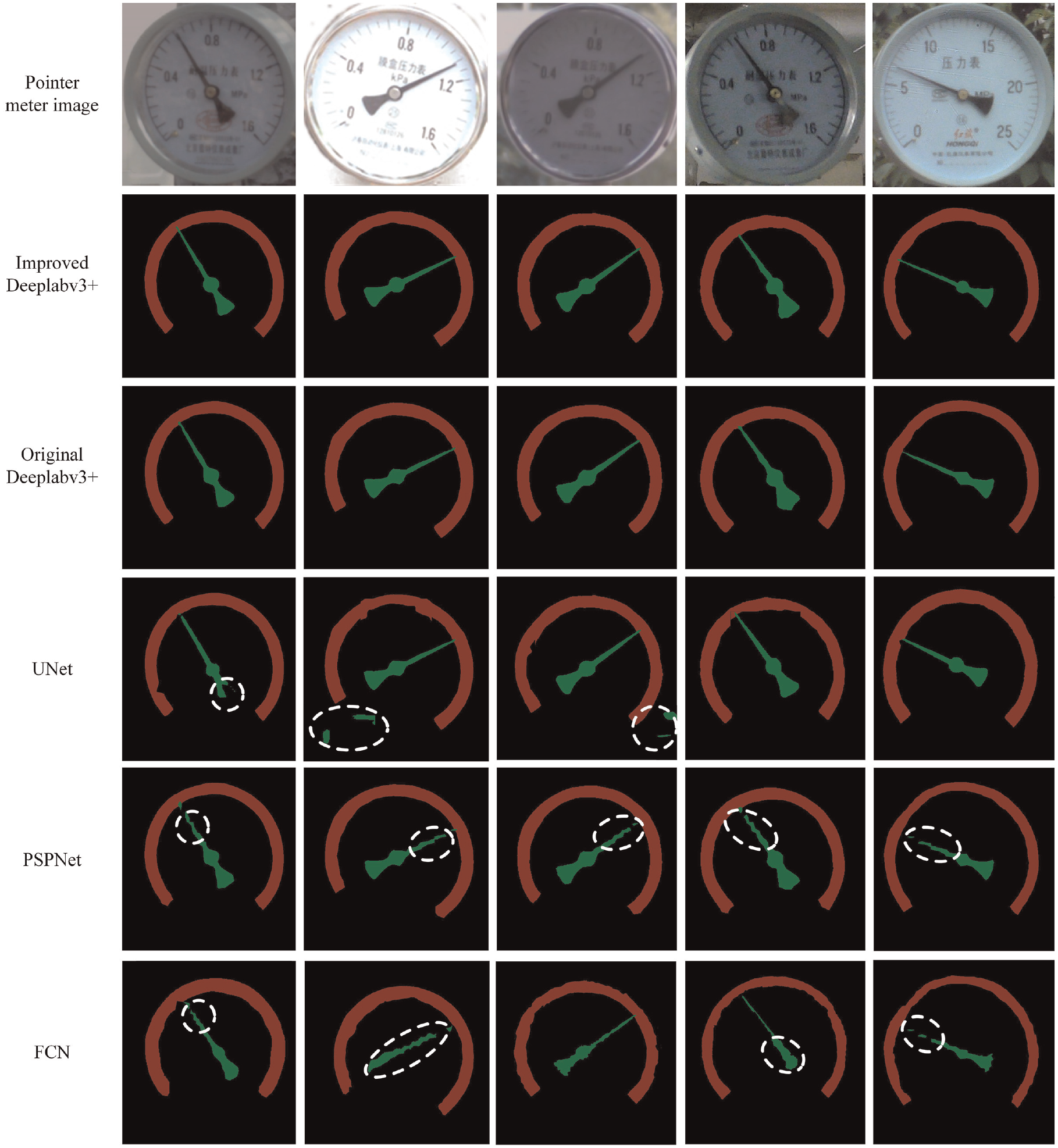
Segmentation results of the pointer meter dataset obtained by different methods.
In order to verify the robustness of the improved Deeplabv3+ for segmentation of dial and pointer, meter images are tested under different real conditions. The experimental results are shown in Figure 13. It is evident that even when the meter images undergo changes various brightness, rotation, or blur, the improved Deeplabv3+ can still accurately segment the dial and pointer without missing detection. The results show the high accuracy and strong anti-interference ability of the improved Deeplabv3+.

