
Abstract
A classification and recognition method for the severity of road traffic accident based on rough set theory and support vector machine was proposed in this article. Rough set theory was used to calculate the importance of attributes in human, vehicle, road, environment, and accident. On the basis of importance ranking, the factors affecting the severity of accident were extracted. Then, with the general accident and major accident as two classification labels, the classification and recognition model of the severity of road traffic accident was established by using support vector machine. The results show that the model could improve the recognition accuracy and reduce the computational workload. Moreover, it has the good ability in classification and recognition as well as generalization compared with the model using support vector machine alone.
Keywords
Introduction
With the increasing of road traffic infrastructures, motor vehicles, drivers, and traffic flow, the role of road traffic in supporting and guiding economic and social development is becoming more and more obvious. As a result, road traffic safety has increasingly become a key issue in concerning the safety of people’s lives and property, as well as affecting the quality and efficiency of economic and social development. Road traffic accidents are the process of simultaneous damage of people or things, which caused by the coupling imbalance of dynamic and static factors such as human, vehicle, road, and environment. Therefore, it is necessary to study the influencing factors, as well as the classification and identification model of the severity of road traffic accident, so as to pave the way for improving the safety level of road traffic.
Researchers have tried different analytical models of traffic accident severity from different perspectives. Among the researches of traffic accident severity, the most widely used is discrete choice model based on logit/probit models.1,2 Logit model is also called logistic model, which obeys logistic distribution. Probit model obeys normal distribution. Both models are commonly used in discrete choice models. However, the logit model is simple and direct. It has a wider application. Bédard et al. 3 used multiple logit model to study the independent effects of drivers, collision types, and vehicle characteristics on the death risk of drivers. Yau, 4 with the use of logit model, a population-based case-control study was conducted to examine the factors, which affected the severity of single vehicle traffic accident in Hong Kong. In particular, individual vehicle accident data of three major vehicle types—namely, private vehicles, trucks, and motorcycles—were considered. The effects of district, human, vehicle, safety, environmental, and site factors on the severity of traffic accident were examined. Unique risk factors associated with each of the vehicle types were identified by means of stepwise logistic regression models. Yao et al. 5 proposed a method of expressway accident prediction based on support vector machine (SVM), which used tabu search algorithm to optimize the parameters of SVM. Ma et al. 6 used logit model to study the influencing factors of the severity of road tunnel accident. Meanwhile, they studied road safety evaluation based on accident severity by using fuzzy Delphi method. It was noted that most of the empirical data sets of classical statistical models 1 could not satisfy the strict assumed conditions of discrete choice model, thus resulting in biased estimation of parameters. Considering that, many scholars had applied some intelligent classification models (e.g. neural network model,7–9 Bayesian model)10,11 for the analysis of accident severity: Delen et al. 7 used a series of artificial neural networks (ANNs) to model the potentially nonlinear relationships between the injury severity levels and crash-related factors. Then they conducted sensitivity analysis on the trained neural network models, so as to identify the prioritized importance of crash-related factors as they applied to different injury severity levels. Sohn and Shin 8 used three data-mining techniques (neural network, logistic regression, decision tree) to select a set of influential factors and to build up classification models for accident severity. The three approaches were then compared in terms of classification accuracy. Alikhani et al. 9 used the pre-clustering method combined with K-means and self-organizing mapping (SOM) to classify the influencing factors of accident severity. Then the ANN and the adaptive neuro-fuzzy inference (ANFI) system were used to classify the severity (casualties or damage) of road accident. Lee 10 proposed a classification model of road traffic accident to predict the severity of road traffic accident injury. The famous classification methods, decision tree, neural network model, and Bayesian network (BN) were used to generate the classification model. BNs can be used to predict complex systems without presupposition and to graphically represent complex systems with related components. Juan et al. 11 analyzed 1536 accidents on rural highways in Spain. They proposed the possibility of using BNs to classify traffic accidents according to their injury severity. The results showed that intelligent classification model had higher classification accuracy and generalization. (e.g. Xie et al. 12 compared three models of back-propagation neural network (BPNN), Bayesian neural network (BNN), and negative binomial (NB) regression model using the data collected from rural street-front roads in Texas. Meanwhile, they evaluated the application of BNN model in vehicle collision prediction. The results showed that BNN model had better generalization ability. It could effectively alleviate the over-fitting problem without significantly reducing the nonlinear approximation ability.)
