
Abstract
Traffic flow parameters have been found to significantly affect crash risk at micro-levels. If such effects do exist at macro-levels, at least two benefits could be expected: (1) the performance and estimates of planning-based crash models could be improved and (2) useful safety knowledge could be provided for regional traffic management. In this article, a flow-based spatial unit was developed by a graph-cut minimization method, based on which regional management strategies are often applied. The graph-cut method partitioned the central area of Kunshan, China, into multiple sub-regions (i.e. graph-cut unit), considering traffic density homogeneity. Bayesian Poisson lognormal models with conditional autoregressive priors were utilized to examine the safety effects of traffic flow parameters, based on the traditional planning-based units and the flow-based graph-cut units. According to the results, no significant traffic flow effect was found for the traffic analysis zone–based model. Traffic flow parameters resulted in a decreased model performance and potential endogeneity issues for the census tract–based model. However, traffic flow effects were found significant for the graph-cut-based model, with an improved model performance. In general, the safety effects of macro-level traffic flow need to be considered for flow-based units developed for regional management.
Keywords
Introduction
Macro-level crash models have been extensively developed to identify the safety effects of demographic, socioeconomic, and lane use factors, providing safety knowledge for decision-makers in the planning stage. In recent years, macro-level traffic flow characteristics have gained increased attention and a number of regional control strategies have been studied for regional management strategies, such as perimeter and boundary flow control,1–3 regional route guidance,4–6 and regional signal control.7–9 Since it is well known that traffic flow parameters are associated with crash risk at micro-levels, 10 the potential existence of traffic flow effects on crash risk at macro-levels may affect the safety performance of regional management strategies. Moreover, macro-level crash models with planning purposes may also be improved by considering such traffic flow effects (if significant), in terms of model performance and estimates. As for macro-level crash models, the modifiable areal unit problem (MAUP) is a critical issue that model performance and estimates (i.e. effects) could significantly vary by different spatial units.11–19 Many spatial units have been examined in previous literature, including traffic analysis zones (TAZ), census tracts (CT), census wards (CW), block groups (BG), countries, and states.16–18 Most of them are planning-based spatial units developed by administrative/political and long-term planning considerations (e.g. TAZ, CT, CW, and countries).20,21 It is unknown that the safety effects of traffic flow parameters can be properly identified based on such units, since most were developed regardless of traffic flow parameters. However, for regional management purpose, flow-based units were suggested by aggregating areas with homogeneous traffic flow characteristics. 22 In doing so, macro-level traffic flow was observed with similar characteristics with micro-level traffic flow, based on which regional management strategies can be easily applied. However, limited research has been identified to explore the effects of macro-level traffic flow parameters on crash risk for either planning-based or flow-based spatial units. For planning-based units, such effects, if exist, could affect model performance and estimates. For flow-based units, exploring such effects would help professionals better understand potential safety impact of regional management strategies.
Thus, in this article, we will examine the safety effects of macro-level traffic flow parameters based on three different spatial units. Two are planning-based units (i.e. TAZ and CT) and the other one is a flow-based unit. The flow-based unit was developed using a graph-cut (GC) minimization algorithm, considering traffic flow homogeneity. The objectives of this research are two-fold: (1) examine whether macro-level traffic flow parameters need to be considered for planning-based crash models and (2) provide some useful safety knowledge of macro-level traffic flow for the development of regional traffic management strategies.
Methodology
Flow-based spatial unit development
Ji and Geroliminis 23 introduced a GC minimization algorithm to partition an urban traffic network into multiple sub-regions, based on traffic density homogeneity. Based on such flow-based unit, macro-level traffic flow was found to have similar characteristics with micro-level traffic. In doing so, regional perimeter control approach can be applied to improve traffic condition for mixed urban network.2,3 Thus, in this study, we will also utilize a GC method to develop a spatial unit for macro-level crash modeling, in order to add safety knowledge to regional traffic management.
GC minimization problem
A GC minimization method is introduced to partition a subject research area into multiple sub-regions, considering intersections as nodes and roadways as edges. Suppose the node set V in an undirected graph

