
Abstract
Due to the feasibility of the gray model for predicting time series with small samples, the gray theory is well investigated since it is presented and is currently evolved in an important manner for forecasting small samples. This study proposes a new gray prediction criterion based on the neural ordinary differential equation, which is named the neural ordinary differential gray mode. This neural ordinary differential gray mode permits the forecasting model to be learned by a training process which contains a new whitening equation. It is needed to prepare the structure and time series, compared with other models, according to the regularity of actual specimens in advance, therefore this model of neural ordinary differential gray mode can provide comprehensive applications as well as learning the properties of distinct data specimens. To acquire a better model which has highly predictive efficiency, afterward, this study trains the model by neural ordinary differential gray mode using the Runge–Kutta method to obtain the prediction sequence and solve the model. The controller establishes an advantageous theoretical foundation in adapting to novel wheels and comprehensively spreads the utilize extent of mechanical elastic vehicle wheel.
Introduction
In the last 5 years some methods have appeared to detect errors, interference effects, modeling errors, various uncertainties in real systems, and so on. For example, Xin et al. 1 and Cheng et al. 2 also proposed the linear matrix inequality (LMI) technique, which provides sufficient conditions to guarantee the existence of asynchronous error detection. Xu et al. 3 found the method suitable for the applications, and the results analyzed the stability of the state-dependent step delay network for gene regulation and proposed suitable sufficient conditions based on model transformation and LMI, resistance is an important component of the control system, but optimal control cannot guarantee fundamental robustness. 4 It is well known that SM control is an effective tool to improve the resilience of control systems regardless of external disturbances or parameter changes. To solve the singularity and flutter problems, a systematic control scheme for SST was sought. 5 To control AS, I/O compensation 11 in slip mode is suggested. However, SM control does not provide AS with optimal nominal capacity. In addition to robustness, optimal suspension control has been incorporated into the slider position control to improve optimization possibilities. 6
For Taylor-corrected linear systems containing nonintegral non-quadratic terms, an optimal slide position control is pursued to improve the optimal control problem, 7 and a linear quadratic strategy for optimal slide position supply for logistics systems is proposed. 8 Currently, many SM-optimized control methods have been used to design vehicle steering suspension. For example, an optimal SM controller with feedback/feedback in the control system has been proposed. 9 Unfortunately, these controls do not achieve the truly optimal possibilities for wide suspension. 4 Furthermore, it is a classic nonlinear mechanical suspension system with complex dynamics that can cause unacceptable ill effects on passengers and drivers. 2 Therefore, an adaptive control tracking method for nonlinear tuning of quadratic systems is proposed to achieve excellent suspension performance. 10 Based on the T-S fuzzing method, in nonlinearly controlled fuzzy systems, a robust nonlinear predictive multivariate control is proposed. 11 Therefore, nonlinear elements of shock absorbers and springs must be anticipated when designing useful ride control models to compensate for nonlinear effects and provide increased drivability of large-scale vehicles.
In practice, few samples are usually available. For example, China has less than 30 oil consumption samples per year so far, so this is also an important area where it can make accurate predictions from a small number of samples. Currently, there are many methods to make predictions with a small number of samples, for example, fuzzy theories, 12 –16 neural systems, 17 –20 and graphic systems science. 21 –23 By better understanding the law of the data, the gray system theory can reduce to a certain extent the source of uncertainty generated by a small number of samples to more effectively predict small sample data. The gray theory approach was developed by Ju-Long 24 to solve uncertainty problems. The basic model is the so-called GM model (1, 1). Because this gray theoretical model is efficient, simple, and inexpensive, it has been widely used in recent years in research to forecast short-term time series, including vehicle flows and prices, and oil production. 25 –28 As a result of further research on GM models (1, 1), many new gray models were created. 29,30 These models take into account the disadvantages of this GM model (1, 1), so we usually get a higher accuracy.
