
Abstract
To solve a non-deterministic polynomial-hard problem, we can adopt an approximate algorithm for finding the near-optimal solution to reduce the execution time. Although this approach can come up with solutions much faster than brute-force methods, the downside of it is that only approximate solutions are found in most situations. The genetic algorithm is a global search heuristic and optimization method. Initially, genetic algorithms have many shortcomings, such as premature convergence and the tendency to converge toward local optimal solutions; hence, many parallel genetic algorithms are proposed to solve these problems. Currently, there exist many literatures on parallel genetic algorithms. Also, a variety of parallel genetic algorithms have been derived. This study mainly uses the advantages of graphics processing units, which has a large number of cores, and identifies optimized algorithms suitable for computation in single instruction, multiple data architecture of graphics processing units. Furthermore, the parallel simulated annealing method and spheroidizing annealing are also used to enhance performance of the parallel genetic algorithm.
Keywords
Introduction
As the most popular type of evolutionary algorithms, the genetic algorithm (GA) is a search technique used in computational mathematics to obtain solutions to optimization problems. In this study, we not only accelerate evolution speed of the GA by the parallel computing capability of the graphics processing units (GPU), but also enable GAs converge to optimal solutions faster with a modified simulated annealing method.
Many models of parallel GAs have been proposed in the literature; the famous ones, for example, include the master–slave model as well as the island model.1,2 The parallel GAs can be used to solve the issues of the past GAs that are susceptible to converge to local optimal solutions. Although computations of the parallel GAs have been realized in using Central Processing Unit (CPU), but due to the difference between architectures of the GPU and CPU, the parallel GAs cannot transport directly from CPU to execute on the GPU. Therefore, the first focus of this study is how to implement parallel GAs with the GPU hardware for operation and optimization of GAs computations.
Although the use of the above parallel GAs has been shown to be helpful in solving the issues of local optimal solutions, in this study we further enhance and optimize the parallel GAs using the island model by combining the mutation operations in GAs with simulated annealing method3,4 and spheroidizing annealing. 5 So the second focus of this article is how to combine parallel GAs with spheroidizing annealing such that GAs can more effectively jump out of local optimal solutions in the face of more complex computation problems.
In this study, we will use the traveling salesman problem (TSP) 6 as the benchmark, although the TSP can be more efficiently solved by many other algorithms such as geometric algorithms. We aim to compare performances of GAs with different parameters settings (the population size and node number), study the differences between CPU (single-thread and multi-thread) and GPU computing, and investigate how much improvement can be gained in convergence after combining GAs with the simulation annealing method and spheroidizing annealing.
According to our experimental results, performance has been improved by two orders of magnitude: the acceleration rate of the proposed GPU computing over the single-thread CPU is about 300, and the acceleration rate of the proposed GPU computing over the multi-thread CPU is about 100. Also, compared to the parallel GA using the master–slave model on the multi-thread CPU, the proposed modified parallel GA using the island model combined with the simulation annealing method on the GPU has better convergence rates. Furthermore, spheroidizing annealing has been successfully combined into the simulation annealing method to have better convergence rates for the modified parallel GA on the GPU.
Background
GPU parallel computing
The GPU was created primarily for the purpose of handling image rendering and display. In recent years, the GPU is gradually used for scientific computation in addition to graphic display. Formerly called as general-purpose computing on graphics processing units (GPGPU), 7 the emergence of GPU let GPU possess the ability of scientific computing. CUDA7,8 and OpenCL 9 are both GPU programming frameworks that allow the use of GPUs for general-purpose tasks. CUDA is proprietary to NVIDIA and hence limited. The GPU hardware architecture is different from that of traditional CPUs. The GPU owns a large number of cores for computing. However, the GPU adopts single instruction, multiple data (SIMD) architecture. 10 Unlike the multitasking CPU, the GPU runs on one task at a time regardless of the large number of cores. So the GPU is most suitable for algorithms with simple and large amount of computations. The CPU can be used for computing while the GPU is operating. Our algorithm uses not only parallelized SIMD architecture, but also heterogeneous system architecture (HSA) 10 composed with the CPU and GPU for further optimization.
TSP
We use the TSP6,11 as a benchmark for quantitative comparison of GA. The TSP is probably one of the most intensively studied problems in optimization, in which for a given set of n cities, along with the cost of traveling between each pair of cities, one needs to find a path of minimum cost for the salesman to visit all the cities once and return to the origin city.
TSP is a combinatorial optimization problem. For example, we define a problem space in equation (1) and the objective function in equation (2)

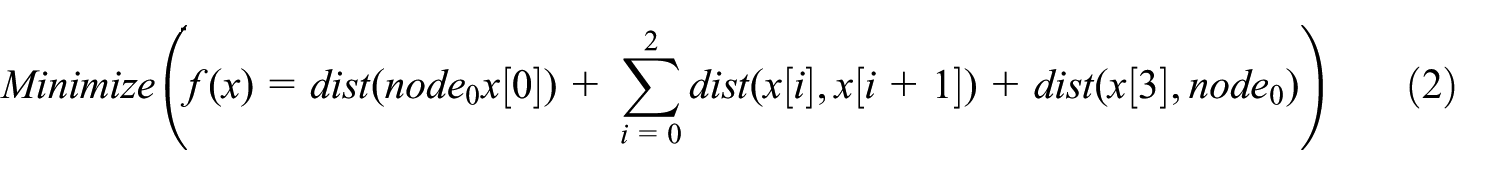
In fact, we can see that one cannot easily work out exact solution for such a problem, and a heuristic method, such as the GA, is a more suitable approach.
Parallel GA
At present, several parallel GA computing models have been proposed, such as the island model and master–slave model.1–3,12–14 These models use the advantage of parallel computing by dividing population of a large size into smaller partitions and performing simultaneous random searches among them. These models greatly improve issues of premature convergence or convergence to local optimal solutions in past GA methods, where a single large population is used. To take advantage multitasking features of multi-core CPUs, 15 these models implement parallel computing on CPU by allocating unused cores with the blocks not yet been operated. The GPU varies greatly from the CPU in parallel computing. Due to lack of multitasking capabilities of GPU computing cores, and the need to use Peripheral Component Interconnect Express (PCI-E) for communication between the GPU and main memory, much computing time will be spent on memory access for algorithms that frequently require GPUs to access memory. So we propose a method to bring all steps of GAs into the GPU for computation and combine it with parallel optimization models described in the following section.
Methodology
Parallel SIMD-based algorithm
First, the GA consists of five processes: (1) initialization of the population; (2) fitness evaluation; (3) selection and reproduction; (4) crossover; and (5) mutation of chromosomes. Except for fitness evaluation, random numbers are applied in all the other GA processes. A method to generate random numbers in parallel is to simply shift the seed of a random number. Computers usually use long sequences of numbers and a seed for table lookup to generate random numbers. We use NVIDIA’s Curand.kernel14,15 and treat each thread ID as the seed of this thread, so that each thread can have its own independent random field. A global evaluation is performed after each thread performs evaluation of its own chromosomes and saves the evaluation results into global memory.
Parallel selection with SIMD
Selection of GA16–18 can be carried out in many ways, of which the roulette-wheel selection method is most famous. However, the roulette-wheel selection method itself has a major flaw for parallel computing with SIMD architecture. First, we can see that in equation (3), which is the probability of being selected in the roulette-wheel selection method, each

