
Abstract
Social life cycle assessment is an important method to assess products’ social impacts throughout their life cycles. There are already some indicators and software to assist conducting social life cycle assessment. However, it is hard for users to share or reuse assessment results because of different application data structures. To resolve this problem, a knowledge-based social life cycle assessment–aided design method is developed in this research. With this method, all elements in the social life cycle assessment process are analyzed and represented as classes, their relationships are described as object properties, and the data structure is represented as data properties to construct an ontology system for social life cycle assessment. Based on the ontology, a social life cycle assessment–aided product development web is developed. According to the data property structure, a bidirectional mapping between database and ontology is realized using JENA and ontology-based data access, which enables the result data to be automatically inputted into ontology individuals. Thus, the result data can be accumulated, shared, and reused among users. A case study with a floor product as well as a user test is carried out to prove the feasibility and usability of the web. The ontology-based social life cycle assessment–aided design method provides users with a new high-efficiency approach, setting the foundation for the intellectualization of life cycle assessment.
Keywords
Introduction
Life cycle assessment (LCA) was first introduced in 1993 during the conference of “Society of Environmental Toxicology and Chemistry,” 1 and considerations about society and social economy were mentioned in this conference. Although it was emphasized that close attention should be paid to environmental impacts caused by social impacts directly or indirectly, social impact was not included in LCA at that time.
Social life cycle assessment (S-LCA) has become a hotspot of researchers and practitioners in the last decade. Weidema, 2 Dreyer et al., 3 and Benoît et al. 4 presented some fundamental research and developed frameworks for S-LCA. The frameworks include damage categories and impact categories as well as suggestions about category indicators and inventory data. In the meantime, Brent and Labuschagne, 5 Hunkeler, 6 and Jørgensen et al. 7 developed variousS-LCA methods and proposed some problems on which further researches should be performed.
The “GuideLines for S-LCA of Products,” or “GuideLines” for short, was first complied in 2009, for the purpose of evaluating the application of S-LCA. It explains how social impacts work on the life cycle (LC) of products and proposes a valid assessment framework, which represents the consensus of the research experts in this field. Then, majority of S-LCA research is conducted based on the GuideLines where theS-LCA is defined as a technique to conduct social impact assessment. The aim is to assess product’s social and socio-economic impacts, and the potential positive and negative social impacts throughout product’s LC also need to be assessed. 8
According to ISO14000 series, S-LCA is divided into four main parts. Different from LCA, it is needed to settle down 6 stakeholders and 31 subcategories to carry out data collection and analysis in the third part (impact assessment). Based on this, some different methods were developed by researchers. A popular one is the performance reference point (PRP) method, which takes the internationally recognized lowest performance level (e.g. ILO1, ISO26000, and OECD2) as a reference point to access enterprises’ performance. 9 Other popular methods, such as checklist 10 and point rating, 11 are also used in different application scenarios. The database method is an alternative one, while existing database are “Social Hotspot database (SHDB)” and “Product Social Impact Life Cycle Assessment (PSILCA) database.” There are also axiomatic methods, such as “Preston pathway (curve)” 12 and “Social Impact Indicators (SII).” 13
Although each method can be used to solve the given problems, S-LCA researchers have to face a scenario that different databases have different indicators, and stakeholders’ rating scores are different. Furthermore, databases are dynamically changing. There is a need to overcome this challenge to give different database a unified specification or standard, to enable data among different databases to be exchanged, accumulated, shared, and reused. Knowledge representation is an ideal choice.
In our work, ontology is chosen to represent the process of S-LCA as well as its main knowledge system. Then, an S-LCA-aided product development web is developed, which can integrate different S-LCA software based on the developed knowledge system. A bidirectional mapping method is applied, which can make the S-LCA result data automatically be inputted into ontology individuals. Thus, users’ different calculation result data can be accumulated, shared, and reused. A case study of a floor product is discussed to demonstrate the feasibility of the web. Usability testing of the web is also carried out by S-LCA experts as well as enterprise personnel, which shows that the web has a good usability and can well aid non-experts to do S-LCA on typical products.
