
Abstract
With economic growth, automobiles have become an irreplaceable means of transportation and travel. Tires are important parts of automobiles, and their wear causes a large number of traffic accidents. Therefore, predicting tire life has become one of the key factors determining vehicle safety. This paper presents a tire life prediction method based on image processing and machine learning. We first build an original image database as the initial sample. Since there are usually only a few sample image libraries in engineering practice, we propose a new image feature extraction and expression method that shows excellent performance for a small sample database. We extract the texture features of the tire image by using the gray-gradient co-occurrence matrix (GGCM) and the Gauss-Markov random field (GMRF), and classify the extracted features by using the K-nearest neighbor (KNN) classifier. We then conduct experiments and predict the wear life of automobile tires. The experimental results are estimated by using the mean average precision (MAP) and confusion matrix as evaluation criteria. Finally, we verify the effectiveness and accuracy of the proposed method for predicting tire life. The obtained results are expected to be used for real-time prediction of tire life, thereby reducing tire-related traffic accidents.
Keywords
Introduction
With the development of the automotive industry, vehicles have gradually become the main means of transportation for most people. Therefore, safe driving of vehicles has also become a focus issue. At present, more than half of traffic accidents on highways are caused by tire wear problems, many of which are caused by punctured tires. The main causes of tire perforation are severe surface wear and abnormal tire pressure, which is most likely to occur in the case of high-speed driving or sudden braking. As a main component of cars, tires have a great impact on the performance of vehicles when they are running. 1 Therefore, the detection of tires can effectively improve the safety of vehicles.
In the past few years, manual inspection has been the main technique used to detect the degree of tire wear. A mainstream method is to define the degree of tread pattern wear by detecting the tread depth and the pattern wear of the shoulder, which combines a mathematical model of the tire and local friction and determines the tire wear rule through experiments.2–5 Another common method is to implant a radio frequency identification (RFID) chip into the tire. Signals from the RFID chip are read by the RFID reader to predict tire wear.6,7 In addition, the tire model established by finite element method is also often used to simulate abnormal tire wear.8–10
However, these methods are too expensive to use in a family car. Additionally, technicians need to manually inspect each tire of the vehicle, so the efficiency is not high. In this paper, we use image processing and machine learning techniques to solve this problem. We train the prediction model and use it in tire life experiments, and then select the appropriate evaluation criteria to judge the accuracy of the prediction model. The flow chart of the method is shown in Figure 1.

Flow chart of the method.
We build a mathematical model of tire wear and mileage, and train the model to predict the life of tire samples. The main steps are as follows.
We build an image library of automobile tire pattern wear and screen tire tread patterns from three brands commonly found in the market. According to the mileage actually used, we divide tires into five categories.
We use appropriate image preprocessing methods to process the completed samples, including normalization, grayscale, median filtering, and histogram equalization, to generate an input sample of the prediction model.
We apply the GGCM and GMRF 11 to extract the wear texture features of the input samples.
We employ the KNN 12 classifier cross-validation method to determine the K value and distance formula of the classifier. Then, we build a mapping model of feature vectors and input sample output categories as the life prediction model of this method.
We utilize test samples to verify the performance of the life prediction model. Herein, we use the MAP and confusion matrix as the evaluation methods for the evaluation results.
The remainder of this paper is organized as follows: in Sect. 2, we introduce the theoretical method of the predictive model of this paper. In Sect. 3, we introduce the main influencing factors of the model and conduct experimental verification of the model. In Sect. 4, we give the experimental results and select appropriate evaluation indicators to evaluate the experimental results. Finally, we conclude the paper in Sect. 5.
Theoretical approach
In this section, we introduce the theory of building predictive models. According to the collected image database of car tire pattern wear, we use image pattern extraction technology to quantify tire patterns with different wear levels to obtain corresponding wear feature vectors. Then, we apply machine learning techniques to build a mathematical model relating the wear feature vectors and the degree of wear.
Image library of automobile tire pattern wear
Referring to the relevant literature, we find that the situation of tire tread wear can be divided into four categories: no wear, light wear, moderate wear, and heavy wear, as shown in Figure 2. In addition, we try to make sure that the same light source and angle are used in the same settings when we take the tire image. After filtering the collected images, the images that do not meet the requirements are deleted, and finally the experimental image library is obtained.

