
Abstract
This article studies a scheduling problem of a two-machine flow shop with both time-dependent deteriorating jobs and sequence-independent setup time. It is assumed that the deterioration of processing time and setup time is of a linear increasing function with respect to the starting time. The objective is to minimize the total completion time of all jobs. For such a scheduling problem, a mixed integer programming model is developed to find an optimal solution for small-sized problems. For medium- and large-sized problems, a modified variable neighborhood search algorithm is presented. To improve the performance of the algorithm, a greedy algorithm is proposed to find a good initial solution. Also, lower bounds are presented for performance evaluation. Numerical experiments are used to evaluate the effectiveness and efficiency of the proposed method, and the results show that an optimal or near-optimal solution can be obtained.
Introduction
It is vitally important to optimally schedule a production system, and great attention has been paid to this issue, such as the studies in the literature.1–9 Among the production scheduling problems, in some production systems, the jobs to be scheduled are subject to deterioration,10–12 which complicates the scheduling problem. Thus, recently, there is a growing research attention to the flow-shop scheduling problem with time-dependent deteriorating jobs. Examples of deterioration jobs can been found in real-life manufacturing workshops, such as steel rolling mills. 13 In a steel rolling mill, when an ingot is waiting to enter the rolling machine, its temperature may drop below a certain level such that it needs to be reheated before its rolling. This takes more time to accomplish the job. Such phenomenon is called deterioration effect in the literature. There are some other examples in scheduling maintenance jobs, such as cleaning assignment and modeling of firefighting. 14
In scheduling production systems with deterioration jobs, some researchers group the jobs as groups for finding a good schedule, and such a method is called group scheduling. For the single-machine group scheduling problem with linear increasing deterioration function, different models are built,15–17,33,35 and efficient solution methods are proposed. With the deteriorating and learning effect of a job being taken into account, efficient methods are given to minimize the make-span or total completion time of all the jobs in scheduling a single machine.18,19,34 Also, Zhang and Yan 18 proposed a method to solve the maximum lateness minimization problem. The studies done in the literature17–19 focus on the single-machine scheduling problem with deteriorating jobs. However, their methods are not applicable to a multi-machine flow-shop system.
The studies on a two-machine flow-shop scheduling problem with linear increasing deterioration have been done in the literature.20–25 In Wu and Lee, 20 to minimize the mean flow time, branch-and-bound algorithms and several heuristic algorithms are proposed to find an optimal solution and near-optimal solution, respectively. In Ng et al., 21 the objective is to minimize the total completion time of the jobs. To do so, some efficient methods and a heuristic algorithm are proposed to obtain the lower bounds and an initial upper bound, respectively. Then, with the lower and upper bounds, the efficiency and effectiveness of the developed branch-and-bound algorithm can be improved. The studies done in the literature22–25 deal with a simple linear deterioration model that is different from the one in Wu and Lee 20 and Ng et al. 21 They proposed branch-and-bound algorithms or heuristics to minimize the make-span and total completion time of the jobs for a two-machine flow shop.
In scheduling a manufacturing system, one issue is how to deal with the setup time. In the literature,20–25 it is assumed that the setup time can be neglected or combined with the processing time. Although this assumption may be reasonable for some manufacturing processes, for some other cases, it is better to be separated from the processing time. 26 This can be shown by taking steel rolling mills as an example. In this system, when the temperature of an ingot drops to a level that is below the required one, it needs to be reheated, which is exactly a setup process. By the Gantt chart shown in Figure 1, a schedule is found with the make-span being 25 s if the setup time is separated from the processing time. However, as shown by the Gantt chart in Figure 2, one obtains a schedule with the make-span being 29 s when the setup time is combined with the processing time. This implies that the performance of the system can be improved by separating the setup time from the processing time. Allahverdi et al. 27 pointed out that two types of setups exist. One is that the setup time depends on the job to be processed only, resulting in a sequence-independent setup. The other is that the setup time depends on both the job to be processed and its preceding job, resulting in a sequence-dependent setup.

An example with the setup time being separated from the processing time.