As an effective technique, ontology has been successfully applied in various areas; however, according to the literature review conducted by the authors, it has not been applied in S-LCA. As a novel contribution, this research applies ontology into S-LCA, to help develop a knowledge-based system, which can makeS-LCA result data be accumulated and directly reused by different users.
In the following sections of this article, the related works and the objective of the research are presented in section “Related works and objectives of this research,” and the development of ontology-based S-LCA system and the S-LCA-aided product development web are presented in sections “Development of ontology for the LCA process” and “Development of S-LCA-aided product development web,” respectively, followed by a case study described in section “Case study of a floor product S-LCA.” And finally, the conclusions are presented in section “Conclusion.”
Related works and objectives of this research
S-LCA
One of the key points of S-LCA is to coordinate the behaviors of stakeholders, for the purpose of obtaining an ideal social impact of product throughout its LC.
Zimdars et al. 14 developed a comprehensive measurement to assess social impacts, which helps overcome the shortcoming of excluding major stakeholder groups. The coordination of stakeholders is the focus of their research.
Another interest to conduct S-LCA is how to improve stakeholder’s performance. Grubert 15 addressed and improved the method of S-LCA. In his method, opportunities, in social sciences especially, are to be identified to improve the rigor during the process of S-LCA. The following work is to determine whether to choose the opportunity or not.
In order to support the process of decision-making, Do Carmo et al. 16 discussed the social impact of social suppliers and presented a model which can generate profiles for them. His research provides a useful method for opportunity selection. Then the concentration should be paid on the contribution result of the chosen opportunity.
Arcese et al. 17 carried out works to classify the contributions on S-LCA. In their work, the wide variety of classified contributions can be used to track the development of themes. Meanwhile, the main approaches can also be defined and classified systematically and reproducibly. Finally, the assessment for the contribution should be carried out using suitable methods and tools.
Holger et al. 18 brought forth a UNEP/STAC guidelines–based S-LCA method. It allows the hydrogen production’s social footprint to be determined based on SHDB, and the composition and social footprint’s regional origin can be identified. Meanwhile, Tecco et al. 19 developed a methodology combining LCA and S-LCA to assess the fruit growers’ association impacts.
These achievements of the above researches show that the key problem of S-LCA is to make comprehensive consideration of all social impacts. But eachS-LCA method is focused on a specific field, using an independent database. It means that the research results cannot be directly reused or accumulated because of the disunity of the S-LCA process as well as the dynamic changing indicators and database.
Knowledge representation is an alternative to solve this problem. If the S-LCA process is represented as a knowledge system, all elements (process, indicators, and database) in this system will be unified as classes and the research results will be stored as instances, in which data can be easily accumulated and reused.
Ontology
Recently, ontology is widely used to represent engineering systems to realize the accumulation, sharing, and reuse of engineering data.
Mate et al. 20 developed an ontology-supported method using abstraction. This method realizes the ontology-based data integration and is helpful to actualize the temporary relationships mapping between data and ontology.
Bellatreche et al. 21 developed an improved ontology integration method. With their method, the process data can be inputted into ontology automatically by saving all data in the sharing ontology as its individuals to avoid content coupling.
Based on ontology, Köhler and Schulze-Kremer 22 brought forth an integration system to develop biological data sources using federated molecular. It realizes the automatic inputting and querying for structured data. Its idea is in accordance with the fundamental technical principle of ontology-based data access (OBDA). 23