Tire wear classification chart.
Due to the wide variety of tire brands and patterns in the market, data collection is affected by diverse natural environments and human factors, resulting in an imbalance of data samples. When collecting images, we exclude tires that are damaged due to abnormal use. Meanwhile, we also consider the influence of tire pressure on the data acquisition. We select cars whose tire pressure within the normal using range (2.5 ± 0.3 bar) for sampling. The four tire pressure errors of cars are also within the allowable range (less than 0.1 bar). According to the survey, most of the samples with mileage less than 30,000 km correspond to new cars, while those with more than 60,000 km have been replaced. The new and old tire samples cause large differences in the samples and have a certain impact. Therefore, after multiple screenings, we use the tire tread patterns of three brands common in the market as research objects and divide them into five categories in equal proportions, as show in Figure 3.
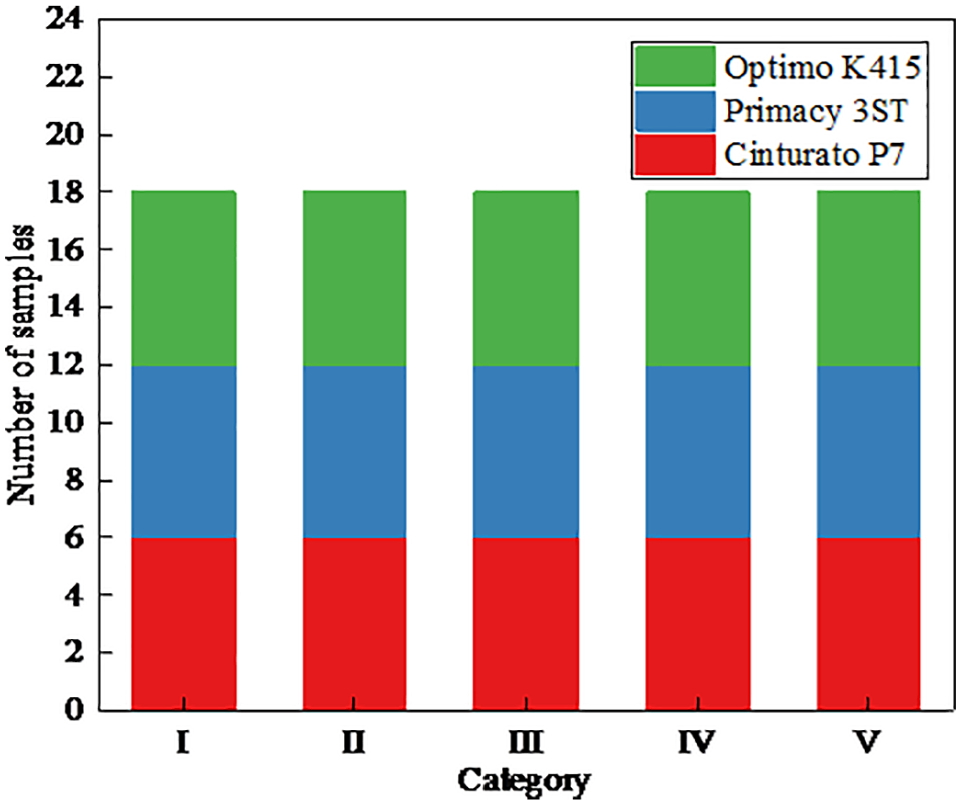
Sample classification map.
We measure tire wear based on their mileage and use that as a classification criterion. The range of the first category of tire is 30,000 to 35,000 km, the second category is 35,000 to 40,000 km, the third category is 40,000 to 45,000 km, the fourth category is 45,000 to 50,000 km, and the fifth type is 50,000 to 60,000 km. The results are shown in Figure 4.

Classification of tire wear.
To determine whether it makes sense to analyze the three different types of tires, we perform a cluster analysis. As the texture features are high-dimensional, we reduce the dimensions and visualize them. Herein, we use t-distributed stochastic neighbor embedding (t-SNE) 13 to reduce the dimensions and visualize the data, as shown in Figure 5.

