
Abstract
To solve the large-scale scheduling problem more efficiently within the requirements of the contract in shipyard, a three-layer parallel computing system was proposed. An optimized model for shipbuilding project scheduling problem was constructed under the condition of taking time and resource constraints into account. Moreover, the key techniques of proposed system were elaborated and the main steps were designed. In the first computing layer, the problem was decomposed into small parts in heterogeneous systems, reducing the problem scale; then, in the second layer, a co-evolution strategy for multi-populations was put forward to improve the algorithm robustness; in the third layer, a massive parallel computing method was performed under the Graphic Processing Unit structure. Finally, through two simulation examples, the robustness and outperforming others of the improved algorithm were verified.
Keywords
Introduction
As a complex system, a shipbuilding project is characterized by its long production period, a great quantity of activities, and a concrete completion date signed in the contract. More importantly, production for a shipbuilding project is highly order-oriented, reflecting the nature of single-item or small-batch production. Little amount of pipeline operation further makes the production quite a contrast to those of conventional projects. Under this condition, schedule control is of ever greater significance. Even though project evaluation and review technique (PERT) and critical path method (CPM) techniques contribute a lot to optimize the schedule, both of them deal only with the time without any consideration of resource constraints. Then, on the basis of CPM, Lu and Li 1 and Kim and de la Garza 2 studied on the scheduling problem with limited resources, which promotes the research on resource-constrained project scheduling problem (RCPSP). Möhring and Schulz 3 mentioned that RCPSP is one of the most intractable problems in operations research. In a resource-constrained project, each activity has duration and renewable resource requirements, and the precedence relationships also exist in different activities, which is shown in Figure 1. The sample project consists of 16 activities with the limited capacity of one renewable resource type. Node 1 and node 16 are dummy activities representing the start and end of the project, respectively. In Figure 1(a), it illustrates the precedence constraints. Besides, Figure 1(b) and (c) gives a feasible solution in which the permutation sequence is given by Figure 1(c) according to the start time of activities.

Example of project schedule model: (a) project network, (b) typical RCPSP schedule, and (c) activity list representation.
In shipbuilding project, as a result of long period and enormous amount of activities, the dummy activities are not limited to the start and end of the project but they are important nodes like milestones. Because of the large scale of the problem, the method for conventional RCPSP has limited optimization effect on the shipbuilding, which is mainly reflected in the speed of problem solving and quality of the optimal solution.
Bearing the above observations in mind, we apply a three-layer parallel computing system to the resource-constrained shipbuilding project scheduling problem, and the rest of this article is organized as follows. In section “Literature review,” some related works are outlined based on literature. Section “Shipbuilding project scheduling problem” describes the problem and illustrates and sets up a mathematical model. Next, a three-layer parallel computing system model is built in section “Proposed 3-layer parallel computing GA system model.” In section “Proposed algorithm,” the steps of the proposed algorithm are designed. Section “Simulation examples” provides two simulation examples to verify the computing system and discuss the differences of genetic algorithm (GA), hybrid GA, and the proposed parallel GA (PGA). Finally, in section “Conclusions and future work,” some advantages and limitations of our parallel computing system are summarized, which points out some remaining future work in the light of this.
Literature review
RCPSP and the extension of RCPSP have gained widespread attention for the last few years. Koné et al. 4 proposed the generalization of two existing mixed integer linear programming models for RCPSP considering storage resources that can be produced or consumed by activities. Kopanos et al. 5 developed two discrete-time formulations based on the definition of binary variables and two continuous-time formulations based on the concept of overlapping of activities for the RCPSP. Sahli et al. 6 presented four mixed integer linear programming models inspired by RCPSP when activities requiring renewable resources are replaced by events consuming or producing non-renewable resources. Christodoulou 7 included a comprehensive literature review on RCPSP and discussed two directions of schedule generation schemes. As the author states, RCPSP can be solved by use of either a serial-schedule or a parallel-schedule generation scheme. The serial method is activity-based, while the parallel method is time-based. Almeida et al. 8 put forward a heuristic framework to solve the multi-skill RCPSP based on parallel scheduling scheme. Maghsoudlou et al. 9 extended RCPSP taking into account multi-skill and multi-mode that integrated with discrete time-cost-quality trade-off. And a new chromosome structure was developed to solve the problem. In their survey, Kreter et al. 10 noted that the break-calendars were necessary to be considered for many operative RCPSP applications and generally different from different renewable resources. Then, they gave the models and solution procedures for the problem.
Husbands and Mill 11 described a framework of co-evolution to solve a highly generalized version of the manufacturing scheduling problem. In their research, a PGA search was used. Nevertheless, the devising parallel implementations provide a more robust search rather than speed up as most previous PGAs work. The author stated that the model presented can be generalized. Jiang et al., 12 Korayem et al., 13 and Yu et al. 14 used the co-evolutionary algorithm to solve different engineering problem. For the large-scale project scheduling optimization, robust performance is one aspect of the consideration, and the other is the computation speed. Wang 15 designed a PGA computing application and conducted in a single system image cluster. GAs are natural parallel evolution algorithms and can greatly improve the computing efficiency in a good parallel environment. Xu et al., 16 Chandio et al., 17 and Xu et al. 18 studied on the parallel computing system for task scheduling problem and analyzed the efficiency. With the rapid development of the hardware, an increasing number of people began to use graphics processing unit (GPU) for computing. Iturriaga et al. 19 presented a parallel implementation on central processing unit (CPU)/GPU of two variants of a stochastic local search method to efficiently solve the scheduling problem. Zhao et al. 20 provided a parallel immune algorithm in the study of traveling salesman problem (TSP). The algorithm was based on GPU and proved to greatly improve the computing efficiency.
Shipbuilding project scheduling problem
Parallel scheduling model based on MAG
Scheduling optimization for shipbuilding projects is a special kind of RCPSP, standing in a great contrast to the regular ones. In regular RCPSP, much attention was paid on activity sequencing and resource allocating, aiming to achieve the duration minimization. However, in terms of shipbuilding project with the feature of single-piece production, different projects are normally in different construction stages so as to avoid the conflict of key resources. Meanwhile, the completion time for each important stage has been determined at the time of signing the contract so as to ensure the effective use of key resources. With extensive studies and practices of lean shipbuilding mode, just-in-time (JIT) model has been introduced into shipbuilding RCPSP for increases in effective resource utilization rate and decreases in idle time of semi-finished products. To lessen the scheduling control complexity, a series of milestones are set for shipbuilding projects alongside their long project timelines. By this way, the overall completion scheduling control problem is broken down and distributed on these milestones. Figure 2 is an illustrative network diagram of a shipbuilding project, with several milestones (nodes 5, 8, and 14) considered. The gray nodes represent dummy activities while dotted boxes indicate activity groups. An activity group ending up with a milestone is also named after the milestone. For short, an activity group with a milestone is here marked by MAG (Milestone Activity Group), such as MAG 5 is the activity group whose last activity node is 5. Relationships between two MAG are serial (e.g. 5 and 8 in Figure 2) or parallel (e.g. 5 and 14 in Figure 2) connections. For the sake of simplified computation, there are four hypothesis:
Each milestone is an end point of a sub-project which is composed of the milestone’s MAG.
The level of MAGs is the same, indicating that a MAG only has one milestone in its realm (not include the start activity node).
The relation between each pair of MAGs is serial or parallel, constituting the overall workflow.
If MAG m is parallel to MAG n, then there is no intersection in their resource utilization sets. In other words, there is no identical resource constraints for these two MAGs.

