
Abstract
Drunk driving is among the main causes of urban road traffic accidents. Currently, contact-type and non-real-time random inspection are methods used to verify whether drivers are drunk driving. However, these techniques cannot meet the actual demand of drunk driving testing. This study considers the following traffic parameters as inputs: speed-up, even-speed, and sharp-turn road segments; vehicle speed; acceleration and accelerator pedal position; and engine speed. Thereafter, this study adopts the support vector machine model to identify drivers’ driving behaviors to determine whether they are drunk driving, as well as the particle swarm optimization algorithm to optimize the model, thereby improving training speed. Results show that the support vector machine model based on the particle swarm optimization algorithm can immediately and accurately determine the drunk driving state of drivers, provide theoretical support to non-contact drunk driving test, and realize the foundation of safety driving assistance system toward the adoption of the corresponding measures. Therefore, this study has positive significance in improving traffic safety.
Introduction
Recent traffic accidents caused by drunk driving account for approximately 50%–60% of traffic accidents. Accordingly, drunk driving has become one of the main causes of vehicular homicides. Drunk drivers often think that they can drink heavily and simultaneously have excellent driving skills and a good experience. In addition, current drunk driving tests involve non-real-time and contact random inspections; hence, a few drivers are still able to drive cars after drinking heavily. This scenario is dangerous, seriously threatens the life and safety of drivers and others and affects traffic and social order. If we can collect relative parameters to identify driving behaviors and determine whether drivers are drunk driving, then we can adopt appropriate warning and limiting measures provided by a traffic safety assistance system or realize a real-time, non-contact drunk driving state monitor through a smart traffic system. These systems may have a positive practical significance to reduce drunk driving accidents and enhance traffic safety.
To date, studies on predicting and identifying drivers’ intentions and behaviors based on traffic environment, vehicle condition, and drivers’ characteristics have provided popular direction for traffic safety research, thereby improving the intelligence of traffic safety assistance systems. For example, MC Nechyba and Y Xu 1 established a control strategy using a hidden Markov model. Ohno 2 developed an adaptive cruise control system and applied it to a vehicle operation simulation system. Kumagai and Akamatsu 3 adopted a dynamic Bayesian network and function tree algorithm and derived a crossroads parking probability prediction model. Finally, Sekizawa et al. 4 established a random transition autoregressive model to identify drivers.
Many researchers have also conducted extensive studies on drunk driving. Linnoila et al. 5 determined that when the alcohol concentration in the blood of drivers reaches a certain level, their driving control ability changes immensely. Weiler et al. 6 proved that drinking affects the lane-keeping ability of drivers. Williamson et al. 7 determined that drinking affects the response time and alertness of drivers. Howland et al. 8 particularly demonstrated that drivers’ response time lengthens after drinking. Furthermore, Carswell and Chandran 9 analyzed the operational condition of vehicles, obtained their travel curve, and then compared the normal operation curve with the abnormal one to determine whether drivers are drunk driving. A Liu and D Salvucci 10 predicted drivers’ state through their operational motions. Identifying driving behaviors and applying them to conduct research on driving assistance systems are significant to the development of a smart traffic system. Brookhuis et al. 11 proposed that an advanced driving assistance system can reduce driver errors and improve traffic safety. Labayrade et al. 12 developed a collision avoidance system that can send out a warning or adopt a braking intervention for drivers aimed at a pre-designed threshold. Chang et al. 13 mainly built a feedback gain controller using particle swarm operation (PSO) and quantum PSO algorithms to realize a driving assistance system. H-H Chiang et al. 14 studied information exchange between vehicles through an embedded digital signal processor when vehicles overtake to avoid collision and realize driving assistance. Finally, Vahidi and Eskandarian 15 explained that many belted alternator starters can be applied to vehicle automatic control and adaptive cruise systems by detecting the relative distance of cars present at a time.
Algorithm introduction
Researchers use different algorithms to identify drivers’ driving behaviors. These algorithms include the PSO algorithm, genetic algorithm, nest algorithm, and Bayesian theory, among others. Each algorithm has its advantages and disadvantages. A few algorithms can hardly achieve a high accuracy rate, whereas several are complex with long operations. This study adopts the support vector machine (SVM) model based on the PSO algorithm, which can substantially improve training efficiency with high accuracy.
PSO algorithm
The PSO algorithm is known for the following aspects: massively parallel, distributed storage, self-organization, self-adaptation, and self-learning. This algorithm is particularly suitable for processing inaccurate and obscure information processing problems that must consider many factors and conditions. Moreover, the PSO algorithm is considerably robust and characterized by lack of noise. Therefore, this algorithm can be used for the parameter optimization of the SVM model to enhance its training efficiency.
The mathematical model of the PSO algorithm is shown as follows