As discussed in the previous section, our aim is to bring all steps of GAs into the GPU for computation, thus, avoiding frequent data transfer between the GPU and main memory (or CPU). 15 Hence, the summation operation in equation (3) will decrease computation speed and performance, since each thread of the GPU with SIMD architecture needs to be executed one time.
To improve performance, equation (4) is used to calculate the weight of chromosome i

where

Process flow for parallel selection with SIMD architecture.
Equation (4) is used to compute the weight of chromosome in each thread. Then the computed weight is compared with the stored weight in the memory location associated with the thread ID. If the computed weight is larger than the stored weight, the ID of this thread is entered into ID reproduction pool of the associated memory block. Upon completion of above step, the offset of associated memory location is incremented by one. The mod operation is performed when the sum of the offset and thread ID is more than the population size for finding the next memory location to be accessed.15,16 The kernel repeats the operation of equation (2) until the value of offset reaches the population size, as shown in Figure 2. Such a procedure can ensure that each cell of the reproduction pool has completed its roulette-wheel selection process and avoid data race due to conflicts of parallel computing threads accessing shared memory. According to equation (4), even chromosomes with lower fitness value also have some chance to be entered the reproduction pool to ensure genetic diversity, and thus, premature convergence can be prevented.

Memory access method for parallel selection.
Considering the memory access limit of the GPU, adjacent chromosomes are used for mating in the parallel crossover process of chromosomes. Figure 3 shows the flow of the parallel crossover16–18 process of chromosomes in SIMD architecture.

Algorithm of parallel crossover processes of chromosomes using SIMD.
We halve the amount of threads to the half of the population size, since every thread is responsive for the crossover process of two chromosomes. Such a framework enables the GPU perform memory access with a half-warp speed.
Parallel mutation and simulated annealing method with SIMD
Parallel mutations are simply achieved by each thread that uses its own random field to perform single-point or multi-point mutations on its chromosomes. We also combine the mutation method with the simulated annealing method. 3 The simulated annealing method by definition is referred to annealing in metallurgy. The principle is that when a crystalline solid is heated to a high temperature, its atoms can leave their original positions and move randomly; when the temperature is cooled down, the atoms can slowly converge and the crystalline solid can achieve its most regular possible crystal lattice configuration, that is, its minimum lattice energy state. The simulated annealing method imitates this optimization random searching algorithm to converge to optimal solutions faster. The pseudo-code implementing the simulated annealing method is listed in Table 1.
Pseudo-code of simulated annealing.

It starts from a state s0 and executes either a maximum of kmax steps or until a state with energy of emax or less is found. The variable e represents the energy of the atom. The call neighbor (s) generates a randomly chosen neighbor of a given state s; the call random() picks and returns a random number uniformly distributed in the range [0, 1). We use equation (5) to compute the probability for changing the energy of the atom to

The variable Temp decreases along with time; when it reaches 0, variables of the atom stop updating.
The simulated annealing method is applied to parallel GA by replacing its mutation process. The modified parallel GA is shown in Table 2.
Parallel GA with simulated annealing method.

We substitute atoms with chromosomes and energy with the fitness evaluation value. By combining with the simulated annealing method, the parallel GA can converge to optimal solutions faster. However, two extra variables, that is, the initial temperature and the rate of descent, need to be attuned. When both parameters are adjusted properly, the optimization level of the modified parallel GA with simulated annealing will be better than that of the original one.
Island model–based parallel GA
As described above, all the operations of the parallel GA have been implemented in a SIMD parallel computing architecture. However, we only increase their iterative speed of GAs, without addressing some of the shortcomings inherent in GAs, such as premature convergence to local optimal solutions. The island model, as depicted in Figure 4, has been shown to have better performance than the serial single population model. 17 In the following, we try to adopt the island model 12 as a base to further improve performance of GAs.

Schematic of a GA using island migration.
Based with the island model, the population of chromosomes is divided into several blocks, and each individual block (or island) individual runs GAs and generates its random search domains. Each island has a certain probability for chromosome migration between islands; chromosomes with higher fitness have higher chances of migration. In this study, after each island completing i-time iterations of GA, a global selection is executed to exchange genes among all islands. Of course, chromosomes with a better fitness value are easy to migrate among islands. In this way, blocks converging into non-optimal solutions before can use chromosomes with a better fitness value to obtain better solutions from the whole random search domain. Thus, the modified parallel GA based on the island model can be implemented by simply inserting division of blocks stages into selection as well as crossover operations. Figure 5 depicts a modified parallel GA based on the island model with SIMD architecture.

