
Abstract
An optimal algorithm which can help traffic managers to make more accurate decisions from previous road accident case knowledge has been proposed. The algorithm based on k-nearest neighbor determines weight value of each accident case feature based on information entropy index, establishes a road accident case retrieval base using two-step cluster algorithm, and proposes a global similarity model of road accident cases. Then, a new comprehensive evaluation index called matching degree is presented. And then, a prototype system is developed to conduct case retrieval experiments to verify the performance of the proposed algorithm for road accident case retrieval. The result of the experiments clearly demonstrates the effectiveness of this case retrieval algorithm for road accident management in real time.
Keywords
Introduction
Case-based reasoning (CBR) is a problem-solving paradigm reusing the previous corresponding case knowledge. The CBR cycle contains four main steps: 1 case retrieve, reuse, revise, and retain. CBR has extensive application in assessing intelligent transportation system (ITS) benefits, traffic pattern recognition, decision support, and traffic emergency management.2–8 Road accident emergency management strategies, consisting of traffic control, road wrecker, and emergency rescue, are always made based on different accident features, such as road accident time, accident location, and accident type. It is feasible to use CBR approach for making road accident management measures from previous case which has similar accident features as the input one. Generally speaking, case retrieve is the most important step in the CBR process. A number of retrieving algorithms currently exist: (1) nearest neighbor (NN), (2) induction algorithms, and (3) template retrieval. NN is used more frequently in many CBR transportation applications currently. Sadek et al. 9 used NN approach to retrieve traffic diversion strategies with the weight value of each case feature assumed to be equal to 1.0. Chowdhury et al. 10 analyzed the diversion strategies under incident conditions based on NN algorithm in CBR model. The performance of case retrieval was evaluated with subjectively inputting eight different combinations of weights to case features (e.g. volume multiplier, incident duration, percentage of drivers diverting, and incident location) and the perfect combination of weights was selected. 10 Hoogendoorn et al. 11 developed a CBR system to help make traffic management decisions, using mean fuzzy membership to determine the case weights value. Ji and Liu 12 also proposed NN algorithm to retrieve similar decision-making cases for traffic congestion management with analytic hierarchy process (AHP) approach to determine the weight of each case feature. And cluster analysis is usually used to improve similarity calculation. 13 Rousseeuw and Kaufman applied the hierarchical agglomerative clustering method on similar occasions. Saharan and Baragona 14 used cluster analysis to measure the similarity of the factors both on the whole data set and separately for severity levels to outline the association between accident type and factors involved.
Although NN case retrieval algorithm plays an important role in the research and application field of aforementioned traffic congestion management, traffic incident management, traffic management evaluation, and so on, two key problems remain to be existing:
If there is no full similarity case in a case base as the input one, users may need to make decisions according to some scattered information like features of the input case. However, NN case retrieval algorithm cannot help to retrieve these data (cases) effectively.
An effective case retrieval evaluation index to evaluate retrieved case set has not been considered. It is too one-sided to evaluate case retrieval accuracy only based on the value of maximum similarity index.
A road accident case retrieval algorithm based on k-NN is proposed in this study. The presented optimal k-NN case retrieval algorithm has not been captured in most previous studies. Along the line of previous studies and the above critical issues, this study determines weight value of each accident case feature based on information entropy index. Based on two-step cluster algorithm, a road accident case retrieval base is constructed to put a solid foundation for equalizing case retrieval. Similarity models, including two local similarity models and a global similarity model of road accident cases, are proposed. Then, a new evaluation index called integrated matching degree for evaluating retrieved road accident case set is proposed. And a road accident case retrieval prototype system is developed, using road accident data base of Shanghai–Hangzhou freeway in China as the original case base. Then, a series of experiments are carried out to verify the effectiveness of the presented optimal case retrieval algorithm by analyzing both the maximum similarity and the integrated matching degree of the retrieved case set.
This article is organized as follows. Section “Case retrieval algorithm” proposes an optimal k-NN case retrieval algorithm, which includes determination of each case feature weight, development of a case retrieval base, and road accident case similarity model. Section “Case retrieval evaluation” details a new evaluation index called matching degree, including local matching degree and integrated matching degree. A prototype system is developed, and the comparative analysis is presented after 40 road accident case retrieval experiments are conducted in section “Case retrieval experiments.” Concluding comments are reported in section “Conclusion.”
Case retrieval algorithm
k-NN algorithm is used to make weighted sum of each case feature similarity and form a retrieved case set which includes a certain number of cases. So, it is the first step to determine the weight and prepare a special case base for retrieval.
Weight determination
Setting each case feature weight accurately is critical to achieve the goal of case retrieval because a road accident case usually contains both numerical data (e.g. accident location) and enumeration data (e.g. accident type). The value of each case feature weight can be determined according to data dispersion analysis. Information entropy is a good index to evaluate the dispersion degree of either numerical data or enumeration data. The value of every feature weight is determined objectively based on data dispersion analysis of each road accident case feature.
Assume that a system may be in many different states and the probability of each system state is

