
Abstract
Accurate prediction of rolling bearings’ Remaining Useful Life (RUL) is critical for ensuring machinery reliability and safety. While deep learning offers considerable potential, prevailing prognostics models face significant challenges: they often overlook critical inter-sensor correlations, exhibit instability in long-term predictions, and demand extensive training data. These limitations severely hinder their efficacy in data-scarce or informationally redundant scenarios. To overcome these issues, this paper introduces a novel hybrid architecture that synergistically integrates Convolutional Neural Networks (CNNs) with the Informer model. The proposed framework is engineered to autonomously extract and fuse salient nonlinear spatiotemporal features from multi-sensor data streams. Raw sensor signals are first segmented via a sliding window approach to preserve degradation characteristics. Subsequently, stacked convolutional layers hierarchically learn high-level representations, effectively capturing both intra- and inter-sensor dependencies. These enriched features are then processed by the Informer module for efficient time-series encoding and long-term dependency modeling, ultimately yielding a precise RUL estimate through a fully-connected layer. Extensive experimental results on rolling-element bearing datasets demonstrate the superiority of our method. It achieves state-of-the-art prediction accuracy and markedly superior stability over time, even when trained with significantly reduced dataset sizes, confirming its robustness and practical utility.
Introduction
Rolling bearings are called the “joints of industry,” 1 and the researcher is similar to a “doctor” who analyzes the state of the bearing at the moment through sensor data. According to statistics, about 40%–45% of the annual mechanical failure are due to bearing damage, 2 so it is important to accurately predict the point in time when the failure occurs to avoid safety accidents and improve equipment safety.
In recent years, scholars at home and abroad have focused on rolling bearing life prediction research and proposed different methods based on modeling, based on data, and based on digital twin.3,4 Data models can abstract complex problems and concisely express data relationships to improve data comprehensibility; at the same time, data model ensures that data is consistent across scenarios and can also reduce redundancy and conflict. Therefore, this paper explores data-driven approaches that enable more efficient and accurate data processing and analysis. In addition, recent studies have extended machine learning and neural network–based approaches to fatigue life and reliability prediction problems in various engineering domains, including gearbox reliability assessment, defect-driven fatigue life modeling, and physics-informed neural network–based life prediction frameworks. These works further demonstrate the effectiveness and flexibility of data-driven and hybrid learning approaches for complex life prediction tasks.5–7 Addressing the problem that multi-layer perception (MLP) cannot automatically learn salient features, Peng et al. 8 considered how to address the persistent challenges of vibration signals being inevitably contaminated by noise interference and extracted features containing redundant or irrelevant information, proposing a novel hybrid feature extraction method based on Adaptive Sparse Narrowband Decomposition (ASND) and Locality Preserving Projection (LPP). This approach was then integrated with a Least Squares Support Vector Machine (LS-SVM) for Remaining Useful Life (RUL) prediction, significantly improving prognostic accuracy in experimental validation. Liu et al. 9 considered to address the challenge of remaining useful life (RUL) prediction for aero-engine rolling bearings, proposing a novel data-driven prognostic method combining deep learning with particle filtering. This approach demonstrates superior prediction accuracy and enhanced stability, while being less susceptible to variations in particle numbers or resampling methods compared to conventional techniques. More importantly, it better captures the evolutionary trends of rolling bearing degradation. Wang et al. 10 considered to overcome interference from noise and other disruptive signals, proposing a novel remaining useful life (RUL) prediction method for rolling bearings based on improved empirical wavelet transform (IEWT) and one-dimensional convolutional neural networks (1D-CNN). The proposed model demonstrates superior prediction accuracy compared to existing approaches, as evidenced by reduced mean absolute error (MAE) and root mean square error (RMSE). Wang et al. 11 considered the problems of gradient dissipation and gradient explosion in long-term time series prediction, and established a Long Short-Term Memory (LSTM) network model to realize the time series prediction of rolling bearing signals. Wang et al. 12 addressed the problem that the model could not effectively recognize different sensor data, and proposed a multiscale learning strategy to automatically learn the representations of different time scales to realize regression analysis and RUL estimation. Although deep learning has achieved relatively excellent results in RUL prediction of bearings, the existing prediction methods have the following limitations. (1) In representation learning, the correlation between sensors are not adequately considered. The data from sensors in a certain range at the current moment is inevitably influenced by the data from other sensors at previous moments, but if the representation learning model does not take into account this spatio-temporal correlation, it can lead to omission. (2) During the training process, a large amount of data is required to train the model. The amount of data in model training will directly affect the prediction accuracy, yet acquiring a substantial amount of data can be highly challenging under certain specialized operating scenarios. Therefore, how to train models with limited training data becomes a pressing issue. (3) The current prediction of bearing life cannot achieve long-term stable prediction. The main reasons include complex and variable influencing factors. Environmental and usage conditions are difficult to measure accurately. There are also issues with data acquisition and processing. Consequently, to enhance the accuracy and stability of bearing life prediction, it is necessary to optimize data processing and analysis methods in order to develop more advanced and stable prediction models.
To address these limitations, this paper improves the Informer network for RUL prediction of bearings. The feature fusion extraction module (abbreviated as FFE for ease of representation) enables monitoring data from different sensors to be used directly as input to the prediction network. By adopting the method of equal-volume data segmentation, it can capture the subtle changes in bearing degradation more meticulously, thus preserving more nonlinear degradation information. Additionally, the feature fusion extraction module allows for the fusion of multi-sensor signals to enhance degradation information. Meanwhile, based on the convolution operation, time encoding is injected, and multiple high-level features are combined in a parallel way to generate the final interpretation results. This process comprehensively utilizes various feature information, improves the model’s ability to identify bearing degradation states and prediction accuracy, and achieves RUL prediction for rolling bearings. Additionally, it can also achieve high-precision RUL prediction with a limited amount of data.
Organization of the model
The model consists of two parts, the Feature Fusion Extraction (FFE) module and the prediction network Informer (Abbreviated as FFE-Informer), as shown in Figure 1. Deep learning faces various problems such as under-utilization of degradation information between different sensors, high demand of training data and inability to achieve long time prediction in the remaining useful life prediction. To address these issues, we employ a series of measures. First, we utilize a convolutional neural network to preprocess the degradation information from different sensors in order to preserve the rich nonlinear features. Second, we perform equal segmentation of the data to enrich the labeled data and maintain high prediction accuracy even with small samples. This model successfully solves the fusion of degraded signals from different sensors and maintains high accuracy with reduced training data samples. In the model, the original input signal is cropped, the cropped signal is used to extract the time domain features, and then the cropped signal is subjected to Fast Fourier Transform to extract the frequency domain features. Finally, these features are passed to the Informer network for training and used for remaining useful life prediction.