When it comes to the gray pattern search, some researchers rely on the pattern method, combine it with the idea of a single pattern and arrive at the pattern with a discrete gray pattern (DGM) (1, 1). 30 When the specimen data are homogenized, DGM models carry out poorly; nonetheless, thanks to 31 propose an NDGM model which extends it to heterogeneous models. 19 The real specimen data cannot usually meet the homogeneous property, due to the GM(1, 1) model being a homogeneous kind model, thus extremely restricts its feasibility. The NGM(1, 1, k) model by Chen and Chen 32 was introduced to correct these shortcomings. Nevertheless, this model introduces some novel methods. For instance, when it comes to predicting real-time series, actually the NGM model is not as powerful as the GM(1, 1) model, even though it can attain greater accuracy on specimens by uneven exponential properties. Thus, the ONGM model was provided by Chen and Meng 33 to solve that problem. Duan et al. provided a gray forecasting model with a point function by combining the gamma function with the SIGM model, which is called the FSIGM model. 34,35 Due to nuclear methods being useful for solving nonlinear problems, some researchers have taken advantage of these properties and proposed gray models based on nuclear methods. 36 –43 The method allows these criteria to effectively forecast nonlinear sequences.
Neural ordinary differential equation (NODE) is a novel nervous system proposed by Si-feng. 44 It makes a single transition 45 successive between different layers of a remaining network; in this way, the whole network becomes successive and can be adjusted with standard differential equations. NODE has aroused the interest of many researchers because it relates differential equations to neural networks (NNs), which is a novel area of NNs. NODE is currently used in various mechanistic and in-depth research studies. 46 –56 According to Lei et al., 57 the gray algorithm is used for the modeling in energy and economics, however, the gray systems could be combined with the fuzzy and artificial intelligence adjusting controlled design for the real-world application in nonlinear systems.
The main contributions and innovations compared with the existing results have been highlighted that gray modeling control and mechanical LMI criterion have been combined to solve nonlinear numerical control inequalities for real-world demonstrations. This study learns that lots of gray models require a preliminary definition of the concept and configuration of the white balance equation. The parameters can be assessed with optimization approaches, for example, least square, according to the bleaching equation. Then, by figuring out this differential equation, the predicted procedure can be calculated. But it cannot guarantee that this terminology as well as configuration of the kind model defined correspond to the properties of these actual data if they lack appropriate knowledge. Secondly, although gray models are adequate for predicting few specimen sizes, their estimation method is based on the risk-reduced least square empirical parameters, which ensures that predictions are made only for bigger specimen sizes. Therefore, while in the condition of few specimens, the probability of obesity according to the least squares method is high. To address these issues, in collaboration with NODE, this document presents a new gray prediction model, whereby NODE the bleaching equation is defined. As for the model, it is not required to offer an explicit configuration and terminology, as the optimum models are acquired through a learning procedure that can be resolved with the Runge–Kutta approach. Thus, for data with different distributions the NODGM model can be used. Due to the model training is according to a sloping function, by controlling the loss threshold or the iteration numbers, the NODE can be trained to decrease the risk of obesity as well as furthermore enhance the predictive efficiency of this model which was trained.
The rest of the article has been arranged as follows: The second section presents these essentials of the GM(1, 1) model. We represent the theory of NODGM and NODE in the third section. The fourth section presents numerical cases of prognostics with gray models in different gross forecasting models. The final section concludes this study and summarizes the presentation.
GM methodology
As the research and development trend in gray system theory, numerous innovative models are provided on the basis of GM(1, 1) model. At the present, this study will describe the modeling procedure and parameter evaluation approach of this fundamental model (GM(1, 1) model).
Here represents the series (1)

