
Abstract
A new triple-loop recurrent neural network (TLRNN) super-twisting terminal sliding mode control (TSMC) scheme based on the barrier function is proposed for the attitude tracking control of flight systems with unknown disturbances and parameter uncertainties. Compared with the traditional recurrent neural network (RNN), the newly designed TLRNN incorporates three different feedback loops, which improves the performance of approximation and enhances the capacity to save information. Additionally, the barrier function-based variable gain super-twisting algorithm is used to reduce chattering and dynamically adjust control gain. The finite-time convergence of a quad-rotor UAV system is derived using the Lyapunov function technique. The experiments, compared with existing methods, demonstrate the effectiveness of the proposed control strategy.
Keywords
Introduction
In recent years, quad-rotor UAVs have attracted a great deal of attention from researchers 1 due to their lightweight and high flexibility, which allows them to be used for specialized aerial operations, including the fighting forest fires, 2 inspecting crops, 3 monitoring routes, 4 tracking moving objects 5 and delivering material for military operations or disaster relief. 6 For the control of a quad-rotor UAV, we have to consider the multi-input and multi-output structure and the dynamics with parametric uncertainty. These characteristics have been studied, for example: adaptive tracking control of quad-rotor UAVs, 7 robust adaptive attitude tracking of quad-rotor UAVs. 8
In past research, several strategies have existed for attitude control of quad-rotor UAVs. These include linear and nonlinear control methods, neural network control, adaptive control and fuzzy logic control.9,10 In quad-rotor UAVs with multiple attitude control strategies, there are unmodelled disturbances and parameter variations as uncertainties, in addition to considering that external factors have a significant impact on the stability of the UAVs, such as nonlinear friction and payload variations.11–13 This requires the development of a control methodology for UAVs with adaptive laws that can rapidly converge and exhibit enhanced robustness.
The sliding mode control (SMC) technique is an effective tool for designing robust control laws in nonlinear systems with uncertain conditions. 14 For example, an adaptive sliding mode controller in Mehmood et al. 15 is designed to compensate for the effects of external disturbances and parametric uncertainties. However, the aforementioned control scheme doesn’t consider problems associated with finite time convergence. Compared with SMC, the terminal sliding mode control technique enables the implementation of convergence in finite time. 16 Therefore, a novel sliding mode controller is proposed in Mofid and Mobayen, 17 which is able to not only establish a fast convergence rate but also adaptively tune the control parameters to guesstimate the unknown parameters of the quad-rotor system. Building upon the concept of finite-time convergence, some researchers have explored predefined-time stability. A predefined-time adaptive distributed controller is designed in Qiu et al. 18 using the backstepping method. This proposed control scheme achieves shorter settling time and smaller tracking errors within a predefined time.
However, the implementation of TSMC is not without challenges, most notably the chattering phenomenon, which causes high-frequency oscillations in control signals that can impair performance and cause increased wear to the actuators.19,20 To address the chattering issue in traditional sliding mode control, a gain optimization scheme for sliding mode control systems based on nonlinear adaptive particle swarm optimization was proposed in Bosera et al., 21 which demonstrated high control performance. The super-twisting algorithm exhibits enhanced robustness in comparison with traditional sliding mode control through the implementation of a smooth control law, which enables more effective management of system uncertainties and external perturbations and achieves a more robust controller in practical applications. The super-twisting control algorithm is designed in Kahouadji et al., 22 which drives the sliding variable, and it’s derivative to zero in finite time. An improved singular-free adaptive super-twisting sliding mode control method was proposed in Abera et al., 23 which utilized the particle swarm optimization (PSO) algorithm to adjust the controller gains. However, the aforementioned super-twisting controller usually requires the assumption that the external disturbances of the system have a known boundary. To overcome the above difficulty, a barrier function in Obeid et al. 24 is used to dynamically adjust the control gain, and ignore the disturbances upper boundary, ensuring sliding mode is achieved. The control gain compensates for the difference between the filtered estimate and the actual disturbance. The method enforces that the system reaches the sliding mode by increasing the gain and then decreasing the gain until it leaves the sliding mode, which for the second-order system used ensures that the sliding mode surfaces towards zero in finite time.
For attitude tracking control of UAVs with external disturbances, the mentioned TSMC can improve control of effects. However, implementing this method can be challenging due to the requirement of a good understanding of the system structure. In Zhao et al. and Zhi et al.,25,26 the observer-based H
To implement adaptive neural sliding mode controller and attitude tracking control of a quad-rotor UAV, inspired by the design structure of different RNNs, this paper proposes a novel triple-loop RNN structure. Compared to the traditional RNN, the triple-loop RNN calculates firing and output weights by neurons in the hidden and output layers. To reduce uncertain disturbance and eliminate the impact of neural approximation errors, a switching controller and a compensator controller are implemented in the control system.
The innovations of this article are described below:
A new neural network structure with a triple-loop has been designed, and the hidden layer neurons receive feedback from themselves and other neurons. Additionally, the input layer receives feedback from both the hidden layer and the output layer neurons. This strengthens the neural network’s ability to capture dynamics and store information and effectively improves the approximation speed of the neural network.
The neural network uses the enhanced sigmoid function as the activation function to avoid gradient saturation, and the continuous function also simplifies the derivation.
The super-twisting algorithm is based on the barrier function and is not affected by the upper bound of the unknown disturbance. This guarantees that the output values remain within a predefined neighbourhood.
The rest of the article is organized as follows. In Section II, the attitude dynamics model of a quad-rotor UAV is given. Section III presents the complete design process of the controller with a triple-loop RNN, and performs stability analyses. Section IV verifies the effectiveness of the proposed controller through experiments. Finally, conclusions are given in Section IV.
Problem formulation and preliminaries
To obtain the attitude dynamics equation of the quad-rotor, the roll, pitch and yaw angles are defined as

