
Abstract
This article proposes a fuzzy cerebellar model articulation controller with reinforcement-strategy-based modified bacterial foraging optimization for solving the cart-pole balancing control problem. The proposed reinforcement-strategy-based modified bacterial foraging optimization is used to adjust the parameters of fuzzy receptive field functions and fuzzy weights for improving the accuracy of the fuzzy cerebellar model articulation controller output. An efficient strategic approach is applied in the chemotaxis step in the traditional bacterial foraging optimization algorithm. In the approach, each virtual bacterium swims for different run lengths and increases the bacterial diversity. Experimental results are presented to show the performance and effectiveness of the proposed reinforcement-strategy-based modified bacterial foraging optimization method.
Keywords
Introduction
The most well-known supervised learning algorithm is the back-propagation (BP).1–3 Because the gradient descent technique is used to minimize the cost function, BP may fall into the local minima instead of reaching the global optima. In addition, the initial values of the system parameters dominate the BP training performance. Although the supervised learning algorithm performs efficiently with precise training data, normally, this is not the case in the real world. When the training data are rough and coarse, they can respond with “evaluative” but not “instructive” feedback in the supervised learning problem. Training an evaluative feedback network is called reinforcement learning; the evaluative feedback is scalar and is called the reinforcement signal. Apparently, the exact training data may be expensive to obtain or even unobtainable, and this has spurred wide discussions on reinforcement learning problems.4–8 Barto et al. 4 used neuron-like adaptive elements to solve difficult learning control problems with only reinforcement signal feedback. The idea of their proposed architecture was called the actor-critic (adaptive heuristic critic) architecture. Berenji and Khedkar 5 proposed a generalized approximate reasoning-based intelligent control architecture for learning and tuning a fuzzy controller based on reinforcement signals from a dynamical system. The architecture includes a priori control knowledge of expert operators in terms of fuzzy control rules. Lin and Lee 6 also proposed a reinforcement neural-network-based fuzzy logic control system (RNN-FLCS) for solving various reinforcement learning problems. The RNN-FLCS can find proper network structure and parameters simultaneously and dynamically. Recently, Anderson et al. 7 demonstrate that learning a predictive model of state dynamics can result in a pretrained hidden layer structure that reduces the time needed to solve reinforcement learning problems. Lewis et al. 8 describe methods from reinforcement learning that can be used to design new types of adaptive controllers that converge to optimal control solutions online in real time by measuring data along the system trajectories. The proposed method was applied to a power system for optimal adaptive control. According to the above-mentioned methods,4–8 their architectures require an extra critic network in addition to the action network.
Recently, evolutionary algorithms, which simulate natural evolutionary processes on the basis of Darwinian principles, have been widely applied to various fields.9–13 First, the genetic algorithm (GA),9,10 which is a popular evolutionary algorithm, was proposed. Inspired by animal social behavior, such as the flocking of birds and schooling of fishes, as well as swarm theory, researchers have proposed several evolutionary algorithms, including particle swarm optimization (PSO), 11 differential evolution (DE), 12 bacterial foraging optimization (BFO), 13 and ant colony optimization (ACO). 14 In heuristic or stochastic situation, it is unlikely to fall into the local minimum. Individuals with specific behavior are similar to certain biological phenomena. The identification of common features between the two has led to the development of evolutionary computation. In this study, we focused on BFO, which was inspired by the foraging behavior of E. coli in the intestines. BFO has a parallelizable searching ability. However, for complex optimization problems, the traditional BFO does not easily yield optimal solutions. Therefore, the performance of the traditional BFO depends on the run length of chemotaxis. To overcome this problem, several researchers have proposed the use of adaptive run-length strategies15–18 for verifying the influence of bacterial run length on executable results. The current study focused on the chemotaxis step for improving the BFO algorithm. Therefore, the strategy method was adopted.
Recently, many researchers19–21 have used evolutionary algorithms for reinforcement learning. GA-based fuzzy reinforcement learning was proposed by Lin and Jou 20 for controlling magnetic bearing systems. Juang et al. 21 presented genetic reinforcement learning, which could be used for designing fuzzy controllers. The GA adopted in Juang et al., 21 which is based on traditional symbiotic evolution, complements the local mapping property of a fuzzy rule when applied to fuzzy controller design. Li et al. 22 proposed an efficient navigation control method of mobile robot. According to the relative position between the mobile robot and the environment, the behavior manager switches to determine toward goal behavior or wall-following behavior of mobile robot. A novel recurrent fuzzy cerebellar model articulation controller (CMAC) based on a reinforcement improved dynamic artificial bee colony is proposed for performing wall-following control of mobile robot.
This study proposes a fuzzy cerebellar model articulation controller (FCMAC) with reinforcement-strategy-based modified bacterial foraging optimization (R-SMBFO) for solving the cart-pole balancing control problem. The proposed R-SMBFO is used to adjust the parameters of fuzzy receptive field functions and fuzzy weights for improving the accuracy of the FCMAC output. An efficient strategic approach was applied to the chemotaxis step in the traditional BFO algorithm. In the strategic approach, each virtual bacterium swims for different run lengths and increases the bacterial diversity.
The remainder of this article is organized as follows: Section “FCMAC” introduces the proposed FCMAC and section “Reinforcement bacterial foraging optimization” describes the proposed R-SMBFO learning algorithm. The control of the cart-pole balancing system is addressed in section “Control of a cart-pole balancing system.” Finally, Section “Conclusion” concludes the paper.
FCMAC
The traditional CMAC, which imitates the function and structure of the human cerebellum, is a popular neural network model. 2 The input space of a CMAC network is quantized into discrete states, and overlapping areas are called hypercubes. Each hypercube covers many discrete states and is assigned a memory cell for storing information. For an input state, only a few hypercubes are activated, and they contribute to the corresponding network output. The superiority of the CMAC model lies in its quick learning speed, high convergence rate, and simple hardware implementation. However, the model has certain drawbacks, which include substantial computing memory requirements and relatively poor function approximation ability. Fuzzy modeling is recognized as a powerful tool for developing models from various sources. The FCMAC overcomes the disadvantages of the traditional CMAC model using fuzzy membership functions.23,24
Albus’ CMAC model has three major limitations: the selection of the memory-structure parameters is difficult, a rigorous theory is required for function approximation, and substantial memory is required for solving high-dimensional problems. Therefore, to overcome these limitations, an efficient FCMAC model is proposed here. The structure of the FCMAC model is shown in Figure 1.

