
Abstract
In this article, a tree-indexed demarcation using forward and backward searches is proposed to segment the seriously touching characters, which is used as an important procedure for the character recognition in the real industrial scenarios. Unlike the segmentation directly depending on the histogram analysis, the reliable and unreliable valleys are first identified from a smoothed projection curve in our method, where a set of image pre-procedures are carefully carried out to catch this smoothed curve. With these operations, two segment binary trees are sequently constructed via the corresponding forwarding and backward searches of the valleys. Then, the delimiter candidates are sophisticatedly selected with a number of well-designed rules. The optimal segmented paths are finally obtained on the width variation measure of the characters, and the isolated characters are achieved. Experiments show that with our tree-indexed demarcation using forward and backward searches method, the touching character groups can be effectively segmented to better serve the industrial automatic recognition system.
Introduction
Character segmentation plays an important role in a variety of character recognition systems. 1 It is very often viewed as a pre-procedure for character recognition, which aims not only to extract characters from the background, but also to isolate touching characters from each other to provide more reliable character information. To our best knowledge, some existing character recognition systems have been well performed without the segmentation. For example, a recognition method is recently proposed using a recurrent neural network to identify words in various scenes, 2 which fully exploits the context-aware relationship among characters. However, with the limited context-based priors, character segmentation is still essential to isolate the characters one by one for the better recognition. As one of the most successful applications, the segmentation is efficiently carried out in the license plate recognition system, wherein license characters are also lack of the context-based priors. Now a plenty of work has been dedicated to the character segmentation rather than the recognition in this system.3–5
In general, the segmentation strategies for characters, especially for touching characters, can be categorized into two major groups, that is, character-based and recognition-based segmentations. For the character-based segmentation, only geometric attributes of characters are taken into account. Character features, such as spatial shape and histogram, are employed to provide the segmented information. For example, a well-known shortest path cutting method is presented to separate two touching characters, where a cost function is defined to measure the payment for each hypothetic cutting path.6–8 Moreover, a morphological segmentation algorithm is developed to deal with the merged handwritten numbers, where the thinning procedure is incorporated to analysis both the foreground and background regions of characters.9,10 As for the recognition-based segmentation, the target character not only is separated from others, but also is tested via some recognition methods. Once the target character is identified, the segmentation procedure is continued for the rest characters. Here, a number of recognition approaches, for example, template matching, neural network, and hidden Markov model (HMM), are used for the segmentation, which significantly improves the accuracy performance for characters. In Song et al., 11 a merged-character recognition framework is sophisticatedly designed, where a necessity–sufficiency matching is adopted for the segmentation with its character-adaptive template masking. Furthermore, a HMM-based segmentation is successfully presented to deal with Urdu scripts. 12 In this method, the features of Urdu characters are trained from both the horizontal and vertical projection profiles and then are dedicated to find delimiters in the given touching group. To address the neural network approach, a reinforcement learning method is recently put forward to search appropriate cutting paths via text recognition with a deep belief network. 13
From an application perspective, the segmentation is mainly to deal with two kinds of characters, that is, printed and handwritten ones. For the printed characters, they numerously exist in text documents with the normalized types. However, due to the over-tight machined-typed gaps, some of them may be adhesive with others in one word. Thus, various segmentation methods are developed to extract the isolated characters from documents by the printed priors, including the aforementioned shortest path cutting approach. In the early research, a method with projection profiles and topographic features of printed characters is proposed to achieve an acceptable segmentation performance. 14 Later, a localization-based method is given for the segmentation, where the geometric center of each character is tagged through a centroid approach. 15 Very recently, an effective algorithm is further presented via a modified projection profiles technique, which fully exploits the histogram processing to determine the delimiters among characters. 16 As for the handwritten characters, the situation becomes more complicated due to touching characters substantial increasing with the scratchy writing. To tackle this trivial problem, a segmentation method with self-organizing feature maps is developed to take advantage of the corresponding neuron node position for each character. 17 Moreover, a segmentation framework is also referred in the Arabic handwritten characters recognition system, where the ascender and descender segmentations are adopted to form the final delimiter decision. 18
However, these traditional character segmentation methods are seldom used in the industrial scenarios. In fact, although printed characters are widely incorporated on products as their identified numbers, the characters captured from industrial cameras tend to be distorted and deteriorated by a variety of factors. As the result, industrial robots on the product line cannot response to the right characters and perform the corresponding programming operations.19,20 In these factors, aiming to better recognize the characters, auxiliary lights are very often employed to mitigate the effect of the varied environment lights from the captured images. Unfortunately, these auxiliary lights may cause a number of unpredictable and strong diffuse emissions on the product surface, which degrades the quality of the captured images with a mass of noises. Moreover, since the printed characters are labeled on the products in different ways, such as sealing and spray painting, in different scenes, not only numerous touching characters are generated, but also some priors of printed characters are varied with an uncertain change. Therefore, we define these distorted characters as the printed-like ones. In this article, the characters spray-painted on steel billets, which are typically degraded into the printed-like ones in the captured images, are presented as a classical industrial instance. And for convenience, our segmentation method is performed on this instance here after.