Given a similarity graph with adjacency matrix W, the simplest and most direct way to construct a partition is to solve the minimum problem


where

Given a subset

In doing so, un-normalized graph Laplacian can be constructed to interpret the GC objective function

where we have


Similarly, the relaxation of the minimization problem can be extended to the case of a general value k. Given a partition of V into k sets

Then, we set the matrix



where Tr denotes the trace of a matrix.
Thus,
Procedure for flow-based unit development
The proposed procedure is similar to the one proposed by Ji and Geroliminis. 23 The main steps are described as follows (Figure 1).
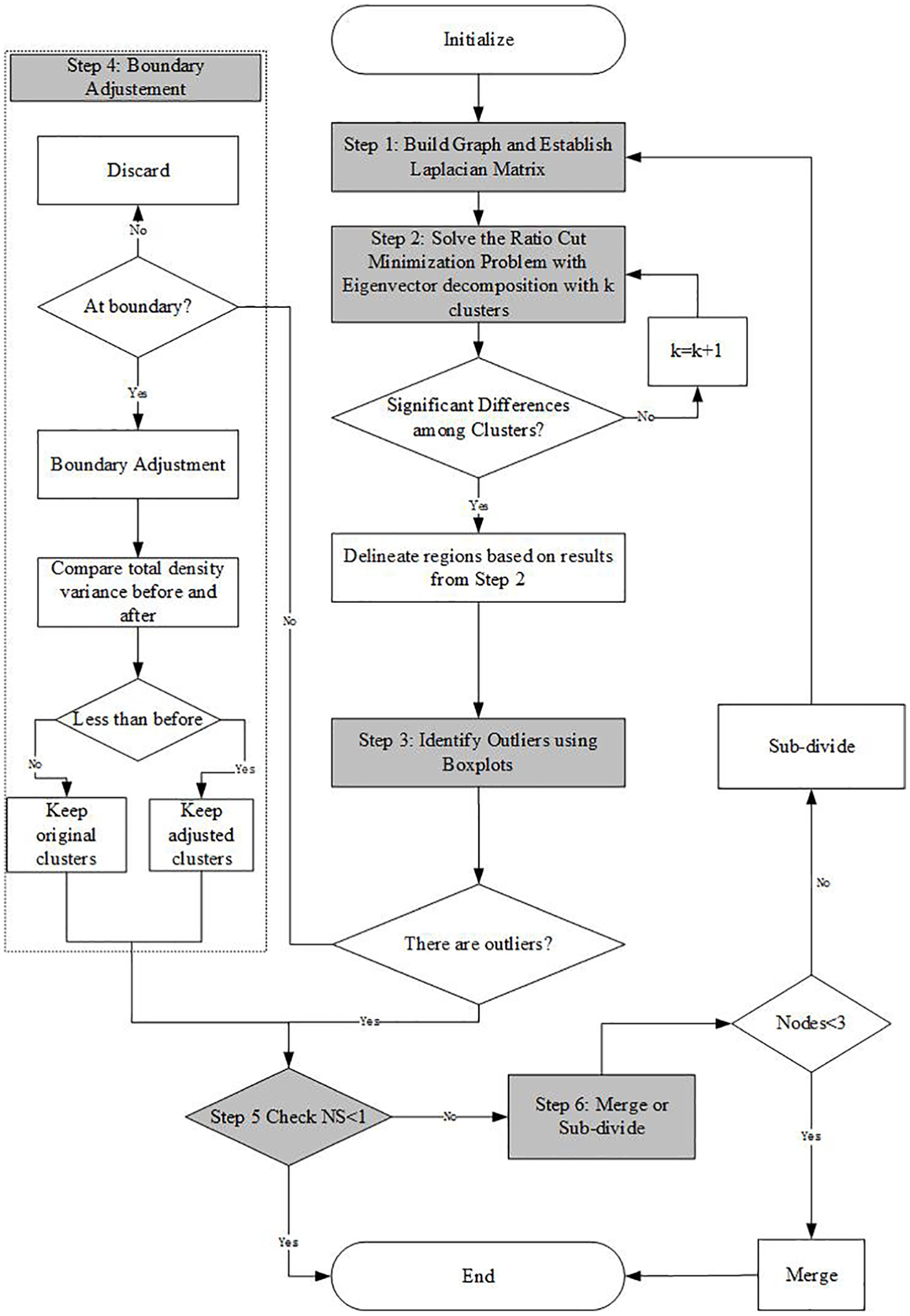
Graph-cut minimization procedure.
Step 1
Construct an undirected graph, based on the traffic network of an area of interest. Intersections are considered as nodes, while roadway sections are considered as edges. Weight

