
Abstract
In most of the previous fault diagnostic literatures, the fault modes and states are pre-determined (i.e. the model structure (topology) is a priori known). However, in practical situation, the monitoring data, especially for the entire life-cycle data, nothing is known about the nature and the origin of the degradation (i.e. the model structure is unknown). Moreover, there is no consensus, how to determine the optimal model structure. In this condition, the different model structures may lead to different fault diagnosis/prognosis results. To address the optimal structure–selection problem, this article presents an automatic segmentation method based on Laplacian eigenmaps manifold learning and adaptive spectral clustering algorithms. Given an entire lifetime data of turbofan engine, we attempt to automatically segment the data into a sequence of contiguous regions corresponding to the degradation states. Furthermore, intrinsic dimensionality estimation, nonlinear dimension reduction, and the optimal number of degradation state estimation have been implemented. Automatic segmentation is applied for degradation state segmentation of non-label life-cycle data, and the output can be considered as the available information for developing fault diagnosis/prognosis. The experimental verification results indicate that the proposed automatic segmentation method is highly efficient and feasible for automatically determining the optimal model structure.
Keywords
Introduction
The turbofan engine providing thrust to the aircraft is one of the most vital systems to aviation system, and large amounts of researches have been carried out in the area of turbofan engine fault diagnosis/prognosis.1–5 The performance of an aircraft’s engine deteriorates when it is operated because its components physically degrade. To comprehensively describe the failure evolution, the degradation states before failure should be paid more attention.
So far, many available fault diagnostic techniques, such as kernel principal component analysis (PCA), 6 Kalman filters,7–9 sliding mode observer, 10 support vector data description, 11 Bayesian network, 12 artificial neural networks, 13 and hidden Markov model 14 , have been successfully applied in many industries. In most of these approaches,15,16 it is assumed that the model structure is pre-determined, ignoring the basic segmentation problem: given an entire lifetime data, we wish to partition our data into contiguous regions corresponding to the degradation states (see Figure 1). The segmentation problem is taken into account in a few of these approaches with unsupervised clustering algorithms,17,18 but the degradation state number is pre-determined as well. There are three possible reasons that explain why the degradation states division is rarely considered in the previous literatures: (1) the degradation states division process itself is time-consuming, (2) finding a reasonable degradation state structure which requires large amount of data, is usually not available in real world, and (3) the curses of dimensionality in high-dimensional data are still the major issue that challenges the degradation states division. Actually, the degradation states division is an important step for fault diagnosis and prognosis. If the number of degradation state is too small, the diagnosis/prognosis results are affected. On the contrary, the CPU time is expensive.

