
Abstract
Recently, the learning-based LiDAR odometry has obtained robust estimation results in the field of mobile robot localization, but most of them are constructed based on the idea of supervised learning. In the network training stage, these supervised learning-based methods rely heavily on real pose labels, which is defective in practical applications. Different from these methods, a novel self-supervised LiDAR odometry, namely SSLO, is proposed in this article. The proposed SSLO only uses unlabeled point cloud data to train the three-view pose network to complete the robot localization task. Specifically, first, due to the sparseness and disorder of the original LiDAR point cloud, it is difficult to use deep convolutional neural networks for feature extraction. In this article, the spherical projection of the point cloud is used to convert the original point cloud into a regular vertex map. Then the vertex map obtained by the projection is used as the input of the neural network. Second, in the network training phase, SSLO uses multiple geometric losses for different situations of matching point clouds and introduces uncertainty weights when calculating the losses to reduce the interference of noise or moving objects in the scene. Last but not least, the proposed method is not only used in the simulation experiments based on the KITTI dataset and Apollo-SouthBay dataset but also applied to a real-world wheeled robot SLAM task. Extensive experimental results show that the proposed method has good performance in different environments.
Introduction
Estimating the self-motion of mobile robots is an important prerequisite for robotic autonomous exploration. With the development of autonomous driving, the real-time locating and path planning of mobile robots are receiving increasing attention and research. In outdoor environments, people can usually apply a global positioning system (GPS) to locate the robot. However, in some special environments, such as long tunnels, dense high-rise buildings, and forests, GPS cannot continuously and stably complete reliable positioning tasks. In this case, the robot needs to use its onboard sensors to estimate its pose. LiDAR has high resolution and a strong interference ability and is not affected by light, and with the accumulation and innovation of optical technology, the LiDAR size, weight, and price are decreasing. Another important advantage of LiDAR is to directly obtain the depth of the object in the environment, which overcomes the monocular camera scale uncertainty, so using LiDAR to complete robot motion estimation has become increasingly popular.
Among the available methods of using LiDAR for estimating the robot position, the most common method is based on iterative matching. The iterative closest point (ICP) and its variant 1 solve the best relative translation and rotation between two poses by minimizing the distance of the closest point in the continuous LiDAR scans. However, the ICP method is sensitive to the initial value. A good matching result requires a relatively accurate initial estimate. At the same time, to maintain the real-time operation of the system, the original point cloud data need to be down-sampled when performing ICP, which can destroy the original physical structure of objects, and result in points on objects in one frame missing their spatial correspondence in the next frame. Another approach is the feature-based method. 2 Feature-based methods are less sensitive to the scanning quality and more powerful; however, they are generally more computationally expensive. Notably, they are sensitive to dynamic objects in the scene. These shortcomings hinder the application of feature-based matching methods to odometries.
Recently, visual odometry (VO) 3 –6 based on deep learning has achieved superior results over classical VO in some three-dimensional tasks. These methods provide new solutions for robot pose estimation tasks using point cloud data. The point cloud data captured from distance sensors are sparse and irregular, and it is difficult to directly perform a 6-DOF pose regression using traditional convolutional neural networks (CNNs). To compute the pose of the robot, such as with deep VO, Li et al. 7 projected the original 3D point clouds into 2D images and performed pose estimation with a neural network. Li et al. 8 take monocular images and point cloud projection images as the input and design an end-to-end odometry network to fuse two kinds of input data to generate pose estimation in a learning manner. Furthermore, most of the proposed deep LiDAR odometries are constructed in supervised learning ways, and the accuracy of these methods relies heavily on large-scale annotated training data, which is not always feasible in practice because large-scale labeling is quite expensive, which limits the scope of application of such methods. How to use unlabeled data to design depth LiDAR odometry is still a problem that needs to be solved urgently.