Island model–based GA with parallel blocks using the GPU with SIMD architecture.
We divide the total population of a size
Effect of temperature decreasing rate on the simulated annealing
Although the simulated annealing method can be used to improve random search, it is difficult to decide a proper value for the temperature decreasing rate. If temperature deceases too fast, the GA might be stuck at local optimal solutions, whereas, if too slow, the GA might converge too slowly. Several temperature deceasing methods have been tested. The first method uses a fixed rate of decrease as shown in equation (6)

where ROD represents the rate of decrease.
The experimental results show that when the length of chromosomes increases, the GA has a high probability to be stuck at local optimal solutions with a fixed decreasing rate. The second method refers to spheroidizing annealing 5 in metallurgy. Based on cyclic spheroidizing annealing shown in Figure 6, we formulate a new temperature decreasing mathematic model in equation (7)

where

Cyclic spheroidizing annealing.
Note that

Mathematic model of cyclic spheroidizing annealing.
This cyclic temperature algorithm solves the issue that the GA is stuck at local optimal solutions while the temperature is too low to provide enough energy to enable the algorithm to escape from local optima. The parameters, that is,
In the future, we plan to use two-leveled GA (GA2) to decide the temperature deceasing rate, as shown in Figure 8. Each chromosome represents a parameter of the rate of decrease. Since the fitness evaluation is obtained by multiple iterations using GA2, the population size cannot be set too large. When the proper parameters are decided for a chromosome with certain length, the whole parameters setting of rate of decrease can be directly substitute into GAs to deal with chromosomes with similar length.
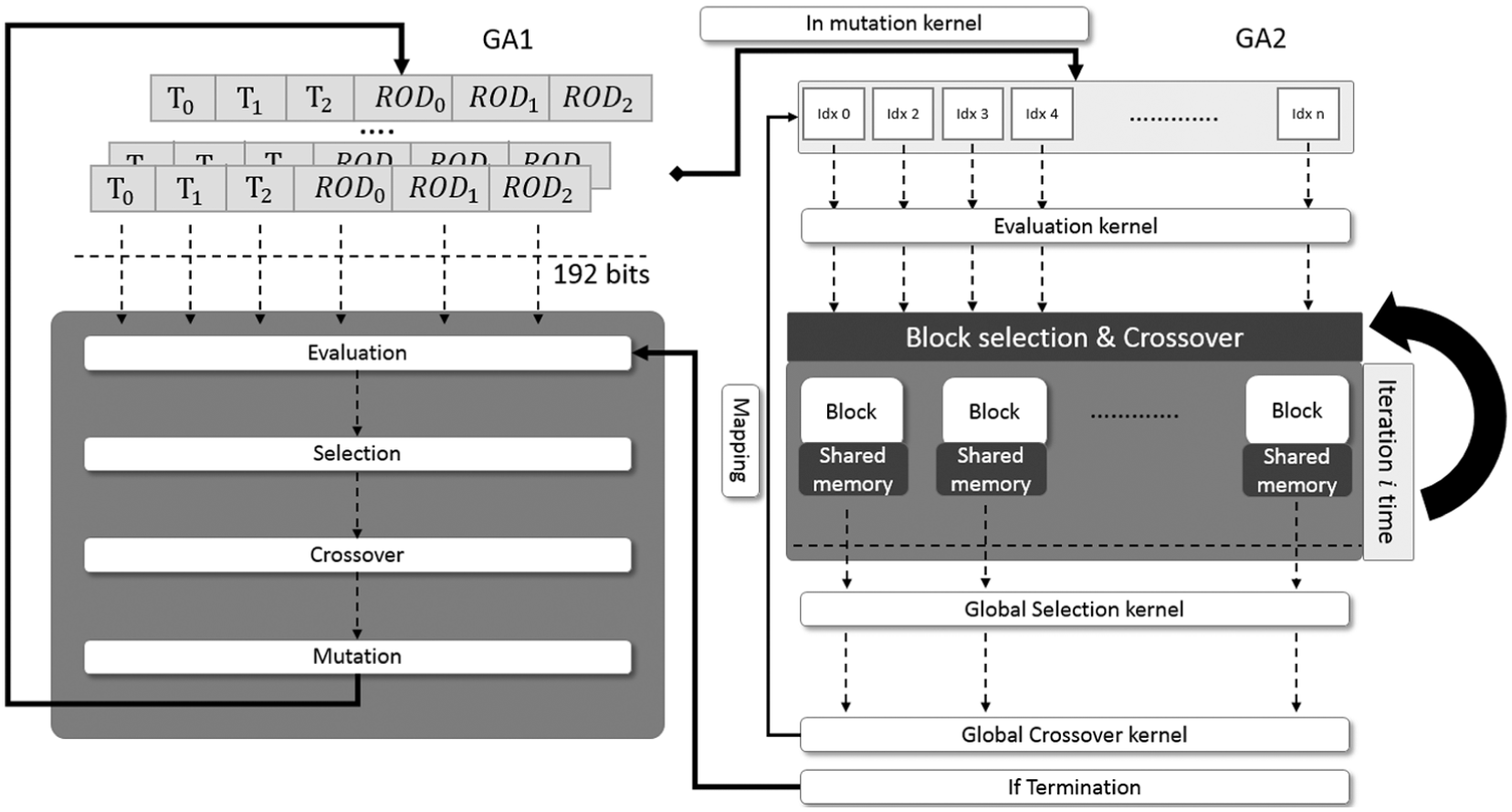
Modified two-leveled GA with simulated annealing.
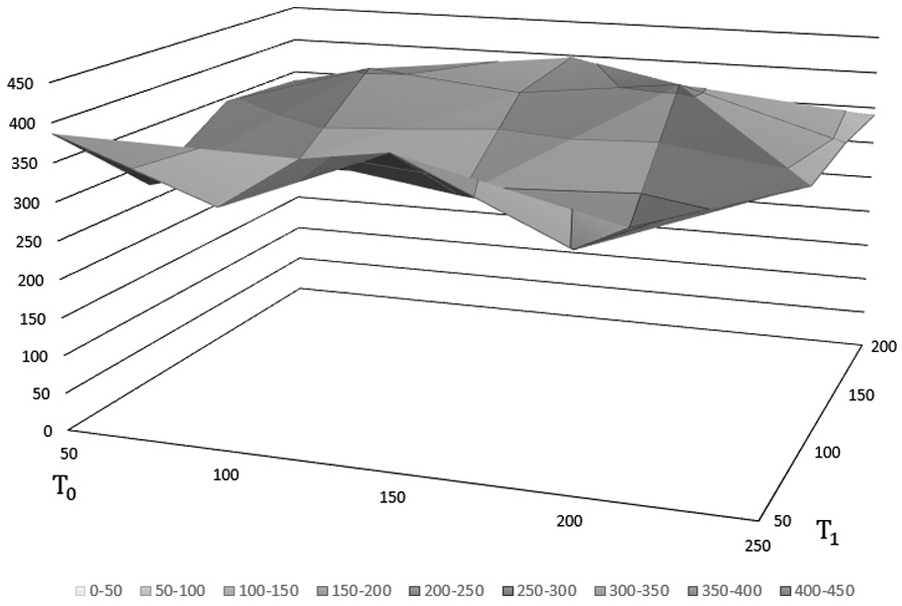
In the following, we study the convergent efficiency of GA with cyclic spheroidizing annealing method compared to that of the fixed decreasing rate method. In the simulation, the number of nodes for the TSP is set as 256, and the simulation time is 5 min.
Figure 9 shows the relative errors (equation (8)), that is, deviation from optima, of GA with the cyclic spheroidizing annealing model, in which