An example of shipbuilding project: (a) a simplified network diagram of shipbuilding project and (b) MAGs grouping.
Classifying activities into multiple groups at this stage lays a foundation for further constructing a parallel structure. Regarding existing means of activity group allocation, Tsai et al. 21 conducted a comparison in view of the communication costs between activities. In the light of milestone activities, this article naturally turns the entire large-scale structure into small operable and independent activity groups for computation. In fact, this method is feasible and sensible for the following three reasons. To begin with, to split the complex issue into independent small-scale activity sequences is conducive to reducing an iteration of computation for scheduling. Second, it retains the natural allocation logic of activities, thereby each MAG carrying its own and concrete meaning. Furthermore, the logic helps to avoid unreasonable computation conditions, resulting in a considerable decrease in the computation burden.
Mathematic model
On the top of extensive research on RCPSP and JIT, a mathematic model is proposed in consideration of shipbuilding project nature. Take MAG as an example, there are
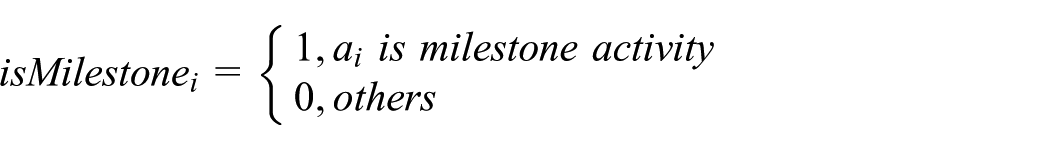
We defined that
Because the date of each milestone and project completion are specified in contract, we use

where






Equation (3) means that
Proposed three-layer parallel computing GA system model
The overall structure of computing system
Currently, most of the solutions to solve the project scheduling are accomplished in a single system, or adopting parallel tools like MATLAB toolbox to improve efficiency, which is convenient to realize, but it cannot achieve the best effect of computational performance on some specific issues. Therefore, this article innovatively proposes a parallel computing system with three built-in layers, namely, sub-problem-solving control layer, population behavior control layer, and individual behavior control layer. This structure is illustrated in Figure 3 with much details where the three-layer structure is displayed clearly and each layer are embedded in a specific algorithm to achieve their function. The sub-problem-solving control layer is built on the basis of MAG referred before. The next two layers are designed to further achieve optimized solutions for each sub-problem (MAG) and use a method of two-layer PGA.