To avoid the time-consuming labeling process, we propose a novel self-supervised learning odometry. This method only needs unlabeled data to complete the learning of neural network and the positioning task of robot. The method proposed in this article takes the vertex map obtained by point cloud spherical projection as the input, which can preserve the spatial structure of objects in the environment as much as possible and alleviate the problem that disordered and sparse point clouds have difficulty using neural networks for feature extraction. Because the premise that a SLAM system can run is that the observed environment is static and there are no dynamic objects. If there are dynamic objects in the scene, the SLAM assumptions will be broken, which will lead to poor positioning accuracy or even failure of the SLAM algorithm. However, in actual applications, dynamic objects generally exist in the environment. So, it is necessary to minimize the impact of dynamic objects when constructing the SLAM system, which helps to improve the positioning accuracy of the system. To reduce the interference of noise and dynamic objects, weighted point-to-point, weighted point-to-plane, and weighted plane-to-plane losses are used in the training phase to constrain different point cloud correspondences in continuous scanning frames. It forces neural network to pay more attention to the static features of the environment and ignore the dynamic and unstable features. Figure 1 shows the KITTI sequence 07 trajectory map estimated after network training without the ground truth pose. The point cloud is colored according to the time stamp, and the color transitions from blue to green as time increases. The figure shows that the method in this article successfully captures the motion trajectory of the mobile robot.
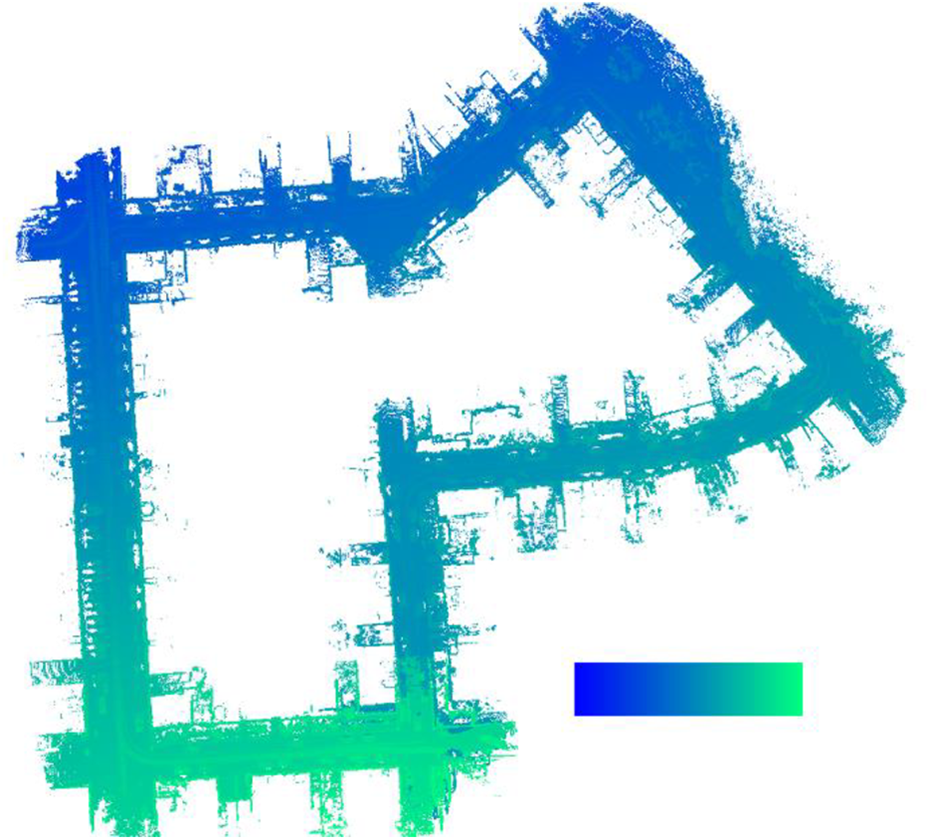
Point cloud map estimated using LiDAR odometry.
The main contributions of the method in this article are as follows:
This article proposes a LiDAR odometry framework based on self-supervised learning, which takes the vertex map generated by the point cloud as the input to predict the ego-motion of LiDAR.
A simple and fast method to calculate the point weights is proposed, which is combined with the self-supervised loss function to better address the problems of noise and dynamic objects in the environment.
The method in this article is experimentally verified on the KITTI dataset, Apollo-SouthBay dataset, and real-world environments and compared with the existing methods, which proves the effectiveness of the proposed method.
The remainder of this article is as follows. Traditional and learning-based LiDAR odometry works are reviewed in the second section. In the third section, the architecture and loss function of the proposed self-supervised deep LiDAR odometry are elaborated. Experimental results and comparisons with other methods are detailed in the fourth section. Finally, the conclusions and future work are discussed in the fifth section.
Related work
LiDAR-based pose estimation algorithms can be roughly divided into two categories. One category is model-based methods, such as ICP and its various variants. ICP aligns the scan and model point clouds in an iterative two-step process. In the first step, the algorithm establishes the correspondence between the two point cloud scans. The second step calculates a transformation to reduce the distance between all corresponding points and repeats these two steps with the transformed scan until a certain optimization criterion is reached. Model-based methods have been proposed in the extensive literature. LiDAR odometry and mapping (LOAM) 9 performs point-to-edge and point-to-plane scanning matching and achieves low drift and low computational complexity of the odometry through parallel high-frequency and low-frequency modules. LOAM is one of the best frameworks. Many works have been developed based on LOAM. LEGO-LOAM 10 proposes a lightweight and ground-optimized SLAM algorithm, which achieves similar accuracy with reduced computational cost. Intensity-SLAM 11 is a complete SLAM framework that combines geometric features and strength information features. Combining intensity information helps to identify the same features on multiple frames. This method uses the scan-to-global map matching method to calculate the optimal pose by minimizing geometric residuals and intensity residuals. LiTAMIN 12 uses the Frobenius norm and regularized covariance matrix to normalize the cost function to improve the computational efficiency of ICP. M-LOAM 13 is a SLAM framework that combines multiple LiDARs. It estimates the pose through online calibration optimization and convergence recognition. The experimental results show that it has a better positioning accuracy than a single LiDAR system. However, the algorithm based on LOAM needs to down-sample the point cloud data during the execution stage, which cannot accurately represent the underlying local surface structure. SUMA 14 proposes a dense LiDAR-based SLAM method to construct a Surfel-based map and estimates the transformation of the robot pose by using the projection data association between the current scan and the rendered model view from the Surfel map. However, the sparse point cloud is a challenge. Li et al. 15 