Basic segmentation problem of lifetime data.
As a matter of fact, the life-cycle data of turbofan engine are the nonlinear and non-stationary time series, which contain abundant potential failure information. However, with the exponential increase of performance monitoring data, the curses of dimensionality are also the main issue that affects the accuracy of fault diagnosis/prognosis. Fortunately, manifold learning algorithm is a perfect tool for data mining that discovers the structure of high-dimensional data and provides better understanding of data. 19 Recently, a variety of nonlinear dimensionality reduction techniques have been proposed which aim to address the limitations of traditional techniques such as PCA. 20 The core idea of manifold learning algorithm is to find a nonlinear low-dimensional embedding of high-dimensional data without losing much information. Additionally, the dimension of the embedding is a key parameter for manifold projection methods: if the dimension is too small, important data features are “collapsed” in the same dimension. On the contrary, the projections become noisy and unstable. 21 There is no consensus, however, on how this dimension should be determined.
Automatic segmentation methods have been employed in image processing and speech recognition22–24 but few about fault diagnosis and prognosis. Forecasting the future states of a complex system is a complicated challenge that is encountered in many industrial applications covered in the community of prognostics and health management. Practically, states can be either continuous or discrete: continuous states generally represent the value of a signal, while discrete states generally depict functioning modes reflecting the current degradation.25–27 In this article, we introduce an automatic segmentation method which aims to address the optimal structure–selection problem and the uncertainty of degradation process. First, we attempt to automatically segment the life-cycle data into a sequence of contiguous regions corresponding to the degradation states. Furthermore, intrinsic dimensionality estimation, nonlinear dimension reduction, and the optimal number of degradation state estimation have been implemented in the proposed method. The procedure of this method is presented in the next section. Section “Automatic segmentation algorithm” discusses the corresponding automatic segmentation algorithms in detail, including Laplacian eigenmaps (LE) manifold learning and adaptive spectral clustering methods. The flowchart of fault diagnosis and prognosis method is given in section “Fault diagnosis and prognosis.” In section “Experimental validation,” the run to failure experiment of turbofan engines is performed to verify the proposed method in this article. Finally, conclusions are presented in section “Conclusion.”
The procedure of automatic segmentation method
There are four steps for machine fault diagnosis and prognosis: (1) data acquisition, (2) data process, (3) fault diagnosis, and (4) fault prognosis.
To avoid the curses of dimensionality and improve the performance of classification, the high-dimensional data can be efficiently summarized in a space of a much lower dimension without losing much information. There are many approaches for dimensionality reduction, such as Sammon mapping, 28 kernel PCA, 29 isomap, 30 locally linear embedding, 31 LE, 32 maximum variance unfolding, 33 and t-distributed stochastic neighbor embedding. 34 Van Der Maaten et al. 35 presented a systematic comparison of 13 existing common dimensionality reduction techniques by four general properties: (1) the parametric nature of the mapping between the high-dimensional and the low-dimensional space, (2) the main free parameters that have to be optimized, (3) the computational complexity of the main computational part of the technique, and (4) the memory complexity of the technique. In practice, one of the main limitations is the computational complexity of these approaches, and this limits to apply in large-scale data.35–37 In terms of the computational and memory complexity, LE is one of the most outstanding techniques. Additionally, constructing a reliable estimator of intrinsic dimension and understanding its statistical properties will clearly facilitate further applications of manifold projection methods and improve their performance. So far many researchers have made great contributions on intrinsic dimensionality estimation, and maximum likelihood estimation (MLE), 21 correlation dimension, nearest neighbor evaluation, packing numbers, and geodesic minimum spanning tree are main available techniques.38,39
In summary, the main problems for affecting the performance of fault diagnosis/prognosis are intrinsic dimensionality estimation, curses of dimensionality, and degradation process uncertainty. In this section, an automatic segmentation method is presented, which can be used to automatically find the low-dimensional embedding and determine the degradation state number and state label. The corresponding automatic segmentation algorithms, fault diagnostic and prognostic approaches are described in sections “Automatic segmentation algorithm” and “Fault diagnosis and prognosis,” respectively.
Figure 2 shows the procedure of the automatic segmentation and fault diagnosis. The life-cycle data are collected by the sensors installed on the equipment, and feature extraction or selection method is employed to select the system degradation indicators. The measured data may be redundant; effective feature extraction and selection is a step for accurate diagnosis and prognosis. To eliminate the degradation process uncertainty and determine the degradation states, an automatic segmentation method is employed, including two phases: (1) phase 1: dimensionality reduction and (2) phase 2: adaptive spectral clustering. In phase 1, LE manifold learning technique is employed to find a low-dimensional embedding via high-dimensional data. In other words, the effectiveness of fault diagnostic and prognostic are increased by this stage. In this article, the fusion data are as the input of degradation state segmentation and fault diagnostic. For fault prognostic, several degradation indicators are often converted into a single degradation indicator in previous papers, so that we choose the first dimensional fusion data as the prognostic parameter. In phase 2, an adaptive spectral clustering algorithm is presented to determine the degradation state number and output the degradation state label. With such a strategy, the life-cycle data are automatically divided into contiguous regions corresponding to the degradation states. Finally, the output of the automatic segmentation method can be considered as the available information for developing fault diagnostic.

The procedure of automatic segmentation and fault diagnosis.
Automatic segmentation algorithm
Let

Phase 1: manifold learning dimensionality reduction
For a fixed point

where

where

where
Let
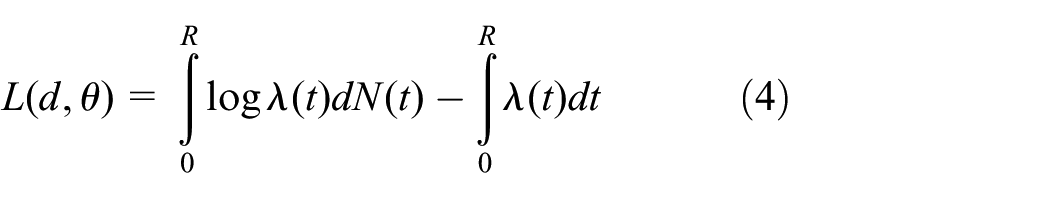
which yields
The MLE must satisfy

