
Abstract
Aiming at the existing intelligent optimization algorithms for solving the integrated scheduling problem of complex products with tree structure, there are problems of missing optimal solutions when designing encoding methods or generating infeasible offspring while designing evolutionary operators, an integrated scheduling algorithm based on the priority constraint table is proposed in this paper. A novel encoding method based on the dynamic priority constraint table is developed, which can guarantee the feasibility and completeness of the initial population individuals. For the legitimacy of the generated offspring individuals, two new different crossover and mutation methods are designed separately. The introduced evolutionary operators can avoid the detection and repairment of the infeasible individuals. An insertion-based greedy decoding method is also developed. In addition, based on the critical operations, a local search strategy is presented to enhance the search ability for the superior solutions. The feasibility and superiority of the proposed algorithm is verified by comparative experiments.
Keywords
Introduction
The production scheduling problem is a typical NP-hard problem, which usually treats processing1,2 and assembly3,4 as two independent stages. The final product is assembled by a series of components, and these components may be parts or sub-assemblies (SUAs) which have been previously assembled. At present, research on production scheduling problems mainly focuses on the manufacturing stage, such as the flow shop scheduling problem5,6 for mass production environments, and the job shop scheduling problem7,8 for multi-variety and small-batch production environment. Figure 1 gives three typical product structures, which show the relationship between parts or assembled components and products in a hierarchical way. In flat structure products, the final product is assembled from a series of parts. In tall structured products, there can be at most one assembly operation in each layer. In complex structure products, each layer can have multiple assembly operations. In this paper, we refer to the product with the first structure as a simple product and the product with the latter two structures as a complex product. With the increase of people’s demand for personalized customized products, if the traditional production method of ”processing first and assembly later” is followed, the inherent parallel relationship between the various operations of the complex product will inevitably be broken, affecting the entire product manufacturing cycle. The integrated scheduling problem is an extension of the traditional job shop and flow shop scheduling problem, and it is a NP-hard problem too. 9 The scheduling object of this problem is the complex products with tree structure, that is, the overall constraints among operations are tree structure. There are machines for processing as well as machines for assembly. The research on the integrated scheduling of tree-structured products can shorten the manufacturing cycle of products and improve the competitiveness of enterprises.

Three typical product assembly structures.
Due to the characteristics of the NP-hard problem, there is no effective algorithms to solve the production scheduling problems in polynomial time. In literature, 10 the authors noticed that the metaheuristic algorithms can effectively solve production scheduling problems and other combinatorial optimization problems. In the past few decades, for improving the manufacturing efficiency and competitiveness of enterprises, various kind of intelligent optimization algorithms are applied to deal with production scheduling problems, such as genetic algorithm, 11 artificial bee colony algorithm, 12 particle swarm optimization algorithm, 13 teaching-learning-based optimization algorithm, 14 water wave optimization algorithm, 15 biogeography-based optimization algorithm, 16 hybrid algorithm 17 and so on. However, due to the existence of the inherent tree-structured constraint relationship of complex products, all existing encoding methods and evolutionary operators have been invalidated, which limits the application of intelligent optimization algorithms for solving the integrated scheduling problem. At present, the research on the integrated scheduling of tree-structured products mainly focuses on simple products.6,18 The literatures on the integrated scheduling of complex products are relatively few, and most of them are rule-based heuristic algorithms. For example, in literatures,19–23 the authors have systematically and comprehensively studied the integrated scheduling of complex tree-structured products, and they have developed lots of integrated scheduling algorithms, which are based on the processing operation tree model. But as the scale of the problem increases, the computation time of these algorithms cannot be guaranteed. For the intelligent optimization algorithm-based solutions, the authors have shown approaches based on genetic algorithm separately,24,25 but they all need to consider additional detecting and repairing work to avoid generating infeasible offspring individuals, which lead to the increase of computation time and the decrease of efficiency of the algorithm. In literature, 26 the authors put forward a virtual component level division encoding method, and then solve the problem based on GA. This algorithm can solve the above problems, but its encoding method is flawed, that is, the optimal solution may be missed. In literature, 27 the authors propose an integrated scheduling algorithm based on an operation relationship matrix table. The designed evolutionary operators focus more on guaranteeing the viability of the offspring individuals, thus, they are yet excellent evolutionary operators. In literature, 28 the authors present a hybrid algorithm based on improved extended shifting bottleneck procedure and GA. Although the problems of imposition constraints and omission of solution spaces are avoided, the repair work for the infeasible solutions generated by genetic operators is still needed.
To solve the problem of previous metaheuristic-based integrated scheduling algorithms, in this paper, a novel integrated scheduling algorithm of complex products based on the priority constraint table is proposed. The designed encoding method can defeat the shortcomings of the encoding method in the previous literature that may omit the optimal solutions, and in the meantime, it can make the design of the subsequent evolutionary operator easier. For the crossover and mutation operators, two different new methods are presented to ensure the legitimacy of the generated offspring chromosomes. A simple but effective decoding method is given. In addition, based on the critical operation set of the optimal scheduling scheme, a local search strategy is presented. Finally, the performances of the introduced algorithm are verified by experiments.
Problem description
The differences between the integrated scheduling problem of complex products and traditional production scheduling problem are that the problem studied in this paper needs to consider the assembly order constraints among jobs, which makes the processing structure of products tree-like. Figure 2 is a processing operation tree of a specific product. In Figure 2, the operation is represented by a node, and each node is composed of three parts, respectively representing the operation’s name, the processing machine and the corresponding time. The direction of the arrow shows the priority constraint relationship between operations. The problem studied in this paper can be described as follows: a single complex product consisting of n operations

