
Abstract
In this article, a novel artificial neural network integrating feed-forward back-propagation neural network with Gaussian kernel function is proposed for the prediction of compressor performance map. To demonstrate the potential capability of the proposed approach for the typical interpolated and extrapolated predictions, other two classical data-driven modeling methods including feed-forward back-propagation neural network and support vector machine are compared. An assessment is performed and discussed on the sensitivity of different models to the number of training samples (48 training samples, 32 training samples, and 18 training samples). All the results indicate that the proposed neural network in this article has superior prediction performance to the existing feed-forward back-propagation neural network and support vector machine, especially for the extrapolation with small samples. Furthermore, this study can be utilized in refining the existing performance-based modeling for improved simulation analysis, condition monitoring, and fault diagnosis of gas turbine compressor.
Introduction
Compressor behavior which can be represented by performance maps is the main concern for researchers to further understand and improve the design performance of any gas turbine. In the off-design phase, the quality of compressor performance maps is very important for the accuracy of gas turbine performance simulation and diagnostic models. In general, considering the complicated feature of compressor, many experimental studies at various operating and environmental conditions are usually carried out to obtain the performance map of compressor. However, there are only very few experimental data in the full operational range because of the cost and venture of the compressor test. This means that the performance map of a compressor is illustrated as a distribution of discrete points. Besides, fluid flow analysis methodologies including stream line curvature (SLC) 1 method and computational fluid dynamics (CFD) approach 2 are also used to determine the compressor performance map. But the basic requirement of above two methodologies is that the geometry of the targeted compressor should be known. Therefore, there is a need to developing effective approach to determine the unknown performance parameters of compressor at desired positions.
In the past few decades, various types of prediction methods for compressor performance map have been developed based on the different applications. Moraal and Kolmanovsky 3 reviewed the curve fitting methods for centrifugal compressor and turbine characteristics in detail. To solve the problem of lacking experimental data at lower or higher speed conductions, Kurzke 4 proposed an effective method named auxiliary coordinates (β lines). Sieros et al. 5 introduced a compressor mapping approach using analytical functions to describe the nonlinear relations between mass flow, pressure ratio, and efficiency. On the basis of Newton–Raphson method, Kim et al. 6 presented an improved level stacking approach to broaden the application scope of level stacking method. Considering the shape variance of compressor map curves, a new compressor map fitting and modeling method was developed by Tsoutsanis et al. 7 Besides, Kong et al. 8 and Li et al. 9 studied the compressor mapping approaches by means of the scaling and shifting technologies which could improve the fidelity and accuracy of gas turbine models. Although the above approaches have many advantages in the prediction of compressor performance map compromising the characteristic of experimental data and the physical process of compressor component, the nonlinear relationships between different key variable are still inexplicit up to now, which show that the computational accuracy and applicability of these approaches need to be further investigated.
