
Abstract
Rolling bearings are critical components in rotating machinery, directly influencing equipment safety and reliability. However, early fault signals are typically weak and easily masked by noise, posing significant challenges for accurate fault diagnosis. To address these challenges, this paper proposes a novel dual-branch fault diagnosis framework termed STCSE, which integrates a simplified single-stage Swin Transformer with a CNN enhanced by Squeeze-and-Excitation attention mechanisms. First, raw vibration signals are processed through Variational Mode Decomposition and Fast Fourier Transform, and the extracted features are stacked into a 5 × 1024 time-frequency fusion matrix. Subsequently, two parallel branches extract complementary features: the Swin Transformer branch captures global contextual dependencies (64-day output), while the CNN-SE branch extracts local features with channel attention (128-day output). The fused 192-dimensional representation is then fed into a softmax classifier for fault categorization. Experiments on three benchmark datasets—Case Western Reserve University, Paderborn University, and Southeast University gearbox—demonstrate that STCSE achieves state-of-the-art accuracy of 100.00%, 98.10%, and 96.40% respectively, with only 2.1M parameters and 0.8G FLOPs, significantly outperforming existing methods in both accuracy and computational efficiency. Ablation studies validate the effectiveness of each design component, and noise robustness experiments confirm the model’s practical applicability under varying signal-to-noise ratio conditions.
Keywords
Introduction
As a critical component of rotating machinery, rolling bearings play a vital role in load support and rotational motion.1,2 However, under complex and variable working conditions, they are highly susceptible to failures due to factors like heavy loads and fatigue, which can lead to the breakdown of the entire mechanical system. Studies have shown that bearing-related failures constitute over half of all failures in rotating machinery, severely compromising equipment availability and overall production efficiency.3–5 Therefore, the timely diagnosis of bearing faults under such challenging conditions is of critical importance.
Traditional vibration-based fault diagnosis methods, such as envelope analysis, wavelet transform, and empirical mode decomposition (EMD), have been widely adopted in industrial practice.4,5 However, these methods heavily rely on expert knowledge for feature extraction and often fail to capture subtle fault signatures under variable operating conditions. The manual feature engineering process is not only time-consuming but also limits the generalization capability across different fault types and severity levels.
To overcome these limitations, deep learning-based approaches have been extensively explored. Convolutional neural networks (CNNs) such as WDCNN 6 and deep residual networks 7 have demonstrated strong performance in automatic feature extraction from raw vibration signals. More recently, Huang et al. 8 proposed the MDSC-FSPPA-LCFF framework that leverages multi-scale depthwise separable convolutions with fast spatial pyramid pooling attention for comprehensive feature learning in multipoint fault scenarios. Similarly, Liu et al. 9 introduced a Joint Learning Network based on local-global feature perception that dynamically distinguishes between local impulse segments and normal signal segments under limited sample conditions. Nevertheless, CNN-based methods inherently focus on local receptive fields and may overlook long-range temporal dependencies that are critical for distinguishing closely related fault patterns.
Vision Transformers (ViTs) 10 and their variants such as Swin Transformer address this limitation through self-attention mechanisms that capture global feature relationships. However, directly applying standard Swin Transformer architectures to bearing fault diagnosis introduces excessive computational overhead due to the multi-stage hierarchical design, which is unnecessary for the relatively simple spectral patterns in vibration signals. Moreover, existing methods typically employ either time-domain or frequency-domain features alone, without effectively integrating multi-scale time-frequency representations.
Based on the above analysis, three key research gaps remain: (1) the lack of efficient Transformer architectures tailored for vibration signal characteristics, (2) insufficient exploration of multi-modal time-frequency feature fusion strategies, and (3) the absence of complementary local-global feature extraction frameworks that balance accuracy and computational efficiency. To address these gaps, this paper proposes STCSE, a dual-branch architecture that combines a simplified single-stage Swin Transformer for global feature extraction with a CNN-SE module for local feature enhancement, operating on VMD + FFT fused time-frequency representations.
Firstly, the raw vibration signals are processed using Variational Mode Decomposition (VMD) and Fast Fourier Transform (FFT) to derive their time-frequency representations. These feature sets are subsequently stacked and fused to create consolidated one-dimensional feature vectors, which are utilized as the input to our proposed model.
Secondly, the feature extraction process diverges into two parallel branches to analyze the fault feature sequences:
Branch 1 transforms the one-dimensional feature sequences into two-dimensional matrices (as distinct from image data to maintain simplicity) and processes them through a Swin Transformer-based network. This leverages the model’s window attention mechanism to effectively capture local spatial features within the fault signals.
Branch 2 processes the one-dimensional feature sequences through an improved 1D Convolutional Neural Network (1D-CNN) enhanced with a channel attention mechanism (Squeeze-and-Excitation, SE). This branch adaptively recalibrates channel-wise feature weights, allowing the model to autonomously prioritize informative channels and extract global characteristics from the bearing fault signals.
Finally, the local and global spatial features from both branches are integrated via a stacking-based fusion strategy. This combines their complementary representations, enhancing the model’s predictive performance and generalization capability.
The effectiveness of the proposed method was evaluated through extensive experiments on three benchmark datasets: the Case Western Reserve University (CWRU) bearing dataset, the Paderborn University (PU) bearing dataset, and the Southeast University (SEU) gearbox dataset. The results show that our novel algorithm outperforms existing state-of-the-art methods, and its analysis offers valuable insights into the critical features and underlying patterns for fault diagnosis.
This work can be summarized by the following primary contributions:
(1) A novel VMD + FFT time-frequency fusion strategy is proposed, which constructs a 5 × 1024 input matrix by stacking four VMD-decomposed intrinsic mode functions with the FFT spectrum, providing complementary multi-scale time-frequency information for fault diagnosis.
(2) An efficient dual-branch architecture (STCSE) is designed, consisting of a simplified single-stage Swin Transformer branch for capturing global features (64-day output) and a CNN-SE branch for extracting local features with channel attention (128-day output), whose outputs are fused into a 192-dimensional representation.
(3) Comprehensive experiments on three benchmark datasets (CWRU, PU, and SEU) demonstrate that STCSE achieves state-of-the-art accuracy with significantly fewer parameters (2.1M) and lower computational cost (0.8G FLOPs) compared to existing methods, while ablation studies validate the effectiveness of each design component.
This paper is structured as follows. The “Introduction” outlines the research background of rolling bearing fault diagnosis. The “Related Works” reviews current research in this field. The “Proposed Method” details the architecture and key algorithmic components of the novel STCSE model. The “Experimental Results and Analysis” describes the experimental outcomes on three benchmark datasets and provides a thorough evaluation including ablation studies, cross-dataset comparison, and noise robustness analysis. The “Discussion” analyzes the limitations and future directions. Finally, the “Conclusion” summarizes the study.
Related works
Recent years have witnessed significant momentum in the development of intelligent methods for rolling bearing fault identification, which primarily revolve around the following aspects:
(1) Research on Fault Data Enhancement Methods: This section reviews current domestic and international research on fault data enhancement. It covers various techniques, including data augmentation, Generative Adversarial Networks (GANs), and Autoencoders, and illustrates their applications in improving the diversity and size of fault data samples.11–13 However, these augmentation techniques primarily address data scarcity and do not fundamentally improve the discriminative power of feature extraction methods, which remains the core bottleneck in fault diagnosis accuracy.
(2) Research on Feature Extraction and Selection Methods: This section reviews previous work on feature extraction and selection for rolling bearing fault data. It covers a range of techniques, including statistical methods, Fourier transform, Gramian Angular Fields (GAF), wavelet transform, modal decomposition, Hilbert-Huang transform (HHT), and Markov Transition Fields (MTF). The advantages and disadvantages of these methods for fault feature extraction are discussed.14–19 However, these handcrafted feature extraction methods require substantial domain expertise and are sensitive to operating condition variations, limiting their adaptability in real-world industrial settings where operating parameters frequently change.
(3) Research on Machine Learning and Deep Learning Methods: This section reviews advances in machine and deep learning for fault diagnosis. It covers traditional algorithms, including Decision Trees, Support Vector Machines (SVM), Random Forests, and K-Nearest Neighbors (KNN), as well as deep learning models such as Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN), Transformer architectures, and Graph Neural Networks (GNN), discussing their effectiveness in fault data identification.20–24,29,32 However, most existing deep learning methods either focus on local features (e.g. CNN-based approaches) or global dependencies (e.g. Transformer-based methods) independently, without effectively integrating complementary local-global representations for comprehensive fault characterization.
(4) Research on Fault Diagnosis and Intelligent Identification Methods: This section reviews established approaches for intelligent fault diagnosis in rolling bearings. It covers rule-based expert systems, data-driven models, physics-based methods, and hybrid methodologies, summarizing their application outcomes. Furthermore, it describes widely-used public fault datasets and benchmark evaluation frameworks, discussing their scale, data quality, labeling accuracy, and applicability for validating new diagnostic algorithms.25,26 However, rule-based and traditional pattern recognition methods struggle with complex, nonlinear fault signatures under variable operating conditions, and their diagnostic performance degrades significantly when encountering unseen fault patterns.
(5) Research on Heterogeneous Data Fusion Methods: This section reviews research on fusing heterogeneous data for rolling bearing fault diagnosis. Such data—encompassing vibration, acoustics, temperature, and pressure from diverse sensors or platforms—plays a critical role in comprehensive analysis. Established fusion strategies, including sensor-level, feature-level, and decision-level fusion, are discussed, highlighting their notable effectiveness in improving fault identification performance.27–29 However, most multi-sensor fusion methods introduce significant computational overhead and require specialized multi-channel hardware configurations, making them less practical for cost-sensitive single-sensor deployment scenarios commonly found in industrial applications.
(6) Dataset Construction for Rolling Bearing Fault Diagnosis: This section examines existing efforts in building dedicated datasets for rolling bearing faults. It addresses key aspects of dataset development, including construction methodologies, data collection strategies, annotation schemes, as well as dataset scale and representativeness, highlighting the critical role of high-quality data in advancing fault identification research.30,31 However, over-reliance on a single benchmark dataset (e.g. CWRU) for model validation significantly limits the generalizability assessment of proposed methods, as different datasets exhibit distinct noise characteristics, fault severity distributions, and operating conditions.
(7) Transfer Learning with Pre-trained Models: This section introduces the application of transfer learning based on pre-trained models for rolling bearing fault recognition. It examines the adaptation of models that have achieved breakthroughs in natural language processing—such as the Generative Pre-trained Transformer (GPT) and Bidirectional Encoder Representations from Transformers (BERT)—to fault data, a approach that is establishing a new research paradigm.32,33 However, domain adaptation for vibration signals across different machinery types and operating conditions remains an open challenge, as the feature distributions of source and target domains often differ substantially.
The above review reveals that despite significant progress in intelligent fault diagnosis, current methods still face critical challenges in three aspects: (1) efficiently integrating local and global feature representations within a unified framework, (2) exploiting complementary time-frequency information through effective multi-modal fusion strategies, and (3) achieving robust generalization across different datasets, fault types, and machinery components. These identified gaps constitute the primary motivation for the STCSE framework proposed in this paper, which addresses each of these challenges through its dual-branch architecture operating on VMD + FFT fused time-frequency inputs.
Proposed method
This section is divided into two primary components. The first presents the overall architecture of the intelligent fault diagnosis system for rolling bearings, while the second introduces the methodology for time-frequency feature extraction and fusion, culminating in the proposed STCSE-based fault identification model.
System architecture design
The overall architecture of the intelligent fault diagnosis system is depicted in Figure 1. It consists of three primary components: the bearing fault status module, the data preprocessing module, and the data analysis and diagnosis module.
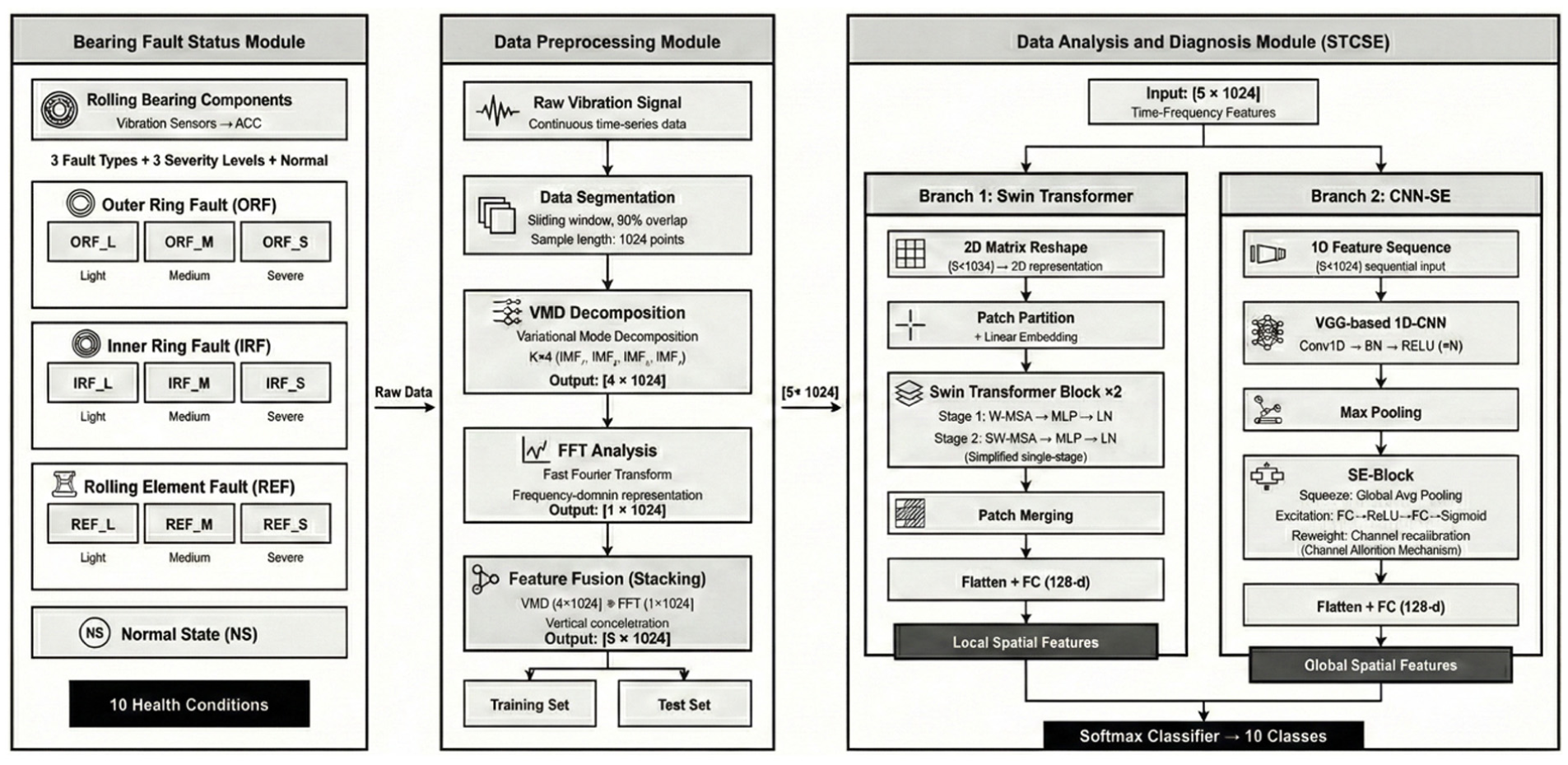
Overall architecture of the intelligent fault diagnosis system for rolling bearings.
Rolling bearing fault components serve as the fundamental source of the research data. Typical fault components that significantly impact the safety and stability of rolling bearings fall into three major categories: outer ring faults, inner ring faults, and rolling element faults. Depending on the severity level of each component’s fault, these can be further subdivided into light, medium, and severe levels.
Consequently, this paper categorizes the operational states of rolling bearings into 10 typical types: Normal State (NS), Outer Ring Fault_Light (ORF_L), Outer Ring Fault_Medium (ORF_M), Outer Ring Fault_Severe (ORF_S), Inner Ring Fault_Light (IRF_L), Inner Ring Fault_Medium (IRF_M), Inner Ring Fault_Severe (IRF_S), Rolling Element Fault_Light (REF_L), Rolling Element Fault_Medium (REF_M), and Rolling Element Fault_Severe (REF_S). Data for different fault types are collected by vibration acceleration sensors and digitized using an Analog-to-Digital Converter (ADC).
Figure 2 illustrates the complete workflow from raw vibration data preprocessing to fault diagnosis for rolling bearing components. Data preprocessing improves data quality, enhances model performance, and ensures stable and efficient training. The preprocessing pipeline in this study comprises two main stages: data segmentation/augmentation and time–frequency feature fusion.