Similarly, the information entropy of the jth road accident case feature can be defined as follows

where m represents the number of the system states,
If the value of information entropy is more close to 0, the degree of dispersion is smaller and the weight value needed by case retrieving accurately is smaller, and vice versa.
The weight value of road accident feature j is modeled as follows

A original case base is developed based on a road accident data base which contains 3542 road accident cases happened in Shanghai–Hangzhou freeway in China. The information entropy of each road accident case feature, such as accident location, accident date, accident time, accident type, accident severity, and weather condition, is analyzed according to equation (2). And then, the weight value of each road accident feature is calculated based on equation (3), as shown in Table 1.
Weights of the road accident case features.

Construction of case retrieval base
Due to smaller weight value of accident type, accident severity, and weather condition, the retrieval accuracy of these three features is lower than the other three (accident location, accident date, and accident time). If there is no same case absolutely in the case base as the input one, the users also want to summarize countermeasures based on some scattered information like features of the input case in the retrieved case set. So, it is important to ensure that every case feature can be retrieved exactly as far as possible. Therefore, the original case base divided into several sub-case bases according to case feature categorization based on two-step cluster algorithm is transferred to a road accident case retrieval base. First, some road accident data, including data of accident location, accident type, accident severity, and weather condition, should be classified before two-step clustering effectively.
Data of road accident location can be classified into two groups: accident prone location and occasional accident location based on accident cumulative frequency curve method. 16 At the same time, data of accident type, accident severity, and weather condition are respectively classified, aiming to get a balance for data frequency distribution. The results of data classification are shown in Tables 2–5.
Data classification of road accident location.

Data classification of road accident type.

Data classification of road accident severity.

Data classification of weather condition.

The acronyms of some road accident features are shown as follows:
OAL: occasional accident location;
APL: accident prone location;
PP: peak period;
LP: low period;
LOP: loss of property;
V-V crash: vehicle-to-vehicle crash;
V-R crash: vehicle-to-roadside facility crash;
AW: abnormal weather (e.g. wind, fog, snow, cloud, and rain).
Based on two-step cluster algorithm, the original case base is divided into nine sub-case bases. The structure of road accident case retrieval base is shown in Figure 1.

Structure of road accident case retrieval base.
Similarity model of road accident cases
A road accident case always has categorical data as well as numerical one. First, methods to calculate the similarity of numerical and categorical data will be presented respectively. And then, a model of global similarity is established.
Local similarity
Local similarity of numerical data
Assume the mth case feature of cases

where sim is the similarity function, D is the distance function,
Local similarity of categorical data
If two cases have the same categorical data, the local similarity of the two categorical data equals 1.0; otherwise, it is 0.
The model is listed below

Global similarity
The model of global similarity is defined as follows

where
The global similarity of input case and each case in road accident case retrieval base can be calculated successively through equations (4)–(6). Then, a retrieved case set can be developed. The number of cases selected from every sub-case base according to global similarity is about

where
Case retrieval evaluation
Some traffic managers usually want to retrieve a completely same case as the road accident just happened in practical in order to assist them in decision-making. Also, in most of the previous studies, retrieving the maximum similarity case is often identified as the only aim of case retrieval or even case reasoning and the maximum similarity degree is also used to evaluate the effectiveness of case retrieval. However, if there is completely no same case in the retrieved case set as the users needed, then the maximum global similarity is not equal to 1.0 (
A new comprehensive evaluation index called matching degree is presented. Matching degree represents the degree of each case in the retrieved case set to match the input case. Assume that there are k cases in a retrieved case set. If the data of the mth feature in a case are numerical, the local matching degree of this feature is defined as follows
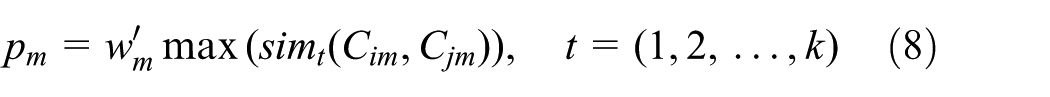
Assume
If the data of the mth feature in a case is categorical, the local matching degree of this feature is defined as follows

