
Abstract
Spatio-temporal context algorithm is commonly used in geology and has been introduced into the field of target tracking in recent years. The algorithm improved the robustness of visual tracking through dense contextual information around the target and thus achieved great tracking results. However, updating errors may occur in spatio-temporal context algorithm when the target has rapid changes in scale and appearance, resulting in the algorithm cannot extract the target area accurately and completely. In order to overcome this problem, this article proposes an improved spatio-temporal context algorithm based on scale correlation filter. First of all, the algorithm extracts samples of different scales around the target after the target is settled by spatio-temporal context algorithm and then forms the pyramid of scale characteristics through samples extracted by histogram of oriented gradients operator. Second, the best scale parameter will be achieved by means of scale correlation filter to update the scale model. Finally, the results show that the algorithm has good tracking effect and robustness through two experiments which are contrast experiment before and after the improvement of algorithm and comparison experiment with other advanced algorithms.
Keywords
Introduction
With the development of visual technology, visual tracking 1 has been widely used in people’s work and life, such as intelligent robot, video monitoring, factory automation, vehicle tracking, and video compression. The technology of visual tracking has attracted attention from researchers at home and abroad, thus the tracking algorithms with good performance emerge in an endless stream, including multiple instance learning (MIL), 2 compressive tracking (CT), 3 locally order-less tracking (LOT), 4 tracking-learning-detection (TLD). 5 The important step of visual tracking is to get accurate appearance models based on the visual characteristics of the target. However, it becomes a huge challenge for the development of visual tracking technique to build a robust appearance model owning to the appearance variation, illumination variation, background clutters, occlusion, and high-speed motion of the target. 6
According to appearance model, 7 there are two main categories of visual tracking algorithms: generative tracking and discriminative tracking. Generative tracking method could search for the best matching position through established target model and update the representation of the target by online learning mechanism. Chen et al. 8 have established generative appearance model based on estimation of probability of density to complete target tracking. Ross et al. 9 introduced the integral value transformation (IVT) method using an incremental subspace model to suit variations. Mei and Ling 10 have proposed a trivial model, which could complete tracking by few priori knowledge and update the model according to the similarity between the target and model dictionary under the framework of sparse representation target tracking. In addition, it will replace the model with the lowest similarity by a new one. In recent years, the generative tracking approaches based on kernel estimating, subspace, and sparse representation have become the hotspot. But the above methods are to complete the tracking through extracting and matching the features of the target while ignoring the importance of background information in the scene. Compared to generative tracking method, discriminative approach maximizing the separation of the target and background, then using the binary classification knowledge has been used to solve the problem of tracking. In order to cope with the problem of tracking failure caused by the target beyond the scope of the picture, Grabner et al. 11 propose to use a certain number of key points as supporters to locate the target, that is, to determine the most likely location of the target