Structure of the model.
Feature fusion extraction module (FFE module)
The Feature Fusion Extraction (FFE) module mainly consists of Convolutional Neural Network 13 (CNN) as shown in Figure 2. Convolutional neural network (CNN) is a kind of network for efficiently processing multidimensional data. It is a feed-forward neural network, which mainly consists of convolutional layer, pooling layer, and fully connected layer. 14 In bearing life research, Wang et al. 10 proposed a novel method for predicting the remaining useful life (RUL) of rolling bearings based on an Improved Empirical Wavelet Transform (IEWT) and a 1D Convolutional Neural Network (1D-CNN), which was validated by promising experimental results. However, there is still insufficient fusion of degraded information from different sensors. Therefore, this paper proposes a feature fusion approach to achieve the fusion of degradation information between different sensors.

Feature fusion extraction module (FFE).
Specifically in the text, the cycle time series data

Where

Where
The ReLU activation function is added after the convolution in order to increase its nonlinear fitting ability during the training process. The formula is as follows:

To improve computational efficiency, the data is optimized using maximum pooling, and the feature mapping state of the j-th step in the i-th pooling layer is:

Where
During the normal operation of rolling bearings, the bearings undergo damage due to rolling contact fatigue. When the damaged parts come into contact with other parts, impacts are formed. Consequently, the vibration signals of rolling bearings contain a wealth of information. 16 Compared to time domain information, frequency domain information can effectively remove white noise. Therefore, Fourier transform is applied to the data processed by CNN, and the following is the transformation formula:

Where n = 1, 2, …, N−1,
The training samples are trained by CNN to get degenerate features. During the training process, the ReLU activation function is added after convolution to increase the nonlinear fit. The following is the transformation formula:
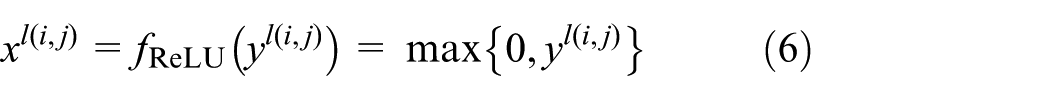
Where

