
Abstract
Cloth manipulation remains a challenging problem for the robotic community. Recently, there has been an increased interest in applying deep learning techniques to problems in the fashion industry. As a result, large annotated data sets for cloth category classification and landmark detection were created. In this work, we leverage these advances in deep learning to perform cloth manipulation. We propose a full cloth manipulation framework that, performs category classification and landmark detection based on an image of a garment, followed by a manipulation strategy. The process is performed iteratively to achieve a stretching task where the goal is to bring a crumbled cloth into a stretched out position. We extensively evaluate our learning pipeline and show a detailed evaluation of our framework on different types of garments in a total of 140 recorded and available experiments. Finally, we demonstrate the benefits of training a network on augmented fashion data over using a small robotic-specific data set.
Introduction
Grasping and manipulation of rigid objects have been studied extensively. 1 –4 In contrast, deformable object manipulation received relatively little attention due to the challenges related to the complexity in modeling, tracking and control. 5 Manipulating clothing items is particularly difficult, as classical control approaches that require modeling the objects’ dynamics are only applicable in restrictive settings. 6 Learning-based and data-driven approaches that do not rely on specific models are a viable approach for tasks that involve highly deformable objects. 7
Clothing items are one example of highly deformable objects and have been used in applications such as grasp point detection, 8,9 folding, 10 –12 sorting, 13 unfolding, 14 dressing, 12 and classification. 15 –17 There is also an increased interest in using deep learning techniques for online shopping and e-commerce in the fashion industry addressing problems such as clothing category classification, fashion landmark detection, image retrieval and similarity-based recommendations. Following the creation of large-scale fashion data sets, 18 –20 significant progress has been made in fashion image analysis. Deep learning-based models have achieved significant performance gain in clothing category classification, 19,21 –23 item recommendation 24,25 and retrieval. 19,26
We present an extension of our earlier work on clothing category classification and fashion landmark detection. 27 While the fashion industry often considers structured data, such as a human wearing clothes facing the camera, the data in robotic applications is less structured and can contain images of upside-down, crumpled clothing items. We built upon the progress made in fashion image analysis and proposed a network architecture and training procedure on a large-scale fashion data set DeepFashion. 19 Our model was capable to generalize well to the noisy, poorly controlled conditions encountered in robotic clothing manipulation. We introduced elastic warping, a novel image augmentation method that uses random displacement fields to create authentic looking clothing configurations to resemble the more challenging clothing configurations encountered in robotic manipulation. Furthermore, we incorporated rotation invariance and attention mechanisms in order to handle difficult configurations faced in robotic manipulation.
In the work presented here, we extend our earlier work 27 and present a full robotic manipulation framework able to classify different clothing items in a robotic manipulation context, and that makes use of the detected landmarks to manipulate the garments. The contributions are: (i) A robotic cloth manipulation framework based on category classification and landmark detection. (ii) An extensive experimental evaluation on a real robot (140 recorded experiments (https://cloth-manipulation-landmarks.github.io/cml-web/)). (iii) An extended analysis on the effect of the elastic warping method parameters. (iv) A comprehensive description of all parts of the framework, including a more detailed description of the underlying network architecture.
Related work
The release of large-scale fashion data sets have sparked increased interested in the computer vision community on the analysis on fashion images addressing clothing recognition, 19,21 –23 recommendation, 25 retrieval 26 and fashion landmark localization. 19,23,28,29 . Liu et al. 19 propose a multi-branch network for simultaneous classification, retrieval and landmark localization and in Liu et al., 20 they demonstrate refinement of landmark localization. Works of Wang et al. 29 and Liu and Lu 30 are examples of deep fashion grammar network for combined clothing category classification and landmark localization.
Image data used by the robotics community differs significantly from that commonly used in retail applications. The items are either spread out or crumpled on a flat surface, 13,15 or they are in a hanging state when grasped by a robotic gripper. 9,31 –33 The robotics community has mostly focused on task specific, handcrafted feature extraction, such as edges and corners 34 and wrinkles. 35 –37 Due to the 3D nature of the manipulation task, the use of physics and volumental simulators is more common in robotics. 16,38 Recent methods 9,32,33 use convolutional neural networks (CNN) instead of handcrafted features for classification.
Our previous work, focused on category classification and landmark localization, which is now extended here in a complete robotic cloth manipulation pipeline. The network has a similar architecture to, 29,30 but has been extended to more challenging clothing configurations present in robotic applications. Our method does not require generation of a specific labeled data set with predefined grasp points. Instead, it leverages the existing labeled landmarks present in the recent fashion data sets and generalizes to images taken in a robotic lab.
Method
We first formulate the problem of category classification and landmark prediction to be used in a cloth manipulation pipeline. We introduce two image augmentation methods to perturb clothing configuration in such a way that they are more representative of clothing configurations encountered during a robotic cloth manipulation task. We then give a detailed description of the proposed network and describe how the gained knowledge is used in the downstream cloth manipulation task.
Problem formulation
Our goal is to simultaneously predict the landmark locations
Image augmentation
The two proposed image augmentations are image rotation and elastic warping. To augment an image together with its landmarks we define the image before transformation as input image
The transformation can be represented as a mapping of the pixels,

