
Abstract
Rapid and accurate lifetime prediction of critical components in a system is important to maintaining the system’s reliable operation. To this end, many lifetime prediction methods have been developed to handle various failure-related data collected in different situations. Among these methods, machine learning and Bayesian updating are the most popular ones. In this article, a Bayesian least-squares support vector machine method that combines least-squares support vector machine with Bayesian inference is developed for predicting the remaining useful life of a microwave component. A degradation model describing the change in the component’s power gain over time is developed, and the point and interval remaining useful life estimates are obtained considering a predefined failure threshold. In our case study, the radial basis function neural network approach is also implemented for comparison purposes. The results indicate that the Bayesian least-squares support vector machine method is more precise and stable in predicting the remaining useful life of this type of components.
Keywords
Introduction
With substantial technology advancement on product design and manufacturing, products with long lifetime and high reliability have been developed and widely used in the areas of aeronautics, astronautics, and communication. As a crucial constituent aspect of prognostics and health management (PHM) activities, accurate lifetime prediction for critical components is considered the key to implementing timely maintenance for reliable and safe operations.1–3 In many situations, such components exhibit gradual degradation for which some performance measures are getting worse and worse during operation and eventually become unacceptable. By analyzing and modeling the performance degradation data, general degradation laws can be obtained and the remaining useful life (RUL) of individual components can be predicted using certain prediction methods. 4
Commonly used prediction methods may fall into three main categories: model-based, data-driven, and hybrid methods. 5 A model-based method requires a clear understanding of the underlying degradation mechanism(s) which, however, may be unavailable for many complex products. However, a data-driven method can be used to directly model the degradation data without the comprehensive understanding of degradation mechanisms. As a result, various data-driven methods based on machine-learning algorithms, such as neural network and support vector machine (SVM), have been applied in the PHM community.6,7 However, these methods have more or less inherent drawbacks. Taking neural networks as an example, the method is essentially a black-box approach, which fails to explicitly explain the input–output relationship; furthermore, issues like overfitting, curse of dimensionality, and premature convergence are difficult to overcome when using these methods. In these aspects, the SVM method offers some advantages. SVM is a machine-learning method with a higher generalization capability and is able to effectively resolve the curse of dimensionality and local optimal problems. 8 Consequently, many SVM-based methods have been used in predicting the RUL of some key components.9–13 As an improved algorithm, the least-squares support vector machine (LS-SVM) approach adopts equality constraints instead of inequality ones in SVM, takes a linear least-squares system as its loss function, and chooses the l2-norm of error to characterize the empirical risk. In this way, the corresponding quadratic optimization problem is transformed into a system of linear equations, which increases the convergence rate to some extent. 14
Extensive research has been conducted on the theory of LS-SVM and on its applications in fault diagnosis and lifetime prediction. Khawaja 15 used the LS-SVM method in fault diagnosis and prognosis. The effectiveness and feasibility of the method was verified through an analysis on fatigue crack extension of planetary gear plate. Wang et al. 16 established a forecasting model for engine life on wing based on LS-SVM. Compared to several commonly used algorithms, the model performed well in terms of both generalization capability and forecasting precision. It is worth pointing out that in both Khawaja 15 and Wang et al., 16 Bayesian inference was utilized to find the best model parameters of LS-SVM. Kamari et al. 17 proposed a mathematical approach to establish a reliable model for predicting the compressibility factor of sour and natural gas. A coupled simulated annealing optimization tool was used with LS-SVM. Ismail et al. 18 employed self-organizing maps least-squares support vector machine (SOM-LS-SVM) that combines the LS-SVM and SOM for time-series forecasting. Two well-known data sets, the Wolf yearly sunspot data and the data of monthly unemployed young women, were used to demonstrate the accuracy of the proposed method in terms of mean average error (MAE) and root mean square error (RMSE) indices. Furthermore, the LS-SVM method was also successfully applied in the medical field. Polat and Güneş 19 focused on breast cancer diagnosis using LS-SVM, and the classification accuracy is 98.53%.
In summary, the LS-SVM method has been applied in many fields and has shown desirable results. However, Bayesian inference has the capability of providing interval prediction of product lifetime using both prior belief and actual observations. It would be promising and quite valuable to consider Bayesian LS-SVM that combines the two methods for both point and interval RUL predictions in PHM. This article employs this method in RUL prediction for a microwave component and verifies its effectiveness by comparing the result with the radial basis function (RBF) neural network approach.
The remainder of this article is organized as follows. Section “Bayesian LS-SVM theory” introduces LS-SVM and Bayesian inference. Section “Degradation modeling and RUL prediction using Bayesian LS-SVM” presents the integration of Bayesian inference and LS-SVM for RUL estimation of an individual unit. In section “Case study and analysis,” a case study is provided to demonstrate the use of the proposed approach in RUL prediction for a microwave component. Finally, section “Conslusion” concludes this article and provides future research directions.
Bayesian LS-SVM theory
LS-SVM regression theory
The key to LS-SVM prediction is to utilize the map function obtained from data modeling based on LS-SVM regression. Next, the LS-SVM regression theory is briefly introduced. 14
We define the training data set in a regression problem as