Based on OBDA, Sicilia et al. presented AutoMap4OBDA. 24 Considering the relations between the use of relational source contents and target ontology’s features, the system can make R2RML mapping files be automatically generated. Another research allows R2RML to define mappings manually. 25 But the mapping effectiveness is not good enough. Combining with the idea of OBDA, Rong et al. 26 proposed a mechanism by coordinating the storage space and ontology generation time, which supports the mapping process with a good performance.
Furthermore, the authors developed an ontology-based knowledge representation and data management method (KRDM), which can automatically obtain engineering data connected with a well-organized ontology system. 27
All these research results indicate that ontology is an ideal tool to represent the knowledge system of S-LCA, because those calculation result data can be saved in ontology to be accumulated and reused.
There already exist some mapping methods. Different from the existing methods, the novelty of the mapping method developed in this research is that the mapping files are automatically generated based on the data properties of classes. In this way, the ontology will get a good extensibility. If there is a new series of data added in the LCA software which has no corresponding class, what needs to be done is to add a new class in the ontology and list the names of the data table in its data properties. The generating process of mapping files is actualized in a JAVA program, which is not presented in this article because of its length limitation.
Knowledge representation in LCA
LCA is widely used in some engineering fields, such as bioenergy and biochemical, 28 energy, 29 and manufacturing industries. 30 In these fields, there is an emergency demand of accumulation, sharing, and reuse of engineering data.
Based on this requirement, for the purpose of developing a model for LC inventory databases, Bertin et al. 31 brought forth a semantic approach, which plays well in developing a comprehensible model. Using the US electricity production as a case study, they discussed on how to develop the model and proved its feasibility based on LC inventory data. Semantic is demonstrated to be an ideal way to construct data for LC inventory.
Meanwhile, in the field of environmental data construction, Takhom et al. 32 developed a framework to manage applied ontologies. It enables not only knowledge engineers but also domain experts to define the explication of knowledge as well as recommendation rules in a collaborative environment. A usage case was also studied to demonstrate how the framework works. The purpose of their research is to make sense that environmental data can be well organized and shared.
For the same purpose, Muñoz et al. 33 developed an ontology-based framework. Using this framework, information as well as knowledge models, which are generated during the process of enterprise environmental assessment, can be shared. The case study was carried out to demonstrate how the models developed in this framework can be applied in real projects.
These research results show that the semantic method, especially ontology, is already used in LCA to make it more user-friendly and systematic. It further demonstrates that ontology is an ideal tool to represent the knowledge system of S-LCA.
Objectives of this research
In this research, the following objectives are to be achieved:
Analyze the process of S-LCA, develop its ontology model based on its own knowledge system, and develop the structure of anS-LCA-aided product development web using its data flow in this knowledge system.
Use KRDM to connect OpenLCA (the software used in this research) with the web and make the data generated by the software be automatically inputted into the ontology model, which helps users to conduct S-LCA easily.
Finally, carry out a case study to demonstrate how to use the aided web. Also, usability testing needs to be done to demonstrate the usability and feasibility of the web.
Development of ontology for the LCA process
Either environment life cycle assessment (E-LCA) orS-LCA has the same application process, just with different object and emphasis. In this research, the aim is to develop an overall LCA knowledge system, which has two main subsystems: E-LCA and S-LCA.
When conducting LCA, users will follow this overall process: choose the LCA type (E-LCA or S-LCA) according to objectives for the LCA of a specified product; then select the needed method; after the assessment, if needed, they will do further optimization design.
Ontology development process is mainly divided into two parts: domain research and relationship analysis. By means of domain research, all concepts, objects, and elements in the given domain are to be listed. Then, all the information and relationships among them are to be analyzed and arrayed according to a certain logical level. 34 Thus, we determine the main elements in the LCA process first and display the main top classes of the process, which are listed in Table 1.
Top classes of the LCA process.