An example with the setup time being combined in the processing time.
With setup time and processing time being separated, both processing time and setup time can be deteriorated. It follows from the above discussion that up to now, the studies in the literature20–25 for two-machine flow-shop scheduling problem with deteriorating jobs are done under the assumption that setup time can be neglected or integrated in the processing time. As shown in the above simple example that by separating the setup time from the processing time, one can improve the performance of the obtained schedule. Thus, it is meaningful to conduct a study on scheduling a two-machine flow shop by separating the setup time from the processing time with both processing time and setup time being deteriorated. This work focuses on this problem.
For the addressed problem, we make the following contributions. The problem is formulated as a mixed integer programming (MIP) model that can be used to find an optimal solution for small-sized problems. Then, to make a large-sized problem solvable, variable neighborhood search (VNS) algorithm is modified such that it is suitable for the addressed problem. Since the performance of a VNS is dependent on its initial solution, a greedy algorithm is proposed to find a good initial solution. In order to evaluate the performance of the proposed method, lower bounds for the problem are presented. Then, by numerical experiments, it is shown that an optimal or near-optimal solution can be found by the proposed method.
The remaining part of this article is organized as follows: section “Problem description and formulation” presents the problem description and its MIP formulations. Then, in section “Solution method,” a modified VNS algorithm is developed to solve large-sized problems. In section “Numerical results,” numerical experiments are conducted to evaluate the effectiveness and efficiency of the proposed algorithms. Finally, conclusions are given in section “Conclusion.”
Problem description and formulation
Problem description
This work studies a two-machine flow-shop scheduling problem with time-dependent deteriorating jobs and sequence-independent deteriorating setup time, and such a system is illustrated in Figure 3.

A two-machine flow shop.
To describe and formulate the problem, we need the following notation:
M1 and M2: machines for steps 1 and 2, respectively;
Oij: operation when job Jj is processed by Mi, i ∈
αij: normal processing time of Oij;
pij: actual processing time of Oij;
δij: normal setup time of Oij;
sij: actual setup time of Oij;
bij: deterioration rate of the processing time for Oij at time t when the processing of Oij starts;
θij: deterioration rate of the setup time for Oij at time t;
π: schedule;
Cij(π): completion time of job Jj at Mi, i ∈
Ci[j](π): completion time of the jth job processed by Mi, i ∈
C2j: completion time of job Jj;
ΣC2j: total completion time of all the jobs;
xrj, r, j ∈
For a two-machine flow shop, a job in

With a linear increasing deterioration of the setup time for machines, the actual setup time for Oij can be written as

Since the deterioration rates of the processing time and setup time of machines are dependent on jobs, they can be written as follows: bij = bαij and θij = bδij with b ≥ 0, respectively. Thus, Expressions (1) and (2) can be rewritten as follows
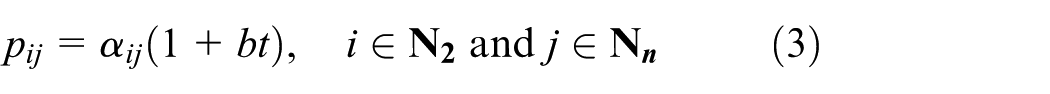

This work aims to minimize the total completion time that is the sum of the time taken for a job to stay in the system. In this work, for simplicity of presentation, it is assumed that the capacity of the intermediate buffer between machines M1 and M2 is unlimited. Then, given a schedule π, for a two-machine flow shop with time-dependent deteriorating jobs and sequence-independent deteriorating setup time, we can obtain the make-span and the total completion time, respectively. Generally, the two-machine flow-shop scheduling problem with time-independent deteriorating jobs and sequence-independent deteriorating setup time can be described as F2|pij = αij(1 +bt), sij = δij(1 +bt)|ΣC2j, where F2 represents that the two machines are serial in a flow shop.
Problem formulation
With an unlimited intermediate buffer between M1 and M2, it is easy to verify that an optimal schedule should make M1 have no idle time when one job is switched to another. Let t0 be the start time for the processing of the first job for a schedule. Then, the completion time of the first job processed by M1 is C1[1] = t0+δ1[1](1 +bt0) +α1[1]{1 +b[t0+δ1[1](1 +bt0)]} = t0+bδ1[1](1/b+t0) + 1/b − 1/b+α1[1]{1 +b[t0+bδ1[1](1/b+t0) + 1/b − 1/b]} = (t0+ 1/b)(bδ1[1]+ 1) − 1/b+α1[1]{1 +b[(t0+ 1/b)(bδ1[1]+ 1) − 1/b]} = (t0+ 1/b)(bδ1[1]+ 1) +bα1[1](t0+ 1/b)(bδ1[1]+ 1) − 1/b = (t0+ 1/b)(1 +bδ1[1])(1 +bα1[1]) − 1/b. For the second job processed by M1, its completion time is