where
The corresponding optimization problem can be expressed as

where EW = (1/2)
To solve this optimization problem with N equality constraints, the Lagrange multiplier method can be employed. By introducing the Lagrange multipliers αi, i = 1, …, N, the resulting Lagrange function can be expressed as

By setting each of the corresponding first partial derivatives of the Lagrange function equal to zero, we have

After eliminating
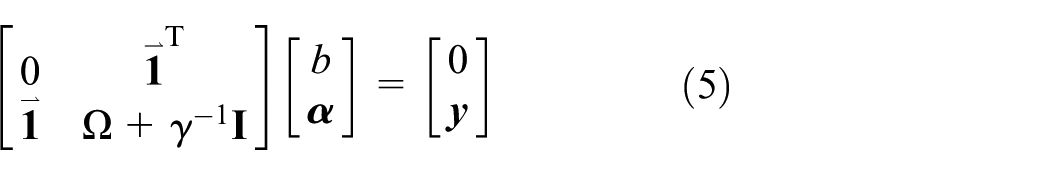
where
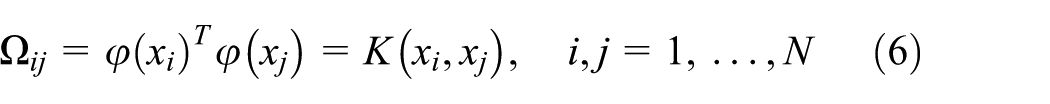
Finally, the LS-SVM regression model used for prediction can be expressed as
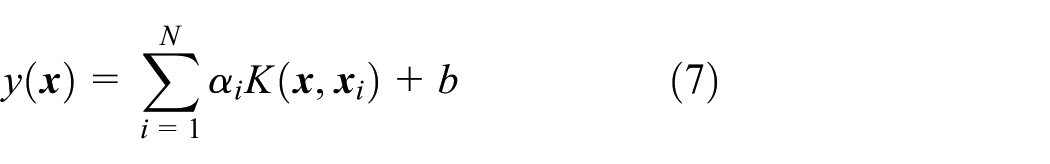
where αi is the weight of the ith vector and K(
Bayesian inference theory
In practice, cross validation is often adopted to determine the model structure H (LS-SVM with kernel function K) and the regularization parameter γ of LS-SVM regression model. However, the cross-validation method needs to be performed repeatedly, which requires significant computational time. To overcome the challenge, the Bayesian framework is employed to the LS-SVM regression to obtain the kernel function parameter, regularization parameter γ, and model parameters
In machine learning, the RBF kernel, or Gaussian kernel, is a popular kernel function used in various kernel-based learning algorithms. The RBF kernel in a general form is

where σ is the kernel parameter. The RBF kernel is selected in this article for the following reasons:
Large deviations will not appear when solving a linearly inseparable problem.
It possesses universality for its applicability for samples that follow any kinds of distributions as long as its parameters are reasonably determined.
In order to carry out interval prediction using the LS-SVM model, we assume that model parameter