Motivated by the recent process, we propose a segmentation method to isolate characters in the industrial scenario, especially in the scene of the steel billets. In details, a series of image pre-processing is incorporated to effectively extract the regions of touching character groups from the captured images. As for the segmentation, a tree-indexed demarcation using forward and backward searches (FBS-TD) is presented with the histogram analysis. The major contribution of our work can be included into three aspects:
Unlike the traditional delimiter decision approaches via the histogram, the valleys of the vertical projection curve are carefully distinguished as reliable and unreliable ones and are used as the reference markers for character delimiters.
A binary tree is built with delimiter candidates, where these candidates are derived from the aforementioned reliable/unreliable valleys with both the forward and backward searches. Here, our segmentation procedure treats the touching character group as a whole, instead of the sequential segmentation in most of the existing methods.
With the measure on the width variation of characters through each path, an optimal path is selected from the binary tree. In practice, the first several optimal paths are chosen to generate different isolated character sequences, which significantly improve the robustness of the following character recognition to satisfy the real industrial scenario.
Experiments show that the touching characters are successfully segmented via the FBS-TD algorithm, where the prior uncertainty of the printed-like characters is efficiently reduced during the delimiter decision for the whole touching group. Especially, in some seriously touching cases, for example, to deal with even five merged characters, our method still can achieve a reliable segmentation performance.
The article is organized as follows. Details of the image pre-procedure are referred in section “Image pre-procedure for segmentation,” while the proposed FBS-TD method is presented in section “Proposed segmentation algorithm.” Experimental results are given in section “Experimental results,” and the conclusion is drawn in section “Conclusion.”
Image pre-procedure for segmentation
In the image pre-procedure, a series of operations are carried out on the captured grayscale images from the industrial camera. The major target of these operations is to turn the grayscale images into the corresponding refined binary ones, while the regions of touching character groups are accurately tagged as the materials for the sequential segmentation. In our pre-procedure, it can be divided into three stages, that is, image denoising, character correction, and region extraction for touching character groups.
Image denoising
A generalized image denoising is carefully designed to deal with the noised captured image. Instead of the traditional denoising merely focusing on removing noise, our generalized denoising to a large extent attempts to obtain a binary image, called as rough binary image, for the better representation of target characters. To this end, some sophisticated methods are employed in our project. Different binary versions are respectively achieved from these methods and used to form the rough binary image. More specifically, the Otsu approach 21 is first incorporated to transform the captured image into one binary image. Here the Otsu not only separates character regions from the billet surface, but also tries its best to alleviate the local illumination variations of the grayscale image. Meanwhile, the well-known Niblack algorithm 22 is also adopted to filter the captured image via a pixel-based adaptive threshold. The second binary image is sequently generated to highlight the borders of character strokes. By the advantages of the Otsu and Niblack, a rough binary image is synthesized with these two images via some morphological operations. However, there still exist a number of small speckle-like noises in the rough image, which is caused by the aforementioned random diffuse emissions on the billet surface. Thus, some simple but effective denoising methods, such as median and meaning filterings, are used to wipe out the speckles.