LCA: life cycle assessment; E-LCA: environment life cycle assessment; S-LCA: social life cycle assessment.
Then, according to the LCA process, the formal descriptions are given for the relationships between each pair of related classes. These relationships conform to certain syntax: classes are subjects and objects, while predictions play the role as object properties, which represent the relationships. This main syntax is displayed in Table 2.
The main syntax representing the LCA process.

LCA: life cycle assessment.
Based on these, the ontology system is developed using the most popular ontology development method “seven-step method” and the widely used software “Protégé.” The structure of the LCA process’ classes is shown in Figure 1, and the structure of their relationships is shown in Figure 2.

Structure of classes of the LCA process.

Relationship structure of the LCA process.
Finally, data properties of classes are to be developed, which will be used to save the LCA process data to enable them to be accumulated, shared, and reused. Part of the data properties is displayed in Figure 3.

Data property setting for the LCA process.
Till now, the ontology system of the LCA process has been developed. In the following section, theS-LCA-aided product development web is going to be developed based on this ontology.
Development of the S-LCA-aided product development web
Foreground development of the S-LCA-aided product development web
According to the ontology system of the LCA process, for the purpose of carrying out both E-LCA andS-LCA for products, the web is designed to have four first-level pages, which are “Register/login,”“LCA (environment),”“S-LCA,” and “Project.” The core pages “LCA” and “S-LCA” are divided into several parts according to ISO14000 series standards. The main structure of the web is shown in Figure 4. Based on this structure, the subsequent web pages at different levels are developed one by one. One of the second-level pages is shown in Figure 5.
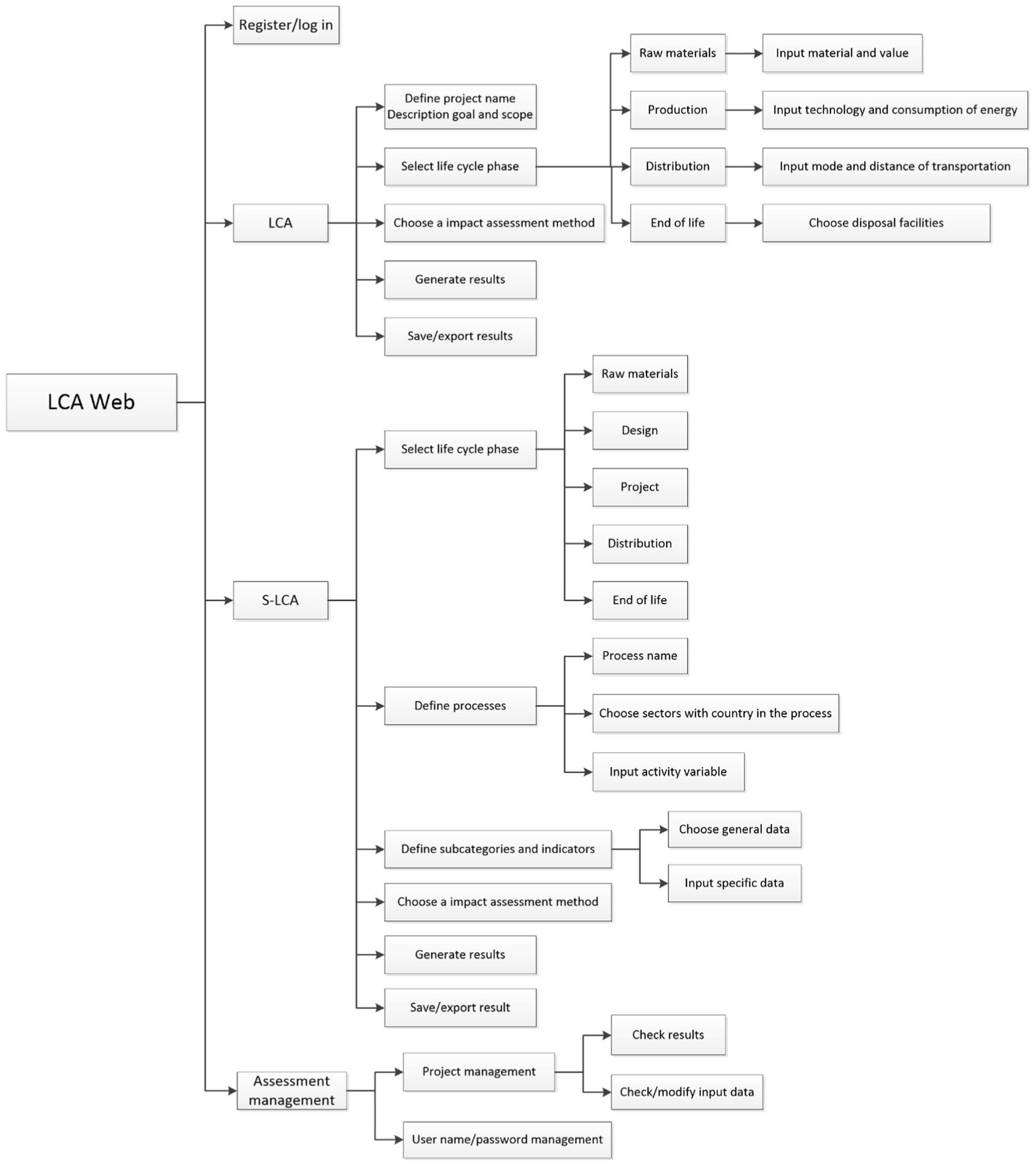
The main structure of the S-LCA-aided product development web.

Home page of LCA in the aided product development web.
Background development of the S-LCA-aided product development web
Process data conversion and ontology automatic entry method
As discussed above, data properties in the ontology system are constructed within a flat class structure. Different ontology files are identified with their unique URIs, which will avoid overwriting of individuals after mapping. In this section, the mapping method is brought forth and the flowchart is shown in Figure 6.