At present, most of the researches focus on the specific space–time conditions (e.g. highways, intersections, and tunnels with obvious external characteristics) instead of the general law of regional road traffic accident. In the research of the influencing factors of accident severity, the factors that can be easily quantified and reveal the law of accidents (e.g. road alignment, traffic flow, and lane width) are often easier to be extracted in the subsystems of human, vehicle, road, environment, and accident. Therefore, taking the data of road traffic accidents as a candidate for influencing factor index, SVM is used to establish the classification and recognition model of the severity of road traffic accidents. It was noted that there were many statistical factors of accident data with big scales, and too many dimensions and levels could affect classification accuracy and calculation speed. In this article, the main elements of sample information were extracted by using rough set theory. The method could effectively deal with the data (which were imprecise, uncertain, and incomplete) and obtain hidden knowledge, thus revealing the potential law. It was in line with the fundamental requirement to analyze the causes of accidents from the statistical data of traffic accidents. And the method could optimize and simplify the input of classification and recognition model, thus improving the calculation speed and classification accuracy of the model.
Research methods
Rough set theory
Rough set theory is an effective tool to deal with the information that is imprecise, inconsistent, or incomplete. On one hand, it benefits from its mature mathematical foundation and does not need prior knowledge; on the other hand, it is easy to use. 13 Rough set theory is a natural method of data mining or knowledge discovery, due to the purpose of the theory is to analyze and infer the data directly, discover the hidden knowledge, and then reveal the potential rules. Compared with the data-mining methods based on probability theory, fuzzy theory, evidence theory, and other theories of dealing with uncertainties, the most striking difference is that it does not need to provide any prior knowledge except the data sets that the problem needs to be processed. Without the need of additional information and prior knowledge, the existing information can be used to recognize the classification and importance of objects in specific conditions.14,15
Rough set theory was used to reconstruct and simplify the factors affecting the severity of traffic accident. The classification process mainly includes the establishment of traffic accident information decision table, which was used to express the knowledge representation system of traffic accidents; the combination and classification of traffic accident information attributes; the selection of influencing factors satisfying the characteristics of data samples; and the calculation of the attribute importance in each single factor (“people, vehicles, roads, environment, and accident”) to the severity of traffic accident. By ranking the importance of attributes, the variables that had a significant impact on the severity of road traffic accident were selected as eigenvectors. 16 The process of the algorithm was shown in Figure 1.
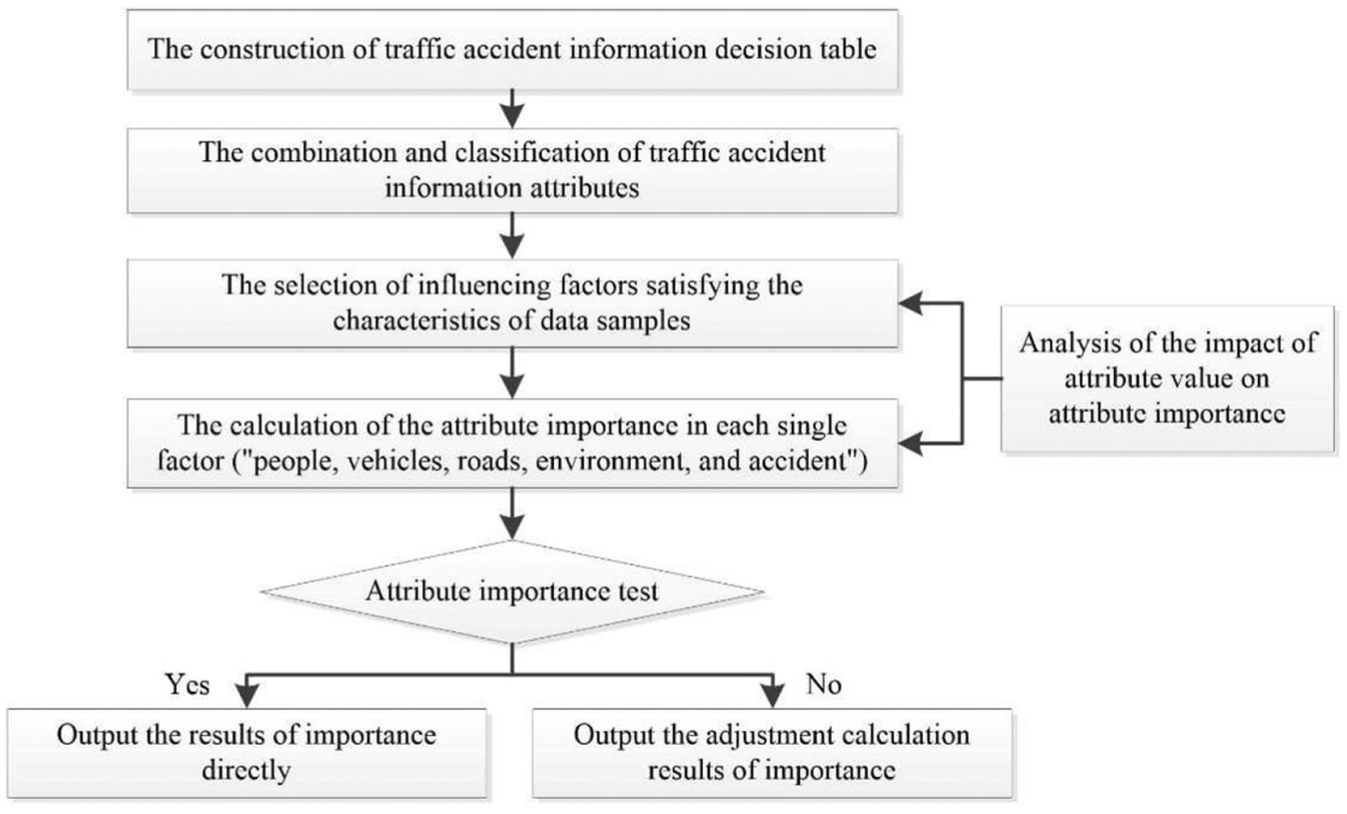
The process of mining algorithm of traffic accident based on rough set theory.
SVM
SVM is a supervised classification algorithm based on Vapnik–Chervonenkis (VC) dimension theory of statistics and structural risk minimization theory. Among the classification models or the classification methods, SVM can find the best compromise between model complexity and learning ability based on the limited information of samples. The basic idea of SVM classification is to construct an optimal classification hyperplane as a decision surface. The surface divides the sample space into two parts, which correspond to the two classes of the two classifications, respectively, so as to maximize the isolation edge between the two classes of samples. It has fast classification speed and strong applicability for the small samples. Because of that, SVM is a powerful tool in the field of classification. It can solve practical problems and overcome the disadvantage that neural networks are easy to fall into local optimal solution.17–19
From the perspective of data mining, the severity of road traffic accident could be regarded as the classification results of SVM.
20
For linear separable sample set,