By Expression (5), an MIP model can be developed for the problem F2|pij = αij(1 +bt), sij = δij(1 +bt)|ΣC2j as follows




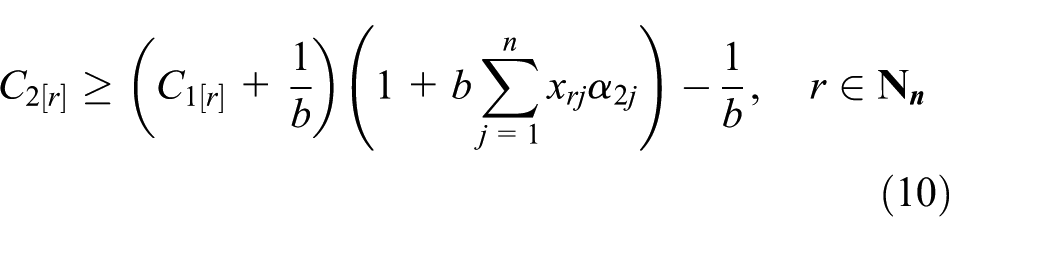

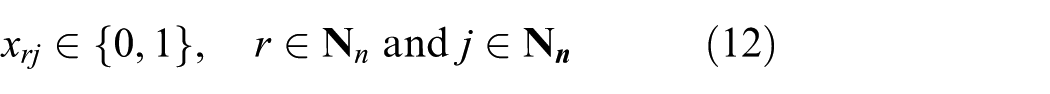

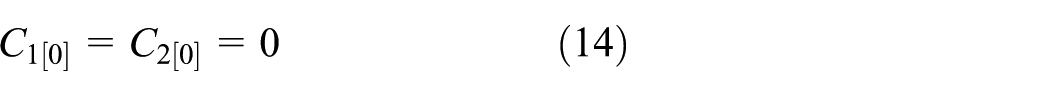
Objective function (6) is to minimize the total completion time of all the jobs. Constraints (7) and (8) ensure that one position in a processing sequence of the jobs can be occupied by only one job, and one job can be scheduled at only one position, respectively. Constraint (9) means that for an optimal processing sequence of jobs, machine M1 cannot be interrupted. Constraints (10) and (11) establish the relationship between the completion time of job Jj at machines M1 and M2. They make sure that the starting time of the jth job to be processed by M2 is greater than or equal to the completion time of the jth job processed by M1 and the completion time of (j − 1)th job processed by machine M2. Constraint (12) confirms the boundary of the decision variables. Constraint (13) confirms that the completion time of each job is greater than zero. Constraint (14) means that the time when M1 and M2 can start to work is zero. Thus, every job is available at t0 = 0. In this way, an MIP model is formulated. However, the computation for solving this problem is exponential with the number of the integer variables in the model. Therefore, it is very difficult to solve the MIP model for the addressed problem when the problem size is large.
Solution method
VNS
Since the time taken to solve the MIP model for F2|pij = αij(1 +bt), sij = δij(1 +bt)|ΣC2j is exponential with the number of binary variables it is inefficient to apply an exact solution method to obtain an optimal. Therefore, an efficient heuristic approach is preferred to find an optimal or near-optimal solution. VNS algorithm is such a kind of heuristic algorithm. It is a metaheuristic algorithm which can improve the local search by systematically changing the neighborhood structures such that a locally optimal solution can be avoided. The basic scheme of VNS can be found in Mladenovic and Hansen, 28 and a good survey is given in the literature.29–31 It has been proved to be a simple and efficient method for solving combinatorial optimization problems. Thus, this work adopts VNS to solve the scheduling problem of a two-machine flow shop with both the jobs and setup time being deteriorated.
Given a schedule π, let Ψk, k ∈ {1, 2, …, K}, denote a neighborhood structure and Ψk(π) be a set of schedules obtained using Ψk based on π. Therefore, Ψk is a scheduling policy for finding better schedules by starting from π. The general VNS can be found in Mladenovic and Hansen 28 as presented in Algorithm 1.
Based on the scheme of VNS obtained by Algorithm 1, a detailed VNS algorithm can be developed to solve the scheduling problem F2|pij = αij(1 +bt), sij = δij(1 +bt)|ΣC2j. To develop a complete VNS algorithm, one needs to determine the construction of the solution, generate an initial solution, and determine the neighborhood structures. In this work, we use the job processing sequence to represent a solution denoted by π = {π1, …, πk, …, πn}, where πk is the job that is scheduled to be processed in the kth position. Since the VNS is a metaheuristics whose performance is heavily dependent on the initial solution, it is necessary to have a good initial solution. Since the VNS is designed for large-sized problem, we need a computationally efficient method to find a good initial solution. A heuristics is useful. Let


