
Abstract
The problem of state-space explosion and state reachability decision has been a focus in Petri net analysis. In this article, some algorithms based on data features of state space are proposed for state-space reduction and reachability analysis in Petri nets. A caching arrangement algorithm for the state reachability graph is proposed to alleviate the memory overhead when all states are generated by a traditional reachability graph generation algorithm. For the reduction of the state space, a compression algorithm based on a hybrid coding is formulated. The changing characteristics of state elements are fully utilized to realize a sharp reduction of the whole state space. For the state reachability analysis, a state reachability retrieval algorithm based on the locally sensitive hashing is reported. In this algorithm, all the states in the compressed state space are distributed to different hash buckets according to the distances among the states, which realize the primary state retrieval efficiently. Then, a state retrieval strategy that reverts the primary retrieved state to its original data is adopted. Finally, the proposed compression and retrieval algorithms are validated on several Petri net models, showing high compression efficiency and exact accuracy of state retrieval.
Introduction
Petri nets, a formal modeling tool invented by CA Petri, 1 have been applied to many fields, such as control of discrete event systems,2–17 system reliability analysis,18–23 modeling, analysis, control,24–33 and the verification of communication protocol. 34 In the analysis of Petri nets, state-space techniques are used in marking reachability, forbidden states including deadlock control,35–37 opacity verification and enforcement, and fault diagnosis.27,38–45 Unfortunately, the size of a state space has a tendency of growing exponentially with respect to the structural scale of a Petri net, which is known as the state-space explosion problem (S2EP). 46 It hinders the development and applications of Petri nets due to the limited capacity of a real computer system in processing a large-size state space. Meanwhile, the state reachability analysis (SRA) is the most fundamental dynamic issue of a discrete event system; many other properties or problems of discrete event systems, such as the deadlock prevention, supervisory control design, and fault diagnosis, can be converted into the reachability problem. The state-space compression and reachability analysis methods show vital significance to alleviate the state-space explosion and analyze the pertinent properties of Petri nets.
Much work concerning state-space compression or reduction has been done to tackle the S2EP. 47 The study in Schmidt 48 uses place invariants and transition invariants to construct the state space of a Petri net. The place invariants which reduce the number of places of every marking show superiority over time and space. Meanwhile, the transition invariants which decrease the number of markings present a slight strength in space with low time efficiency. However, combined with the partial-order compression method, transition invariants in Schmidt 48 manifest a remarkable improvement in space and time.
A partial-order reduction 49 method exploits the independence of concurrently executed events to address the S2EP. It reduces the size of reachable state set by a cycle constraint and allows portions of the state space to be pruned. The method usually shows satisfactory performance in memory consumption. The minimal coverability sets method by Piipponen and Valmari 50 deals with two key problems to construct minimal coverability sets. One is to explore conditions or criteria under which a marking is converted to a finite coverability set of reachable markings. Another is to preserve the maximal coverability set with data structures based on binary decision diagrams and covering sharing trees. The method presents excellent time efficiency, but its internal memory consumptions are huge.
In Clarisó et al., 51 an abstract interpretation method is proposed. It includes two abstract domains and uses linear inequalities and polynomial equalities to derive non-structural invariants. The abstract interpretation has good performance in the state-space reduction but poor reachable state verification. The work in Emerson and Wahl 52 proposes a dynamic symmetry reduction method by using a symbolic algorithm to generate the reachable state set. In the light of the symmetry of the fired path among states, the algorithm calculates dynamically respective representation symbols of states and ensures the uniqueness between symbols. While the state reachability graph is generated, states are sequentially mapped to their representative symbols. Finally, all the reachable states are equivalently characterized by representative symbols to achieve the reduction of state space.