STCSE algorithm model.
Data segmentation involves dividing raw vibration signals into fixed-length samples to facilitate subsequent feature extraction. To capture the periodic nature of rolling bearing faults, the sample length is set to cover at least one complete rotation cycle, ensuring all critical features are retained. Furthermore, an overlapping sampling strategy is adopted for data segmentation to enhance model generalization and facilitate a comprehensive performance evaluation. The sampling procedure employs a sliding window with 50% overlap to extract consecutive samples from continuous vibration data. Based on the rotational speed and sampling frequency, each complete rotation cycle corresponds to 406 data points. To ensure adequate coverage of periodic features, the sample length is set to 1024 points, spanning multiple rotation cycles while maintaining computational efficiency.
The integration of time-domain and frequency-domain feature extraction constitutes a key innovation of this work. Time-domain analysis effectively captures transient events and amplitude variations, whereas frequency-domain analysis reveals periodic patterns and spectral distributions, providing complementary insights into fault characteristics.
VMD is an adaptive signal processing technique that decomposes a signal into a set of intrinsic mode functions (IMFs). Each IMF captures distinct time-domain characteristics representing specific frequency components at different scales, enabling effective multi-resolution analysis of fault signatures.34,35 The decomposition performance of VMD is highly sensitive to the number of modes K. An excessive K value causes over-decomposition, generating spurious components without physical significance that complicate subsequent analysis. Conversely, an insufficient K results in under-decomposition, where multiple intrinsic modes are mixed within a single component, hindering effective feature extraction. Based on empirical analysis of raw fault data, this study identifies K = 4 as the optimal number of modes for VMD decomposition. Consequently, each 1024-point sample is transformed into a 4 × 1024 feature matrix, effectively capturing multi-scale signal characteristics. FFT serves as a fundamental frequency-domain analysis technique that converts time-domain signals into their spectral representations. This transformation enables the acquisition of energy distribution across frequency bands, thus elucidating the signal’s spectral composition.36,37
Construction of time-frequency fusion matrix
This study innovatively integrates VMD and FFT to exploit their complementary strengths for multi-scale feature extraction from rolling bearing fault signals. The hybrid approach enables comprehensive time-frequency analysis by stacking the extracted features into a 5 × 1024 representation, which serves as the input to our fault diagnosis model for network training. This systematic feature fusion enhances signal processing capabilities for improved fault detection and diagnosis.
The input representation for STCSE is constructed by stacking the VMD-decomposed components and FFT spectrum into a unified matrix. Specifically, for each vibration signal segment of length 1024, VMD decomposition with K = 4 modes yields four intrinsic mode functions (IMF1–IMF4), each of dimension 1 × 1024. The FFT spectrum of the original signal, also of dimension 1 × 1024, is computed to capture the global frequency characteristics. These five components are vertically stacked to form a 5 × 1024 input matrix:

The rationale for this stacking (concatenation) fusion strategy, as opposed to weighted or attention-based fusion, is threefold: (1) it preserves all information from each component without introducing learnable fusion parameters that require additional training data; (2) it maintains the computational simplicity needed for efficient inference; and (3) the subsequent dual-branch network can implicitly learn the optimal weighting of these components through its feature extraction layers. The ablation study in Section 4.4.2 confirms that this stacking strategy achieves the best performance while maintaining the lowest computational overhead among the tested fusion approaches.
Key algorithm research
Branch1: Swin Transformer
Swin Transformer is a backbone network designed to reduce the computational complexity of standard Transformer architectures. Its core innovation lies in a hierarchical windowing scheme that partitions images into non-overlapping windows, within which self-attention is computed. This approach is augmented by cross-window attention mechanisms that enable efficient information exchange across different regions. 38
This paper presents an innovative approach that restructures one-dimensional time-frequency features of rolling bearings into a two-dimensional matrix representation—distinct from conventional image conversion to avoid RGB-channel complexity. In this framework, each matrix element functions as a pixel analog, enabling effective local feature extraction from bearing fault signals through the Swin Transformer architecture.
Swin Transformer employs a hierarchical architecture comprising four core components: patch partitioning, linear embedding, Swin Transformer blocks, and patch merging layers. Following the original implementation, the network accepts 224 × 224 × 3 input images and processes them through four sequential stages containing [2, 2, 6, 2] Swin Transformer blocks respectively. Each stage applies progressive downsampling with ratios of [4, 8, 16, 32], ultimately reducing the feature map resolution to 1/32 of the original input size. 39
Given the substantially smaller volume of rolling bearing fault data in our study compared to the original implementation (designed for hundreds of millions of samples), we developed a simplified Swin Transformer architecture containing just one stage. Experiments confirm that this lightweight design maintains strong performance on our limited dataset while effectively mitigating overfitting and reducing computational cost.
Figure 3 illustrates the shallow Swin Transformer architecture developed in this work. The processing pipeline begins with time-frequency multi-scale features of dimensionality [5, 1024], which are reshaped into a [32, 32, 5] matrix. The Patch Partition layer divides this matrix into non-overlapping 4 × 4 patches, transforming the dimensions to [8, 8, 80]. Subsequent Linear Embedding performs feature projection to yield a [8, 8, 64] representation. Swin Transformer Blocks process these features while preserving the [8, 8, 64] dimensionality. The architecture concludes with adaptive pooling, reducing the feature map to [1, 1, 64] before flattening it into a 64-dimensional feature vector.