The processing operation tree of a specific product.
The objective function

is subject to

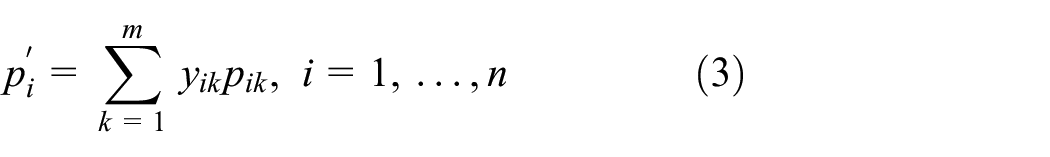





Among them, equation (1) is the objective function of the problem, which is to minimize the completion time of the product. Equation (2) means that each operation should be assigned to only one machine for processing. Equation (3) denotes the processing time of operation
Algorithm design
As an evolutionary search algorithm, the genetic algorithm has shown good effectiveness in solving traditional flow shop scheduling problem and job shop scheduling problem. Therefore, for the integrated scheduling problem of complex products with tree structure, a GA-based integrated scheduling algorithm is presented in this section. In order to facilitate the design of the subsequent strategies, we simplify the processing operation tree and only describe the priority constraint relationships among operations. Then its corresponding priority constraint graph (PCG) can be obtained. Figure 3 is a priority constraint graph of the product shown in Figure 2. The priority constraint graph is essentially a directed acyclic graph, and the edge indicates the priority relationship between two operations. For example,

The priority constraint graph of the product shown in Figure 2.
Establishment of the priority constraint table
Due to the existence of priority sequence constraints, traditional genetic algorithms cannot be directly used to solve the studied problem. In order to avoid generating infeasible individuals during population evolution, in this section, the process of establishing the priority constraint table will be given first. The following symbols and variables are introduced and explained as follows:
Thereinto, the element value of

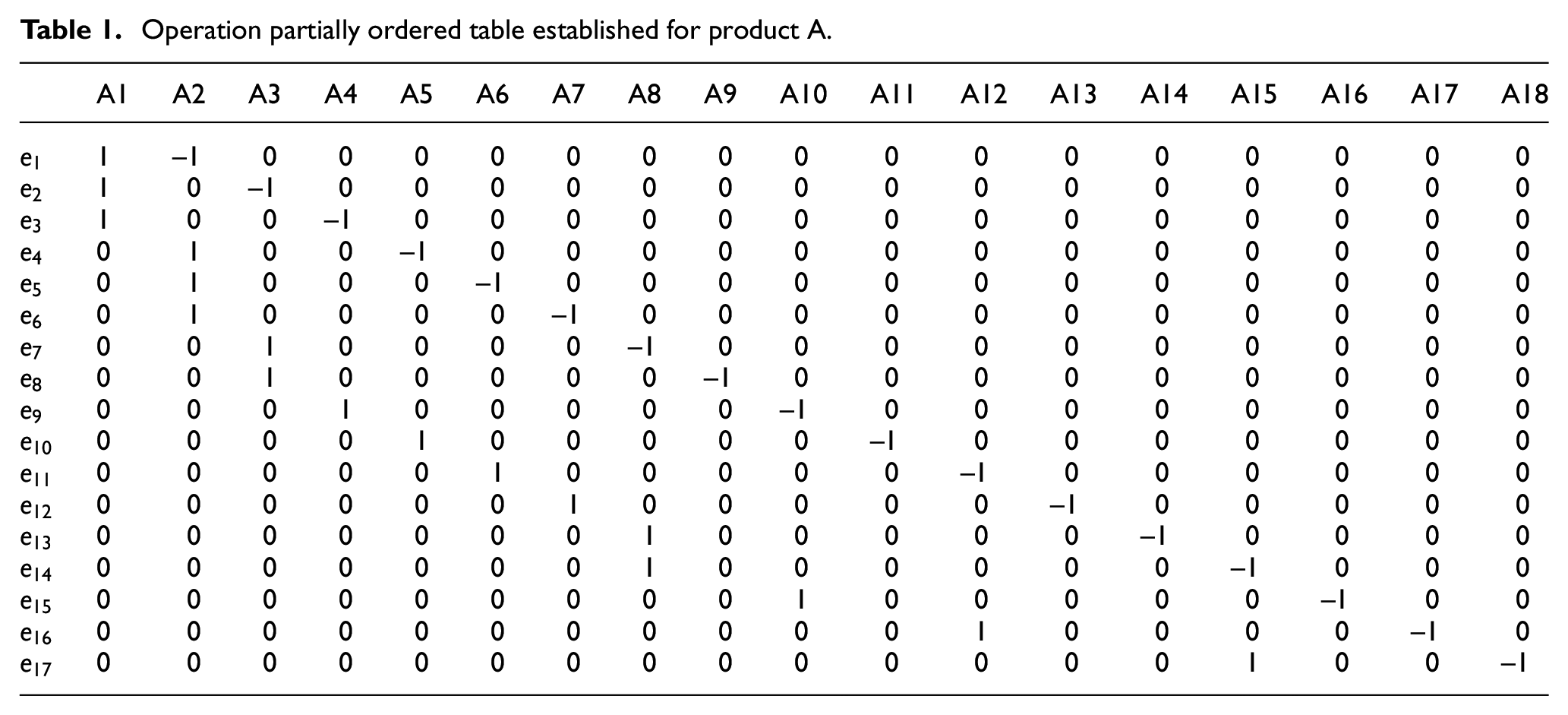
According to the above definition and the priority constraint graph, the priority constraint table of a complex product can be established. Table 1 is a priority constraint table of the product shown in Figure 3. The priority constraint table indirectly expresses the dependence relationship among operations. It is essentially a dynamic correlation matrix. In a PCT, each column records the operation information and each row shows the priority constraint relationship between two operations. The PCT not only facilitates the understanding of sequence constraints among operations, but also facilitates the entry of product information. Therefore, based on the priority constraint table, this paper will present new encoding method and evolutionary operators subsequently.
Operation partially ordered table established for product A.
The encoding method based on the dynamic PCT
In this paper, we adopt the operation-based encoding strategy, that is, the integer on each gene position represents the operation’s number of the complex product. In order to ensure the operation genes of the chromosomes satisfy the priority constraint defined by PCG, a novel encoding scheme based on the dynamic priority constraint table is proposed. The main idea is: without considering the use of machines, identify the priority constraint table and obtain the current schedulable operation set. Then a schedulable operation is randomly determined for processing. The specific steps of the designed encoding method are as follows:
Step 1: Identify the priority constraint table PCT, and gain the current schedulable operation set S. The specific steps are: According to the rules for establishing the priority constraint table, if the non-zero element of
Step 2: Randomly select an operation
Step 3: Repeat Step 1, and if the current set S is empty, then the encoding process is complete; otherwise, jump to Step 2.
Through the above-mentioned encoding method, a chromosome which fully meets the priority constraint relationships among operations can be obtained. Figure 4 is the chromosome schematic diagram obtained by applying the above encoding method to the product shown in Figure 2.