where
When
Rotation
Rotating images is often used to increase the performance in classification and/or detection tasks.
40
When clothing items lie on a flat surface, they can be in any orientation. We hence randomly sample an angle
Elastic warping
Our proposed elastic warping method is similar to the elastic deformation proposed in Simard et al. 39 but is further extended to produce realistic, task-specific images and to allow for landmark detection.
The deformation is created by generating two random displacement fields
First: Sample nS
pixel positions uniformly in the transformed image:
Second: For each pixel location in

All other entries in the displacement fields are set to 0.
Third: Convolve the two displacement fields with a Gaussian filter

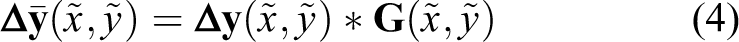
where
Fourth: Use the smoothed displacement field to create the transformed image,
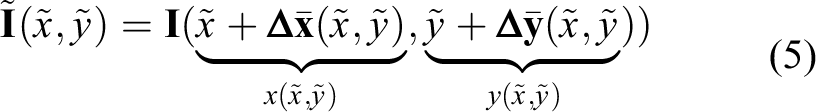
The strength of the distortion can be adjusted by the number of initially displaced pixels nS
, the scaling of the uniform distribution α and the smoothness of the Gaussian filter

Example images of our proposed elastic warping with
Landmark warping
The displacement fields indicate where a pixel in the transformed image was located in the input image. Due to the random nature of these fields no inverse exists. Therefore it is not trivial to know if/where the pixels of the input image are found in the transformed image. As our goal is to preserve the correct position of the landmarks defined in the input we describe an efficient method for retrieving the landmark position in the transformed image.
For every landmark position


where
We use the fact that the pixel coordinates are unique integer values and create a hash table for all coordinate pairs in one set. In the following, one can search for each pair in the other set if a key exist in the hash table, which reduces time complexity for existing coordinated pairs to
If the hash table does not return a valid value, no exact match exists in
Network architecture
The main network architecture is loosely based on the VGG-16 42 network structure similar to the networks proposed in Wang et al. 29 and Liu and Lu. 30 The structure can be seen in Figure 2(a). Compared to the base VGG-16 network, several structural changes are included: rotation invariance layers, a landmark localization branch and attention branches for classification.

The different components of our model. (a) Overall network structure, (b) rotation invariance encoder, (c) landmark (LM) localization branch, (d) attention branch, (e) category aware spatial attention and (f) channel attention.
Rotation invariance
As mentioned before, variation in orientation occurs more often in a robotic cloth manipulation task. In order to account for this, we replace the 2D convolution in the conv1 to conv4 layers with Averaged Oriented Response Convolutions (A-ORConvs). They produce enriched feature maps with the orientation information explicitly encoded. 43
A-ORConvs are an improvement of the Oriented Response Convolutions (ORConvs) initially proposed in Zhou et al.
44
These convolution blocks use Averaged Active Rotating Filters (A-ARFs) and Active Rotating Filters (ARFs), respectively. Both are a 5D tensors of size
In our network (Figure 2(b)), we use the A-ORConvs with four orientation channels (i.e.
Landmark localization branch
The landmark localization branch is the same as proposed in Liu and Lu.
30
The branch structure is depicted in Figure 2(c). It uses transposed convolutions
46
to produce heatmaps for all landmarks. The transposed convolutions allow for an upsampling of the S-ORAlign features
The landmark localization branch can be trained separately from the classification. Let