SwinTransformer branch architecture.
As shown in the right portion of Figure 3, the Swin Transformer Block employs a two-stage sequential architecture. The first stage utilizes the Window-based Multi-head Self-Attention (W-MSA) mechanism, while the second stage employs the Shifted Window-based Multi-head Self-Attention (SW-MSA) mechanism. This design incorporates Layer Normalization (LN) and Multi-Layer Perceptron (MLP) components with residual connections at each stage.
Architecturally, W-MSA computes self-attention within localized non-overlapping windows, restricting focus to intra-window content without cross-window connections. While this windowed approach substantially reduces computational complexity compared to global self-attention, it prevents inter-window information exchange, thereby hindering the modeling of global dependencies. To overcome this limitation, SW-MSA introduces a shifted window strategy through cyclic and reverse-cyclic shifting operations. This innovative mechanism establishes cross-window connections while maintaining non-overlapping window efficiency, enabling effective capture of high-level visual patterns through localized yet globally-aware processing.
Each Swin Transformer Block systematically alternates between two core stages: the first stage employs W-MSA, followed invariably by the SW-MSA in the subsequent stage. This paired configuration forms a complete two-stage processing module. The output of each stage is mathematically represented by equation (2):
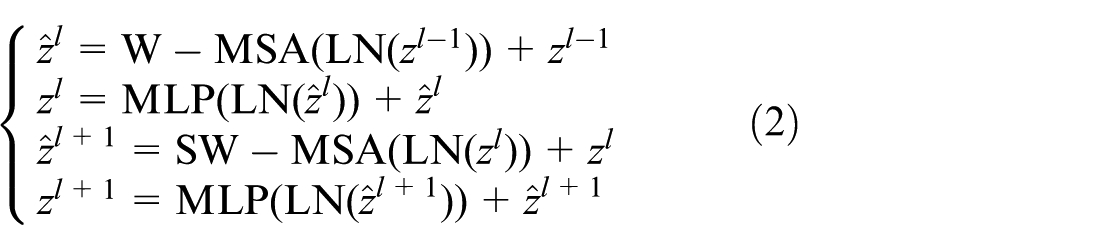
where:
The self-attention mechanism serves as the fundamental building block of Transformer architectures, with its computational formulation given by equation (3):

where Q denotes the query matrix, K represents the key matrix, V corresponds to the value matrix, d is the dimensionality of Q and K, B indicates the bias term.
Branch2: CNN-SE
The 1D-CNN exhibits proven capability in capturing localized features within one-dimensional sequential data like rolling bearing vibration signals. By stacking multiple convolutional-pooling layers and increasing kernel quantities, the architecture effectively learns hierarchical features, thereby boosting its representational power.
The SE module operates by learning channel-wise importance coefficients through fully connected layers. These coefficients adaptively recalibrate feature maps, enhancing informative channels while suppressing less significant ones. SE blocks can be seamlessly integrated into standard CNN architectures, such as VGG, ResNet, GoogLeNet, etc., delivering substantial performance gains with minimal computational overhead.40,41
This paper introduces a novel VGG-based architecture enhanced with channel attention mechanisms to improve rolling bearing fault identification. As illustrated in Figure 4, the proposed CNN-SE framework incorporates a series of convolutional-pooling modules (within the dashed box) forming the VGG backbone. The 2D input features first undergo 1D-CNN convolution and ReLU activation before being processed by the SE-Block, which strengthens the model’s capacity for discriminative learning across channels and global representations.
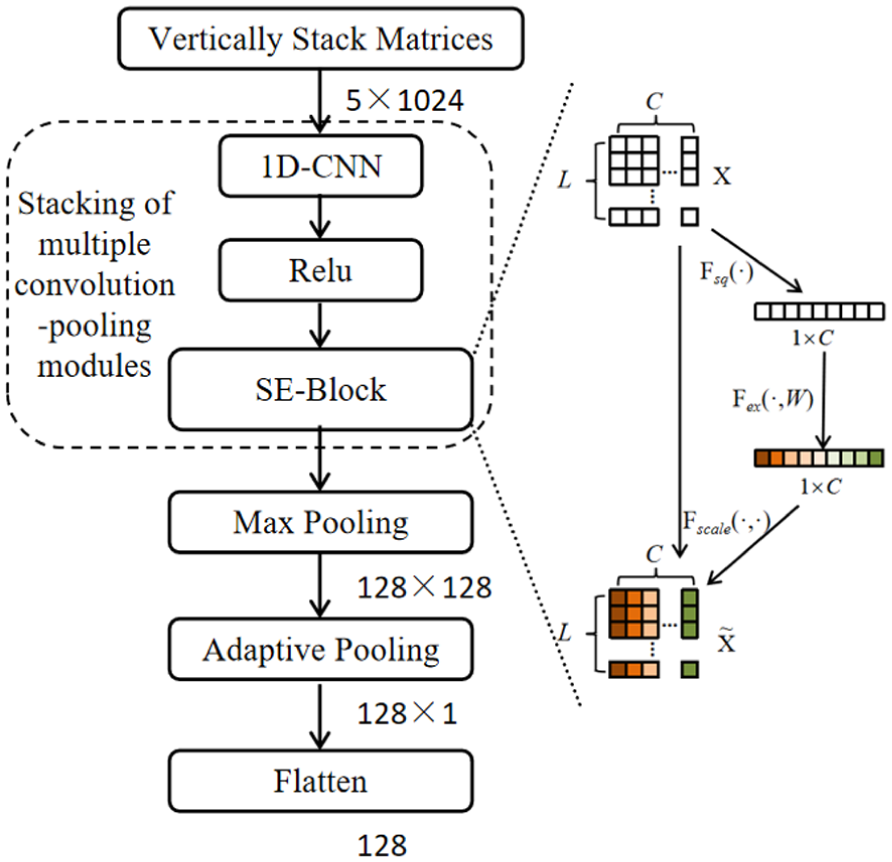
CNN-SE branch architecture.
The specific procedure unfolds as follows: the feature matrix of dimension [5, 1024] is first processed by the VGG network for feature extraction. The resulting features then undergo max pooling, reducing their dimensionality to [128, 128]. Finally, the feature map is fed into an adaptive pooling layer, further transforming its dimensions to [128, 1], and is subsequently flattened into a 128-dimensional feature vector.
The internal architecture of the SE-Block, as depicted in the right portion of Figure 4, employs a three-stage workflow comprising: the Squeeze operation for global context aggregation, the Excitation step for modeling inter-channel dependencies, and the Reweight function for feature recalibration.
The first step implements the “Squeeze” operation (denoted as Fsq(·) in Figure 4), which performs feature compression through global average pooling. This operation collapses each channel’s temporal sequence into a scalar value, effectively creating a pooling layer with global receptive field that extracts comprehensive contextual information while maintaining the original channel dimensionality.
The second step executes the “Excitation” operation (signified as Fex(·,W) in Figure 4), which models channel-wise dependencies through fully-connected layers. This process generates a weight matrix W that captures attention distribution across feature channels, effectively quantifying the relative importance of each channel.
The third step performs the “Reweight” operation (denoted as Fscale(·,·) in Figure 4), where the compressed features pass through two fully-connected layers. The final layer employs a sigmoid activation, constraining outputs to the [0,1] range—thus serving as normalized importance ratios for each channel. These activation values are then multiplied with the original input features, dynamically recalibrating channel-wise significance through learned attention weights.
The preceding sections have detailed the key algorithms and core design methodologies investigated in this study. Through the comprehensive elaboration of Figures 1 to 4, we have established a deeper understanding of the proposed framework. The subsequent section will proceed with experimental validation to evaluate the effectiveness of the designed approach.
Experimental results and analysis
This study employs the rolling bearing dataset from the CWRU Bearing Data Center, 42 a benchmark widely recognized in the field, to validate the proposed fault diagnosis model. The experimental setup utilizes vibration signals collected under 1730 rpm rotational speed with a 3 hp load, sampled at 12 kHz. Following the classification criteria detailed in Table 1, bearing faults are categorized into 10 distinct types based on location and damage severity. The processed dataset comprises 2330 samples (233 per fault condition), which are partitioned into training, validation, and test sets following a 7:2:1 ratio through stratified sampling.
Bearing fault conditions of the CWRU dataset.