As an effective data-based modeling method, artificial neural network (ANN) is widely used in many areas because of its ability of nonlinear processing and storing massive experimental knowledge. 10 Theoretically, ANN can approximate any nonlinear model and develop the relationships among input and output variables involved in a physical process without considering the underlying physical process. 11 Hence, ANN has become increasingly popular for predicting the performance map of compressor in the recent years. Considering the fast convergence characteristics and nonlinear mapping capability of feed-forward back-propagation neural network (BPNN), Feng et al. 12 applied BPNN to predict the characteristic map of compressor working in a low-speed condition. Yu et al. 13 constructed a three-layer BPNN to overcome the lack of information about stage-by-stage axial-compressor performance. The network was first trained by experiment data, and then its prediction results were regarded as experiment data in the second training. Ghorbanian and Gholamrezaei 14 investigated the applied capability of four kinds of ANN including general regression neural network (GRNN), rotated general regression neural network (RGRNN), radial basis function network (RBFN), and multilayer perceptron network (MLPN) in predicting the compressor performance map in detail. According to their study, it indicated that the RGRNN had the least mean error only for the prediction of interpolation, but MLPN was suggested to provide good prediction for interpolation as well as extrapolation. Besides, Sepehr et al. 15 predicted performance map of rotary vane compressor by BPNN. Their results demonstrated that the statistical performance of BPNN was better than that of nonlinear regression model. Although ANN has been verified to be a very effective method in interpolation prediction of compressor performance map, it is important to point out that a large number of samples are necessary to sufficiently train ANN to get highly prediction accuracy and calculation stability. In order to improve the predicting accuracy of compressor characteristic with small samples (experimental data), different kinds of improved methods have been developed. For example, Kong et al. 16 extrapolated compressor map curve data in the area of off-design by the method of genetic algorithms. Fei et al. 17 proposed a kernel partial least squares (KPLS) model to predict the operating parameters of a centrifugal compressor. Zhao et al. 18 presented a steady-state hybrid modeling of chillers using polynomial neural network compressor model. Tian et al. 19 applied a hybrid artificial neural network—partial least square (ANN-PLS) model to describe the thermodynamic performance of a scroll compressor.
Support vector machine (SVM) is a new machine-learning method in pattern recognition, condition monitoring, and fault diagnosis.20–22 One of the most important advantages of SVM is a good nonlinear mapping ability with small samples, which largely benefits from the combination of Vapnik–Chervonenki’s theory (VC-theory) and kernel method (kernel tricks). 23 Kernel method is a kind of universal technology which can transform the nonlinear problem into a linear problem through the nuclear space theory.24,25 Nonlinear vector in low-dimensional space is mapped into high-latitude space by nonlinear function, so the transformed vector in high-latitude space could be treated by linear method. The kernel method, as the core algorithm of SVM, is one of the most influential achievements in machine-learning community. 26 There is a member of kernel functions according to Mercer’s theorem of kernel function analysis, such as polynomial kernel function, sigmoid kernel function, and Gaussian kernel function. 27 Among these kernel function, Gaussian kernel function had a distinct advantage because of the stronger mapping capability and fewer arguments.28,29
In this study, a novel network combined BPNN with Gaussian kernel function is proposed to improve the predicting accuracy of compressor performance map. First, compressor performance map and the related problems are introduced. Then, structure and algorithm of the novel network are illustrated after introducing the algorithms of BPNN and SVM. Finally, prediction accuracy and stability of the network are explored when compared with that of BPNN and SVM in the case of a different number of training samples.
Problem description of compressor performance map
Compressor performance map
The characteristic of compressor in the form of Cartesian coordinate’s graph is usually defined as compressor performance map. General speaking, the operating characteristics of compressor can be determined only by two of the four parameters which are corrected speed