In practice, it may be more convenient to fix the number of neighbors
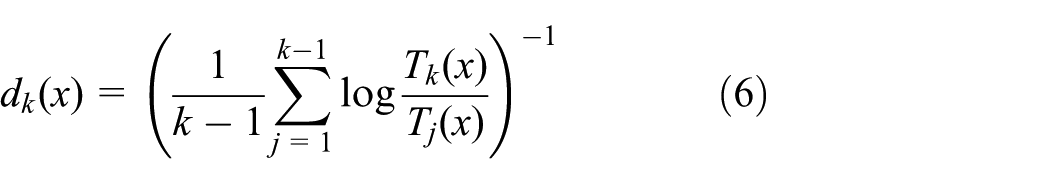
The intrinsic dimensionality

Let
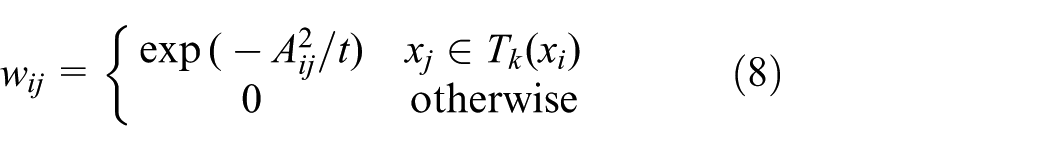
where the parameter
Assume the constructed graph G is connected. Compute eigenvalues and eigenvectors for the generalized eigenvector problem

where
Let
Phase 2: adaptive spectral clustering
Adaptive spectral clustering and LE manifold learning are both based on LE algorithm, the difference between them is calculated by the generalized eigenvector problem. LE manifold learning finds a lower dimensional embedding by a pre-defined value, but adaptive spectral clustering determines the degradation state number by the first maximal eigengap. For all clustering algorithms, how to automatically determine the number of clusters is a general problem. Kong et al.
40
designed the first maximal eigengap for determining the number of clusters. According to the spectral graph theory, in the ideal case of r completely disconnected clusters, the normalized Laplacian matrix contains the eigenvalue as 1 with multiplicity

Note that the input data of adaptive spectral clustering are the low-dimensional embedding

Therefore, the k-means clustering algorithm is employed to cluster
Fault diagnosis and prognosis
Fault diagnostics and prognostics have received increased attention due their potential to provide early warning of system failures, forecast maintenance as needed, and reduce life-cycle costs. Support vector machine (SVM)41,42 has been proven to have an excellent generalization capability and has been successfully applied in machinery fault diagnosis. In this article, SVM was chosen to develop fault diagnosis, and Cox proportional hazards model (PHM) was to develop fault prognosis.
Figure 3 shows the flowchart of fault diagnosis and prognosis method. The steps of fault diagnosis and prognosis are summarized as follows:
Step 1. Data acquisition: the monitoring data are collected by sensors installed on the equipment. The historical data are as the training data, and the real-time data are as the testing data.
Step 2. Feature extraction and selection: the monitoring data may be redundant, so that the appropriate degradation indicators are selected in this stage.
Step 3. Data fusion: to improve the effectiveness of fault diagnosis and prognosis, the degradation indicators are processed by LE algorithms. The fusion data are as the input of degradation states segmentation and fault diagnosis, and the first dimensional fusion data as the prognostic parameter.
Step 4. Degradation states segmentation: adaptive spectral clustering is employed to segment the unlabeled monitoring data.
Step 5. Fault diagnosis: SVM is employed to develop fault diagnosis; the corresponding algorithm is described in section “Fault diagnosis based on SVM.”
Step 6. Fault prognosis: Cox PHM is employed to develop fault prognosis; the corresponding algorithm is described in section “Fault prognosis based on Cox PHM.”