Character correction
Although the characters are now represented in the rough binary image during the denoising procedure, they suffer from some other problems, that is, stroke breaks and holes in characters. Therefore, character correction is dedicated to achieve a more refined binary image via character inpainting. For example, a conditional dilation approach 23 is used to deal with broken strokes, where the structural morphological analyses and the stroke extension are carried out with the minimum distance detection between two structural points. To fill holes in characters, a simple filter is adopted via the morphological opening and closing. With these operations, the characters are more approximated to the standard printed ones, which can provide more accurate histogram information for our segmentation.
Region extraction for touching characters
In this stage, we focus on the touching character extraction from the refined binary image. The minimum enclosing rectangle method 24 is employed to separate the binary image into several regions, where each region contains either an isolated character or a touching character group. With the average width prior of single characters, the touching character groups can be easily picked out by testing their region widths and are used as target materials for the character segmentation.
To illustrate the whole image pre-procedure, an example of characters on the billet surface is shown in Figure 1, where the captured image, its rough and refined binary images, and the corresponding touching groups are respectively given. It shows that the billet characters are well represented in the refined binary image, since the image denoising and character correction effectively performed on the captured image. Here, not only speckle-like noises are removed, but also characters are corrected with their more smooth strokes in the refined image. Consequently, the regions of touching character groups are successfully extracted with their minimum enclosing rectangles. It is worth mentioning that the serious adhesions do exist in this example, where even five characters are merged in the first touching group to bring a great challenge for the segmentation.

Illustration for image pre-procedure. From top to bottom, images denote the captured grayscale image, the corresponding rough and refined binary images, and the regions of touching character groups.
Proposed segmentation algorithm
A segmentation method via the FBS-TD is proposed to deal with the serious adhesions among characters. Our method is mainly divided into three parts, that is, local valley analysis, binary tree construction and segmented path optimization, as shown in Figure 2. In the local valley analysis, the existing vertical projection approach is used to obtain a series of local valleys. Meanwhile, the valleys are distinguished as reliable and unreliable ones. Sequently, a segment binary tree is built with the delimiter candidates derived from these valleys, where a delimiter selection strategy is presented by screening all reliable/unreliable valleys in both forward and backward directions. Thus, the binary tree efficiently includes all possible segmentation situations for the touching group, where each path on the tree represents a segmentation case. During the segmented path optimization, the variation measure is incorporated to test the widths of the segmented characters on each path. The optimal isolated character sequence is finally obtained with the corresponding path of the minimal width variation.

Framework of our segmentation procedure.
Local valley analysis
The histogram analysis is first performed on the target touching character group to obtain its vertical projection curve. Mathematically, the delimiters of merged characters are very often matched with the local valleys of the projection curve. Inspired with this idea, the traditional vertical projection approach pays attention on these valleys to find the relatively accurate delimiters for characters. However, in the real industrial scenario, the situation becomes more complicated, especially in the case for the serious adhesions of several characters. Here, we heuristically cast the valleys into three categories, that is, delimiter valleys, character, and false ones. The delimiter valleys indicate the accurate delimiters. Meanwhile, character valleys contain the intrinsic information of characters themselves, which are fixed for the given symbol just as shown in Figure 3. For the false valleys, they are derived from the uncertainty of printed-like characters, such as the noise perturbation and irregular strokes, which may cause trouble for the segmentation. Nevertheless, most of false valleys can be viewed as small-scale disturbances on the projection curve. To alleviate these disturbances, a graphical smoothing approach is adopted, where a curve-based binary image is first built. In this image, the pixels are set to 0, once their locations are below the curve, while others are set to 1. And a smoothed projection curve is achieved with a morphology filter for this binary image. More details of this approach are shown in Figure 4. In this figure, compared with the original vertical projection curve, only a limited number of valleys are reserved on the smoothed curve, where a variety of false valleys is removed.