Tire cluster diagram.
Figure 5 shows that there is an association for the same type of tires (points with the same color in the figure) and that different types of tires (points with different colors in the figure) are different from each other. We can also demonstrate that it makes sense to conduct research on various tire types together.
Image preprocessing
Since the collected original pattern library does not meet the experimental requirements, it is necessary to choose a suitable preprocessing method. We collect the sample images and build a sample library for the experiments. Then, scale normalization and grayscale preprocessing are performed on the collected original images, as shown in Figure 6.
Scale normalization: the original sample size is normalized, and the size is unified to 256 × 256 pixels to ensure the balance of the sample.
Grayscale: the original image is in RGB three-channel mode, and replacing it with a grayscale image can reduce the calculation speed and complexity of feature extraction.
Median filtering: 14 this preprocessing is used to reduce noise caused by the natural environment and human factors during shooting.
Histogram equalization: 15 this preprocessing is used to enhance the contrast of the image, make the gray values of the image evenly distributed, and reduce the influence of uneven illumination during shooting.
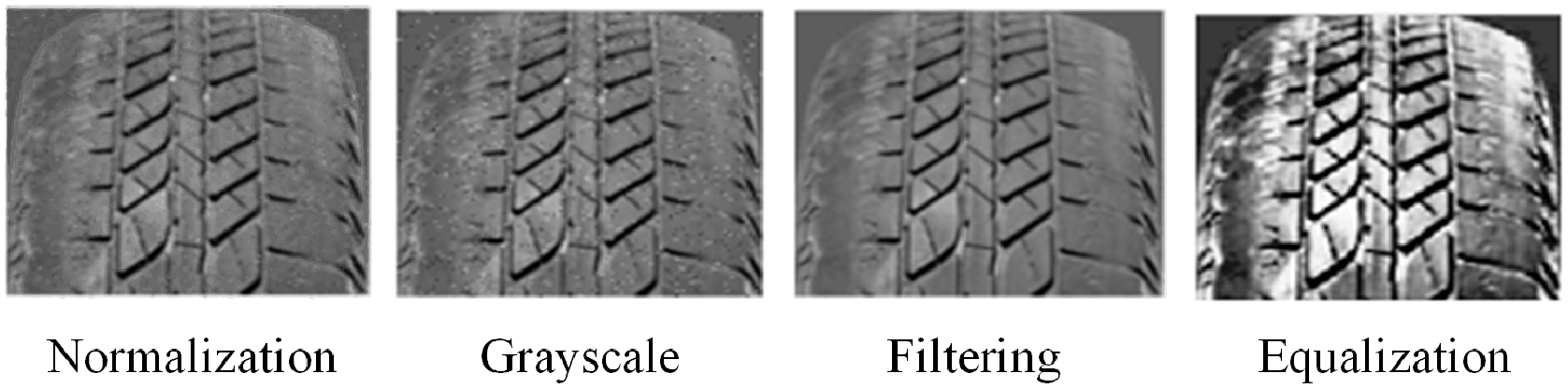
Pretreatment method.
Wear texture feature extraction model
In this subsection, we select and improve algorithms such as GGCM and GMRF to extract texture features from sample images.
Gray gradient co-occurrence matrix
As a classic algorithm for extracting texture features, GGCM is a vital part of the fusion feature extraction model.16,17 Herein, we briefly introduce the GGCM algorithm. Consider an image with a two-dimensional function of the form:
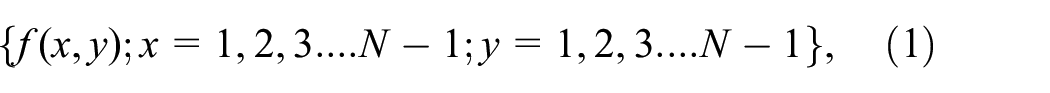
where the gradient image is

The gradient image is obtained by a gradient operator. If a large number of gray levels lead to a large amount of calculation, then the gray level and the gradient need to be normalized. Then, the normalization to the gray levels of the original image is defined as:
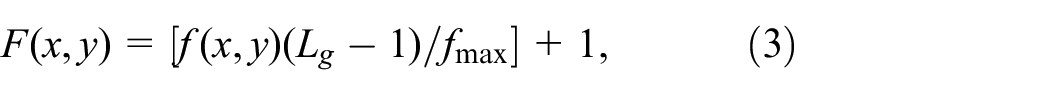
where [x] is the integer part of x, fmax is the maximum gray level of the original image and Lg is called the grayscale after normalization. The normalization to the gradient image is defined as:

in which gmax is the maximum gradient of the gradient image and Ls is the gradient scale after normalization. Then, we obtain two matrices after the normalization of the gray levels and gradients as follows:

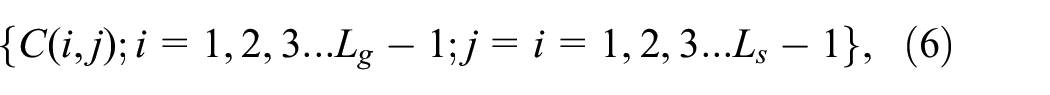
where C(i, j) is the number of pixels after normalization, i is the gray level and j is the gradient. The gray-gradient co-occurrence matrix is normalized as:

in which
Based on the normalized GGCM, 15 quadratic statistical features can be obtained,19,20 and their calculation formulas are shown in Appendix A. The GGCM describes the gray and gradient information of pixel points in space. 21 We use a feature vector composed of the feature parameters T = [T1, T2, T3, T4, T5, T6, T7, T8, T9, T10, T11, T12, T13, T14, T15]T of the gray-gradient co-occurrence matrix to describe the tire pattern texture with different wear level image features.
Gauss-Markov random field
A Gauss-Markov random field is essentially a set of multidimensional normal score plots and satisfies Markovian random variables.
22
Using
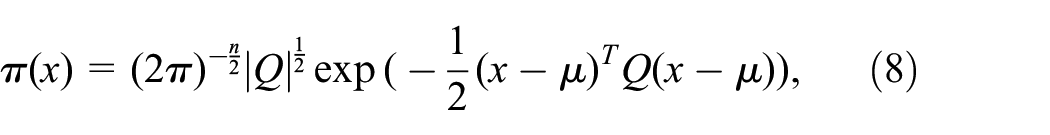
in which Q is the exact matrix and is the inverse of the covariance matrix. The elements at each position determine the nature of x. An element
Considering the complexity of tread pattern, parameter performance description and data calculation amount, we adapt the fifth-order GMRF model to describe the texture characteristics of tread pattern under different wear levels. The method is as follows:

where r is the radius of the neighborhood η and {r1, r2, r3, r4, r5, r6, r7, r8, r9, r1, r10, r11, r12} = {(0, 1), (1, 0), (1, 1), (1, −1), (0, 2), (2, 0), (1, 2), (−1, 2), (2, 1), (−2, 1), (−2, 2), (2, 2)}. Then, we can use a feature vector g = [g1, g2, g3, g4, g5, g6, g7, g8, g9, g10, g11, g12]T to represent the texture characteristics of tires with different degrees of wear.
K-nearest neighbors and distance formula
The KNN concept utilizes information from measured neighboring points to estimate the unmeasured point values.23,24 Each uncertain parameter is normalized to eliminate the effect of different value ranges to construct a KNN proxy model. 25 Then, the mean value of K closest points is calculated, and a larger weight is given to the closest points to estimate the value of unmeasured points, as shown in equation (10):

where
The principle of KNN classification algorithm is to take the samples of all known categories as training groups, calculate the distance between the predicted samples and all known samples, and select the K known samples closest to the unknown samples. According to the majority voting rule, the training sample and KNN were divided into more categories to predict the category of the unknown sample. By calculating the cross-validation loss,24,27 we choose the best distance formula and K value. First, the samples were randomly divided into several groups, one of which was used as a training sample and the other as a verification sample. Then the training sample is used to train the model, and the verification sample is used to verify the model. Finally, we take the classification accuracy as the performance index of the classifier. The steps are shown in Table 1.
Cross-validation experimental steps.

This section lists four commonly used distance formulas and chooses the most suitable one. For pixels p, q, and z with coordinates
(a)
(b)
(c)
then, D is a distance function or metric. The standardized Euclidean distance 28 between p and q is defined as follows:
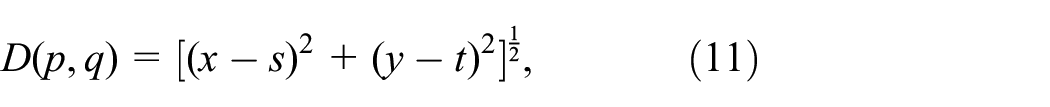
the city block distance 29 between p and q is

the Chebyshev distance 30 between p and q is

and the Minkowski distance 30 between p and q is

Under cross-validation, we compare the above four different distance formulas and analyze the verification accuracy and cross-loss entropy corresponding to different K values. The results are shown in Figure 7.