The flowchart of fault diagnosis and prognosis.
Fault diagnosis based on SVM
For linearly separable part, there is an optimal hyperplane

where
The optimal classification function is

where
For linear non-separable part, the main idea is to map the original d-dimensional space into a d′-dimensional space
The objective function is

The optimal classification function is

Fault prognosis based on Cox PHM
Let

where
The cumulative hazard rate is

The reliability function is

Treating the subjects’ events as if they are statistically independent, the joint probability density of log-likelihood function is
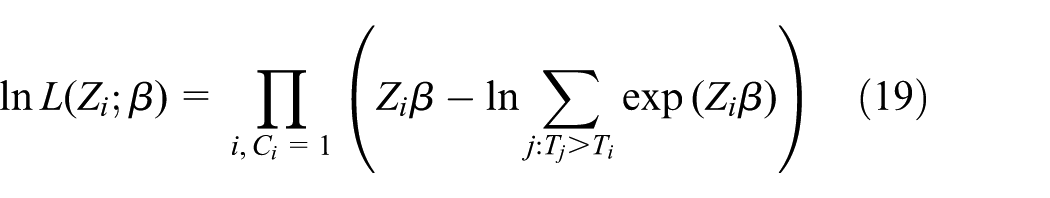
where
The overall service lifetime can be obtained by

where
The remaining service life can be obtained by

where
To evaluate the prognostic performance, the mean absolute percent error (MAPE) is given as