To further validate the generalization capability of STCSE, the Paderborn University (PU) bearing dataset 43 was adopted. Unlike the CWRU dataset which uses artificially seeded faults, the PU dataset contains bearings with real damage caused by accelerated lifetime tests, providing a more realistic and industrially representative evaluation scenario. The dataset includes seven fault categories: normal condition, inner race faults at three severity levels (low, medium, high), and outer race faults at three severity levels. Vibration signals were sampled at 64 kHz under varying speed and load conditions. Following the same preprocessing pipeline as described in Section 3.1, each signal segment was decomposed using VMD (K = 4) and transformed via FFT to construct the 5 × 1024 input matrix. The dataset was split into 70% training, 15% validation, and 15% test sets with strict sample-level separation.
To assess the cross-component applicability of STCSE beyond bearing fault diagnosis, the Southeast University (SEU) gearbox dataset 44 was adopted. This dataset contains vibration signals from a drivetrain system with five conditions: normal, chipped tooth, missing tooth, root crack, and surface wear. Gear faults exhibit fundamentally different vibration characteristics from bearing faults, including meshing frequency harmonics and sidebands, making this dataset particularly suitable for evaluating the generalization capability of the proposed method. The same VMD + FFT preprocessing and STCSE architecture were applied without any task-specific modifications.
To prevent data leakage, strict sample-level separation was enforced: consecutive signal segments extracted from the same continuous vibration recording via the sliding window (50% overlap) were assigned exclusively to either the training or test set, ensuring no temporal overlap between training and test samples. This separation guarantees that the model is evaluated on genuinely unseen data.
All performance evaluations were conducted on a dedicated deep learning server, with the complete hardware and software configurations detailed in Table 2.
Configuration parameters of the experimental environment.

The experiments were implemented using PyTorch 2.1.1 under Python environment, employing the Adam optimizer for parameter optimization with a batch size of 32 and initial learning rate of 0.0003. The learning rate was dynamically adjusted during training, and the cross-entropy loss function was utilized for model optimization. All models were trained for 50 epochs, and all reported results represent the average of three independent trials.
Evaluation of individual module contributions
The proposed STCSE model employs a dual-branch architecture for feature extraction. To evaluate the diagnostic performance of each branch and their integrated framework, comparative experiments were conducted among the standalone Swin Transformer model, the standalone CNN-SE model, and the complete STCSE model. For fair comparison, all models received identical inputs: the 5 × 1024 feature vectors formed by stacking multi-scale features extracted through VMD and FFT. The key distinction lies in their processing pipelines: both the Swin Transformer and CNN-SE models directly connect their extracted features to fully-connected layers for fault classification, whereas the STCSE model first fuses features from both branches before the final classification layer. By comparing the classification accuracy achieved by these three configurations, the individual contribution and effectiveness of each module within the STCSE framework can be rigorously validated.
The evaluation employs three key metrics: training accuracy, testing accuracy, and loss value. Training accuracy measures the proportion of correctly classified samples in the training set, while testing accuracy reflects the model’s classification performance on unseen test data. The loss function quantifies the discrepancy between model predictions and ground-truth labels. Our optimization objective is to simultaneously maximize classification accuracy and minimize the loss value, thereby achieving robust model performance. The experimental results are summarized in Table 3.
Experimental results of module performance evaluation.
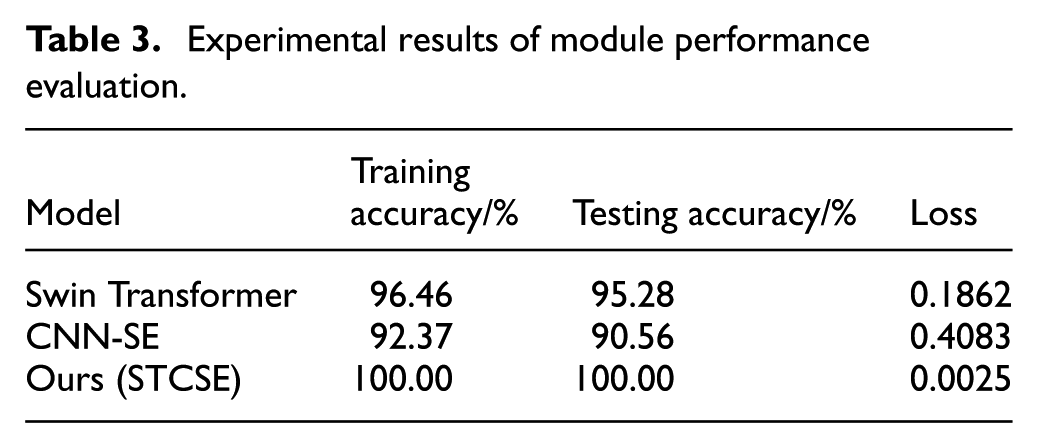
According to the experimental results presented in Table 3, while both Swin Transformer and CNN-SE models demonstrate strong feature extraction capabilities, their performance in bearing fault classification remains suboptimal. Specifically, the Swin Transformer model achieves a test accuracy of 95.28%, with its limitation stemming from the window attention mechanism’s primary focus on local feature extraction while insufficiently modeling global dependencies in fault signals. In contrast, the CNN-SE model effectively captures global characteristics through channel attention mechanisms but exhibits weaker perception of local details, resulting in a test accuracy of only 90.56%. The proposed STCSE model integrates the local modeling capability of Swin Transformer with the global perception mechanism of CNN-SE, achieving effective complementarity between local and global features. This integration enables the model to reach a perfect test accuracy of 100%, significantly outperforming all individual models.
t-SNE visualization analysis
t-Distributed Stochastic Neighbor Embedding (t-SNE) serves as an effective nonlinear dimensionality reduction technique that projects high-dimensional features into a two-dimensional space, generating interpretable feature distribution maps. In such visualizations, the formation of well-separated clusters for different categories indicates stronger discriminative power of the model for the corresponding states.
To investigate the discriminative capability of each module in the proposed STCSE model, we conducted t-SNE visualization analysis on the outputs from different processing stages, as shown in Figure 5. The left subplot displays the t-SNE visualization of the original features, where the 10 fault categories exhibit mixed distribution patterns with significant inter-class overlap, indicating the inherent inability of raw features to effectively differentiate fault types. The two middle subplots present the feature distributions processed by the Swin Transformer and CNN-SE modules respectively: compared to the original features, both demonstrate noticeable clustering tendencies, revealing their respective advantages in local and global feature extraction, though certain categories still show blurred boundaries and feature stacking. The rightmost subplot shows the feature visualization after processing by the complete STCSE model, where the 10 fault categories are clearly separated with compact clustering and well-defined inter-class boundaries. This demonstrates that through the integration of local and global features, the model significantly enhances feature discriminability, further validating the effectiveness of the proposed architecture.