Figure 1 shows a performance map of multi-stage axial flow compressor, which only includes speed lines and aerodynamic stability line. Figure 1 is drawn based on experimental data. The original characteristic map of the multi-stage axial compressor, given by the equipment manufacturers, is obtained by compressor characteristic experiment. The coordinate values of six points at each speed line in the original map are extracted to fit the speed lines in Figure 1. In this way, the speed lines in the original characteristic map are reproduced. As shown in Figure 1, it can be seen that there are significance variance between different speed lines, especially at higher n. In other words, π is relative sensitive to the small changes in G with the increase in n. This drawback can cause that the common methods fail to model the compressor maps within a reasonable accuracy.
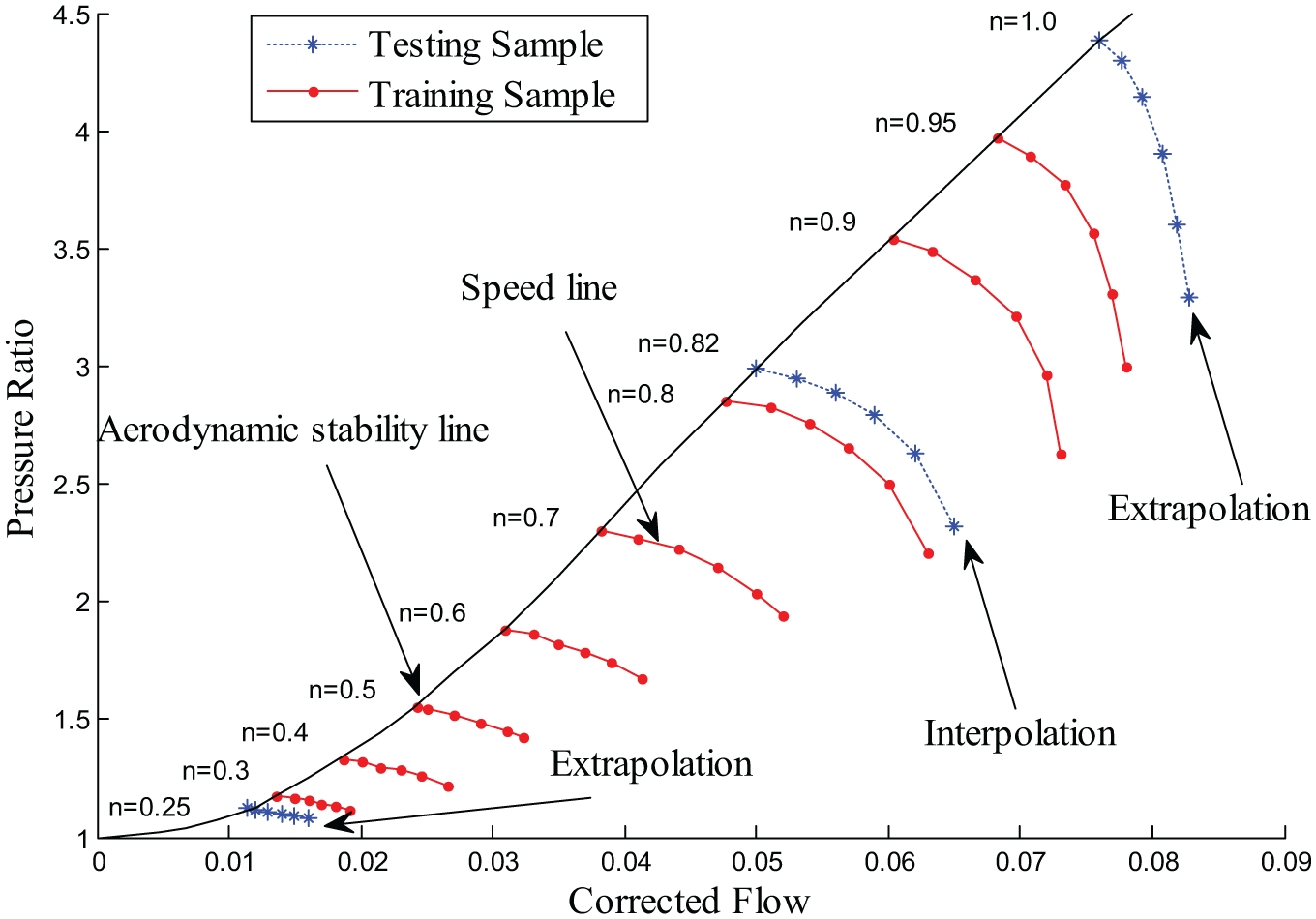
Compressor performance map.
Problem description of interpolation and extrapolation
As previously mentioned, limited experimental data can be obtained in the full operational range considering the cost and venture of compressor test, which means that most of the information (such as the interpolation and extrapolation of data near certain stable state, parameter characteristic of the compressor under start-up or shut-down conduction, and the surge margin of the compressor) need to be predicted. For the interpolated and extrapolated prediction of data, the essential problem is finding the general relation among the mentioned four key variables of compressor. However, the highly nonlinear characteristics of compressor performance are difficult to mathematical model using a small number of experimental data. Therefore, the prediction accuracies of conventional interpolation approaches for compressor performance map are usually unsatisfied. Besides, although ANN can effectively solve the interpolated prediction with higher accuracy, the extension of ANN to extrapolated prediction of compressor performance cure is still debuted and future verified. This is because the prediction accuracy of ANN directly depends on the trained knowledge. And the prediction model based on ANN only develops the potential data relationships among input and output variables, but the physical process is ignored. Therefore, how to utilize the obvious similarity feature between the borders upon speed lines and the nonlinear data analysis advantage of ANN technology to develop a new compressor map fitting and modeling method is significant.
Compared to the prediction of efficiency for compressor map, researches on the prediction of pressure ratio receive more attentions. Therefore, the former is beyond the scope of this study. In other words, the known or input information T is defined as