where nB
is the total number of training samples. The groundtruth heatmap

If there is more than one maximum per landmark one of them is chosen at random.
Attention branch
The attention branch can be seen as a union of spatial attention
47
and channel attention.
45
The attention learns a saliency weight map
Spatial attention – Landmark
Clothing landmarks represent functional regions of clothing and provide useful information about an item. The predicted heatmaps
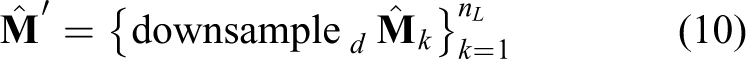
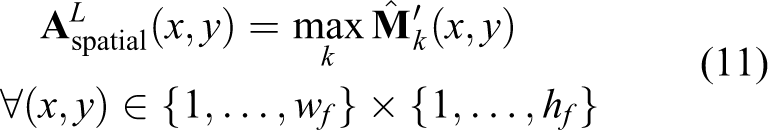
This attention is learned in a supervised manner since it is directly derived from the predicted heatmaps.
Spatial attention – Category
Since the landmark attention only covers corner points of a clothing item, an additional spatial attention is used that focuses more on the clothing center. The category attention (Figure 2(e)) is modeled using an U-Net structure. 48
Given the S-ORAlign features
Channel attention
The channel attention (Figure 2(f)) is implemented via a Squeeze-and-Excitation block.
45
A squeeze operation creates

where
Factorization
The factorization (Figure 2(d)) is performed by multiplying the channel-wise feature responses in the spatial attention with the corresponding channel weights

To refine the attention, an additional
Output architecture
Given
Manipulation framework
Our manipulation framework, shown in Figure 3, consists of the deep neural network described in the previous section. It takes an image of the current scene containing a garment, and outputs the estimated landmarks

Overview of our cloth-manipulation framework. The deep neural network takes the current state of the garment, identifies the class and estimates the landmark positions. The manipulation strategy is then decided given the template. After execution the new state is fed into the network and the process continuous until the task is successfully performed.
Manipulation strategy
The implemented algorithm consists of two parts: an analysis step and a manipulation step. The analysis step detects the landmarks and clothing category. Based on the certainty of the landmarks a mode of operation for the manipulation step is selected, and based on the category a template is selected. The manipulation step has two modes of operation: landmark placement, where a landmark is picked and placed at its position in the template, or stochastic stretching, where a random point on the edge of the clothing is picked and placed a distance outward. The intuitive reason for the two modes for the manipulation strategy is that if the method is not confident to have identified the right category and landmarks, the clothing item needs to be further spread out to make an identification of the category/landmarks feasible. After each execution of the manipulation step, the analysis step is repeated followed by another manipulation step until the clothing has reached the final state described by the template.
A template
Analysis step
An image is taken and transformed to match an image taken from a virtual camera located right above the clothing to remove perspective distortion and rotation, improving the accuracy of the proposed network. The virtual camera is placed such that the bottom of the clothing in the template is parallel to the bottom of the image. When initializing the algorithm, the homography

where k is a scalar.
The contour of the garment is found using the OpenCV
50
implementation of Suzuki et al.,
51
and a bounding box containing the region of interest is determined. The region of interest is passed through the network yielding the class