with
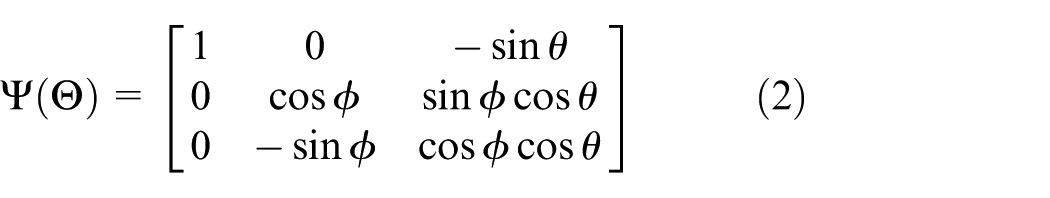

As we consider that the quad-rotor UAV is axisymmetric, the matrix

with the input from the controller, the matrix M is given by:

which the

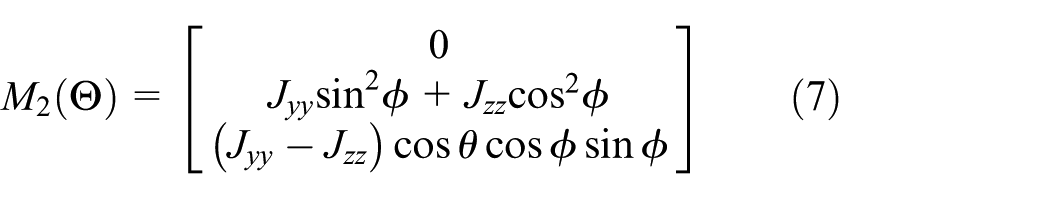

Consider a 3-DOF quad-rotor dynamical system, which simplified state-space form of this model is given:

where


Therefore, the objective can be summed up as follows: for the design of the control laws
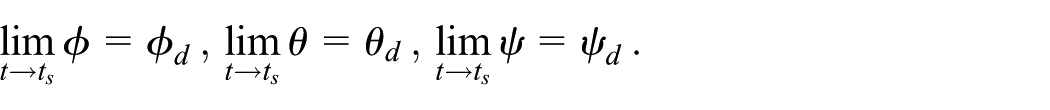
1.
2. The function
In this study, the barrier function as follows:


Suppose a continuous positive definite function

Then, the origin of the system is a finite time stable equilibrium. The settling time