by using the vote results of the support points. Dinh et al. 12 first extract similar objects in the context as distracters and distinguish real target with distracters through a series of speeded up robust features (SURF) to complete the tracking when there are similar objects in the scene. In order to adapt the algorithm to the tracking task of complex scenes, Wen et al. 7 not only used spatial context and temporal context model but also established a support domain through SURF to ensure the effectiveness of tracking. Yang et al. 13 adopt data mining to segment some areas around the target as auxiliary objects and then conduct collaborative tracking to the auxiliary objects and target, achieving good results. The success rate of the above algorithms is based on obtaining a complete target model or obtaining rich target features, and this process will cost a lot of computation time, resulting in the failure to achieve real-time tracking. Besides, the extracted kernel points and auxiliary objects are sparse, leaving surplus area of context underutilized, thus reduce efficiency of the context information. In the view of these shortcomings, Zhang et al. 14 proposed a highly efficient spatio-temporal context (STC) algorithm. The algorithm fully utilized the dense context (compared to the sparse context above) around the target to complete tracking and achieved good results. It has surpassed most state-of-the-art trackers.
However, the accuracy of the STC algorithm will be reduced rapidly when the target scale and appearance changes quickly, which is caused by the error accumulation of the algorithm in updating the scale model. 15 To overcome the problem, the article proposed an improved STC algorithm based on scale correlation filter, which constructs a discriminative correlation filter based on scale feature pyramid to replace the original scale parameter update method in STC algorithm and achieve more accurate target scale estimation.
The contributions of this article are as follows: first, the STC algorithm is used as the basic framework, making full use of the context information around the target and using Bayes to calculate the target center position, so that the tracking algorithm has higher accuracy and robustness. Second, in contrast to traditional algorithm of STC, the scale correlation filter is introduced in the proposed algorithm, which makes the estimation of the target scale more accurate and can adapt to the rapid scale change of the target.
The remaining sections are arranged as follows: first and foremost, review the STC algorithm and its implementation process. In the second place, the content of the improved algorithm proposed in this article is introduced. Furthermore, introduce the process of our algorithm. Last but not the least, the article shows a large number of experimental results and obtains the final conclusion.
STC tracking algorithm
Since the spatial and temporal characteristics of the target background area are relatively stable, STC tracking algorithm is simple and effective to improve the accuracy of target location by using abundant background information. 16 The algorithm uses the extreme search process of the target’s confidence map in the current frame to replace the tracking process. In the first frame, STC algorithm first calculates a confidence map according to the correlation formula and then takes the position of the extreme of the confidence map as the center of the target. In the current frame, the location of the target center is represented by x*, the context features can be defined as
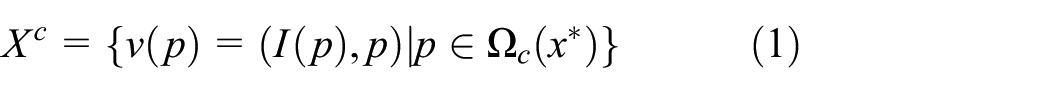
where p represents point coordinates in the frame, and I(p) represents the gray value of the point p. Around the target center x*,
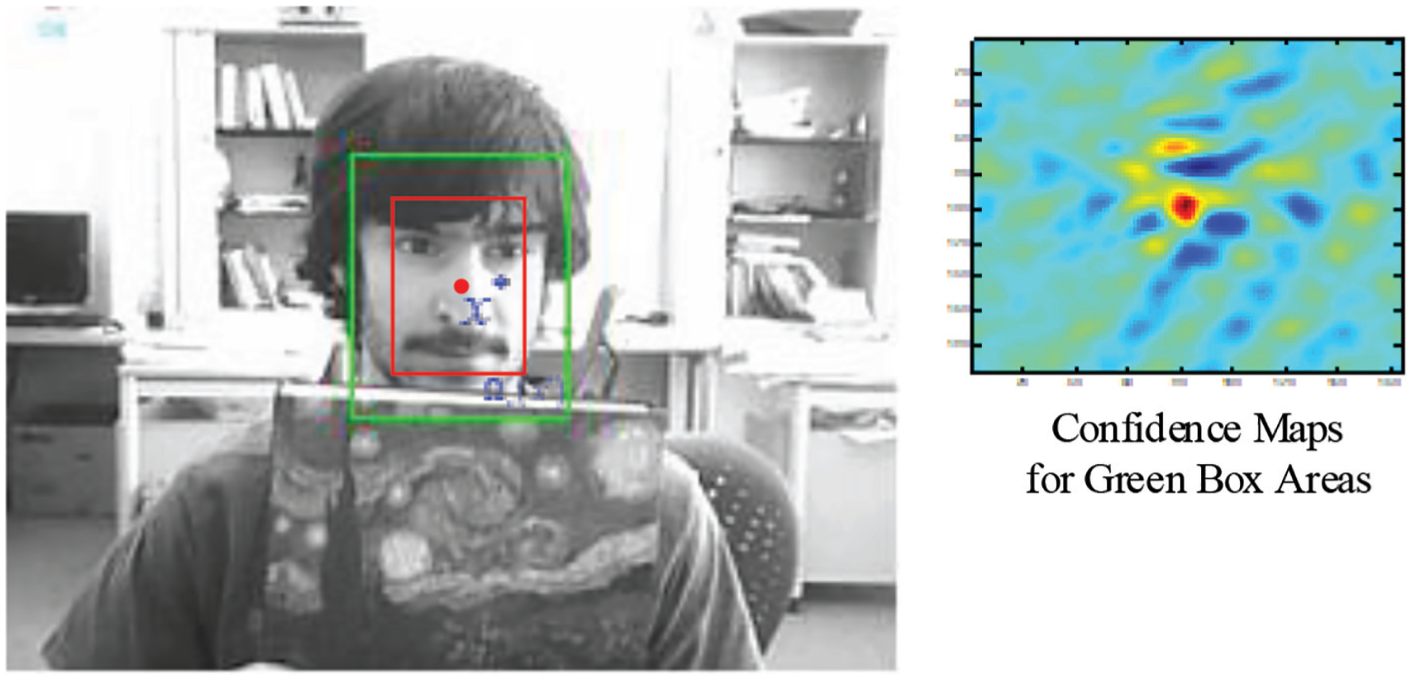
Target, surrounding local context, and its confidence map.
By means of some basic probability formulas, the confidence graph c(x) as