where i is the index of speed lines at which the experiment data are selected, so i = 1, 2, …; j is the index of samples selected at each speed line, and j = 1, 2, …;
The target or prediction information Y is determined as in equation (4)

where q is the total number of target sample.
Feed-forward neural network with Gaussian kernel function
BPNN
As one of the most representative networks of feed-forward neural network, BPNN is composed of simple elementary neuron. The basic principle of an elementary neuron is shown in Figure 2(a). The output of the neuron is expressed in equation (5)

where

Basic principle of BPNN: (a) basic neuron and (b) BPNN.
Figure 2(b) shows the basic structure of BPNN with two inputs and one output. It consists of three layers: one input layer, one hidden layer, and one output layer. The two inputs and one output of BPNN is
Kernel function
Recently, kernel method is developed to solve the linearly inseparable or nonlinear problems in classification. According to the basic theory of kernel method which is shown in Figure 3, the linearly inseparable data in low-dimensional space (L) can be mapped to a high-latitude space (H) by the nonlinear mapping function

The basic principle of kernel theory.
It is worth noting that the kernel function is always expressed as a form of the inner product. So the kernel functions can be applied directly without knowing the specific expression of the nonlinear mapping function, which avoids the problem of solving nonlinear mapping function.
In practical applications, the selection of the appropriate kernel function is vital. Nowadays, there are a lot of different kernel functions according to Mercer’s theorem of kernel function analysis. Three representative kernel functions are listed as follows:
Polynomial kernel function

where
Sigmoid kernel function

where
Gaussian kernel function
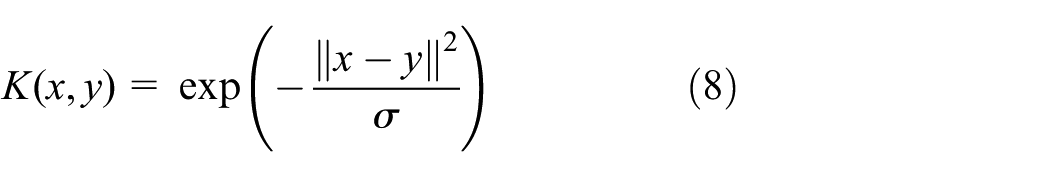
where
Gaussian kernel function BPNN
A novel neural network combining BPNN and Gaussian kernel function is proposed which can be named as Gaussian kernel function back-propagation neural network (GBPNN). The structure of GBPNN includes one input layer, one Gaussian kernel layer, two hidden layers, and one output layer, as illustrated in Figure 4.

Algorithm structure of GBPNN.
The two input variables of GBPNN are corrected speed n and corrected flow G, and ratio pressure π is selected as the output variable of GBPNN, so it can match the model of compressor performance map which is shown in equation (1).
The dotted line box in the Gaussian kernel layer is the Gaussian neurons, and its amount is determined by the number of speed lines that obtained the samples, just as it is illustrated in equation (3). The numbers of neurons in the hidden layer and output layer are the same as that of BPNN, which can be determined by optimized algorithm.
K in the dotted line box represents Gaussian kernel function as expressed in equation (8), and the output of Gaussian neurons

where
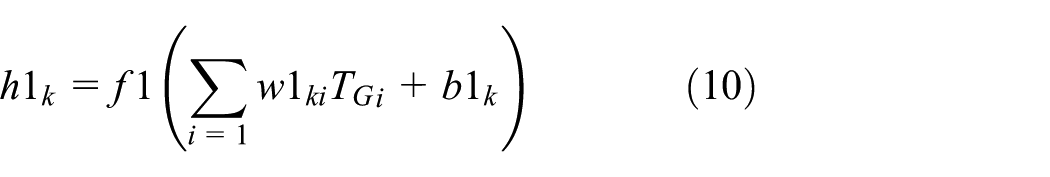
where k is the index of neurons in hidden layer I,
Similarly,

where l is the index of neurons in hidden layer II,
In equation (12),

where m is the index of neurons in output layer,
The error function is defined as in equation (13)

Weight
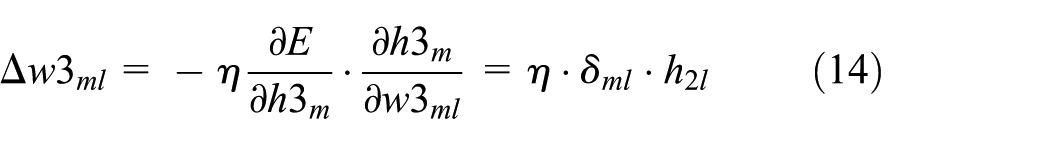
where
Threshold
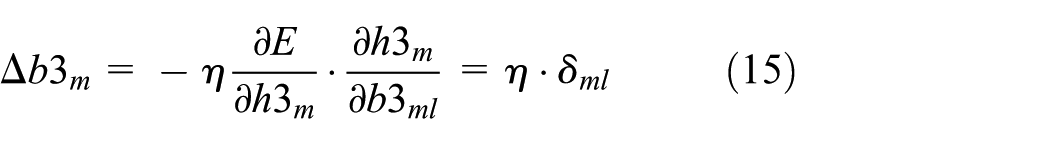
Weight

where
Threshold

Weight

where
Threshold

The calculation steps of BPNN
GBPNN method is the combination of BPNN and Gaussian kernel function. It can be seen from Figure 4 that errors are forward passed and weights (threshold) are reversely adjusted in GBPNN, so GBPNN model is a kind of forward network. The calculation steps of GBPNN are the same as most of the other forward neural networks, just as it is shown in following:
Step 1: select training and testing samples;
Step 2: determine parameters of GBPNN;
Step 3: train GBPNN with training samples;
Step 4: stop training if the error is acceptable;
Step 5: predict compressor performance map;
Step 6: analyze prediction accuracy with testing samples.
Results and discussion
In this section, GBPNN proposed in this article will be applied to predict the performance map of a multi-stage axial flow compressor. To demonstrate the potential capability of GBPNN for the interpolation and extrapolation, other two classical data-driven modeling methods named BPNN and SVM are also compared. The three models above are all realized based on M language in the MATLAB simulation environment. Besides, an assessment is performed and discussed on the sensitivity of different models to the number of training samples (48 training samples, 32 training samples, and 18 training samples). Furthermore, the prediction accuracy of GBPNN, BPNN, and SVM is evaluated by the mean absolute error (MAE) which can be calculated using the following functions