where
Experimental validation
To validate the effectiveness of the proposed method, the run-to-failure tests on turbofan engines were performed. The experimental data were downloaded from the Prognostics Data Repository (http://ti.arc.nasa.gov/project/prognostic-data-repository). 43 The data sets consisted of multiple multivariate time series, reflecting the natural degradation of turbofan engines. The dataset 1, namely, train_FD001, test_FD001, and RUL_FD001, was considered in this article. In the training set, the fault grows in magnitude until system failure. In the test set, the time series ends some time prior to system failure. RUL_FD001 provides a vector of true remaining useful life (RUL) values for the test data. The dataset contained 24 element vectors consisted of 3 operational settings and 21 sensor measurements. 44 The total lifetime for each engine in the training set is shown in Figure 4. It can be seen from Figure 4 that the lifetime varies from 128 to 362 cycles (mean = 206.3 cycles, standard deviation = 46.34 cycles).
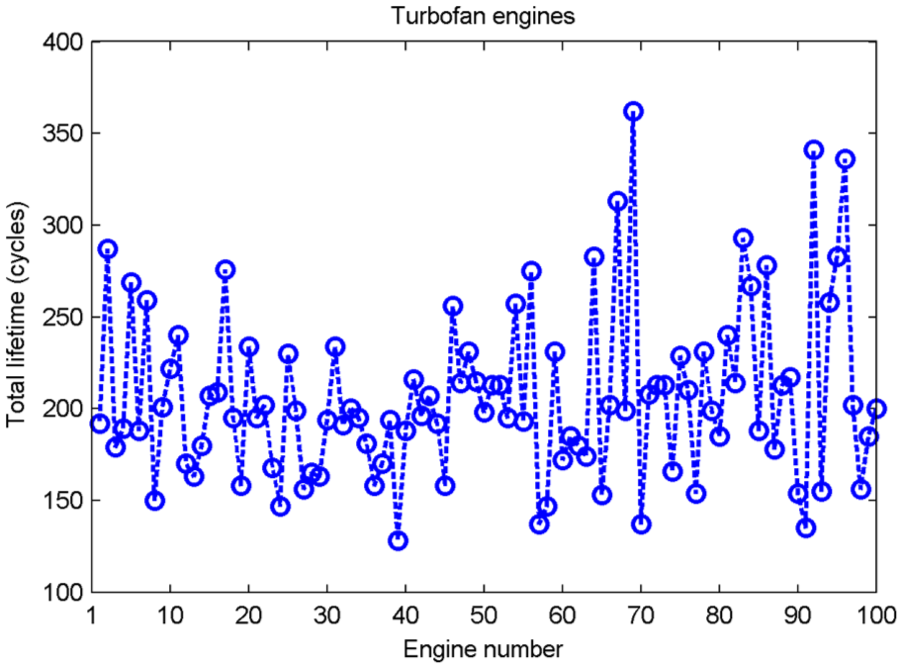
Actual lifetime of each engine in the training set.
Degradation state segmentation
To improve the effectiveness of fault diagnosis and prognosis and reflect the natural degradation of turbofan engines, the respective features are selected. For fault diagnosis, the 24 features are as the degradation indicators. By automatic segmentation in section “Automatic segmentation algorithm,” the dimension of the life-cycle data (24-dimension) was reduced into 6-dimension. Where, the neighborhood number in Phase 1 was in the range of 6–12, and the neighborhood number
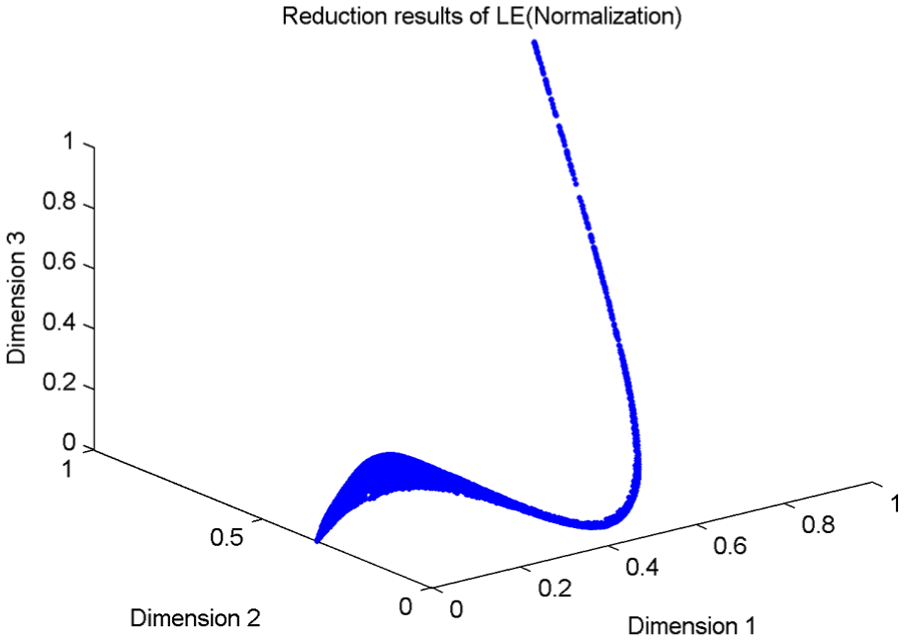
Visualization of the reduction results by LE manifold learning.
By Phase 2 in section “Automatic segmentation algorithm” with the output of Phase 1, the state number and class label were obtained. Where, the neighborhood number
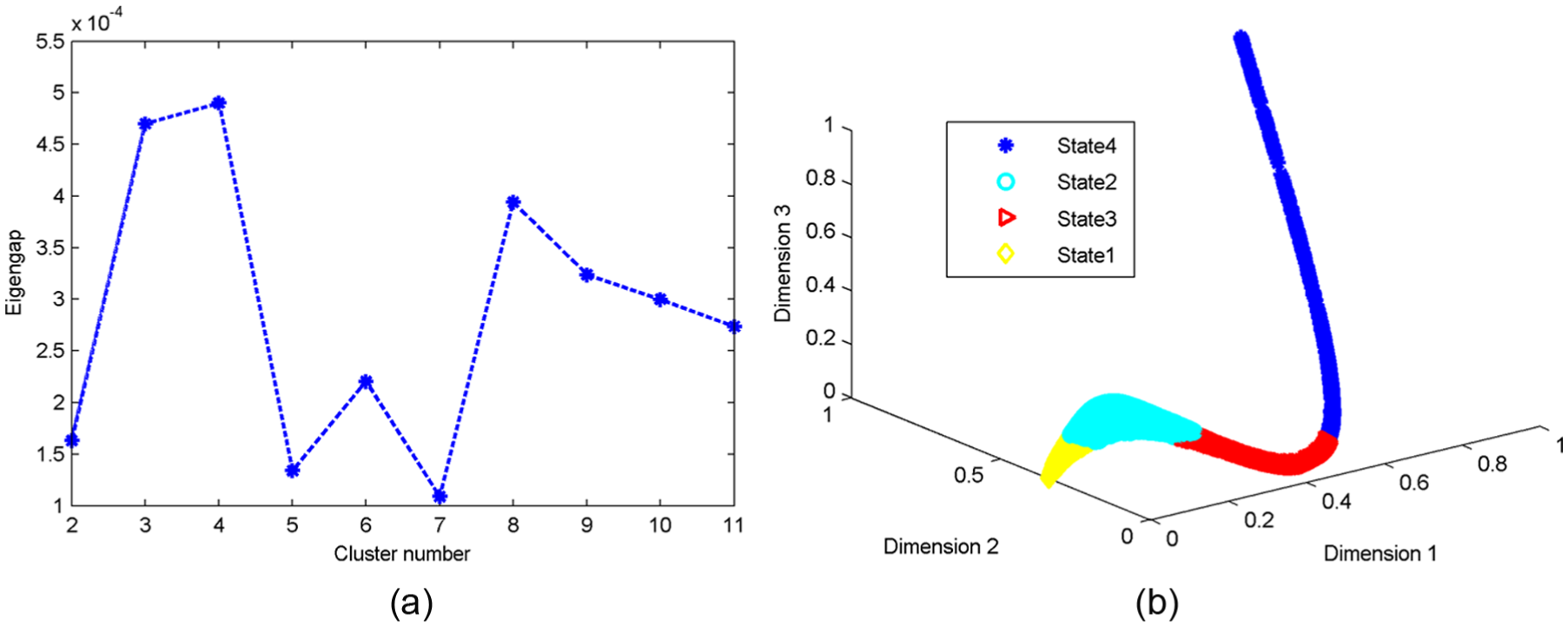
Results of automatic segmentation: (a) estimation of degradation states number and (b) results of adaptive spectral clustering.
Fault diagnosis
For fault diagnosis, the engines No. 1–No. 60 are taken as the train samples and the engines No. 81–No. 100 are taken as the test samples. Note that here the samples are random distribution, and the optimal parameters of SVM are found by grid search algorithm, and the cluster labels are considered as the true labels of turbofan engine. The diagnosis results by SVM are compared with the true labels, which are shown in Figure 7. The diagnosis accuracy is 99.55%. The respective corresponding degradation states of No. 94 engine and No. 82 engine over the operational time are shown in Figure 8. It can be seen that two engines start with different initial operational states owing to different degrees of initial wear and manufacturing variation which is unknown to the user. This wear or variation is considered normal, that is, it is not considered a fault condition. No. 94 engine goes through four degradation states, while No. 82 engine only three degradation states. The results indicate that No. 82 engine is operated at degradation state 2, and No. 94 engine has the higher reliability in the initial operational state than No. 82 engine. The reason is that products exist the difference in material and manufacturing process.

