
Abstract
Model-based stereo vision pose estimation depends on the establishment of the model. The photo-model-based method simplifies the model-building process with just one photo. Programming languages do not predefine the shapes, colors, and patterns of objects. In the past, however, it was necessary to calculate a pixel per metric ratio, that is, the number of pixels per millimeter of the object, based on the photo’s shooting distance to generate a photo-model with the same size (length and width) as the actual object. It restricts the real application. The proposed method extends the traditional photo-modeling algorithm and relaxes the photo prerequisite for target pose determination. Various pixel per metric ratios will be assumed to generate 3D photo-models of different sizes. These models will then be employed in stereo vision image matching techniques to detect the pose of the target object. Since it is not a data-driven method, it does not require many pictures and pretraining time. This article applies the algorithm to the cleaning of seaports and aquaculture, aiming to locate dead or diseased marine life on the water surface before collection. Pose estimation experiments have been conducted to detect an object’s pose and a prepared photo’s pixel per metric ratio in real application scenarios. The results show that the expanded photo-model stereo vision method can estimate the pose of a target with one pixel per metric ratio unknown photo.
Introduction
Robots play an important role in marine biological fishing, invasive species control, and surface collection. Using robots such as autonomous underwater vehicles (AUVs) for precise positioning and targeted marine creatures can reduce the capture of nontarget species and minimize the impact on the marine environment. They are used for water surface cleaning and retrieval in marine ports and aquaculture.
Estimating the six degrees of freedom (DOF) pose of a marine creature floating on the water surface is crucial for autonomous robots to track or grasp it effectively. Concerning automated robots, visual information is expected to allow robots to adapt to different environments. 1,2 For a robot with vision sensors, such as cameras, it has been difficult till now to accurately detect the 3D pose of the target object, especially if the target object cannot be predefined since the shape or size is arbitrary. On the other hand, some vision-based AUVs have been researched, for example, for eliminating invasive species with a monocular camera. 3 In contrast to the current state of robot vision research for use on land, applying robot vision in water is at a lower stage.
Since monocular vision has a single and cheap hardware setup, it is widely utilized for visual pose detection. 4,5 A fish-catching robot has been developed to deal with problems of the target’s 3DOF recognition. 6 However, it cannot avoid the disadvantage that its depth distance measurement is inaccurate. Many studies have used Red, Green, Blue, and Depth (RGB-D) cameras composed of one RGB camera and depth sensor with infrared light to improve the distance detection abilities of monocular vision. 7,8 However, sometimes, depth information is not readily available, including systems operating outdoors, where common depth sensors do not work well with noisy and sparse depth information. 9,10 Furthermore, optical laser sensors have been explored for vision tasks in previous studies. 11 –14 However, these sensors often come with a higher cost. With the development of deep-learning technology, monocular RGB images can also achieve pose recognition. 9,15 However, this requires many pictures and pretraining time.
Unlike monocular vision and RGB-D methods, stereo vision is another method for estimating 3D pose and perceives a greater variety of target material properties and light conditions. 16 When it comes to pose detection, stereo vision methods can be roughly categorized into two types: stereo-matching and model-matching methods.
Stereo matching, also known as disparity estimation, utilizes epipolar geometry to compute the 3D coordinates of a physical point (2D–3D method). In terms of stereo-matching methods, feature-based approaches are commonly used for pose detection. These methods involve extracting feature points and matching them using techniques such as Fast, 17 Sift, 18 and Surf. 19 However, mismatch is inevitable. Removing mismatched noise points is a complex problem.
Point-cloud-based methods use a scene point cloud generated by stereo matching, 20 which can be seen as a global extension of feature-based methods. However, it is generally necessary to organize and structure the 3D discrete points into a higher-level representation, such as voxels. 21 One of the challenges in this process is removing noise points that do not correspond to the target objects.
Additionally, identifying and segmenting the desired objects within the point clouds is a complex task. 22 However, mismatches are inevitable in stereo vision, and addressing them is crucial in achieving accurate results.
Model-matching methods, also known as model-based recognition methods, have the advantage of avoiding mismatches and are especially effective in handling occlusion scenarios. Although monocular model-based method can estimate 6D pose, the distance measurement accuracy is lower than that of stereo vision due to the inability to use parallax displacement. 23,24 These methods first acquire the object model, projecting all points of a solid 3D model onto stereo vision image planes. Subsequently, these projected points are matched with their corresponding counterparts on the actual target, leading to accurate pose estimation (3D–2D method).