The transitions merging method by Kurshan et al. 53 compresses a sequence of transitions into a single transition to eliminate the interim states. The authors of Bozga et al. 54 apply a live variable reduction method to construct equivalence representations on a system model by dead values unused either in variables or in queue contents, which simplifies the state space with a rather considerable ratio.
McMillan 55 proposes a net unfolding method that constructs a finite prefix by unfolding the net and forms an occurrence net. The unfolding will be ceased when the occurrence net structure generated is sufficient to characterize all the reachable markings. This occurrence net, simplifying the overlapping transitions among concurrent events, avoids the state explosion problem in the process of searching the whole state space. In view of the fact that the finite prefix constructed in McMillan’s net is too large, an improved method is proposed in Esparza et al. 56 The method makes the number of non-truncated events less than the total number of reachable states by employing the adequate orders, which can effectively realize the reduction of the state space.
In general, previous works present the high compression efficiency with varying degrees, which are usually based on a good understanding of the structure of Petri nets. Meanwhile, these compression methods may confront with a complicated search issue and data structures issues based on the reachability graph and net structure. The S2EP and SRA problems are coupled with each other and the methods of the state compression and state retrieval must be considered systematically. A universal compressed and retrieval method is credible, which does not involve the complex structure of Petri nets.
In this article, focusing on data characteristics of the state space in Petri nets, we propose three algorithms to deal with the S2EP and SRA problems. First, a caching arrangement algorithm for the efficient generation of state reachability graph is proposed. Then, to reduce the state space, a compression algorithm based on the hybrid coding is proposed, in which every state is compressed. Finally, for the SRA, we propose a state reachability retrieval algorithm based on the locally sensitive hashing algorithm, which implements data classification on the basis of the distance similarity and achieve highly efficient data retrieval.
The rest of this article is organized as follows. Section 2 introduces the basic concepts of Petri nets. The proposed caching arrangement of the reachability graph method is described in section “Caching arrangement of the reachability graph algorithm” in detail. Section “Basic methods on data compression and retrieval” presents some basic methods in data compression and retrieval for a better understanding of the reported algorithm. The proposed compression method is described in section “State-space compression based on hybrid coding.” In section “State reachability retrieval based on locally sensitive hashing,” a state retrieval algorithm is developed. The experimental results are given in section “Experiment” and the conclusions are reached in section “Conclusion.”
Petri nets
A Petri net is a four-tuple N = (P, T, F, W), where P = {p1, p2, …, pm} is a non-empty finite set of places drawn by circles in which the number of black dots indicates the amount of tokens in a place, and T = {t1, t2, …, tn} is a non-empty finite set of transitions drawn by rectangles with P∩T = ø, and F ⊆ (P × T)∪(T × P) represents a flow relation drawn by arcs with arrows from places to transitions or from transitions to places. W: (P × T)∪(T × P) →
A marking M called a state of a Petri net N is a mapping P to N, where M(p) denotes the number of tokens in place p. (N, M0) is called a net system or marked net with an initial marking M0. A marking M is usually represented by a |P|-dimensional vector M = [M(p1), M(p2), …, M(p|P|)] that indicates token distribution of all places.
A transition t ∈ T is enabled at M, which is denoted as M [t〉, if M(pi) ≥ W(pi, t) for any pi ∈ •t. Then, a new marking M′, defined by M′ (pi) = M(pi) − W(pi, t) + W(t, pi), for pi ∈ •t, is reached by firing t from M. The fact is denoted as M[t〉M′. Marking M′ is said to be reachable from M if there exist a sequence of transitions σ = t0, t1, …, tn and markings M1, M2, …, Mn such that M [t0〉M1[t1〉M2,·…,·Mn [tn〉M″ holds. The set of markings reachable from M in N is called the reachability set of Petri net (N, M) which is denoted as R(N, M). The state space of a Petri net N consists of all reachable markings from the initial marking M0.
The state space of Petri nets N can be represented as an m × n matrix
The first row denotes the initial marking M0.
Every row in matrix
All rows in matrix
The matrix
A Petri net example is presented in Figure 1(a). It consists of five places P = {p1, p2, p3, p4, p5}, six transitions T = {t1, t2, t3, t4, t5, t6}, and the initial marking M0 = (1, 0, 0, 0, 0). Its state-space reachability graph
57
is shown in Figure 1(b). The state space composed by all markings can be represented by a 5 × 5 matrix