Cross-validation determination distance formula graph.
From Figure 7, with the increase of K value, the loss of cross-validation continues to increase. For experiments in this section, we determine that when K = 1, cross-validation with the Minkowski distance formula has the minimum loss. However, when K = 13, the cross-validation loss increases again, while the cross-validation loss of the city block distance formula is relatively stable. Therefore, we choose the city block distance formula and K = 1 as the KNN classifier parameter in subsequent experiments.
Experiment
This section briefly describes the important parameters of tire features in the feature extraction model and the weight distribution of the fused features. After establishing a theoretical analysis of the life prediction model, we conduct experiments to verify the accuracy of the model. Before the experiments, we separate the training samples from the test samples. We then repeat the experiments with different proportions of training and test samples to obtain the average accuracy.
Parameters of tire features
The gradient is defined as a vector, which means that the directional derivative of the function at that point is maximized in that direction. As can be seen from Figure 8, with the increase of mileage, the tire surface texture gradient presents an upward trend, which means that as the mileage increases, the texture characteristics of the tires will change significantly, and the wear on the tire surface will not be equal. This has certain influence on the study of tire surface texture characteristics.

Gradient graph.
The difference moment reflects the sharpness of the image and the depth of the texture grooves. The deeper the texture grooves, the greater the contrast and the clearer the visual effect. The larger the gray difference, the larger the value of the difference moment. The inverse difference moment reflects the homogeneity of image texture and measures the variation of image texture locally. A large value indicates that there is no variation between different areas of the image texture, reflecting that this part is very uniform. Figure 9 shows that as the mileage increases, the values of the difference moment and inverse difference moment gradually decrease, indicating that the texture features of tire surface become increasingly fuzzy.
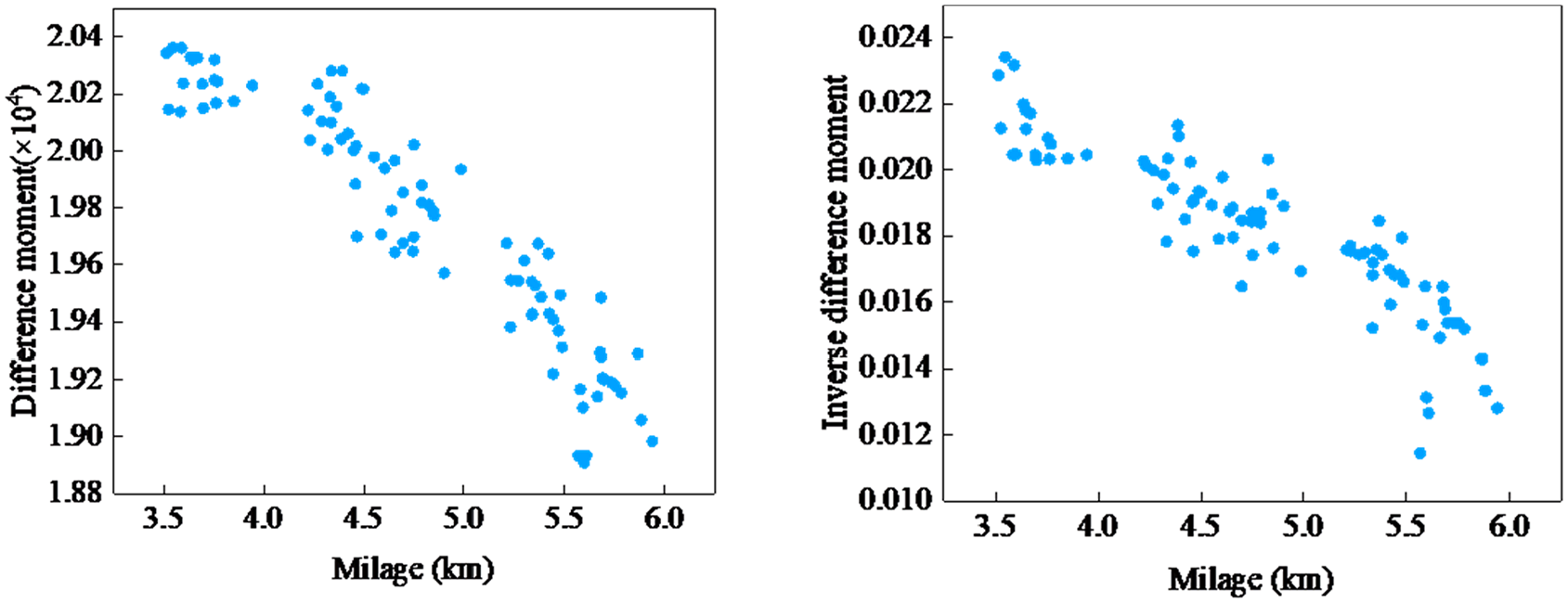
Difference moment and inverse difference moment graph.
According to the characteristics of entropy: the greater the entropy corresponding to a single random variable, the greater the amount of information contained. The entropy value of an image changes with the richness of the gray-scale information of the pixels it contains, the greater the amount of information in the image, the greater it is. The mixed entropy is a second-order statistic derived from GGCM, which can be used as a feature to describe different degrees of tire texture wear. As shown in Figure 10, the three tires are Optimo K415, Cinturato P7, and Primacy 3ST respectively. It is clear that the Optimo K415 texture is much more complex than the other two textures, which is also reflected by the green point value in Figure 11. The texture of the other two tires is similar, with similar values represented by the blue and red dots in Figure 11.