A chromosome schematic diagram of the product shown in Figure 2.
The decoding method based on greedy insertion
Based on the characteristics of the integrated scheduling problem, in order to make all operations start processing as early as possible, an insertion-based greedy decoding method is presented. The specific decoding steps are as follows:
Step 1: Initialize the pre-start time
Step 2: Read an operation from the chromosome in order from left to right. Assume that the current operation is
Step 3: For operation
Step 4: Update the pre-start time of the affected operations. Read the priority constraint table, obtain the technology successor of operation
Step 5: If all operations has been processed, then the decoding process is finished; otherwise, jump to Step 2.
Through the above decoding method, a specific individual can be decoded into a scheduling scheme. Figure 5 is a specific scheme corresponding to the individual shown in Figure 4.

The corresponding scheduling scheme by decoding the individual shown in Figure 4.
Selection method
In order to make the traits of good individuals inherited to the offspring with greater probability, the algorithm adopts the roulette selection method, supplemented by elite retention strategy.
Crossover operators
In genetic algorithm, crossover is an important part to ensure that the population evolves toward promising regions, which determines the global search ability for the optimal solutions. Due to the more complex priority constraints of the integrated scheduling problem, the existing crossover methods are invalid. Therefore, in order to ensure that after crossover process, operations of the offspring individuals can still meet the priority sequence constraints, and in the meantime, the offspring individuals can inherit the superior traits of the parent individuals, the following two crossover methods are designed.
(1) The designed two-point crossover method
Step 1: In the paired parental chromosomes V1 and V2, the starting and ending position of the recombinant gene string (the positions selected are the same in the two parent chromosomes) are determined randomly, and ensure that the number of genes in the recombinant gene string is greater than 1 and not equal to the length of the entire chromosome.
Step 2: Generate the offspring individual V1′. The recombination position of V1′ is determined according to the starting and ending position of the recombinant gene string determined in Step 1. The recombinant positions are filled by the genes of the recombination gene string determined by V1, and the arrangement order is the order in which they appear in V2. The remaining parts of V1’ are the same as that of V1. The generation procedure of offspring individual V1′ is shown in Figure 6(a).
Step 3: Generate the offspring individual V2′. The recombination position of V2’ is determined according to the starting and ending position of the recombinant gene string determined in Step 1. The recombinant positions are filled by the genes of the recombination gene string determined by V2, and the arrangement order is the order in which they appear in V1. The remaining parts of V2′ are the same as that of V2. The generation procedure of offspring individual V2’ is shown in Figure 6(b).