Segmentation results under different conditions.
Reading accuracy experiment
To test the stability of the proposed recognition algorithm, the repeatability tests are conducted on NVIDIA Jetson TX2 NX. The pointer meter is shot with different positions, angles and illuminations. Then images are processed via the proposed methodology. Ten sets of readings are obtained. Four set of reading results are displayed in Figure 14.
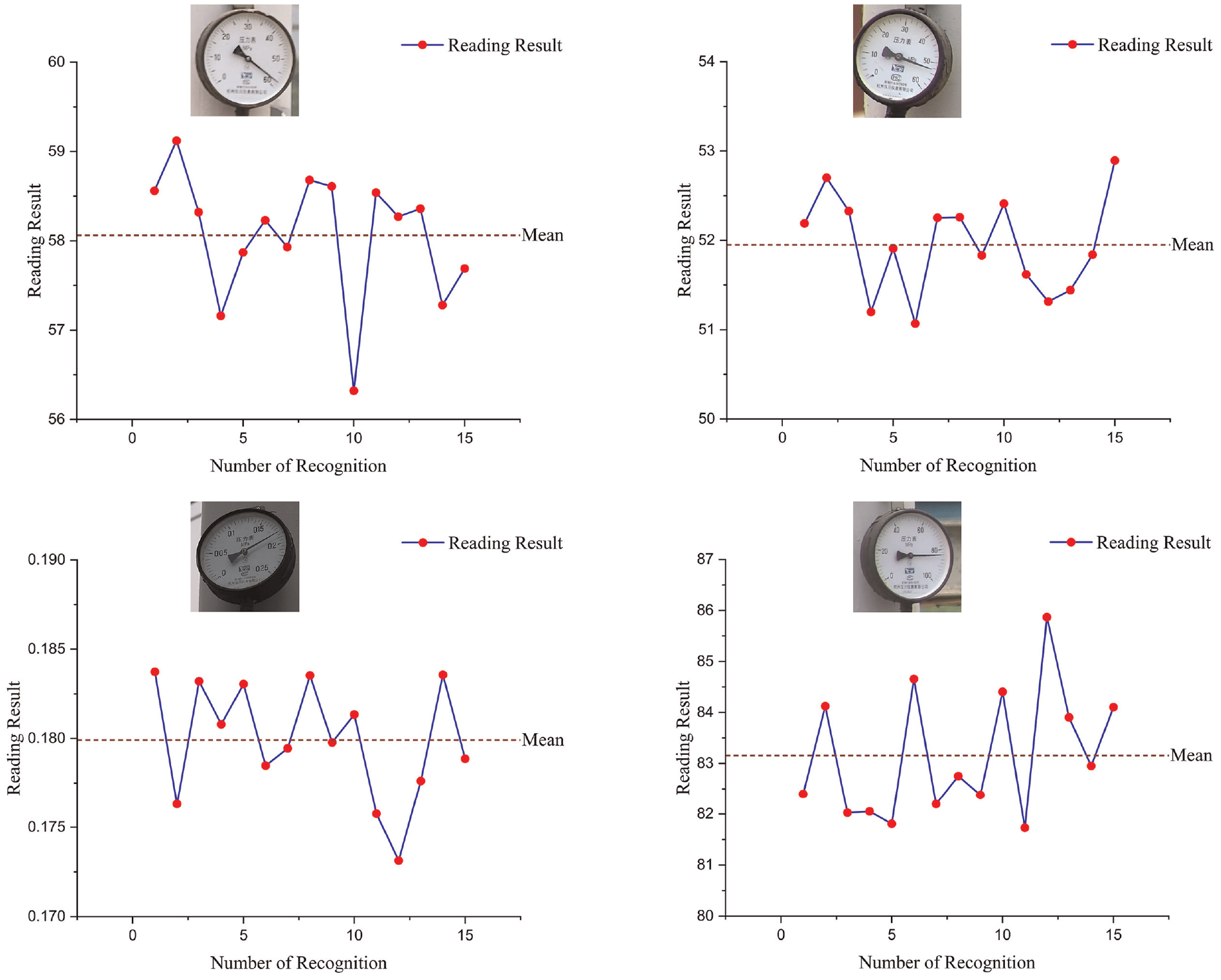
The reading results of the repeatability test.