proposed a mobile robot system that combines LIDAR, IMU, and GNSS data. The system performed point cloud registration on GPU, which improves computing efficiency. In addition, a hierarchical optimization structure was proposed to improve the mapping quality. Zheng and Zhu 16 used a bird’s-eye view that effectively retains the neighborhood relationship of ground surface points nearly parallel to laser beams. This method obtained better results than SUMA. Jiang et al. 17 took LiDAR and inertial measurement unit (IMU) data as the input and used the rank Kalman filter to estimate the robot’s pose, which improved the accuracy and robustness of the robot’s indoor positioning. Demim et al. 18 proposed the SVSF-SLAM algorithm, which has better robustness and accuracy. Compared with EKF-SLAM, SVSF-SLAM has the advantages of low computational complexity, high estimation accuracy, and robustness. Mosbah et al. 19 described a SLAM method based on second-order smooth variable structure filter embedded in a mobile robot. Compared with the competitors, Mosbah’s method obtained higher positioning accuracy and robustness.
Compared with model-based LiDAR odometry, the learning-based LiDAR odometry method is not perfect. As a technical solution to the robot navigation problem, it is attracting increasing research interests and shows the great potential of this approach. StickyPillars 20 is a fast and accurate point cloud registration method based on a graph convolutional network, and the registration result is better than the feature registration method based on ICP. SLOAM 21 uses semantic segmentation to detect tree trunks and the ground, separately models them, and proposes a pose optimization method based on semantic features, which achieves better results than traditional methods in a forest environment. Unlike SLOAM, Yue et al. 22 proposed a semantic SLAM system that integrated camera and LiDAR. The system obtains semantic information from image data and combines the semantic information with point clouds to complete the collaborative semantic mapping. S-ALOAM 23 integrates semantic information into the LOAM pipeline and uses point-by-point semantic labels for optimization in the dynamic point elimination stage, feature selection stage, and corresponding point searching stage. The experimental results demonstrate that this method outperforms the state-of-the-art SLAM methods. Dmlo 24 explicitly implements geometric constraints in the framework and decomposes pose estimation into two parts: a learning-based matching network to provide accurate correspondence for two scans and rigid transformation estimation using singular value decomposition, which yields comparable or better results to conventional LiDAR odometry methods. As an improved version of SUMA, SUMA++ 25 combines semantic information to constrain the projection match and thus can reliably filter moving targets in the scene and achieve the most advanced performance. These methods are all successful applications of deep learning in LiDAR odometry. However, they only use deep learning for intermediate feature extraction, and odometry estimation is still obtained through geometric transformation. Lo-net is the first learning-based end-to-end LiDAR odometry with continuous point cloud scanning as the input to directly output the relative transformation while designing a mask network to compensate for dynamic objects in the scene; thus, it eventually yields an accuracy similar to that of LOAM. Deeppco 26 designed two parallel subnetworks to estimate translation and rotation and achieved a performance comparable to traditional methods. Both Lo-net and Deeppco train the framework in a supervised learning manner, which limits their application scenarios.
In reality, obtaining the true value of the pose often takes considerable energy. How to fully use all point cloud data to train the pose network is a challenging and meaningful research. Cho et al. 27 proposed the first LiDAR odometry implemented in an unsupervised manner, introducing an uncertainty-aware loss with geometric confidence that successfully captures the relative motion of large-scale trajectories. Nubert et al. 28 proposed a self-supervised LiDAR odometry method using point-to-plane and plane-to-plane geometric loss and used Kd-Tree in the corresponding point searching strategy to search for the relationship between the source domain and the target domain in a 3D space without additional visual field loss. The experimental results show that the proposed method achieves similar accuracy to LOAM. Similar to the works of Cho and Nubert, this article is dedicated to the design of a self-supervised deep LiDAR odometry to achieve accurate pose estimation by fully utilizing all available LiDAR data while avoiding the effects of outliers and motion targets using multiple geometric consistency-weighted losses in different scenarios.
Proposed approach
In this section, the proposed method is described in detail. First, the pose estimation problem is modeled; second, this article uses the same projection function
Problem statement
The problem of estimating the robot pose transformation