Design of adaptive recurrent neural network sliding mode control
Terminal sliding mode controller
Consider the attitude system (equation (9)):

where
Define the attitude tracking error as follows:

The time derivative of the error can be expressed as:

In order to improve the fast convergence characteristics of the system, inspired by Yang et al., 37 consider the terminal sliding mode as:
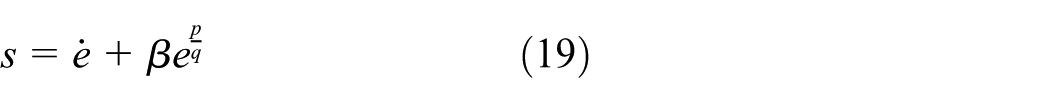
where the

According to equation (20), the equivalent controller

We can obtain the closed-loop dynamical equation:
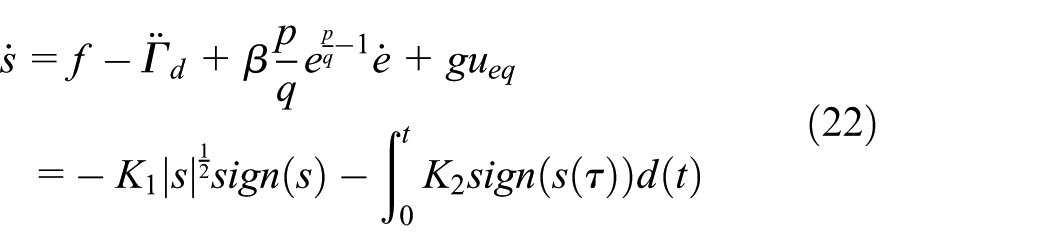
The
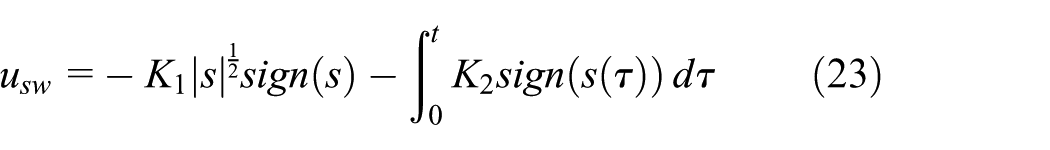
which the

where the

For the definition of this barrier function,
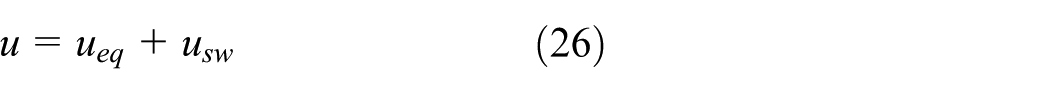
Substituting equation (26) to obtain the derivative of equation (19):
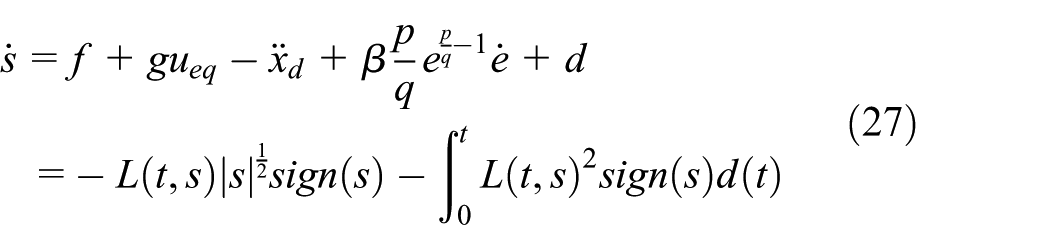
Rewrite of the above equation, let us take:


where

where
where

Taking the derivative of

From equation (30):

According to the Song et al.,
36
we can know
To guarantee that the attitude system tracks the desired trajectory in finite time, consider the Lyapunov function as:

From equation (19), taking the derivative of

Hence, the attitude system will converge to the desired trajectory in finite time. From Song et al.,
36
the finite time
TLRNN structure
The newly proposed neural network architecture is illustrated by Figure 1. This neural network is composed of three layers, which are the input layer, the hidden layer with self-feedback capability and the output layer. In addition, the developed neural network has
1. Input layer: Neurons in this layer receive input signals, and feedback signals from neurons in the other two layers. Therefore, the input signal of this layer can be written as follows:
the signal
2. Hidden layer: The neurons in this layer receive feedback from themselves and signals from all other neurons. Therefore, the input signal of this layer can be given as follows:

where
3. Output layer: The output layer receives the signals of the hidden layer and provides delayed feedback signals to the hidden layer and the input layer, which output can be written as:

where

Structure of the TLRNN.