where N is the sample number,
Sample partition and data preprocessing
For the prediction of GBPNN, BPNN, and SVM, the data sample is vital. In this study, six known experimental data at every speed line (n = 0.95, n = 0.9, n = 0.8, n = 0.7, n = 0.6, n = 0.5, n = 0.4, and n = 0.3) shown in Figure 1 are selected as training samples according to the sample selection method proposed in Ghorbanian and Gholamrezaei. 14 Therefore, 48 samples can be obtained to train GBPNN, BPNN, and SVM. Similarly, 18 experimental data at speed lines of n = 1.0, n = 0.82, and n = 0.25 (blue dashed line in Figure 1) are selected as the testing samples which are divided into interpolated prediction and extrapolated prediction. In practical, considering the deficiency of experiment data at high- and low-speed conductions, the prediction of samples at corrected speed n = 1.0 is regarded as the extrapolation of high speed, and that of n = 0.25 is defined as extrapolation of low speed. Besides, the prediction of n = 0.82 in the middle of performance map is regarded as interpolation.
To eliminate the influence of the sample dimension, all the samples should be normalized using the following function

where s is the original sample,
Parameters configuration of prediction models
When the samples are obtained, the structures and related parameters of every prediction model need to be determined. The parameter configurations of BPNN are fully in accordance with that of Ghorbanian and Gholamrezaei.
14
In other words, BPNN consists one input layer, two hidden layers, and one output layer, where the corresponding neuron numbers are 2, 10, 10, and 1, respectively, for the prediction with 48 training samples. According to the basic principle of GBPNN, the number of neurons in Gaussian kernel layer will be determined by the number of speed lines that obtained the training samples. This means that the numbers of neurons in Gaussian kernel layer of GBPNN are 8 for the prediction with 48 training samples. In order to reasonably compare the prediction performance of GBPNN and BPNN, GBPNN also includes the same hidden layers, output layer, and the corresponding neuron numbers of hidden layers and output layer. In other words, the structure of GBPNN is 8-10-10-1. By analyzing the effects of coefficient

The sum of prediction error with value of gain coefficient in Gaussian kernel function.
Kernel function (ker), non-separable case (C), and loss function (loss) are the very important factors for SVM. In this study, radial basis function is selected as the kernel function (ker = rbf), and radial basis width parameter (p1) and insensitivity (e) are 0.3 and 0.001, respectively. Besides, epsilon insensitive function is taken as the loss function. Non-separable case is 800.
Prediction of compressor performance map with 48 training samples
Both the extrapolated and interpolated predictions are performed in this comparison. The training and testing samples used in different prediction models are same, and the initial weights of GBPNN and BPNN are given randomly.
Figure 6 shows the comparison of GBPNN, BPNN, and SVM for the interpolated and extrapolated prediction of compressor performance map. As shown in Figure 6, it can be seen that the values at speed lines of n = 0.82 predicted by every of the above three models are in good agreement with the experimental data, which means that there are perfect prediction accuracy of GBPNN, BPNN and SVM in interpolated prediction. Besides, a careful inspection of Figure 6 reveals that the difference of GBPNN, BPNN, and SVM is obvious when they are used to predict the extrapolation of compressor performance map, especially at n = 1.0. As shown in Figure 7, GBPNN has the best prediction performance, following SVM and BPNN, respectively.

Prediction of compressor performance with 48 training samples.

Extrapolation prediction of compressor performance (n = 1.0) with 48 training samples.
To eliminate the influence of randomness of weights and thresholds on GBPNN and BPNN, and avoid the problems of stiffness and blockage in local minima, Figure 8 illustrates the variations of MAE using different models with 50 times prediction. According to the results, it is observed that BPNN has a higher sensitivity than GBPNN to the initial weights and thresholds, which shows that the prediction performance of BPNN is difficult to satisfy the prediction accuracy demand of compressor performance map. Besides, although the outputs of SVM are unchanged because of its fixed parameters, the MAEs of SVM are more than those of GBPNN with 48 training samples. Table 1 shows the mean value of MAE for 50 times. For the GBPNN, the mean value of MAE for 50 times is only 0.014 which is obviously lower than those of SVM (0.025) and BPNN (0.080). All of these demonstrate that GBPNN is superior to BPNN and SVM in accuracy and stability of the prediction of compressor performance map.