where x and p are both point positions in the picture, T represents the target,
The context prior probability model
Only when the context prior probability model

where I(p) represents the gray value of the position p, and

where a represents regularization constant, and
The confidence map
In equation (2), the confidence function c(x) can be expressed as

where k represents a regular constant,
Spatial context model
In original STC algorithm, the spatial context model

To replace the equations (3)–(6) into equation (2)

where ⊗ means convolution operation, but it will bring a large amount of computation to the algorithm and make the algorithm too slow. It is well known that Fourier transformation after image convolution is equivalent to conduct Fourier transformation at first following product the corresponding pixels value. The fast Fourier transform (FFT) is very fast and can save a lot of running time. Thus, STC introduced FFT operations to increase the speed. The following equations can be obtained by FFT transform on both sides of formula (7)

where ⊙ represents the multiplication of the corresponding pixels. Thus, the spatial context model can be represented as

STC algorithm visual tracking process
After the spatial context model is produced, the subsequent tracking task of STC algorithm is accomplished by calculating the confidence graph of the likelihood of the target position.
17
Assuming that the spatial context in frame t is represented by

The confidence map

where

where
The shortage of STC algorithm
For the STC algorithm, the tracking result will be offset when the target has a rapid scale variation or appearance variation in a short time, and the target area that is tracked will not be extracted accurately (i.e. the scale change of tracking cannot match that of the target), as shown in Figure 2 (the pictures comes from the “Dog1” image sequences which belongs to visual tracker benchmark).

The STC algorithm tracking results under severe scale variations in a short period of time.
From Figure 2, we can see that in the first row, the scale variation of the target is small, and the STC algorithm tracking effect is ideal. While in the second row, the target has a rapid scale variation, which causes the tracking results offset and cannot accurately extract the target. This is because the STC algorithm adopts the Markov time smoothness hypothesis, causing the algorithm to learn the tracking results of each frame. It can easily lead to error accumulation, causing tracking drift and even track failure.
Improved STC algorithm based on scale correlation filter
To overcome the shortcomings of the STC algorithm, this article proposes an updated tracking window model based on scale correlation filter, using the scale correlation filter 18 instead of the original scale parameter of STC tracking algorithm to update the scale of tracking window. While inheriting the efficient location feature of STC algorithm, the model could extract target object more accurate and more complete. The algorithm first extracts samples of different scales around the target after the target is settled by STC algorithm and then forms the pyramid of scale characteristics through samples extracted by histogram of oriented gradients (HOG) operator. 19 Finally, the best scale parameter will be achieved by means of scale correlation filter to update the scale model.
Feature pyramid
After the STC algorithm estimates the target location, the e layers HOG feature pyramid of the sample will be extracted from the location.
Scale correlation filtering
In the feature map, the target area is assumed to be represented by s. At t time, the optimal correlation filter
18
can be obtained by minimizing the cost function

According to Parseval theorem, the operation is converted to frequency domain

where o represents the desired correlation output, s represents training sample, λ(λ ≥ 0) represents regularization parameter. The s,o, and h are M × N matrices,

It can be seen from the above function that the introduction of regularization parameter can deal with the influence of zero frequency components in S and avoid the denominator of 0. The optimum filter can be obtained by minimizing the training sample output error. But this requires solving


where

The maximum value of y is the required target scale.
The algorithm flow
First, calculate confidence map in frequency domain according to the correlation formula of the STC algorithm and then determine target center by finding the location of the maximum response point of the target in the confidence map. Second, construct an
The algorithm of our method.