And for a certain input case, the integrated matching degree of retrieved case set can be finally defined as

where p denotes the integrated matching degree of a retrieved case set.
Case retrieval experiments
A prototype system used for verifying the performance of the proposed optimal algorithm for road accident case retrieval is developed. The operating environment of the system is configured to Genuine Intel (R) processor and 0.99G memory as the configuration of other common personal computers. Results of these experiments will be evaluated based on the integrated matching degree and maximum similarity. During experiments, the retrieval time consumed will be recorded to verify whether the case retrieval algorithm can work in real time. The interface of road accident case retrieval system is shown in Figure 2.
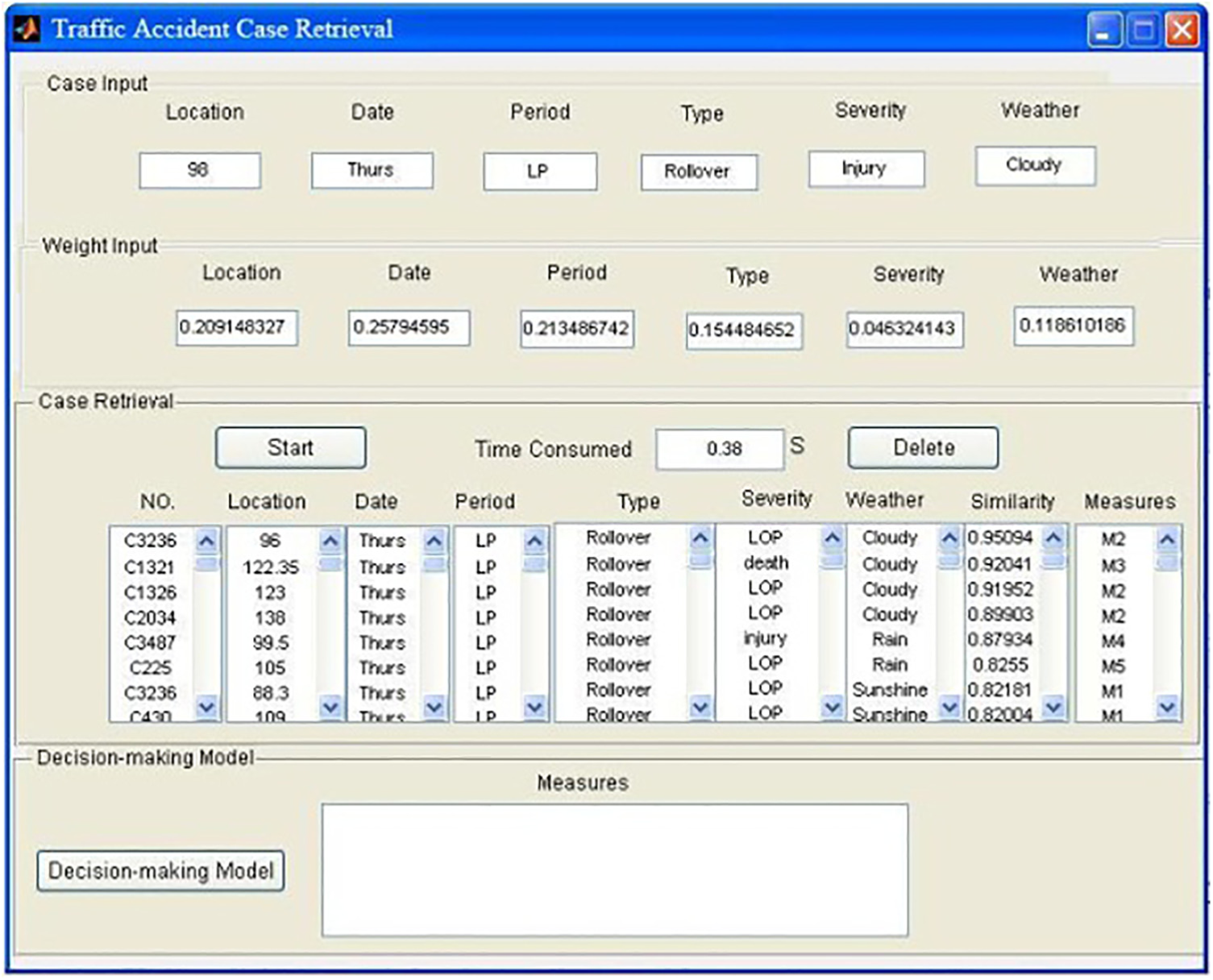
Road accident case retrieval system.
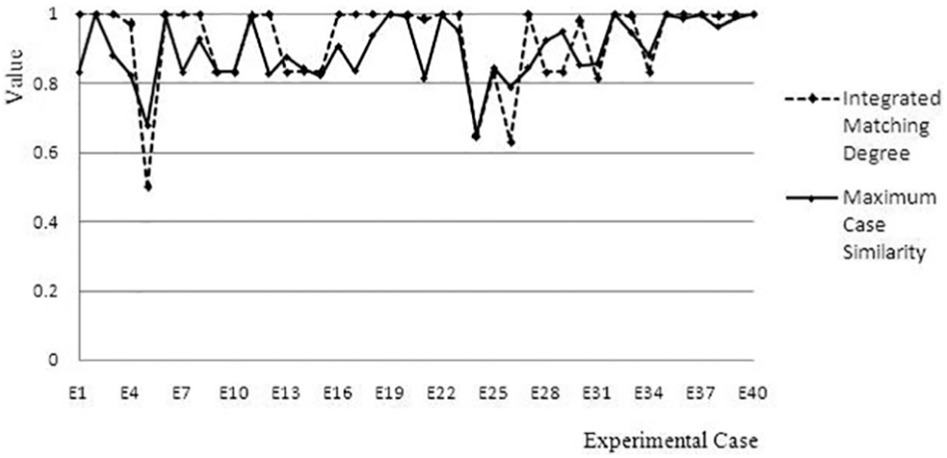
The system randomly generates 40 experimental cases and each one is retrieved in the original accident case base and case retrieval base, respectively, based on the similarity models (equations (4)–(6)) of road accident cases. The parameters of case feature weights are set according to the values depicted in Table 1 and the matching degree of retrieved case set can be calculated in equations (8)–(10). The results are shown in Figures 3 and 4.
Analysis of experiments on original case base.