A simple Petri net model. (a) A Petri net example. (b) The state-space reachability graph of the Petri net ((a)). (c) The state space of the Petri net described in matrix
If any marking can be found from the rows in matrix
Caching arrangement of the reachability graph algorithm
For the study of the state space in a Petri net, the traditional process 58 is to generate the whole state space, named the original data in this article, and then conduct the subsequent compression process. When the scale of a state space reaches a certain degree, the reachability graph is hardly possible to be stored due to the limited memory. 59 The relationship between the state count and the number of philosophers in the classic dining philosopher systems (DPS 60 ) is shown in Figure 2, where the drastic increase in the system brings state explosion, which leads to block the study of the state compression itself.

State-scale counts of DPS with the number of philosophers.
In order to alleviate the storage issue caused by the state explosion before compressing the state space, a caching arrangement algorithm of the reachability graph shown in Table 1 is proposed as follows.
The caching arrangement algorithm of the reachability graph.

In Table 1, each unlabeled reachable state M is enabled and fired to generate a new marking M′, and the state M′ will be stored in the caching region. Once the number of states stored in the caching region reaches the MaxNum, all the states in the caching region will be extracted for the subsequent state compression process. Then, the caching region is cleared. The above procedure is conducted circularly until the whole reachability graph has been gained. The algorithm depends on equation
Basic methods on data compression and retrieval
The methods of data compression consist of lossy and lossless based on the degrees of information distortion. A lossy compression method is mainly applied in a low accuracy scene and can reach a good compression efficiency. In comparison, the lossless compression has a low compression efficiency, but meets a high-accuracy requirement. In this article, we focus on the lossless compression. The proposed method of data compression consists of the Run-Length Encoding (RLE), Golomb–Rice coding, and adaptive prediction encoding, while the retrieval method is the locally sensitive hash (LSH), and the measure method in data retrieval utilizes hamming distance.
The RLE
The RLE61,62 based on the statistical coding is considered as a lossless data compression technique. In the RLE, the same values that occur in many consecutive elements are stored as the ordered pairs

A run-length coding principle example.
In Figure 3, a string of 18-bit 300000000011110000 has four runs (3, 1), (0, 9), (1, 4), and (0, 4). It is encoded as 8-bit 31091404 by the RLE. The RLE traces element values and its counts of strings by sequential scanning.
The Golomb–Rice coding
The Golomb–Rice coding,63,64 conducted mainly for non-negative integers, is a data compression method without loss of information in the coding process. The main idea of the Golomb–Rice coding is to use shorter encodings for smaller numbers and use longer encodings for larger numbers, that is, if the encoded value is smaller, the coding length is shorter. It achieves the purpose of data compression and saves the storage space.
The Golomb–Rice coding uses an adjustable parameter m and a block encoding method, by which the input string x is divided into two parts consisting of the group number q and the remaining part r. q and r can be calculated by the following formulas. The symbol % denotes the remainder operator


After the input string x is divided, a unary coding is used for encoding q. The unary coding is a simple encoding method for non-negative integers only. Given a non-negative integer num, its unary coding is composed of num “1” plus “0.” An encoding example is given in Table 2.
The unary coding example.

Meanwhile, a fixed-length binary coding is conducted to encode r, which means that the low
The adaptive prediction encoding
The main idea of the predictive coding65,66 is described as follows. First, a mathematical model is established to predict the current sample point by using historical sample data, and then, the difference value is obtained by subtracting the current actual value by the predicted value. As a result, the difference value that is relatively small can be encoded to achieve the compression purpose. The predictive coding diagram is shown in Figure 4.
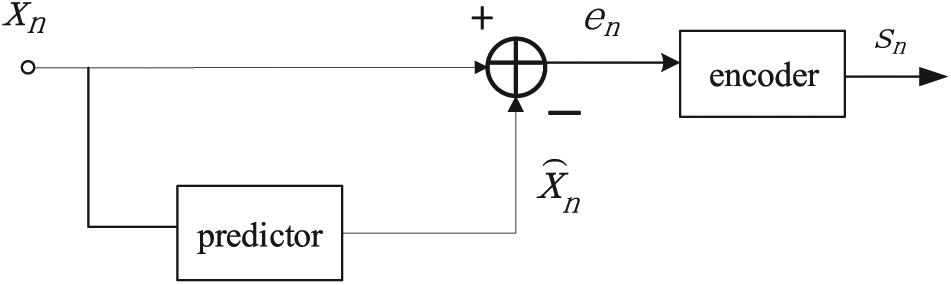
The component diagram of the predictive coding.
The predictor forecasts value xn that is currently being encoded through the previously encoded data. Thus, the predicted value
The adaptive predictive coding 67 is a nonlinear prediction method. In the processes of data prediction, the adaptive prediction method corrects and adjusts constantly the predictive coefficient by analyzing the statistic characteristic and the variation of the original data, which makes the predictor change with the input data and obtains the ideal output of the predicted value finally. The schematic diagram is shown in Figure 5.
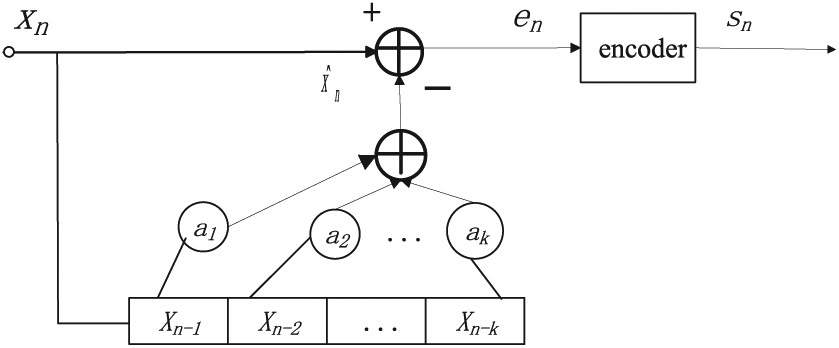
The component diagram of the adaptive predictive coding.
In Figure 5, the current sample xn is predicted by the nonlinear combination of some sample Xn–1, Xn–2, …, Xn-k before the current coding. The predictive value formula of the adaptive predictive coding is shown as follows