is computed for each landmark, the position is transformed to the original image using the inverse homography
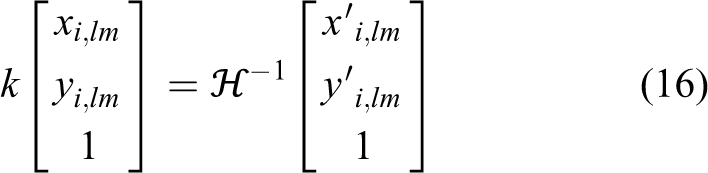
where k is a scalar. The landmarks are finally transformed to a three dimensional point in the world coordinate frame by assuming that all landmarks lie in the plane coinciding with the table. They are then compared with the template to form a set
The final part of the analysis step determines the certainty of the landmarks to select between the two modes of operation. As a measure of uncertainty Ui
for landmark i the weighted maximum eigenvalue of the covariance matrix
Manipulation step
Dependent on the result of the analysis step, the manipulation step does either landmark placement or stochastic stretching.
Landmark placement: The landmark i with lowest uncertainty as selected by the analysis step is picked and placed at its location
Stochastic stretching: If the analysis step could not determine any certain landmarks, the manipulation step does stochastic stretching. A contour around the clothing in the transformed image is found by using the OpenCV
50
implementation of Suzuki et al.,
51
and a random vertex
Data sets
In this section we introduce all data sets used for the training and evaluation.
DeepFashion data set
The DeepFashion: Category and Attribute Prediction Benchmark (DeepFashion data set (http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion/AttributePrediction.html))
19
is a large collection of fashion images. It consists of 289,222 annotated images that where collected from shopping websites and Google image search. The images cover
This data set is used to train the networks with our proposed augmentation methods.
CTU Color and Depth Image Dataset
The CTU Color and Depth Image Dataset of Spread Garments (CTU data set (https://github.com/CloPeMa/garment_dataset))
52
is designed for testing and benchmarking garment segmentation and recognition. This data set exemplifies the unstructured clothing configuration often found in robotic cloth manipulation, meaning the garments are not only spread out flat but also exhibit wrinkles and a huge number of different orientations. The data set contains
In-Lab data set
While the CTU data set is much closer to a real robotics cloth manipulation task than the DeepDashion data set, we created a small In-Lab data set that is even more typical for robotic tasks. It contains
Garments used for manipulation experiments
To evaluate the manipulation algorithm, seven garments from different categories and with different visual features were used. Three of them in the category ‘t-shirt’: one grey with a black star-shaped pattern, one with colorful stripes and one with a wide dark region. Furthermore, we used one grey sweater with colorful thin stripes, a dark and a white blouse, a pair of orange shorts and a pair of blue jeans.
Learning experiments
This section describes different experiments designed to evaluate the performance of our network and learning procedure. In this section the individual experiments and results are described in detail.
Pretraining on the DeepFashion data set
We use the same settings as in the literature 19,29,30 for training and evaluation. The training set contained 20,922 images while the validation set holds an additional 40,000 images. The test set (used for the final evaluation) is composed of the remaining 40,000 images.
We use the normalized error (NE) 20 as the landmark localization error measure. This is the l 2 distance between the predicted and ground truth landmark in normalized coordinates. For the category and attribute classification top-k classification accuracy is used.
Before training, the images are cropped to their bounding boxes. We train our model with and without our proposed data augmentation steps whereas the evaluation is always performed without augmentation. All implementation details can be found in the code basefn: website
Experiments on CTU data set
We perform two types of experiments on the CTU data set. In the first experiment, we analyze the inference performance of our network, solely trained on the entire DeepFashion data set. This is done in order to be able to evaluate the usefulness of the proposed data augmentation methods. In the second experiment, we evaluate the performance of our network when trained and evaluated on the CTU data set.
Experimental setup
In order to use both, the
For the second experiment, we split the CTU images randomly into a train, validate and test set (i.e.
Performance evaluation
The results of landmark prediction and category classification on the CTU data set with pre-trained models are shown in Tables 1 (top) and 2, respectively. First we note that the benefit of training with rotated images becomes apparent. That rotations are boosting the performance is not surprising considering the composition of the CTU data set that contains images taken in a high variety of orientations, where in the DeepFashion data set all items of clothing are upright. Adding elastic warping increases the performance further for the landmark prediction for all cases except the one where training was performed on DeepFashion with no rotation. The overall classification accuracy of
Results on CTU data set for landmark localization with different augmentation methods, when trained on the DF data set (top) and in the CTU data set (bottom).a