The gray model adopts the 1-AGO series to establish the forecasting system instead of the sequence of raw data, such as Figure 1. It is a 1-order generation (1-AGO) accumulated queue. The difference of transformation between a residual network and an ODE network. ODE: ordinary differential equation.

Here we define the GM(1, 1) model as follows

in which
In the end, the predictive values for the raw data
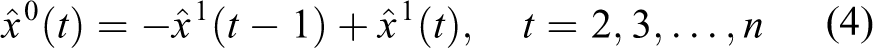
Preliminary proposed methodology
An NODEs
NODE is discriminated against from a single NN, it is a novel branch of a NN. As displayed in Figure 1, the remaining network possesses a distinct transform function f(h(t), θ(t)) in between every layer; thus, the entire networks express a sequence of diverse input transformations of the NN. Of course, the latent state path is the dotted line shown in the top row of Figure 1, and the weights are stored in each layer of network. As the depth between the networks rise rapidly, the derived resources needed to maintain the site become expensive. But in NODE, this transformation from data input to data output are both continuous, thus the curve h(t) presents a smooth mild curve, which is displayed on the last line in Figure 1, which presented that the network itself can be corrected with standard differential equations (ordinary differential equation (ODE)).
In terms of such a continuous NN, this study applies common NN training methods to train ODE with ODE symptoms. Then only save the ODE parameters regardless of the depth of the NN. By resolving the ODE with the preliminary value which can calculate the h(t) value for any t.
Actually, NODE could be considered as a particular residual network, their configuration is a series of residual blocks shown in Figure 2. With comparison to the criterion residual network, in the ODE network each block possesses the identical f. From the residual block that presents the h(t) input and h(t + 1) output satisfies

in which k is the step size and presents that there is only one equilibrium solution as it has a proper function f(t, θ, h(t)) equated to the output signal from the normal remaining network on the corresponding layer. So ODE is considered as a successive remaining network, which is called the ODE NN. The block in residual.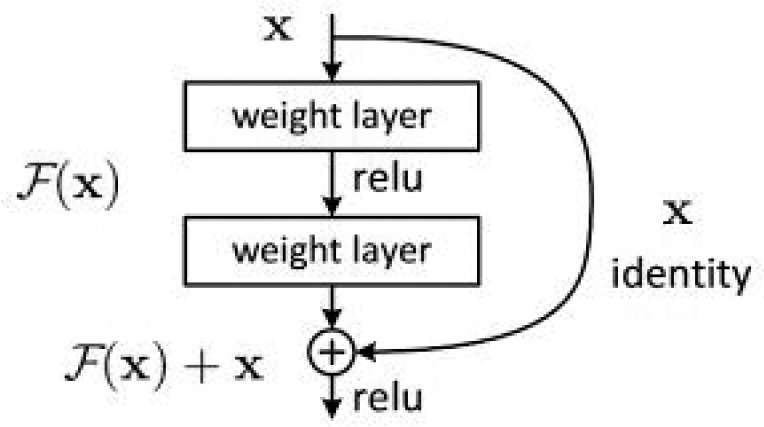
In the NODE condition, this function f embodies the variables which could be produced. As with a single nervous system, the transmission of backscatter needed for NODE training is followed. Euler’s method described above is only an exact 1-series method—a number of higher order ODE solution methods have been provided recently. Such as, the Runge–Kutta approach 38 is a common method for solving ODE, which has better accurateness than Euler’s approach. In this article, the Runge–Kutta approach is considered as black box while resolving ODE, called ODESolver. The procedure for solving Runge–Kutta approach is from the initial value under an ODE problem