The main idea of this algorithm is to make sure that the make-span for completing these jobs to be short since our objective is to minimize the total completion time. By Algorithm 2, an initial schedule is found. Then, we need to design the neighborhood structures to search for an optimal or near-optimal schedule. In Kirlik and Oguz, 30 four types of neighborhood structures are given for single-machine scheduling problem with total weighted tardiness minimization as objective, and they are shown to be effective. Thus, based on them, four similar neighborhood structures are developed for the problem addressed here. They are denoted as Ψ1, Ψ2, Ψ3, and Ψ4 and presented as follows.
Let u and v denote the uth and vth positions in a schedule and assume that v > u. Then, neighborhood structure Ψ1 operates as follows: the job at Position u in a schedule is taken away and inserted into Position v. By doing so, the jobs in Position k, k ∈ {u+ 1, …, v}, are shifted one position forward along the initial solution π. This can be illustrated by an example as shown in Figure 4. For this example, the initial schedule is π = [5 7 2 8 1 4 6 3 9] and u = 3 and v = 7. By Ψ1, Job 2 at Position u = 3 is removed and inserted into Position v = 7, leading to that the jobs at Position k, k ∈ {4, 5, 6, 7}, are shifted one position forward such that a new schedule π′ = [5 7 8 1 4 6 2 3 9] is obtained. We define Insert (π, u, v) as an algorithm for performing Ψ1 as follows:


An example of insert operation.
Neighborhood structure Ψ2 is used to swap two jobs at Positions u and v in π. An example of a swap operation is shown in Figure 5. The initial schedule π = [5 7 2 8 1 4 6 3 9] and u = 3 and v = 7. Then, by swap operation, a new solution π′ = [5 7 6 8 1 4 2 3 9] is obtained. We use an algorithm to define Swap (π, u, v) for Ψ2 as follows:

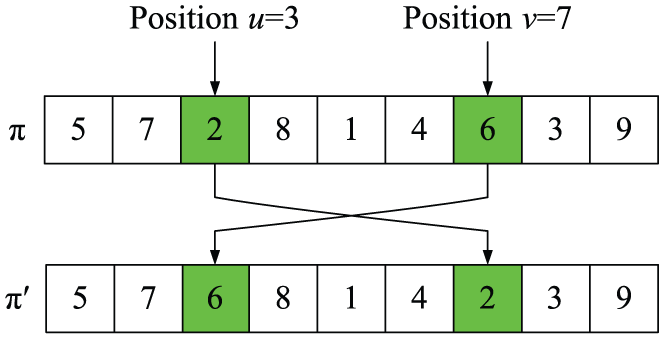
An example of swap operation.
We define two adjacent jobs in a schedule π as a job block. For neighborhood structure Ψ3, we randomly select two Positions u and v in a schedule π such that u+ 1 < v − 1. These two jobs form a job block denoted as block (πu, πu+1). Then, the block is inserted into Position (v − 1). Such an operation is 2-optinset operation and is illustrated in Figure 6, where π = [5 7 2 8 1 4 6 3 9], u = 3, and v = 7. The block (π3, π4) = (Job 2, Job 8) is then inserted into Position 6, leading to a new solution π′ = [5 7 1 4 6 2 8 3 9]. We use an algorithm to define 2-optinsert (π, u, v) for Ψ3 as follows:

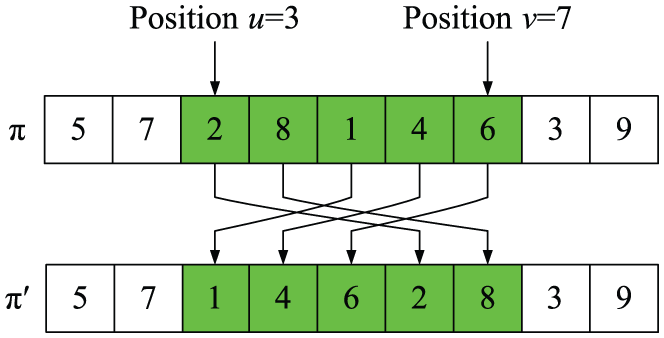
An example of 2-optinsert operation.
For neighborhood structure Ψ4, two Positions u and v in a schedule π are selected such that |v − u| ≥ 3 to form two job blocks (πu, πu+1) and (πv, πv+1). Then, the positions of job blocks (πu, πu+1) and (πv, πv+1) are swapped. Such an operation is called a 2-optswap operation and is illustrated in Figure 7, where π = [5 7 2 8 1 4 6 3 9], u = 3, and v = 6, and job blocks (π3, π4) = (Job 2, Job 8) and (π6, π7) = (Job 4, Job 6) are formed. Then, they are 2-optswapped to obtain π′ = [5 7 4 6 1 2 8 3 9]. We use an algorithm to define 2-optswap (π, u, v) for Ψ4 as follows:


An example of 2-optswap operation.
Up to now, four neighborhood structures have been proposed. Then, with Algorithm 2 and Ψ1−Ψ4, we present the detailed VNS algorithm to find an optimal or near-optimal schedule for problem F2|pij = αij(1 +bt), sij = δij(1 +bt)|ΣC2j. This algorithm is given as follows:

Lower bounds
It is well known that effective lower bounds can help to evaluate the effectiveness and efficiency of a heuristic algorithm. This work develops two methods to calculate the lower bound. The main idea to obtain the lower bound is to calculate the workloads on the two machines, respectively. Based on this idea, we analyze the lower bounds as follows. Suppose that (
Theorem 1
For any job Ji, if
Proof
With the assumption that
In Theorem 1, due to
Theorem 2
For any job Ji, if
Proof
Based on Theorem 1, with the assumption that
In Theorem 2, due to