Where
Informer module
The Informer model is a lightweight model improved from the Transformer. 17 In data-driven rolling bearing RUL prediction, Long Short-Term Memory (LSTM), 11 the Transformer model, and others are the mainstream models for prediction. However, the aforementioned models are limited to predicting shorter time series, which can significantly constrain the computational efficiency and prediction accuracy when dealing with long series prediction.
The Informer model 18 consists mainly of the Encoder and the Decoder. The Encoder receives a large number of long sequence inputs and replaces canonical self-attention with ProbSparse self-attention. The computation is optimized for computational efficiency by finding important queries. In canonical self-notation by query, key, and value are denoted by Q, K, and V for these three matrices respectively. For more explicit representation, this paper takes the i-th row in Q, K, and V. Then the i-th query attention can be defined as:

Where
Next, we define the query coefficient criterion:

Remove the constant and define the i-th query sparsity measure as:

Where the first term is the logarithmic sum of all keys and the second term is the arithmetic mean of all keys.
Importance of sparse self-attention mechanism: sparse multi-head self-attention mechanism is mainly used in image recognition aims to improve foreground-background discrimination and reduce edge region ambiguity. 19
The encoder aims to extract the robustness and long-term dependence of long sequence inputs. Let the t-th sequence input be

Where AB denotes the attention block. It contains the multi-head probabilistic sparse self-attention and the basic operation.

Individual encoder operation.
The remaining useful life prediction framework of the total model is shown in Figure 1. The Informer network has the ability to process the state of the monitored data for a longer period of time and perform long time series prediction. Its main functions include focusing on processing feature information, mining temporal correlations in hidden data, and updating parameters automatically to improve prediction accuracy.
It should be clarified that this study adopts the original ProbSparse attention mechanism and its threshold setting from the Informer model without modification. The improvement proposed in this work lies in the introduction of the FFE feature fusion extraction module and the task-oriented RUL prediction framework, rather than changes to the internal attention threshold function.
Analysis of feature extraction and fusion
Typically, statistical features such as mean, variance, standard deviation, etc. are often used as inputs in time series data processing by extracting the mean, variance, standard deviation, etc. from the time and frequency domains. To clarify the motivation for introducing statistical features, it should be noted that bearing vibration signals are typically non-stationary and contain significant noise and operating-condition interference. In raw waveform form, degradation-related changes are not always sufficiently stable or prominent, especially in early degradation stages. Statistical features computed over signal segments can provide more stable and compact representations of signal variation trends.
In this work, statistical features are not used as a replacement for raw vibration signals, but as complementary degradation descriptors. Together with FFT-based frequency-domain features and multi-direction vibration inputs, they are fused in the FFE module to form a more informative feature representation. This fused representation helps the prediction network focus on degradation-related characteristics and improves the stability and effectiveness of RUL prediction.
However, this method still suffers from the problem of insufficient information mining. To solve this problem, we simultaneously utilize vibration information recorded by multiple sensors. Since bearing degradation is inevitable, this paper takes the XJTU-SY dataset 20 as an example. Therefore, maximizing the degradation characteristics will help to accurately predict the remaining service life of the bearings.
To this end, a FFE module is introduced to enrich the data and make it more representative. The FFE module performed CNN convolutional processing and statistical feature extraction on the raw vibration signals, and added moment information at each minute interval. Specifically, CNN employs a smoothing window to smooth the data at a specific stride, subsequently enhancing the representativeness of a moment’s features through upscaling and downscaling.
The processing of the FFE module is performed as follows: a single sampling of the vibration signal X is performed with the smoothing window operation on the time domain signal and the frequency domain signal, and then the data are transformed by convolution, pooling and nonlinear transformation. At the same time, some statistical features commonly used in rolling bearing RUL prediction are selected as degradation features, and the specific information is shown in Table 1. Where:
Characteristics and their formulas.

The XJTU-SY dataset 20 collected the acceleration signals in the horizontal and vertical directions during the operation of rolling bearings. In the study of remaining bearing life, the horizontal acceleration signal is mainly usually the main focus. However, the vertical and horizontal acceleration signals also contain a large amount of bearing life information. Therefore, in this paper, the horizontal and vertical acceleration signals are combined with each other. The horizontal signal serves as the main signal, while the vertical signal functions as the auxiliary. It can be expressed as:

Where F is the fusion feature,

The value of α: (a) Bearing1_1, (b) Bearing2_3, and (c) Bearing3_2.
It is clearly observed through the experimental results that adjusting the fusion ratio of data from different sensors significantly improves the accuracy of the prediction results, thus enhancing the robustness of the model and proving its effectiveness in the overall network.
Before model training, the raw vibration signals are first segmented into fixed-length samples for feature construction and network input. For each signal segment, time-domain statistical features are computed, and FFT is applied to obtain frequency-domain features. These features, together with multi-direction vibration signal inputs, are used to form the fused feature representation in the FFE module.
To improve training efficiency and increase the number of labeled samples, the original long signal sequences are divided into multiple equal-length segments. Segments originating from the same time interval are assigned the same RUL label, so that each constructed sample corresponds to a supervised RUL target value.
The proposed framework performs RUL regression rather than multi-step time-series forecasting. After feature fusion and sequence modeling by the Informer network, the output is mapped through a fully connected layer to produce a single RUL prediction value for each input sample.
It should be noted that assigning a static RUL label to segmented samples is an approximation, whose validity depends on the assumption that the segment window is sufficiently short such that the RUL variation within a segment is limited. When degradation evolves rapidly or the segment window is relatively long, a potential label drift effect may occur. In this work, multi-source feature fusion in the FFE module enhances degradation-sensitive representations and can mitigate the impact of this approximation to some extent; however, more refined label modeling to explicitly address label drift is beyond the scope of the present study and will be explored in future work.
Experimental validation
We will conduct extensive experiments on datasets with the XJTU-SY dataset 20 and the PHM2012 dataset. 21 The above datasets have three different working conditions. The dataset mentioned above comprises three distinct working conditions. The subsequent comparison is made among four models—Informer, Informer Stack, FFE-Informer, and FFE-Informer Stack in terms of their predicted outcomes for the full lifespan data across these three working conditions.
Introduction to the bearing dataset
XJTU-SY bearing dataset as the basis for analysis
The XJTU-SY bearing dataset is openly released for scholars around the world. It has a sampling frequency of 25.6 kHz, a sampling interval of 1 min, and a sampling duration of 1.28 s. It records the complete life cycle data and can be used for model-based and data-driven residual useful life prediction. The experimental platform is shown in Figure 5.

Testbed of rolling element bearings.
It provides real experimental data to characterize the degradation over the entire life cycle. Taking Bearing1-1 and Bearing2-2 as an example, their horizontal and vertical raw acceleration signals are depicted in Figure 6. The 123-sampled raw data of Bearing1-1 are subjected to CNN processing, and then their feature data are extracted. The feature map is plotted into a 3D map as shown in Figure 8.

Horizontal and vertical signal vibration diagram: (a) Bearing 1_1horizontal signal, (b) Bearing1_1vertical signal, (c) Bearing 2_2horizontal signal, and (d) Bearing2_2vertical signal.
PHM2012 bearing data set
The PRONOSTIA platform can address issues that include testing, validation, bearing health assessment, diagnosis, and prognosis. The primary aim of the experiment is to validate real-world data pertaining to accelerated bearing degradation. The platform is shown in Figure 7. A radial force equal to the maximum dynamic load of the bearing of 4 kN is applied to the bearing under test, and the bearing is subjected to accelerated degradation tests over a period of several hours. The bearing speed was maintained at approximately 1800 revolutions per minute. The sampling frequency was 25.6 kHz. Each sample contained 2560 data points and was repeated every 10 s. When the amplitude of the vibration signal surpasses 20g, it indicates that the bearing has reached the end of its lifespan (Figure 8). 21

The PRONOSTIA platform.

Three-dimensional diagram of features.
It should be noted that for the PHM2012 dataset, the failure time and RUL labels are generated following the commonly used test-bench criterion (vibration amplitude exceeding 20g), in order to maintain a consistent label definition and ensure comparability with prior studies. Using a different threshold would shift the failure time earlier or later, thereby changing the endpoint definition and distribution scale of the RUL labels, which may further affect the training target and generalization behavior of the model. In this work, we follow the standard setting for PHM2012; a systematic sensitivity analysis with respect to different thresholds will be considered in future work.
Prediction metrics
In order to evaluate the prediction performance of FFE-Informer, two prediction metrics are used in this paper, Mean Square Error (MSE) and Mean Absolute Error (MAE). 22 MSE can be used to evaluate the accuracy of a prediction algorithm under instances given RUL prediction results. The specific expression is given below: therefore does not reflect the distribution of the errors. Its formula is:

Where
MAE (Mean Absolute Error) is the average of the absolute values of the errors, MAE is not sensitive to outliers and

Where
Network parameter configuration for FFE
The hyperparameters that need to be set for the proposed FFE model include the cut length
FFE parameter configuration.