Character valleys for printed characters with their corresponding histograms: (a) symbol “B” and (b) symbol “5.”
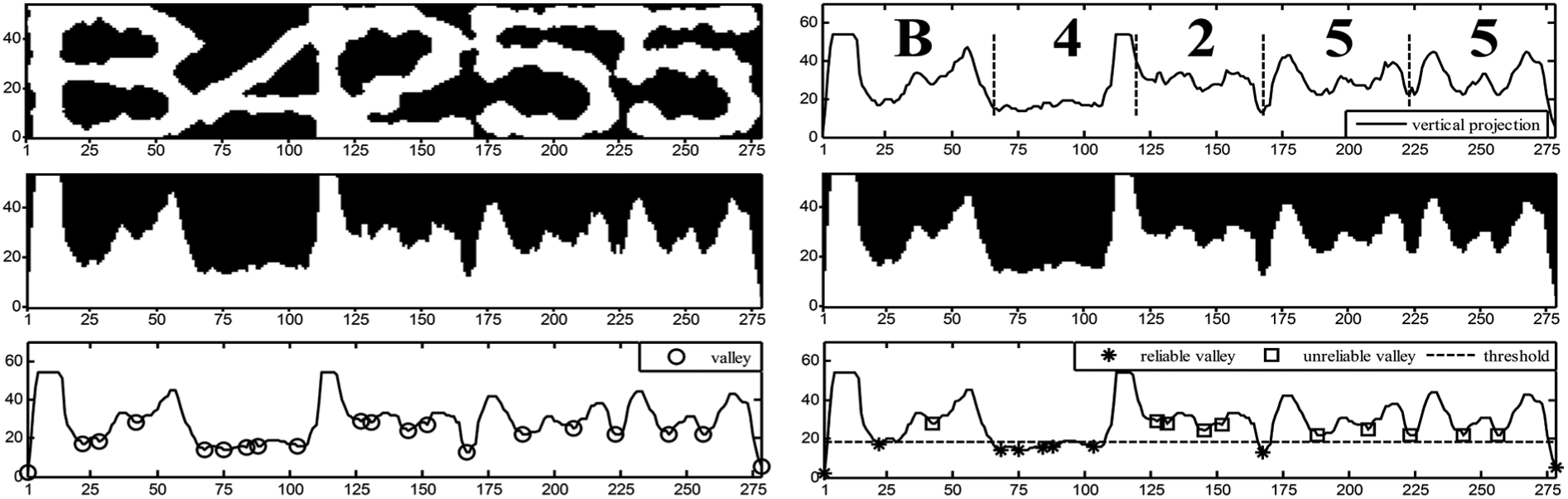
Illustration for reliable and unreliable valleys from the touching group image. The subfigures from left to right and from top to bottom respectively represent the touching character group, original vertical projection curve, curve-based binary image, smoothed binary image with erosion operation, smoothed vertical projection curve, and the final markers for reliable/unreliable valleys. Here, the positions of reliable and unreliable valleys locate at {1,22,68,75,84,88,103,167,278} and {42,127,131,145,152,188,207,223,244,257}.
However, it still cannot identify the delimiter valleys directly from the smoothed vertical projection curve. In practice, we only divide the valleys into two categories, that is, reliable and unreliable valleys, with a given threshold. The reliable valleys are selected, once the valleys are below the threshold. We believe that the delimiter valleys are included in these valleys with a high possibility. Conversely, the other valleys are defined as unreliable ones. It is worth mentioning that some unreliable valleys over nearby the reliable ones are empirically removed to further reduce the valley number. For example, the unreliable valley close to the second reliable one is wiped in the last subfigure of Figure 4.
Segment binary tree construction
Since a set of reliable and unreliable valleys are well obtained during the local valley analysis, two segment binary trees are respectively constructed with the forward and backward searches. To express the construction procedure more clearly, each tree node represents a delimiter candidate that is chosen from the valleys with our proposed selection strategy. Given a delimiter candidate as the parent node, two delimiter candidates are picked up as the corresponding child nodes for the segmentation of the next character, which should be satisfied with the following rules.