The structure of the FCMAC model.
In the proposed FCMAC model, a Gaussian function is used as the fuzzy receptive field function and the fuzzy weight function for learning. Some learned information is stored in the fuzzy receptive field function and fuzzy weight function, represented using the mean and variance of Gaussian functions. Similar to the traditional CMAC model, the proposed FCMAC model approximates a nonlinear function y = f(x) using two primary mapping functions


where X, A, and D are an s-dimensional input space, an NL-dimensional association space, and a one-dimensional output space, respectively. These two mapping functions are realized through fuzzy operations. The function S(x) maps each state x in the input space X onto an association memory selection vector
The proposed FCMAC model consists of three layers. Layer 1 is called the input layer. The fuzzy receptive field function uses the Gaussian function

where x is the input state and m and σ are the center and variance of the fuzzy receptive field function, respectively.
An ND-dimensional problem is considered in layer 2, and the ND-dimension Gaussian function is expressed as follows

where
In Layer 3, the value of the association memory selection vector corresponding to each fuzzy weight is treated as the input matching degree to produce a partial fuzzy output. The Gaussian basis function used in this study is combined with the centroid defuzzification method, which is used to defuzzify the partial fuzzy output into a scalar output. For 2D functions, the crisp output y is derived as follows

where
Reinforcement bacterial foraging optimization
Proposed R-SMBFO
In this study, a novel R-SMBFO method is proposed. The strategy method in the chemotaxis step of the traditional BFO algorithm was adopted to solve the long execution time required for multidimensional problems and solve the trapping problem for determining local optimal solutions.
A bacterium represents a solution of the optimization problem, and it can be expressed as a D-dimensional vector,

where
The bacterial population can be expressed as
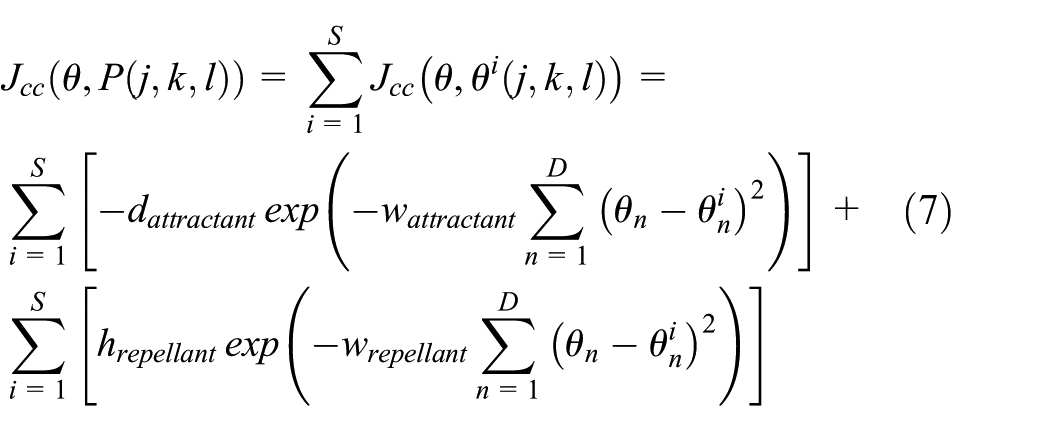
where