The time window contains a large amount of degradation information. In particular, this performance improvement is related to the time window size. Bearing1-1, Bearing2-2, and Bearing3-5 in the XJTU-SY dataset are used as examples for discussion. In this paper, the impact of different cutting window sizes on the prediction performance is first analyzed. Their sizes are set to 64, 128, 256, and 512. Accordingly, the box plots of MSE and MAE for the three tested bearings are shown in Figure 9(a)–(c), where (a), (b), and (c) correspond to Bearing1-1, Bearing2-2, and Bearing3-5, respectively. It can be seen in these box plots that the predictive ability of the model can be improved by appropriately increasing the window. Therefore, the time information of bearing degradation can be aggregated by appropriately enlarging the window. The prediction results of RUL under four different window sizes are shown in the figure. From these box plots, it can be seen that the MSE and MAE values are smoother when the time window is increased in a certain range, which means that the prediction performance of FFE-Informer can be effectively improved by increasing the time window size. However, it should be noted that as the time window size increases, the accuracy will go into a larger range of fluctuations up and down, but since larger time window sizes produce high-dimensional input vectors, more memory storage and computation time is required. Based on the above analysis, a time window size of 256 is suitable for the RUL prediction of bearings.

Box plots of MSE and MAE for the three tested bearings under different time window sizes: (a) Bearing1-1, (b) Bearing2-2, and (c) Bearing3-5.
Experimental results
In this section, long time series prediction of FFE-Informer is studied and discussed by performing bearing RUL estimation. Firstly, the effect of cutting window size on prediction accuracy and reduction of training datasets is analyzed. Then, the benefits of Informer are discussed and a comparison between FFE-Informer and other advanced forecasting methods in long time forecasting is presented to illustrate its superiority. In particular, the MSE and MAE for each bearing in the test datasets are calculated from halfway through the life cycle to the end, as the predictions for these check time instances are more reliable and meaningful than earlier ones. 23
Impact of training set share on prediction accuracy
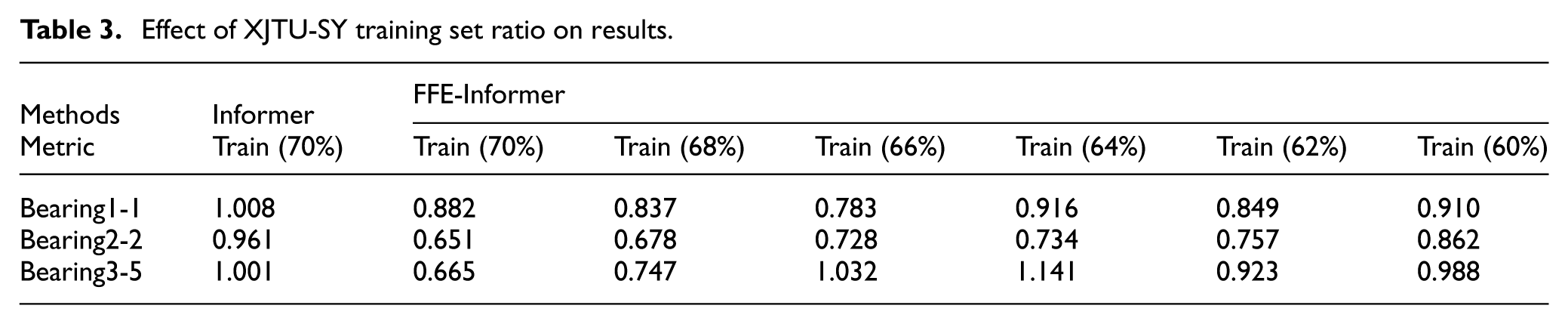
The size of the training data will have a direct impact on the knowledge and quality that the algorithm can learn, as follows: (1) Typically, improving the training set will improve the accuracy of the algorithm. (2) When the training set is too small, the algorithm is prone to underfitting resulting in poor prediction on new data. And when the training set is too large, the algorithm is prone to overfitting, meaning it learns the specific details of the training data too well and may not generalize well to new data. (3) As the size of the training set increases, the training time of the algorithm increases accordingly. Experiments conducted with various datasets have demonstrated that the FFE module maintains its effectiveness in terms of accuracy even when the amount of data is reduced. The MAE representation will be used to illustrate this, employing a test set of 20% and a training set of 10% respectively, with a prediction length of 128. The resulting data is presented in Table 3. Based on the experimental results from the XJTU-SY dataset, it can be observed that the model, after incorporating the FFE module, can achieve an accuracy that is comparable to or even lower than the Informer model’s direct prediction accuracy, despite reducing the training data by 10%. Therefore, the FFE module is effective in training with reduced training set. To make the model more convincing, we will demonstrate the applicability of the model by performing further validation on the PHM2012 dataset. Validating a model using another datasets are an important practice to be able to assess the generalization ability and applicability of the model. By testing the model on different datasets, we can verify its performance in various situations and confirm its validity in the real world. By testing the model on different datasets, we can validate performance in various situations and confirm effectiveness in the real world. The training data is shown in Table 4, and it can be seen from the experimental data that it is still valid. Therefore, the model proposed in this paper according to the existence of general applicability. In order to reduce the time, the prediction length in Table 4 is set to 24. Based on the data presented in the table, it can be observed that the prediction accuracy of the FFE network remains steady and maintains a high level even when the amount of data in the training set is reduced.
Effect of XJTU-SY training set ratio on results.
Effect of PHM2012 training set ratio on the results.

