
Abstract
The use of mobile robots for assisting astronauts in extravehicular activities could be an effective option for improving mission productivity and crew safety. It is thus critical that these robots follow the astronaut and maintain a stable distance to provide personalized and timely assistance. However, most extraterrestrial bodies exhibit rugged terrain that can impede a robot’s movements. As such, a novel predictive-guide following strategy is proposed to improve the stability of astronaut–robot distance in obstructive environments. This strategy combines a deep reinforcement learning navigator and a Kalman filter-based predictor to generate optimized motion sequences for safely following the astronaut and acquire predictive guidance concerning future astronaut movements. The proposed model achieved a success rate of 95.0% in simulated navigation tasks and adapted well to untrained complex environments and varied robot movement settings. Comparative tests indicated our strategy managed to stabilize the following distance to within ±1.0 m of the reference value in obstructed environments, significantly outperforming other following strategies. The feasibility and advantage of the proposed approach was validated with a physical robotic follower in a Mars-like environment.
Keywords
Introduction
Future manned extraterrestrial exploration may include sustained human habitat development and in situ resource utilization. 1,2 These surface exploration missions will inevitably require extravehicular activities (EVAs), which could be time-consuming and dangerous. Thus, the cooperation of astronauts and mobile assistant robots offers the potential to increase mission productivity and ensure crew security during EVA tasks, due to improved mobility, load capacity, and environmental tolerance. Specifically, assistant robots can operate alongside astronauts and perform repetitive tasks or assist with photographing, lighting, tool carrying, material mining, collecting and transporting, repairs, and alerting the astronaut of potential hazards. In the past 20 years, several exploratory analog field tests involving astronaut–robot cooperation during EVAs have been conducted, such as the astronaut-rover interaction field test, 3 the desert research and technology study, 4 and MOONWALK. 5 These projects have investigated issues of EVA astronaut–robot cooperation, including astronaut following, on-site astronaut–robot interaction, and collaborative operation. 6,7
Stably following an astronaut requires maintaining a consistent astronaut–robot distance and is a prerequisite for efficient cooperation in several ways: timely and personalized responses to the astronaut’s requests, stable distance for robust visual tracking of the astronaut, as well as sustainable following. However, it can be challenging to maintain a stable astronaut–robot distance in complex extraterrestrial terrain, where rocks or sand can impede the robot. In addition, strictly following the astronaut’s trajectory is often not ideal for the robot, due to differences in their size, mobility, and gait. Even if the robot possesses obstacle avoidance capabilities, efficient coordination is required for stable following distances. Existing astronaut following strategies typically do not consider following stability in the presence of obstacles, in which either the robot is directly controlled to maintain a fixed following distance based on stereo vision powered astronaut detection and location, without considering the hazards, 3 or the obstacle avoidance technique is implemented independently of astronaut following. 6
Techniques for stably following a human have seen increasing interest in social applications of family services, elderly care, and medical assistance. One intuitive method is to control the robot to directly approach the target person with the help of some vison-based perception techniques. 8 –10 For example, Pang et al. 8 employed a proportional-derivative (PD) controller to maintain a consistent distance and orientation relative to an identified human target. In a comparable study, an end-to-end controller was trained using deep reinforcement learning (DRL), making the robot a robust follower using only monocular images. 9 Besides, deep learning-based methods have also been applied, due to their high accuracy and speed of human detection, to improve the robot’s following robustness and efficiency. 11,12 These techniques featured simple control systems, nevertheless, have been limited to ideal conditions without the inclusion of obstacle avoidance. Recent efforts considering obstacle avoidance during human following have involved more complete following frameworks. Wu et al. implemented human following and obstacle avoidance modules separately, applying a priority decider for robot behavior coordination. 13 Yun et al. combined three artificial force fields in coordinating human following and obstacle avoidance. 14 By these methods, obstacle avoidance and target following of the robot were implemented independently, which might lead to the loss of optimality. For following path optimization, the issue can also be considered a path planning problem and addressed using combined global and local path planning algorithms. 15,16 For instance, Pang et al. utilized the A* 17 and timed elastic band 18 to identify optimal collision-free following paths for the robot. 15 However, path searching in the GPS-denied environment calls for real-time obstacle map construction based on 3D-LiDAR sensors, involving high power consumption and computational demand.
Some innovative attempts have been made to improve the intelligence and efficiency of the following robot, given knowledge of the target human’s predicted movements. 19,20 For example, Bayoumi and Bennewitz predicted human motion using a modified Markov decision process (MDP) 21 and developed a DRL-based navigator, which resulted in foresighted following behaviors and shorter following trajectories. 19 Recovery mechanisms, based on human trajectory prediction, have also been implemented when the robot misses a target in dynamic environments. 20 These studies suggested that the prediction of user movement could significantly improve following efficiency and the foresightedness of the robot, but the mechanisms how it contributes to following stability remain to be addressed.
This study devotes to coordinative planning of obstacle avoidance and astronaut following for the EVA assistant robots, so as to improve the following stability in obstructed environments. We resolve astronaut following into two process, namely robot navigation and predictive guide. A novel predictive-guide strategy is proposed, which combines a DRL navigator and a Kalman filter (KF)-based predictor. The predictor is applied for acquiring predictive-guide information concerning future astronaut movements, while the navigator is then provided with fused data including predicted information and depth information acquired from the robot’s field of view (FoV), to generate optimized motion sequences for avoiding obstacles and following the astronaut. Simulations were conducted to assess robot adaptability to unknown complex environments as well as varied speed settings. Comparative tests suggested this strategy outperformed the other two strategies in following stability. Finally, the effectiveness of the proposed technique was verified experimentally using a physical robotic test bed developed by our group. The primary contributions of this study are as follows: A novel predictive-guide strategy is introduced to enable target following in obstructed environments, which improved stability. The DRL-based navigator is well generalized to unseen conditions, complex obstacles, variable robot motion settings, and a real-world robotic test bed, after being trained in a relatively simple simulation environment. A physical robotic follower is designed and constructed to demonstrate the advantages of our predictive-guide strategy in real-world settings.
Scenario formulation for robotic following of astronauts
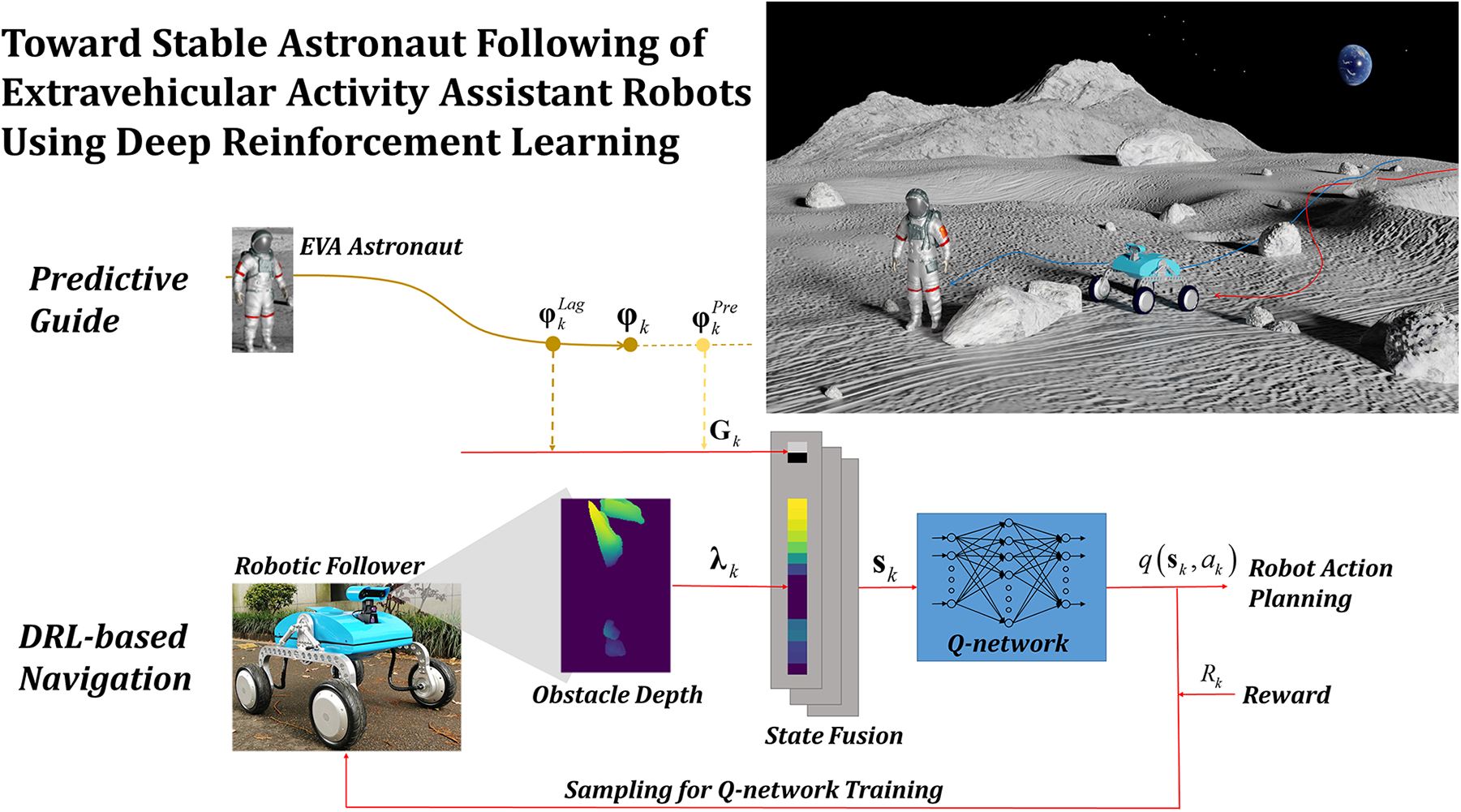
This study focuses on developing a predictive following strategy to enable assistant robots to follow astronauts while maintaining a stable distance on obstructed extraterrestrial surfaces. Figure 1 shows an example of predictive following, in which path 1 shows a possible strategy in which the robot tracks the astronaut’s trajectory and approaches the current astronaut position, while path 2 reveals a more ideal solution in which the robot finds a shorter path to avoid rocks and approach to predicted astronaut positions.