Computing system structure.
This system is implemented in the MATLAB operating environment, as illustrated in Figure 4. A variety of mathematical methods are provided in class library of MATLAB, which allows the user to pay more attention to the design of computing systems and algorithms. Moreover, C++ and CUDA are also applied to improve the system structure and implement key functions of GPU computing. The first layer and the second layer are achieved through MATLAB, in which the first layer adopts the C++ to obtain the various site computing status and then updates their own status. The data interaction is achieved using the network to access the shared database. The third layer uses the GPU to calculate; the data interaction of which with the second layer is realized through the copy of memory between host and device.

Structure diagram of system realization.
Design of the first computing layer and the third computing layer
Some scholars tried to design a parallel computing system to solve the scheduling problem, such as heterogeneous computing in distributed computing sites,18,21,22 which assigns the tasks required to be calculated to the nodes that need to be calculated, as shown in Figure 5. The way that solves the subtask scheduling problem of task in different calculating nodes is more suitable to deal with the needs of dynamic planning and handle offsite scheduling problem. As the MAG grouping proposed in this article is based on the milestone nodes in the contract, department is taken as units to form different MAGs. The design of second layer structure is based on this idea. It consists of a novel grouping strategy of parallel computing, which is shown in section “Parallel scheduling model based on MAG” and particularly designed for rapidly solving large-scale problems. To put it brief, the group strategy decomposes the target problem into sub-problems and then addresses them in the heterogeneous computing system (HCS). In this regard, the problem scale is reduced and the problem-solving efficiency is improved. Such a strategy is of great significance for shipbuilding industry wherein the number of tasks amounts to ten thousands for a single project and even hundreds of thousands for a cruise ship project.
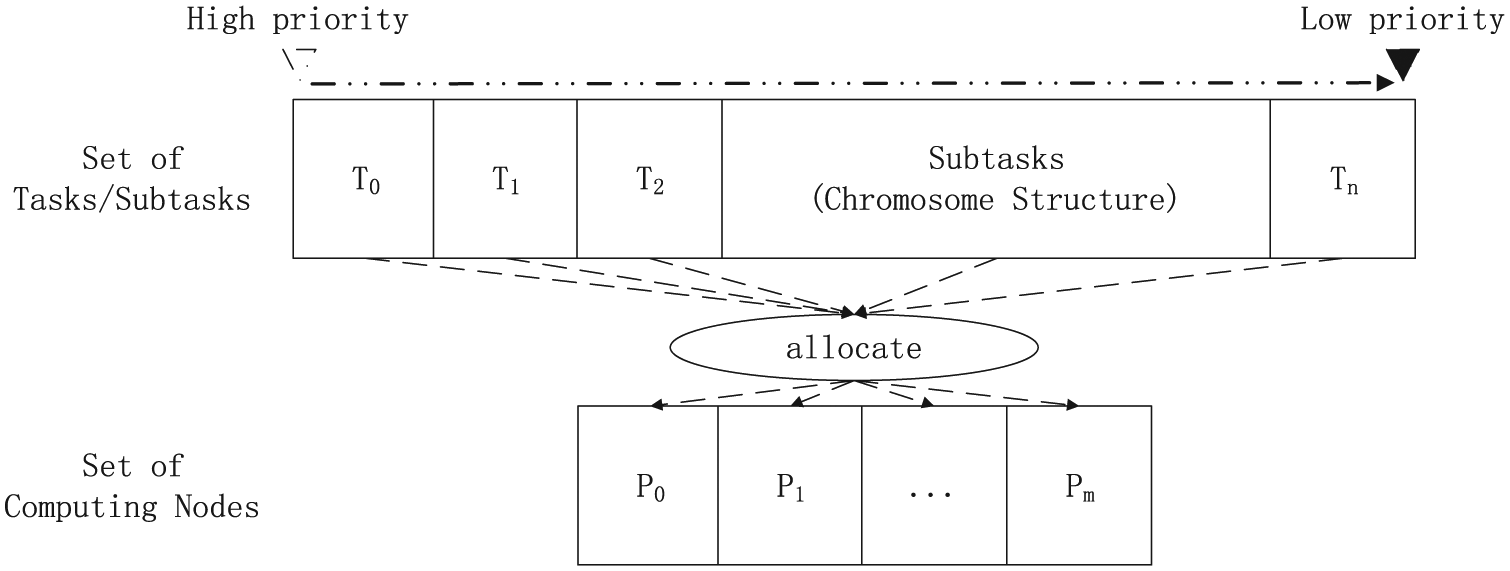
Schematic diagram of distributed computing.
The third layer is an individual behavior control layer, which targets at GA computation on the unitary population. In fact, GA has parallel attributes in its nature. However, in most cases, computational systems adopt the serial design model or realize the parallel computing to a limited extent. With an increase in the problem’s scale, operations on individual crossover, mutation, decoding, and fitness calculation are difficult to carry out, let alone the huge amount of computing resources to consume. As a result, computation time would dramatically rise in case of the serial design model.
Yang et al. 23 proposed a CPU-GPU-based GA to solve the scheduling problem, in which a large number of similar repetitive work is very consistent with the calculation characteristics of GPU. Wang and Shen 24 designed the structure of the GPU calculation, as displayed in Figure 6 where one block handles one task and one thread handles one activity plan of itself. According to the settings of different GPU dimensions, the required computing structure can be designed. In this sense, a large amount of work, such as population initialization, coding, decoding, and genetic operation, is all placed on the third layer, and a GPU-based individual control layer is designed and illustrated in Figure 7.