(2) The designed multi-point crossover method
Step 1: In the paired parental chromosomes V1 and V2, several recombinant genes are determined stochastically, and positions of these genes may be discontinuous, but the positions selected of the two parent chromosomes are the same.
Step 2: Generate the offspring individual V1′. According to the position of the recombinant genes determined in Step 1, the first consecutive recombinant gene string of V1 is obtained as the current recombination string. Obtain the starting and ending position of the current recombinant string in V1, and the recombination position of V1′ is determined according to the starting and ending position of the current recombinant string. The recombinant positions are filled by the genes of the current recombinant string, and the arrangement order is the order in which they appear in V2. Update the current recombinant string by the next consecutive recombinant gene string in V1, and perform the recombination process in the above way until all recombinant genes in V1 are recombined. The remaining genes of V1′ are identical to the remaining genes of V1. The generation procedure of offspring individual V1′ is shown in Figure 7(a).
Step 3: Generate the offspring individual V2′. According to the position of the recombinant genes determined in Step 1, the first consecutive recombinant gene string of V2 is obtained as the current recombination string. Obtain the starting and ending position of the current recombinant string in V2, and the recombination position of V2′ is determined according to the starting and ending position of the current recombinant string. The recombinant positions are filled by the genes of the current recombinant string, and the arrangement order is the order in which they appear in V1. Update the current recombinant string by the next consecutive recombinant gene string in V2, and perform the recombination process in the above way until all recombinant genes in V2 are recombined. The remaining genes of V2′ are identical to the remaining genes of V2. The generation procedure of offspring individual V2′ is shown in Figure 7(b).
(3) Analysis of the designed crossover methods
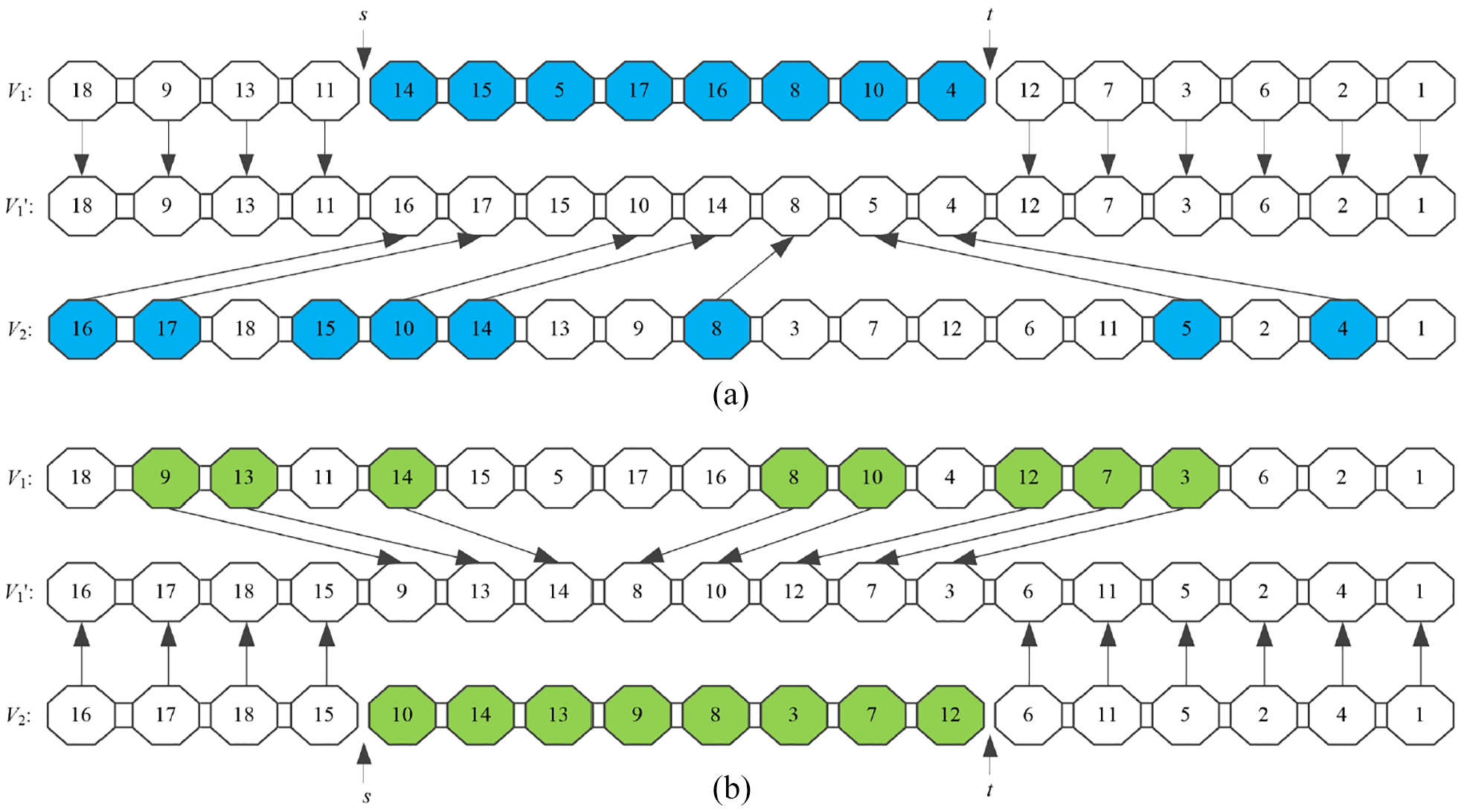
The designed two-point crossover method: (a) generation of offspring chromosome V1′ and (b) generation of offspring chromosome V2′.
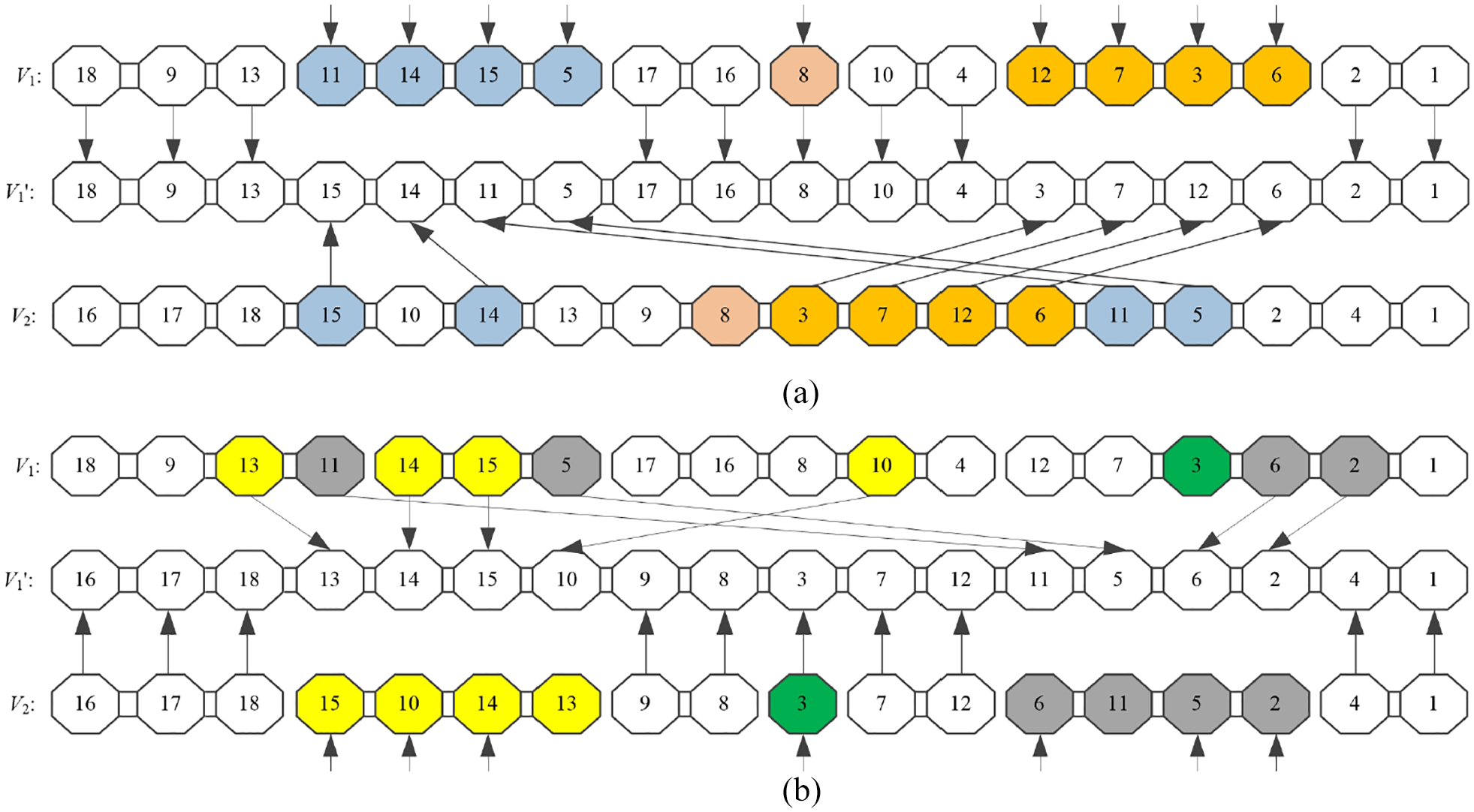
The designed multi-point crossover method: (a) generation of offspring chromosome V1′ and (b) generation of offspring chromosome V2′.
Through simple analysis, it can be found that the above two crossover methods generate the offspring individuals by filling the crossover positions with the selected genes in the order in which they appear in the paired parent chromosomes. The genes of the selected gene string satisfy the priority constraints in the paired chromosomes, so the generated offspring individuals must be legitimate. Assuming that