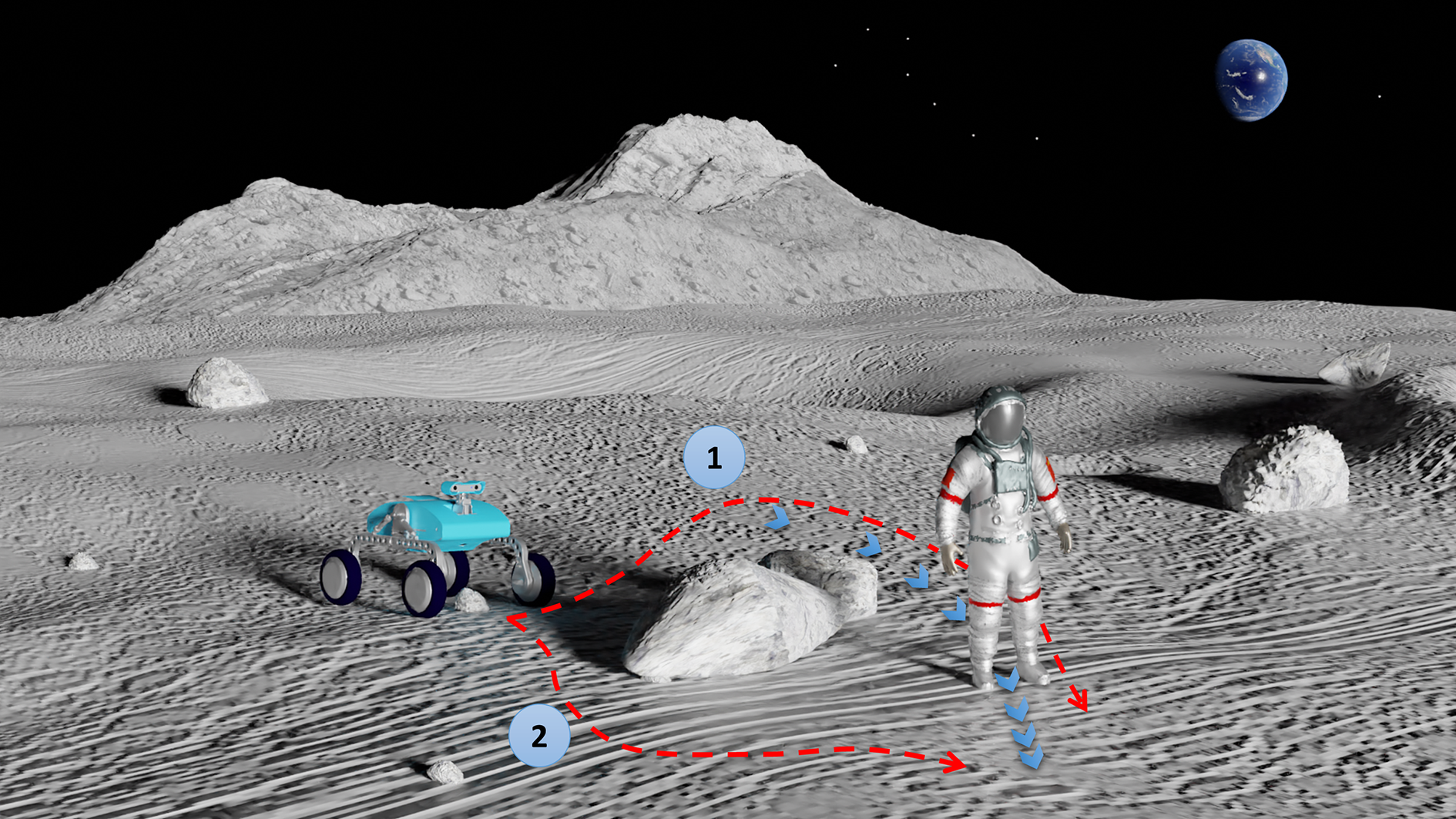
An EVA scene with an astronaut followed by an assistant robot. Path 1: an elementary path tracking the astronaut’s trajectory. Path 2: a shorter path to avoid rocks and approach to the predicted astronaut position. EVA: extravehicular activity.
For convenience of explanation, the astronaut’s position, robot’s position, and astronaut’s velocity are, respectively, denoted by
A robotic follower was designed and constructed as shown in Figure 2, to validate the proposed model. The robot has a mass of approximately 42.0 kg and an outer envelope size of 850 × 710 × 580 mm3. The outer structure is composed of a dexterous four-wheel differential platform, a pair of self-stabilizing suspension assemblies, an electrical cabin, and an orientation-adjustable stereo camera (detailed facts of the robotic follower can be found at www.researchgate.net/publication/358734507_Data_Brief_A_Dexterous_Smart_Robotic_Follower).The robotic follower provided an eligible test bed to validate numerical settings and evaluate physical experimental results.

The robotic follower acting as a test bed.
The predictive-guide framework
Astronaut following in obstructive environments can be decomposed into two hierarchies: robot navigation and guidance. A novel predictive-guide framework for astronaut following control of the robots is proposed and described in this section.
The predictive-guide framework
The framework of the predictive-guide strategy consists of a DRL powered navigator and a KF-based predictor, as shown in Figure 3. The predictor was used to acquire predictive guidance information based on the astronaut’s trajectory, which was then fused with local obstacle measurements and provided to the navigator for robot behavior planning. We suggest astronaut following and obstacle avoidance could be coordinated simultaneously in a predictive manner, using this hierarchal framework.
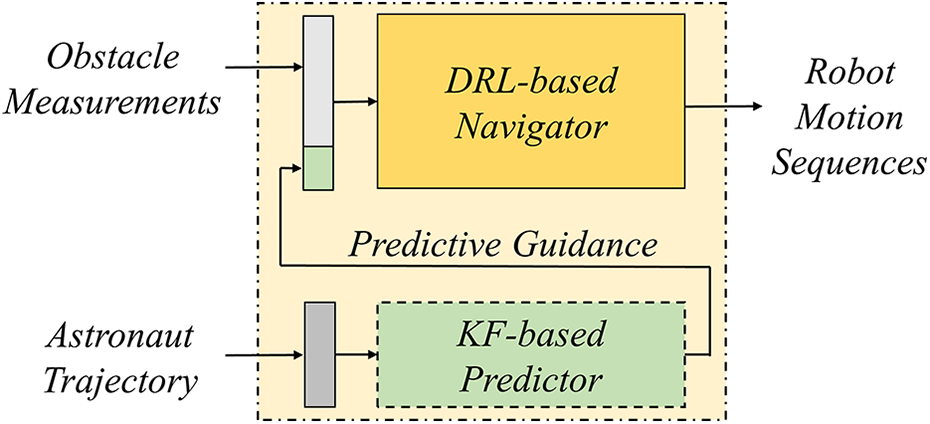
The predictive-guide framework.
End-to-end navigator
An end-to-end navigator is built based on DRL, which can carry out reactive motion planning according to the target information and the perceived depth measurements from the robot’s FoV. A concise principle of DRL as well as the design of the navigator and the reward function will be introduced in this subsection.
Reinforcement learning model
Reinforcement learning constructs optimal mapping relationships between states and actions by estimating how humans would respond to external signals. 22 The deep Q-network (DQN), 23 a representative reinforcement learning framework that uses a Q-network to represent state spaces and evaluate actions, provided an attractive end-to-end architecture mapping raw high-dimensional sensing data for robotic action decisions. We modeled the robot navigator based on DQN, due to its high generality and simpler architecture for single networks, compared with other DRL frameworks. The mathematical model of the navigator, based on MDP, 21 is presented below.