The difference of structure for RNN, DLRNN and TLRNN.
Design of the attitude controller
In this section, the main work is to present the design process for the adaptive TLRNN sliding mode controller. The dedicated control method proposed in this study is introduced in Figure 3. The attitude controller consists of a TLRNN, a compensator and a switching control, and the parameters of each unit are updated in time, which performs the estimation of three input signals, that is,

Block diagram of the TLRNN.
Consider the equivalent controller of the control system obtained by TLRNN approximated:

where the
Based on the description above, the controller

where

where the

From the Taylor expansion, we obtain the following function expression:

with

Substituting equation (41) from equation (40) and using equation (46), the following differences can be obtained:

where the
The

where
The real-time updated neural network weights are expressed as follows:
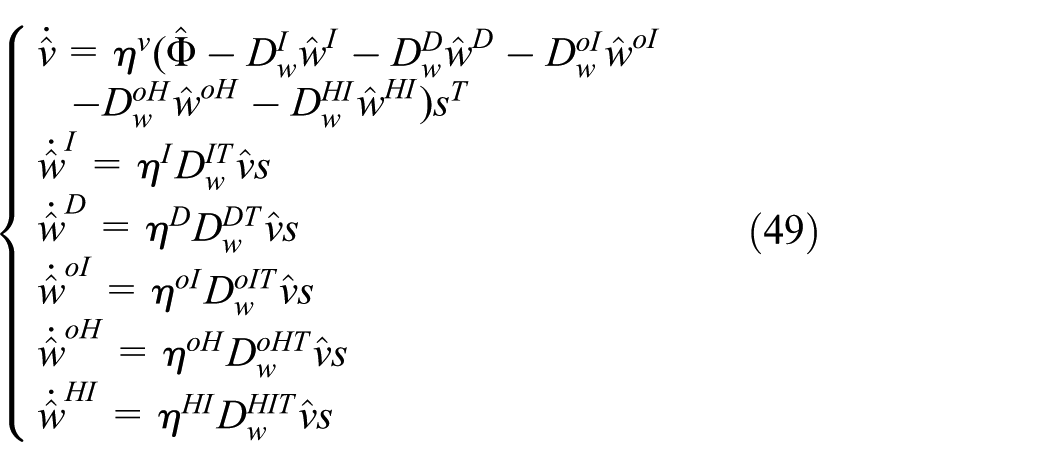
where

Taking the derivative of

Substituting equations (43), (47) and (49) into equation (51), we can get:
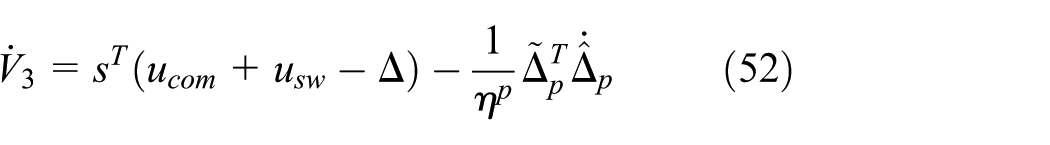
When

where
2. When

where
Due to

The derivative of

According to the definition of barrier function in equation (25), we divide the proof into two parts:
When