Schematic diagram of CPU-GPU calculation.
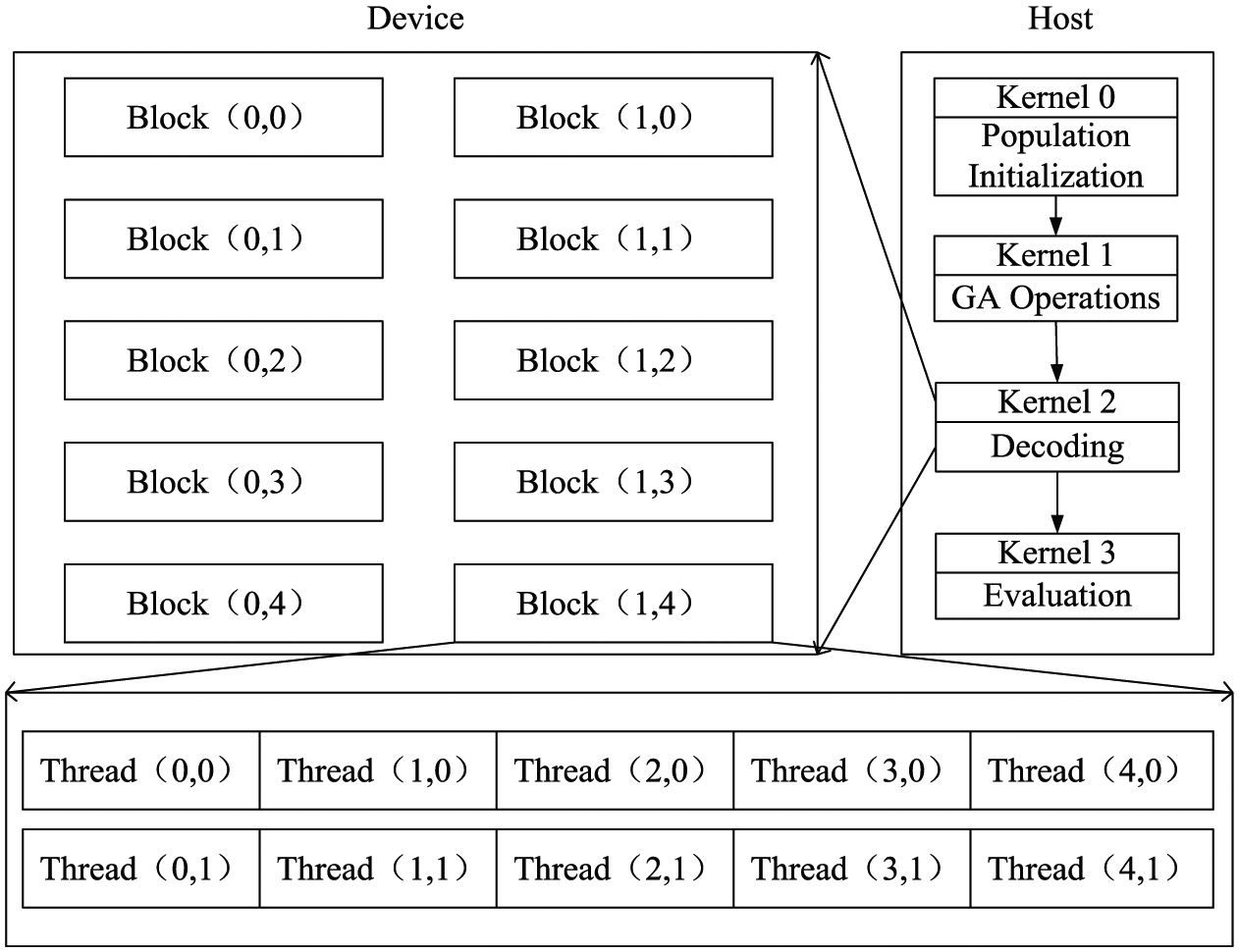
Schematic diagram of GPU computing structure.
Design of the second computing layer
Unlike the differences described in section “Design of the first computing layer and the third computing layer,” the design of second-level parallel computing does not directly improve the computational efficiency, but rather improve the convergence rate by increasing the solution quality of the algorithm. Even though efforts (four hypotheses in section “Shipbuilding project scheduling problem”) have been done in the milestone tasks’ set to decrease the grouping complexity and reduce their mutual interference, the number of tasks inside the MAG still reaches as much as around one thousand. This is apprehensible since coupling relationships become too complicated to tackle if the granularity of MAG is very small, on which the research does not meant to attach much emphasis. In accordance with the partitioned MAGs, there is a large solution space, easy to incur precocious phenomena. Satisfied with the present optimum, the algorithm often sees a premature convergence away from the global optimized solution. There are many solutions for avoidance of precocious phenomena. Mutation merely does help to escape from the local optimum but at a cost of tremendous computing time. Besides, several well-developed methods have been applied to counteract with precocious phenomena, among which hybrid algorithms