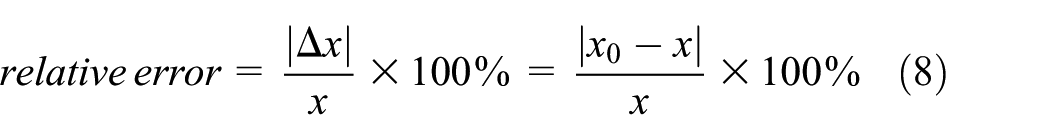

Relative errors of GA using the cyclic spheroidizing annealing model (
The simulated results are also listed in Table 3. We also found that when ROD2 = 0.999, the relative error of GA with fixed deceasing rate annealing model is 407.8804%.
Relative errors of GA using the cyclic spheroidizing annealing model (

Figure 10 shows the relative errors, that is, deviation from optima, of GA with the cyclic spheroidizing annealing model, in which
Relative errors of GA using the cyclic spheroidizing annealing model (
Relative errors of GA using the cyclic spheroidizing annealing model (

From the experimental results, we observe that the proposed cyclic spheroidizing annealing model can effectively offset the decrease of temperature, and thus enable the GA to escape local optimal solutions.
Experimental result and discussion
The experimental environment is listed as follows:
CPU: Intel® Core™ i7-4770K 3.5 GHz processor with 16 GB memory; GPU: NVIDIA Titan Black.
Operating system: Linux Ubuntu 14.04 (64 bit).
Benchmark: TSP.
To search solutions for the TSP on the CPU, the single-thread program written in MATLAB uses the GA on the website in Vedenev, 18 whereas the multi-thread program written in C# uses a master–slave model.2,19 In the experiments, we combined the proposed parallel GA on the GPU SIMD architecture with the island model and improved simulated annealing method. We compared performance of the proposed parallel GA on the GPU with those of the single-thread and multi-thread program on the CPU. This experiment only uses GAs to compute optimal solutions for the TSP, which is mainly used as a benchmark and not particularly optimized. Since the purpose of this study is to develop a good computing model for parallel GAs.