The key to modeling is to solve the probability density function p. The traditional method converts the probability problem into a least square problem and uses an iterative method to solve it. This article uses a deep neural network to model the pose estimation problem, that is,
Input projection
The point cloud obtained from the LiDAR is usually represented by the Cartesian coordinate system. To convert the original sparse and irregular point cloud into a data format that can be conveniently processed by the CNN, this article uses efficient and dense point cloud spherical projection to project the point cloud data P into a regular vertex map

where w and h are the width and height, respectively, of the vertex map V generated by the projection,

Point cloud spherical projection. (a) Raw point clouds from LiDAR; (b) the corresponding vertex map.
Normal calculation
To strengthen the geometric consistency during the training phase, the normal map N comprising the normal vectors ni
corresponding to the vertices vi
in the vertex map V is used when calculating the self-supervised loss. Since the calculation of the normal vector requires additional time overhead and the participation of the normal vector is not required during the inference period, unlike Chao et al.
27
, this article estimates the normal mapNcorresponding to the vertex map V offline before network training. Given a point vi
in the vertex map and k neighboring points


where Normal data encoding.


Network architecture
The proposed network consists of two parts: a feature extraction network (Feature Net) and a 6-DOF pose regression network (Pose Net). Feature Net encodes the input frame and extracts the features. Pose Net decodes the input feature vectors to estimate the relative motion between the input frames. During training, Kd-tree is used to find the target correspondence in the three-dimensional space; then, the geometric loss is calculated and back-propagated to the network. As shown in Figure 4, Feature Net consists of a convolutional layer, a maximum pooling layer followed by eight residual blocks and an adaptive average pooling layer. The input of Feature Net is the vertex maps obtained by the projection of the adjacent LiDAR point cloud scans, which goes through the last residual block to output feature maps with a size of

Schematic diagram of the proposed network.
Layers of the network architecture.

Loss function
The design of the loss function significantly affects the stability and accuracy of the entire network. Cho et al.
27
used projection data associations to search for correspondence points, but the method was unstable. In this regard, the author increased the FOV loss to prevent divergence training away from the FOV state, thus enabling stable training of the whole network. Unlike the above losses, inspired by model-based approaches
14
and similar to a previous study,
28
this article combines multiple weighted geometric losses to measure the difference between the target scan and the source scan mapped to the target space. Assuming that each sequence contains
For a point vs
in the source scan Vs
, this article directly establishes a KD-Tree in three-dimensional space to find its corresponding point in the target scan. As shown in Figure 4, the points vs
and ns
in the source domains Vs
and Ns
are projected to the target domain according to the transformation matrix T estimated by Pose Net to obtain

After searching for nk
matching pairs
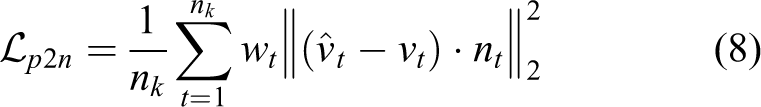
In extreme cases, the nearest point searching strategy will have an incorrect match. As shown in Figure 5, the green five-pointed star is the position of the LiDAR, the pink line and blue line are the two scans of the LiDAR at different positions, and the dashed ellipse represents the approximate plane where the black point is located. In this case, the closest points found by KD-Tree will have incorrect associations because their surface directions are inconsistent, so the plane-to-plane loss in the loss function will be increased to compare with the surface directions of the paired points to reduce the impact of these matches. Extreme situations may exist in the closest point search.
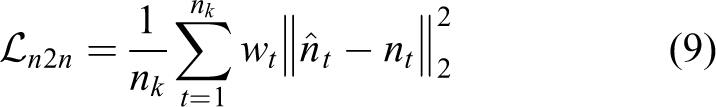
To make full use of all available points, this article calculates the point-to-point loss of each matching pair
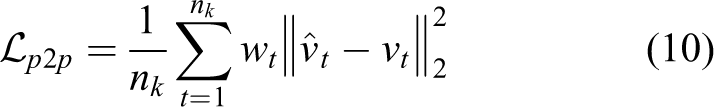
In short, the self-supervised weighted geometric loss is