In Oentaryo et al.,
25
the solution of the optimization problem depends on the bacterial run length. In the strategy method, the previous and current fitness functions of each bacterium are stored and the two fitness functions are compared to lead an evaluation. If the current fitness function is more advantageous than the previous one, the “+” sign is marked. If the current fitness function is more disadvantageous than the previous one, the “−” sign is marked. Otherwise, the “=“ sign is marked. In this case, the current and previous fitness functions have the same advantageous. In the strategy method, the status is obtained from three consecutive fitness functions and is a combination of two consecutive signs from above-mentioned three signs (i.e. “+,”“−,” and “=”). For example, the status (=+) denotes that the fitness values
The strategy method.

Deterioration: –; status quo: =; improvement: +.
As shown in Table 1, the statuses in the proposed strategy method are divided into three cases. The position of the run length (
The strategy method in the chemotaxis step of the BFO was adopted. The formulations of the bacterial position and the bacterial run length in different strategies are as follows:
Case 1


Case 2
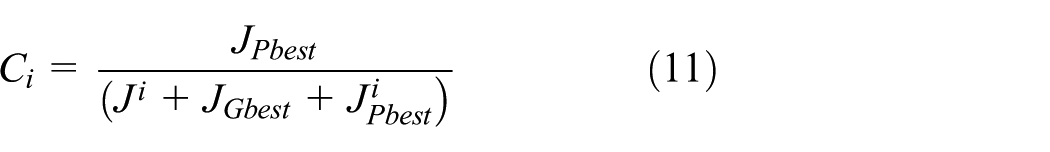
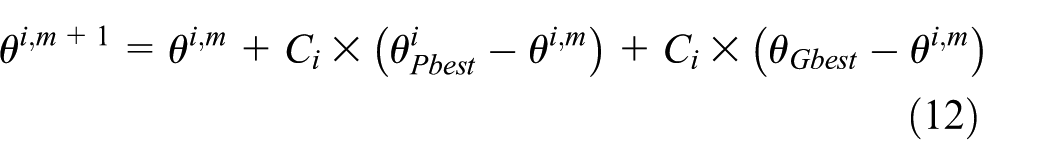
Case 3


where
Consider the following definitions of variables:
Step 1: Initialize the parameters S,
Step 2: Elimination-dispersal loop:
Step 3: Reproduction loop:
Step 4: Chemotaxis loop:
Step 5: Chemotaxis step:
For bacterium i,
The new position of the bacterium is updated and the fitness function is estimated using equation (6).
For swimming step m,
According to Cases 1–3 of the strategy method, a strategy is evaluated and Ci is updated.
Compute the new position of the bacterium using equations (9), (11), or (13).
Evaluate the fitness function and update the strategy status
Next m
Next i
Step 6: If
Step 7: Reproduction: Evaluate the health of bacteria.
Step 8: If
Step 9: Elimination-dispersal: If a random value is generated and is less than probability p, the bacterium will be randomly assigned to a new position. The parameter
If