are believed to be the best choice.25–28 When combined with strong local searching algorithms, GA as an excellent global optimization algorithm can rapidly converge to the global best. Figure 8 depicts such a combined approach. However, as the large-scale problem at present has burdened much on computing, it is inevitable to spend even longer time for conducting the sequentially hybrid algorithm. To overcome these barriers, this article puts forward a parallel computing layer defined as population behavior control layer. The population behavior control layer is shown in Figure 9.
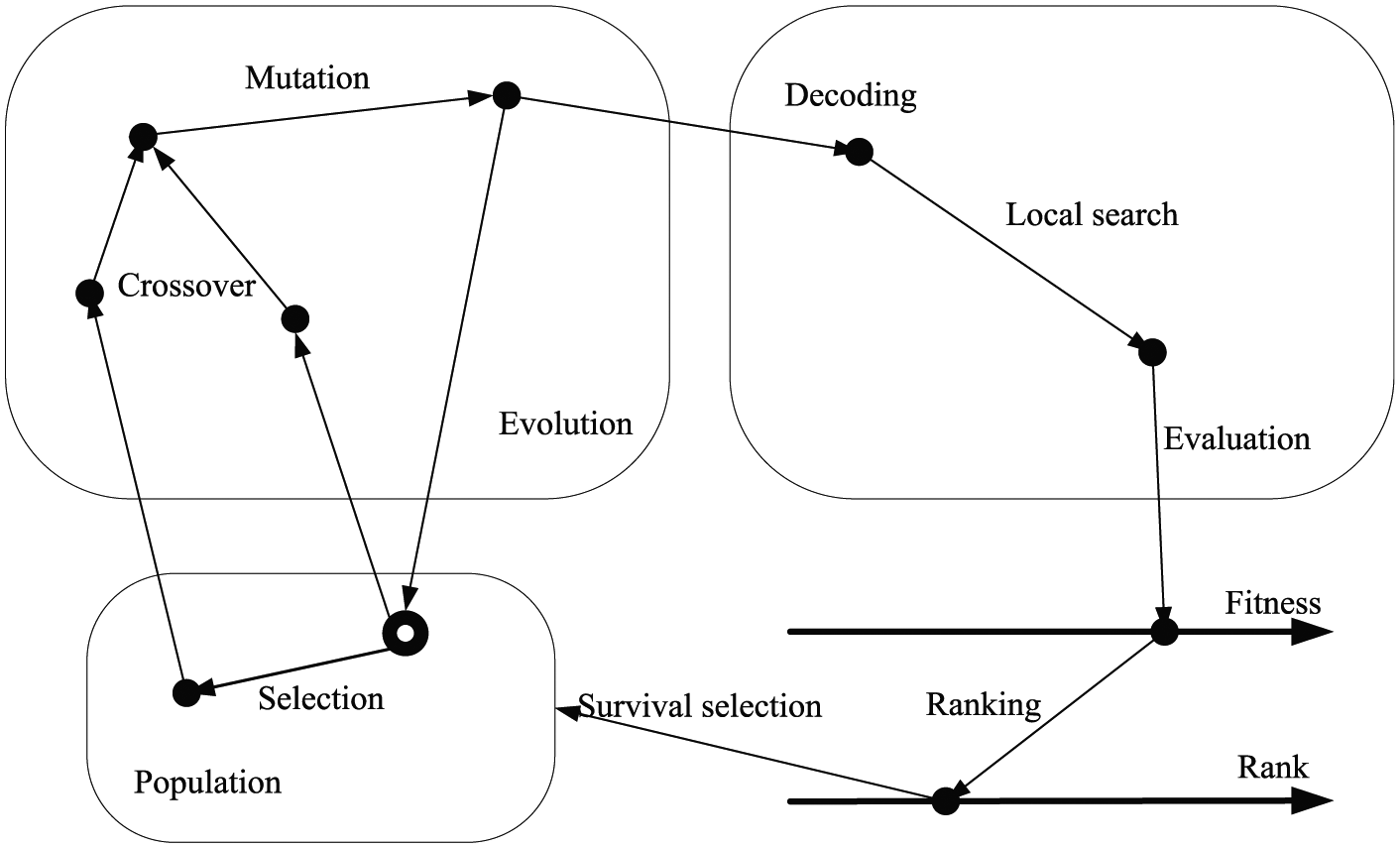
GA combines with local searching.
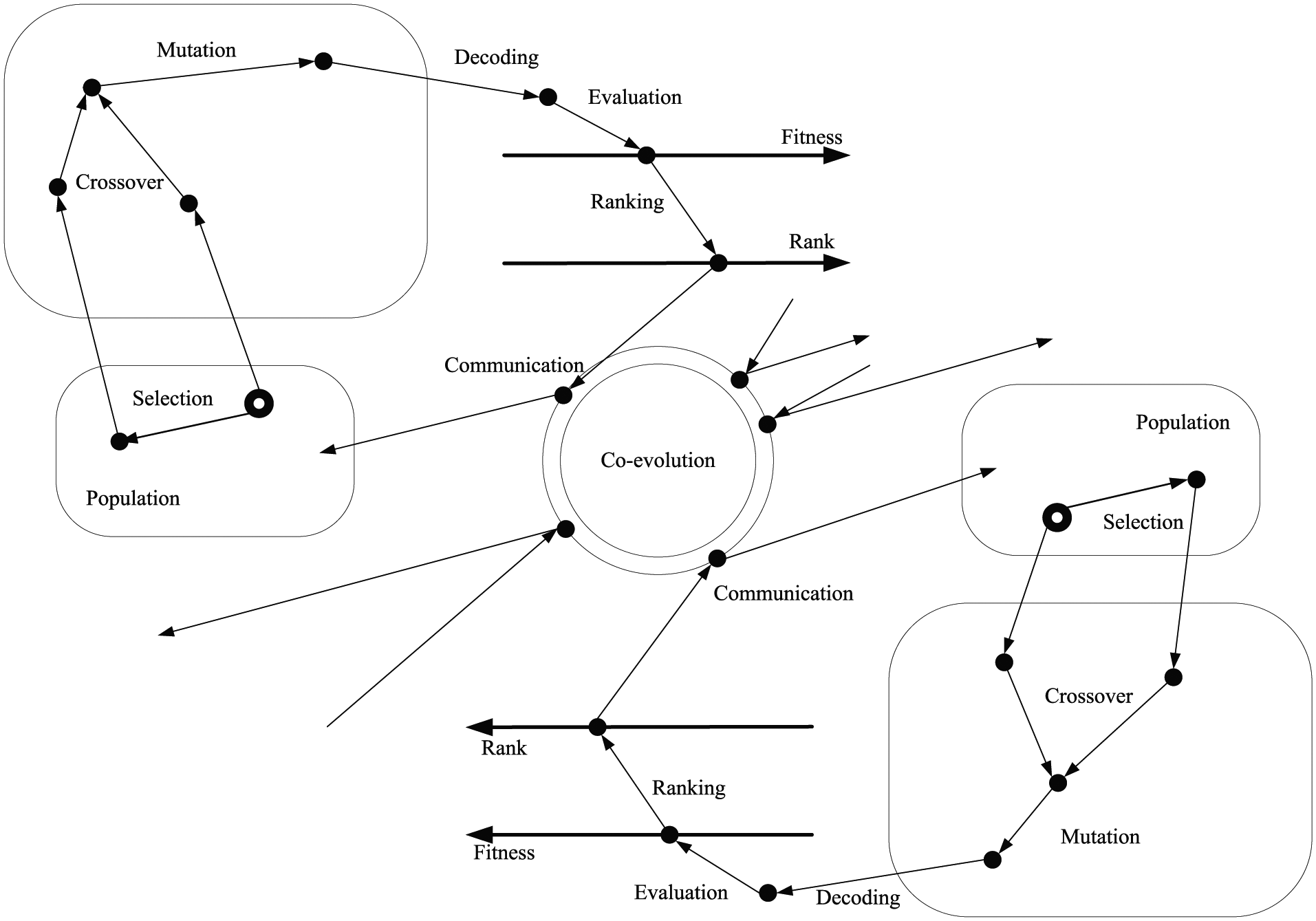
Parallel GA with co-evolution strategy.
This layer is based on the co-evolutionary algorithm which is proven to have a more robust performance and whose computation time can be significantly reduced in the parallel computing environment. 29 The substance of co-evolutionary lies in exchanging individuals across populations’ border to maintain the population diversity. By design of competing and cooperating policies, it is available for the algorithm to converge to the global optimum as fast as possible without influences on the original population evolution.
Proposed algorithm
Algorithm strategy
While exact methods are available for obtaining optimal solutions for small-scale problems, metaheuristic algorithms are required as the scale and complexity of the problem increase. 30 For the large-scale problems, it is prerequisite to be much stricter with algorithm design, seeking optimization in either quality or efficiency.
In alignment with the articulated three-layer parallel computing system, algorithm proposed in this article can be divided into two parts. On one hand, it explains that problems decompose into sub-problem based on MAG, which is shown in Figure 10. As a large-scale problem, project is broken down into a number of sub-problems. According to the hypothesis in section “Parallel scheduling model based on MAG,” each MAG is capable to get solutions independently and complete the entire project planning according to the networked synchronization information. On the other hand, a parallel computing for solving a single sub-problem is presented, which is displayed in Figure 11. In Figure 11(a), appropriate number of populations are generated, and various populations that get evolution dependently are working on obtaining a same goal. Figure 11(b) is a sub-flowchart of “Population Evolution” in Figure 11(a), which illustrates an evolutionary process for a single population. And “External Populations” indicates the data interaction with other populations which perform the same process in Figure 11(b).On the basis of GA, when satisfying the conditions of co-evolution, communication of multiple populations is conducted, which is in line with evolutionary strategy in section “Co-evolutionary strategy among populations.”