where
Thus, W, D, and the Laplacian matrices can be derived for solving GC minimization.
Step 2
Compute the first k eigenvectors
Step 3
Each cluster needs to be carefully checked for extreme high or low values (i.e. extreme daily traffic density). Those outliers could be derived from malfunction or other issues of detectors, which possibly undermine the performance of spatial partitioning. Boxplot is a simple and sound way to detect extreme values.
Step 4
If there is an extreme value existing in a cluster, the corresponding edge (i.e. the roadway section) needs to be examined if it is the boundary of two nearby regions. If not, then this roadway section needs to be discarded because it may affect further sub-dividing and merging. If so, a boundary adjustment process needs to be applied, by merging the roadway section into nearby regions. Ji and Geroliminis 23 point out that boundary adjustment can refine the edges of a rough sketch to make it more distinct and clearer. The basic principle is that if the total variance of daily traffic density of two nearby regions decreases after the boundary adjustment, then the adjusted boundary will be retained; otherwise, the initial boundary will be retained.
Step 5
After boundary adjustment, each cluster will be checked for their similarities using a NS value proposed by Ji and Geroliminis 23
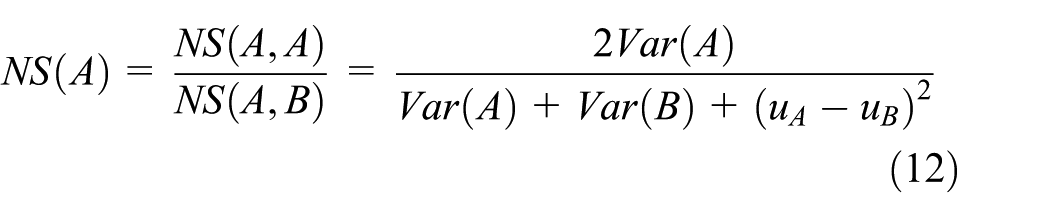
where NS (A, B) measures the average quadratic density distance between two clusters A and B. NS (A, A) measures the average quadratic density within the cluster A.
Step 6
If a cluster has a NS less than 1, then the corresponding sub-region is considered as homogeneous in traffic density. If it has a NS greater than 1, then the number of nodes within the cluster needs to be checked. If less than 3, each node within the cluster needs to be merged into a proper nearby cluster, ensuring a lowest NS value of all clusters. If a cluster has more than three nodes, it needs to be further sub-divided based on the GC minimization method (i.e. repeat the previous steps). According to Ji and Geroliminis, 23 the average NS values of all clusters can be checked

Spatial model configuration
Conventional frequency models (e.g. Poisson lognormal models) rely on a strict assumption of independence of observations, while recently spatial models have shown the superiority by incorporating spatial autocorrelation and dependency. In general, spatial crash models have shown the superiority over conventional crash models. 24 As for spatial crash modeling, many different models were employed before, including Poisson lognormal model, Poisson gamma model, negative binomial spatial model, Poisson lognormal spatial model, geographic weighted Poisson regression model, and Bayesian spatial varying-coefficient model. 25 Since the main purpose of this study is to examine the effects of traffic flow parameters rather than comparing multiple spatial models, Bayesian Poisson lognormal models with conditional autoregressive (CAR) priors are applied to analyze crash data, which has been widely applied in many different research fields such as epidemiology. 26
The Bayesian Poisson lognormal model with CAR prior can be presented as below