MAE curves of 50 times prediction with 48 training samples.
The mean of MAE of 50 times prediction with three kinds of training samples.

MAE: mean absolute error; GBPNN: Gaussian kernel function back-propagation neural network; SVM: support vector machine; BPNN: back-propagation neural network.
Prediction of compressor performance map with 32 training samples
Considering the fact that the prediction accuracy of data-based modeling approach can be affected by the number of training sample, the prediction performance of GBPNN, BPNN, and SVM needs to be further analyzed. In this study, 30% of the total samples are cut off, which means that only 32 samples (four experimental data at each speed lines of n = 0.95, n = 0.9, n = 0.8, n = 0.7, n = 0.6, n = 0.5, n = 0.4, and n = 0.3) are used to train the above three prediction models. It is noting that all the structures and related parameters of every model are same as those of 48 training samples.
Figure 9 presents the prediction results using GBPNN, BPNN, and SVM with 32 training samples. From the figure, it is easily found that all the prediction accuracies of above three models are acceptable for the interpolation (n = 0.82) of compressor performance map. However, for the extrapolation at speed lines of n = 1.0, only GBPNN has a relatively acceptable prediction accuracy, as shown in Figure 10.

Prediction of compressor performance with 32 training samples.
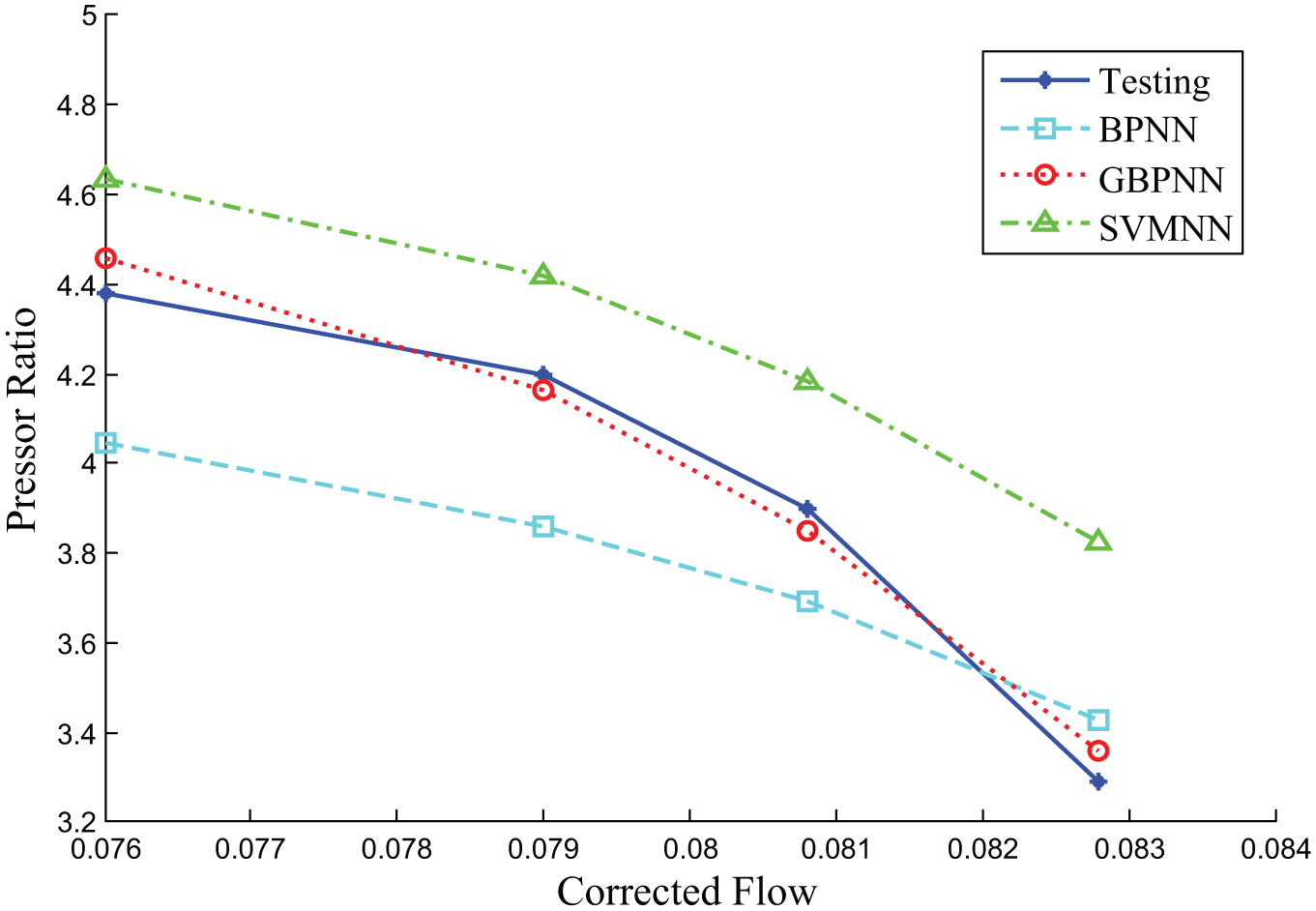
Extrapolation prediction (n = 1.0) of compressor performance with 32 training samples.
The results shown in Figure 11 and Table 1 indicate that all MAEs of GBPNN, BPNN, and SVM are bigger than those of 48 training samples. The mean values of MAE for prediction of 50 times are 0.045 for GBPNN, 0.043 for SVM, and 0.146 for BPNN. This is because the above three prediction models may not be trained well when the training sample is smaller. Besides, BPNN is so sensitive to the number of training samples that its prediction accuracy decreases significantly with the reduction in training sample number. However, GBPNN has a higher steady performance than BPNN because of the addition of Gaussian kernel layer. Moreover, it should be noted that SVM can provide the lowest mean MAE for the prediction of 50 times due its advantage of solving small sample problem.