In the kth time step, the navigator observes a state
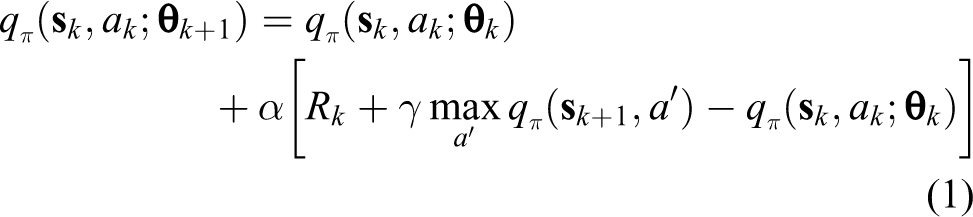
where α represents the learning rate. The navigator can then be trained by minimizing the following loss function
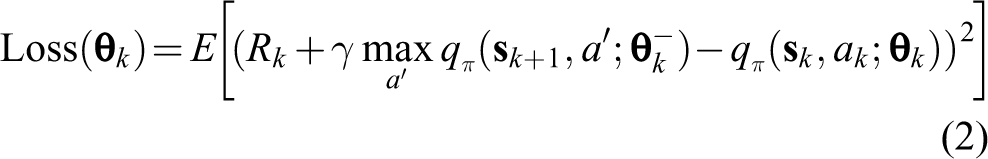
where
Navigator design
An end-to-end navigator based on DQN was developed for assistant robot behavior planning. A Q-network composed of four fully connected layers activated by rectified linear units is provided with fused local depth sensing data from the robot’s FoV and guide information concerning the astronaut’s position. Figure 4 illustrates information flow in the proposed DRL-based navigator.
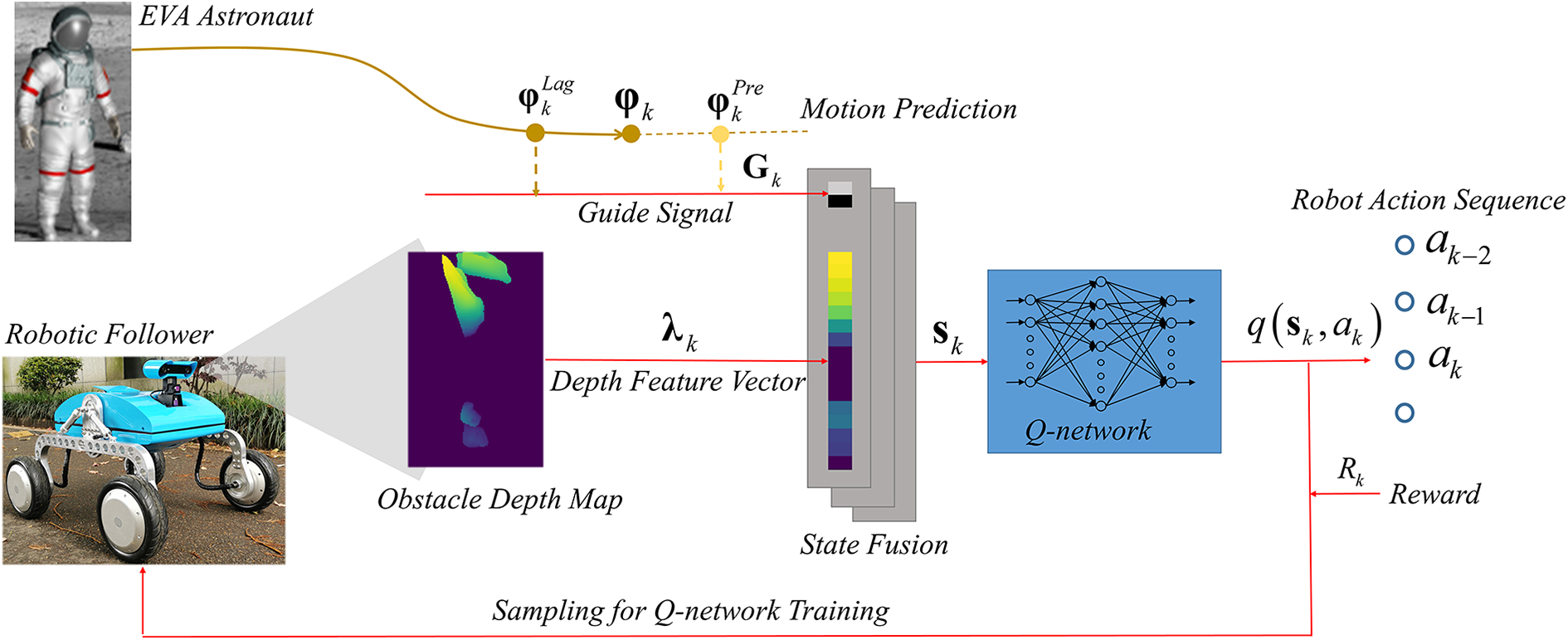
Information flow in the predictive-guide strategy.
Depth feature vectors
A depth feature vector
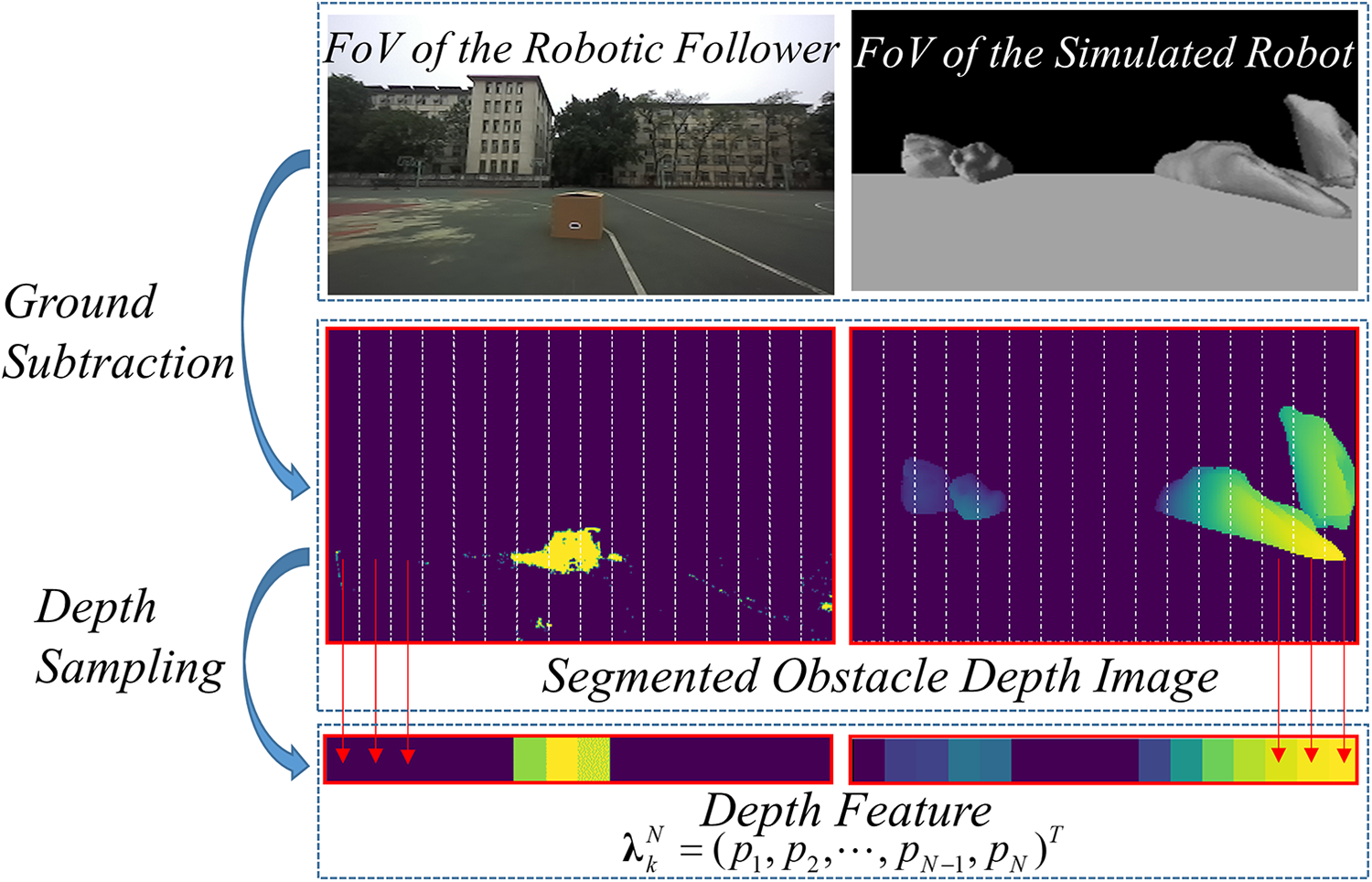
Depth feature vector acquisition.