Analysis of experiments on case retrieval base.
Define the minimum similarity threshold of reference case as 0.8. From Figure 3, it can be seen that there are 37 experiments which can meet the minimum threshold. The retrieval accuracy is about 92.5%. So, the weight values of case features are assigned reasonably. At the same time, the average consumed retrieval time is about 0.39 s that can meet real-time decision-making for traffic management in practice. However, the maximum similarity of case E5, E24, and E26 is only 0.6788, 0.6526, and 0.7887 respectively. And the integrated matching degree of these three cases is smaller.
In next step, the same experiments will be conducted on the proposed case retrieval base to modify the disadvantages mentioned above.
After experiments on case retrieval base, in Figure 4, it can be seen that the integrated matching degree in most experiments has been improved clearly. Generally, for cases E5, E24, and E26, the value of integrated matching degree increased about 67.1%, 25.9%, and 53.6%, respectively. The optimization of integrated matching degree can make up the loss of small case similarity on decision-making. The users can make a more scientific and reasonable management measures through comprehensive assessment on the retrieved case set. The average consumed retrieval time is about 0.40 s which can also be acceptable.
Conclusion
This article has assessed the dispersion of road accident data based on information entropy method. On the basis of road accident data classified, a road accident case retrieval base is developed with two-step cluster algorithm to help traffic managers capture more accurate case set through k-NN retrieval algorithm. And a global similarity model of road accident cases has been proposed. Then, a new evaluation index called matching degree is presented and its function has been discussed in detail. Taking integrated matching degree and maximum similarity degree as the two main evaluation indexes, users can get a more comprehensive evaluation in the result of case retrieval.
The proposed system has conducted dozens of case retrieval experiments to verify the presented optimal algorithm for case retrieval in the field of maximum similarity, case retrieval time, and integrated matching degree. The result of the experiments clearly demonstrates the effectiveness and promises this optimal case retrieval algorithm for road accident management in real time.
Further research along this line will be focused on the critical issues such as case reuse, new case revise, and studying on case retain to enlarge the whole case base in the cycle of case reasoning.
Footnotes
Handling Editor: Jiangchen Li
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This paper has been supported by the Project of Safety Oriented Operation Management-Facility Risk Analysis and Control (Tongji University—Shenzhen Urban Transport Planning Center “City Traffic Joint Laboratory” funding).