where the predictive coefficient a(i, n) is related to the information source Xn-i. After the predictive value is achieved, the error value en can be subsequently computed by equation (4)

The error value en is the difference value between xn and its predicted value
LSH
As an efficient approximate query method, the locally sensitive hash (LSH)68,69 is applied to mass data query. For a given mass data set, the set is chronologically mapped into binary codes called the hash value by a series of hash functions hi() (i = 1, 2, …, n). The nearer data are hashed to the same hash value named the hash bucket by a large probability. As a result, the query efficiency can be much improved. The LSH schematic diagram is shown in Figure 6.

The LSH schematic diagram.
For a series of hash functions H = {h1(), h2(), …, hn()}, H is a mapping from the original data set X to the hash code space U, that is,
If
If
In the above, P [.] denotes the probability of mapping the two points to the same hash bucket. The LSH definition indicates the probability relation of the data distance. The relationship curve of the distance and the probability is shown in Figure 7.

Probability with the data distance.
As shown in Figure 7, the distance versus probability curve is a monotonous decline. The key segment is the critical distance between r1 and r2. When the distance is greater than r1, the probability of mapping into the same hash bucket is very high and greater than p1, but it is rather minute-less than p2, when the distance is less than r2. Therefore, the main focus is just on the interval between (0, r1) and (r2,+∞).
Hamming distance
Hamming distance, 70 mainly implemented by adding up the sum of different values in the same location between two code words, is a measure methodology of the distance similarity. If X and Y are two code words with their length being n, the hamming distance is defined as follows

In equation (5), xi denotes the ith bit value of the code word X and ⊕ represents the XOR,
State-space compression based on hybrid coding
From the view of data characteristic, if the state space of a Petri net is represented as a matrix
For every element in

State-space matrix
Motivated by the variation property of

Flow diagram of the state-space compression algorithm based on hybrid coding.
Computation of local difference values
Since the elements in

Illustration of the context.
In Figure 10, the adjacent elements a, b, c, d, and e of the current encoding element x constitute the context of x, which implies the characteristics of local data variability of x. The difference values gi (i = 1, 2, 3, 4) between x and its adjacent elements are given as follows
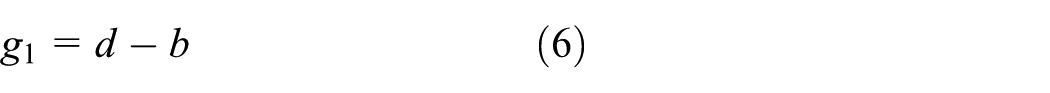

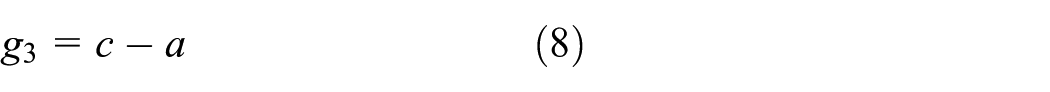

The difference values gi can effectively decide the variation intension of x’s adjacent elements and make a preparation for the subsequent encoding mode choice and the predictive value computation in the predictive encoding mode.
Encoding mode selection
Through the computation of the adjacent difference value gi of the current element, the encoding process enters the coding mode selection phase. The encoding mode selection process is shown in Figure 11.