This Runge–Kutta approach is a constant step size, which makes it less flexible than the adjusted step size method. 58 Thus, this study could call ODESolver the ODE network redirection
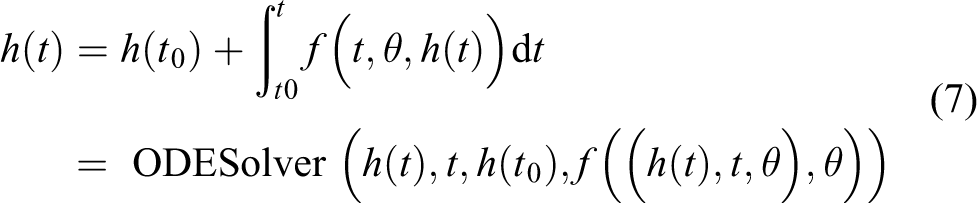
ODESolver calculates an answer according to the start value h(0), θ, the initiate point t0 as well as the end point t, as the answer of ODE in the equation. By calling the ODESolver, it can be calculated. Then, from the function f(t, θ, h(t)) could readily get the part of f relative to the numerical hidden layer h. Use ODESolver to compute the transformation result (h(t0), t0, θ, t), that can directly calculate the end position a(tn) = ∂L. Then it can use ODESolver to resolve equation (7) and calculate entire adjacent states backward, initiating from the ultimate continuous condition a(tn)

While acquiring
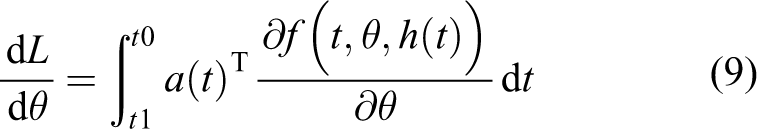
We finally could use the dL/dθ slope to renovate the parameters and accomplish the regeneration procedure.
Actually, to insert a vector and then release another vector of a certain size is a single nervous system’s real role. At the same time, since the network itself is a complex multilayered feature with distinguishability, it can update parameters by spreading forward and backward. In this way, a single NN could be incorporated into standard differential equations, as presented in the “NODGM statement” section. Learn more about the derivative procedure of equations. Equations (7) to (9) are included in Annex B to the NODE. 59 –61
NODGM statement
In the section, the study introduces a novel gray model that is called NODGM. Rather than estimating the corresponding differential model 62 -65 by solving the parameters with the least squares approach, the NODGM model defines the function fx1(t), t, θ, which replaces estimate 1 with t. The AGO family can treat the bleaching equation as a knot, and by teaching its ODE a better predictive model can be obtained.
Whereas assume the condition of f is a function of t and x1(t), in the NODGM model, the coefficient θ is a parameter. Thus, this function of f could be as follows
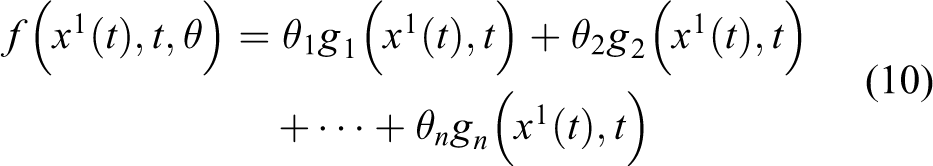
in which

By a DNN, where the function f is defined, and θ is the weight value. By transforming the NN that derives the numerical function f, so the model can possess various patterns such as nonhomogeneous, homogeneous, nonlinear, or linear. Given the preliminary value time span tspan and θ, h(0), then that can utilize an ODESolver to calculate the forecasting procedure H

in which tspan = [0, 1,…, n − 1]. We develop the loss function to train the numerical NODE to optimize the coefficient θ

Therefore, the NODGM model is based on the slope for parameter formation, not the least squares approach. Meanwhile, since the function of this bleaching equation has been derived by the NN, prior knowledge is incorporated into the network design, which significantly reduces the time required to practice ODE.
Case study
If these time steps are small enough, entire conditions in the system are continuous time instances. DGM step (2, 1) should ensure that follow-up is consistent and limited. The control adapts to the gray oracle signal reception conditions and possesses adaptive force control for tracking the movement produced by the ideal damping hybrid control to study the movement of the mechanical elastic vehicle wheel which is equipped with an active suspension of the vehicle.
To check control circuit, the first step in DGM(2, 1) has been corrected, use trailer to simulate digital random motion data set, predict signal sequence 6 will be set to 0.001s, then design Simulink step to design two standard tunnels A (impulse and steps) to illustrate the effectiveness of the proposed monitoring. This road connection, which works on the rear and front wheels, has a certain delay that corresponds to the vehicle’s speed and wheelbase. The measurable coefficients for the simulator are shown in Table 1.
Measurable program factors.