where
For the spatial correlation term


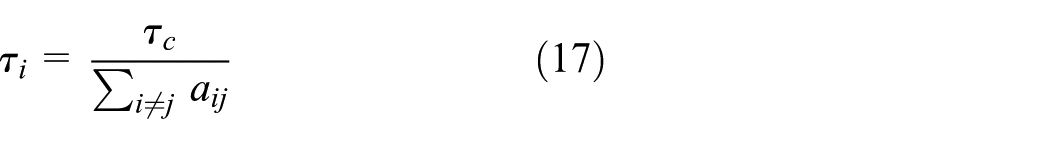
where
The relative risk (RR) of a sub-region can be calculated as

Data preparation
In this study, the central area of Kunshan, Suzhou (within the Kunshan Middle Ring Road), was of particular research interest. Overall, 5662 crash records in the year 2015 were collected from the Kunshan Police Department, containing the detailed information of drivers, roadway, and vehicles. For each record, there is a unique geographic coordinate, which can be further used for location finding in geographic information systems (GIS) map and data matching with other features (e.g. traffic flow characteristics). In order to conduct macro-level crash modeling, planning-based data including population, roadway proportion, and land use were also acquired from the Bureau of Kunshan City Planning. More importantly, 30-s-interval traffic flow data between 10 and 16 September 2015 were extracted from microwave detectors, including occupancy, speed, and traffic counts. In order to apply spatial partitioning based on the GC minimization, the daily traffic density of each roadway section was calculated and considered as the measure of traffic flow homogeneity between two intersections connected by this section. Figure 2(a) displays the subject area and detector locations.
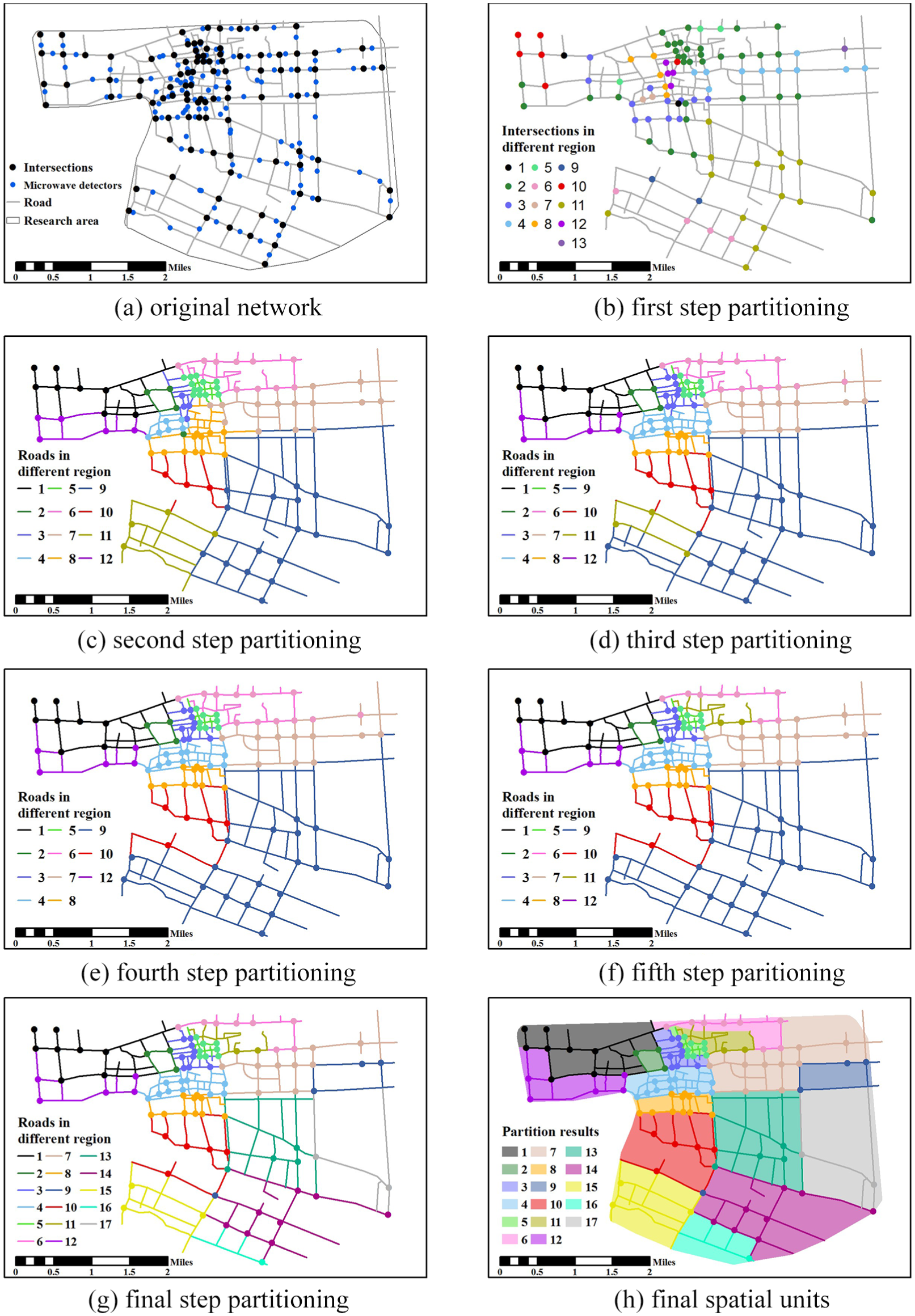
Spatial partitioning procedure based on the GC minimization method.
As for crash modeling, we selected the observed number of crashes of each sub-region as the dependent variable. We calculated the expected number of crashes for each sub-region as the crash expectation (i.e. variable Ei in equation (14)). The crash expectation of a sub-region can be derived as the total number of crashes multiplied