The first-layer parallel computing system.

The second- and third-layer parallel computing system.
Proposed GA steps
Chromosome encoding
The chromosome encoding scheme is based on the sequence of activities composing genes in a single MAG. Generate a code chain randomly with the length of
Population initialization
According to individual number
Set the cycle counter initial value
Generate an individual of which the length is Set the cycle counter initial value r = 1. And put activity 1 into the sselectable set SS. Choose an activity from SS as the rth gene of the individual i in accordance with certain rules from SS. And remove the activity from the SS. If all predecessors of the successor are selected, add them into SS. If r < N, then
Put the individual into the initial population.
If
Reproduction
GA accumulates best genes by “survival of the fitness” and obtains the optimum during evolution. A new generation is generated by two ways: crossover and mutation.
Crossover
There are several methods to make a crossover. In this article, a single-point crossover is applied, as shown in Figure 12.

Crossover operation.
Mutation
Mutation results in new genes. There are also a number of methods to mutate, such as insertion, swap, and reversion (see Figure 13(a)). However, some of them might undermine the precedence constraints between activities. For this regard, this research adopts the rebuild method, namely, regenerating the gene section before the mutation point. The process is shown in Figure 13(b), where the last two sites 2 and 7 are unchanged, but regenerate other parts of the chromosome.

Mutation operation: (a) common mutation method and (b) rebuild mutation method.
Decoding rule
Prior to fitness calculation, it is necessary to decode the chromosome. By decoding, basic information of each activity is acquired, including begin to end time, resource consumption alongside the time line, and so forth.
The decoding algorithm consists of
Decoding rules are given as follows:
Initialization
If
Calculated by following formula






Co-evolutionary strategy among populations
To maintain diversity of the population and avoid mature convergence, two strategies inserted into the co-evolutionary model are articulated as follows.
Competitive strategy
Let a constant
Corporative strategy
When a population traps into the local best in consecutive
Simulation examples
In this section, two simulation examples are given to validate the proposed algorithm based on the three-layer parallel computing system. The first simulation example intends to illustrate the feasibility and efficiency of the proposed algorithm. Then, two MAGs in the first simulation group are selected to conduct the second experiment, by which to what degree the proposed two-layer parallel GA (2LPGA) outperforms others can be seen. Configurations of the simulation environment are shown in Table 1.
Configurations of simulation environment.

Simulation example 1
In this part, a feasibility graph to represent shipbuilding project scheduling was set up using the authors’ self-developed program in MATLAB. There are 9700 activities grouped in 11 MAGs. Details about each MAG are shown in Table 2.
Information of MAG.

Parameters’ value exerts a great impact on the solution quality and searching speed. In fact, the coefficient weight attached on each MAG varies for different project stages and scheduling needs. In this simulation test, an equal weight was assigned to every MAG, namely, 1/11. Considering the simulation environment, the number of populations for co-evolution was initialized as 6. Table 3 compares computation conditions of the proposed GA driven by GPU and driven by CPU in terms of the problem scale and the population size. The GA driven by GPU is named third-layer PGA which applies the third computing layer. The GA driven by CPU can run directly through .m files in MATLAB. For each condition, these two kinds of algorithms were applied for five times, during which results of both the best and the worst value were trimmed. It is apparently seen that the proposed third-layer PGA performed well in a short computation time. Drawn from previous experience, if a population size is too small, the search space gets much smaller and the solution quality cannot be guaranteed. In contrary, if the size is too big, computation consumes more time, resulting in defects in calculation efficiency. Through this experiment, it was observed that the optimal solution could be achieved with proper population size, and increasing population size to above 200 would undermine the calculation time more than the solution quality. In this sense, the population size was determined to be 200.
Computation conditions of the usual GA and the third-layer PGA.

With such a condition (200 being the population size), the large-scale problem of 600 activities and 1300 activities were calculated. Taking a group of typical data as the source, a convergence diagram was generated (shown in Figure 14). In general, the convergence curves see several transient local convergences. For the 600 activities experimental group, the convergence speed was slow down in two periods. One is from generation 17 to generation 26, the other is generations beyond generation 36. In comparison, the 1300 experimental group experienced a rather slow convergence speed in three periods. They were generation 21 to generation 30, generation 32 to generation 50, and generation 51 to generation 78. However, it encountered a local optimum after generation 118. In lights of these clues, communication operations across populations were found to be necessary when there was a trend toward premature convergence. By means of statistics for the above group data, the authors ultimately selected to apply the

Convergence curve.
The simulation result of the optimal MAG scheduling is illustrated as Figure 15 and the fitness value is 0.