t-SNE visualization of different stages in the STCSE model.
Comparative experiments
Results for the CWRU dataset
To validate the effectiveness of the proposed STCSE model, a comprehensive evaluation was conducted against both traditional baseline models (CNN, CNN-LSTM, CNN-Transformer) and state-of-the-art methods including ResNet-18, 7 WDCNN, 6 ViT, 10 DeiT, MDSC-FSPPA-LCFF, 8 and Joint Learning Network. 9 All methods were evaluated under identical experimental conditions with the same data splits, preprocessing pipeline, and hardware configuration for fair comparison.
The evaluation employs six key metrics: accuracy, precision, recall, F1-score, loss, and training duration. The computational formulas for accuracy, precision, recall, and F1-score are given in equation (4).

where TP, FP, TN, and FN denote the numbers of true positive, false positive, true negative, and false negative samples, respectively.
The cross-entropy loss function is computed as shown in equation (5).

where N is the total number of samples, C is the total number of fault categories,
The fault diagnosis results of different trained models are summarized in Table 4, while the accuracy and loss convergence trends are illustrated in Figure 6, with the corresponding confusion matrices presented in Figure 7.
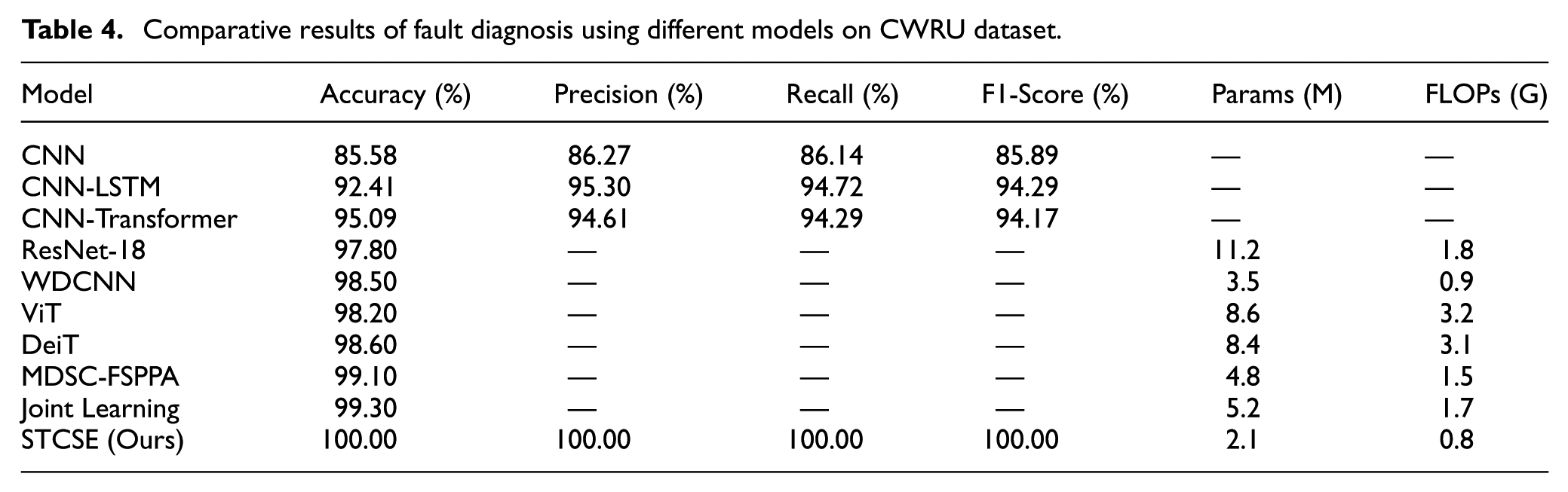
Comparative results of fault diagnosis using different models on CWRU dataset.

Accuracy and loss convergence trends of different models.