MAE curves of 50 times prediction with 32 training samples.
Prediction of compressor performance map with 18 training samples
To further investigate the prediction accuracy and stability of GBPNN, the training samples are reduced to a minimum of 18 training samples in this analysis. As shown in Figure 12, six experimental data at each speed lines of n = 0.9, n = 0.7, and n = 0.6 are selected as training samples to train the prediction models. The experimental data at speed line of n = 0.8 are regarded as the testing samples to estimate the prediction performance of different models with small samples. Besides, considering the effects of data samples on modeling GBPNN, BPNN, and SVM, the related parameters of different prediction models need to be determined again. For BPNN, it still consists of one input layer, two hidden layers, and one output layer, but the corresponding neuron numbers of every layer are 2, 5, 5, and 1, respectively. In this case, the structure of GBPNN changes to 3-5-5-1. All the weights and thresholds of GBPNN and BPNN are randomly distributed. Besides, the key parameter of SVM is C = 800, e = 0.001, and p1 = 0.8.

The compressor performance map with 18 training samples.
Figure 13 compares the prediction values of GBPNN, BPNN, and SVM with 18 training samples. According to the results shown in Figure 13, it is clearly exhibited that the prediction values obtained using GBPNN are in a very good agreement with the experimental data for about 80% of samples. In addition, SVM can effectively predict the trend of targeted data with only the relative lower prediction accuracy. Compared to the above prediction approach, the prediction values using BPNN are obviously deviated with the real experimental data because the number of training samples is so small that BPNN cannot be trained well, which demonstrates that BPNN is not available for the prediction of compressor performance map in the case of 18 training samples.
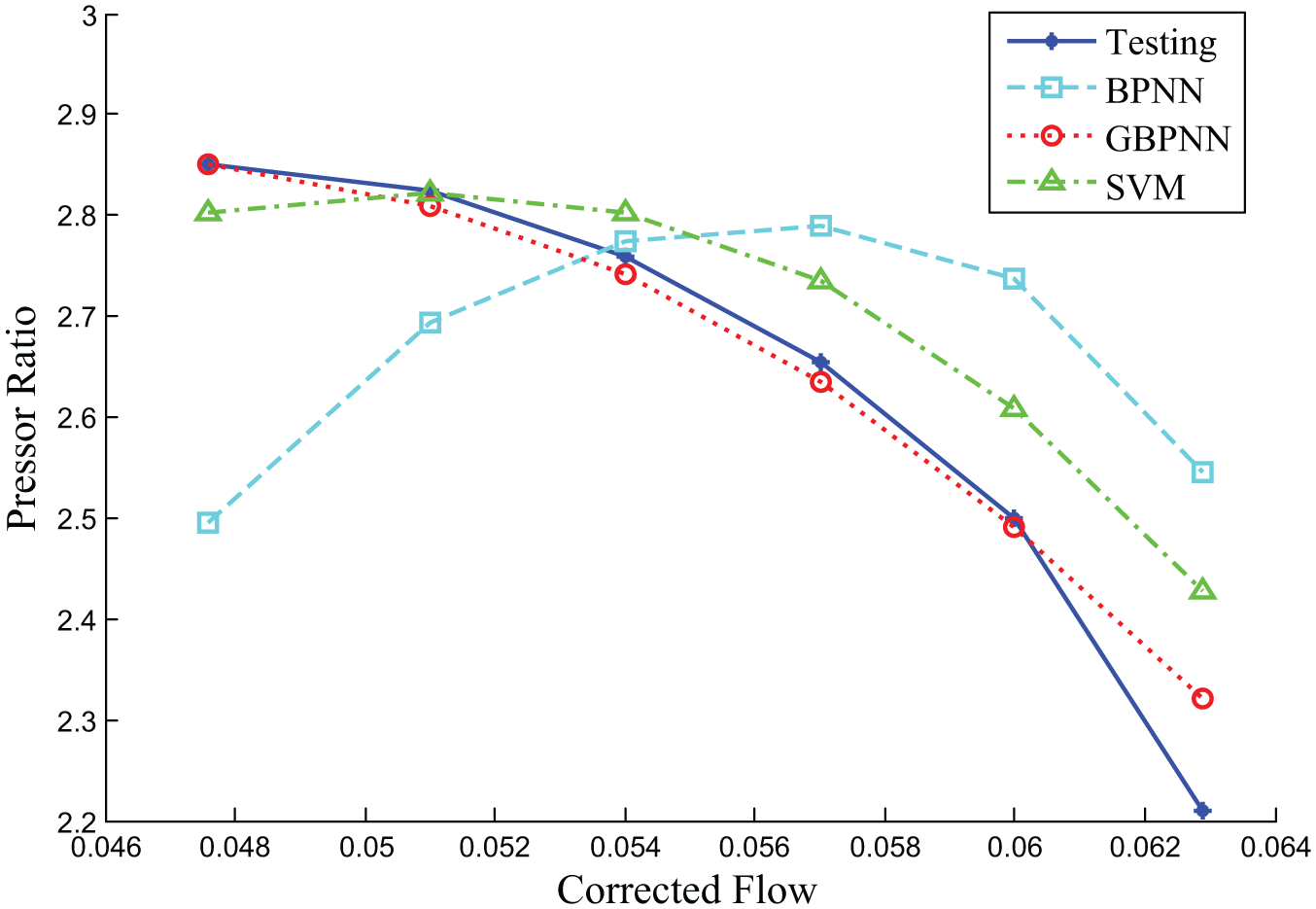
Prediction of compressor performance with 18 training samples.
In addition, the variations of MAE for the 50 times prediction with 18 training samples are plotted in Figure 14, and the mean MAE is listed in Table 1. As shown in Figure 14 and Table 1, all the MAEs of GBPNN, BPNN, and SVM with 18 training sample are higher than those with 48 and 32 training samples. The mean MAE of BPNN is 1.151, but that of GBPNN is only 0.289. In this case, although SVM provides the minimum mean MAE of 0.250 compared to the other two approaches, more than 54% of the predicted MAE of GBPNN are smaller than those of SVM due to the fluctuated characteristic.