The population size and iteration speed
In this experiment, the population size is varied from 512 to 8192, the number of nodes is varied from 16 to 256, and 2000 iterations are performed at each run. Figure 11 shows plots of the execution times of parallel GAs on the CPU using the master–slave model with various population sizes and node numbers. Table 5 lists the experimental results.
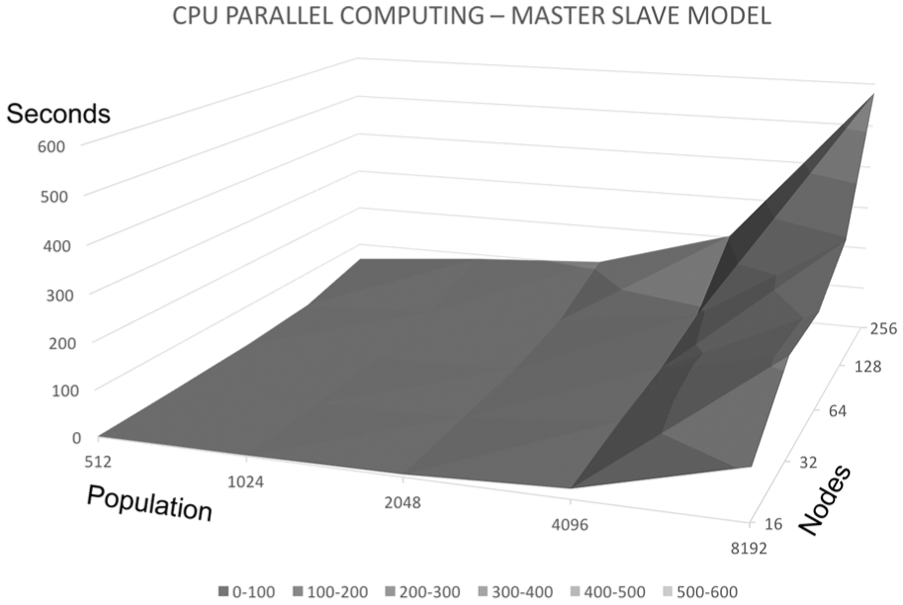
Execution times for 2000 iterations (in seconds) of master–slave parallel GAs on the CPU with various population sizes and node numbers.
Execution times for 2000 iterations (in seconds) of master–slave parallel gas on the CPU with various population sizes and node numbers.
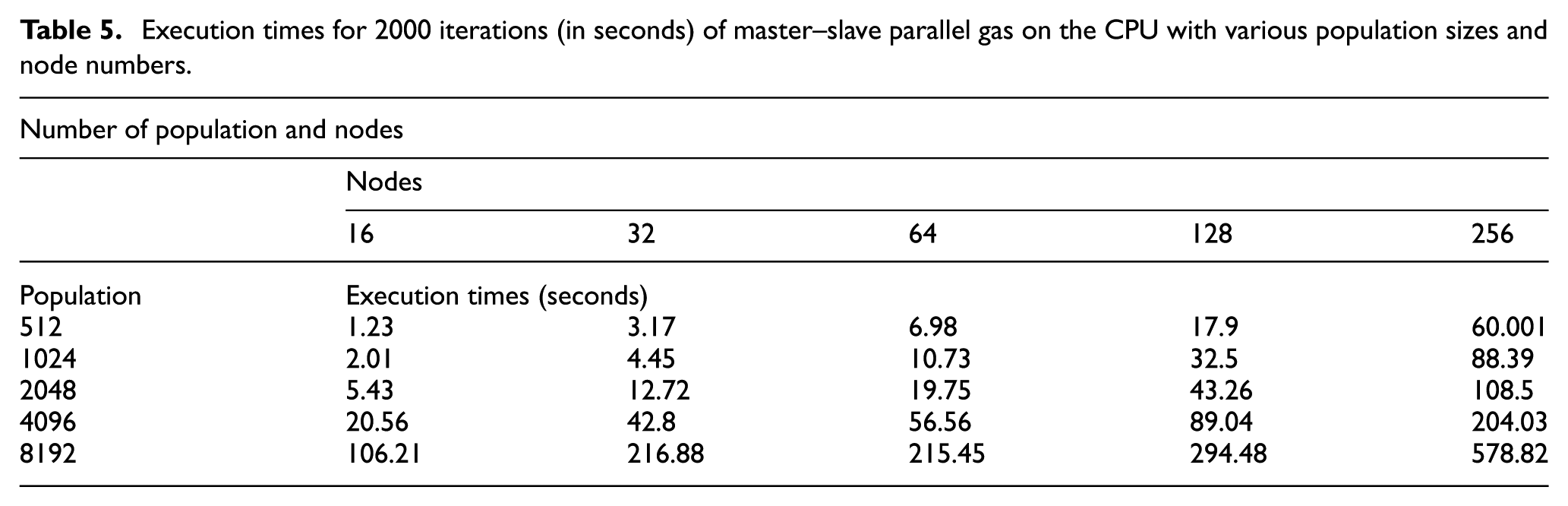
Figure 12 shows plots of the execution times of GAs using the single-core CPU with various population sizes and node numbers. Table 6 lists the experimental results.
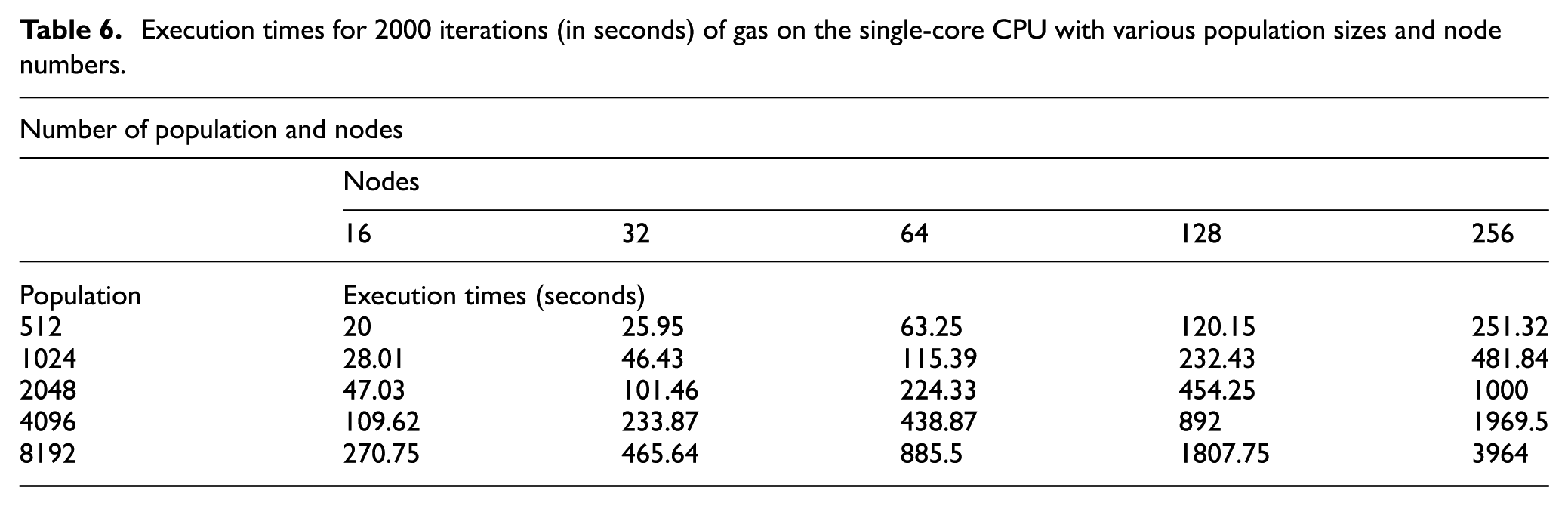
Execution times for 2000 iterations (in seconds) of GAs on the single-core CPU with various population sizes and node numbers.
Execution times for 2000 iterations (in seconds) of gas on the single-core CPU with various population sizes and node numbers.
As shown in Figures 11 and 12, the execution time of GAs on the CPU is relatively long (>60 s for 256 nodes) and increases sharply when the population size or the node number increases. Figure 13 shows the execution times of modified parallel GAs on the GPU with various population sizes and node numbers. Table 7 lists the experimental results.