Traditional model-based pose estimation methods mainly rely on handcrafted models. They are made according to the style and size of the original object, so are generally used when a target size is given. An application utilizing a fixed 3D marker has been developed for the purposes of AUV navigation and battery recharging. 25,26 However, for other situations, aquatic organisms are always on the move, making it difficult to measure and model them accurately. An innovative approach using deformable models and stereo vision was employed to accurately measure the size of tuna. 27 However, the complexity of model building limits the generality of this method in detection.
A photo-model-based pose estimation method has been proposed 28 in response to overcome the disadvantages encountered in constructing models. It simplified the model-making process since it does not need to predefine the object’s shape, color, pattern, and coding in the programming language. 28,29 This method belongs to the model-based recognition method. It involves creating 3D models from 2D photos and then projecting these models onto binocular images to match actual objects for pose estimation (2D–3D–2D).
The photos employed for photo-model generation are pre-prepared instead of being captured on-site to minimize the environmental constraints at the specific application site. In the pose estimation process, the generated models are matched with binocular images taken on-site to find the best match. Regarding deformable objects, such as clothes, and the issue of partial occlusion, previous studies have investigated various environmental factors that influence the handling of such objects. 29,30 These studies have conducted experiments and provided empirical evidence supporting the effectiveness of the photo-model approach. Additionally, a 3D target object’s pose could be estimated and tracked in real time by using stereo vision and its 2D photo. 31 Moreover, a visual servoing system for catching marine creatures was developed using the photo-model approach. 24
However, previous algorithms based on photo-models rely on camera calibration to obtain the pixel per metric (PM) ratio and calculate the target size based on the shooting distance. Previous method uses a known PM ratio photo to generate a photo-model of the same size as the object. It cannot use photos with unknown PM ratios. The ratio measures the number of pixels per unit length of an object. It is an important parameter for object size detection in pictures. 32 –34 Existing studies usually rely on the camera calibration with reference objects of known size to ensure this ratio. 35,36
However, in practical scenarios, the size of targets on the ocean surface is often unknown, which poses a challenge for model-based approaches. To address this issue, a proposed expanded method overcomes the limitations of the previous size-fixed photo-model approach by assuming different PM ratios. This enables the generation of photo-models of different sizes from the same photo. By utilizing this approach, spatial model matching of the object with an unknown size can be facilitated, ultimately leading to accurate estimation of the target’s pose.
On the other hand, while the data-driven method with deep-learning techniques utilizes images for 3D pose detection, it necessitates a considerable amount of training data and pretraining time. 37,38 In contrast, the photo-model-based method, which belongs to the model-based approach, can accurately recognize the object’s pose with just a single photo. 31 This approach eliminates the need for large amounts of training data and simplifies the model-building process.
The main purpose of this article is to verify whether it is possible to use photo-models of assumed dimensions, that is, generated from different PM ratios, to perform model-based stereo vision methods for estimating the pose of objects of uncertain dimensions. This article aims to enhance the current photo-model-based algorithm and propose a convenient pose detection method using stereo vision. The proposed method will serve as a foundation for future research on visual servoing in marine aquaculture, specifically for the collection of deceased or ill marine creatures on the surface of the water. This article does not discuss recognition target underwater.
In this study, we assume the PM ratio for model generation. To verify the generality of the algorithm, in addition to taking pictures of the target, we also downloaded a photo with unknown shooting distance from Bing image. Using two photos for separate pose estimation experiments, the results confirmed that using photos of the same species with unknown shooting distance and stereo vision, the target pose can be recognized.
More precisely, the contributions of this article are as follows: This article proposes a method to estimate target pose by using stereo vision and a shooting distance unknown photo. In the case where the model of the same size as the object cannot be generated, 3D planar models of different sizes are generated by assuming the PM ratio of the pixel length to the actual length of the object. The target pose and PM ratio estimation problem is transformed into an optimization problem. The pose and ratio can be solved simultaneously.
The rest of this article is organized in the following sections: The second section presents expanded photo-model generation and the photo-model-based pose estimation method. In the third section, we discuss the adaptability of the proposed method for recognizing an object’s pose according to the pose–ratio fitness distribution and pose estimation experimental results. The conclusions and future work are described in the final section.
Expanded photo-model-based pose detection
This section introduces the methodology of the expanded photo-model-based recognition method with the variable PM ratio. The developed photo-model-based stereo vision system is shown in Figure 1. Each coordinate system is as follows:

Photo-model-based stereo vision system.
Figure 2 shows a perspective projection of the stereo vision system. Each coordinate system is as follows:
Perspective projection of stereo vision system. In the 3D search space, the spatial plane model is projected onto the left and right images through perspective projection.
2D pixel photo-model
This subsection is a description of the 2D pixel photo-model generation before explaining the 3D photo-model generation. There are two central portions of the model generation. The first portion is 2D pixel model generation, and the 2D pixel model size is fixed with the unit pixel. The latter is the 3D plane model generation, its size (length and width) is variable, and its unit is millimeters. The estimation of the relative pose needs to use the generated 3D plane model.
The hue value in HSV color representation is used for the extraction of the target color. The advantage of HSV is that each of its attributes corresponds directly to the basic color concepts, which makes it conceptually simple. Therefore, it is easy to understand the program for the image matching process. In addition, the hue of the HSV color system shows good robustness against a change in the lighting intensity.
The model generation process is represented in Figure 3. Scan Figure 3(a) from outside to inside. The part of the image with target hue values is determined as the photo-model frame. As shown in Figure 4(a), the model is generated based on a photo. The coordinate system of the model

2D pixel photo-model generation processes are described as (a)–(d): (a) shows a photograph with a target object (the squid) in the background, (b) represents a model surface space
3D photo-model with specified PM ratio
To explore the object, the photo-model needs to be converted from a 2D pixel model to a 3D spatial plane model. For the jth 3D spatial plane model, its length and width are calculated as follows

where
Its unit is (pixel/mm). It is the ratio of the 2D pixel model to the 3D spatial plane model.
The coordinate of the ith point of jth model

Because from 2D photo generate a 3D searching model, the thick of a target is unknown, therefore

Therefore,

The prepared photo and the generated 2D pixel photo-model. (a) The photo size is 640 × 480 pixel. The photo-model is composed of the inner portion and outer portion with sampling points. (b) The 2D pixel photo-model is only a small part of the photo including the target, the whole photo is not a model. Sampling points are collected at a certain interval. Its coordinate system
Projective transformation of the photo-model
This subsection introduces the basic component of the projective transformation of the photo-model as follows. More details have been proposed in the literature.
28,30,39
It should be noted that in the past
As shown in Figure 1, the pose of

Based on

For simplicity,

The summary of the calculation process from 2D pixel photo-model generation to the 3D photo-model’s stereo vision perspective projection.
About stereo vision, position

The position vector

Then

where

The projective transformation process is summarized in Figure 5.
Photo-model-based matching in 3D space
As shown in Figure 6, the 3D toys of marine creatures are prepared. The squid is used for explanation the photo-model-based matching.