Rule 1
The candidates should be selected from valleys which are located in the range of
Rule 2
Using D as a reference location, the most nearby valley on each side of D is selected as a delimiter candidate, where reliable valleys have priority to unreliable ones. Once no valley exists on one side, the corresponding delimiter candidate for this side is tagged with the value of −1.
Rule 3
The valley is directly selected as a delimiter candidate, when it locates at D. As for the other candidate, it is chosen with the nearby valley, where the reliable valley is still preferred. However, when no other valleys locate in the given range, such candidate is also tagged with the value of −1.
Rule 4
The delimiter candidate search for the child nodes is stopped if the parent node location
More specifically, some examples are given in Figure 5, where the delimiter candidates are selected from the varied valleys in different situations. Here, we represent the valley with its corresponding location. For instance, the valley located at N is named as Valley N. Note that in Case 1 of Figure 5, although Valley N is closer to the reference location D than Valley M, the delimiter candidate is still set at Valley M due to the priority of reliable valleys in Rule 2. In Case 2, since there are no valleys on the left side of D, the corresponding candidate is set to −1 with Rule 2. As for Case 3, the Valley D is directly chosen according to Rule 3, while the nearest Valley P is following selected.

Selection illustration for delimiter candidates in different cases. Symbols * and □ denote the reliable and unreliable valleys, respectively; (·) denotes the delimiter candidates.
With the selection rules for delimiter candidates, two segment binary trees are built with the forward and backward searches. For the touching character group in Figure 4, the corresponding binary trees can be achieved in Figure 6, where the average character width

Segmented path with forward and backward searches for the touching characters in Figure 4. The value in each node represents the corresponding delimiter candidate’s location: (a) binary tree with forward search and (b) binary tree with backward search.
Segmented path optimization
We note that there exist a number of complete paths for the touching characters as shown in Figure 6. However, only one path is the accurate path for the segmentation. Thus, an approach is proposed for the optimal path selection, wherein a variation minimization measure is incorporated to test the widths of the isolated characters of the touching group.
Given a complete path, the number of characters is equal to the layer number of the binary tree. The width of each character can also be calculated with the distance between the adjacent delimiter candidates on the path. Thus, the variation of character widths on the corresponding path is obtained. Assuming the widths of all characters are almost the same, the complete path with the minimal variation is selected as the optimal one by

where
In practice, the minimal width variation strategy performs not well enough. Once the characters are overlapped to some extent, the aforementioned equal width assumption may be invalid. In this case, the widths of characters have a larger variation value. Moreover, there exist some narrow characters, that is, symbol “1”, which are also not in accord with this assumption. When these characters adhere to other characters, the variation minimization strategy becomes inefficient. To relieve these impacts, the n-variation minimization method is adopted to enhance the robustness of character segmentation in the industry scenario as
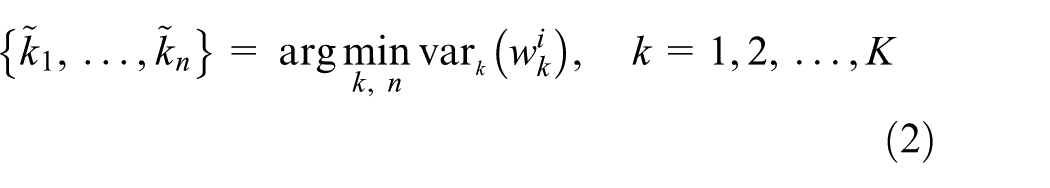
where the first nth paths of the minimal width variations are selected.
To illustrate our strategy, the example is still used with the binary trees in Figure 6, where the variations on all complete paths are shown in Table 1. The corresponding isolated characters of the first two optimal paths are further represented in Figure 7. Note that although Path 3 achieves the minimal width variation in Table 1, its mistake segmentation result is achieved in Figure 7. It is because there are too many reliable/unreliable valleys exist during the interval of the serious overlapped symbols “4” and “2” as shown in Figure 4. As a result, the equipartition tends to be performed with its minimal width variation. On the contrary, Path 2 of the second minimal variation is more accurate for the segmentation, which increases the robustness of the segmentation.