It should be noted that the statement regarding “stable performance” under reduced training data is based on the overall trend observed in the reported results, and does not imply statistical non-significance. Since repeated runs and formal significance tests (e.g. paired t-test or Friedman test) were not conducted in this study, we have revised the wording accordingly to avoid over-interpretation.
It should be noted that the “small-sample” advantage discussed in this study is defined in a relative sense, based on the experimental setting where the training data ratio is reduced to 60%. The results indicate that the proposed FFE-Informer framework maintains stable prediction performance under comparatively limited training data conditions. This robustness is mainly attributed to the input-side feature fusion strategy, which integrates multi-direction vibration signals with statistical and frequency-domain features to provide more degradation-sensitive representations. More extreme data-scarce scenarios and comparisons with transfer learning or meta-learning strategies are beyond the scope of the present work and will be considered in future studies.
FFE analysis of long time series prediction results
This section examines and analyses the rolling bearing life prediction results from the XJZU-SY and PHM2012 dataset. In the XJZU-SY dataset, the model performs more stably in long series prediction after adding the FFE module, which improves the accuracy of prediction. In the PHM2012 dataset, the prediction accuracy is also improved after adding the FFE module. This indicates that the FFE module plays a key role in long series prediction and has a good effect on the progress of model prediction.
Comparative analysis in the XJZU-SY dataset and PHM2012 dataset
In order to prove the superiority of the proposed FFE network in long time series prediction, we adopted three methods applicable to such predictions, such as Informer et al., to predict the RUL of the tested bearings under three working conditions. As can be clearly seen from the table, with the increase of the prediction length, the loss error also rises. Evidently, the model performs much more stably in long time series prediction with the addition of the FFE network. It can be concluded that the FFE network plays a key role in the stability of model prediction in long series prediction, which also confirms superiority in long time prediction. Bearing1-1, Bearing2-2, and Bearing 3-5 are selected for analysis, and their results are shown in Table 5. From Tables 5 and 6, it can be clearly seen that the FFE module plays a more obvious role in the prediction. Taking a prediction length of 168 as an example, the MSE reflects that the accuracy rate of the bearings has improved by 42%, 36%, and 50% respectively, while the MAE suggests that the accuracy has been enhanced by 19%, 34%, and 33% respectively. Taking Bearing1-1 as an example, it can be observed from the results that the predicted value fluctuates slightly above and below the true value. As illustrated in Figure 10, there is a significant deviation between the estimated RUL and the actual RUL in the initial prediction stage, but this deviation gradually diminishes over time. This is because, in the initial phase, the bearings are in the break-in period with minimal wear. Consequently, capturing degradation characteristics and establishing an accurate correlation between monitoring signals and RUL is challenging at this stage. And as bearing wear increases, more degradation information can be captured by monitoring signals. Therefore, the proposed FFE-Informer can obtain highly accurate RUL prediction results.
Multivariate long series time series prediction results (XJZU-SY).

Multivariate long series time series prediction results (PHM2012).