Mutation operators
Since the existing mutation methods cannot be directly applied to treat the integrated scheduling problems, in order to ensure the offspring individuals can also satisfy the priority constraints after performing mutation operator, based on the priority constraint table, two new mutation methods are designed.
(1) The designed insertion-based mutation method
The main idea of the designed mutation method is: Firstly, randomly determine a gene in the parent chromosome V. Then, by identifying the priority constraint table, obtain the technology predecessors and the technology successors of the selected gene operation, and mark their position in the parent chromosome V. Finally, insert the selected gene into any position before the technology successor and after the position of the technology predecessor which is closest to the selected gene. If there is no technology predecessor, i.e. the selected operation is a leaf-node operation, and then randomly insert the selected operation into any position before the technology successor. If the selected operation is a root-node operation or the positions of the technology predecessor operation, the selected operation and the technology successor are consecutive, then another mutation gene operation is randomly reselected. The procedure for performing the above mutation operation on a chromosome is shown in Figure 8.
(2) The designed scramble mutation method
Step 1: In the parent chromosome V, randomly determine the starting and ending position of the mutant gene string, and ensure that the number of genes in the mutant gene string is greater than 1 and not equal to the length of the entire chromosome.
Step 2: Add the genes of the mutant gene string to the gene stack, so that the gene operations in the same gene stack meet the priority constraints, and there is no constraint relationship among operations of different gene stacks. The specific procedures are as follows: obtain a gene from the mutated gene string in order from back to front, assuming currently it’s
Step 3: Randomly pop genes out of the gene stacks to generate the mutated gene substrings. The specific procedures are as follows: randomly select a gene stack and determine whether the gene stack is empty. If it is empty, then randomly select another gene stack; otherwise, pop the top element of the selected stack as the mutation gene of the current mutation position. Repeat the above processes and obtain the gene for the next mutation position until all gene stacks are empty.
Step 4: The generated offspring chromosome V1 can be obtained by putting the mutated gene string into the mutation site. It can be seen that the offspring individuals completely satisfy the priority constraints. The procedure for performing the above mutation operator on a chromosome is shown in Figure 9.
(3) Analysis of the developed mutation methods