(a) Marine biological models. The three labels correspond to model number, English name, and size (unit: cm). (b) Photos of marine biological models. It should be noted that the model is only a part of photos, including the target, that is, inside of the black frame in the photo.
Figure 7 illustrates the experimental setup for the fitness distribution experiment, which will be elaborated upon in the subsequent subsection. The target object and manipulator remain stationary while the 3D photo-models vary in distance and size.
In Figure 7, two example models of equal size, generated from the same photo, are displayed. Therefore, they have the same PM ratio. The first model’s projection transformation result is depicted in Figure 8(a), while the second model’s stereo projection result is shown in Figure 8(b). Additional example results for 3D model projection onto stereo vision image planes are illustrated in Figure 8.
In Figure 8(c), through forward projection equation (9), the 3D model in 3D searching space is projected onto the left and right camera images.

Experimental environment for 3D model projection onto stereo vision image planes. The pose of the object is fixed as

A series of 2D projection transformation results of 3D photo-models at various positions in space with different PM ratios based on the perspective transformation. When
As shown in Figure 4, when the prepared photo is 640 × 480 pixel, the divided squid model is 386 × 152 pixel. According to equation (4), in Figure 8(a), the photo-model spatial size is 193 × 76 × 0 mm3 with
Compared to monocular vision, which only observes the projection results of the left camera, binocular vision tends to exhibit a greater positional difference when projecting the model onto the image. Therefore, stereo vision is more helpful in accurately identifying pose and size. As shown in Figure 8(b), when the distance between the model and the object is close and their sizes are similar, the coincidence is higher. This characteristic has inspired us to create a fitness function, which utilizes coincidence to accurately describe the resemblance in pose and size between a photo-model and the target object.
Definition of the fitness function
Figure 9(a) shows the left image projection example of the jth model. The evaluation points of hue value,
The 2D model is composed of dots whose relative positions are predefined and fixed. Figure 9(b) shows another situation where the overlap area between the real target and the model is increased compared to the area depicted in (a).
The correlation between the projected model and captured images on the left and right 2D images is calculated by equations (11)–(13)



where

Calculation of the matched degree of each point in model space (
The evaluation values in equations (12) and (13) are tuned experimentally.
Calculating p of each sampling point (equations (12) and (13)) based on color similarity is considered to be constant, with a time complexity of O(1). Furthermore, for each photo-model (the jth photo-model), the fitness calculation complexity given in equation (11) is
In equation (12), if the hue value of each point of captured images, which lies inside the surface model frame
Similarly, in equation (13), if the hue value of each point in the left camera image, which are in
Likewise, a function
Feasibility of pose recognition of expanded photo-model with PM ratio search
Stereo image acquisition
The photo-model-based stereo vision system is shown in Figures 1 and 7. The utilized manipulator in the system is a PA-10 robot arm manufactured by Mitsubishi Heavy Industries, Tokyo, Japan. And two CCD cameras mounted on the end effector. The resolution of stereo images is 640 × 480 pixel. The PC is Yoga Pro 13s (CPU: Core(TM) i5-1135G7, 2.42 GHz; RAM: 16 GB).
Fitness distribution experiment
Using still pictures of the target captured by the left and right cameras, the fitness value

Fitness distribution of C02 squid listed in Figure 6. (a) Left and right camera images. (b) Prepared photo for photo-model generation. (c)–(e) fitness distribution with position-ratio scan, that is,