where Vid is the particle’s current speed; Xid is the particle’s current location; ω is the inertia weight; d = 1, 2,…, D; i = 1, 2,…, n; k is the current iterative number; r1, r2 are random numbers; and c1, c2 are the acceleration factors, which are decided to be 1.5 and 1.7 for this study.
The PSO starts from creating the initial particles and assigning them initial velocities and locations. It evaluates the fitness at each particle location by the objective function. It determines the individual best fitness and location of each particle, comparing its current fitness to its ever-best fitness at its ever-best location. If better, the particle’s individual best fitness and location is updated to current fitness and location. And it also determines the global best fitness and location of the whole particle swarm by comparing each particle’s fitness to the global ever-best fitness. It then iteratively updates the particle velocities and locations, within bounds, based on equations (1) and (2). Iterations proceed until the algorithm reaches a stopping criterion. It finally outputs the individual and global best fitness and location.
SVM model
The SVM model is a popular supervised learning algorithm. This algorithm mainly adopts nonlinear conversion
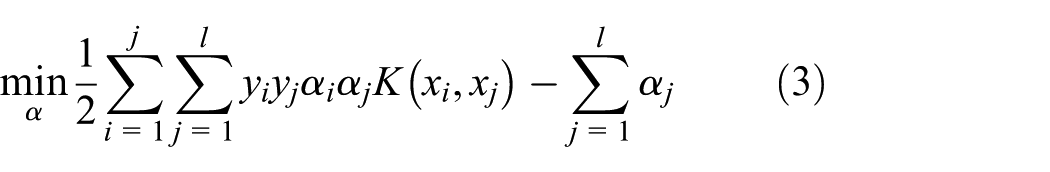

where
The coefficients

The kernel functions enable them to operate in the high-dimensional feature space by simply computing the inner products between the images of all pairs of data in the feature space. This operation is often computationally cheaper than the explicit computation of the coordinates. Most popular kernels include String kernel, Polynomial kernel, and Radial Basis Function (RBF) kernel. The RBF kernel is chosen, whose function is as follows

SVM based on PSO
As the values of penalty factor C and the factor σ in RBF kernel function would affect the accuracy of SVM classification, PSO algorithm is applied to optimize the two parameters to improve the accuracy of SVM. Taking the two parameters as two swarms, it iteratively evaluates the fitness of the SVM objective function by updating the particles’ velocities and locations in the two swarms. It finally finds the best values of the two parameters. The procedure of SVM based on PSO is shown in Figure 1.

The procedure of SVM based on PSO.
Parameter selection
Experiment introduction
Driving behaviors can reflect the driving state of drivers, particularly because drinking has significant influence on the physical and mental states of drivers. In addition, drunk driving behavior is considerably different from normal driving behavior. The driving experiment designed in this study presumes that a driver is driving in typical urban road environments, which comprise speed-up, even-speed, and sharp-turn road segments. In the experiment, drivers are driving on a driving simulator where the typical urban road environments are simulated. Drivers drive through every road segment before drunk and drive through the same road segments again after drinking a certain amount of wine. To improve the precision and to enhance the contrast, the driver is asked to drive eight times before and after drunk. The parameters that reflect the characteristics of driving behavior are collected before and after drunk. These parameters include vehicle speed, acceleration and accelerator pedal position, and engine speed. These parameters can reflect the apparent differences between the normal and drink driving states of drivers.
Parameter comparison
An even-speed road segment is taken as an example of a road environment. The following diagrams (Figures 2–5) compare the characteristic curves of relative parameters collected before and after drunk, such as vehicle speed, acceleration, engine speed, and accelerator position. The collected data of these parameters are Fourier transformed to their characteristic values of frequency and power.