Experiment
Experimental setup and parameters
In this chapter, the experimental hardware mainly includes Intel i5 3.0 GHz CPU and 4 GB RAM. The proposed algorithm is implemented in win7 + MATLAB 2012.
By referring to previous papers and repetitive experiments, the parameters of the proposes algorithm are as follows: regularization parameter
Evaluation criteria
The following three criteria are used to evaluate the performance of the algorithm: center location error (CLE), distance precision (DP), and overlap precision (OP). The DP values at a threshold of 20 pixels. The formula for OP is
Comparable experiment with STC
In this section, we compare the tracking performance before and after algorithm improvement to prove the effectiveness of the improvement. Four sets of standard test video were selected in this experiment: Dog1, ClifBar, Shaking, and Dancer (tracking results are shown in Figure 3). The pictures used in this section are all from visual tracker benchmark.

The tracking results of the current method and STC algorithm.
Figure 3(a) is the tracking performance of the two algorithms in the test image sequences “Dog1.” In the image sequences, the large-scale variation and appearance variation due to the rotation of the target are the main challenges. It can be seen from the test results that the change of the target scale and appearance are small in the first 753 frames. Both our method and the STC algorithm can track the target object well. Since the 908th frame, due to the target object rapidly approaching the camera and rotating, which leads to large-scale and appearance change. Although the STC algorithm tracking window still lies in the target area, it is unable to extract the object completely. After the 946th frame, offset occurs in the tracking result of the STC algorithm and then loses the target. By comparison, our method can accurately track the target position and extract the target area in the whole video sequence.
In “ClifBar” sequences, the main challenges are motion blur, large-scale variation, occlusion, and complex backgrounds. The tracking results are shown in Figure 3(b). In the 33rd frame, the STC algorithm cannot extract the target area exactly and completely due to the large-scale change of the target. At the 204th frame, the center of the tracking window is shifting. The target is lost after the 222nd frame due to accumulated errors. Our method can accurately track and extract the target in the first 204 frames. From the 217th frame to the 222nd frame, the results of our method present deviation due to the target motion blur. After the 289th frame, motion blur disappeared, and the target area can still be extracted accurately.
Figure 3(c) shows the tracking results in the “Shaking.” The current algorithm performed well in the whole test, means that the algorithm has good adaptability to illumination variation, scale changes, appearance changes, and complex background. As the STC algorithm performs well in the first 62 frames, it means that the STC algorithm has good adaptability to scale variation and illumination variation. However, after the 297th frame, although the target can be tracked, the target area cannot be extracted completely due to rapid scale variation.
The challenge of video “Dancer” is the appearance and scale changes caused by dancing movements of the target person. The tracking results are shown in Figure 3(d). At the 67th frame, the STC algorithm cannot extract the target area completely because of the appearance changes caused by the rotation of the target, then it loses the target in the subsequent frames. While our method can track the target well and extract the target area completely.
Figure 4 shows the tracking error of STC and our algorithm in four test videos. As can be seen from the error graph, in the test sequence “Dog1” (Figure 4(a)), the error generated by our method is less than 10 pixels, which performs quite well. The STC algorithm result occurs shifting at the 900th frame and then loses the target in the subsequent tracking. In the error graph (Figure 4(b)), both our method and STC algorithm track the target well in the first 200 frames as the location error is not exceed 10 pixels. But at the 220th frame, serious deviation appears in the STC tracking result and then loses the target. Our method achieves sound performance during the whole tracking process. In the tracking error graph of Shaking test sequence (Figure 4(c)), we can see an excellent performance of two algorithms, demonstrating that two algorithms are not sensitive to illumination variation. In Figure 4(d), the error of our method is less than 10 pixels. The error of STC algorithm is less than 10 pixels in the first 140 frames, then results in 20 pixels deviation in the subsequent frames.

The error graph of the current method and STC algorithm.
The quantitative performance of the tracking results of two algorithms is measured (Table 2). In the table, use bold numbers to mark better results. It can draw a conclusion that the proposed method performs better than the STC algorithm in the CLE test, except a slight lag in the “Shaking” sequences. The results show that the accuracy of the proposed method is better than that of the original STC algorithm, but it is slightly slower than the original algorithm.
The tracking performance of current method and STC algorithm.