The optimal classification hyperplane determined by the optimal solution

Road traffic accident data sets are nonlinear and separable. At this time, any classification hyperplane would have misclassified samples. It was necessary to introduce nonnegative relaxation variables
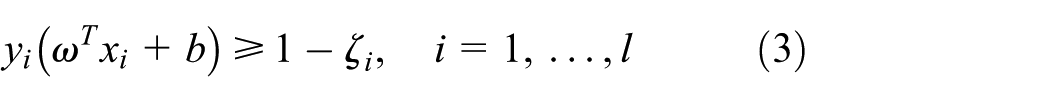

When the data set was linearly inseparable, SVM realized the nonlinear transformation of the linearly inseparable sample by the kernel function satisfying Mercer’s condition. The decision function mapped by the kernel function was shown in equation (5)

After reconstructing and simplifying the influencing factors of traffic accident severity using rough set theory, the establishment of classification and recognition model based on SVM included two stages—(1) training stage: SVM model was trained after establishing data samples based on input and output variables of classification recognition model, and (2) prediction stage: using the trained SVM model, the traffic accident samples with unknown output variables were predicted, and then the classification results of severity were obtained.
The classification and recognition model for the severity of road traffic accident
The l sets of traffic accident data samples were given. The influencing factor of the severity of road traffic accident was X, and
Step 1: Selection of input and output variables. (1) The characteristics of traffic accident data were analyzed, and information decision table based on rough set theory was established, in order to express the knowledge system of traffic accident. (2) The factors influencing the severity of traffic accident were combined and reconstructed. Then the importance of attributes contained in human, vehicle, road, environment, and accident was calculated by rough set theory. By ranking the importance, the variables that had significant impact on the severity of road traffic accident were selected as the eigenvectors of the model input. (3) Determination of output variables: the severity of road traffic accidents was selected as output variables of the model, and the classification labels of the accident severity were defined as two types—general accident and severe accident.
Step 2: Selection of study samples—The statistical data of road traffic accidents and related influencing factors were selected as research samples. The research samples were divided into training samples and test samples. The training samples were used for learning and training of SVM, and the test samples were used to verify the validity of the model after training.
Step 3: Selection of kernel functions—The sets of road traffic accident data are nonlinear and separable. In dealing with nonlinear samples, the radial basis function (RBF) kernel is superior to other kernels in SVM classification kernels. 21 Due to that, RBF kernel was selected as the kernel function of the classification model; the RBF kernel was expressed as equation (6)