where
Then, the objective function (2) can be reformulated as

where µ and ζ are also called as regularization parameters, and γ = ζ/µ.
20
Equation (10) can make the variances of
As a result, the LS-SVM regression model H has the following parameters that need to be inferred from the training data set S:
Level 1. Inference of model parameters
Given the training data set S and regularization parameters µ and ζ of model H, the estimates, denoted by

where p(S |
Level 2. Inference of regularization parameters µ and ζ
The estimates of regularization parameters µ and ζ, denoted by µMP and ζMP, are obtained from the training data set S by applying Bayes’ rule at the second level

where a flat, non-informative prior is assumed for µ and ζ. The probability p(S | µ, ζ, H) is the same as in equation (11).
Level 3. Inference of kernel parameter σ
It is easy to see that

Then, the optimal value of RBF kernel parameter σ can be found by maximizing the model evidence p(S|H).
It is worth pointing out that at each level of the Bayesian framework, one has

and the likelihood at a certain level equals the evidence at the previous level. In this way, by gradually integrating out the parameters at different levels, the subsequent levels are linked to each other. Interested readers can refer to Suykens and colleagues14,20 for more details.
Interval estimate of Bayesian LS-SVM regression
After finding all the model parameters, the interval prediction of LS-SVM regression can be performed. By taking expectation on both sides of equation (1), the point estimate of LS-SVM regression model can be obtained as

where
Let yN + 1 be the observed value at time N + 1; then, it can be expressed as
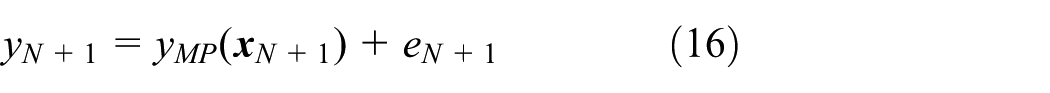
where eN + 1 is the error term at time N + 1, which is assumed to follow the normal distribution with zero mean and variance 1/ζMP. Then, the mean and variance of yN + 1 can be obtained as


According to Suykens et al., 14 one obtains
where QD = (µI + DG)−1 − µ−1I; θ(x) = [K(x, x1), …, K(x, xN)]; Ω
kl
= K(xk, xl) = ϕ(xk)Tϕ(xl), where k, l = 1, 2, …, N; 1
v
= [1, 1, …, 1]
v
;
where DG = diag([λG, 1, …, [λG, Neff]) and UG = [(vG, 1ΩvG, 1)1/2vG, 1, …, (vG, NeffΩvG, Neff)1/2vG, Neff].
Since the model parameters

As a result, the 95% confidence interval of yN + 1 can be expressed as

Degradation modeling and RUL prediction using Bayesian LS-SVM
Basic architecture
Figure 1 illustrates the basic flow of using the Bayesian LS-SVM method for performance degradation modeling and lifetime prediction. First, training data and the setting algorithm parameters are used as the input to the LS-SVM framework, and then modeling begins using the LS-SVM learning algorithm on the training data. Multiple one-step predictions that constitute a degradation curve can be obtained based on this model. Meanwhile, Bayesian inference is applied to find the optimal model parameters and obtain the error bars of LS-SVM regression model. Ultimately, both point and interval estimates of RUL are obtained considering the pre-specified failure threshold.

Basic architecture of RUL prediction based on Bayesian LS-SVM.
Lifetime prediction based on Bayesian LS-SVM
In the course of implementation, an iterative algorithm is introduced: training data set will be continuously updated after each one-step prediction. Specifically, each predicted value will be added into the original training set, and the updated set will be used in training to predict the value at the next point in time. The detailed procedure can be described as follows.
Let (