R & EW: rotation & elastic warping; DF: DeepFashion.
a The values represent the normalized error (NE). Best results are marked in bold.
Results on CTU data set category classification with different augmentation methods, when trained on the DF data set.a

R & EW: rotation & elastic warping; DF: DeepFashion.
a Best results marked in bold.
The results of the second experiment, trained and evaluated on CTU data set, are shown in Table 1 (bottom). Note that landmark predictions are obviously significantly better when learned on the original data set. In this case the elastic warping seems to especially boost the performance in the case of no rotations. We hypothesize that this is probably connected to the data set composition and size as the EW augmented images boost the performance. We omit the category classification results on the CTU data set since all the tested models achieve
We conclude that, adding elastic warping as a data augmentation method improves the performance in most of the evaluated cases. Our network outperforms the one proposed by Liu and Lu 30 when trained with the same augmentation methods in both experiments. This indicates that state-of-the-art methods are likely to not generalize well to more challenging robotic focused data sets.
Experiments on In-Lab data set
We leverage our In-Lab data set to investigate the performance of the network solely trained on the DeepFashion data set, and then subsequently used to classify images taken in a robotic lab environment.
The results for landmark prediction and category classification are shown in Tables 3 and 4, respectively. Some landmark predictions are exemplified in Figure 4. Interestingly, the hoody item is almost always misclassified with the exception of the model employing the elastic warping method. Furthermore, the long sleeve t-shirt (Figure 4 top row in the middle) is often classified as a sweater. With these two challenging items the best accuracy we achieve is
Results on In-Lab data set for landmark localization on unknown items of clothing.a

R & EW: rotation & elastic warping; DF: DeepFashion.
a The values represent the normalized error (NE). Best result marked in bold.
Classification accuracy on In-Lab data set for unknown items of clothing.a

R & EW: rotation & elastic warping.
a Best result marked in bold.

Example images of the landmark localization on our In-Lab data set. The categories are from top left to bottom right: Tank, Tee, Sweater, Hoody, Jacket, Jeans. Robot arms are visible in the images. The predicted heatmaps are shown in red and the blue crosses denote the selected maximum values.
Elastic warping parameters
We investigated the effect of the elastic warping parameters α and
Results on CTU data set for landmark localization with different parameters for the elastic warping, when trained on DF data set (top) and in the CTU data set (bottom).a

R & EW: rotation & elastic warping; DF: DeepFashion.
a The values represent the normalized error (NE).
Robotic experiments
The algorithm described in the ‘Manipulation strategy’ section was implemented on a Baxter robot. The proposed network is used to perform cloth manipulation with the aim to stretch garments. The robot is presented with garments in different predefined starting states and the evaluation criteria is based on whether it can bring the garment into the state described by its template. The experiments is ended either when the state was within the tolerance from the template or when manually terminated.
Experimental setup
The manipulation clothing was tested with the initial states: folded hem, folded collar, folded sleeves, folded waist, folded legs and crumbled, see Table 6. All experiments were repeated five times with a model trained on the DeepFashion data set with rotation and with elastic warping parameters
Success rate of manipulation with model trained on the DeepFashion data set with elastic warping parameters

aA ‘–’ is placed where the experiment is not applicable. Each experiment was repeated five times.The limits for class and landmark certainty and the weights were chosen empirically, see Table 7. A tolerance of
Weights and relevant landmarks for the robotic experiments.a Omitted weights have a value of 1.

Manipulation results
The success rates for the experiments are shown in Table 6. The results are summarized in Table 8 where ‘manually terminated’ are the proportion of failures that were terminated manually because the solution was not advancing, ‘closeness’ indicates how close the manually terminated experiments were from being solved, ‘closeness stdev’ is the standard deviation of the closeness number, ‘bad move’ is the proportion of failures that were terminated manually because of the robot making an irrecoverable bad move, and ‘false success’ is the proportion of failures that the algorithm reported as a success. The results of running the complete algorithm with classification are shown in Table 9, where ‘no class’ means that the algorithm was manually terminated because no class was ever determined. The experiments on the CTU data set resulted in 0 successes. Recordings of all experiments are available at the websitefn: website.
Summary of rates of success and failures for each class with model trained on the DeepFashion data set with elastic warping parameters

a Closeness is the mean minimum mean error of the manually terminated experiments.
Success rates [0–1] for experiments folded hem and folded collar for garments tee (stars) and tee (stripes) with classification.