Different model tire maps.
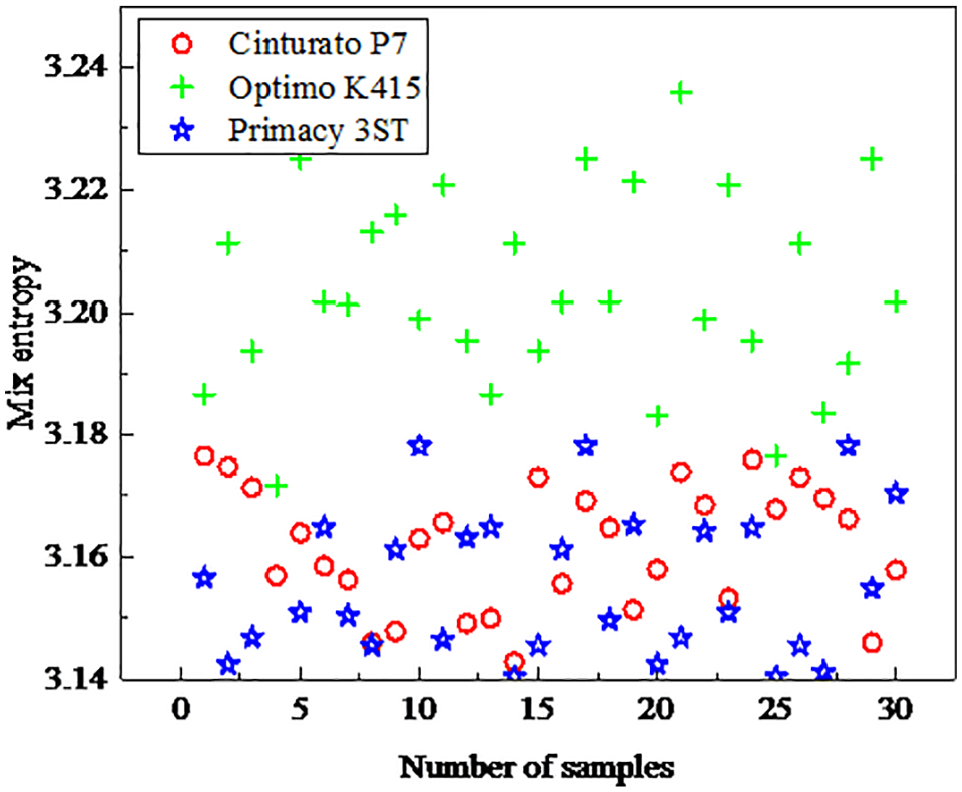
Mixed entropy graph.
According to the entropy theory, the higher the entropy value of the image, the more uniform the gray distribution is. As the entropy of the image increases, the information content of the image increases and the image becomes more complex. The mixed entropy is a second-order statistic derived from GGCM, which can be used to describe the characteristics of tire tread texture with different wear degrees.
Weight allocation of feature extraction model fusion features
In this subsection, we combine the two features of the GGCM and GMRF and assign multiple feature weights to the experiments. Then, we obtain a fusion feature that describes the degree of wear at different angles of the tread pattern, as shown in Figure 12. As can be seen from the results, when x = 0.7 and y = 0.3, the accuracy is the highest, but the fluctuation range is large. When x = 0.4 and y = 0.6, the accuracy decreases slightly, but the fluctuation range is small and the result is stable. In addition, we also provide a comparison diagram of the classification results of single features and fusion features, as shown in Figure 13. This section verifies whether a single feature or a fusion feature should be selected for classification. Compared with the results of single feature classification, the accuracy of fused feature classification is improved to more than 90%.

Weight distribution experiment chart.