Flow diagram of the encoding mode selection process.
If the difference value gi is zero, the algorithm chooses the predictive coding mode where the location variation of the element x is active; otherwise, it chooses the RLE code where x′ local variation is steady and continuous.
The predictive value computation
The data model is generally built via the characteristic of the adjacent elements of the current sample by traditional adaptive predictive encoding method.
71
However, the algorithm complexity is high using this method. In this article, a first-order edge detection mechanism is employed to compute the predictive value during the predictive encoding, which achieves a good predictive effect with low complexity. The predictive value

For the context in Figure 10, the predictive value computation is conducted by choosing the maximum among a, b and a + b − c. The most outer elements e and d of x are not used in the predictive value computation. This makes the computation simpler and more effective.
RLE mode
The RLE mode 72 is executed when the data set vary consistently.
State reachability retrieval based on locally sensitive hashing
From the perspective of matrix

The procedure block diagram of the proposed state reachability retrieval algorithm.
Normalization of state length
Since the lengths of compressed states are unfixed by the previous hybrid coding algorithm, we need to make the lengths of states consistent before applying the locally sensitive hashing method. First, the maximal length Lmax is given by equation (11)

where n denotes the count of reachable states and Mi represents the ith state. The functions length() and max(), respectively, denote the calculation of the vector dimension and the maximum value. When the length of a state in the state space is less than Lmax, we append zero element to the state such that the state lengths are constant in the end.
Establishing the hash index structure
Constructing an effective index structure is a key point in LSH algorithm, which can achieve an efficient query of given states. The aim of constructing the index structure is to acquire hash functions.
Given p = (x1, x2, …, xn), the hamming code of p is defined as follows 73

where Unary k (xi) denotes that the first xi bits are 1 and v(p) is the combination of the sequence Unary k (x1), …, Unary k (xn).
Any one of hash functions h can be constructed by the following method

where r() means rth bit of v(m) and r is the random integers subjected to the uniform distribution. The hamming code of state m is denoted as v(m). This random construction of hash functions in locally sensitive hashing is handler and more applicable.
The compressed state space M = {M0, M1, …, Mn} is the queried data set. First, a series of random hash functions hi(.) are generated to initialize l hash tables. After the initialization of hash tables is finished, states Mi are mapped into different hash buckets by hash functions. The constructing of the hash index structure mainly classifies the state set and reduces dimensions of states, which contributes to an efficient state query in the next.
Primary state retrieval
After the index structure of
Fine retrieval by returning
An unreachable state can be retrieved from the state space by a mistake, since the unreachable state or the retrieved state may be mapped into the same hash bucket. Therefore, an accurate state retrieval is introduced via returning the retrieved state q and the candidate state S1 to their original states Qin and Min, that is,. the states before being hashed. Then, Min and Qin are compared to decide whether they are equal. If Min and Qin are equal, the retrieved state q is a reachable state. The fine state retrieval method realizes accurate reachability analysis with little time consumption.
Experiment
Experiment models
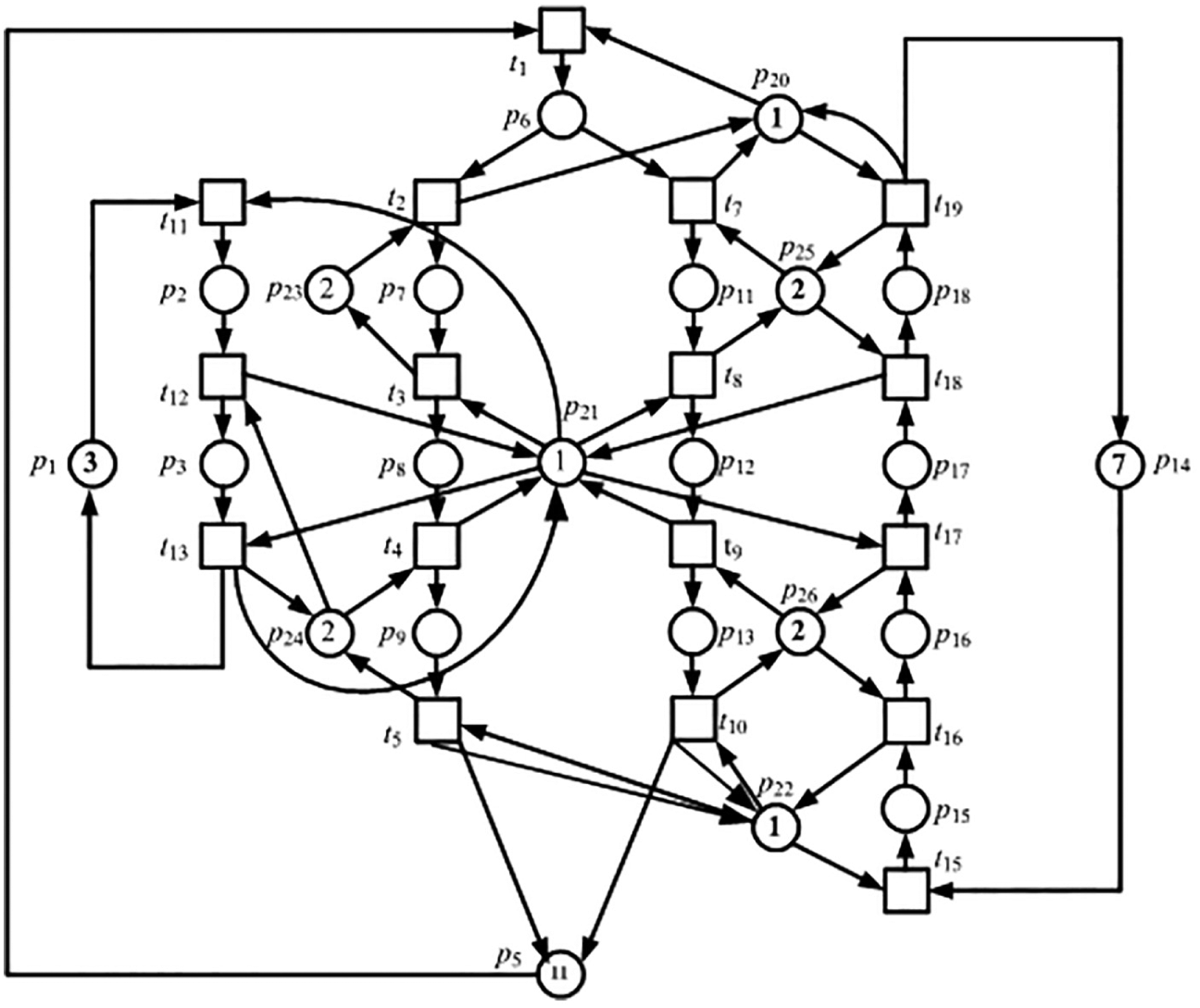
This section conducts experiments to discover the state-space compression ratio and state retrieval time by applying the proposed methods. The first experiment is devoted to a Petri net model of a flexible manufacturing cell that consists of 26 places p1–p26 and 20 transitions t1–t20.
7
The model shown in Figure 13 can yield an immense reachable state space that contains 26,750 reachable states denoted by a 26,750 × 26 matrix