Process data conversion and ontology automatic entry flowchart.
The sequential steps are as follows:
Based on JENA SDB, build RDF resource storage and get access authority.
Obtain all information of tables in ontology files, including table name, primary key (PK), foreign key (FK), and general column information. Then map their correspondence. Based on ontology querying technique JENA ARQ, 35 obtain information of table name and PK from compiled ontology files, and then generate relational mapping files for them (see details in step (A)). Obtain information of table name and column without PK and then generate relational mapping file for them (see details in step (B)). Obtain information of table name and FK and then generate relational mapping file for them (see details in step (C)).
Replace templates of SQL and ODBC files based on mapping relations (see details in steps (B) and (C)).
Use JDBC to execute SQL files and load OBDA file using Ontop API. Finally, obtain ontology data from the database.
(A) Acquiring meta-information from table and creating database table name.
For the purpose of obtaining meta-information of tables, set the data properties in data layer ontologies as set DP; then

where X is a positive integer.
The data properties’domain is set DPD; then
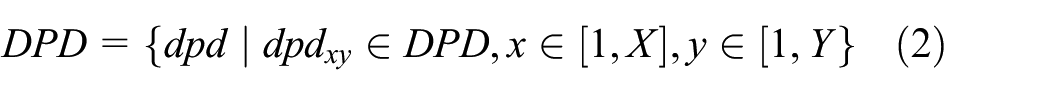
where X and Y are positive integers.
Then, the primary key in ontology file is set PK.
Go through
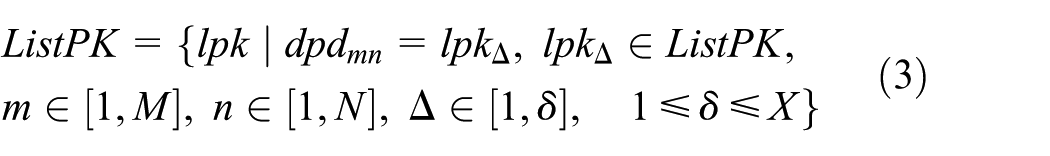
where M, N, and
Go through

where A is a positive integer.
(B) Acquiring meta-information from column and adding database column.
For the purpose of obtaining meta-information of column, go through
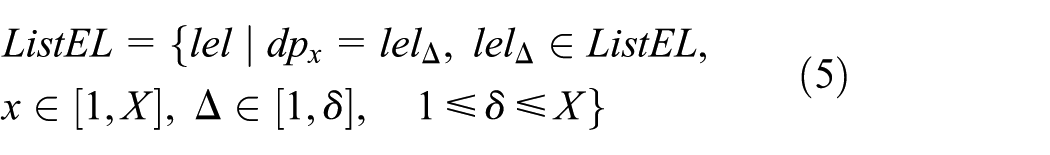
where X and
According to the name of

where B is a positive integer.
(C) Acquiring meta-information from class and creating external table.
Set the data properties in ontology as set OP; then

where I is a positive integer.
Set domain of opi as set OPD; then
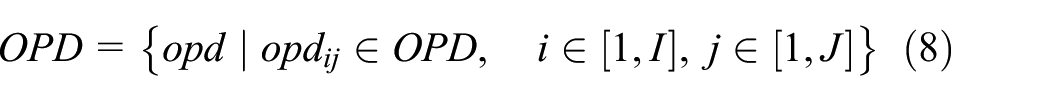
where I and J are positive integers.
Set range of opi as set OPR; then

where I and Q are positive integers.
Go through opi and find out all opdij and opriq. According to class names they related to, create external tables the names of which are set ListFK; then