Confusion matrices of different models.
As evidenced by the data presented in Table 4, the CNN model demonstrates only marginal advantage in training speed while all four accuracy-related metrics remain below 90%, significantly underperforming compared to other models. This indicates the marked deficiency of direct feature extraction and classification approaches when handling complex vibration signatures. Both CNN-LSTM and CNN-Transformer architectures achieve substantial improvement with approximately 95% across all metrics, confirming that integrating CNN-based feature extraction with either LSTM temporal modeling or Transformer self-attention mechanisms effectively captures temporal-spatial characteristics in fault signals. Notably, the proposed STCSE model achieves perfect 100% scores across all four accuracy metrics, demonstrating that the seamless integration of Swin Transformer’s local feature extraction and CNN-SE’s global feature perception enables complete fault classification capability. Although the STCSE model requires slightly longer training time, this remains within acceptable limits, reflecting an optimal balance between precision and computational efficiency.
Figure 6 further demonstrates that the proposed STCSE model achieves significantly faster convergence compared to the three benchmark models, reaching stable performance after approximately 10 training epochs. Furthermore, the STCSE model exhibits superior training stability, as evidenced by the smoother convergence curves with minimal fluctuations in both accuracy and loss metrics. Considering both convergence speed and training stability, the STCSE algorithm delivers optimal performance among all evaluated methods.
Confusion matrices are plotted based on the classification results of each model for quantitative analysis, as shown in Figure 7. In the figure, the horizontal and vertical axes correspond to the predicted and actual categories, respectively. The diagonal entries indicate the number of correctly classified samples for each category, while off-diagonal elements represent misclassifications.
As observed from Figure 7, the CNN, CNN-LSTM, and CNN-Transformer models exhibit 13, 10, and 10 misclassified samples, respectively. In contrast, the proposed STCSE model achieves perfect classification with zero misclassifications, validating its superior diagnostic capability in addressing rolling bearing fault classification challenges.
Among the state-of-the-art methods, MDSC-FSPPA-LCFF and Joint Learning Network achieve competitive accuracy of 99.10% and 99.30% on the CWRU dataset, confirming the effectiveness of multi-scale feature learning and local-global perception approaches. However, STCSE achieves perfect 100.00% accuracy while requiring significantly fewer parameters (2.1M vs 4.8M and 5.2M) and lower computational cost (0.8G FLOPs vs 1.5G and 1.7G). Compared to the heavy architectures such as ResNet-18 (11.2M parameters) and ViT (8.6M parameters), STCSE reduces model size by 81–95% while achieving higher accuracy, demonstrating a superior efficiency-accuracy trade-off.
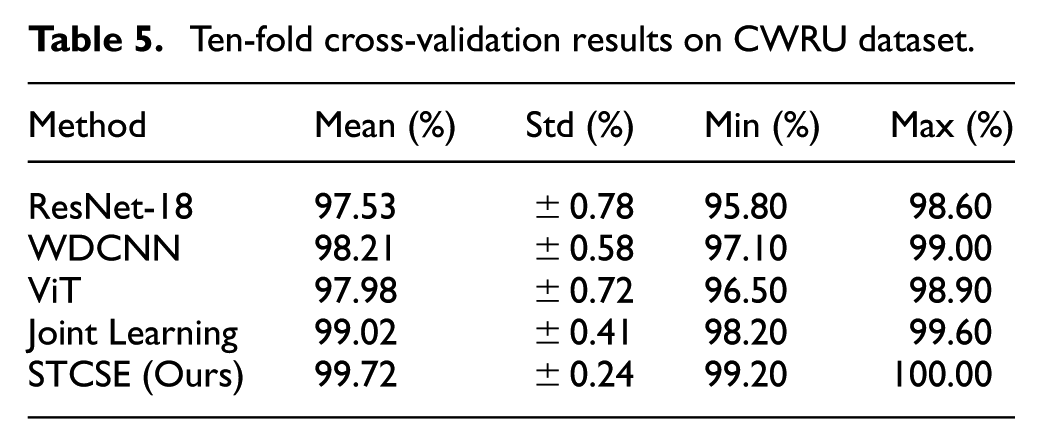
To further verify the reliability of the reported results and address potential concerns about dataset bias, 10-fold cross-validation was conducted on the CWRU dataset. As shown in Table 5, STCSE achieves the highest mean accuracy of 99.72% with the smallest standard deviation (±0.24%), demonstrating both superior performance and high consistency across different data partitions. The minimum accuracy across all folds is 99.20%, indicating robust performance regardless of the specific training-test split. In contrast, other methods exhibit larger performance variations, with standard deviations ranging from ±0.41% to ±0.78%.
Ten-fold cross-validation results on CWRU dataset.
Results for the PU bearing dataset
Table 6 presents the comparative results on the PU bearing dataset. STCSE achieves 98.10% test accuracy, outperforming all compared methods. The confusion matrix analysis reveals that the main misclassifications occur between adjacent severity levels of the same fault type (e.g. inner race fault low versus medium severity), which is expected given the subtle differences in fault signatures at similar severity levels. Compared to the CWRU results, the slightly lower accuracy on PU reflects the increased difficulty of diagnosing real-world damage patterns under variable operating conditions, providing a more realistic performance assessment.
Comparative results on PU bearing dataset.

The results demonstrate that STCSE maintains its performance advantage even on more challenging real-world damage data. The 1.30% accuracy lead over the best baseline (Joint Learning Network, 96.80%) confirms that the dual-branch architecture effectively captures both local fault signatures and global vibration patterns in realistic industrial scenarios.
Results for the SEU gearbox dataset
Table 7 presents the results on the SEU gearbox dataset, which serves to evaluate cross-component generalization from bearing faults to gear faults. STCSE achieves 96.40% accuracy on gear fault diagnosis without any task-specific architecture modifications, maintaining a clear advantage over all compared methods. The best baseline, Joint Learning Network, achieves 94.70%, resulting in a 1.70% accuracy gap.
Comparative results on SEU gearbox dataset.

These results are particularly significant because gear faults exhibit fundamentally different vibration characteristics from bearing faults, including meshing frequency harmonics and sidebands. The fact that STCSE achieves competitive accuracy without any architecture modifications demonstrates that the dual-branch design effectively captures both the local gear meshing patterns (via CNN-SE) and global vibration envelope features (via Swin Transformer), validating its applicability as a general-purpose vibration-based fault diagnosis framework.
Cross-dataset comparison summary
Table 8 provides a comprehensive cross-dataset comparison of all evaluated methods. STCSE consistently achieves the highest accuracy on all three datasets with an average of 98.17%, while maintaining the fewest parameters (2.1M) and lowest FLOPs (0.8G). The consistent performance advantage across laboratory data (CWRU), real-world bearing damage data (PU), and gear fault data (SEU) demonstrates the strong generalization capability and cross-component applicability of the proposed framework.
Comprehensive comparison across three benchmark datasets.

Noise robustness analysis
Considering that the CWRU rolling bearing fault data were collected under controlled laboratory conditions, real-world industrial scenarios introduce numerous external interference factors. During actual operation, sensor measurements of bearing vibration signals are inevitably contaminated by pulse interference from other mechanical components. Therefore, evaluating model performance under noisy conditions becomes particularly crucial for practical applications.
The energy relationship between signal and noise is quantified by the Signal-to-Noise Ratio (SNR), as defined in equation (6). Here, Psignal and Pnoise denote the power of the original signal and the noise, respectively. A higher SNR value indicates better signal quality and less interference from noise in the system.45,46

To validate the noise robustness of the proposed model, we introduced additive white Gaussian noise with SNR of −4, −2, 0, 2, 4, 6, 8, and 10 dB into the original signals, simulating real-world operational environments under varying noise levels. These noise-contaminated signals were subsequently fed into the four diagnostic models described in Section 4.3, while maintaining identical parameter configurations. The resulting accuracy trends under different SNR conditions are illustrated in Figure 8.