The designed insertion-based mutation method.

The designed scramble mutation method.
It is not difficult to find that the above two mutation methods are based on the idea of the designed encoding method and its encoding principle in this paper. Therefore, after the mutation process, the offspring population will not contain infeasible individuals. In addition, even if the selected mutation gene or mutation gene sequence is identical, the generated offspring individuals may not be unique.
The designed local search strategy
After decoding an individual into a specific scheduling scheme, we can find one or more paths from the last processing operation to the initial moment. The operations on the path are closely arranged, and its length value is equal to the completion time of the current scheme. We define such a path as a critical path, and call the operation on the critical path as a critical operation. For the scheduling scheme described in Figure 5, the critical path is shown in the dashed box in Figure 10, we can find that the operations
Step 1: Obtain the critical operation set of the current scheduling scheme.
Step 2: Determine whether the critical operation set is empty, if it is empty, the local search process is finished; otherwise, read an operation from the critical operation set in turn, assuming that the current operation is
Step 3: Obtain the machine predecessor set of
Step 4: Determine whether
Step 5: Put

The scheduling scheme shown in figure 5.
Through the above steps, we can transform some critical operations of the original scheduling scheme into non-critical operations, thereby achieving the goal of shortening the product completion time. For example, in the critical path shown in Figure 10, when judging whether the critical operation

The new scheme by moving
Procedure of the proposed algorithm
The overall flowchart of the designed integrated scheduling algorithm for complex products is shown in Figure 12.

The overall flowchart of the integrated scheduling algorithm based on PCT.
Computational experiments
At present, there are huge number of benchmarks for traditional job shop scheduling problems, but no benchmark has been found for the integrated scheduling problem of complex products. Most of the previous integrated scheduling algorithms are rule-based algorithms, and the test instances are all single specific instances. In order to fully test the performance of the proposed algorithm compared with the previous algorithms, we randomly generate 100 instances. Each instance is randomly generated by the following parameters: the number of operations is [50,100], the number of machines is [4,8], the processing time is [1,20], and the number of processing operation tree layers is [2,
Parameters setting
In order to analyze the influence of the parameters on the performance of ISA_PCT, we adopted the Taguchi method of design-of-experiment method (DOE)
29
to determine the parameters of the algorithm proposed in this paper. The specific complex product from literature
25
is used for testing. The instance is composed of the classic job shop standard test problem FT10, and its process assembly diagram is shown in Figure 13. There are four key parameters of the algorithm namely, population size (

The process assembly diagram of the products shown in literature. 25
The parameter values of different factor levels.