Bearing1-1 prediction results: (a) RUL prediction and (b) feature prediction.
It is observed that the prediction error increases as the prediction horizon becomes longer, which is common in long-range sequence prediction tasks and is mainly caused by uncertainty accumulation and error propagation. With extended forecast ranges, indirect degradation cues and operating variability introduce additional uncertainty, leading to gradual error growth. This trend is qualitatively consistent with cumulative error effects similar to those discussed in random-walk–type processes, although bearing degradation is not strictly a random walk. In our framework, FFE-based feature fusion improves degradation representation and helps reduce, but not fully remove, long-horizon error accumulation.
Comparison with representative deep learning models
To further validate the comparative performance of the proposed model on public benchmark datasets, several representative deep learning models for time-series forecasting were selected as baseline methods for comparison, including the Long Short-Term Memory network (LSTM), the Gated Recurrent Unit network (GRU), and the Temporal Convolutional Network (TCN). These models have been widely adopted in remaining useful life (RUL) prediction studies and are considered representative and comparable baselines.
The comparison experiments were conducted on two publicly available bearing degradation datasets, namely the XJTU-SY dataset (Bearing1-1, Bearing2-2, Bearing3-5) and the PHM2012 dataset (Bearing1-6, Bearing2-3, Bearing2-7). To ensure fairness, all models were evaluated under a unified experimental configuration. The training ratio was set to 70%, the input window length was 256, and the prediction horizon was 168, following a multi-step RUL sequence prediction setting. The data preprocessing procedures and sample construction strategies were kept consistent across all models. The evaluation metrics were Mean Absolute Error (MAE) and Mean Squared Error (MSE).
The comparison results are presented in Tables 7 and 8. On the XJTU-SY dataset, the proposed FFE-Informer model demonstrates overall competitive performance compared with mainstream deep sequence models and achieves the best results under several bearing conditions. For example, it obtains the lowest MAE and MSE values on Bearing2-2 and reaches prediction accuracy comparable to the best-performing baseline on Bearing3-5, indicating good stability and adaptability across different degradation patterns.
RUL prediction performance comparison on XJTU-SY datasets.

RUL prediction performance comparison on PHM2012 bearing datasets.

On the PHM2012 dataset, the advantage of the proposed model is more pronounced. Under the Bearing2-3 and Bearing2-7 conditions, FFE-Informer achieves the lowest MAE and MSE among all compared models, showing significantly smaller prediction errors than LSTM, GRU, and TCN. Under the Bearing1-6 condition, it also maintains leading or near-best performance. Overall, the results indicate that the proposed model exhibits strong generalization ability and competitive performance across different datasets and degradation trajectories.
Depth ablation study of the front-end feature extractor
To further investigate the impact of the front-end feature extraction module depth on remaining useful life (RUL) prediction performance and model generalization ability, this study conducts a structural depth ablation analysis based on the proposed Feature Fusion Extractor (FFE) architecture. Several front-end variants with different convolutional depths are constructed to enable a systematic evaluation. The objective is to examine whether increasing the number of convolutional layers consistently improves prediction accuracy under an unchanged overall forecasting framework, and to analyze the stability of deeper structures under different training sample ratios.
In terms of architectural configuration, three front-end settings are designed for comparison: an Informer baseline model without a front-end convolutional extraction module, an FFE-2 configuration consisting of two convolutional layers and two pooling layers (used as the default setting in this work), and an FFE-4 configuration, which increases the convolutional depth to four layers while keeping the number of pooling layers unchanged. The FFE-4 variant is introduced as an extended structure with increased feature extraction capacity, aiming to isolate and evaluate the effect of convolutional depth on prediction performance.
The ablation experiments were conducted on two publicly available benchmark bearing degradation datasets, namely the XJTU-SY bearing dataset (Bearing1-1, Bearing2-2, Bearing3-5) and the PHM2012 dataset (Bearing1-6, Bearing2-3, Bearing2-7). All compared models were trained and evaluated under a unified experimental configuration to ensure fairness. The input window length was set to 256, and the prediction horizon was set to 168, following a multi-step RUL sequence forecasting setting. Two training ratios, 70% and 60%, were adopted to cover both regular-sample and limited-sample scenarios. The evaluation metrics were MAE and MSE computed in the normalized label space. Performance was consistently evaluated on the latter half of the degradation stage to better reflect realistic RUL prediction conditions. The corresponding results are reported in Tables 9 and 10.
Ablation results of different FFE depths on the XJTU-SY dataset.