where
2. When

where
According to the proof of Theorem 1, the attitude system will converge to the desired trajectory in a finite time. Therefore, the proof is finished.
Simulation results
To demonstrate the superiority, three experiments are considered to validate the proposed TLRNN-based sliding mode controller on a quad-rotor. Firstly, comparison with a double loop recurrent neural network in Fei and Lu, 40 that is, DLRNN. Secondly, compared with traditional neural network architectures, that is, RBF. Finally, compared with an integral fast terminal sliding mode controller in Ghadiri et al., 33 that is, IFTSMC.
Parameter section
Sliding mode parameters: The parameters
Super-twisting gains: The initial linear gain
NN learning rates: The learning rates for the TLRNN were set to a common, relatively small value (0.001) to ensure stable and smooth weight adaptation without causing overshoot or oscillation in the control signal. This is a standard practice in adaptive control to ensure the separation of dynamics between the fast controller and the slower parameter update laws.
Compensator gain: This gain provides additional robustness. It was set to a small value (0.01) to minimally influence the nominal controller performance while ensuring steady-state error elimination.
The limits of input saturation are:
Comparative analysis
Figure 4 shows the tracking results of the actual attitude compared to the desired attitude, which is obtained using the three different methods. In the figure, we can see that roll, pitch and yaw signals are successful in tracking the desired trajectory, and that the proposed method is the fastest. Therefore, we can also conclude that the proposed method is better than the other two methods in the presence of perturbations.

After incorporating multiple rounds of simulation experiments, the comparison of stabilization times under the stabilization error threshold of 0.01 is presented in Table 1 below.
Stabilization time comparison under different neural network estimators.

To demonstrate the performance comparison under different payload conditions, we doubled the mass parameter
Stabilization time comparison under different neural network estimators with

The Figure 5 shows a comparison of the tracking errors for the three attitude angles. From the figure, it can be seen that the three tracking errors obtained by the proposed method converge to zero in the shortest possible time.
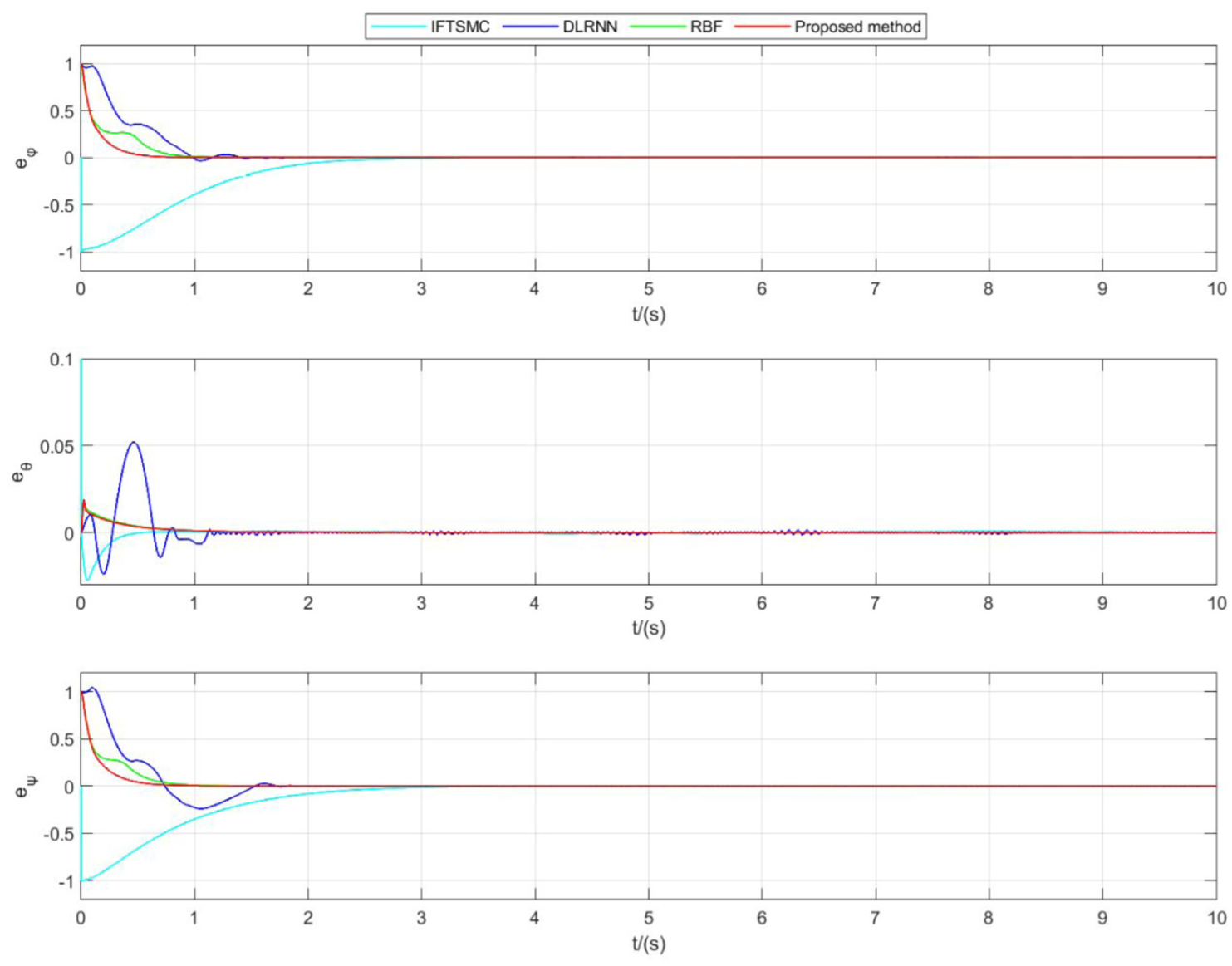
The comparison of the sliding surfaces of the three methods can be shown in Figure 6. The sliding surfaces under each method converge to the origin in finite time, and the proposed method is superior to other methods in convergence time.