The Petri net model of a flexible manufacturing cell.
Another experiment is conducted for the classic DPS. As a typical control representative of concurrent systems synchronization, mutual exclusion, and deadlocks, the dining philosopher model is widely used in Petri net modeling and analysis. Since the number of philosophers is variable, the Petri net model of DPS is extensible, and its extension has a structural symmetry. A fundamental unit of DPS is shown in Figure 15.
In Figure 14, pi denotes the ith philosopher’s place when pi + 1 represents the (i + 1)-th philosopher’s place and so on. For this experiment, 6, 7, and 10 philosophers are, respectively, chosen as the subject to be investigated. The related parameters of the chosen models are described in Table 3. The size of the state-space matrix
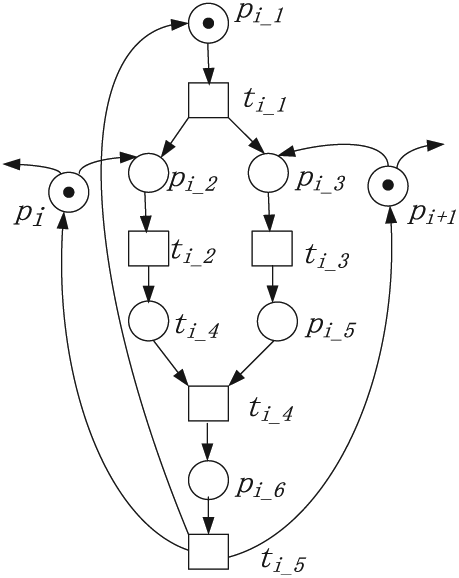
The fundamental unit of DPS.
The related parameters of Petri nets in DPS.