The closeness is computed as the mean error of the landmarks compared to the template. Each time the landmarks are measured in the analysis step, the mean distance to their position in the template is computed based on those measurements. The minimum value during one execution of an experiment, or the minimum mean error, is taken as a measure of closeness to the solution for that execution. The mean of all minimum mean errors, taken across all executions of all experiments for a class that resulted in manual termination, is taken as mean minimum mean error and is reported as ‘closeness’ in Table 8.
The manipulation strategy has no notion of in what order the landmarks should be placed, it merely picks the one with least uncertainty. This leads to the common failure scenario of placing a landmark in a way that moves the clothing into a state that is much harder to solve. Another failure reason is incorrect output of the network. For some configurations of the clothing the network is over confident in the position of the landmarks, making the manipulation strategy perform a bad move. The extent of this depends on the garment being used, and the effect can also appear when the manipulation strategy tries to place the landmarks in a bad order, resulting in a challenging state as discussed previously.
Discussion and limitations
The method was sensitive to lighting conditions and to the color of the garment. A garment with similar color to the background showed to be problematic for the method as can be seen for Tee (dark) in Table 8. Garments that had smaller parts with a similar color to the background or garments with an overall slightly similar color could cause problems on the contour detection, as the detection of the contour would miss part of the garments and present an incomplete image to the network (see Figure 5). The dependence on lighting can be observed for the garments Sweater and Jeans in Table 8, where the success rate is low and the rate of manual termination is high. Wrinkles and small displacements could influence the detected class with the effects largely affected by the lighting conditions.

Failure cases due to erroneous detection of the contour. Left: The shirt color and background are too similar. Right: Lighting conditions lead to wrongly detected bounding box.
The model trained on the CTU data set had poor performance, with no successes at all. Even though the CTU data set is more similar to the application than the DeepFashion data set.
This indicates that the smaller size of the CTU data set has lead to over fitting and showcases the importance of using large-scale data sets and data augmentation methods like elastic warping combined with more robust manipulation strategies.
The experiments show the potential in using landmark placement for robotic cloth manipulation. As can be seen in Table 6 some simple cases had a high success rate and there is a possibility of solving the hard initially crumbled state. Furthermore, the method has a low rate of false success, it can accurately determine whether the garment is stretched.
Conclusion and future work
We presented a complete cloth manipulation framework based on category classification and landmark detection. We use a large publicly available fashion image data set with a data augmentation method called elastic warping to train a network for garment classification and landmark detection for robotic manipulation application. We evaluate the performance of the network and the effects of the elastic warping thoroughly. We show that the parameter of the method can be tuned to fit a desired target distribution. Furthermore, we perform a wide set of real world robotic experiments where the goal is to stretch the garment from different starting configurations and provide all experimental videos on our supplementary websitefn: website. This extensive evaluation highlights the importance of more robust preprocessing methods as the used contour detection, as it is susceptible to different lighting conditions as well as erroneous if the garment color is similar to the background color. Finally, we show the inadequacy of using smaller data set for robotic purposes when dealing with novel clothing items, by comparing the performance of our method trained on a large-scale fashion data set with the performance trained on a robotic specific data set. Furthermore we plan to incorporate the learning component also in the manipulation step to formulate more robust manipulation strategies and combine the stretching step with the manipulation step. Performing an investigation towards the effect of occlusions.
Footnotes
Authors’ note
Oscar Gustavsson and Thomas Ziegler contributed equally to this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed the receipt of the following financial support for the research, authorship, and/or publication of this article: This research has been financed by the Swedish Research Council, Knut and Alice Wallenberg Foundation and European Research Council (ERC) (grant Agreement No. 884807).
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.