Numerical results
To evaluate the performance of Algorithms 2 and 7, computational experiments are carried out. Algorithms 2 and 7 are coded in C and run on a Pentium III 2.20-GHz personal computer (PC) with 2.00-GB RAM. The MIP was coded in software LINGO 11 solver on the same computer. The considered scheduling problem (F2|pij = αij(1 +bt), sij = δij(1 +bt)|ΣC2j) can be solved optimally by the MIP when the number of jobs is <20, but for a medium- or large-sized problems, an exactly optimal schedule cannot be found within a reasonable computational time using the MIP. As a metaheuristic algorithm, the proposed VNS may not achieve a global optimum. Therefore, three sets of experiments are conducted in this article. For the first experiment, we compare the VNS with MIP for the considered scheduling problem with different sizes (n = 10, 20) to evaluate the effectiveness and efficiency of the VNS. For the second experiment, we compare the VNS with lower bound when the problem size is medium or large. For the third experiment, we evaluate the improvement made by the VNS with respect to the initial schedule obtained by the greedy algorithm.
Parameter setting
All the data were randomly generated from the discrete uniform distributions but with different parameters. In the second experiment, nine different sizes of the jobs n = (10, 15, 20, 25, 30, 35, 40, 45, 50) are used to test the proposed method, while five different sizes of the jobs n = (10, 20, 30, 40, 50) are used to do so in the third experiment. For each size of the jobs, the normal processing time for M1 and M2 is generated from the discrete uniform distributions [1, 10], and the normal setup time for M1 and M2 is generated from the discrete uniform distributions [1, 4]. For all the tests, t0 = 0 is set, and the deterioration index are set to be three different values, that is, b = 0.1, 2, and 5 for small, medium, and large, respectively. We repeat 10 times for each approach to obtain the average values for all the tests.
It is vitally important to set the parameters since the performance of the VNS is usually sensitive to them. In this article, for the proposed VNS, we have only one parameter: loopmax. In order to determinate loopmax for the VNS, we examine the problem with its size being 20 (n = 20) since we can analyze the effect of loopmax by comparing with the optimal solution obtained via the MIP. The performance of the VNS can be measured by the percentage of the relative percentage deviation (RPD) from the obtained solution to the optimal solution. The RPD is given as
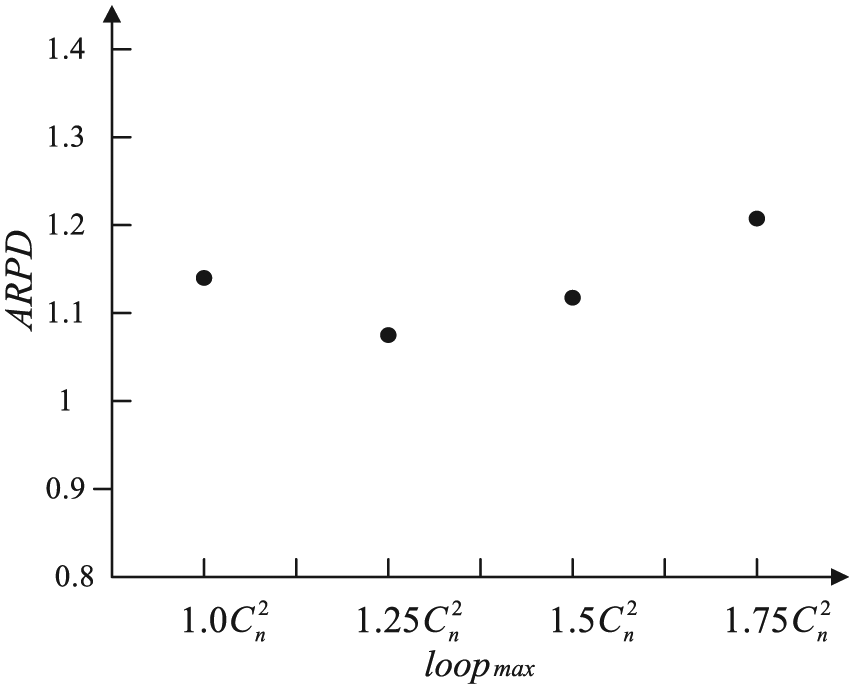
The ARPD at different considered levels of parameter loopmax.
Experiment 1
In this experiment, we select two different sizes of jobs n = (10, 20) to compare the VNS with MIP, since they can be solved by LINGO 11 within reasonable computational time (3600 s). For each experiment, the VNS repeats 10 times to obtain the maximum and minimum values of the objective function. The deviations are used to show the performance comparison between VNS and MIP, and it is formulated as Dev. = (The minimum value of the objective obtained by VNS) − (The value of the objective obtained by MIP).
The computational time of the MIP and the deviations are shown in Table 1. It can be observed that for all the cases, Dev. is zero, when the job size is 10 and 20. This experiment shows that the VNS can find the optimal solution when the job size is small (n ≤ 20). Most of the maximum values are greater than the minimum values except that they are equal for one case as shown by bold values since the scheduling problem with deteriorations jobs is a combinatorial optimization problem and has a strong relationship with the starting processing time for every job. When the size is 10 and 20, almost all the tests can be solved by the MIP within reasonable computational time (287 s), except that for two tests, it takes 3637 and 1828 s as shown with bold values in Table 1, respectively. The shortest time is 2 s only. The average time taken for solving these problems with job sizes 10 and 20 is 30.65 and 54.7 s, without considering the two worst cases with the computational time 3637 and 1828 s, respectively. As the size increases, it would be more complex and difficult for the MIP to solve.
Comparative results for the solution of VNS and MIP with n = 10 and n = 20.