Experimental results
In this section, the implementation details and experimental results of SSLO are introduced. The system configuration of the network in the training phase is introduced in detail; then, the system performance is evaluated and compared with the existing self-motion estimation methods. The KITTI dataset, which is the one most widely used in autonomous driving, was used for benchmark testing. To evaluate the stability of the proposed network, the Apollo-SouthBay dataset was used to verify its multi-environmental adaptability.
Implementation details
The proposed network is constructed using the public PyTorch framework and trained using NVIDIA GTX1080Ti with the Adam solver in the training phase, where
Benchmark dataset
The KITTI odometry dataset is one of the most widely used datasets to evaluate odometry/SLAM algorithms. It consists of 22 independent suburban, highway, or urban driving sequences, and each sequence includes stereo grayscale and color camera images, point cloud data captured by LiDAR sensors, and calibration files. The point cloud data were collected with Velodyne HDL-64 at a sampling frequency of 10 Hz. Among these 22 sequences, only sequence 00-10 provides the ground truth pose obtained from the IMU/GPS fusion algorithm, while sequence 11-21 does not provide the ground truth pose for benchmarking.
The Apollo-SouthBay dataset contains six southern routes in San Francisco Bay area and covers various scenarios, including residential areas, urban areas, and highways. The dataset contains LiDAR scans, post-processed ground truth poses, and poses from the GNSS/IMU integration solution. Similar to the KITTI odometry dataset, this dataset uses Velodyne HDL-64 for point cloud data collection. The Apollo dataset sequence is longer than the KITTI sequence, the scenario is more complex, and it is more challenging to test the algorithm.
Experimental results
Evaluation on the KITTI dataset
The network was trained and evaluated on the KITTI dataset using the same training set/test set division strategy as other learning-based LiDAR odometries
27,28
; that is, sequences 00-08 were used as the training set, and sequences 09 and 10 were used as the test set to verify the network performance. To quantitatively evaluate the accuracy of pose estimation, the evaluation criteria provided by the KITTI benchmark are used in this article to calculate the average translation
KITTI odometry evaluation: Comparison of the average translation and rotation errors of all possible lengths between 100 m and 800 m.