Then, the one-step prediction model can be expressed as

Subsequently, this predicted value can be added into the original training set. Similarly, the regression model used to predict the (r + n)th value can be expressed as
where
Implementation of RUL prediction
The RUL of an asset or system is defined as the length from the current time to the end of its useful life. 7 The word “useful” in RUL usually implies an economic aspect which can differ significantly from the technical remaining lifetime of an asset. The technical lifetime of an industrial machine is often longer than its economic life time. 21 Obviously, the precise definition of the useful life depends on the context and operational characteristics.
It is important to predict the RUL of a system, because it has an important role in maintenance planning, spare parts provision, operational performance, and profitability. 21
The procedure of RUL prediction can be illustrated by Figure 2 and described as follows:
Collect training data by monitoring the asset’s performance state (often characterized by one or more key index parameters).
Train LS-SVM using the training data with a performance degradation trend being the final output; apply Bayesian inference to obtain a confidence interval while taking the uncertainties resulting from the model itself and prior information of model parameters.
Calculate both the point and interval estimates considering the given failure threshold.
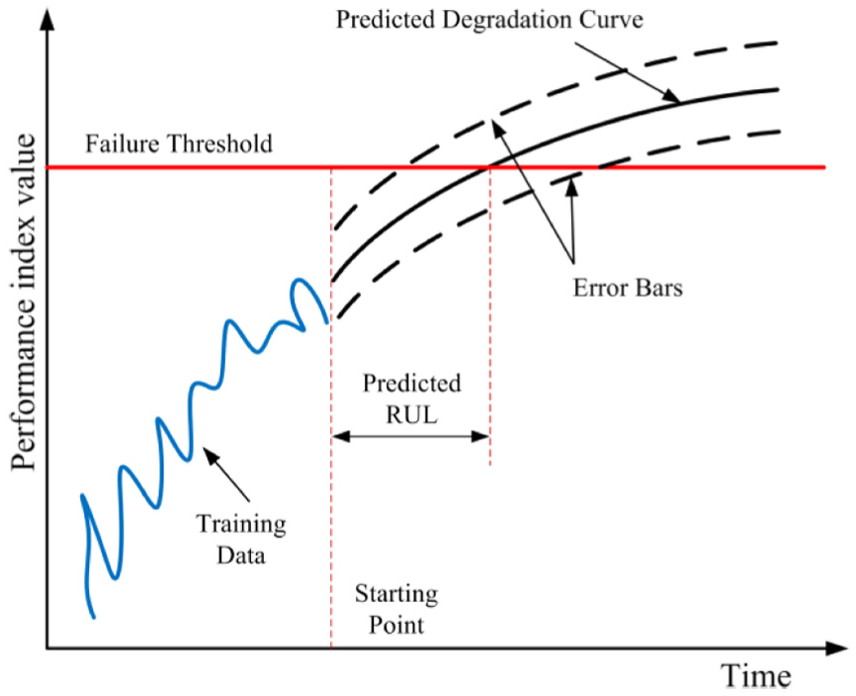
Principle of RUL prediction.
Case study and analysis
Description of data
In this section, a study on a microwave component’s degradation data is conducted to demonstrate the effectiveness of the proposed method. An important performance measure of the microwave component in this case study is the component’s power gain, which measures the ability of the component to increase the power of a signal from the input to the output. In this experiment, to model the power gain degradation of microwave component, one measurement was taken each day and a total of 361 data points were collected. From Figure 3, one can see that the degradation process exhibits a linear trend with significant fluctuation in the middle portion.

Power gain’s degradation data of a microwave component.
Analysis of prediction results
In order to verify the prediction accuracy of LS-SVM, the RBF neural network (RBFNN) is used in comparison. To be more specific, the original training data set was divided into two parts. The first 200 data points were used to train LS-SVM and RBFNN, respectively, to get the predicted values of the latter 161 data points. By comparing the predicted values and real data, we can compare the prediction accuracy of these two methods.
The flowchart of LS-SVM for degradation modeling is shown in Figure 4, where r (200 in this study) and n represent the number of training data points and total number of data points, 22 respectively.

Flowchart of Bayesian LS-SVM for degradation modeling.
Other parameters used in the procedure are as follows:
For LS-SVM, the regularization parameter is γ = 212 and the kernel function parameter is σ2 = 19;
For RBFNN, the expansion rate is spread = 100 and the target of MSE is set to be goal = 0.01.
The graphical outputs of these two methods are shown in Figure 5.