Comparison of vehicle speed characteristic curves.

Comparison of acceleration characteristic curves.

Comparison of engine speed characteristic curves.

Comparison of accelerator position characteristic curves.
The diagrams show significant differences between the relative parameters of normal and drunk driving behaviors. This study takes the relative parameters (i.e. vehicle speed, acceleration, accelerator pedal position, and engine speed) as inputs, adopts the SVM model to identify driving behavior, and determines whether the driver is drunk driving. To improve the training speed and strengthen the practicability of the algorithm, this study adopts the PSO algorithm to optimize the parameters of the SVM model.
Driving behavior identification and drunk driving determination
This study uses MATLAB to implement the SVM algorithm based on the PSO algorithm. The following parameters are used in this study: vehicle speed, acceleration and accelerator pedal position, and engine speed on typical urban road segments (e.g. speed-up, even-speed, and sharp-turn road segments). Thereafter, we identify the driving behaviors of drivers and determine whether they are drunk driving (Figures 6–11).

Driving state determination on even-speed road segments.

Fit curve and accuracy rate on even-speed road segments.

Driving state determination on speed-up road segments.

Fitness curve and accuracy rate on speed-up road segments.

Driving state determination on sharp-turn road segments.

Fitness curve and accuracy rate on sharp-turn road segments.
On even-speed road segments, the accuracy rate of determining a drunk driving state can reach as high as 98.83%, whereas that on speed-up and sharp-turn road segments can reach 93.03% and 88.62%. By contrast, based on the same data, the accuracies of other classic models are listed in Table 1.
Accuracy comparison of models.

SVM: support vector machine; PSO: particle swarm operation.
From the accuracy comparison, it shows that the accuracy of SVM model based on PSO, which is introduced in this study to identify drunk driving, is better than other classic models. On typical urban road segments, the SVM model based on PSO can immediately and accurately identify the driving behaviors of drivers and determine whether they are drunk driving.
Conclusion
Drunk driving is among the main causes of urban road traffic accidents, and the driving behavior characteristics of drivers in a drunk driving state are significantly different from those of drivers in a normal state. This study considers vehicle speed, acceleration and accelerator pedal position, and engine speed as input parameters and develops the SVM model to identify the driving behaviors of drivers and to determine whether drivers are in a drunk driving state. To improve the model training speed, the PSO algorithm is adopted to optimize the model of the parameters. The data are collected from the experiment which is designed to simulate the typical driving on the urban road during speed-up, even-speed, and turning driving, whether the drivers are under drunk driving or not. The results show that the SVM model optimized by the PSO algorithm, after well trained, has high identification rate of whether drivers are in a drunk driving state in a typical urban road segment: the accuracy comes to 98.83% for speed-up segment, 93.03.49% for turning segment, and 88.62% for even-speed segment. The accuracy is sure to be higher if the data were collected from actual traffic circumstance.
This research provides theoretical support for systems to identify drunk driving state and the possible realization of non-contact drunk driving test. Furthermore, this study can be applied to enhance the driving-safety-assistant systems, so that the systems can substantially develop corresponding reactions, exact warning, or appropriate restriction to the drunk driving drivers, for example, after the determination of drunk driving. The realization of non-contact drunk driving test can dramatically increase the efficiency and convenience of testing drunk driving, which would decrease the fluke mind of the drunk drivers. Finally, this research has a positive significance in improving traffic safety.
Footnotes
Academic Editor: Yongjun Shen
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the “Fundamental Research Funds for the Central Universities” (310822151119).