Execution times for 2000 iterations (in seconds) of modified parallel GAs on the GPU with various population sizes and node numbers.
Execution times for 2000 iterations (in seconds) of modified parallel gas on the GPU with various population sizes and node numbers.

From the experimental results, we find that the modified parallel GA on the GPU has greatly reduced the execution time. For illustration, we divide the execution time of GAs on the CPU by that of parallel GAs on the GPU and show the acceleration ratios with varied population sizes and node numbers in Figures 14 and 15. Tables 8 and 9 list the acceleration ratios. We observe that as the amount of data (the population or node number) increases, the acceleration ratio increases, since the CPU reaches its limit while the GPU still does not.
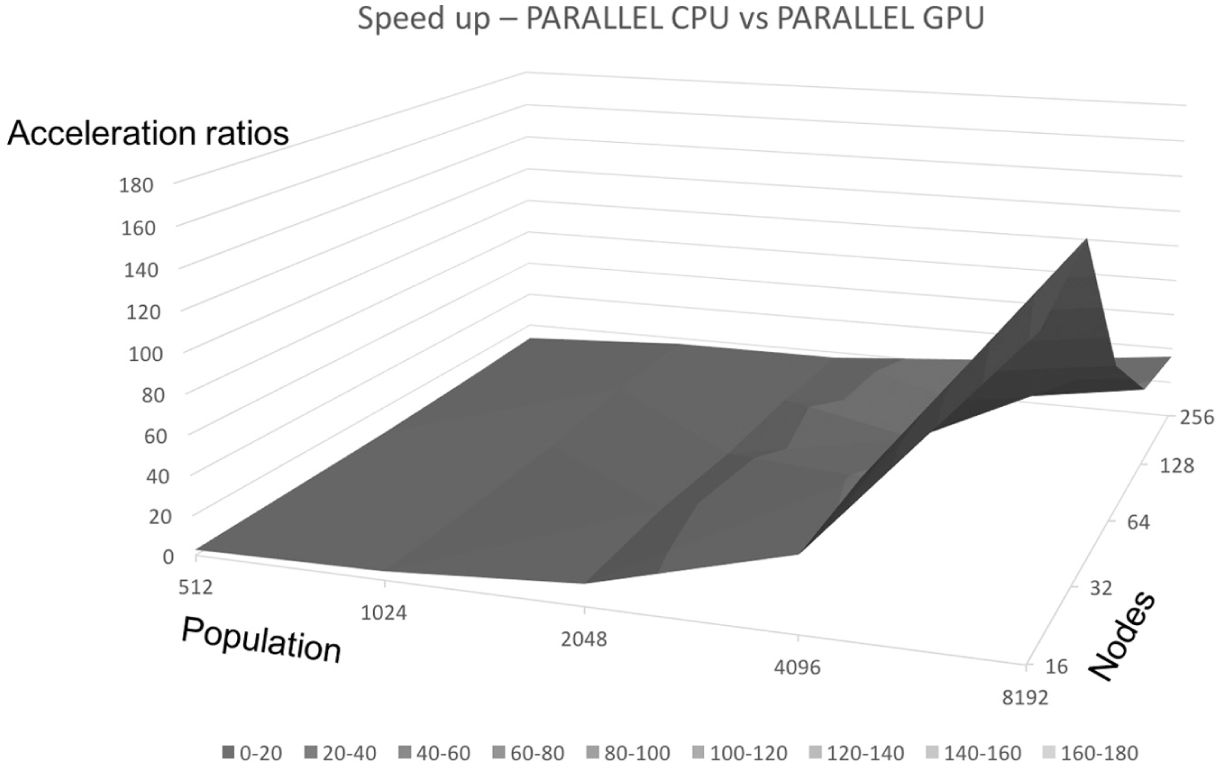
Acceleration ratios of GAs on the GPU over that on the parallel CPU.
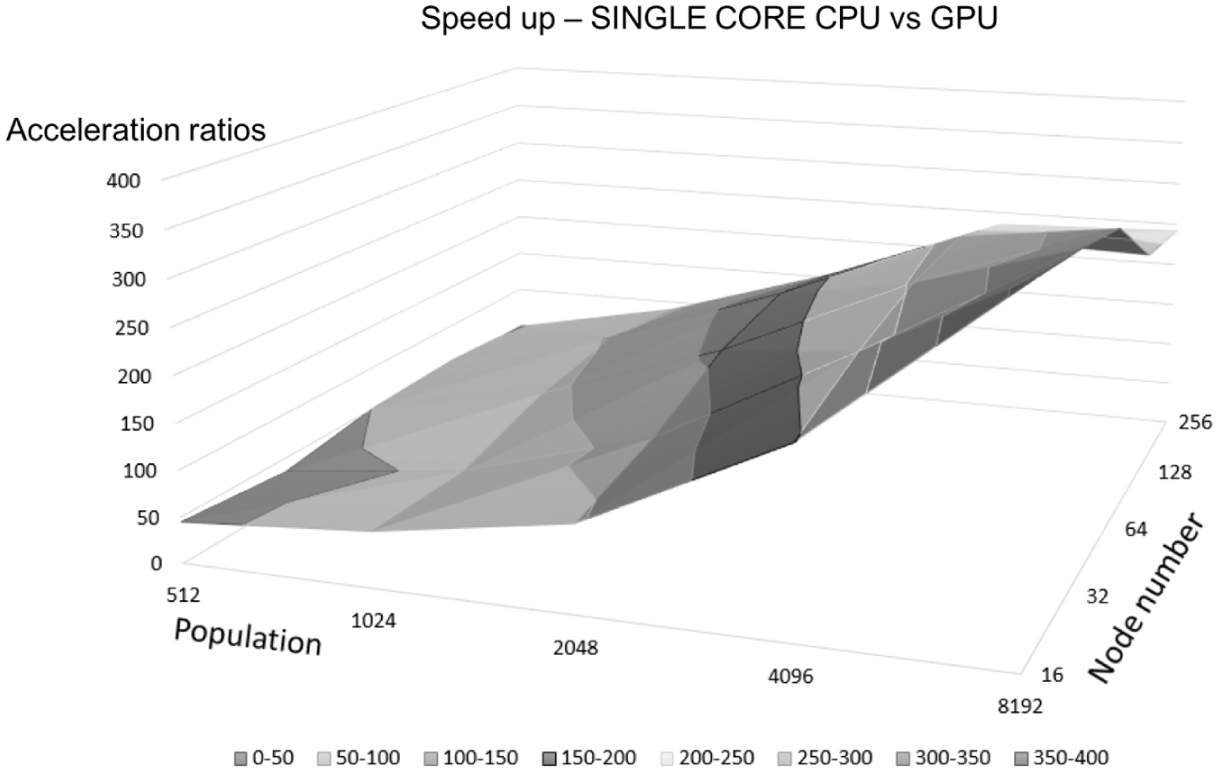
Acceleration ratios of GAs for GPU over single-core CPU.
Acceleration ratios of GAs on the GPU over that on the parallel CPU.