Flowchart of the proposed chemotaxis step.
Reinforcement learning for FCMAC
The desired outputs for each input are provided in the supervised learning problem, whereas the reinforcement learning problem requires only simple “evaluative” or “critical” information for learning. Only a small amount of information is available to indicate whether the output is right or wrong. Figure 3 shows the R-SMBFO. In this study, the reinforcement signal indicates whether a success or a failure control occurs.
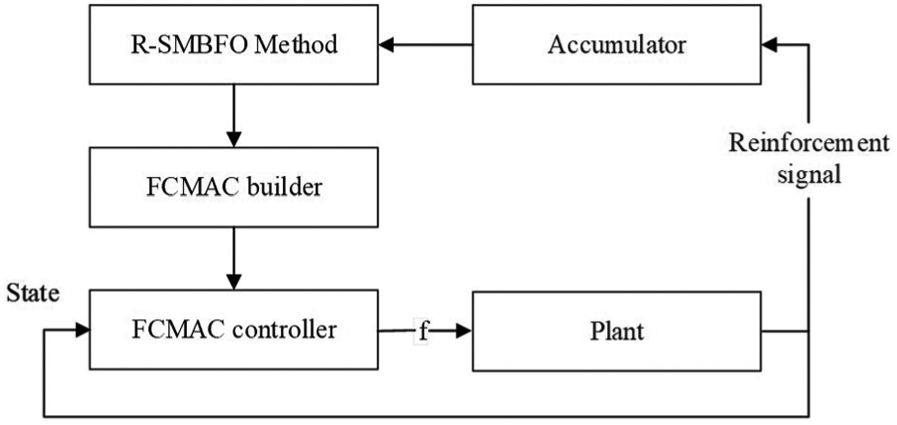
Schematic diagram of the R-SMBFO for the FCMAC controller.
The proposed FCMAC, shown in Figure 3, is the control network that initiates appropriate actions according to the current input vector. The actor–critic architecture of Barto et al. 4 consists of a control network and a critic network. By contrast, the input and output of the proposed FCMAC are the state of a plant and a control action of the state, respectively, denoted by f. The reinforcement signal is generated only when a failure occurs, and it is the one and only available feedback notifying the FCMAC.
Figure 3 shows a schematic diagram of the R-SMBFO for the FCMAC controller which consists of an accumulator, a relative performance measure indicator, accumulates the number of time steps before a failure occurs. An accumulator measures the duration of the experiment in a “success” state, and this feedback is treated as the fitness of the proposed R-SMBFO method; in other words, the accumulator is the indicator of the “fitness” of the current FCMAC. Before failure occurs, it is essential for R-SMBFO to determine an expression for the number of time steps and treat the formula as the fitness function. In the proposed method, no critical network is required for use as a multistep or single-step predictor.
Figure 4 describes the R-SMBFO method for the FCMAC. The method is applied in a feed-forward situation, and it monitors the environment (plant) until a failure occurs. The fitness function is measured for the duration of the experiment in a “success” state by the aforementioned accumulator. A fitness value is assigned to each string in the population. If a fitness value has a higher value, the corresponding string has a better solution. In this study, many time steps were used to define the fitness function before failure occurred. The R-SMBFO maximizes the fitness value, and the fitness function is given as follows

where TIME_STEP(i) records the duration that the experiment is in a “success” state for the ith population. Equation (15) indicates that longer time steps (keeping the desired control state longer) imply a higher fitness of the R-SMBFO method.

Flowchart of the proposed reinforcement learning method.
Control of a cart-pole balancing system
This section discusses the control of a cart-pole balancing system, 4 which was considered to evaluate the FCMAC along with the R-SMBFO method. In the experiment, we used a Pentium(R) 4 chip processor with a 3.2 GHz CPU, a 1 GB memory, and visual C++ 6.0 simulation software. The initial parameters of the R-SMBFO before training are presented in Table 2.
Initial parameters before training.

The classical control problem of cart-pole balancing was examined in this study by applying the proposed R-SMBFO. As shown in Figure 5, the cart-pole balancing problem involves learning how to balance an upright pole properly. Both the cart and the pole only move vertically, and each of them has 1 degree of freedom. The parameters




where the length of the pole l = 0.5 m, the combined mass of the cart and pole m = 1.1 kg, the mass of the pole mp = 0.1 kg, the acceleration due to gravity g = 9.8 m/s, the friction coefficient of the cart on the track
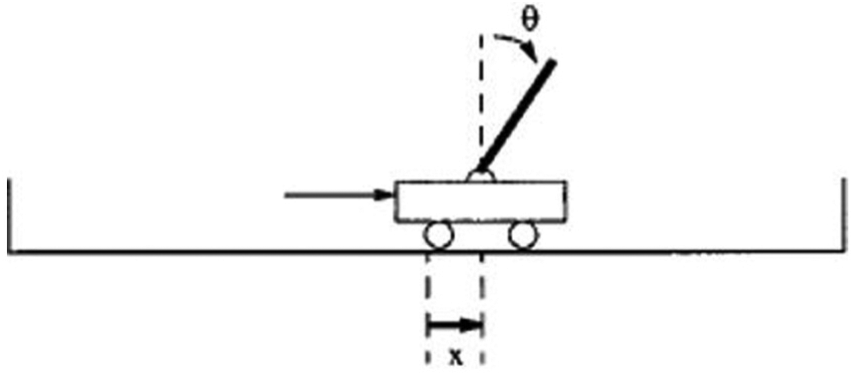
The cart-pole balancing system.
The four input variables
The initial values of the input variables in the experiment were set to (0, 0, 0, 0). Each experiment consisted of 30 runs, and each run started with the same initial state. Figure 6(a) shows that the average number of generations required for balancing the pole using the FCMAC and R-SMBFO learning method is 9.82. In this figure, the largest fitness value of each run in the current generation is selected before the cart-pole system fails. When R-SMBFO learning stops, the best strings of the swarm in the final generation are selected and tested on the cart-pole balancing system.