In addition, the control inputs of three attitudes are shown in Figure 7. The proposed method has more stable control inputs and less chattering compared to using RBF and DLRNN. Based on the described barrier function, an effective reduction of the control input can be observed after the time

Control inputs

Time-varying disturbance.
Furthermore, several performance metrics related to tracking errors are utilized to demonstrate the effectiveness of the proposed methodology.
Integral absolute error (IAE): IAE =
Integral time absolute error (ITAE): ITAE =
The triple-loop feedback structure of the TLRNN enables a more dynamic memory and richer representation of the system’s uncertain dynamics (
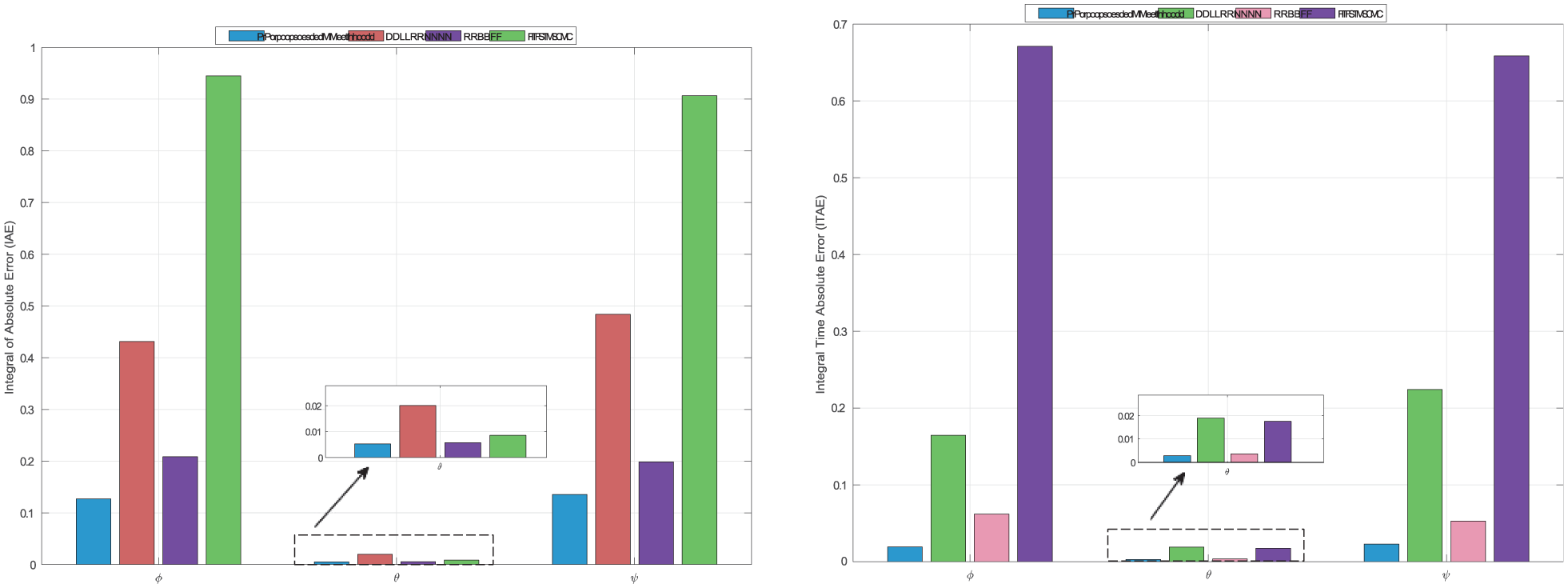
Performance metrics comparison: (a) IAE and (b) ITAE.
The ITAE metric specifically penalizes errors that persist over time. The barrier function-based gain
In conclusion, according to the tracking trajectories, tracking errors, sliding mode surfaces and control inputs for roll, pitch and yaw angle under four different methods, the finite time tracking of quad-rotor UAV attitude by the proposed method can be obtained, which also proves the fast and accurate estimation of unknown dynamics by TLRNN and ensures the good stability of the system.
Additionally, we have deployed a quadrotor UAV hardware platform to validate the proposed algorithm in Figure 10. The UAV is equipped with an integrated flight control system embedded in the onboard computer (avionics computer), which is powered by a dedicated battery module. A real-time data communication module enables bidirectional interaction with the ground control station (GCS), facilitating the transmission of flight commands from the GCS to the UAV and the feedback of flight status data to the ground. The entire system operates through the coordinated execution of the power module, actuator, flight control unit and data communication unit, forming a closed-loop control structure that ensures stable and reliable autonomous flight.