Selection for the optimal segmented path.

The bold values are described as the paths with the first two minimal width variations.

Character segmentation with the n-variation minimization in Table 1: (a) characters in Path 2 and (b) characters in Path 3.
Experimental results
To evaluate the performance of the proposed FBS-TD method, we extract various touching character groups as test materials from different captured steel billet character images. In details, there are about 280 touching character groups obtained from 120 steel billet character images. Among these groups, the number of merged characters varies from two to five as shown in Figure 8. In our experiments, the first two optimal paths are selected with their corresponding minimal width variations as the final segmentation results. And the segmentation is defined as a successfully one, once all characters on one of the optimal paths are relatively accurate isolated. Actually, this definition is reasonable for the real industrial recognition system, since the character recognition can only be activated along with the correct segmentation.

Samples of captured steel billet character images.
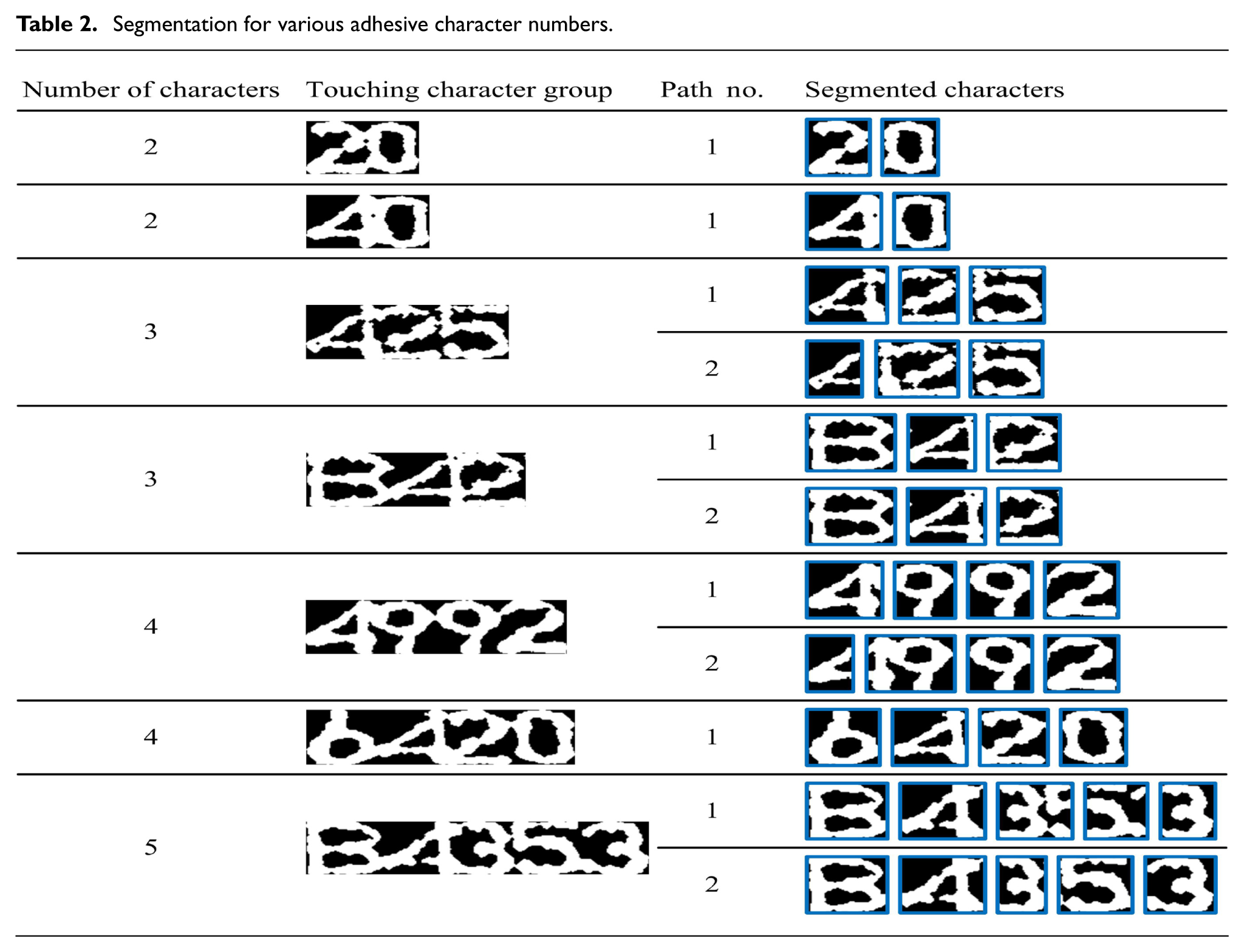
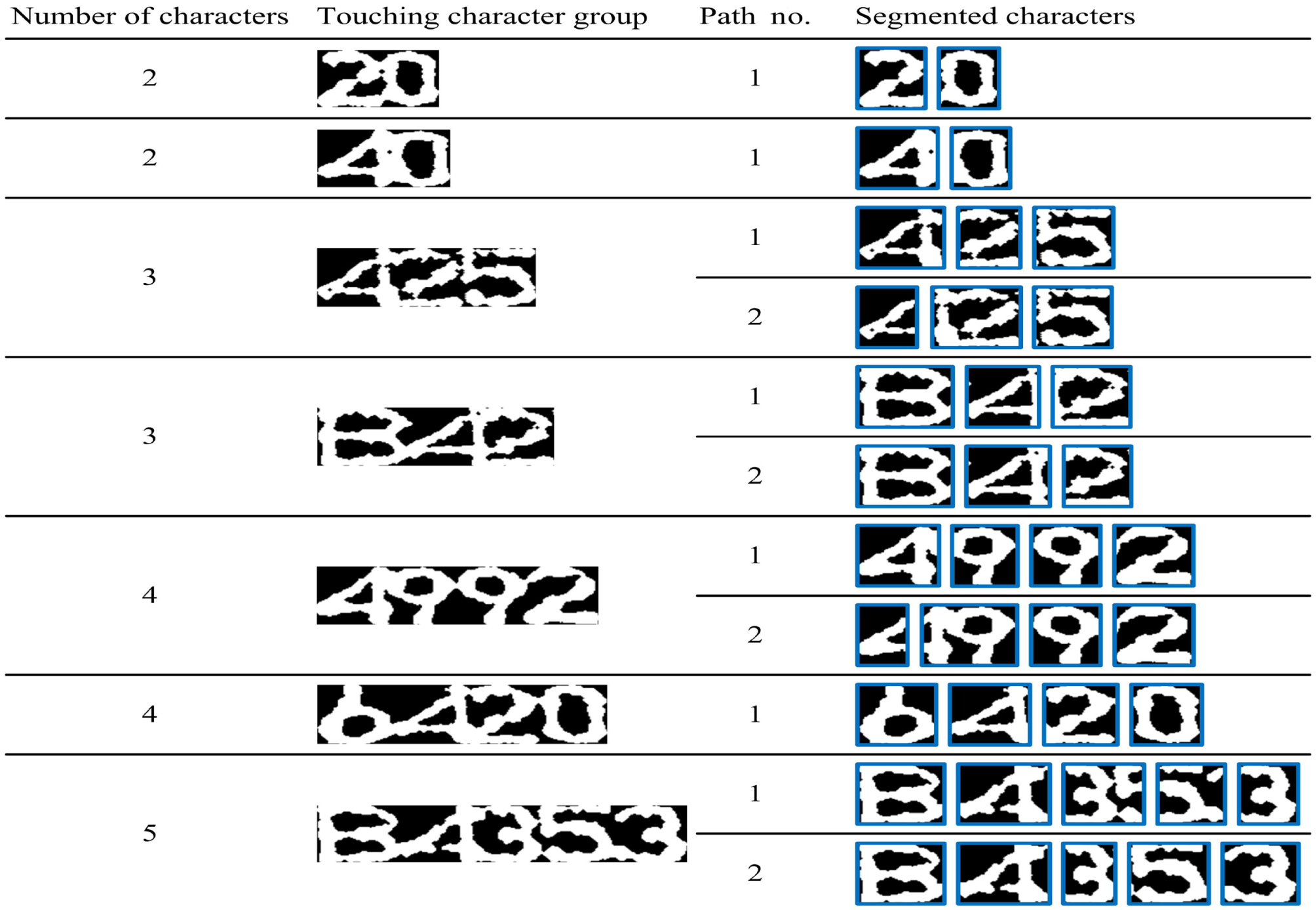
Several segmentation results with various numbers of characters are given in Table 2, where the width variations of optimal paths are listed in ascending order. It shows that with the FBS-TD method, the touching groups of different merged characters are successfully separated. We also note that although the strategy of the first nth paths is adopted, the segmentation may only have one acceptable path during the path selection due to the aforementioned rules of delimiter candidates. Moreover, the first path with the minimal variation of character widths also cannot always guarantee the accurate segmentation. It is because the printed characters are now degenerated into the printed-like ones, where their character priors are seriously changed. Therefore, the second path provides a more effective complement for the segmentation to increase the robustness of the real industrial system.