Step 4: Optimization of structure parameters—The structural parameters of classification and recognition model mainly included the penalty parameter C and the kernel function parameter
Step 5: Model training—By reconstructing and simplifying traffic accident data as the training samples and using RBF as the kernel function, the SVM model was trained according to the structural parameters obtained by step 4. Cross-validation (CV) is a commonly used method of model accuracy testing. The accuracy testing method based on CV was selected to evaluate the model in the training process.
Step 6: Model prediction—The trained SVM model was used to predict the severity of traffic accident test samples, and then, the prediction results were substituted into step 7.
Step 7: Model evaluation—The test results were compared with those predicted by the model using SVM alone.
Step 8: Output model evaluation results.
Empirical study
Characteristic analysis of data set
A large number of real and reliable traffic accident data were provided by the Traffic Accident Research Institute of China Automotive Technology and Research Center. In this article, accident data of one region in China from 2006 to 2013 were selected as the object of empirical study. There were 4320 accident information from database system in all, including 2042 property damage accidents, 1922 injury accidents, and 356 fatal accidents. Characteristic variables of influencing factors of road traffic accidents were from “Accident Basic Information” data set.
Establishment of decision table of traffic accident information
Traffic accident data presented super-spatial structure which was radial, multidimensional, and multilevel. According to rough set theory, its sample matrix could be regarded as a knowledge representation system—the knowledge representation system of traffic accident. Therefore, in the sample matrix of traffic accident data, each column corresponded to one attribute of rough set, and each element to one attribute value of corresponding attribute in its column. According to the different types of attributes, the attributes were divided into conditional attributes and decision attributes. Then the decision table of traffic accident information was established. The decision table of traffic accident information was shown in Table 1.
Decision table of traffic accident information.
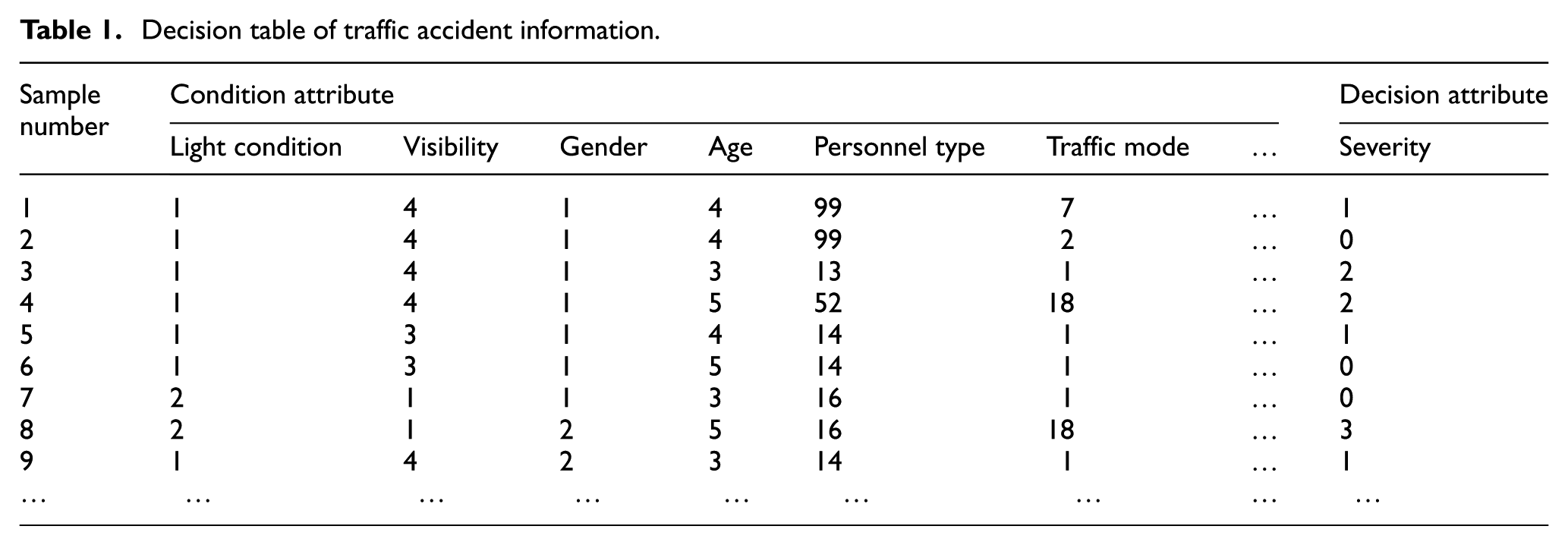
There was a total of 54 attributes in the accident database. In addition to the decision attribute of traffic accident severity, the remaining 53 were conditional attributes. Due to the conditional attributes contained many kinds, they had a certain degree of complexity. In order to facilitate analysis, 53 conditional attributes were combined and classified. In this article, the initial dimension of conditional attributes was simplified by analytic hierarchy process (AHP). Emphasis was laid on the establishment of attribute sets of personnel information, vehicle information, road information, environment information, and accident information.
Calculation of importance of each attribute in “people, vehicles, road, environment, and accident.”
Taking 4320 road traffic accident data in a certain area of China as the analysis objects, the severity of traffic accident was selected as the decision attribute of each decision subtable. The accident samples in the database included simple accident samples. These accidents referred to minor vehicle scratch accidents. The attribute values of each factor of minor accidents might not be complete; therefore, the sample size of 53 factors in the whole data system was incomplete. Therefore, first, the 53 attributes were classified into five types of attributes: human, vehicle, road, environment, and accident. Then the importance of each attribute based on rough set theory was calculated. According to the importance ranking of condition attributes to the severity of traffic accident, the attributes with higher importance were selected as input variables of SVM classification model to meet the capacity requirements of sample attributes. The analysis results of the importance of 53 conditional attributes in each attribute type were shown in Tables 2–6.
Importance of human’s attributes to traffic accident severity.