CLE: center location error; OP: overlap precision; DP: distance precision; FPS: frames per second.
Comparing with the other algorithms
To prove the effectiveness of the proposed algorithm, we compared it with the other algorithms (CT, IVT, TLD, Adaptive structural local sparse appearance model (ASLSAM), and L1) in four test image sequences (“Coke,”“FaceOcc1,”“FaceOcc2,” and “Sylvester”). The tracking results are shown in Figure 5. The pictures used in this section are all from visual tracker benchmark.

Tracking results in four test image sequences.
In the “Coke” sequences, the main challenges are target rotation, illumination variation, and covering complex background. The tracking results of each algorithm are shown in Figure 5(a). At the 23rd frame, deviation occurs in L1 algorithm and then loses the target. Since the target is temporarily covered at the 41st frame, IVT and TLD algorithms lose the target. CT and ASLSAM result in slight deviations, while our algorithm works well. Both ours and CT could track target at the 60th frame, but slight deviations appear in CT algorithm. At the 267th frame, all tracking algorithms are deviated owing to the losing target by large-scale covering. But after the 275th frame, when the target reappears, our method tracks the target successfully.
The main challenge of “FaceOcc1” sequences comes from the varying degrees of covering. The results are shown in Figure 5(b). At the 120th frame, the TLD algorithm cannot judge the target object correctly due to covering and thus generates an expanded tracking scale. Since the target is blocked by large area, the tracking results of all algorithms are shifting, except ours. ASLSAM algorithm misses the target from the 586th frame till the end. At the 699th frame, our algorithm and the CT algorithm deviate from the tracking target because of the large area covering. At the 860th frame, the CT algorithm recovers the target tracking, but our algorithm is still in deviation. The robustness of our algorithm needs to improve when the target faces long-time covering.
Challenges of FaceOcc2 test video are illumination variation, target rotation, and covering. As can be seen from the trace result in Figure 5(c), the TLD algorithm has a large deviation when the target is covered and rotated at the 419th frame. A slight deviation occurs for the CT and the L1 algorithms at the 619th frame because target person changed appearance by wearing a hat. At the 709th frame, owing to the covering of target, the IVT algorithm loses the target, and the CT algorithm has a large tracking deviation and drops the target after the 748th frame. Although our algorithm has a certain deviation after the 709th frame, we can still locate the target well.