The experimental relative standard deviations are both below 1.8%. Low relative standard deviation indicates excellent stability and reliability of our algorithm. Perspective transform and pointer central-line extraction are analyzed as the two main error sources. In perspective transform step, there is a certain deviation in the fit of the minimum circumscribed circle and the minimum circumscribed ellipse of dial. So the error caused by shooting angle still exists. When pointer central-line is extracted based centroid, the reading error is arisen by deviation between the fitted centroid and the actual centroid.
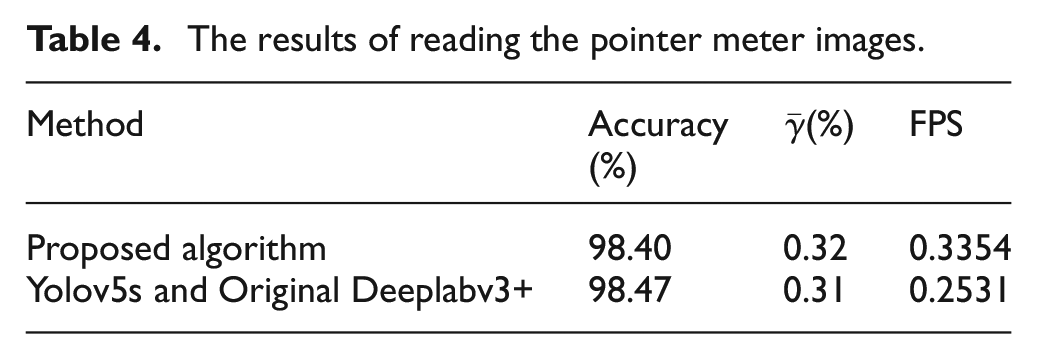
To verify the performance of the proposed recognition algorithm, the proposed algorithm is compared with the original algorithm on NVIDIA Jetson TX2 NX. Table 4 shows the results. The accuracy of readings is determined by the percentage of images with a fiducial error of less than 2%. As shown in Table 4, the reading accuracy and average fiducial error of the two algorithms are basically similar, both of which can meet the accuracy requirements of substation meter identification. However, the proposed algorithm has a higher FPS, which can improve the inspection efficiency of inspection robots.
The results of reading the pointer meter images.
Conclusion
Pointer meter recognition is one of the most important tasks of inspection robots, which are widely employed in the fields of modern industry. This work presents a lightweight and accurate pointer meter recognition algorithm based on improved Deeplabv3+.
The main contributions are as follows. To reduce computation consumption, the YOLOv5s is pruned by network slimming. Furthermore, in improved Deeplabv3+, the dilated convolutions are replaced by JPU and depthwise separable convolutions. To improved reading accuracy, the perspective transform is utilized to reduce the error caused by shooting angle. Meanwhile, distance map is introduced to loss function in improved Deeplabv3+, which increases edge pixels loss weight for better segmentation accuracy.
A series of experiments are conducted to assess the performance of the proposed algorithm. The light-weighting of pruned YOLOv5 is evaluated by FPS. Results indicate that the computation consumption of YOLOv5 is reduced by pruning. The light-weighting and accuracy of improved Deeplabv3+ is evaluated by three statistical indicators, including PA, MIOU, and FPS. The experimental results indicate that the enhanced Deeplabv3+ demonstrates superior performance in terms of lightweighting and segmentation accuracy compared to the original Deeplabv3+ and other state-of-the-art semantic networks, namely UNet, PSPNet, and FCN. Furthermore, the algorithm is ported to NVIDIA Jetson TX2 NX and compared with the traditional algorithm. The experimental results indicate that the proposed algorithm not only has almost the same accuracy and average fiducial error as the original algorithm, but also increases the FPS by 32.5%, which will effectively enhance the inspection robot’s efficiency and reduce its power consumption. Our research improves the inspection efficiency of the inspection robot, reduces the operation energy consumption of the robot, and improves its endurance.
The method studied in this paper still has shortcomings in the recognition of instrument readings in complex environment such as rainy days and foggy days. In future study, we would like to research pointer meter recognition algorithms under complexity environments, where the pointer meters are easily affected by dust, reflection, fog, and other factors. We plan to enhance the anti-interference ability of pointer meter recognition algorithm by adversarial neural network and image pre-processing.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Natural Science Foundation of Fujian Province (Grant No. 2023J01047) and the Natural Science Foundation of Xiamen City (Grant No.3502Z20227185).
Data availability statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.