where
(D) Generating configuration files for mapping ontology to data.
Based on the three configuration templates in JENA, according to ListTable, ListColumn, and ListFK obtained in steps of (A)–(C), generate three configuration files. Merge them as one database statement and package it. Integrate the packaged statement in the network service module, which can map the selected ontology automatically and then generate the process database for engineering process data.
(E) Generating mapping configuration files for automatic inputting data into individual.
Based on the three configuration templates in OBDA, according to ListTable, ListColumn, and ListFK obtained in steps (A)–(C), write database statements separately to obtain three configuration files. Merge the three files in one OBDA automatic mapping file, which can automatically select data from engineering database, and then input them into ontology’s individuals.
Till now, the process of automatically inputting data into ontology individuals has been finished.
LCA process knowledge managing method
When the web is running, the process data generated by LCA software will be inputted into individuals of LCA ontology. These individuals have fixed URI and will be easily queried with top-level knowledge logic. Thus, the represented data in the ontology system can be accumulated, shared, and reused. According to the knowledge querying process, the knowledge managing method is developed in the following steps (Figure 7 for more details.):
User sends aided development request through the web. The web calls LCA software for calculation and the results will be stored in ontology individuals through automatic mapping program discussed in section “Process data conversion and ontology automatic entry method.”
Logic represented in object properties links ontologies with its individuals after the data were inputted.
User sends querying request through the network platform, and the packaged reasoning query program automatically performs semantic reasoning of knowledge in LCA ontology and returns the needed information to the user to make it be reused.

LCA process knowledge managing method.
Until now, we have finished the development of the web, which is constructed based on the knowledge system of the LCA process. The process data conversion and ontology automatic entry method make the web a good interface to integrate with the LCA software. It can also automatically input engineering data into ontology individuals, while these data are generated during the LCA process. All these make the LCA data obtained by different users be accumulated, shared, and reused. In the following section, a case study is to be discussed to demonstrate these advantages of the web.
Case study of a floor product S-LCA
Goal and scope
The object to be analyzed is an all-steel antistatic viaduct floor, with a size of 600 × 600 × 30 mm3. Each block of floor is consisted of three parts: panel, pedestal, and stringer. The panel is stamping formed, with the hollow part being filled with high-quality cement. For the purpose of improving the wear resistance of the surface, mineral powder is used to spray paint the veneer. The pedestal is made by steel and the stringer is made by color zinc. The structure of the block is displayed in Figure 8.

Structure of the block.
This block is produced in China and is a hotspot of the society because a large amount of offices as well as Chinese families need to decorate their rooms. It has to be mentioned that, however, this kind of floor is designed to mainly support the environment of machine room. In China, people prefer to use this kind of floor in their study rooms, kitchens, and so on; meanwhile, government, enterprise, and university also prefer to use it in offices and labs. Floor is an important issue which means the potential of indoor air pollution. For the above reason, this product is chosen to be the case of the S-LCA study.
The goal of this research is to calculate the influence degree of each social hot topic and, according to the assessment result, to propose improvement suggestions and measures to the enterprise on the floor’s social impacts. Also, some suggestions on sustainable development and sustainable consumption will be advised to the government.
At the earlier stage of S-LCA, all the stakeholders and their subcategories are to be determined, such as children employment, forced working, average salary, working time, health and safety, and social benefits. They are listed in Table 3 for details with the PSILCA database as a reference.
Stakeholders considered in S-LCA of floor.

S-LCA: social life cycle assessment.
LC inventory analysis
According to the contents shown in Table 3, data collection of the floor product during its production process is finished. See details in Appendix 1 (Supplementary Material).
In Appendix 1 (Supplementary Material), national and industry data come from government departments and NGOs, such as China National Bureau of Statistics, International Labour Organization, and The World Bank. Corporate data mainly come from Corporate Social Responsibility Report, Corporate website, news, and papers.
According to the collected data, the floor production corporate has medium-level working conditions. But the corporate provides legal social welfare, as well as Staff Poverty Alleviation Fund, Organization Building, and so on. It also has a fair salary system, which takes many actions to protect staff’s healthy and safety. It has also been fully accredited with many environmental certifications and is the first corporate to put zero-carbon floor products into market in China. A feedback mechanism is provided to consumers, and customer satisfaction surveys are conducted regularly, but the transparency is moderate. However, data about working time and discrimination problem have not been found.
S-LCA of the floor product
The performance reference method, one checklist method, 36 is chosen to conduct S-LCA on the floor. In this method, “PRP” of each subcategory is to be determined by the lowest national or international standards. PRP is used to assess the performance of the corporate to determine its social impact. In this case study, the impact categories are WC (Working conditions), HS (Health and safety), HR (Human rights), SER (Socio-economic repercussions), IR (Indigenous rights including cultural heritage), and G (Governance).
Check each subcategory and score it to obtain a qualitative table (corporate performance assessment, social impact assessment, degree of contribution to the impact category) and overall assessment of each stakeholder. See Table 4 for details.
Social impact of the floor product.