Simulation result.
Simulation example 2
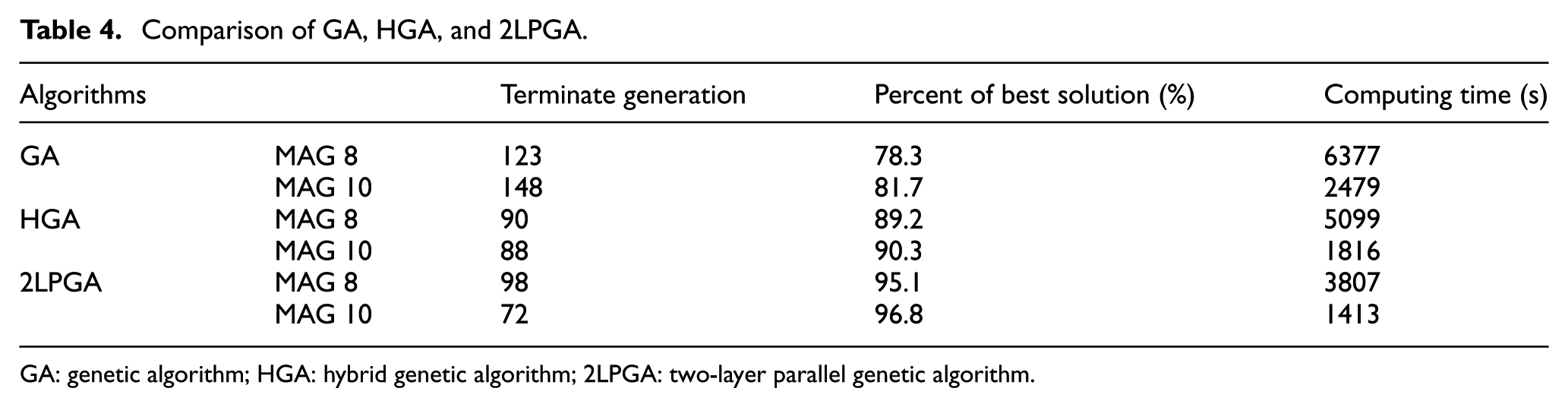
In order to differentiate the proposed algorithm from hybrid GA (with simulated annealing algorithm), the hybrid GA is abbreviated as HGA and the proposed algorithm is represented by 2LPGA.
In this part, GA, HGA, and 2LPGA were applied to solve the sub-problem of MAG 8 and MAG 10 from simulation example 1. The same simulation environment was arranged for these three algorithms: the number of chromosomes in the population was 200, the crossover probability was 0.7, the mutation probability was 0.3, and the max iterative time was 200. In addition, if the fitness value is 0 or the best fitness does not change in 20 loops, the algorithm would be terminated.
In order to avoid the random error, each algorithm was run 20 times and calculated the average values. The terminate generation, percent of best solution
Comparison of GA, HGA, and 2LPGA.
GA: genetic algorithm; HGA: hybrid genetic algorithm; 2LPGA: two-layer parallel genetic algorithm.

Convergence trend of three algorithms: (a) fitness value comparison and (b) average fitness value comparison.
Seen from Figure 16, the convergence trend of 2LPGA and HGA is nearly equivalent and considerably faster than GA. However, 2LPGA outweighs HGA in the computation time and the quality of solution (reflects in the average fitness). To summarize, the 2LPGA performs better than GA and HGA in terms of searching speed, higher solution quality, and robustness.
Conclusion and future work
Since resource-constrained shipbuilding project scheduling problem is an non-deterministic polynomial-time hard (NP-hard) combinatorial optimization problem, an efficient heuristic approach is required. In this article, a three-layer parallel computing system is proposed to solve this problem. In the first layer, a JIT scheduling model is designed with respect to requirements of shipbuilding projects. It helps to decompose the project into small parts, reducing the problem scale. However, these small sub-problems are still in large scale for the common RCPSP. On this account, the remaining two layers are arranged for computing with 2LPGA, targeting at conversions of the original serial computation into parallel counterparts without influences on the computing quality. In the second layer, a competitive strategy and a cooperative strategy for multi-populations are put forward to improve the algorithm robustness. In the last layer, each individual is regarded as an independent thread to operate generic and decoding processes. Together with the adopted GPU framework in this layer, computational efficiency increases remarkably.
The quality and convergence rate are shown to be more ideal. Moreover, the proposed algorithm is proven to be much competent to generate a solution in line with expectations written in contract already for the large-scale problem of shipbuilding project scheduling in a virtual shipyard with reasonable amount of time. The proposed algorithm stands out remarkably when the project involves a large number of activities.
However, further improvements are still required. First, MAG scale remains quite large, waiting to be decomposed into smaller groups. The exponential relation between coupling influence and the group fine-grain would be the first barrier to overcome. Therefore, a corresponding algorithm is needed to undertake this task. Second, since the solution satisfying constraints is not unique, resource balance models are considered to be necessarily designed and added to the research. Besides, application of the parallel system to other NP-hard combinatorial optimization problems is also an important research orientation for the authors.
Footnotes
Academic Editor: Peter Nielsen
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the National Natural Science Foundation of China (No. 51679059) and the High Technology for Ship Scientific Research Program of Ministry of Industry and Information Technology of the People’s Republic of China ((2016) No. 543).