Importance of vehicle’s attributes to traffic accident severity.

Importance of road’s attributes to traffic accident severity.

Importance of environment’s attributes to traffic accident severity.

Importance of accident’s attributes to traffic accident severity.

SVM modeling and calculation
Based on the comparison of the importance of attributes, the establishment of independent variable set (including driver attributes, vehicle attributes, driving environment attributes, road attributes, and accident attributes) was focused on with 30 variables by summarizing the data that we had consulted. Thus, the factors that had significant influence on the severity of traffic accident were screened out. At the same time, the computational complexity of the model was reduced. It was worth mentioning that the variable assignment was based on the past experience in road traffic accident research, and the attribute variables were shown in Table 7.
Attribute variables definition.

With the MATLAB software platform, SVM package was used for SVM modeling based on empirical data and kernel parameter optimization. The algorithm of sequence minimization was used to solve the problem. Considering the observed number of fatal accidents was only 356, two classification labels were defined for accident severity—general accidents (2042 events, accounting for 47.3%) and severe accidents (2278 events, accounting for 52.7%), which included injuries (1922 events) and fatalities (356 events).
In stratified random sampling, 30% of the samples were used as training set and 70% were used as test set. The parameter of CV was set 5 during training. In the process of optimizing nuclear parameters by genetic algorithm, the number of iterations was set to 100 and the number of population was set to 20. The optimum combination of the corresponding parameters was obtained by using MATLAB software:

The iterative process of parameter optimization.
According to the optimized structural parameters, a prediction model of traffic accident severity based on sample data training was established. Based on the data of test set, a classification and recognition model combining rough set theory with SVM was used to predict the severity of traffic accident. The test results were compared with those predicted by the model using SVM alone. Table 8 showed the different effects.
Optimum contrast.

SVM: support vector machine.
Conclusion
Taking the traffic accident data provided by the Traffic Accident Research Institute of China Automotive Technology and Research Center as the samples, the classification and recognition model of the severity of road traffic accidents based on rough set theory and SVM was proposed in this article. The main tasks were as follows. (1) After analyzing sample data, the decision table of traffic accident information was established. (2) Through rough set theory, the significant degree of each attribute in “people, vehicles, road, environment, and accident” was obtained. By ranking based on importance, the variables were reconstructed and simplified, which improved the scientificity of input parameters and the accuracy of the model. (3) Two classification labels of general accident and major accident were set up. Data samples were built based on input variables and output variables of the classification recognition model. The SVM model was trained. Then the trained SVM classification recognition model was used to predict traffic accident samples with unknown output variables, and the classification results of the severity were obtained. Finally, an example was given to verify the validity of the model.
The results showed that compared with a single classification method, the combined classification method based on rough set theory and SVM had high fitting ability and prediction accuracy. Meanwhile, it could improve the calculation speed under the condition of large data quantity, thus better realizing the identification and prediction of the severity of traffic accidents in regions or road sections.
In the specific application process of SVM, the choice of its kernel function and insensitive loss parameters have a great influence on the prediction effect. At present, there is no more effective way to reasonably select these parameters. The next step should be to focus on how to use the relevant optimization algorithm to reasonably select SVM parameters. In addition, this article only models the severity of traffic accident by two classifications. In the future research work, the severity of traffic accident can be modeled according to the three classifications of classification labels under the premise of considering the number of deaths, injuries, and direct property losses.
Footnotes
Handling Editor: Hai Xiang Lin
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.