Fitness distribution of C02 squid. The size of the prepared photo (b) is different from that in Figure 10. (c)–(e) fitness distribution with position-ratio scan. (f)–(h) fitness distribution with orientation-ratio scan.
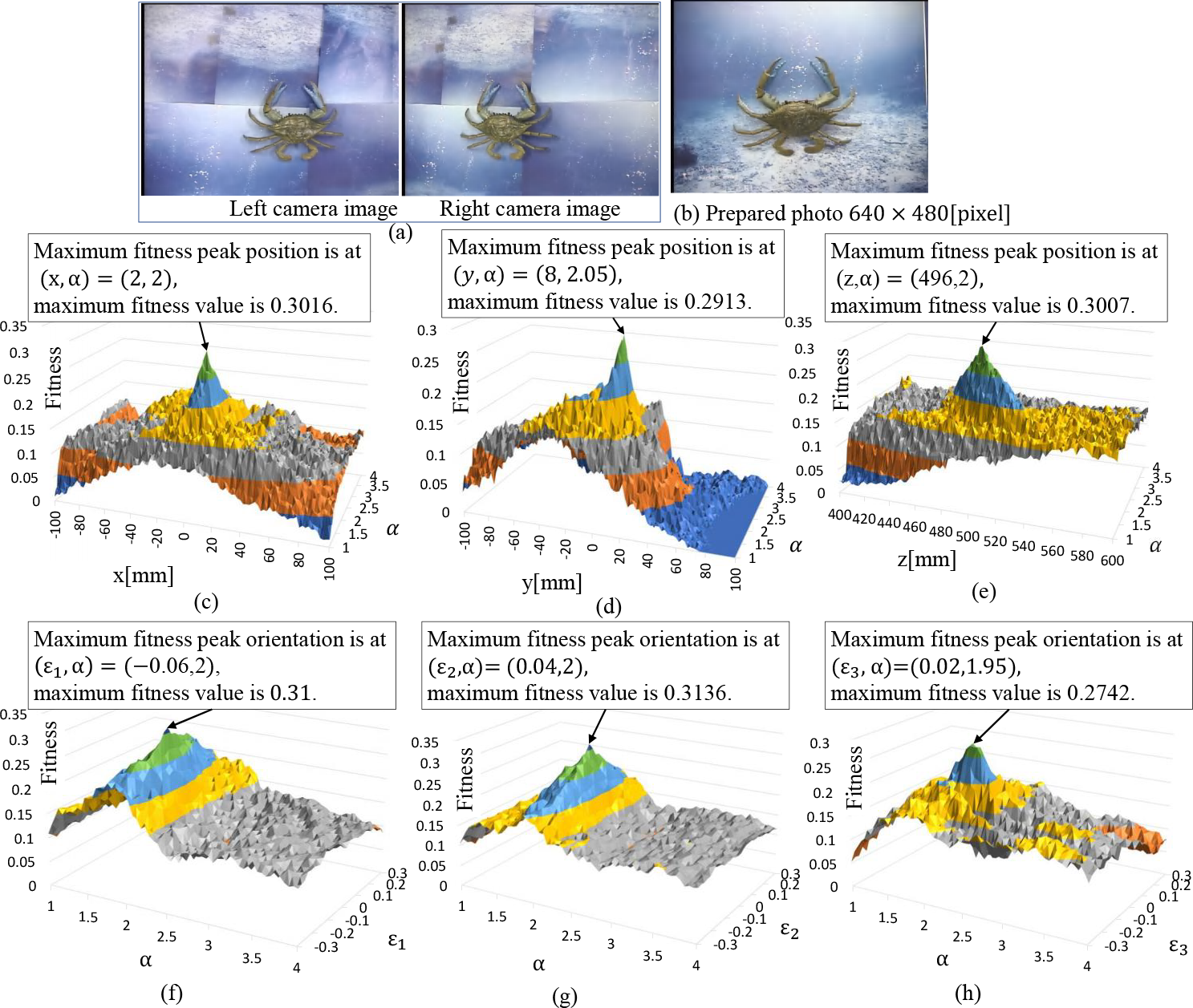
Fitness distribution of C01 crab. The size of the prepared photo (b) is the same as that in Figure 11. (c)–(e) fitness distribution with position-ratio scan. (f)–(h) fitness distribution with orientation-ratio scan. In each subfigure of (c)–(h), the maximum fitness value and corresponding coordinate to give the maximum value are shown in text boxes.
Figures 10 to 12 illustrate the distribution of fitness results for the pose–ratio of C01 crab and C02, which are depicted in Figure 6.
The true pose of an object is set as

In this experiment, the target objects’ sizes and poses do not change. To imitate photos taken at different heights, photos of different sizes are prepared. Therefore, corresponding to different size photos, the true photo ratios are as follows