Comparison of single and fused feature classification results.
The weight ratio of each feature component of the GGCM and GMRF is selected as 4:6. To avoid the influence of different value ranges and dimensions of the two features, the standard normalization method is adopted, as shown in equation (15):
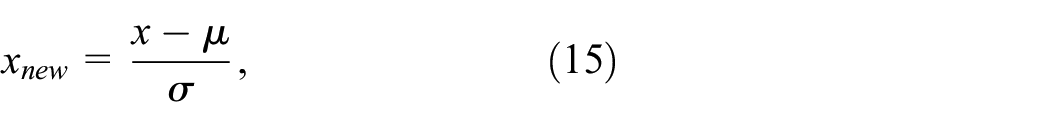
where
After normalization, the values of the sample data are limited to (0, 1), which matches the standard normal distribution. The steps of feature fusion and weight allocation are as follows:
(1) Let F be the fusion feature of the weights to be assigned, as shown in equation (16):

(2) Set the step size as 0.1, we traverse all x and y values and calculate the average classification rate of the classifier.
(3) Select the four weight combinations with the highest average classification rates, corresponding to 30, 35, 40, and 45 test samples.
(4) According to variance analysis, if a feature does not diverge, that is, the variance is close to 0, then the influence of the feature in the sample is very small and it is meaningless to distinguish the sample. Therefore, from the four groups of weight combinations, we choose the group with the largest mean variance as the weight coefficient of fusion features.
Results
In this section, we choose the MAP and confusion matrix as the evaluation indicators of the experimental results.
Sample classification and experimental testing
According to the different proportions of the test group and the training group (0.5, 0.6, 0.8, and 1.0), we divided the collected sample database. Different training groups were used to train the model, and different test groups were used to test the model, so as to obtain the average accuracy and running time of the model. The experimental results are shown in Figure 14. The abscissa represents the number of the test image, and the ordinate represents the classification of wear degree. In the same abscissa, the red asterisk shows the predicted classification result, the blue circle indicates the true classification result, the overlap of two points indicates that the predicted classification result is correct, and the absence of overlap indicates that the predicted classification is incorrect. For example, in the resulting image in the upper right corner of Figure 14, the true classification of the first test image is the fourth category represented by a blue circle, and the predicted classification is the fourth category represented by a red asterisk. These two points overlap, indicating that the prediction of the first test image is correct. Table 2 lists the precision and time spent on different scale models. The prediction time of the model is short (average 5–6 s) and the average precision is high (average precision is more than 80%).

Test model result graph.
Experimental results and operating conditions.
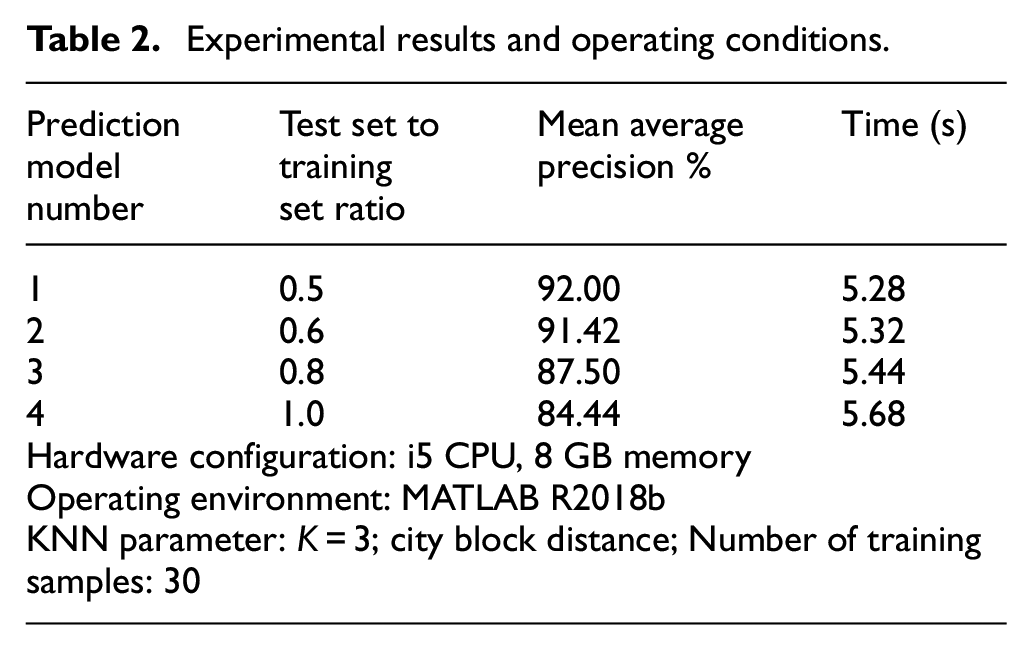
The verification model conditions are shown in Table 2: an i5 CPU, 8 GB running memory, MATLAB R2018b operating environment, KNN classifier (K = 3), city block distance, and 30 verifications per group. It should be noted that the K value of KNN classifier is different from that of theoretical analysis. When K = 3, the prediction model has the highest accuracy.
Evaluation of experimental results
After obtaining the results through experiments, we perform a series of evaluations, such as for the accuracy of the results. This section introduces two evaluation methods and applies them to the model.
Mean average precision
In measuring the performance of a model, it is unscientific to use precision or recall alone. Next, we introduce MAP as an evaluation indicator.
We define categories that are identified and correctly classified as true positive (TP) but incorrectly classified as false positive (FP), categories that are not correctly identified and classified as true negative (TN), and categories that are uncertain but incorrectly classified as false negative (FN). Equation (17) can be used to calculate the accuracy and equation (18) is used to calculate the recall rate.