The difference between the GDM(2, 1) model prediction and the exact data is so small, particularly while the development is small relatively. The GDM(2, 1) model’s tracking error will be slightly larger if the data change remarkably; but it still suffices the qualification for engineering work. Thus, in DGM(2, 1) reliable quality can also be determined. The matrices weighted in the hidden layer and output have been indicated by W 2 and W 1. After training the BP algorithm, this weighted factor can be collected in the following equations

In addition, based on matrix numbering, the NN model could be developed in the LDI indications as follows

The above equation proves that the nonlinear term can be confined by an upper bound and a lower bound. According to the interpolation algorithm, the nonlinear term can be represented by the following equation

Assume that

and

Then, by solving (6.3) and (6.4),

The uncertain nonlinear system can be described by the following T-S fuzzy model with uncertainty Rule 1:
IF

Rule 2:
IF

By introducing matrix representation, it can be rewritten as follows Rule 1:
IF

Rule 2:
IF

where
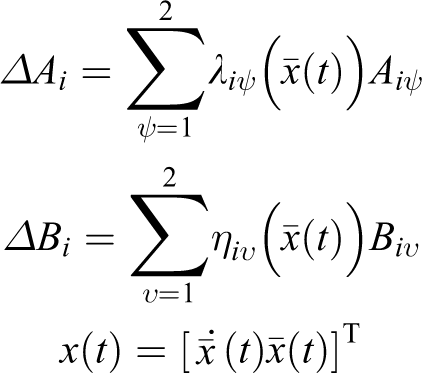


Notice that

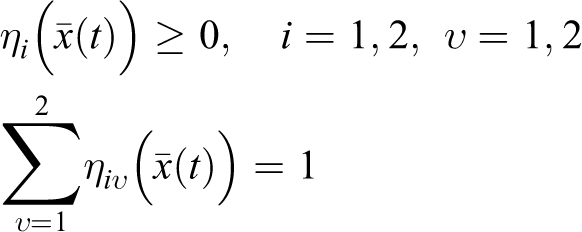
Hence, the overall fuzzy model with uncertainty

The fuzzy sets Fuzzy sets 
According to the above equations, we know that the pairs
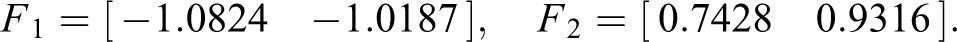
The Riccati equation for linear continuous systems is used to design these feedback gains because the local fuzzy controllers are designed based on T-S fuzzy model without uncertainty. According to the above conditions, we can obtain the matrix G as follows
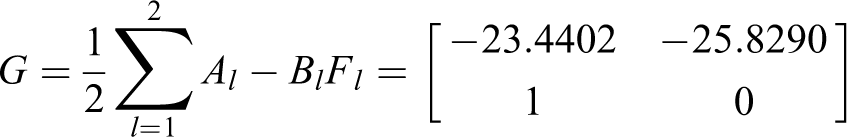
The final output of the fuzzy controller is
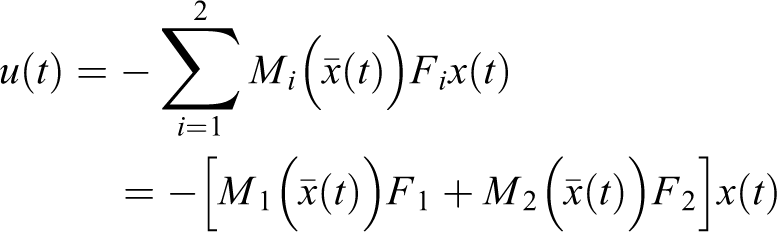
We can derive the closed-loop uncertain fuzzy system