SVM diagnosis results.

Degradation states of No. 94 engine and No. 82 engine.
Fault prognosis
For fault prognosis, train_FD001 are taken as the training samples, test_FD001 are taken as the testing samples. The literature45,46 suggested the features

where

Cox PHM estimated results of RULcon = 0.9: (a) Cox PHM RUL estimates and (b) Cox PHM RUL estimation error: MAPE = 50.2934.

Cox PHM estimated results of RULcon = 0.95: (a) Cox PHM RUL estimates and (b) Cox PHM RUL estimation error: MAPE = 50.809.

Weibull estimated results: (a) Weibull RUL estimates and (b) Weibull RUL estimation error: MAPE = 98.5072.
The mean remaining service life of Weibull estimation is estimated by

where
From the above results, the automatic segmentation has been proven to be a high-efficiency and feasibility method, which can automatically find the low-dimensional embedding and determine the structure of the degradation model. Thus, the data uncertainty can be eliminated, which is of great significance for fault diagnosis and prognosis.
Additionally, the main challenge in the automatic segmentation method is the available life-cycle data. Finding a reasonable model which requires large amount of data is usually not available in real world. The overall accuracy of fault diagnosis/prognosis will be seriously affected by the insufficient data. Moreover, selection of the monotonous features representing the degradation progression is a prerequisite for effective fault prognostics. However, the performance of the automatic segmentation method itself is sufficiently accurate.
Conclusion
In this article, an automatic segmentation was performed, which was validated through three artificial data sets and the run-to-failure experiments of turbofan engine. The results suggest that the automatic segmentation method has effectively overcome the curse of dimensionality and eliminated the degradation process uncertainty. It is a high-efficiency and feasibility method for model selection of high-dimensional data.
The proposed approach has three main benefits. First, only the performance monitoring data are required but not the prior knowledge about the equipment or the operating conditions. Second, the method can be employed in single or multiple operating conditions. Third, the method not only can deal with low-dimensional data (directly Phase 2) and high-dimensional data but also the non-convex and convex data. Therefore, the proposed method can be seamlessly applied to any mechanical equipment, and the output of the automatic segmentation method can be considered as the available information for developing fault diagnosis/prognosis.
Footnotes
Academic Editor: Yangmin Li
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.