Ablation results of different FFE depths on the PHM2012 dataset.
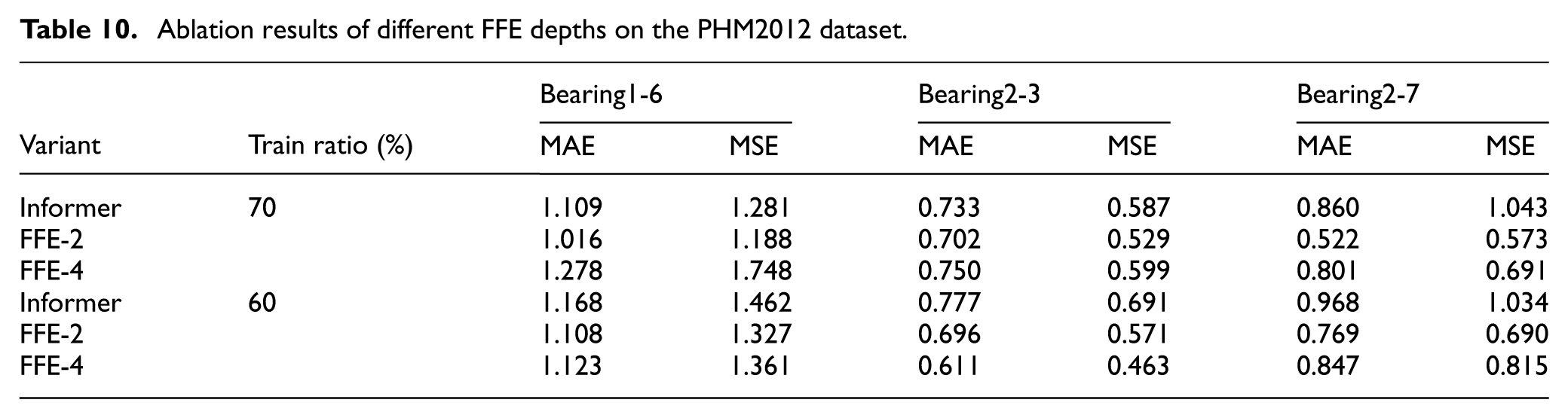
The experimental results show that introducing a front-end feature extraction module consistently improves prediction performance overall. The FFE-2 configuration achieves lower MAE and MSE values than the Informer baseline in most bearing cases across both datasets, indicating that lightweight convolutional feature extraction is beneficial for modeling vibration-based degradation sequences. However, when the convolutional depth is further increased to FFE-4, the prediction errors do not exhibit a consistent decreasing trend. Instead, performance degradation is observed on multiple bearing sequences, accompanied by reduced stability.
A further comparison under different training ratios reveals that when the training proportion decreases to 60%, the performance fluctuation of the FFE-4 configuration becomes more pronounced, whereas FFE-2 maintains relatively stable accuracy. This suggests that deeper front-end convolutional structures are more prone to overfitting under limited data conditions. This trend is consistently observed across both the XJTU-SY and PHM2012 datasets. Overall, the results indicate that for vibration time-series based RUL prediction tasks, a deeper front-end feature extractor does not necessarily lead to better performance. Instead, a moderately deep and lightweight convolutional structure achieves a more robust balance between predictive accuracy and generalization capability. Therefore, the FFE-2 configuration is adopted as the default front-end setting in this work.
Conclusion
In this paper, we improve a bearing RUL prediction framework using a model combination of CNN and Informer, referred to as FFE-Informer. The framework primarily utilizes degradation information gathered from various sensors and employs the FFE module to perform dimensionality reduction and expansion operations on the collected data. Immediately after that, we introduce temporal coding techniques to enhance the accuracy of long time series prediction by subtly incorporating temporal information into high-level features. Meanwhile, the sparse attention mechanism is employed to enhance attention to local and edge information, thereby further improving the prediction effect. Ultimately, these learned feature representations were input to the fully connected layer and we were able to accurately estimate the RUL. In order to validate the excellent performance of the FFE-Informer model, we conducted exhaustive experimental validation using the XJTU-SY dataset and the PHM2012 dataset, and made an in-depth comparison with the original model. The experimental results show that the FFE-Informer model exhibits high accuracy in predicting future long sequences. What is even more exciting is that it enables highly accurate RUL predictions using only a relatively small number of datasets. This is a great contribution to maintenance decision making.
Footnotes
Handling Editor: Divyam Semwal
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was mainly supported by The National Natural Science Foundation of China (No. U23A20631) and also supported by Scientific Research Innovation Capability Support Project for Young Faculty (No. SRICSPYF-BS2025023), The LiaoNing Revitalization Talents Program (No. XLYC2403117), The Joint Fund Project of Liaoning Science and Technology Department (No. 2024-MSLH-393).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
The figures and tables data used to support the findings of this study are included within the article, and the article permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.