From equations (20) to (22), we have
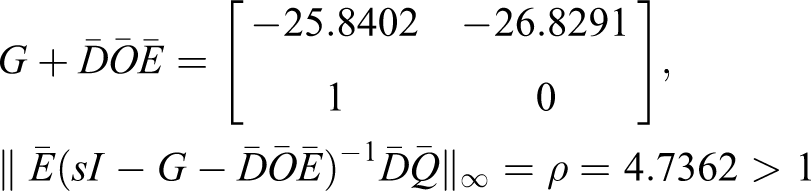
Hence, the closed-loop uncertain fuzzy system is not quadratically stable. This implies that the fuzzy controller cannot stabilize the fuzzy model with uncertainty Simulated controlled modeling uncertain nonlinear system 
Subsequently, we attempt to improve the stability of the closed-loop uncertain nonlinear system
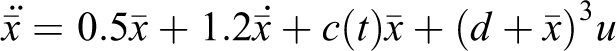
To analyze the uncertain dithered model, the corresponding uncertain relaxed model is established as the following equation

with

where

The nonlinear term of this system is

Similarly, the nonlinear term can be represented as follows
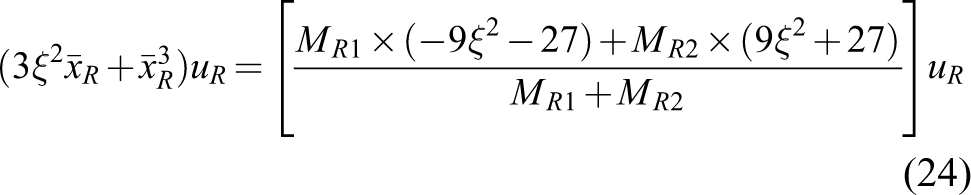
where

and

By solving equations (34) and (35),

By using Rule 1:
IF
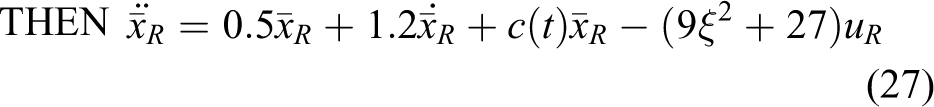
Rule 2:
IF

By introducing matrix representation, equations (27) and (28) can also be rewritten as follows Rule 1:
IF
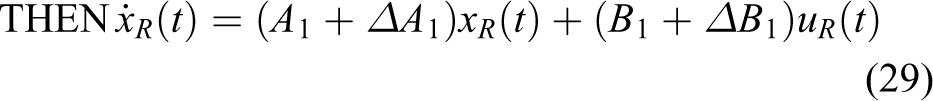
Rule 2:
IF

where

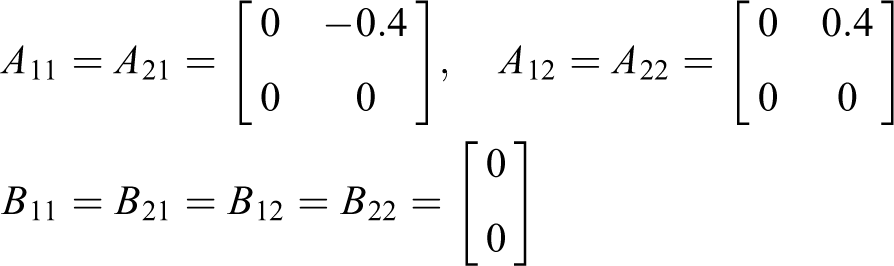
Notice that

The final output of the fuzzy relaxed model with uncertainty

Based on equation (31), we can obtain the corresponding fuzzy controller

Substituting equation (31) into equation (32), the closed-loop uncertain fuzzy relaxed system

Theorem is employed to check whether the closed-loop uncertain fuzzy relaxed system
Comparisons of proposed approach and related works.