WC: Working conditions; HS: Health and safety; HR: Human rights; SER: Socio-economic repercussions; IR: Indigenous rights; G: Governance.
To carry on this S-LCA in the web, the process is as follows (in the web, the PSILCA database is integrated in the checklist method, which can have a more quantity assessment result): open the web and go to theS-LCA page; transform the data in Appendix 1 (Supplementary Material) according to the PSILCA database; input basic information of the floor S-LCA project and input data of subcategory and indicators in Table 3. Figures 9 and 10 show the details. Click on the calculate button; the software OpenLCA will be called to conduct S-LCA on the floor product. The calculation result will automatically appear; see Figure 11. Meanwhile, the data of the calculation results are automatically inputted into the individuals of the LCA ontology system; see Figure 12. Here, the data saved in ontology can be accumulated, shared, and reused by different users directly. The action of extracting data from the LCA software is not needed anymore.
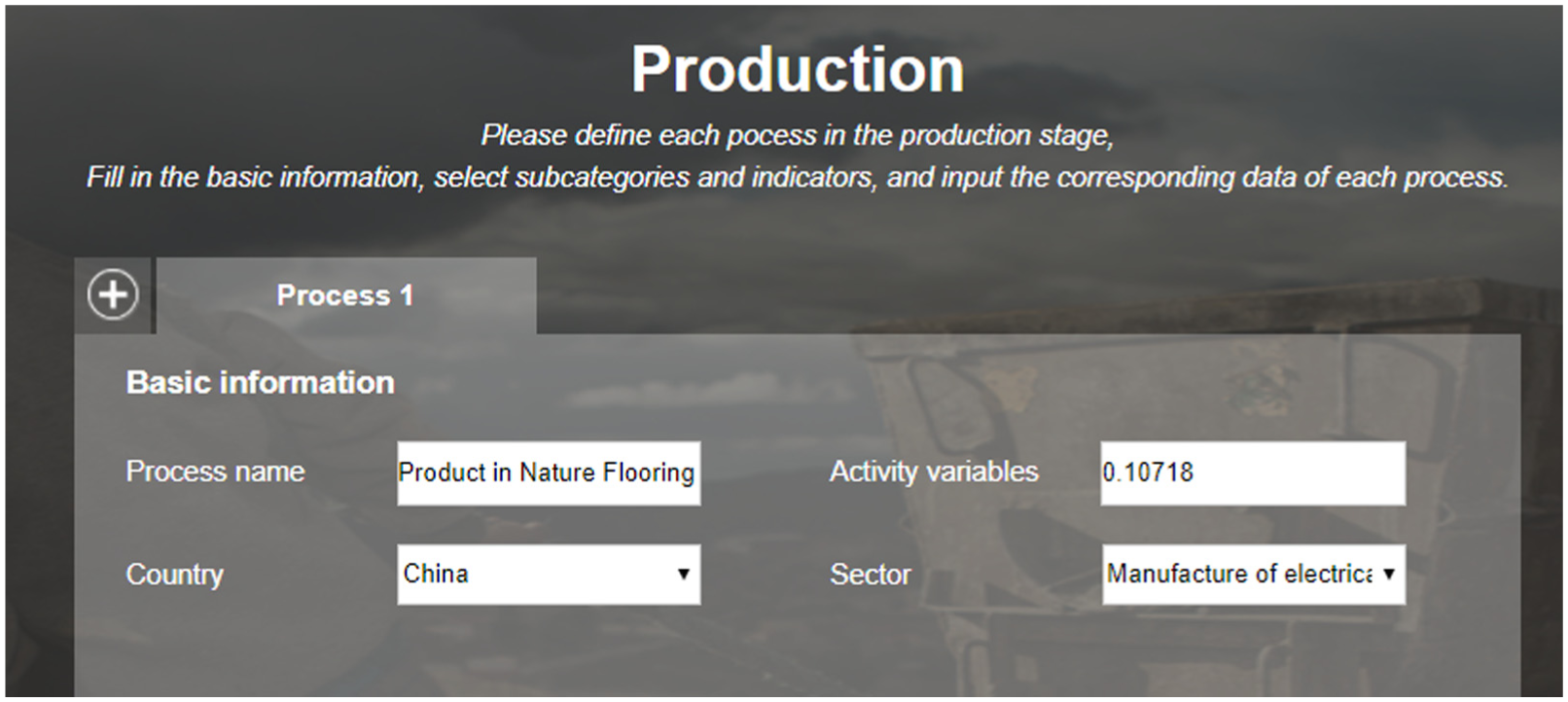
Basic information inputting.