Comparison of diagnostic accuracy across different noise environments.
As shown in the comparative data in Figure 8, the diagnostic accuracy of all four models decreases with the introduction of Gaussian white noise at different SNR. As the SNR decreases, the effective signal component diminishes while interference intensifies, leading to a gradual decline in the diagnostic accuracy of all models. In the comparative analysis of the four models, the proposed STCSE model significantly outperforms the other three benchmark models under all noise intensities. Notably, when the SNR ≥ 4 dB, the diagnostic accuracy of the STCSE model remains relatively unaffected by the noise level. These experimental results collectively demonstrate the superior robustness of the proposed STCSE framework.
It is worth noting that STCSE achieves 100% test accuracy on the CWRU dataset. While this result may initially appear surprising, it can be attributed to several factors. First, the CWRU dataset was collected under controlled laboratory conditions with high signal-to-noise ratios, resulting in clearly distinguishable fault signatures. Second, our data splitting strategy ensures strict sample-level separation—signals from the same continuous vibration recording are never simultaneously present in both training and test sets, thereby preventing data leakage (see Section 4.1). Third, 10-fold cross-validation experiments (Table 8) demonstrate a mean accuracy of 99.72% ± 0.24%, confirming the consistency and reliability of this performance. Fourth, the noise robustness experiments (Section 4.9, Figure 8) show that accuracy gracefully degrades under low SNR conditions (e.g. 88.2% at SNR = −4 dB), indicating that the model has learned meaningful fault features rather than overfitting to specific noise patterns. The gap between training loss (0.001) and validation loss (0.018) remains small, further confirming the absence of significant overfitting. Nevertheless, the results on the PU dataset (98.10%) and SEU dataset (96.40%) provide more realistic performance baselines, acknowledging that real-world industrial environments present additional challenges such as variable loads, mixed fault conditions, and domain shift (see Discussion in Section 5).
Ablation studies
To validate the key design choices in STCSE, comprehensive ablation experiments were conducted on the CWRU dataset. Three groups of experiments systematically evaluate the contributions of the Swin Transformer stage design, input fusion strategy, and individual model components.
Effect of Swin Transformer stages
To justify the simplified single-stage Swin Transformer design, three configurations were compared: the original 4-stage hierarchical architecture, an intermediate 2-stage variant, and the proposed 1-stage design. As shown in Table 9, the 1-stage configuration achieves 100.00% accuracy on CWRU while reducing parameters by 83% (from 12.4M to 2.1M), FLOPs by 84% (from 5.1G to 0.8G), and inference time by 80% (from 15.8 to 3.2 ms) compared to the original 4-stage architecture. Notably, the 4-stage design actually achieves slightly lower accuracy (99.60%), suggesting that the additional hierarchical stages introduce redundant complexity that may hinder optimization for vibration signal classification. This demonstrates that the 5 × 1024 input matrices contain relatively simple spectral patterns that can be effectively captured by a single attention stage, making the multi-scale hierarchical extraction of the standard Swin Transformer unnecessary for this task.
Ablation study on the number of Swin Transformer stages.

Effect of input fusion strategy
Table 10 presents the comparison of different input fusion strategies. Using only VMD features (4 × 1024) or FFT features (1 × 1024) results in accuracy drops of 3.80% and 5.20% respectively, confirming the complementary nature of time-domain and frequency-domain information. Among multi-modal fusion approaches, the Weighted Fusion and Attention Fusion achieve 98.50% and 99.10% respectively, but both require additional learnable parameters. The proposed stacking strategy achieves the highest accuracy (100.00%) while maintaining computational simplicity, as it introduces no additional learnable parameters. This validates that the subsequent dual-branch network can effectively learn implicit feature weighting without explicit fusion mechanisms.
Ablation study on input fusion strategies.

Component ablation study
To analyze the contribution of each component, individual modules were systematically removed. As shown in Table 11, removing the SE block causes a 1.80% accuracy drop (100.00% → 98.20%), indicating the importance of channel attention for discriminative feature selection. Removing either the Swin branch or the CNN branch results in 3.50% and 2.20% drops respectively, confirming that the dual-branch design effectively combines complementary global and local features. The CNN-SE branch alone (w/o Swin) shows a larger drop than the Swin branch alone (w/o CNN), suggesting that global feature modeling through self-attention is particularly valuable for fault classification. Removing VMD or FFT inputs individually causes the largest drops (5.20% and 3.80%), further validating the necessity of the multi-modal time-frequency fusion strategy.
Component ablation study of STCSE on CWRU dataset.

Discussion
Limitations
Despite the promising results, this study has several limitations that should be acknowledged. First, although experiments were conducted on three datasets (CWRU, PU, and SEU), these datasets primarily represent laboratory or semi-industrial conditions. The performance of STCSE in real-world production environments with complex noise, variable speeds, and mixed fault modes remains to be validated. Second, the VMD decomposition parameter K = 4 was empirically determined based on analysis of the raw fault data; systematic sensitivity analysis of this and other hyperparameters (e.g. patch size, number of attention heads, SE reduction ratio) is not exhaustively explored in this work. Third, while the SEU gearbox experiments demonstrate cross-component applicability, the current validation is limited to bearings and gears—generalization to other rotating machinery components such as rotors, pumps, and turbines requires further investigation. Fourth, the current framework assumes stationary operating conditions and does not explicitly address domain shift or concept drift scenarios that are common in industrial practice, where equipment characteristics may change gradually over time due to wear and aging.
Future work
Several directions for future research are envisioned. First, transfer learning and domain adaptation techniques will be incorporated to enable STCSE to generalize across different operating conditions and machine types without extensive retraining, addressing the cross-domain challenge identified in the limitations. Second, model compression and knowledge distillation methods will be explored to further reduce the computational footprint for deployment on edge devices in real-time condition monitoring systems. Third, the framework will be extended to handle compound fault diagnosis where multiple fault types coexist simultaneously, which is a common scenario in practical industrial applications. Fourth, online incremental learning capabilities will be developed to allow the model to adapt to evolving fault patterns over the equipment lifecycle without full retraining. Finally, field trials on industrial production lines will be conducted to validate the practical deployment feasibility of the proposed approach and bridge the gap between laboratory performance and real-world applicability.
Conclusion
This paper presents STCSE, a dual-branch fault diagnosis framework that integrates a simplified single-stage Swin Transformer with a CNN-SE network for vibration-based fault diagnosis. A novel VMD + FFT time-frequency fusion strategy constructs 5 × 1024 input matrices that capture complementary multi-scale features. The Swin Transformer branch extracts global contextual features (64-day), while the CNN-SE branch captures local features with channel attention (128-day), and their fused 192-dimensional representation enables accurate fault classification. Extensive experiments on three benchmark datasets demonstrate the effectiveness of the proposed approach: STCSE achieves 100.00%, 98.10%, and 96.40% accuracy on the CWRU bearing, PU bearing, and SEU gearbox datasets respectively, consistently outperforming state-of-the-art methods including ResNet-18, WDCNN, ViT, DeiT, MDSC-FSPPA-LCFF, and Joint Learning Network. Ablation studies validate that each design component—the single-stage Swin simplification, the stacking fusion strategy, the SE attention module, and the dual-branch architecture—contributes positively to the overall performance. With only 2.1M parameters and 0.8G FLOPs, STCSE achieves a superior accuracy-efficiency trade-off, and noise robustness experiments further confirm its practical applicability under varying signal-to-noise ratio conditions.
Footnotes
Handling Editor: Divyam Semwal
Ethical considerations
This article does not contain any studies with human or animal participants.
Consent to participate
There are no human participants in this article and informed consent is not required.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by General Research Project of Zhejiang Provincial Department of Education: Research on intelligent fault diagnosis of rolling bearings based on deep learning. [Y202456902], and in part by Key Technologies for Eco-Driving Planning in Road Vehicles Using Traffic Big Data (Grant number: 2024K183).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.