by the proportion of its exposure, which is equal to the multiplicative of daily traffic volume, total population, and area size. The estimation of crash expectation is based on an assumption that crash risk is the same across regions. However, the relative crash risk (i.e. RR) could largely vary among different regions, intuitively. Such variations can be due to traffic, social-economic, and land use factors. Thus, 30-s microwave data were aggregated to obtain ADT and average speed of each roadway section between two intersections. Daily traffic density of each roadway section was derived by dividing ADT by section distance. Then, three spatially aggregated traffic variables (ADT, daily traffic density, and average speed) for each sub-region were calculated by averaging roadway sections within the region. Speed variance of each sub-region was also derived by calculating the variation of average speed of roadway sections. Other explanatory variables include commonly used social and lane use variables, aggregated from the planning-based data. For convenience, the spatial weight in Bayesian CAR models was considered as the adjacency-based first-order neighbors. Models were developed and compared for three spatial units (i.e. GC, TAZ, and CT), based on which variables were calculated per spatial aggregation levels. Based on the spatial partitioning procedure, there are 17 GC sub-regions. The details are discussed in section “Flow-based unit development.” All the variables available for model development are shown in Table 1. As for boundary crash assignment, the ratio of exposure method was used. 28 In other words, boundary crashes were all located based on the ratio of the exposure of adjacent spatial units.
Summary of variables and descriptive statistics.