The evaluation index on algorithm performance
This article mainly focuses on the state-space reduction and state reachability, for which the state-space compression algorithm based on hybrid coding and the state reachability retrieval algorithm based on locally sensitive hashing are proposed. The evaluation indexes in compression and retrieval algorithm performance need to be considered for their assessment. For the compression algorithm, the compression ratio is an important evaluation index, reflecting the compression degree of the compression algorithm on the Petri net state space. The compression ratio CR is defined as follows
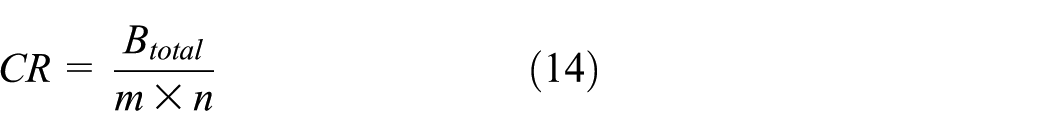
where m × n denotes the size of
For the proposed retrieval algorithm, the retrieval time is regarded as a critical evaluation index. The retrieval time RT is defined as follows

where tstart and tend, respectively, denote the time of submitting the query requirement and that of returning the query result. In most cases, many models need to be tested in a retrieval algorithm, leading to various experimental results. For a clearer analysis, the average retrieval time

In equation (16), k and RTi denote the number of retrieval and ith retrieval time, respectively. The average retrieval time can indicate the overall performance of the retrieval algorithms.
Experiment results and analysis
The experiment results of the state-space compression algorithm, compared with the RLE method under the same condition, are shown in Table 4.
The experiment result in the state-space compression algorithm.

Note: The bold value in table 4 shows the effective compression rate between the algorithm proposed in this paper and the RLE algorithm.
In Table 4, the proposed algorithm has better compression efficiency than the RLE. At best, the compression ratio of the proposed algorithm reaches 18.36%, which is about four times less than that in the RLE. Furthermore, the performance of the proposed algorithm manifests stability in multiple Petri net models. The RLE performs worst, with the compression ratio almost being 130% in the flexible manufacturing cell model.
Other experiment results of the state reachability retrieval are shown in Figure 15. Based on the location of the retrieved state in the state space, for convenient expression, four kinds of the retrieved states, namely, the initial state, the middle state, the final state, and the unreachable state are, respectively, labeled by numbers 1–4. The unreachable state is chosen by approximating the random reachable state. Meanwhile, the proposed state retrieval algorithm is compared with the linear search method. In consideration of the overall experimental performance of the retrieval algorithm, the average retrieval times based on four Petri net models are shown in Figure 16.
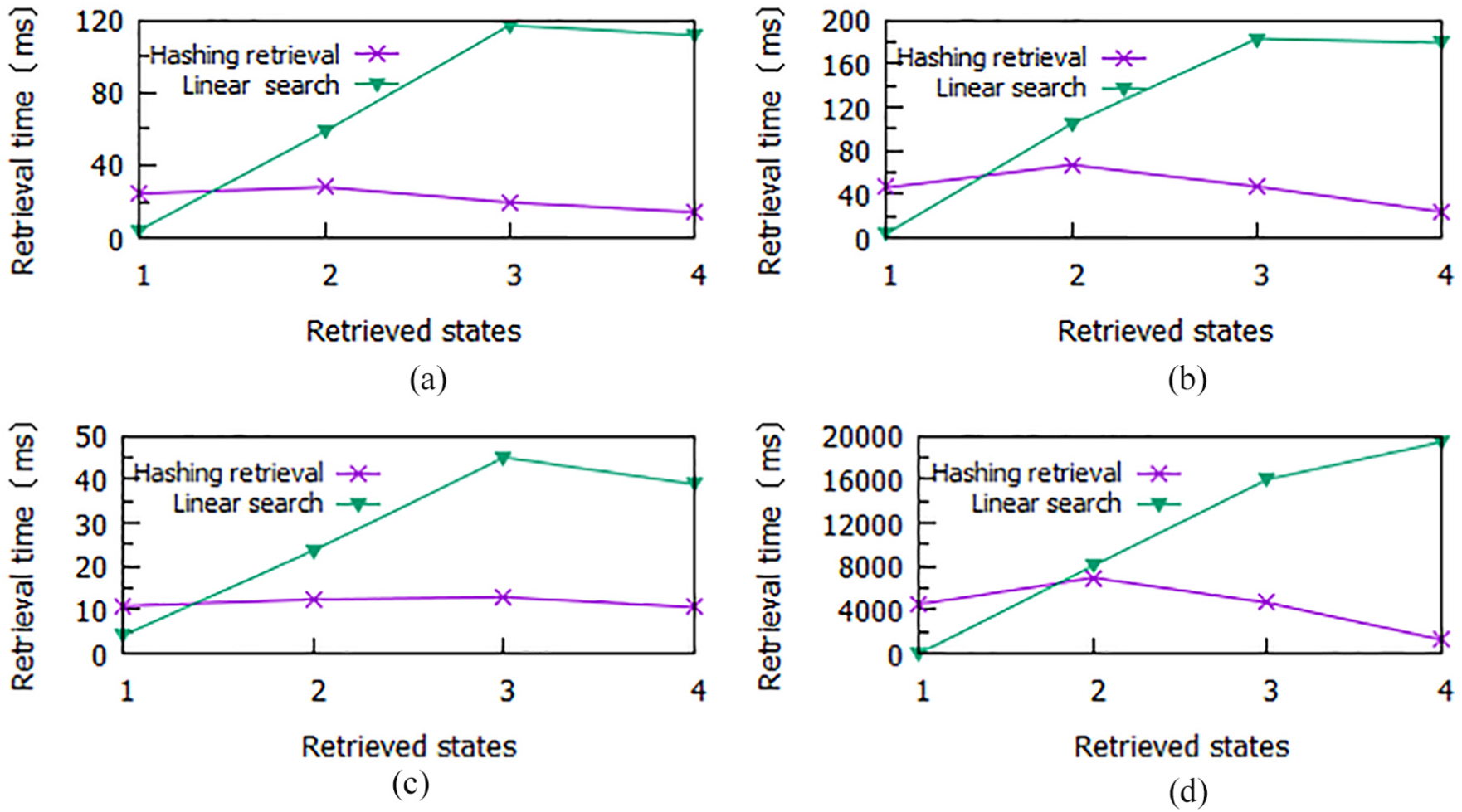
The experiment result in the state reachability retrieval algorithm. (a) Flexible manufacturing cell. (b) 6 dining philosophers’ system. (c) 7 dining philosophers’ system. (d) 10 dining philosophers’ systems.