Guide information
A guide point
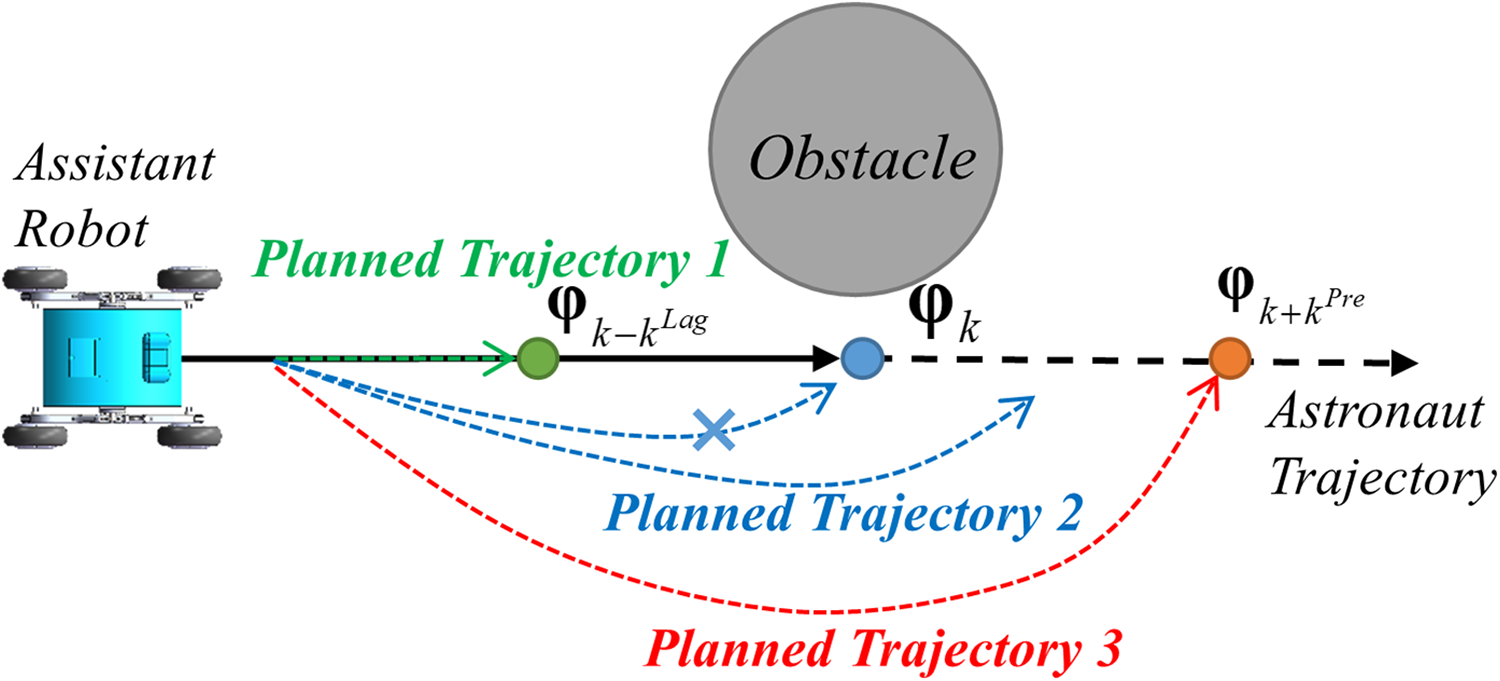
The effects of using different guide points.
A combined strategy for guide point determination was developed using the mechanisms discussed above and can be expressed as
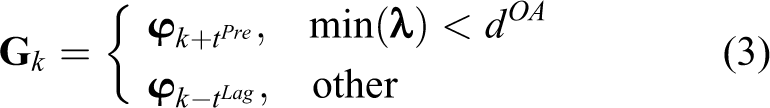
where
State fusion with multiple moments
Generally, a limited perception of the robot’s forward-facing FoV and the high dynamic due to the movement of the robot itself can negatively affect obstacle avoidance planning in complex environments. We suggest that fused states from continuous time steps could compensate for these issues. Specifically, depth feature vectors and guide information during the last k Memory steps, used to overcome incomplete perception, can be fused as

The dimensions of
Action set
The action set for the robotic follower includes discrete movements commands (
Integrated reward
A dense integrated reward was included to optimize the DRL-based strategy for improved guide point following, obstacle avoidance, and energy saving. These attributes are described in detail below.
Reward for guide point following
A large positive reward of
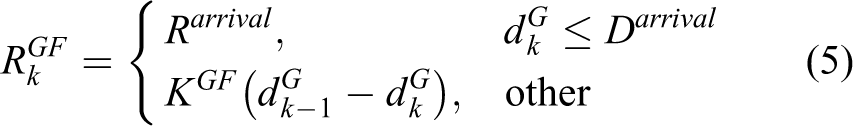
where
Reward for obstacle avoidance
The robot is considered at risk of a collision if an obstacle enters its FoV. A function
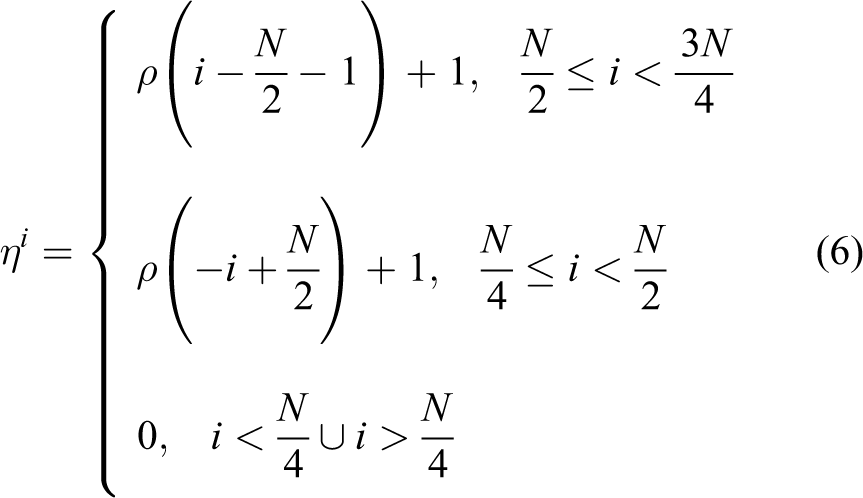
where ρ represents the slope of the curve and N represents the length of
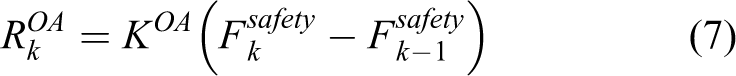
where

where
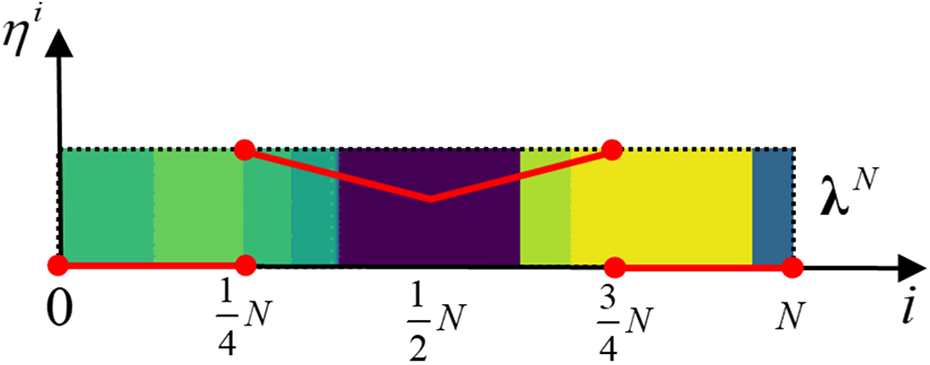
The sum weight curve of the safety function. The weights at two ends are set to 0 to prevent the disturbance from obstacles on the robot FoV edges. FoV: field of view.
Reward for energy optimization
A reward for optimizing the length of the robot’s path, denoted as
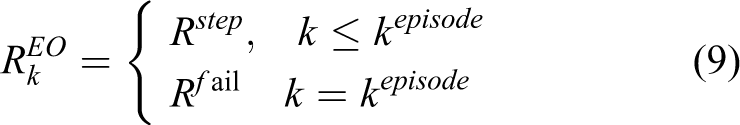
The final comprehensive reward was calculated by summing the three rewards discussed above
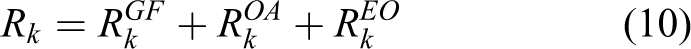
Astronaut movement prediction
The predicted astronaut position
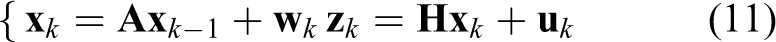
In the above expression,
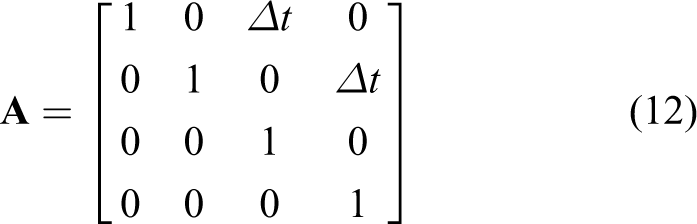
where
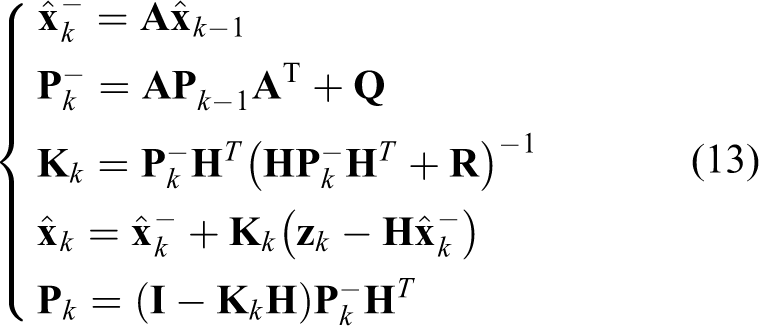
In these expressions,
Numerical analysis
The numerical work mainly copes with navigator training, discussion about the method generalizability, as well as comparative analysis on the performance of the proposed predictive-guide following strategy.