GC: graph cut; CT: census tract; TAZ: traffic analysis zone; ADT: average daily traffic; SD: standard deviation.
Results and discussions
Flow-based unit development
As most microwave detectors were installed along arterials in the subject area, totally 99 intersections (Figure 2(a)) were used for developing an undirected graph (i.e. 99 nodes). The GC minimization method was applied to ensure that all clusters were significantly different in daily traffic density. ANOVA tests were used to examine density difference among clusters. We started from half-cut (i.e. k = 2) and increased the number of clusters until the ANOVA null hypothesis was rejected. When k = 13, ANOVA presented a significant difference among clusters (p = 0.00012). Note that, Levene’s test and the Kolmogorov–Smirnov (K-S) test were applied to ensure equal variances of clusters and their normality. 29 Figure 2(b) displays the clusters of the intersections after the initial spatial partitioning. Note that there was one cluster found with only one node (i.e. one intersection). This cluster was merged into a spatially nearby cluster, and totally 12 sub-regions were delineated (Figures 2(c) and 3(a)). Then, boxplots for each cluster were drawn to identify outliers (shown in Figure 3(a)). When an outlier was found at the boundary of two adjacent regions, it was moved from the original region to a nearby region. Then, the sum of the density variance of each region was compared with the original value. When the total density variance decreased, the boundary adjustment was accepted. If not a boundary, then the outlier will be discarded in further adjustment. Figure 3(b) shows the results of boundary adjustment. After the initial boundary adjustment, the NS value of each cluster was examined. Regions 3, 6, 11, and 9 have values larger than 1. Thus, those regions were further sub-divided or merged into nearby regions. Region 3 was further sub-divided into two parts. One part had NS less than 1 and another part had only two nodes, which were merged into Region 4. Region 11 (with only two nodes) was merged into Region 9 and Region 10. After the adjustment (shown in Figures 2(e) and 3(c)), those regions had NS values less than 1. Region 6 was sub-divided into two areas using graph partitioning (k = 2). Both sub-areas had NS values less than 1. Since the nodes in original Region 11 had been merged into other regions, one sub-area was labeled as Region 11. These steps are shown in Figures 2(f) and 3(d). Region 9 was sub-divided into six parts (i.e. Regions 9, 13, 14, 15, 16, and 17). Each region was checked for their NS values. All sub-divided regions had NS value less than 1. These are shown in Figures 2(g) and 3(e). Finally, ANOVA tests were applied again to ensure significant differences among the 17 regions (Figures 2(h) and 3(f)). The average NS value is 0.8211, indicating that the proposed spatial partitioning procedure successfully lowered traffic inhomogeneity within each region, as well as enlarges the variance of traffic flow among different regions.

Boxplots of clusters during the spatial partitioning procedure.
Crash model results
For the three spatial units (i.e. GC, TAZ, and CT), aggregated variables were calculated and Bayesian Poisson lognormal CAR models were developed, respectively. Correlation test and variance inflation factor (VIF) test were applied to ensure that there is no significant multi-collinearity among variables (VIF > 5) before they entered into the Bayesian CAR model. For each Bayesian CAR model, 100,000 iterations were conducted with 10,000 iterations as burn-in period. All the three models appeared to reach convergence within the simulation period. Table 2 presents the modeling results, and Figure 4 shows the observed crash number and the RR for each region based on the three spatial units.
Significant explanatory variables for spatial modeling for three spatial units.

GC: graph cut; CT: census tract; TAZ: traffic analysis zone; SD: standard deviation; ADT: average daily traffic; DIC: deviance information criterion; MAD: mean absolute deviation; MAPE: mean absolute percentage error; model 1: original model excluding traffic flow parameters; model 2: model including traffic flow parameters.
Coefficients of significant variables are in bold.