We draw a two-dimensional curve of precision and recall, use them as the vertical and horizontal coordinates, respectively, and name them PR curve. Then, we use the PR curve under area as a measure. Finally, we have the concept of average precision (AP). Its calculation formula is shown in equation (19):

The mean average precision, which is the average of AP values, is the AP values for multiple validation sets. 31 The MAP calculation formula is shown in equation (20):

Classification accuracy rate is the ratio of the number of correctly classified samples to the total number of samples in a given sample. However, the accuracy is not applicable to uneven data. For example, in a binary classification problem, we have 1000 samples, of which 10 are positive samples and 990 are negative samples. If all samples are directly classified as negative, then the accuracy is 99%, while the positive samples are all wrong, so the classification performance of the model is actually very poor. For experiments in this section, we choose random test samples and training samples that will lead to data imbalance. The accuracy of evaluation cannot accurately describe the classification performance of the model. Therefore, the confusion matrix is used to further study the classification performance of the model.
Confusion matrix
The confusion matrix is a case analysis table that summarizes the predicted results of the classification models in machine learning. The records in the data set are summarized in the form of matrix according to the two criteria of the real category and category judgment predicted by the classification model. The rows of the confusion matrix represent the true values and the columns represent the predicted values. All the correct predictions are on the diagonal, so it is convenient and intuitive to see what is wrong with the confusion matrix and why the values appear outside the diagonal. As shown in Figure 15, the numerator value of the precision is the value on the diagonal of the matrix. 32

Confusion matrix diagram.
Evaluation of experimental results
The confusion matrix is calculated by comparing the position of each measured pixel with the corresponding position in the classified image. In Figure 16, the abscissa indicates the expected classification result, and the ordinate indicates the actual classification result. The overlapping of the two indicates that the classification is correct. It can be seen that during classification, only the first and fourth types have allowable errors, and the accuracy of the other classification results is above 80%, indicating that this method can accurately predict tire life.

Model classification result confusion matrix.
By using the MAP and confusion matrix to verify the experimental results, it can be seen that the model shows good accuracy in tire life prediction.
Conclusion
This paper presents a novel method for predicting the life of automobile tires. Firstly, we establish an original image database and perform preprocessing and texture feature extraction on the original image. Secondly, we input the extracted features into the classifier to train and test the model. Finally, we use appropriate evaluation indicators to analyze the accuracy of the model.
Experiments demonstrate that the proposed method shows high accuracy, fast efficiency and low cost in predicting tire life. However, there are still some shortcomings in this study. For example, factors such as road conditions, tire size, and tire quality require further consideration. Moreover, this article only makes experimental predictions based on small sample data, and this work needs to be extended to large sample tests. We will report on these results in future publications.
Footnotes
Appendix A
In this appendix, we introduce the 15 parameters describing the GGCM extraction of texture feature, they are: small gradient advantage, large gradient advantage, gray distribution unevenness, gradient distribution unevenness, energy, gray average, gradient average, gray mean square error, gradient mean square error, correlation, gray entropy, gradient entropy, mixed entropy, difference moment, and inverse difference moment. Their calculation formulas are:
where i and j are the coordinates of the pixel in the digital image, P(i, j) and g(i, j) are the values of the coordinates.
Handling Editor: James Baldwin
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work reported in this paper was supported by the National Natural Science Foundation of China under Grant No. 11602142.