Figure 6 shows the trajectory estimated by the method in this article on the KITTI dataset. From left to right and top to bottom are sequences 01, 07, 09, and 10 of KITTI. In this figure, the orange line is the ground truth value of the pose, and the blue line is the estimated value of the pose output by the network. The figure shows that the method in this article has a higher estimation accuracy for the rotation angle between adjacent frames, but the translation vector estimate has worse accuracy than the rotation angle estimation. SSLO has good estimation performance in different environments, especially in sequences that are not observed during training, but it can still maintain high accuracy.
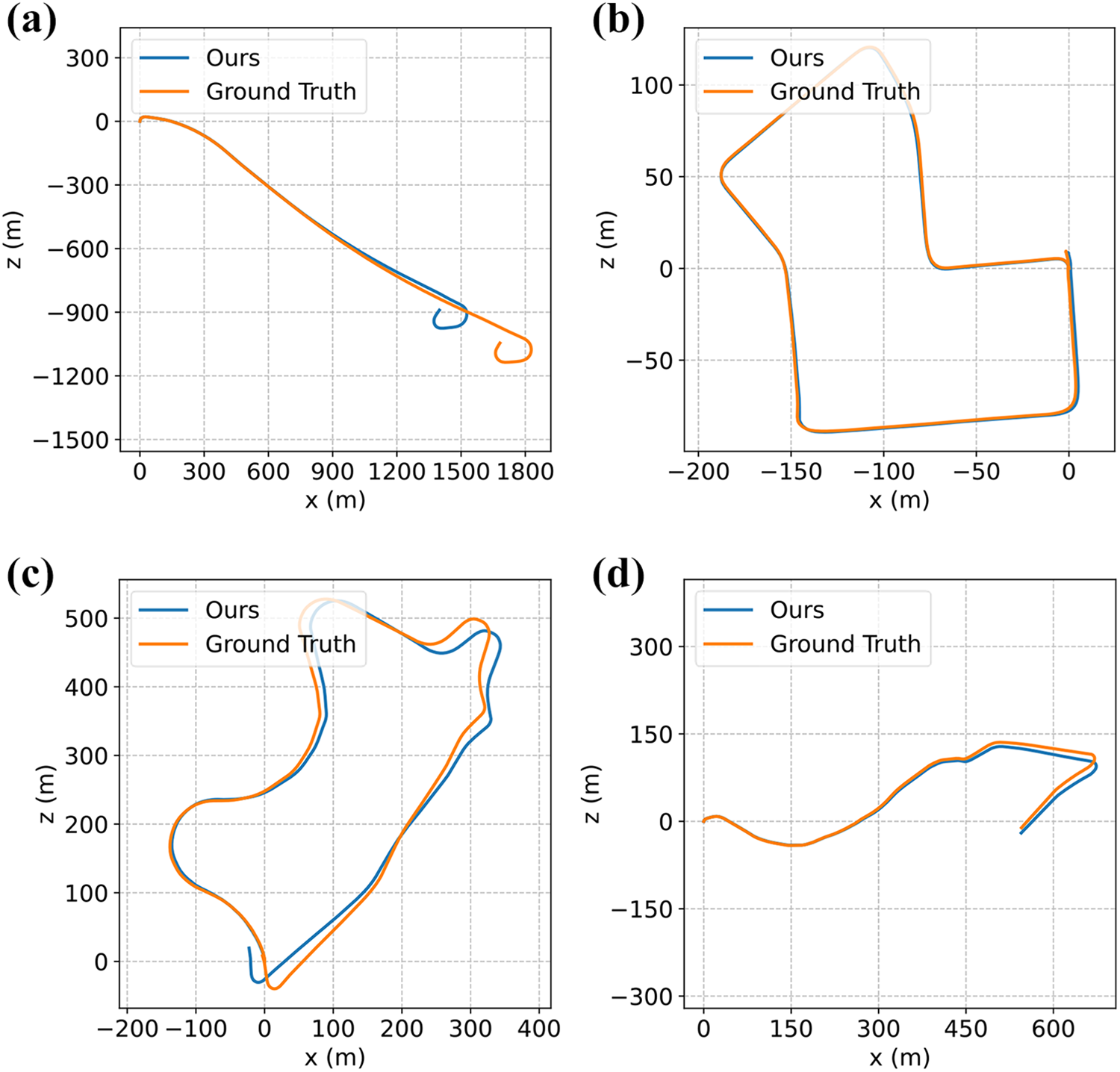
Trajectories of different sequences on the KITTI dataset. (a) Qualitative result on KITTI sequence 01; (b) qualitative result on KITTI sequence 07; (c) qualitative result on KITTI sequence 09; (d) qualitative result on KITTI sequence 10.
To carefully observe the performance of the proposed model, Figure 7 plots the error curve of the estimated pose on each degree of freedom on KITTI sequence 09 over time. Figure 7(a) shows the translation error along x, y, and z. Figure 7(b) shows the rotation error of the yaw angle, pitch angle, and roll angle. The maximum translation error in each coordinate axis direction is approximately
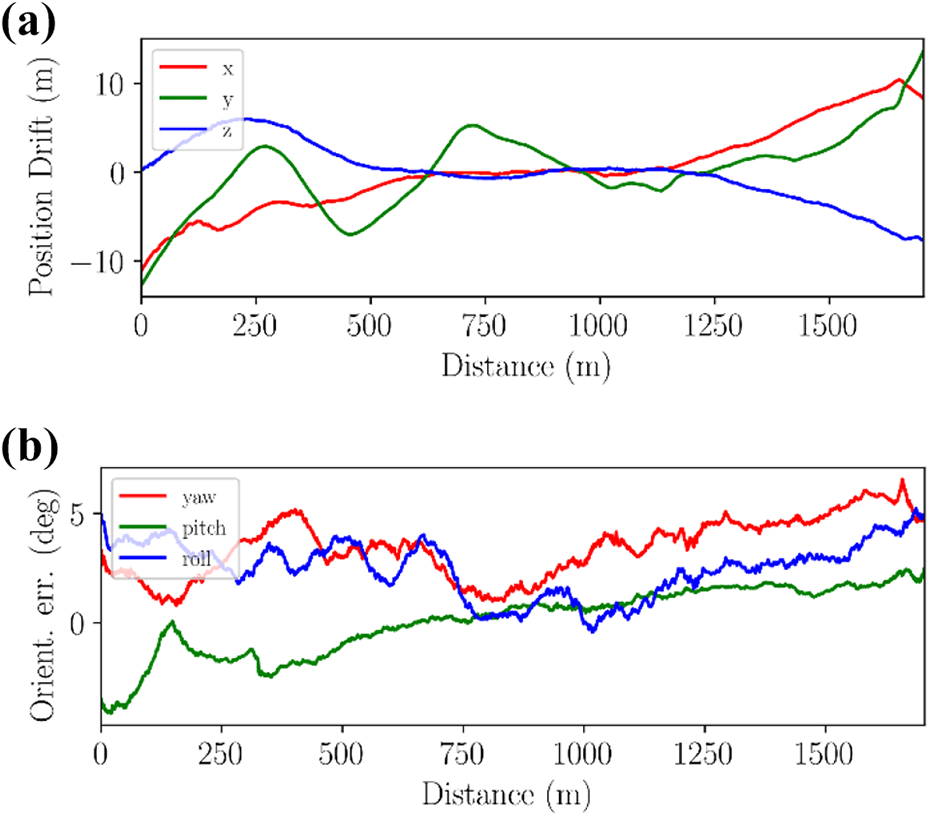
Translation and rotation errors. (a) Translation error of KITTI sequence 09; (b) rotation error of KITTI sequence 09. Evaluation on the Apollo-SouthBay dataset
Evaluation on the Apollo-SouthBay dataset
To verify the versatility of the method in this article, experiments were conducted on the San Jose Downtown sequence of the Apollo-SouthBay dataset and compared with the results of the pose estimation using the point-plane ICP algorithm in Open3d. The test trajectory is shown in Figure 8. The blue line in this figure is the method in this article, the purple line is ICP, and the orange line is the ground truth. When we evaluate the performance of the odometry, the translation and rotation errors obtained using the evaluation criteria provided by the KITTI benchmark are shown in Table 3. The comparison results show that the method in this article is better than traditional point-plane ICP. Point-plane ICP obtains very poor estimation results in a scene with many moving objects; in particular, the estimation of translation cannot follow the change of the real pose. In contrast, the method in this article has obtained better average translation accuracy and angle accuracy.