MIP: mixed integer programming; VNS: variable neighborhood search.
Experiment 2
To investigate the effectiveness of the proposed VNS for such problems, it is compared with the lower bound. In this experiment, the test problem size is n = 10, 15, 20, 25, 30, 35, 40, 45, and 50, respectively. For each test, it repeats 10 times to obtain the mean solution, and the mean absolute percentage of deviation is defined as follows:
Table 2 shows the performance of the proposed VNS, where the values of %D are presented. It can be observed that the average deviation percentages are zero for the small-sized problem (n ≤ 20). Also, the VNS can achieve the optimal solution for small-sized problems, which is consistent with the results obtained in Experiment 1. The average deviation percentages are <3% for almost all the test problems. We note that the average deviation percentage becomes larger when the deterioration rate index is larger. This is because the large deterioration rate index can make the actual processing time and setup time become much longer. The experiment shows that the VNS can be used to solve the addressed scheduling problem effectively, especially when the problem size is large. In summary, it follows from Table 2 that a near-optimal or optimal schedule can be found by the proposed VNS even though deterioration rate index is relevantly large. In other words, the proposed VNS method is applicable and effective to the addressed problem.
Comparative results for the solution of VNS with lower bound.

Experiment 3
To investigate the performance of the proposed VNS, it is compared with greedy algorithm in order to evaluate the improvements made by the VNS. In this experiment, the test problem size is n = 10, 20, 30, 40, and 50, respectively. For each test, the VNS runs 10 times to obtain an average solution value. We define the percentage improvement (PIVG) as
It follows from Experiment 1 that the optimal solution can be found by MIP within reasonable computational time. However, when the problem size is >20 (n > 20), it may not be able to find an optimal solution by the MIP within a reasonable computational time (3600 s). For such cases, VNS algorithm is used to obtain an optimal or near-optimal solution. As shown in Table 3, such a solution can be obtained within 3 s even if the number of jobs is 50. Therefore, the VNS algorithm is computationally efficient.
Improvements by performing VNS (in seconds).
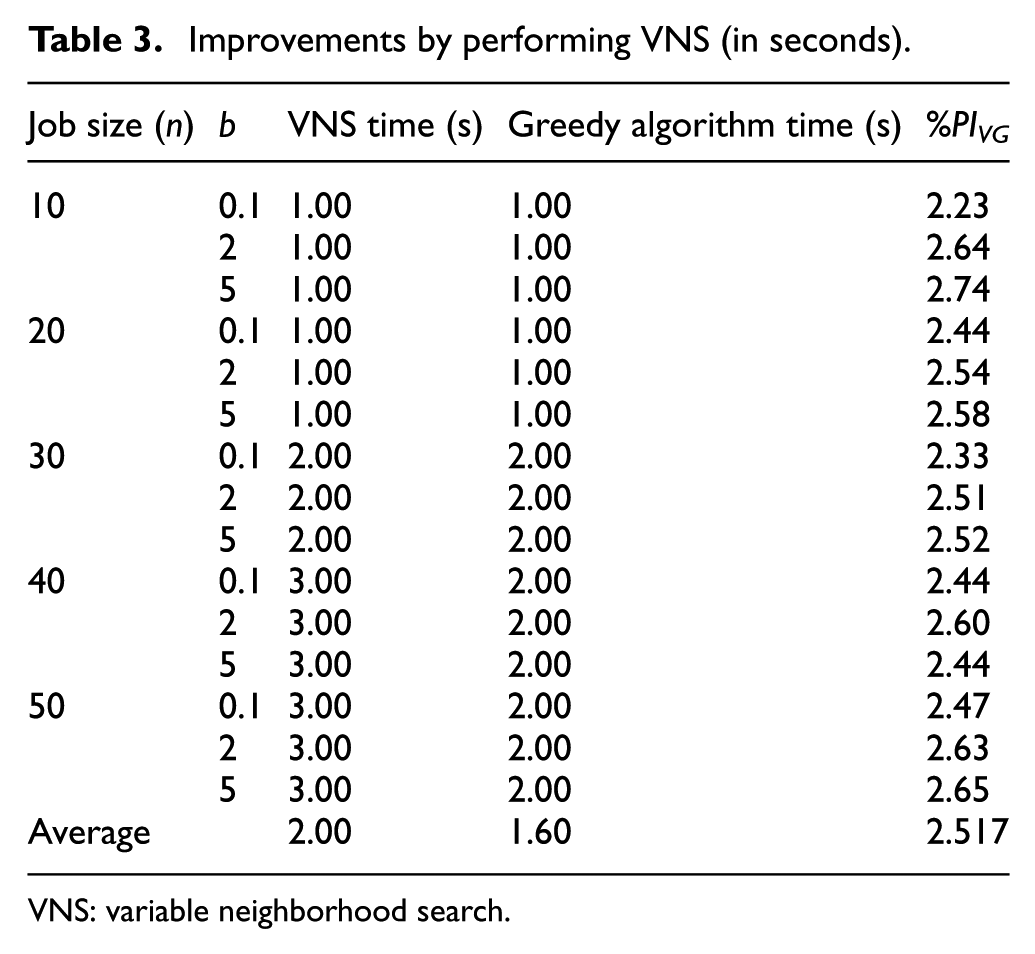
VNS: variable neighborhood search.