Total observed crashes and relative risk for the three spatial units.
For TAZ-based variables, residential land use was found to be correlated with underground parking lots (r = 0.65). Average speed was negatively correlated with average density (r =−0.72). TAZ is a relatively small area unit, and it could be considered as reasonable that TAZ still preserve somewhat micro-level fundamental relationships among traffic parameters. Notably, no significant correlation was found between traffic flow parameters and non-traffic factors (i.e. roadway, land use, and socioeconomic variables). Since correlated variables could raise the issue of multi-collinearity, VIF test was conducted and some variables were removed including underground parking lots and ADT. The modeling results indicate that the relationship between traffic flow parameters and regional crash risk is insignificant at TAZ level. Only planning-based variables were found significant at 95% level for both the original model and the model considering traffic flow parameters, including local roads, public land use, business land use, and residential land use. In addition, the model estimates and performance measures were almost the same for the two models. The slight differences in model estimates and performance could be attributed to the stochastic nature of Monte Carlo Markov Chain (MCMC) used by Bayesian methods. This implies that the inclusion of traffic flow parameters is unnecessary for TAZ-based models. Moreover, TAZ is a proper spatial unit for planning-based spatial modeling without potential endogeneity issues (i.e. correlation between traffic flow parameters and planning-based factors).
For CT-based variables, no significant correlation was found between traffic flow parameters and non-traffic flow parameters. Moreover, the relationship among traffic flow parameters appears to be insignificant at this regional level. This indicates that the fundamental relationship between traffic flow parameters may not always hold for spatial units at any levels. It also proves the necessity of partitioning area with similar traffic characteristics to capture macro-level traffic flow characteristics. 23 VIF test was also conducted to eliminate multi-collinearity. ADT was found to have a VIF of 9.04, which was removed before modeling crash data. For the original CT model excluding traffic flow parameters, business land use, residential land use, and public land use were found as significant. This finding is consistent with TAZ-based models. The effects of local roads became insignificant, possibly due to the aggregation (i.e. MAUP). When including traffic flow parameters, average speed, business land use, residential land use, and public land use were found as significant. Slight changes in model estimates were found for the three lane use factors, while the directions of effects remained unchanged. The overall model performances have a slight decrease (deviance information criterion (DIC), mean absolute deviation (MAD), and mean absolute percentage error (MAPE)), with the additional positive effects of average speed. However, according to previous literature, 30 relatively low-speed area tended to be associated with higher crash risk. Moreover, previous literature suggested the non-existence of possible linear relationship between average speed and crash risk. Thus, some potential endogeneity problem may arise that unknown factors at the CT level are correlated with average speed but not considered in the model. Thus, although the inclusion of traffic flow parameters may increase model performance, it should be treated carefully due to potential endogeneity issues. In general, the original CT-based model was well fitted.
For GC-based variables, average density is highly positively correlated with ADT (r = 0.67). Such relationship was considered as reasonable and similar to that at micro-levels. Significant correlations were found between traffic flow parameters and non-traffic parameters. ADT was positively correlated with major arterial percentage (r = 0.51) and negatively associated with green space (r = –0.59). Average speed was negatively associated with local roads percentage (r = –0.63), public land use (r = –0.51), and residential land use (r = –0.55). Note that they are not significant based on TAZ or CT units, which were developed by administrative consideration and demographics. By developing GC unit based on traffic flow homogeneity, those factors correlated with traffic flow tended to be aggregated and such correlations became significant. High correlations among roadway, land use, and socioeconomic factors were also identified. For instance, major arterial percentage was negatively associated with local roads percentage (r = –0.68). Floating population is positively associated with on-ground parking lots (r = 0.73). Residential land use is positively associated with green space (r = 0.55), floating population (r = 0.61), and underground parking lots (r = 0.83). Public land use is positively associated with commercial land use and negatively associated with underground parking lots. Such correlations could also be expected based on GC unit. Since many factors were found to be significantly correlated, multi-collinearity could be an issue that affects model estimates and performances. Multiple variables were found to have high VIF values, including underground parking lots (VIF = 21), green space (VIF = 18.8), major arterial road percentage (VIF = 11.2), and commercial land use (VIF = 7.5). Those variables were removed before entering Bayesian models. For the original Bayesian model excluding traffic flow parameters, minor arterials percentage, local roads percentage, industrial land use, and residential land use were found as significant. When considering traffic flow parameters, residential land use, speed variance, and daily traffic density were found as significant variables for the GC-based model. With the inclusion of speed variance and daily traffic density, the effects of industrial land use, local roads, and minor arterials became insignificant. Thus, the effects of traffic flow parameters (i.e. speed variance and daily traffic density) were considered to be more important at this regional level. A region with higher speed variance tends to be associated with higher regional crash risk. This is reasonable according to the previous literature. 