Navigator training settings and results
The navigator was trained through a cross-platform simulation environment mainly based on V-REP 27 (see Appendix 1 for details of the training settings). An environment containing three clusters of obstacle was constructed to train the navigator, as depicted in Figure 8(a). At the beginning of each training episode, the location of the robot was randomly initialized, while the guide point was maintained at a constant position throughout all episodes. Each navigation episode is considered a success only if the robot has arrived at the guide point within the maximum number of steps. We managed to train the navigator with a success rate of 95.0% using piecewise hyperparameters. Success rate and the average Q value over the training episodes are plotted in Figure 9, demonstrating the navigator optimization process.
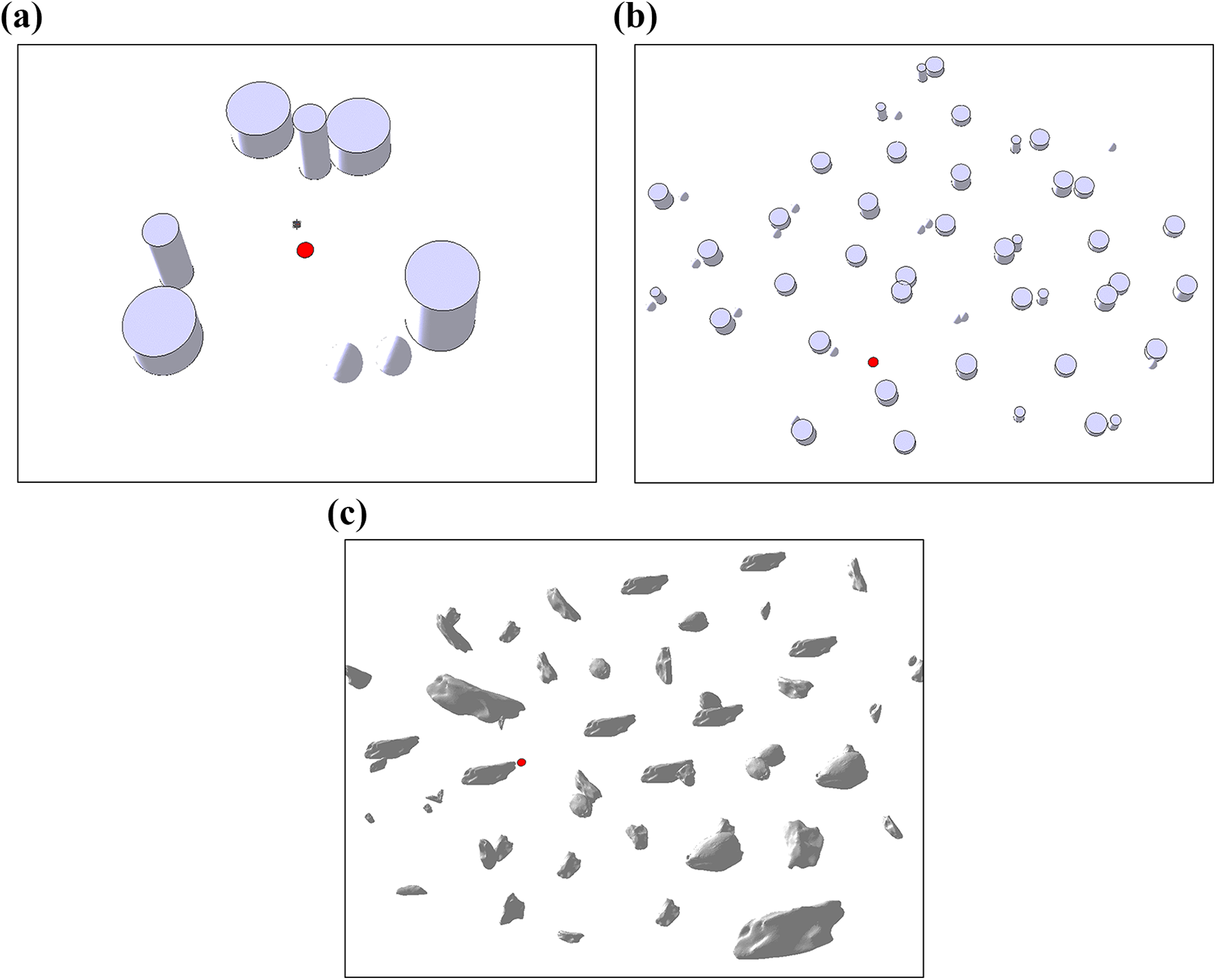
Obstacle environments used for navigator training and testing: (a) environment 1 for training, (b) environment 2 with regularly shaped obstacles, and (c) environment 3 with irregular rock-like obstacles.
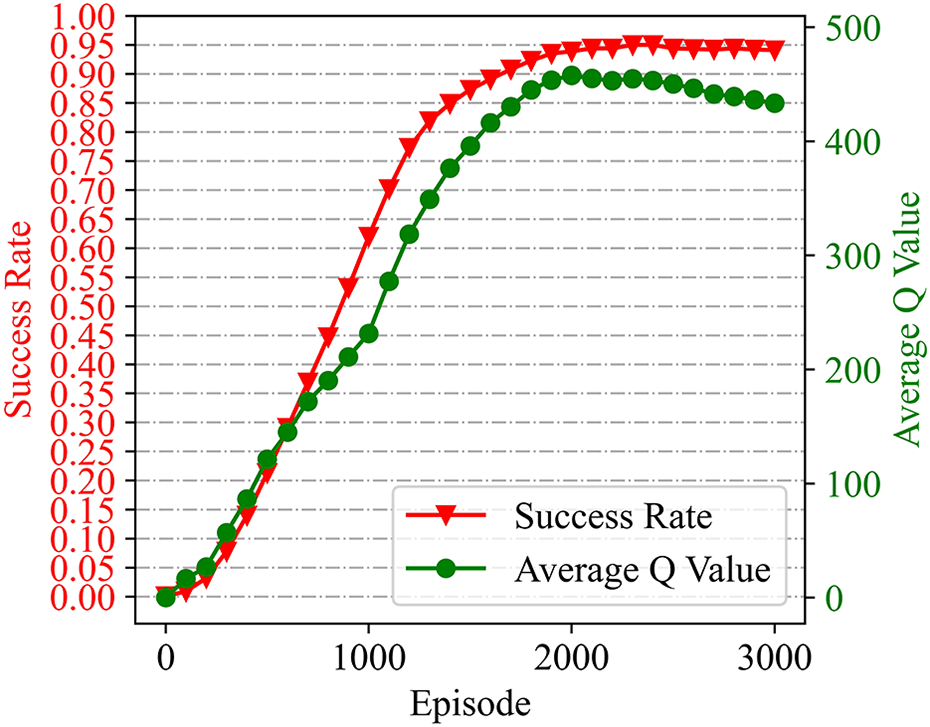
Training curves. The red curve is for success rate over the training episodes and the green for the average Q value.
Generalizability analysis
The generalization ability of learning-based algorithms represents its adaptability and feasibility in a strange environment. We have tested the adaptability of the trained navigator to several untrained environments as well as varied motion parameters in simulation in the following subsection.
Navigator generalizability in unseen environments
The trained navigator was applied to unseen environments to evaluate algorithm generalizability. Three obstacle layouts used are shown in Figure 8. Environment 1 is the training environment, while environments 2 and 3 are unknown to the robot and exhibit clusters of regular shapes and irregular rock-like obstacles, respectively.
We conducted 1000 repetitive navigation tests in each environment to evaluate the adaptability of the navigator. It should be noted the navigator was no longer trained when applied to the two novel environments, relying solely on the model acquired during the previous training runs. The position of the robot and the guide point were randomly initialized at the beginning of each test episode. As shown in Table 1, the trained navigator adapted well to environment 2, with a high navigation success rate comparable to that of the training environment. What’s more, the trained navigator exhibited robust generalizability in environment 3, among rock-like obstacles with complex shapes and variable sizes.
Navigation success rates in three different environments.