LMI: linear matrix inequality.
For the proposed control law, three control elements have been added to the surface control model S to achieve a robust scheme for tracking. The first item is PI control, whose input is used as an uncertainty estimator to estimate the unknown uncertainty that changes over time under various adverse conditions online, and the design of this estimator does not require an upper uncertainty limit. In addition, the introduction of PD compensator can reduce the tracking error in short-term and stable condition. The second term is then used as a nonlinear perturbation observer to predict compensation for external perturbations, such as unknown loads, sampling dynamics, and noise measurements. In this article, the proposed NODGM algorithm is used in the structural optimization design. The novel NODGM combines the NN linear differential scheme and the Lyapunov stabilization approach for nonlinear suspension system. The proposed algorithm is a bionic algorithm with fast convergence speed, easy parameter setting and memory ability. The gray evolved NNs learn the way of wolves foraging, randomly generates initial values in the solution space to simulate the location of the wolves, and uses the formula of encirclement and attack to approach the optimal solution. The improved gray NN linear differential scheme algorithm modifies the convergence coefficient to increase the proportion of global search, avoids falling into the best solution in the region, adds memory capabilities, improves convergence efficiency, adds weights for different positions, makes the search direction clearer, and uses greed strategies to avoid excessive unnecessary searches. Due to interference compensation, the nonlinear interference observer technology can provide excellent tracking performance without the need for large feedback gains and without measuring acceleration. Finally, the third concept of control, model-based control, can quickly learn the dynamics of the system through the uncertainty created by the uncertainty. Based on this understanding, in this article, we will utilize the proposed standard based H∞ control method for demonstration. A model with nonlinear active suspension was used for simulation to verify its suitability for the implementation of practical applications. In the numerical analysis of functions and structures, the results show that the improved gray NN linear differential schemes with Lyapunov LMI can achieve good results. Although most of the advantages we employed from artificial NN (ANN) and gray models are not unique, engineers, psychologists, and neuroscientists use ANN models extensively in many scientific studies. In most cases, these models are introduced to provide more convenient optimization tools than those commonly used in classical optimization theory. Unfortunately, the high-efficiency ability of ANN models in optimization tasks has led to widespread neglect of the real and important goals of the early proponents of these models. These goals can be summarized in the connectionist psychology manifesto. According to it, mental processes are simply macroscopic phenomena arising from the interaction of a large amount of microscopic information.
Conclusions
In this article, based on the NODE that provides a novel gray model. With comparison to the gray model possessed artificially defined concepts and structures, the NODGM model presents much nimble characters as well as learning related models from various samples, which means the NODGM will have comprehensive applications. Meanwhile, if compared to the method by least squares, these slopes are comparatively complicated, but dominates repetition loss and avoids obesity; thus, NODGM has superior generalization results than the smallest square model. These numerical experiments illustrate that the NODGM model actually forecasts short-dated control conditions for nonlinear systems in the real world. Therefore, our model can be used to predict all practical applications for current studies, 66 –69 which is also believed robust in engineering systems and decision-making. Nevertheless, this model still has two problems. First, inferior preliminary network weights can cause locality minimization during training, thereby reducing model performance. Second, some form of adjustment can be made to reduce the weight and thereby increase the strength of this model. In the continued work, we plan to improve the proposed model.
Footnotes
Acknowledgements
The author(s) are grateful to the anonymous reviewers for constructive suggestions.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The author(s) are grateful for the research grants given to Ruei Yuan Wang from the Projects of Talents Recruitment of GDUPT, Peoples R China under Grant NO. 2019rc098, and the research grants given to ZY Chen from the Projects of Talents Recruitment of GDUPT (NO. 2021rc002) in Guangdong Province, Peoples R China.