Acceleration ratios of gas for GPU over single-core CPU.

Converging speed over various node numbers
In this experiment, we mainly verify that the modified parallel GA (using the GPU) combined with the island model and simulated annealing shows better converging speed than the original GA (using the CPU). First, we run both GAs for 300 s. Figures 16 and 17 depict the relative errors of GAs using the CPU with various node numbers (16, 32, 64, 128, and 256) for single-core and multi-thread processes, respectively. From both figures, we observe that when the number of nodes is over 64, the GA using the CPU cannot converge into optimal solutions; also the converging speed is exponentially inverse to the number of nodes.

Relative errors of GAs using the CPU with various node numbers over 300 s.
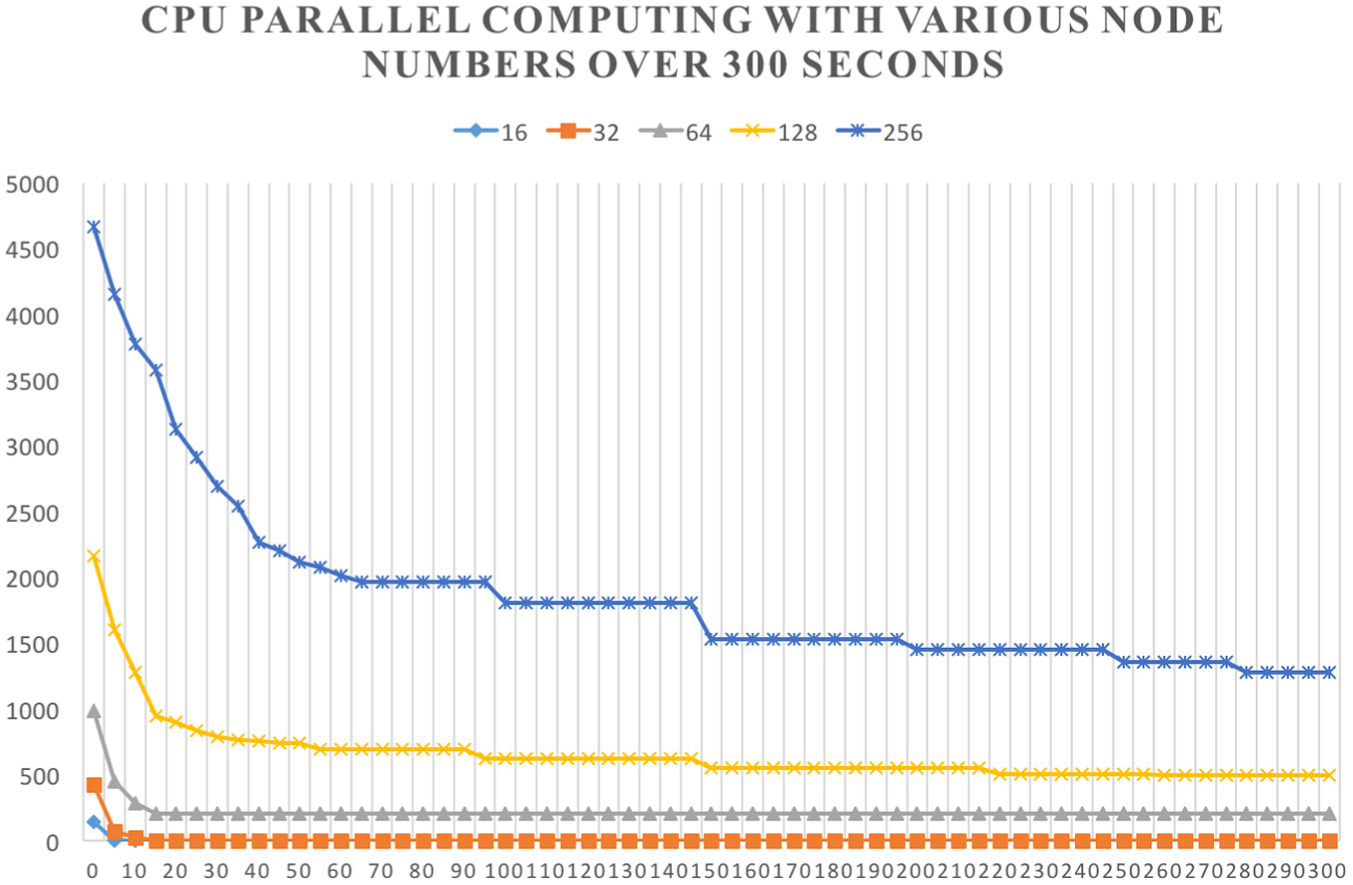
Relative errors of GAs using the CPU parallel computing with various node numbers over 300 s.
Figure 18 depicts the relative errors of the modified parallel GAs using the GPU with various node numbers (16, 32, 64, 128, and 256). From the plot, we observe that when the number node is less than 256, the modified parallel GA converges well (within 10 s); also, the overall converging speed of the modified parallel GA using the GPU is obviously faster than that of the original GA using the CPU.