Trajectories of the test set on the San Jose Downtown sequence.
San Jose Downtown evaluation using the evaluation criteria provided by the KITTI.

ICP: iterative closest point.
Evaluation on a real-world SLAM task
This article uses a mobile robot equipped with LiDAR to perform algorithm testing in the real world. The robot is equipped with a Robosense RS-LiDAR-16 LiDAR to obtain point cloud data. To meet the algorithm requirements, the robot is also equipped with a laptop as an upper computer, which is equipped with Intel i7-10750 H CPU, NVIDIA RTX2070MQ GPU, and 8 GB memory. The LiDAR and mobile robot are shown in Figure 9.

Mobile robot platform. (a) RS-LiDAR-16 LiDAR; (b) mobile robot.
As shown in Figures 9 and 10, the mobile robot is used for indoor and outdoor experimental verification. Since the 16-line LiDAR used in the experiment is different from the 64-line LiDAR in the KITTI and Apollo-SouthBay dataset, the network weights need to be retrained when verifying the performance of proposed SSLO method. Due to the idea of self-supervised learning, we can easily complete the retraining of the odometry network. In the retraining phase, we collect the LiDAR point cloud recorded during the robot running indoors and outdoors, and then project the point cloud into a vertex map as the input of SSLO according to formula (2) in section “Input projection,” and refine the neural network weights trained by the KITTI dataset. After network retraining, we conduct actual experiments in an unfamiliar environment that the robot has never reached before.

Photos of (a) indoor laboratory and (b) outdoor academic building environment.
In the indoor actual verification, we controlled the robot to take a closed-loop path. From the estimated trajectory in Figure 11(a), it can be seen that the proposed method can achieve accurate robot localization. The estimated positions at the beginning and the end basically coincide, but the point-to-plane ICP method introduces large errors, resulting in low positioning accuracy, and unable to obtain a closed path estimation. It can be seen more clearly from the point cloud map in Figure 12 that the laboratory map established by the ICP method has a larger deviation. For example, in the upper right corner of Figure 12(b), there is a serious mapping deviation at the corner of the room. While, the right angle of the room in the upper right corner of Figure 12(a) is clearly visible. This shows that in the indoor SLAM task, the proposed method is obviously superior to the ICP method and has higher positioning accuracy.