It can be seen from Table 3 that the values of PIVG are increasing as the deterioration rate index of jobs increases for different job sizes except n = 40. Also, we note that for all the tests, the VNS makes a significant improvement with respect to the initial schedule found by the greedy algorithm, especially when b is large. This can be explained as that the small value of b leads to a shorter make-span for this considered problem, and it implies that the greedy algorithm may obtain a better solution when the value of b is small. All in all, the VNS can be used to solve the addressed scheduling problem effectively and efficiently, and it can also make further improvement to obtain a near-optimal or optimal solution compared with the greedy algorithm. Note that the proposed VNS is a metaheuristics other than a simple dispatching rule. Thus, from Table 3, we can conclude that the proposed VNS outperforms a simple heuristic method.
Conclusion
In some production processes, jobs may be subject to deterioration that should be taken into account in scheduling such systems. The scheduling problem of a two-machine flow shop with time-dependent deteriorating jobs and setup time is studied in this article. Although significant studies on scheduling problem of scheduling a two-machine flow shop with time-dependent deteriorating jobs have been done, the existing studies assume that job setup time and its deterioration can be neglected or integrated into the processing time. However, by doing so, the performance of the obtained schedule is not good enough. As far as the authors know, there is no research report on scheduling a two-machine flow shop with both time-dependent deteriorating jobs and setup time. To solve such a challenging problem, the problem is formulated as a MIP model. For small-sized problem, with this model, an optimal schedule can be found using a commercial software tool. For medium- and large-sized problem, a VNS is proposed to find an optimal or near-optimal solution. Since the performance of a VNS is sensitive to the initial solution, a greedy algorithm is developed to find good initial solution for the VNS to improve the performance of the proposed method. Also, lower bounds are presented for performance evaluation. Numerical experiments with different sizes are used to test performance of the proposed method. Results show that using the proposed VNS, an optimal or near-optimal solution can be obtained. Also, the proposed VNS is computationally efficient and outperforms a simple heuristic method. Thus, the proposed VNS is applicable to practical problems.
The existing studies show that performance can be improved using group technology. It is our future work to study how group technology can be used to solve the scheduling problem addressed in this article.
Footnotes
Academic Editor: ZhiWu Li
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by Science and Technology Development Fund (FDCT) of Macau under Grants 065/2013/A2 and 102/2013/A, National Natural Science Foundation of China under Grant 61273036.