Subcategory and indicator data inputting.

S-LCA result page.

S-LCA result data saved in ontology as individuals.
According to the result shown in Figure 11, the three social hotspots of the floor corporate are “Health and safety,”“Safe and healthy living environment,” and “Contribution of economic development.” All these issues have positive social impact. It means that the floor corporate plays really well in Chinese flooring industry.
Usability testing for the S-LCA-aided product development web
This section will discuss on the usability testing for the S-LCA-aided product development web. The focus of the testing is on the action flow and web knowledge structure, while the visual effect is also mentioned.
A total of 10 users are recruited to participate in the testing. Two of them are LCA software experts. Three users have been engaged in LCA practice for a period of time who have experience using LCA software but are not experts. The rest know about LCA but did not have experience using the software. All these users conducted S-LCA on the web according to the given case. Because the web is designed based on the knowledge system of the LCA process, all users can finish the LCA no matter whether they have used other software before or not.
After the testing, users conduct “Satisfaction evaluation” on the web. Standard of satisfaction scale is “very satisfied, satisfied, general, dissatisfied, very dissatisfied,” which has related scores as “2, 1, 0, –1, –2.” The mean value of each term is used to generate testing result; see Table 5 for details.
Question and score of usability testing.

The scores in Table 5 show that most scores of the questions are in the range of 1–2 and no negative score exists, which means that users are satisfied with the web. The usability of the web has a good performance (question 1). It has to be mentioned that the question of operation efficiency just scores 0.66 (question 2). This is because there are five users who have not used the LCA software before and they need a period of time to get used to the calculation process of LCA. However, according to questions 2 and 3, users have high assessment on the knowledge structure of the web, which demonstrates that the constructed ontology system is helpful to develop the web.
In all, the web does work well in interactive logic, information structure, and function, which can really help non-expert user to develop simple LCA well. Further research has to be done to refine the function of the web, to gather LCA result data produced by different users to develop an LCA knowledge base and to integrate more expert LCA software.
Conclusion
For the purpose of realizing the sharing and reuse of data generated by different S-LCA processes, a knowledge system–based S-LCA-aided design method is developed.
As a novel contribution, ontology is used to analyze the process of S-LCA and represent its elements as classes. Triples syntax is used to describe elements’ relationships as object properties and data structure as data properties. Then the S-LCA process knowledge system is constructed.
Based on the ontology, an S-LCA-aided product development web is developed, which can make professional S-LCA software be integrated into it. According to the structure of data properties, KRDM is used to assist the development of an exchanging database for the web. And a bidirectional mapping method between database and ontology is also brought forth, which can make the calculation result data be automatically inputted into ontology individuals.
Moreover, when user conducts S-LCA on the web, his calculation data will be automatically saved in the ontology model as individuals, which will be accumulated, shared, and reused by different users. Because all data in the ontology model have fixed URI, each user’s calculation result will be unique, which means that no data coupling will happen. The benefit is that even a beginner can conduct S-LCA on the web to secure an ideal result because he can reuse the accumulation experience of experts.
A case study of a floor product is discussed to show the feasibility of the web and the method. A user testing is carried out to show their usability. In the test, no matter experts or beginners all give high estimation on the web.
In fact, the ontology-based S-LCA-aided design method provides LCA users with a new high-efficiency approach which paves the way for intellectualization of LCA.
Supplemental Material
Appendix – Supplemental material for Ontology based social life cycle assessment for product development
Supplemental material, Appendix for Ontology based social life cycle assessment for product development by Zhen Shang, Meidan Wang, Daizhong Su, Qinhui Liu and Shifan Zhu in Advances in Mechanical Engineering
Footnotes
Handling Editor: Shengfeng Qin
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors acknowledge the support received from the “Scientific Research Foundation for the Returned Overseas Chinese Scholars (160070130003),”“Nature Science Foundation of Heilongjiang Province (QC2016063),”“State Education Ministry and the Fundamental Research Funds for the Central Universities (GK2070260135),” and “NTU Global Strategic Partnership Fund (01 PVI XX039).”
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.