The quadrotor’s hardware structure.
The proposed TLRNN controller in this work indeed introduces higher computational complexity compared to linear controllers (e.g. PID) or feedforward neural networks (e.g. RBF). This complexity primarily stems from the forward computation of the triple feedback loops and the online parameter update laws (equation (49)). A preliminary analysis indicates that for a network structure with m = 9, n = 7, q = 3, the computational load per control cycle is estimated to be within 400 floating point operations (FLOPs). Although this exceeds the requirements of simpler controllers, such a computational demand remains well within the capabilities of modern mainstream embedded flight control processors (e.g. STM32H7 series), allowing stable operation at control frequencies of 1 kHz or even higher. The real-time feasibility of the algorithm has been validated through simulations with a control period of 1 ms (1 kHz).
Conclusion
A triple-loop recurrent neural network super-twisting terminal sliding mode control scheme based on the barrier function is proposed for the attitude tracking control problem of a quad-rotor UAV with model uncertainty. The new neural network TLRNN is mainly used to approximate the unknown part of the equivalent controller. Compared with the conventional neural network, the newly designed TLRNN better estimates the unknown dynamics and can achieve better approximation performance. The parameters of the newly designed neural network are mediated online by adaptive laws. In addition, using a variable gain super-twisting algorithm based on a barrier function, the scheme also effectively reduces chattering. The proposed technique is compared with the conventional neural networks RBF and DLRNN, and the experimental results show that the proposed technique is superior to RBF and DLRNN in the attitude tracking control of quad-rotor UAVs.
Limitations and future work
Although the proposed TLRNN-based controller demonstrates superior performance in simulations, several challenges remain. Firstly, the computational burden of the triple-loop structure may limit its application in real-time systems with limited processing power. Future work will focus on optimizing the network structure and implementing it on embedded platforms. Secondly, the performance relies on the initial weights and learning rates, which may require careful tuning. Automated hyperparameter optimization techniques could be explored. Lastly, the proposed TLRNN introduces additional computational load compared to traditional controllers due to its triple-loop feedback structure and online parameter updates. A theoretical analysis estimates the complexity to be approximately
Footnotes
Handling Editor: Chaofang Hu
Funding
The author received no financial support for the research, authorship and/or publication of this article.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.