Navigator generalizability for various motion settings
It is of great significance to investigate the robustness of the DRL-based navigator to various robot speeds, since accurately controlling the robot on extraterrestrial surfaces without precise models of friction and the softness of the ground is challenging. The robot was trained to drive ahead and steer with a maximum wheel tangential speed of 0.5 ms-1 and 0.7 ms-1, respectively. In evaluation episodes, a multiplier factor was introduced to vary the robot’s speed, which was applied to each motion in the robot’s action set. One thousand episodes of navigation tests were conducted in environment 2, and the resulting success rates over the speed multiplier factor are plotted in Figure 10. Evidently, multiplier factors as low as 0.5 and as high as 2.0 produced success rates of no less than 85% in the untrained environment, indicating that the trained navigator is robust to varying robot speeds.
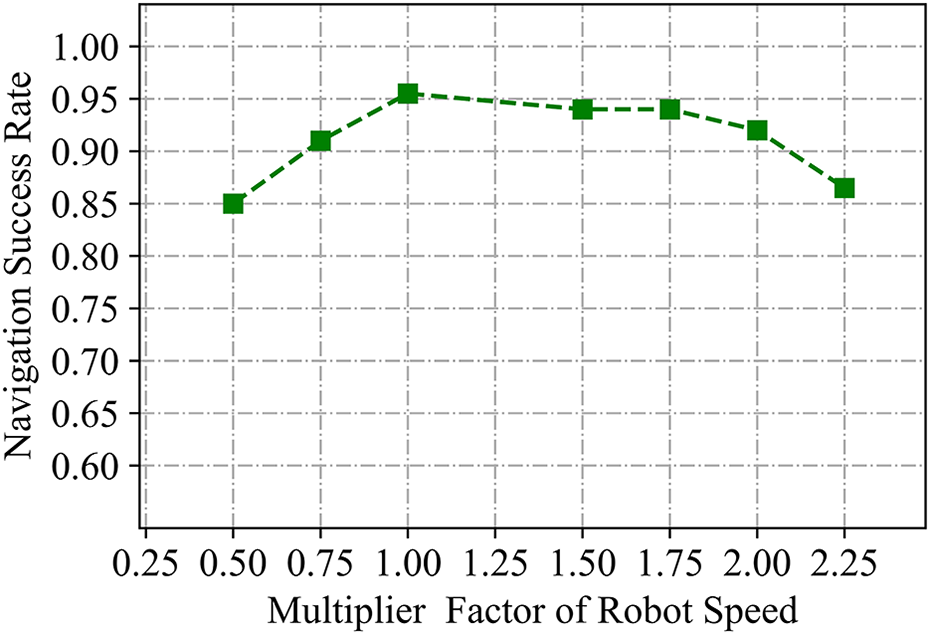
Success rates for various robot speeds. The multiplier factor equal to 1.00 stands for a driving speed of 0.5 m s−1 and a steering speed of 0.7 m s−1 of the robot.
Astronaut following performance
In this subsection, numerical analyses about the performance of the proposed predictive-guide following strategy are conducted, including an effectiveness validation of the method, a comparative analysis about the following stability, as well as a supplementary analysis about the quantitative influence of the robot’s and the astronaut’s speeds.
Simulation of astronaut following
The effectiveness of the proposed predictive-guide strategy for astronaut following was preliminarily validated in simulation. The astronaut was set to move through a preset trajectory, with a constant speed of 0.25 m s−1, as the assistant robot attempted to avoid the obstacles and keep up with the astronaut. Two examples, in which the astronaut walks along straight and circular trajectories, are shown in Figure 11. The predictive-guide strategy was initialized by
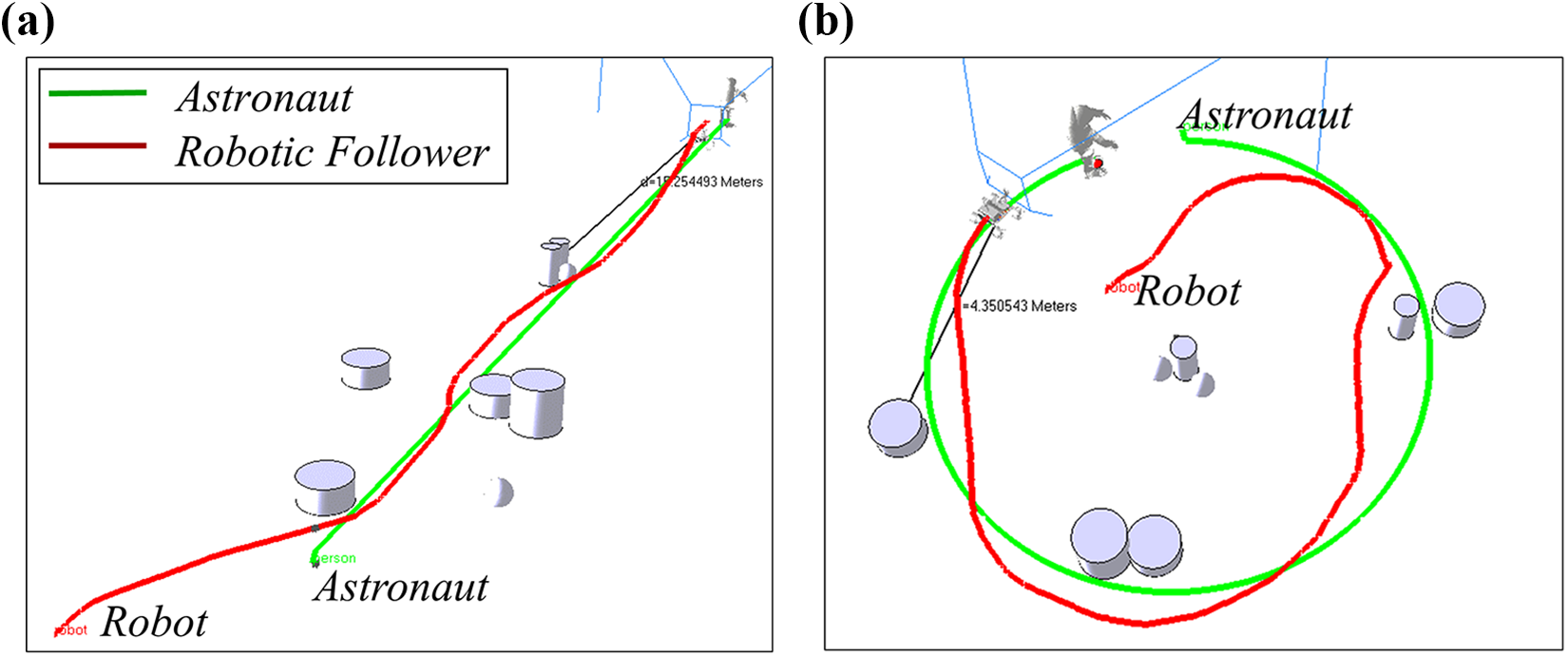
Following trajectories. The astronaut walks along a (a) straight trajectory and (b) circular trajectory.
Comparative analysis
Predictive knowledge of the astronaut’s future movements, one of the primary contributions of this study, was included in the predictive-guide strategy to assist the navigator in planning an ideal following sequence, which was expected to improve following stability. Quantitative analyses were conducted to determine the advantages of the proposed technique. The OA-first and target-guide techniques, based on the trained DRL navigator, were included for comparison purposes, as discussed below.
Each of these strategies was used to control the robot as it followed the astronaut and traversed complex terrains. The astronaut was set to walk along a straight trajectory of length 50.0 m at a speed of 0.25 m s−1. Each test episode began with the same initial robot position and the same preset astronaut trajectory. Parameters were set as
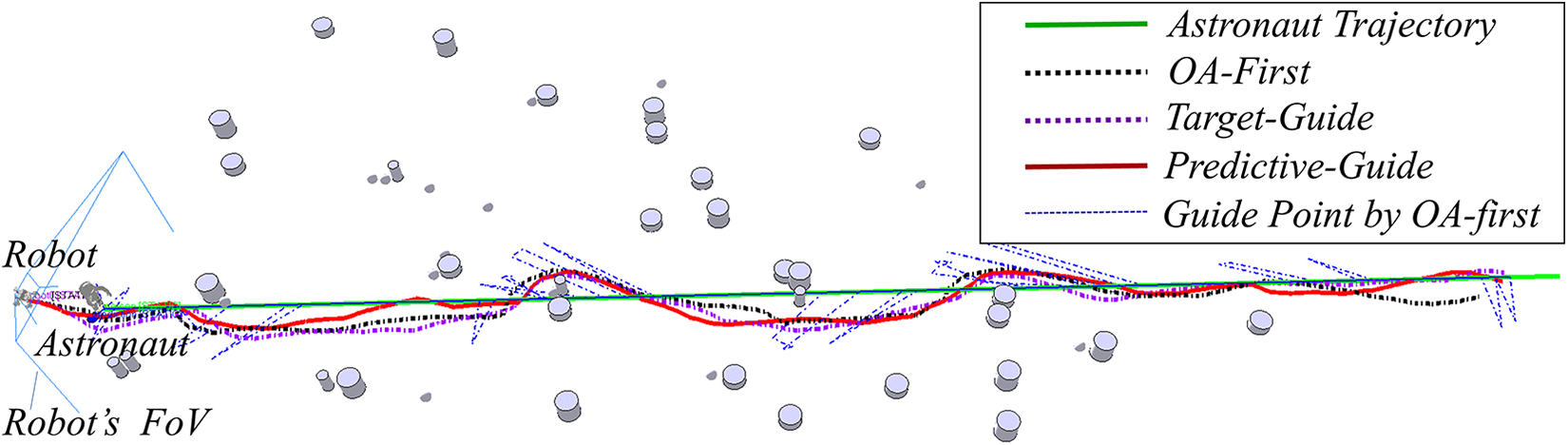
Motion trajectories by the three following strategies. The simulated astronaut walks with a speed of 0.25 m s−1 and the reference following distance is set as 2.0 m.