Prediction trajectories of (a) indoor laboratory and (b) outdoor academic building.

The indoor point cloud maps constructed by (a) our method and (b) ICP method. ICP: iterative closest point.
In the outdoor verification experiment, we controlled the robot to walk around the academic building. The trajectories estimated by SSLO and ICP method are shown in Figure 11(b), from which, it can be found that the trajectory estimated by ICP cannot return to the initial position correctly, while the proposed method can complete the robot positioning task with higher accuracy. The environment maps constructed according to the pose obtained by the proposed SSLO method and the ICP method are shown in Figure 13. From Figure 13(a) and (b), it can be indicated that the environment map based on the ICP method has a large dislocation, which causes the academic building map unable to be closed, while the proposed SSLO method can get an accurate map of the environment.

The outdoor point cloud maps constructed by (a) our method and (b) ICP method. ICP: iterative closest point.
Ablation study
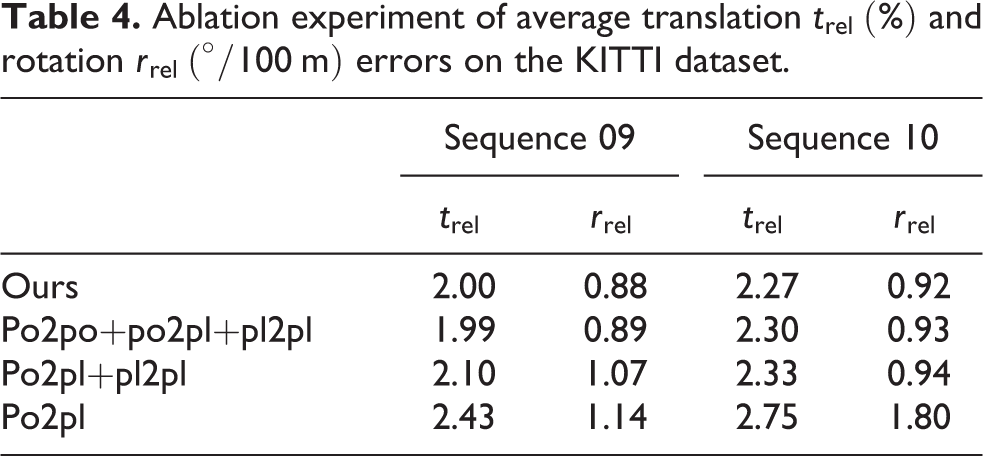
In this section, to verify the effectiveness of the proposed multiple weighted geometric loss, the network is retrained by combining different loss functions and subsequently tested on the same test sequence. The results are shown in Table 4. The results of combining multiple weighted geometric loss functions are better than those of any single method.
Ablation experiment of average translation
Runtime
In the robot pose estimation process, the real-time performance of the algorithm is an important indicator. Commonly used LiDARs, such as the Velodyne HDL-64 LiDAR used in the KITTI and Apollo-SouthBay datasets, are set to 10 Hz, which means that one frame of scan data is output every 0.1 s. Therefore, real-time performance in this case means that the processing time of each data point is less than 0.1 s. Tested on a desktop computer equipped with Intel Xeon(R) CPU E5-2603V2 and NVIDIA GTX1080Ti GPU, the average data processing time per frame is 24 ms on CPU, and the inference time is 27 ms on GPU. The total pose estimation time of adjacent frames is 51 ms, which is less than 0.1 s and thus satisfies the real-time requirements of the algorithm.
Conclusions
This article presents an end-to-end self-supervised LiDAR odometry network for estimating the 6-DOF poses of a robot that does not require any data with pose labels to complete the training of the network. Geometric loss is used to learn domain-specific features during network training. The proposed method was validated on a public benchmark dataset and compared with other learning-based methods, and the method in this article showed excellent performance. The analysis shows that the learning-based method can overcome some of the shortcomings of the model-based method, but the accuracy cannot surpass that of the traditional LiDAR odometry method, and further research is required. In future work, we plan to add a long short-term memory model to the network to use time information and merge it with IMU data to build a multimodal end-to-end odometry framework.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by The National Natural Science Foundation of China (Grant No. 61803227, 61973184, 61773242), National Key Research and Development Plan of China (2020AAA0108903), Independent Innovation Foundation of Shandong University (Grant No. 2018ZQXM005), Young Scholars Program of Shandong University, Weihai (Grant No. 20820211010).