MAE curves of 50 times prediction with 18 training samples.
Conclusion
Aiming at improving the prediction accuracy of compressor performance map on the interpolation and extrapolation conditions, this article proposed a novel feed-forward GBPNN.
An investigation is performed to study and demonstrate the potential capability of GBPNN for the typical interpolated and extrapolated predictions of a multi-stage axial flow compressor. And the prediction values using different models including GBPNN, BPNN, and SVM are compared in detail.
First, it is found that the number of training samples is a very important factor to affect the prediction accuracy of the above three data-based modeling approach. With the decrease in training samples, the prediction accuracy will decrease obviously for any approach. The interpolated values predicted using the above three models are in good agreement with the experimental data when the training samples are 48 and 32. However, when the numbers of training samples are reduced to 18, BPNN is not available for the interpolated prediction of compressor performance map due to the fact that BPNN cannot be trained well using only 18 training samples.
Second, for the extrapolated predictions of compressor performance map, all the results indicate that GBPNN has highest prediction performance than the other two models because of the addition of Gaussian kernel layer which can effectively capture the similarity feature between the borders upon speed lines.
Third, the sensitivity of GBPNN, BPNN, and SVM on the number of prediction is investigated. According to the analysis, it is detected that BPNN has a higher sensitivity than GBPNN to the initial weights and thresholds with any of the three training samples conductions, which shows that the prediction performance of BPNN is difficult to satisfy the prediction accuracy demand of compressor performance map.
Footnotes
Appendix 1
Academic Editor: Neal Y Lii
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (Grant No. 51475100, Grant No. 51305089) and the Central University Basic Scientific Research Special Fund of China (HEUCF140306).