Relative errors of the modified parallel GAs using the GPU with various node numbers over 300 s.
To verify that the acceleration of converging speed has been improved by the optimized parallel GA besides the high-speed computing power of the GPU, the following experiment we used the same maximum iteration (5000) as termination settings for GAs running on the CPU and GPU.
Figures 19 and 20 depict relative errors of GAs using the CPU with various node numbers for 5000 iterations for single-core and multi-thread processes, respectively. From both figures, we observe that the GA converges relatively slowly on the CPU.

Relative errors of single-thread GAs using the CPU with various node numbers for 5000 iterations.

Relative errors of multi-threaded GAs using the CPU with various node numbers for 5000 iterations.
Figure 21 depicts relative errors of modified parallel GAs using the GPU with various node numbers for 5000 iterations. From comparison of plots in Figures 19–21, we observe that for the same iteration, the modified parallel GA using the GPU converges much faster than the original GA using the CPU.
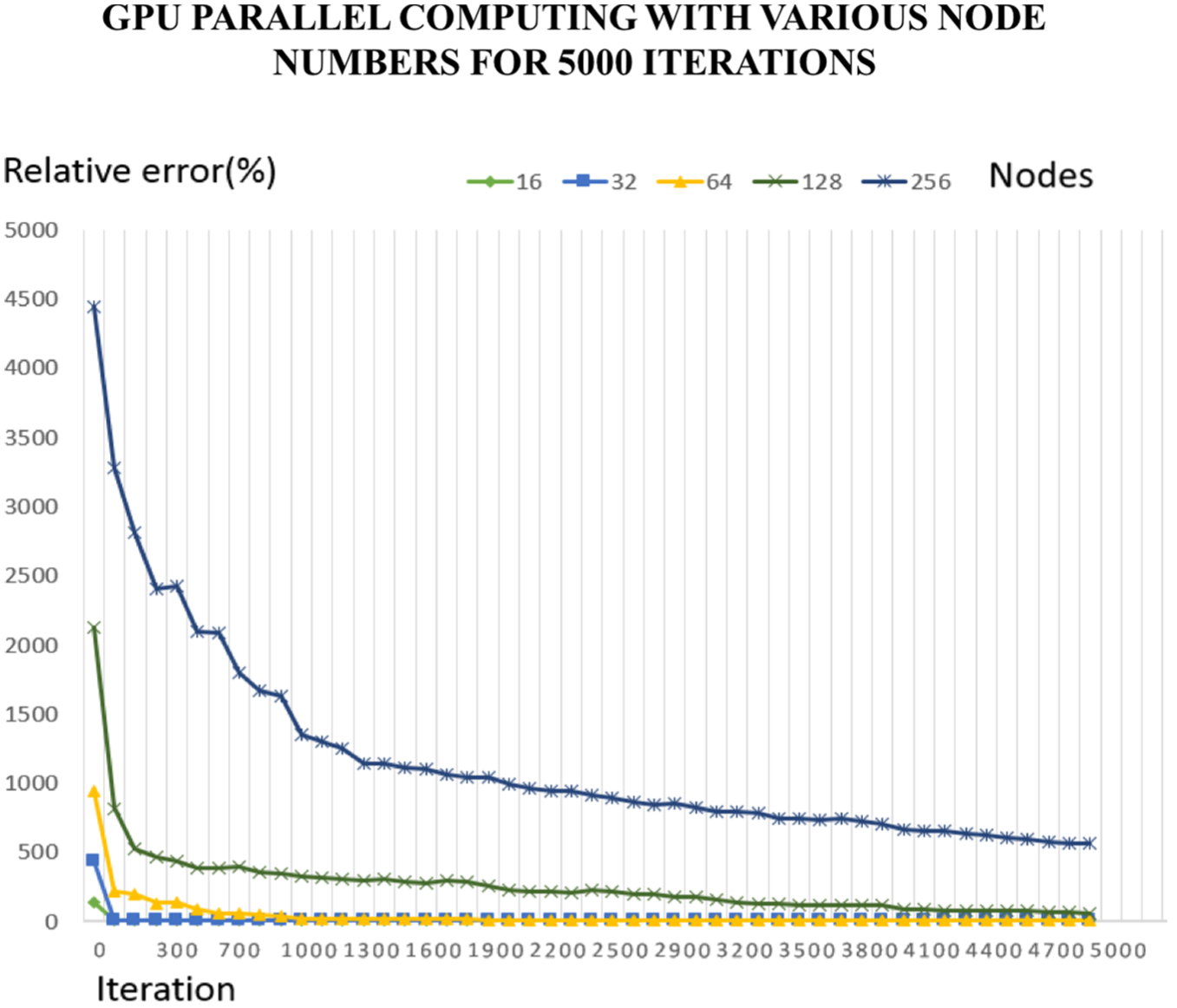
Relative errors of modified GAs using the GPU with various node numbers for 5000 iterations.
Conclusion
We experimentally prove that the GAs can be inputted into SIMD architecture for highly parallel computing. We have shown how to modify the GA process and memory access method to adjust for SIMD architecture. Also, to further enhance the converging speed on the GPU with SIMD architecture, the parallel GA has been combined with the island model and simulated annealing, which have been used in traditional CPU for parallelization. The modified parallel GA takes advantage of the blocks feature of NVIDIA CUDA and shows high performance. We replace mutation of GAs with the simulated annealing, which we plan to implement with a two-level GA to determine parameters for the rate of decrease in our future work.
Footnotes
Academic Editor: Artde Lin
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was partly supported by Ministry of Science and Technology, Taiwan, under grant number MOST 105-2221-E-029-012-MY2.