Illumination and target rotation are the challenges of sequence “Sylvester.” We can see from the Figure 5(d) that L1 algorithm loses the target due to target rotation at the 601st frame. IVT algorithm loses the target in the 689th frame for illumination variation. Our method, TLD algorithm and ASLSAM algorithm have sound performance in the test.
The error graphs of each algorithm in the four test sequences are shown in Figure 6. Our method performs well in the “Coke” and “Sylvester” sequences, achieving more favorable tracking results than other trackers. In the “FaceOcc1” and “FaceOcc2” sequences, since the target is covered by large area, the error of our algorithm is about 20 pixels. The tracking effect is slightly lower than the ASLSAM algorithm but better than the remaining tracking algorithm. This shows that the robustness of the proposed algorithm can be improved when the target is covered. As can be seen from Table 3, the algorithm proposed in this article is superior to other tracking algorithms in terms of processing speed.
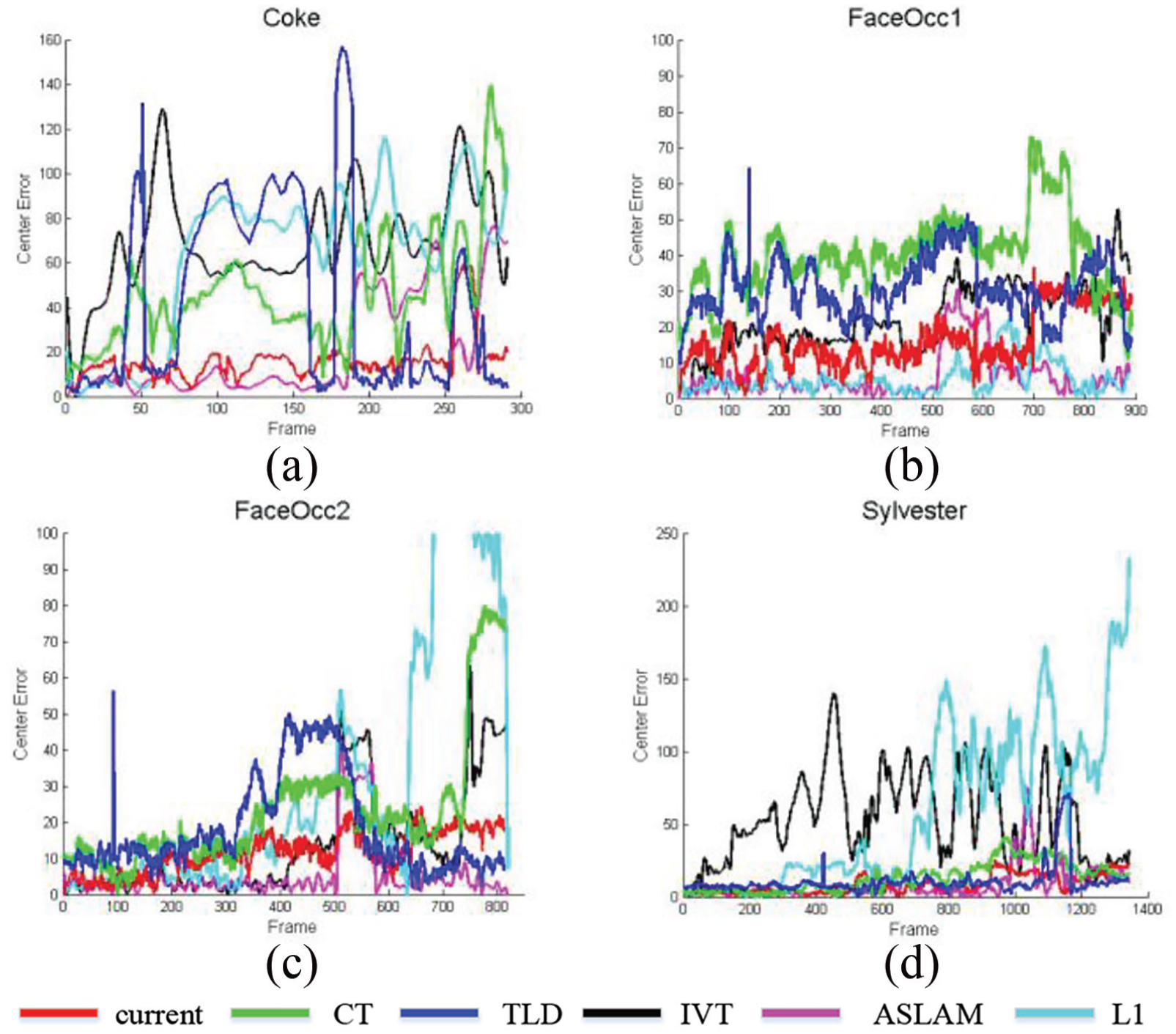
The error graph in four test image sequences.
Processing speed of trackers (frame/s).

IVT: integral value transformation; CT: compressive tracking; TLD: tracking-learning-detection.
Conclusion
The influence of illumination and appearance change, complex background, target rotation, and scale change bring difficulties to the robustness and accuracy of visual tracking. Therefore, an improved STC tracking algorithm based on scale correlation filter is proposed in this article. The method first calculates the confidence map in the frequency domain and finds the maximum response point of the target in the graph as the target center. Then, it constructs the scale correlation filter based on the characteristic pyramid. Furthermore, the desired output value of the scale correlation filter is calculated using the Gaussian function, and the filter is updated with the maximum value as the current scale. Finally, the experimental results show that the tracking algorithm proposed in this article has more favorable tracking results than the STC algorithm when the target changes in sharp scale and appearance, and the comprehensive performance of our algorithm outperforms other state-of-the-art trackers.
Although our tracker achieves a desirable performance in experiments, more is required. The proposed algorithm may lose the target in case the target has been occluded for a long time. A possible solution is to establish the scheme of occlusion judgment and target detection, which will make the algorithm keep tracking after the reappearance of the target. However, this may enlarge the computational load of the tracker. Investigating the object-tracking strategy of human beings maybe the best way to solve the tracking problems.
Footnotes
Handling Editor: Yanling Wei
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.