The relationship between
Figure 10(a) shows the left and right camera images of the C02 squid. And the size of the prepared photo (b) is smaller than that of Figure 11(b). Figure 10(c) to (e) shows the fitness distribution results with position and photo ratio scan, (f) to (h) show the fitness distribution results with orientation and photo ratio scan. All the fitness distributions (c) to (h) have peaks whose poses and ratios are near the actual values given by equations (14) and (15).
When the size of the prepared photo changes in Figure 11, the same conclusion can be drawn. As shown in Figure 11(e), when α changes from 1 to 4, that means the size of the squid model changes from 386 × 152 × 0 mm to 96.5 × 38 × 0 mm, although z is still 480 mm, the fitness has changed dramatically due to the change of α. Only when α is close to the actual scale, that is, when the model size is close to the object’s actual size, the fitness has a high value.
Concerning C01 crab, same as the squid, Figure 12(c) to (e) shows the position-ratio fitness distribution, and (f) to (h) show the orientation-ratio fitness distribution. All the pose–ratio fitness distributions (c) to (h) also have peaks near the true value.
In this section, by the fitness distribution experiment, it is verified that the fitness function equation (11) can transform the PM ratio estimation and target’s pose detection problems into optimization problems. It is also confirmed that the proposed method can estimate 3D target pose by using stereo vision and one PM ratio unknown photo.
Pose estimation experiment with genetic algorithm and different photos
To verify the detection ability of the proposed expanded photo-model-based algorithm, pose and ratio detection experiments were conducted with different photos in real application scenarios. As shown in Figure 1, in this experiment, the squid object floats on the water in the pool without pose constraints. The distance between
While the fitness function transforms the main problem of recognizing the pose of an object and the ratio of a prepared photo into an optimization problem, the pose and ratio fitness distributions involve much computation. We choose the genetic algorithm (GA) as an optimization method to find the maximum fitness value because of its simplicity and effectiveness. 31,41 Because of the limited space, GA will not be introduced in detail here.

The 3D pose estimation results with GA and two different prepared photos. Figure 1 shows the experimental environment. (a) shows the original stereo images at a moment. The distance between
In previous studies,
31,41,42
the chromosome in the GA consisted of six variables, representing possible pose solutions. However, for PM ratio detection, as shown in equation (16), each chromosome is elongated and now comprises seven variables. The 30 individuals of GA are used in this experiment, where the chromosome of an individual consists of 68 bit. The first three variables (1–30 bit) of an individual in 3D space are the jth model’s position

As shown in Figure 13(a), the cameras capture the left and right images at an arbitrary moment. Each experiment was performed using a prepared photo. Figure 13(c.2) is downloaded from Bing images (http://cn.bing.com/images). Its PM ratio is unknown. According to GA, the 3D models with random poses and ratios generated from the prepared photos (b.2) and (c.2) converge to target objects in 3D space. GA stops evolving after the 500th generation. (b.1) shows the estimation results using the model generated from the photo (b.2). (c.1) is the estimation result of the model generated from the photo (c.2).
The average one-generation evolution time of the model generated from Figure 13(b.2) is 0.213 s with
Table 1 summarizes the GA estimation results of two experiments. The distance between the end effector and the target floating on the pool’s water surface is 680 mm. The length and width of the target are measured with a manual tape measure. The experimental results of two different photos are close to the actual value. Since they are two different size photos corresponding to the same target object, the PM ratios are different. Photo 1 is the target’s photo, and the estimation result is closer to the true value than that with photo 2. Although photo 2 is not the target photo and the shooting distance is unknown, the detection result using it is close to the true value. The detected distance, object length, and width are close to the true value. We can see that the expanded photo-model-based algorithm can detect the pose of objects using PM ratio unknown photos in the practical application scenario.
Table 2 presents the relative error of GA in estimating the distance and size of objects on the water surface. Based on Table 1 detection results, when the photo 1 was used, the distance detection absolute error is