Graphical outputs of (a) LS-SVM and (b) RBFNN.
To make a quantitative comparison on prediction accuracy of the two methods, three accuracy indices, MAE, mean square error (MSE), and RMSE, are considered

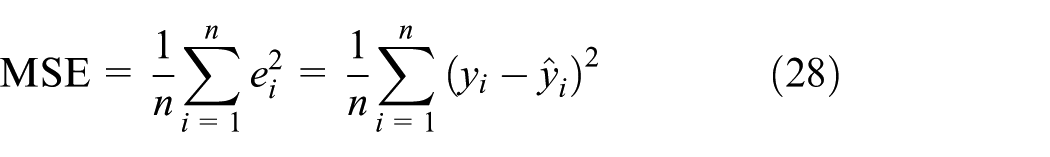
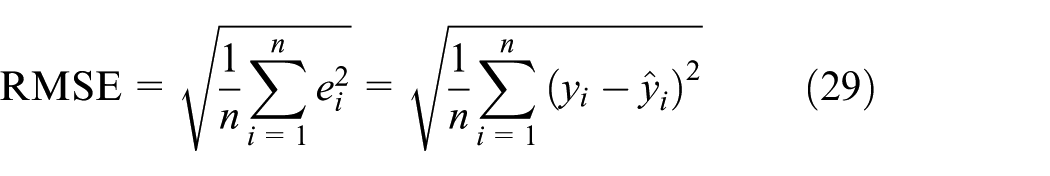
where
Comparison on precision using 200 training data.

MAE: mean average error; MSE: mean square error; RMSE: root mean square error; LS-SVM: least-squares support vector machine; RBFNN: radial basis function neural network.
Then, the value of r is chosen equidistantly between 100 and 240 with the interval of 20. The corresponding results are shown in Table 2 and Figure 6.
Comparison on precision using different amounts of training data.

LS-SVM: least-squares support vector machine; RBFNN: radial basis function neural network; MAE: mean average error; MSE: mean square error.