Segmentation for various adhesive character numbers.
Segmentation statistical results with various touching character numbers and the corresponding time consumption are shown in Table 3. In Table 3, it is observed that the successful segmentation rate is deteriorated with the merged character number increasing. In the case of the serious touching character groups, more possible paths exist and consequently disturb the selection for the accurate segmented path. It is worth mentioning that although the successful rate is only about 81% to separate five continual touching characters, the total successful rate of segmentation system is still acceptable. In practice, there exist a limited number of serious touching character groups in our test database, which is about 7% for all character groups. As for the time consumption, the segmentation platform is on a PC equipped with 4-core i5 3.0 GHz CPU and 4 GB of RAM in the MATLAB environment, where no mex files are used in our system. Here, more time consumption is also spent for the serious touching character groups, where the searching procedure of delimiter candidates on all complete paths bears a number of computational burden.
Segmentation statistical result with various adhesive character numbers.

In our test, a number of failure cases are also analyzed with the FBS-TD. Although the n-variation minimal approach is employed, it is still somewhat sensitive to deal with some touching narrow character groups. A segmentation example for narrow characters is shown in Figure 9. Since the width of symbol “1” seriously deviates from the average character width, the uncorrect segmentation is achieved. Because the true delimiter around the border position of “1” is now out of the acceptable searching scale corresponding to the average width, a false segment binary tree is founded using Rule 1. Consequently, the segmentation error is inevitably generated.

Segmentation example for touching narrow character group: (a) touching group, (b) characters on Path 1, and (c) characters on Path 2.
Conclusion
The FBS-TD method is proposed to segment the seriously touching characters, which is used as an important procedure for the character recognition in the real industrial environment. Unlike the segmentation via the existing histogram analysis, the reliable and unreliable valleys are identified from a smoothed projection curve. Later, with the average character width, two segment binary trees are constructed via the corresponding forward and backward searches. Then, the delimiter candidates are carefully selected according to a number of well-designed rules. Finally, the optimal segmented paths are obtained on the width variation measure of the characters, and the isolated characters are achieved. Experiments show that in most cases, the touching character groups can be successfully segmented via the proposed algorithm. However, it is somewhat sensitive to the groups with narrow characters. To deal with this problem, the prior of narrow characters will be further taken into account in the future work to improve the performance of our segmentation system.
Footnotes
Handling Editor: Zhaojie Ju
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by National Natural Science Foundation of China under grant 61471157 and 61501169, Provincial Key Research and Development Program of Jiangsu, China, under grant BE2017071, and the Fundamental Research Funds for the Central Universities of China under grant 2016B08814.