31 With the increase in traffic density, there is also a slight increase (b = 0.011) in crash risk. Previous literature suggests controversial findings on the relationship between traffic density and crash risk: some claimed a positive linear relationship, while others suggested a quadratic function. 32 It is reasonable to expect that, at first, increased traffic density would create more interactions and thus more crash risk. While it reaches a certain level, traffic becomes too congested, resulting in fewer movement and lower crash risk. Since we only considered an average effect without regarding temporal effects, the density effect of each zone needs to be further explored in detail. The DIC, MAD, and MAPE were all significantly lower than the original model, showing it was better fitted including traffic flow effects.
Conclusion
Traffic flow parameters were found to be correlated with crash risk at micro-levels according to the previous literature. 33 The increased research attention on regional traffic management also raises an interesting question of identifying potential safety effects of traffic flow parameters at macro-levels. Moreover, it is also interesting that whether adding traffic flow parameters could also affect model performance and estimates for planning-based crash modeling. Thus, spatial crash models were developed based on three spatial units: TAZ, CT, and GC. TAZ and CT are traditional planning-based spatial units. GC is a flow-based spatial unit, which can be used for regional control purposes. To obtain GC unit, a GC minimization method was utilized to partition the central area of Kunshan, China, into sub-regions, based on the within-unit traffic density homogeneity. In order to deal with spatial dependency, Bayesian Poisson lognormal CAR models were employed. For each type of unit, two models were developed: one original model excluding traffic flow parameters and one including traffic flow parameters.
The GC-based model including traffic parameters was superior over the original one without traffic flow parameters. Moreover, it suggests significant traffic flow estimates. For the TAZ-based models, no difference in model performance was found by adding traffic flow parameters. And no significant effects of traffic flow parameters were suggested. The CT-based model including traffic parameters was found to have a slightly worse model performance than the original model. However, the effects of traffic flow parameters in the CT-based model appeared to be suspicious, possibly due to potential endogeneity issues. Thus, traffic flow parameters did not significantly improve planning-based models. However, they significantly affected crash risk for the GC-based model. Since GC units were developed for regional traffic control purposes, it can be concluded that both safety and efficiency need to be considered for regional traffic management.
In general, the safety effects of traffic flow parameters do exist at macro-levels. For planning purposes, it is unnecessary to consider traffic flow parameters as explanatory variables in macro-level crash models. However, for regional traffic management, the potential safety effects of traffic flow parameters may need to be considered and examined. This article can be considered as a preliminary study with encouraging findings for this research direction.
Admittedly, there are limitations that should be addressed. First, most traffic data were collected for arterial roads, where microwave detectors are installed. Thus, only those roads were used for spatial partitioning. Limited by the sparsity of microwave data and the size of the subject area, only 17 GC zones were finally delineated, which possibly raise overfitting issue. Nonetheless, the intent of the modeling is not for prediction but identifying model effects. Moreover, Bayesian CAR models were introduced to deal with the issue and the coefficients were assumed to follow prior normal distributions which can be considered as the equivalence of L2 regularization. 34 Second, spatial and temporal heterogeneity were not considered in this study. Spatial heterogeneity had been discussed in the previous literature. 16 It could be examined in the future, especially for the effect of multiple traffic flow parameters. Moreover, since GC unit is defined based on traffic flow data instead of planning data, temporal heterogeneity can also be discussed in the future. Also, other traffic flow parameters can be attempted for spatial portioning, instead of traffic density. Third, only several simple aggregated traffic parameters were considered in the study. It is interesting to extract other features of traffic flow (e.g. the features of macroscopic fundamental diagram) and examine their possible effects on safety. In addition, other spatial models (e.g. simultaneous autoregressive model) can be applied in the future to identify those effects. Finally, boundary crash data assignment is an important issue that needs to be further examined. Currently, a previous method was used in this study. However, according to recent literature, 35 there have been many different methods dealing with the boundary issue. We recommend that future studies can be focused on these research topics.
Footnotes
Handling Editor: Jiangchen Li
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the National Natural Science Foundation of China (nos 51508093 and 51608114) and the Fundamental Research Funds for the Central Universities (no. 2242018K40008).