Accuracy comparison on (a) MAE and (b) MSE.
From the results, one can see that the LS-SVM method outperforms the RBFNN method under various sizes of training data. Particularly, the RBFNN method suffers from data fluctuation (see the results when the sizes of training data are 140, 160, and 180). In contrast, the LS-SVM method is much more robust and stable.
RUL prediction using Bayesian LS-SVM
Figure 7 shows the flowchart for implementing the Bayesian LS-SVM for RUL prediction. Compared to the flowchart given in Figure 4, the main differences are as follows: (1) the original amount of training data equals the total amount of data, that is, r = n, and (2) the confidence interval is given based on Bayesian inference at each step, while the modeling principle of these two processes keeps the same.
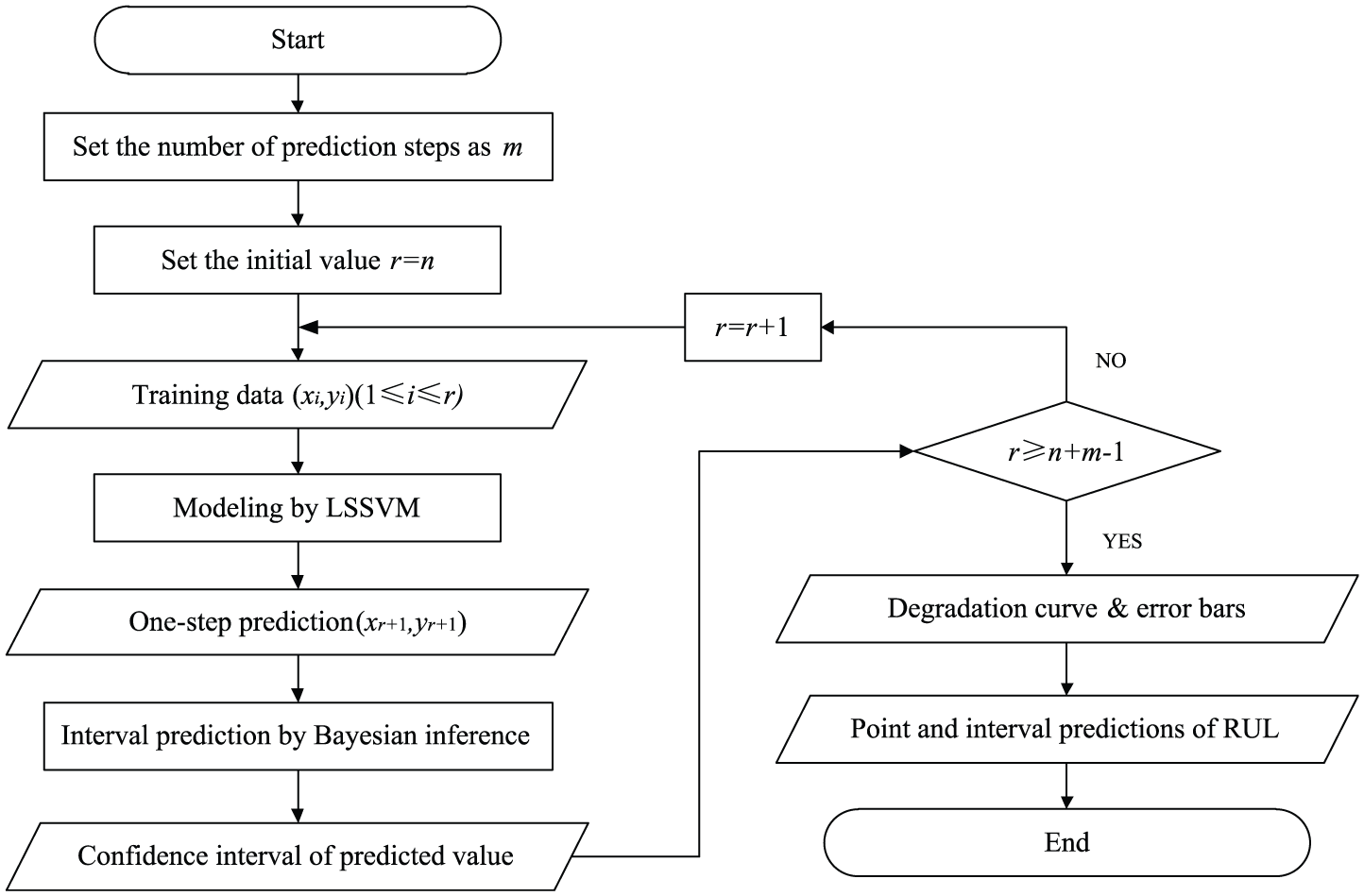
Flowchart of Bayesian LS-SVM for RUL prediction.
The parameters used in the algorithm are γ = 1000 and σ2 = 500, and the failure threshold is set to be 18. The corresponding results and its partial enlarged view are shown in Figure 8. With the starting point of X = 361, the point estimate of RUL is 671 days and the 95% interval prediction is [649, 693] days.

RUL prediction curve and its 95% confidence bands of microwave component: (a) RUL prediction results and (b) partial enlarged view.
Conclusion
This article provides a basic architecture for RUL prediction of a certain microwave component. The problem of LS-SVM regression under Bayesian framework with three levels of inference is analyzed, and the regression model is obtained from the past observations. Then, the point and interval estimation using the LS-SVM regression model is derived. Finally, by modeling the degradation of component’s power gain via the Bayesian LS-SVM method, both point and interval estimates of RUL are obtained. The accuracy and stability of this method are also verified by comparing the results with those of the RBF neural network.
In practice, the selection of model parameters will directly affect the accuracy of the model. Therefore, how to select the optimal model parameters is a crucial future research direction. Furthermore, selecting appropriate kernel functions for LS-SVM modeling can also be studied.
Footnotes
Academic Editor: Yongming Liu
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the National Natural Science Foundation of China (grant nos 61603018 and 61104182) and the China Scholarship Council. The work of H. Liao was supported by the US National Science Foundation under grant nos CMMI-1238301 and CMMI-1238304.