The orthogonal results of different factor levels.
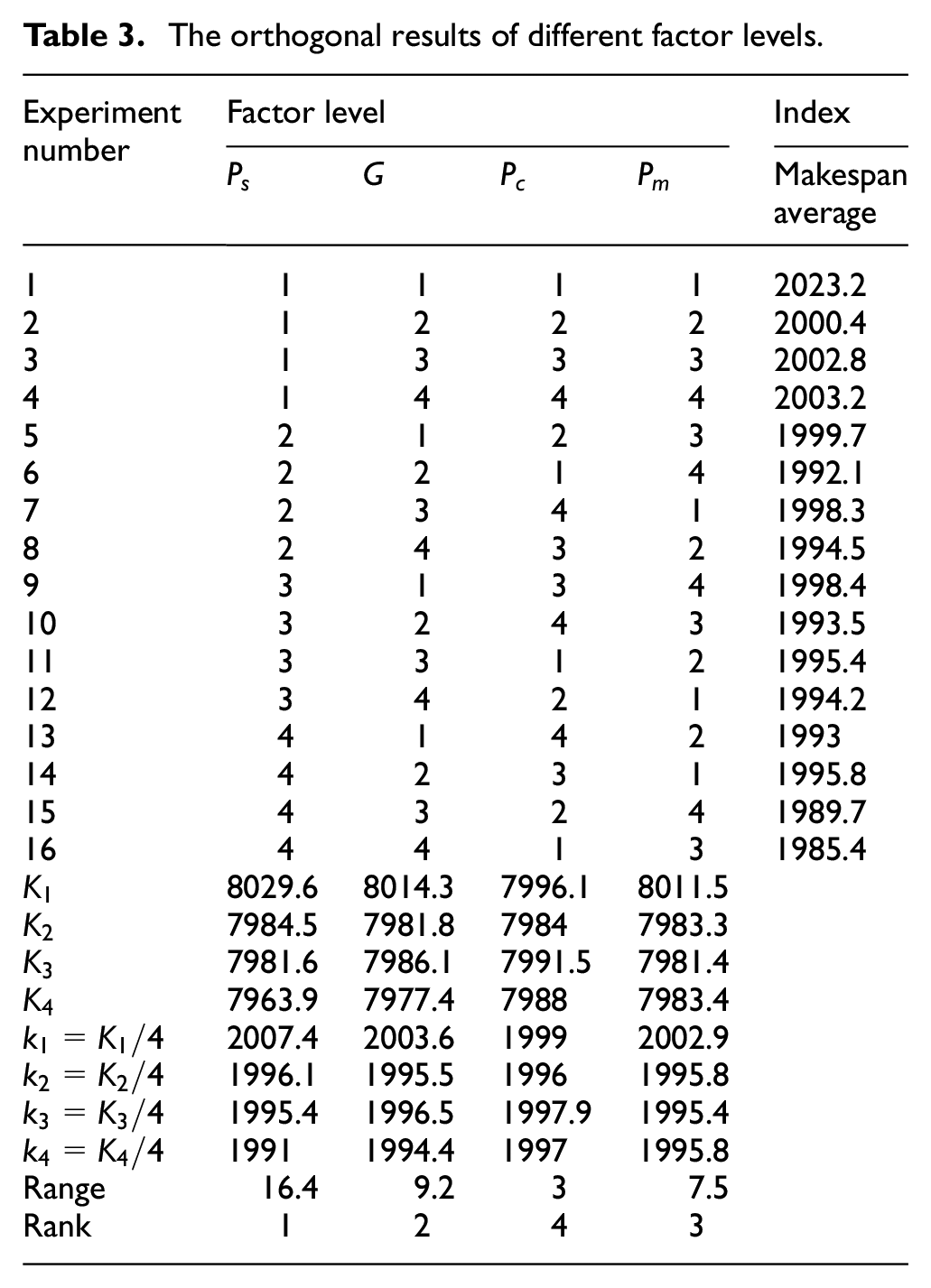
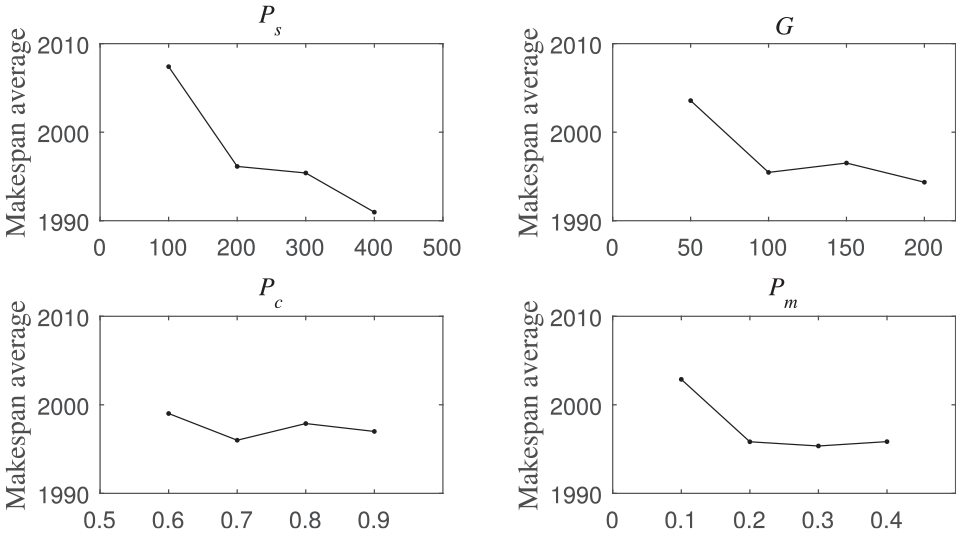
The influence of the four key parameters on the performance of ISA_PCT.
It can be seen from Table 3 and Figure 14 that: first, the parameter
Comparisons with existing algorithms
During the 30 independent runs of the above algorithms for 100 randomly generated examples, the minimal makespan obtained is shown in Figure 15(a) and the average makespan obtained is shown in Figure 15(b). It can be seen from Figure 15 that the optimal maksepan change curve and average makespan change curve of the proposed algorithm are all located below the whole figure. Figure 16 presents the statistics of the results shown in Figure 15. In Figure 16, the first group of data is the statistics of the total number of the occasion that the minimal makespans obtained by each algorithm is the minimum among all four minimal makespan obtained by different algorithms, while the second group data are about the average makespan. In the first group of data shown in Figure 16, for the 100 instances described in Figure 15, algorithm ISA_PCT obtains the optimal solution for 100 examples, algorithm ISA_HGA obtains the optimal solution for 41 examples, algorithm ISA_ORMT obtains the optimal solution for 36 examples, and algorithm CSA_VCLDC only obtains the optimal solution for 14 examples. The second group data of Figure 16 shows the average solution capability of each algorithm for the testing instances. Therefore, it can be seen from Figures 15 and 16 that the quality of the solution of ISA_PCT is better than that of the other three algorithms.

The scheduling results by applying different algorithms for 100 randomly generated instances: (a) the minimal makespan obtained by applying different algorithms for each instance and (b) the average makespan obtained by applying different algorithms for each instance.