and the relative error is

The length detection absolute error is

and the relative error is

The calculation for the relative error in the last row, when using photo 2, is performed in the same manner as explained earlier. However, it should be noted that photo 2 in Table 2 (Figure 13(c.2)) and the target object C02 in Figure 6(a) have some shape differences, although they belong to the same species. While using the same species’ photo can help explore the pose and size, there might be a slight increase in the error value
For comparison, the performance of the expanded photo-model method is evaluated against other existing methods. The most common research is the size detection of marine creatures. Tuna research 27 makes use of stereo vision technology, employing finely constructed models. On the other hand, fish research 14,34 utilizes laser sensors for dimensional measurement, offering increased precision at the expense of higher costs. In Billfish and Tuna research, 43 caught fish size on board is detected using a size known reference object.
In the research, data on the size and positioning detection of relevant binocular products in the air have been included for comparison. 14,34 Similar studies on agricultural products in the air have also been incorporated for comparison. 44,45 The results show that our research achieves high positioning accuracy but only average size detection accuracy. Overall, as can be seen from the table, our method is a low-cost and practical approach in terms of effectiveness in distance and size measurements.
The target detection results of GA.a

a Through perspective transformation, the projection results of two models on the left and right images corresponding to the pose and ratio are shown in Figure 13(b.1) and (b.2), respectively. The last row shows the measurement of the target under the tape measure. Even though photo 2 is not the target photo, the detection result is near the actual value.
Relative error in distance (mm) and size (mm) for different methods.a

a The most common research is the size detection of marine creatures. Since this research is specifically aimed at detecting objects on the water surface, we have also included data on binocular product size and positioning detection for comparison purposes. The results clearly demonstrate that our research achieves a high level of accuracy in terms of positioning. However, in terms of size detection, our results fall within the average range.
In the previous subsection, the fitness distribution experiments were conducted to verify the feasibility of the proposed expanded photo-model-based recognition method. Those pose–ratio fitness distributions of the fitness function in Figures 10 to 12 have maximum peaks at the true pose of targets and true ratios of the prepared photos. These results prove that the problem of detecting the pose of a marine creature from a picture of unknown shooting status is transformed into an optimization problem. And through the pose estimation experimental results in this subsection, it is confirmed that the proposed expanded photo-model-based method can estimate a target object’s pose by using stereo vision and only one PM ratio unknown photo; the fitness function equation (11) can transform the target pose and PM ratio estimation problem into an optimization problem that GA can solve.
We conducted the experiments with one target and two different photos to clarify that this proposed method can detect both the pose and size of an object in the actual application using just a single pre-prepared photo where the shooting distance is unknown.
The above three points are the contributions of this article and are verified by the pose estimation experiments.
Conclusion and future work
This study presents the expanded photo-model-based pose estimation method that overcomes the limitations of the previous fixed PM ratio approach. By utilizing photos with unknown PM ratios taken at unknown distances, the proposed method allows for the generation of photo-models of different sizes from the same photo. Experimental results have demonstrated the effectiveness of this approach in detecting the pose and size of objects. Moving forward, further research and optimization efforts are necessary to improve the performance and efficiency of this method.
Indeed, the proposed expanded photo-model-based method is still in its early stages. The model shape can be further refined. The addition of a new PM ratio parameter has increased the computational complexity compared to the previous method. As a result, the amount of calculation required for pose estimation also increases. Therefore, it is important to explore ways to optimize the algorithm and minimize the computational burden while maintaining accurate pose and size detection. Reducing the number of sampling points can improve speed, but accuracy may be affected. The real-time tracking performance of GA needs to be further investigated in the future. It is recommended that a wider variety of experimental objects both on the water surface and underwater be included to enhance the generalizability of the findings. In addition, in this study marine organisms are considered as rigid bodies. Although death weakens their deformation, they still undergo deformation on the water surface. Therefore, conducting further experiments is crucial for determining the reliability of the proposed method.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.