The average retrieval time versus various retrieved states.
Figures 15 and 16 show that the hashing retrieval algorithm proposed in this article has better time efficiency in the state retrieval, especially in the final state and the unreachable state. Compared with the traditional linear search method, the proposed algorithm possesses more robust adaptation over various state positions and Petri net models. The average time of the proposed algorithm is about 1/15 that of the linear search at best. The linear search method appears to be unstable, where the retrieval time increases linearly, making it unsuitable for massive data retrieval.
Note that the Petri net reduction techniques originally reported in Murata 40 can be used for state-space reduction, as did by Uzam. 28 In this article, we can use this method to simplify a plant model first if the reduction rules in Murata 40 are applicable. For example, the net shown in Figure 13 with 26 places can be reduced as shown in Figure 17. The reduced version with 23 places has 11,880 reachable states. Then, we can use the proposed state compression algorithms to compress its states. The estimated compression ratio will be calculated as 39.75% × (11,880/26,750) × (23/26) = 15.62%.
Reduced version of the Petri net model in Figure 13.
Conclusion
This article explores the relation between the state compression and the state retrieval and constructs a solution. For the reachability graph generation, the proposed caching arrangement algorithm of the reachability graph effectively solves the storage problem of the complete state space. Based on the data characteristic of the states in Petri nets, a hybrid coding algorithm is proposed to make a lossless compression for the states. Meanwhile, locally sensitive hashing is introduced to conduct a state retrieval on the compressed state space. The experiments show that the proposed algorithms achieve good performance in the state compression and state retrieval, offering a promising solution for relevant problems in Petri nets. Nevertheless, the compression efficiency in the proposed method is not ideal because of a balanced consideration on the state compression and the state reachability retrieval. At the same time, much time is spent in constructing the hashing index of the retrieval algorithm. In the future, we will explore more efficient compression algorithms by combining the other compression technique and investigate the retrieval algorithm that has a more concise index structure.
Footnotes
Handling Editor: ZhiWu Li
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is partially supported by the Fundamental Research Funds for the Central Universities with Grant Nos. K50510040013 and K5051304007 and the Doctoral Students’ Short-Term Study Abroad Scholarship Fund of Xidian University. The authors extend their appreciation to the Deanship of Scientific Research at King Saud University for funding this work through research group number RG-1439-005.