The statistics of the results shown in Figure 15.
Figure 17 shows the average execution time of different algorithms for instances described in Figure 15. Because algorithms CSA_VCLDC and ISA_ORMT are solutions based on the standard genetic algorithm, for some instances, the execution time of algorithms CSA_VCLDC and ISA_ORMT is better than that of ISA_PCT. However, the average execution time of algorithm ISA_PCT proposed in this paper is generally better than that of algorithm ISA_HGA. In conclusion, the performance of the proposed algorithm ISA_PCT outperforms other comparison algorithms.
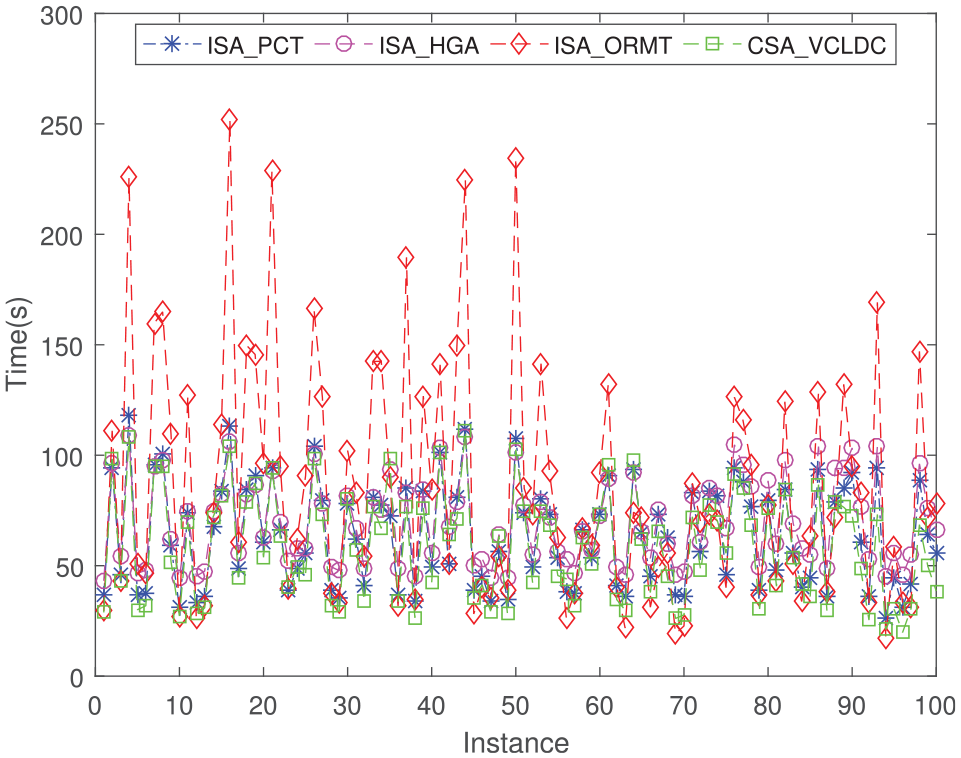
The average execution time of different algorithms for solving instances in Figure 15.
For the complex product shown in Figure 13, Figure 18 shows the trend of the optimal solution in each generation of the population when we apply the above algorithms to solve the instance. It can be seen from Figure 18 that the algorithm ISA_PCT obtains the optimal solution at the 33rd generation, the algorithm ISA_HGA obtains the optimal solution at the 66th generation, the algorithm ISA_ORMT obtains the optimal solution at the 78th generation, and the algorithm CSA_VCLDC only obtains the optimal at 95th generation. It can be seen that the convergence of the proposed algorithm is better than the other three comparison algorithms.

The optimal makespan obtained by different during each generation.
Conclusion and future research
For the integrated scheduling problem of complex products with tree structure, a GA-based integrated scheduling algorithm is presented. The proposed algorithm overcomes the problems of previous metaheuristic-based integrated algorithms. Based on the processing operation tree, the priority constraint table is constructed, which indirectly expresses the priority dependence relationship among operations. The designed encoding method not only guarantees the legitimacy of the initial individuals, but also solves the problem of missing solution space in the previous algorithms. The decoding method is simple but effective. The presented evolutionary operators can ensure that the operations in offspring individuals meet the priority constraints, thereby avoiding the extra detection and repair work in previous literatures. The proposed local search strategy further enhances the search ability of the algorithm for the optimal solution. The performance of the proposed algorithm is verified by the comparative experiment.
The algorithm proposed in this paper uses a random initial population method, so the quality of the initial population may be poor. Therefore, in future work, we can consider combining the designed encoding method with some heuristic rules to improve the quality of the initial population. At the same time, the evolutionary operators designed in this paper focus on ensuring the legitimacy of the offspring individuals. Therefore, it is necessary to design more effective operators to ensure that the population evolves to the most promising region. The processing machine involved in this paper is only the ordinary processing machine. In the fierce market competition environment, many enterprises have introduced flexible production lines. Therefore, the follow-up research can be carried out on the integrated scheduling problem with flexible machines. In this paper, only the single-piece tree structure complex product integrated scheduling problem is considered. In actual production applications, there are multiple products being processed at the same time, and orders may arrive at any time. Therefore, future research can consider the dynamic multi-orders integrated scheduling problem. In addition, the multi-objective complex product integrated scheduling problem is also one of the future research directions.
Footnotes
Handling Editor: James Baldwin
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: We acknowledge the support of the National Natural Science Foundation of China [Grant numbers 61772160, 61370086].