Figure 7(a) shows the angular deviation of the pole when the cart-pole balancing system was controlled by the FCMAC with the R-SMBFO leaning method; the system started from the initial state given by


Angular deviation of the pole with the sampling time 0.002 s by a trained the proposed R-SMBFO method.
We also compared the control performance of the proposed method with that of reinforcement particle swarm optimization (R-PSO) 26 and the reinforcement genetic algorithm (R-GA) 27 by applying all these methods to the same problem. Figure 6(b) and (c) shows that an average number of generations required for balancing the pole using the R-PSO and R-GA methods are 12.94 and 15.47, respectively. Figure 7(b) and (c) shows the angular deviations of the pole as presented in Kennedy and Eberhart 26 and Karr. 27 The average angular deviations of the R-PSO and R-GA methods are 0.0506 and 0.0481, respectively. Thus, in the experiment, the proposed R-SMBFO method showed superior control performance compared with these two methods.26,27
The GENetic ImplemenTOR (GENITOR), 19 reinforcement symbiotic evolution (R-SE), 21 symbiotic adaptive neuro-evolution (SANE), 28 the temporal difference and genetic algorithm-based reinforcement (TDGAR), 20 and the clustering- and Q-value-based genetic algorithm learning schemes for fuzzy system design (CQGAF) 29 have also been tested on the same control problem, and Table 3 shows the simulation results. In the table, the number of trials represents the number of training episodes required. The structure of the neural network considered in Whitley et al. 19 included five input nodes, five hidden nodes, and one output node, and the authors adopted a GA to adjust the weights in a neural network. In Juang et al., 21 R-SE was used to adjust the parameters of a recurrent neural fuzzy network, and the population size, crossover rate, and mutation rate in R-SE were set to 200, 0.5, and 0.3, respectively. The use of SANE in Juang et al. 21 involved the application of a symbiotic evolution algorithm to a neural network with five input nodes, eight hidden nodes, and two output nodes. In TDGAR, 20 a new hybrid learning algorithm integrates the temporal difference (TD) forecasting method and the GA to perform reinforcement learning. In the CQGAF, 29 a weak reinforcement signal is used to perform GA-based fuzzy system design. Results presented in Table 3 show that the proposed R-SMBFO is highly feasible and effective.
Performance comparisons of various existing models.

R-SMBFO: reinforcement-strategy-based modified bacterial foraging optimization; R-PSO: reinforcement particle swarm optimization; R-GA: reinforcement genetic algorithm; R-SE: reinforcement symbiotic evolution; SANE: symbiotic adaptive neuro-evolution; TDGAR: temporal difference and genetic algorithm-based reinforcement; GENITOR: GENetic ImplemenTOR; CQGAF: clustering- and Q-value-based genetic algorithm learning schemes for fuzzy system design.
In this study, the CPU times were used to compare the proposed method with existing methods.19–21,25,27–29 The comparison results are shown in Table 4. The average CPU time of the R-SMBFO method was 12.57 s. The comparison in Table 4 shows that the proposed R-SMBFO method requires a shorter CPU time than the other existing methods.
The comparison of CPU time for various existing models.

R-SMBFO: reinforcement-strategy-based modified bacterial foraging optimization; R-PSO: reinforcement particle swarm optimization; R-GA: reinforcement genetic algorithm; R-SE: reinforcement symbiotic evolution; SANE: symbiotic adaptive neuro-evolution; TDGAR: temporal difference and genetic algorithm-based reinforcement; GENITOR: GENetic ImplemenTOR; CQGAF: clustering- and Q-value-based genetic algorithm learning schemes for fuzzy system design.
Conclusion
This study proposes a FCMAC with an R-SMBFO learning method and applied it to the cart-pole balancing control problem. The proposed R-SMBFO uses a strategy method in the chemotaxis step. The advantages of the proposed method are that each bacterium swims for different run lengths and increases the bacterial diversity. The R-SMBFO learning method was used to adjust the parameters of the FCMAC. Experimental results showed that the performance of the FCMAC with R-SMBFO learning is superior to that of other methods.
Footnotes
Handling Editor: Silvia Rodrigo
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors would like to thank the Ministry of Science and Technology of the Republic of China, Taiwan for financially supporting this research under Contract No. MOST 106-2221-E-167-016.