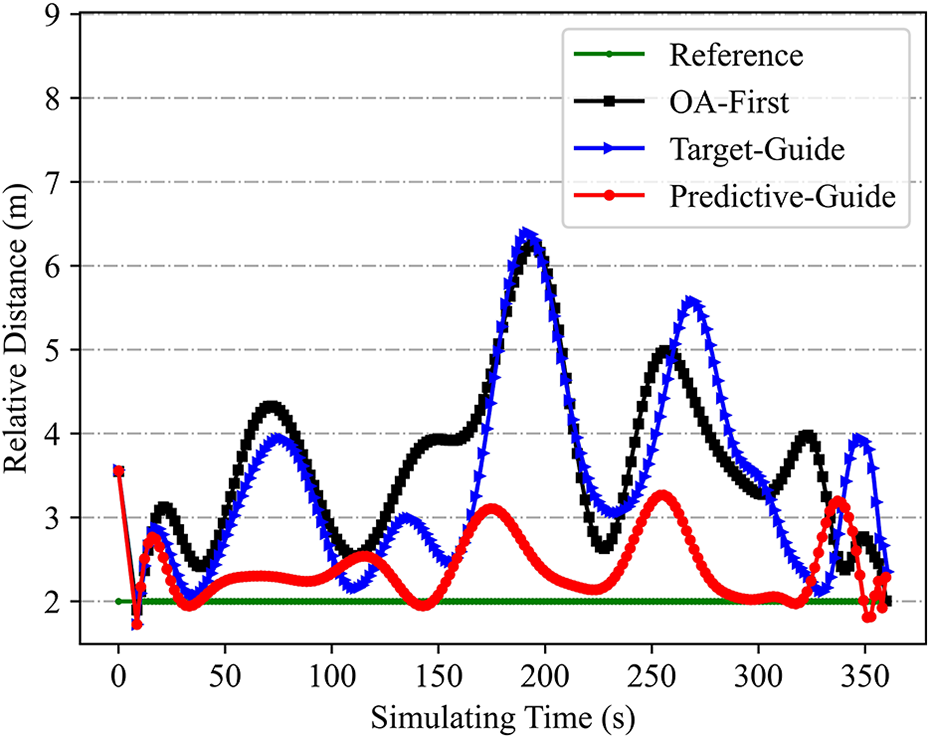
Astronaut–robot distances for the three following strategies. The astronaut walks with a constant speed of 0.25 m s−1 and the reference following distance is set as 2.0 m.
Influence of speed ratios
Intuitively, robots traveling at higher speeds can more easily approach a walking astronaut in an obstructed environment. In this section, the ratio of the robot’s speed to the astronaut’s walking speed is quantitatively investigated as a crucial factor affecting following distance stability. Figure 14 depicts astronaut following test results for various speed ratios. As the speed ratio decreased, the average astronaut–robot distance increased significantly. It was also difficult for the robot to maintain a stable relative distance when the speed ratio decreased to 1.4. In this case, both the target-guide and predictive-guide strategies produced maximum distance values exceeding 7.0 m. In addition, the OA-first simulation terminated after 200s, as the astronaut–robot distance had diverged beyond the navigator’s trained coverage. In summary, higher robot speeds provide improved stability for astronaut following. Figure 14(b) demonstrates that faster moving speeds can also reduce cumulative mileage during the following process, as the robot avoids obstacles and follows the astronaut more efficiently. Furthermore, mean deviation
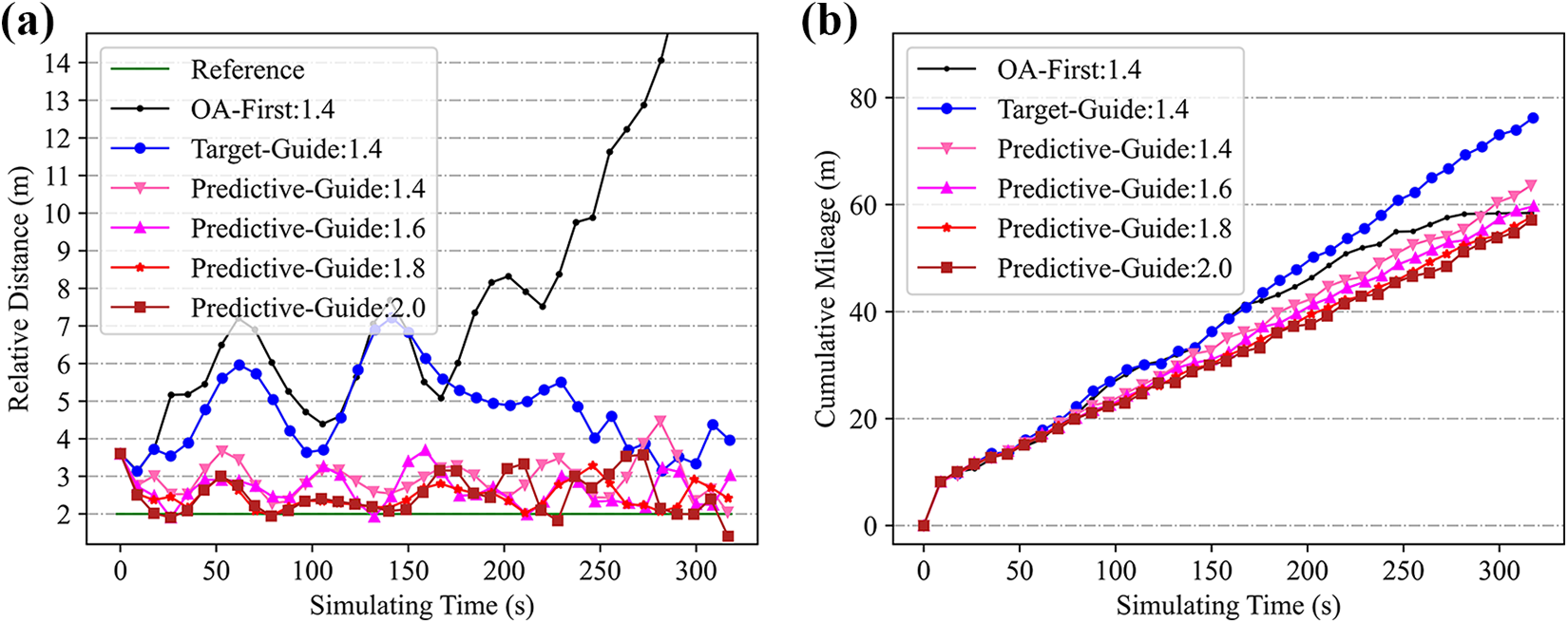
The influence of speed ratio of the robot’s speed to the astronaut’s walking speed. The astronaut walks with a constant speed of 0.25 m s−1 and the reference following distance is set as 2.0 m: (a) astronaut–robot distance and (b) cumulative robot mileage.
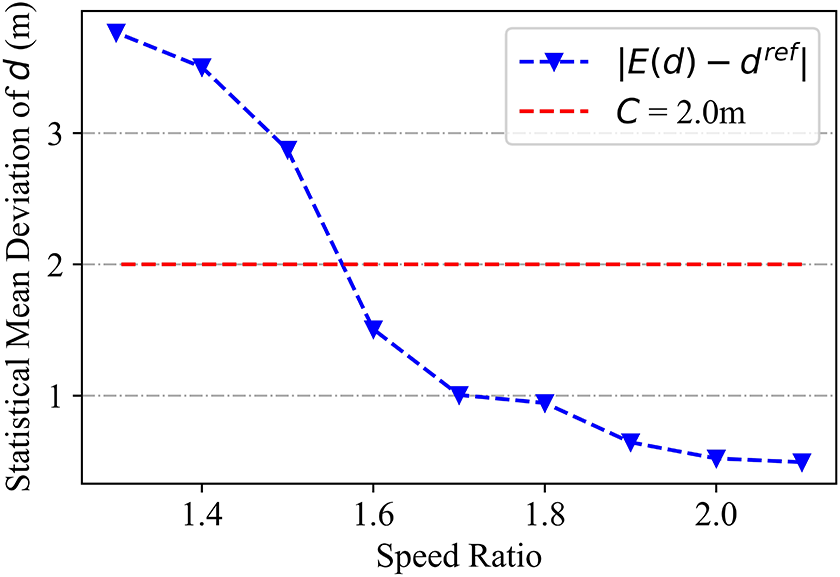
Statistical analysis of astronaut–robot distance over speed ratios. C = 2.0 indicates a classical threshold for a stable following distance.
Experimental results and discussion
The performance of the proposed method is evaluated through real-world comparative experiments. As shown in Figure 16, we conducted field tests using the developed robotic follower and an analog astronaut at a Mars-like site in Huzhou, China, in February 2022. A ZED 2 camera 28 was installed in front of the robot to detect the astronaut and collect depth information from obstacles. An efficient DCNN-based human detection algorithm 26 was adopted to locate the astronaut and estimate the walking trajectory. The following strategies and the astronaut detection module were run by an onboard NVIDIA Jetson TX2 controller. 29 In addition, an ultra-wideband (UWB) location system was employed to accurately record the trajectories of the astronaut and the robot, as well as the position of obstacles, but only for the purpose of obtaining quantitative experimental results.

The experimental scenario at a Mars-like site. The robot running the predictive-guide strategy tries to follow the analog astronaut walking along a winding path with rocks and slopes. The UWB tags are installed onside the astronaut’s helmet and robot’s electrical box to record the trajectories. UWB: ultra-wideband.
Three following strategies were tested comparatively, namely the OA-first strategy, the target-guide strategy, as well as the predictive-guide strategy. In each test, the analog astronaut was instructed to walk along a winding path with rocks and slopes, at an average speed of 0.25 m s−1. And the robotic follower was set to move at a maximum speed of approximately 0.5 m s−1, with a control period of 1.0s. The trajectories of the astronaut and the robot, as well as the following distances by the three algorithms, were plotted in Figures 17 and 18, respectively. Interesting and obvious conclusions can be drawn as follows: Rocks and slopes may interfere the following motion of the robot, resulting in a temporary increase in the astronaut–robot distance, as illustrated in Figure 18, at about 20s and 70s. The OA-first strategy has a poor coordination ability in target following and obstacle avoiding, resulting in irreversible divergence of the following distance, hence missing the astronauts after finishing the climbing the slope; while by the target-guide strategy or the predictive-guide strategy, the robot can timely respond to and continuously follow the astronaut. In case of the narrow passage that only the astronaut can pass, the robot can autonomously choose the side with smaller obstacles to go and resume following afterward. The predictive-guide strategy performs best in preventing the interference of obstacles, maintaining the variation of following distance within 1.3 m. That is to say, the method enables more stably astronaut following in the presence of obstacles, which is optimized by predictive calculations.
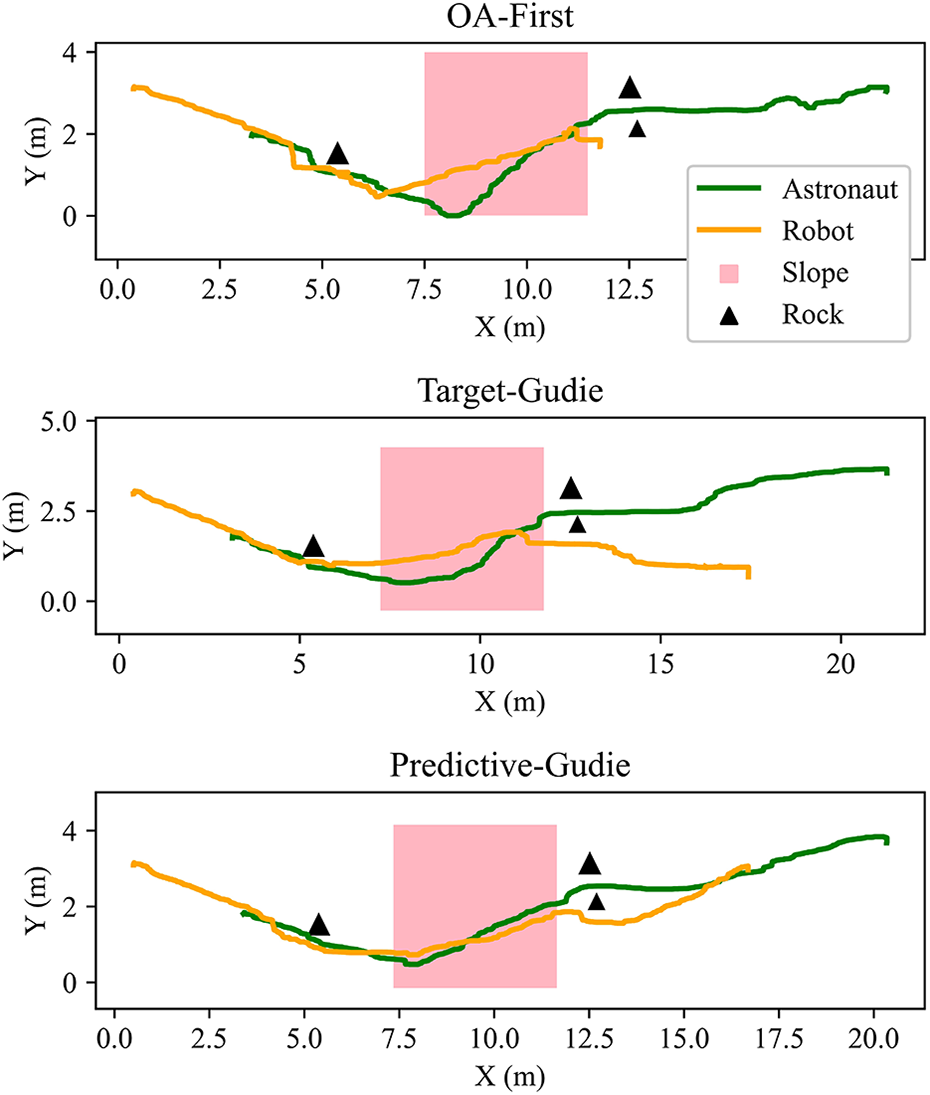
Trajectories of the analog astronaut and the robot by the three following strategies.
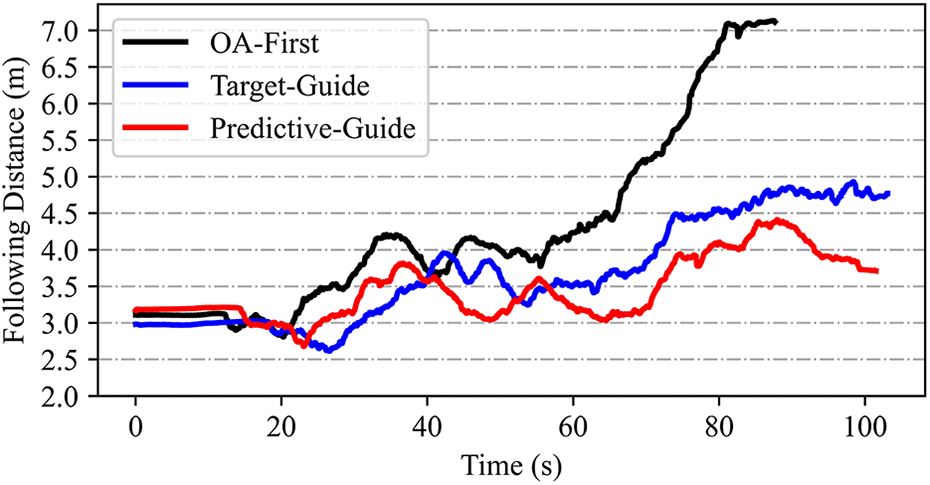
Following distances by the three following strategies.
Conclusion
In this study, a novel astronaut following strategy was proposed for extraterrestrial assistant robots, enabling the prediction of movements to avoid obstacles without requiring dynamic modeling or global path planning. The framework is provided with local depth sensor data and predictive-guide information regarding the astronaut, which improves foresightedness and adaptability. Although trained in a relatively simple simulated environment, the method is well generalized to unknown scenarios in both simulations and the real world. A comparative numerical analysis showed the proposed predictive-guide strategy managed to stabilize variations in following distance to within ±1.0 m in obstructed environments significantly outperforming other techniques. A physical robotic follower was also designed and constructed, which verified not only the effectiveness of the predictive-guide algorithm but also the practicality of the integrated system. This work represents a significant step in improving astronaut–robot cooperation during EVAs and could also be applied to social robotics.
In future work, recent DRL algorithms for continuous action space will be studied to achieve more delicate control of the robotic follower, which could improve the smoothness of the following process. In addition, the presented experiments were conducted on paved ground, and the performance of our following strategy for robotic followers needs to be further investigated on rugged terrain.
Footnotes
Appendix 1
Acknowledgments
The authors would like to thank Dr Lin Zhang of University of Cincinnati for giving some general advice on English writing of this article. The authors would also like to thank Huzhou Institute of Zhejiang University for funding this research.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Huzhou Institute of Zhejiang University under the Huzhou Distinguished Scholar Program (ZJIHI—KY0016).